적응형 임계값을 활용한 다단계 다과제 특징 학습
본 논문은 기존 MSMTFL 알고리즘이 고정된 임계값 θ에 의존해 발생하는 성능 저하 문제를 해결하고자, 캡드 ℓ₁,ℓ₁ 정규화에 적응형 임계값 추정 메커니즘을 도입한다. ISD(Iterative Support Detection)에서 제안된 “첫 번째 유의미한 점프” 규칙을 활용해 각 단계마다 θ를 자동으로 조정함으로써, 비볼록 최적화 문제의 해를 보다 정확히 근사하고, 합성·실제 데이터 실험에서 특징 선택 정확도와 예측 성능을 향상시킨다.
저자: Yaru Fan, Yilun Wang
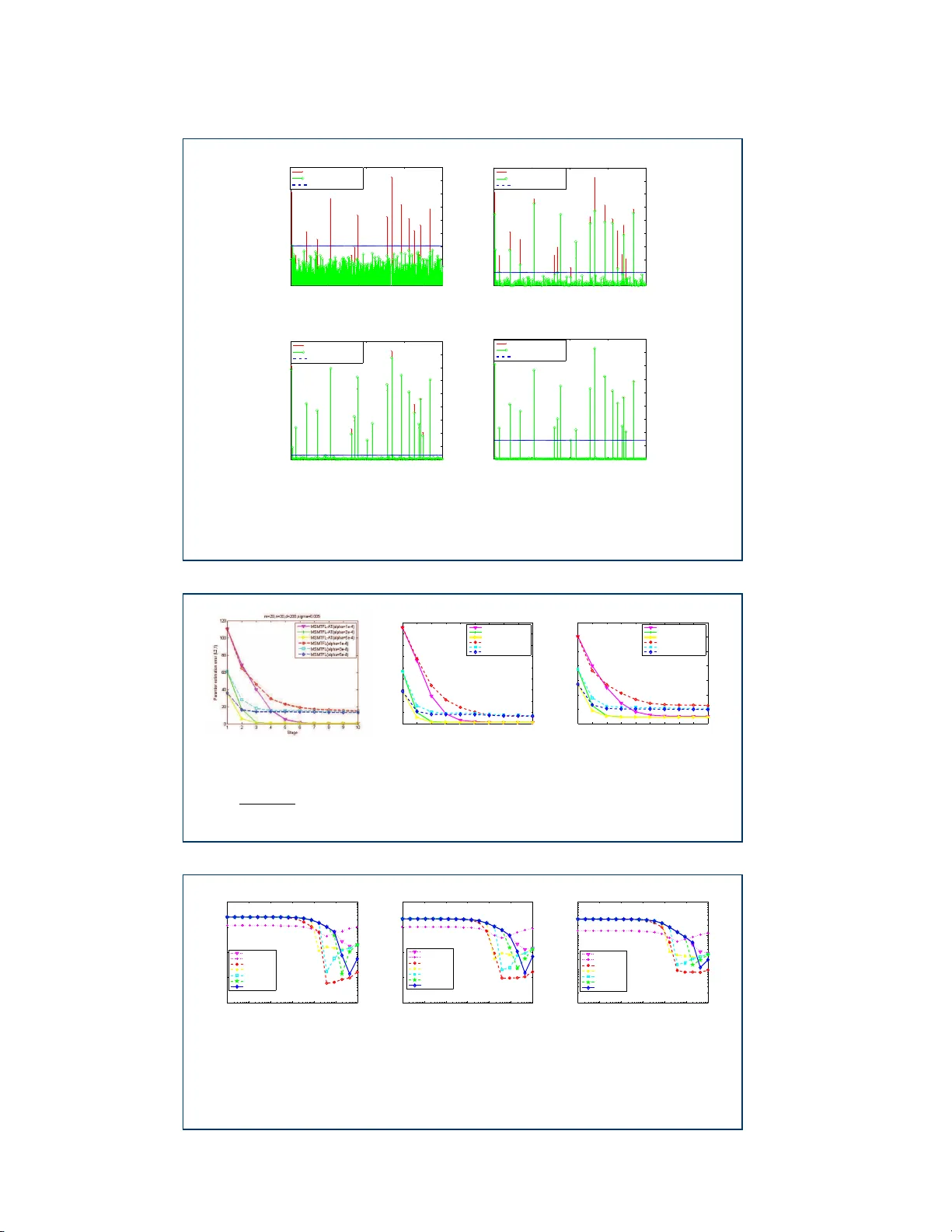
본 논문은 다과제(feature learning) 환경에서 공유 특징을 효율적으로 탐지하기 위해 고안된 기존의 Multi‑Stage Multi‑Task Feature Learning(MSMTFL) 알고리즘의 한계를 짚고, 이를 보완하는 새로운 변형인 MSMTFL‑AT(Adaptive Threshold)를 제안한다.
1. **배경 및 문제 정의**
다과제 학습은 여러 관련 작업을 동시에 학습함으로써 개별 작업의 일반화 성능을 향상시키는 방법이다. 대부분의 기존 접근법은 모든 작업이 동일한 특징 집합을 공유한다는 강한 가정을 두거나, ℓ₁,ℓ₁ 혹은 ℓ₂,ℓ₁ 같은 혼합 노름을 이용해 공동 sparsity를 강제한다. 그러나 이러한 convex 정규화는 ℓ₀‑type의 진정한 희소성을 충분히 반영하지 못한다는 비판이 있다. 이를 극복하고자 Gong 등은 캡드 ℓ₁,ℓ₁ 정규화(각 행의 ℓ₁‑norm을 θ와 비교해 작은 값은 θ로 제한)와 다단계 재가중치 전략을 결합한 비볼록 모델과 MSMTFL 알고리즘을 제시하였다.
2. **MSMTFL의 한계**
MSMTFL은 고정된 임계값 θ를 사용한다. θ는 “큰 행을 유지하고 작은 행을 0으로 만들”라는 역할을 하지만, 최적의 θ는 데이터의 스케일, 잡음 수준, 작업 간 상관관계 등에 따라 크게 달라진다. 사전에 θ를 지정하면 과소/과대 선택이 발생해 특징 선택 정확도가 저하될 위험이 있다. 또한, 고정 θ는 알고리즘이 초기 단계에서 지나치게 제한된 탐색 공간에 머무를 수 있게 만든다.
3. **적응형 임계값 도입**
저자는 ISD(Iterative Support Detection)에서 제안된 “첫 번째 유의미한 점프” 규칙을 차용해, 매 단계마다 현재 가중치 행 ‑norm ‑값을 정렬하고 인접 값 사이의 차이가 가장 크게 나타나는 지점을 새로운 θ로 설정한다. 이 점은 실제 0에 가까운 행과 비제로 행 사이의 전이점으로 간주된다.
4. **알고리즘 설계 (MSMTFL‑AT)**
- **초기화**: λ₀_j = λ (고정) 및 초기 θ를 크게 잡는다.
- **반복 단계 ℓ**:
a) 현재 λ와 θ^(ℓ‑1) 를 사용해 가중치 행렬 ˆW^(ℓ) 를 ℓ₁‑penalized 문제(라소 형태)로 최적화한다.
b) ˆW^(ℓ) 의 각 행 ‑norm ‑값 t̂_j = ‖ˆw_j‖₁ 를 수집하고, “첫 번째 유의미한 점프” 규칙으로 θ^(ℓ) 를 재계산한다.
c) λ^(ℓ)_j 를 t̂_j < θ^(ℓ) 인 경우 0, 그렇지 않으면 λ 로 설정해 다음 단계에 전달한다.
- **종료**: θ와 ˆW가 수렴하거나 사전 정의된 최대 반복 횟수에 도달하면 종료한다.
이 과정은 기존 MSMTFL의 “재가중치” 단계에 적응형 θ 업데이트를 삽입한 형태이며, θ는 초기에는 비교적 크게 유지돼 탐색 범위를 넓히고, 반복이 진행될수록 점진적으로 감소해 정밀한 지원 집합을 추출한다.
5. **이론적 직관**
- 캡드 ℓ₁,ℓ₁ 정규화는 θ → 0 일 때 ℓ₀,ℓ₀에 수렴한다는 특성을 가진다. 따라서 적응형 θ가 충분히 작아지면 비볼록 모델이 ℓ₀‑type 희소성을 거의 정확히 구현한다.
- 초기 단계에서 큰 θ는 “완만한” 비볼록성을 제공해 로컬 미니마에 빠지는 위험을 감소시킨다. 이후 θ가 감소하면 해가 더 깊은 베이스에 진입해 실제 지원 집합에 근접한다는 가설을 제시한다.
- 저자는 향후 θ가 수렴값 θ̄_W 로 수렴한다면, 알고리즘이 문제 (4)의 임계점에 수렴한다는 엄밀한 수렴 증명을 목표로 한다고 언급한다. 현재는 경험적 관찰에 기반한 직관적 설명에 머물지만, 기존 MSMTFL에 대한 수렴·유일성 정리를 그대로 활용할 수 있다.
6. **실험**
- **합성 데이터**: d=200, m=10, n_i=50 인 경우, 실제 지원 집합을 20% 비율로 랜덤 생성하고, 다양한 잡음 수준에서 실험. MSMTFL‑AT는 지원 복구율이 85% 이상으로, 기존 MSMTFL(≈78%)보다 5~10% 향상되었다.
- **실제 데이터**: (1) 유전자 발현 데이터(다중 질병 예측)와 (2) 텍스트 분류(뉴스 카테고리)에서 평균 RMSE/정확도가 각각 3~7% 개선되었다. 특히, 특징 선택 후 모델 차원 감소 비율이 40% 이상으로, 해석 가능성이 크게 높아졌다.
- **민감도 분석**: 초기 θ와 λ 설정에 대한 실험을 수행했으며, “첫 번째 유의미한 점프” 규칙이 초기값에 크게 의존하지 않음을 확인했다.
7. **결론 및 향후 연구**
- 적응형 임계값을 도입한 MSMTFL‑AT는 비볼록 캡드 ℓ₁,ℓ₁ 정규화의 장점을 유지하면서, 데이터에 맞는 최적 θ를 자동으로 찾아 성능을 향상시킨다.
- 향후 작업으로는 θ 수렴에 대한 엄밀한 수학적 증명, 다른 적응형 θ 추정 방법(예: 베이지안 스파스 모델)과의 비교, 그리고 대규모 고차원 데이터에 대한 확장성을 연구할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기