Robust Clustering Using Outlier-Sparsity Regularization
Notwithstanding the popularity of conventional clustering algorithms such as K-means and probabilistic clustering, their clustering results are sensitive to the presence of outliers in the data. Even a few outliers can compromise the ability of these…
Authors: Pedro A. Forero, Vassilis Kekatos, Georgios B. Giannakis
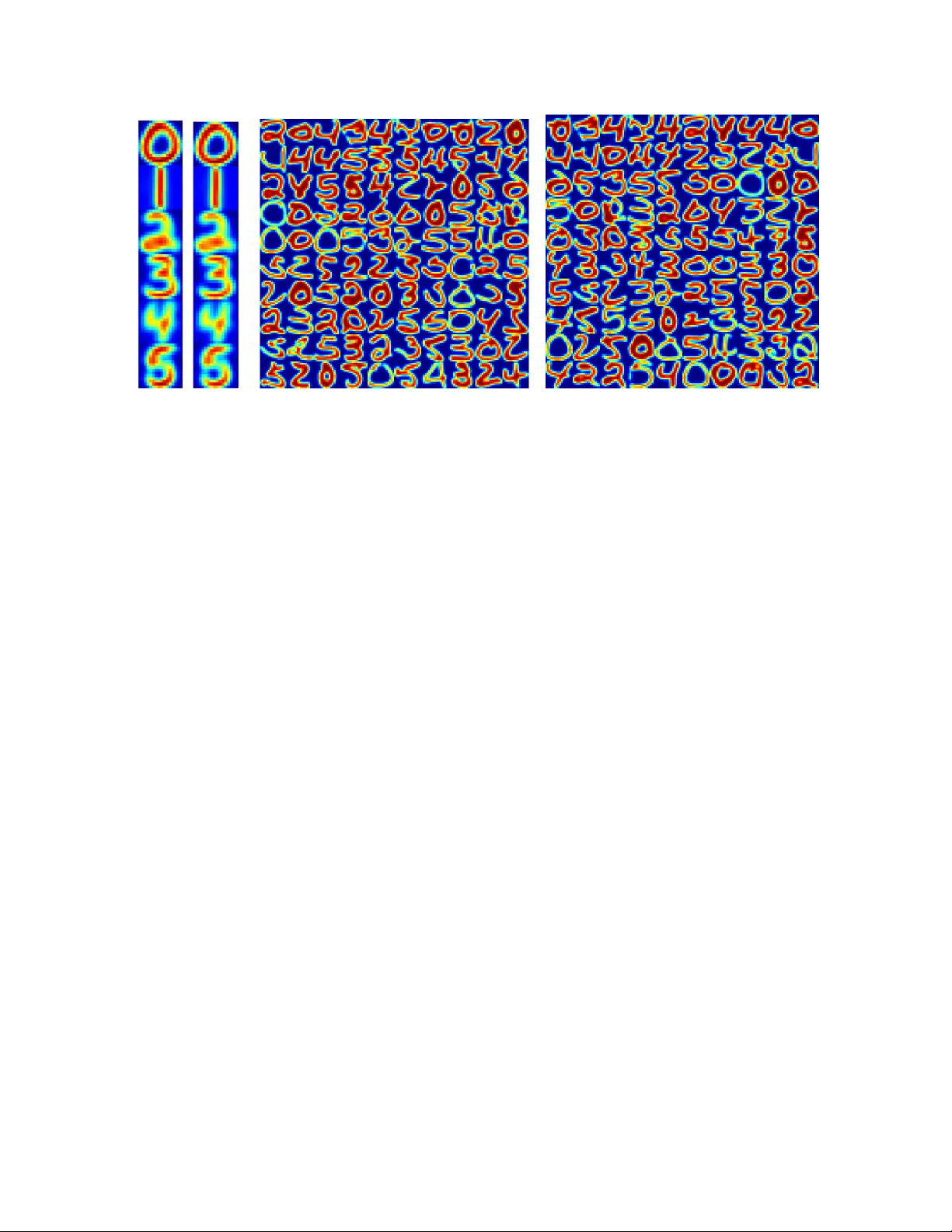
1 Rob ust Clustering Using Outlier -Sparsity Re gularizat ion Pedro A. Forero, Student Member , IEEE, V assilis Ke katos, Member , IEEE, and Geor gios B. Giannaki s (Contact Author)*, F ellow , IEEE Abstract Notwithstanding the popular ity of con ventional clustering algo rithms such as K- means an d p roba- bilistic clustering, their clustering resu lts are sensiti ve to the presen ce of outliers in the data. Even a few outliers can compro mise the ability of these algorithm s to identify mea ningfu l hidden structures renderin g their outcome unreliable. This paper develops robust clu stering algorithms th at not only aim to cluster the d ata, but also to iden tify the o utliers. The n ovel approach es rely on the infre quent presenc e of ou tliers in the data which translates to sparsity in a jud iciously chosen domain. Capitalizing on the sparsity in the o utlier domain, outlier-aware robust K-mean s and probab ilistic clustering approach es are pr oposed. Their novelty lies on iden tifying outliers while effecting sparsity in the outlier doma in through carefully chosen regularization. A block coo rdinate descent appr oach is dev elope d to o btain iterati ve algorithm s with convergence guarantees and small excess computatio nal c omplexity with respect to their n on-ro bust counterp arts. K ernelized versions of the robust clustering algor ithms are also developed to efficiently handle high-dim ensional data, identify nonline arly sep arable clusters, o r e ven cluster objects that are not represented by vectors. Numerical tests on both synthe tic a nd real datasets validate the perfo rmance a nd applicability of the novel alg orithms. Index T erms (Block) coordin ate descent, clustering, expectation-m aximization algorithm , Group- Lasso, kernel methods, K-means, mixture mo dels, ro bustness, sparsity . Part of this work was presented at the 36th IEEE Intl. Conf. on Acoustics, S peech, and Signal Processing, Prague, Czech Republic, May 2011. W ork was in part supported by NSF grant CCF-1016605; Dr . Kekatos was funded by the European Community’ s Sev enth Framew ork P rogramme (FP 7/2008 under grant agreement No. 234914). The authors are with the ECE Dept., Univ ersity of Minnesota, Minneapolis, MN 55455, U SA, Emails: { forer002,k ekatos,georgios } @umn.edu May 22, 2018 DRAFT 2 I . I N T RO D U C T I O N Clustering aims to partition a set of d ata into su bsets, called clus ters, such that data assigne d to the same clus ter are simil ar in s ome se nse. W orking with un labeled da ta and u nder minimal ass umptions makes c lustering a cha llenging, yet u niv ersal tool for revealing data structures in a g amut of a pplications such as DNA microarray a nalysis and bioinformatics, (soc ial) network analysis, image proc essing, and data mining [31], [14]. Moreover , clustering can serve as a pre-processing step for supervised learning algorithms in applications wh ere labe ling data one -at-a-time is costly . Multiple interpretations a cross disciplines of what a cluster is, have led to an abundant literature of app lication-specific a lgorithms [31 ]. Among the algorithms wh ich cluster da ta represen ted by vectors, K-mean s and Gaus sian mixture model (GMM-)based c lustering a re two popu lar sch emes [22], [31]. Con ventional K-means relies on the Euc lidean distance a s a similarity me asure, thereby yielding pa rtitions that minimize the within- cluster s catter [14]. Contrastingly , s oft (a.k.a . fuzzy) K-means is tailored to identify overlapping clusters by allowing e ach da tum to be long to multiple c lusters [1]. GMM-bas ed clus tering conside rs ob served data drawn from a probability de nsity function (pdf) follo wing a G MM, where eac h c lass-cond itional pdf c orresponds to a cluster [31]. Clustering a rises as a by-produ ct of a maximum likelihood (ML) estimation framew ork for the GMM parame ters. ML parameter estimates are typically obtained through the expectation-maximization (EM) algorithm [9]. Kernel metho ds have been devised to enab le clustering of nonlinearly sep arable clusters [26], [25]. Notwithstanding their pop ularity , K-mean s a nd GMM-based clustering are se nsiti ve to inconsisten t data, termed outliers, due to their func tional de pende ncy on the E uclidean distanc e [16]. Outliers appea r infrequently in the data, eme r ging e ither due to reading errors or be cause they belong to rarely-seen and hence, markedly informati ve phe nomena. Howev er , even a fe w outliers can render clustering unreliable: cluster centers and model p arameter estimates can be se verely bias ed, and thus the d ata-to-cluster assignme nt is dete riorated. This mo ti vates robustif ying clustering a pproache s against outliers at affordable computational complexity in order to unravel the u nderlying structure in the d ata. Robust clus tering approach es to clus tering h ave been in vestigated . In [8] and [15], an add itional cluster intended for g rouping outliers is introduced with is cen troid a ssumed equidistant from all non -outlying data. Possibilistic clustering measures the so-called typicality of each datum with respect to (wrt) each cluster to de cide whether a datum is a n outlier [20], [24]. However , pos sibilistic clustering is sen siti ve to initialization and ca n output the s ame cluster more than once. Clustering approac hes originating from robust statistics, such as the minimum volume ellipsoid a nd Huber’ s ǫ -con taminated model-based metho ds May 22, 2018 DRAFT 3 [18], [34], extract one clus ter at a time. This defla tion a pproach ca n hinder the unde rlying d ata structure by removing eleme nts b efore se eking other clusters. Other approache s roo ted on robust statistics are based on the ℓ 1 -distance (K-medians), Tuk ey’ s biweighted func tion, and trimmed means [3], [19], [12], [32]; but a re all limited to linea rly separab le clus ters. The first co ntrib ution of the p resent work is to introduce a data model for c lustering that explicitly accoun ts for outliers via a deterministic o utlier vector per datum (Se ction II). A datum is d eemed a n outlier if its corresponding outlier vector is non zero. Translating the fact that outliers are ra re to sp arsity in the outlier vector d omain lea ds to a neat connection between clustering and the compres siv e sampling (CS) paradigm [5]. Building on this mo del, a n o utlier -aware clustering method ology is developed for clustering both from the deterministic (K-mean s), and the proba bilistic (GMMs) perspec ti ves. The seco nd con trib ution of this work comprises various iterativ e clustering algorithms developed for robust hard K-mean s, s oft K-means, and GMM-based clustering (Se ction III). The algorithms are base d on a block coordina te descent (BCD) iteration and yield closed-form updates for each se t of optimization variables. In p articular , e stimating the outliers bo ils down to solving a group-Las so problem [33], whose solution is compute d in clos ed form. The novel robust clustering algorithms op erate at a n a f fordable computational complexity of the same order a s the one for their no n-robust cou nterparts. Several c ontemporary applications in bioinformatics, (social) n etwork ana lysis, imag e processing, and mac hine learning ca ll for o utlier -aware clustering of h igh-dimensional data, or in volve nonlinearly separab le clusters . T o accommoda te these clustering needs, the novel algorithms are kernelized in Sec tion IV; and this i s the third contributi on of our work. The assumed model not only enables such a kernelization for both K-mea ns and the probab ilistic se tups, but it also yields iterativ e a lgorithms with c losed-form updates. In Section V, the algorithms developed are tested using synthetic as well as real datasets from handwritten digit recognition sy stems and s ocial networks. The results corrobo rate the effecti veness of the methods . Co nclusions are drawn in Section VI. Notation: Lower -(upper- )case boldface letters a re res erved for column vectors (matrices), a nd calli- graphic letters for sets; ( · ) T denotes transposition; N N the set o f n aturals { 1 , . . . , N } ; 0 p ( 1 p ) the p × 1 vector of all zeros (one s); I p the p × p identity matrix; diag ( x 1 , . . . , x p ) a p × p diagona l matrix with diagonal entries x 1 , . . . , x p ; range( X ) the rang e sp ace of matrix X ; E [ · ] denotes the expec tation operator; N ( x ; m , Σ ) d enotes the multi variate Gauss ian pdf with mean m and covariance matrix Σ ev a luated at x ; k x k A := √ x T Ax for a p ositi ve semidefinite matrix A ; k x k p := ( P n i =1 | x i | p ) 1 /p for p ≥ 1 stands for the ℓ p -norm in R n . May 22, 2018 DRAFT 4 I I . S PA R S I T Y - A W A R E C L U S T E R I N G : C O N T E X T A N D C R I T E R I A After re viewing the clustering task, a mod el pertinent to outlier-contaminated data is introduced next. Building on this mod el, robust a pproache s are d ev eloped for K-mean s (Section II-A) as well as probabilistic clustering (Section II-B). A. K -means Clustering Gi ven a set of p -dimensional vectors X := { x 1 , . . . , x N } , let {X 1 , . . . , X C } be a partition of X to C subsets (clusters) X c ⊂ X for c ∈ N C , which are collectively exhaustive, mutually exc lusiv e, a nd non- empty . Partitional c lustering s eeks a partition of X such tha t two vectors assign ed to the same c luster are closer to ea ch other in some well-define d sense, such as the Euc lidean distance, than to vec tors ass igned to other clus ters. Among partitional c lustering methods, K-mea ns is one of the most widely used with well-docume nted merits and a long history [4]. I n the K-means setup, a centroid m c ∈ R p is introduced per cluster X c . Then, instead of comparing distanc es b etween pairs of points in X , the point-centroid distances k x n − m c k 2 are considered . Moreover , for each input vector x n , K-means introduces the unknown membe rships u nc for c ∈ N C , define d to be 1 when x n ∈ X c , an d 0 othe rwise. T o gu arantee a valid partition, the membership coefficients apa rt from being b inary (c1) : u nc ∈ { 0 , 1 } ; they s hould also satisfy the co nstraints (c2) : P N n =1 u nc > 0 , for all c , to preclude emp ty clus ters; and (c3) : P C c =1 u nc = 1 , for all n , so that ea ch vector is assigned to a clus ter . The K -means clustering task can be then posed as that of find ing the cen troids { m c } C c =1 and the c luster assignme nts u nc ’ s by so lving the optimization problem min { m c } , { u nc } N X n =1 C X c =1 u nc k x n − m c k 2 2 subject to (c1)-(c3) . (1) Howe ver , problem (1) is k nown to be NP-hard, even for C = 2 [7]. Practically , a suboptimal so lution is pu rsued us ing the ce lebrated K-means algorithm. This algorithm drops the (c2) c onstraint, which is checked in a po st-processing s tep instead. Then, it alternately minimizes the c ost in (1) wrt one o f the set o f variables { m c } a nd { u nc } , while keeping the othe r one fixed, and iterates. K-means iterations are guaranteed to co n verge to a s tationary point of (1) [28]. T o b etter mo ti vate and further u nderstand the pros a nd cons of K-means c lustering, it is instructive to postulate a pe rtinent data model. Suc h a mode l as sumes that the input vectors can be expres sed as x n = P C c =1 u nc m c + v n , whe re v n is a zero-mean vector cap turing the deviation o f x n from its assoc iated centroid m c . It is eas y to se e tha t u nder (c1)-(c3), the minimizers of (1) offer merely a b lind May 22, 2018 DRAFT 5 least-squares (LS) fit of the da ta { x n } N n =1 respecting the cluster assignmen t constraints. Ho wever , su ch a simplistic, yet widely a pplicable model, does not take into acco unt ou tliers ; that is points x n violating the assume d mod el. This fact paired with the sensitivity of the LS cost to large residuals explain K-means’ vulnerability to outliers [8]. T o robustify K-means, cons ider the follo wing data mode l which explicitly a ccoun ts for ou tliers x n = C X c =1 u nc m c + o n + v n , n ∈ N N (2) where the outlier vector o n is defi ned to be deterministically no nzero if x n correspond s to an outlier , an d 0 p otherwise. The unkn owns { u nc , m c , o n } in (2) can now be estimated using the LS app roach as the minimizers of P N n =1 x n − P C c =1 u nc m c − o n 2 2 , which are the ma ximum likelihood (ML) estimates if v n ∼ N ( 0 , σ 2 I p ) . E ven if u nc ’ s we re known, estimating { m c } an d { o n } ba sed so lely on { x n } would be an unde r -determined problem. The key obs ervation here is that most o f the { o n } are zero. This moti vates the following criterion for c lustering and identification of a t most s ∈ N N outliers min M , O , U ∈U 1 N X n =1 x n − C X c =1 u nc m c − o n 2 2 s. to N X n =1 I ( k o n k 2 > 0) ≤ s (3) where M := [ m 1 · · · m C ] , O := [ o 1 · · · o N ] , U ∈ R N × C denotes the membe rship matrix with e ntries [ U ] n,c := u nc , U 1 is the s et of a ll U matrices satisfying (c1) and (c3), a nd I( · ) d enotes the indica tor function. Due to (c1) an d (c3), eac h s ummand in the cost of (3) ca n b e rewrit ten as P C c =1 u nc k x n − m c − o n k 2 2 ; and the La grangian form of (3) a s min M , O , U ∈U 1 N X n =1 C X c =1 u nc k x n − m c − o n k 2 2 + λ N X n =1 I ( k o n k 2 > 0) (4) where λ ≥ 0 is an outlier -controlling p arameter . For λ = 0 , o n should be set e qual to the gene rally nonzero v alue x n − m c for a ny c and yield a z ero o ptimum c ost, in wh ich c ase a ll x n ’ s are declared as outliers. When λ → ∞ , the optimum o n ’ s are ze ro, all the x n ’ s are de emed outlier free, and the problem in (4) reduces to the K-means cost in (1). This reduc tion of the NP-hard K-mea ns problem to an insta nce of the problem in (4) e stablishes the NP-ha rdness of the latter . Along the lines of K-means , similar iterations could be pursued for suboptimally solving (4). Howev er , such iterations ca nnot provide any conv ergence gua rantees due to the discontinuity of the indicator function at zero. Aiming at a practically fe asible so lver of (4), consider first that U ∈ U 1 is given. The optimization wrt { M , O } remains n on-con vex d ue to P N n =1 I( k o n k 2 > 0) . Follo wing the s ucces sful CS paradigm, where the ℓ 0 -(pseudo)norm of a vec tor x ∈ R N , defined as k x k 0 := P N n =1 I( | x n | > 0) , was May 22, 2018 DRAFT 6 surrogated by its co n vex ℓ 1 -norm k x k 1 , the problem in (4) is replaced by min M , O , U ∈U 1 N X n =1 C X c =1 u nc k x n − m c − o n k 2 2 + λ N X n =1 k o n k 2 . (5) Our robust K-means approac h is to minimize (5), which is con vex in { M , O } , but remains jointly non-con vex. The algorithm for subo ptimally s olving the n on-con vex p roblem in (5) is postpo ned for Section III-A. Note that the minimization in (5) resembles the group La sso criterion u sed for recovering a bloc k-sparse vector in a linear regression setup [33]. This e stablishes an interes ting link b etween robust clustering and CS. A co uple of remarks are now in order . Remark 1 ( Mahalanobis distanc e). If the c ov ariance matrix of v n in (2) is known, sa y Σ , the Euclidean distance in (3)-(5) c an be replaced by the Mahalanobis dista nce k x n − m c − o n k 2 Σ − 1 . Remark 2 ( ℓ 1 -penalty for entry -wise outliers). The regularization term P N n =1 k o n k 2 in (5) enables iden- tifying who le data vectors as outliers. Re placing it b y P N n =1 k o n k 1 enables recovery of outlying data entries instead of the whole vector . Iterati ve solvers for this ca se c an be d eveloped using the methodology presented in Sec tion III; due to spac e limitations this case is not pursue d here. Constraints (c1) an d (c3) in (1) entail hard membersh ip ass ignments, meaning that ea ch vector is assigne d to a s ingle cluster . Howe ver , soft clus tering which allo ws ea ch vector to partially be long to several clusters, c an better identify overlapping clusters [1]. One way to obtain fractional memberships is via so ft K-mean s. So ft K-mean s diff ers from hard K-means by (i) relax ing the binary-alph abet con straint (c1) to the bo x c onstraint (c4 ): u nc ∈ [0 , 1] ; an d (ii) by raising the u nc ’ s in (1 ) to the q -th power , where q > 1 is a tuning parameter [1]. The robust soft K-mea ns sch eme proposed here amounts to replacing x n with its outlier-compensated version ( x n − o n ) , an d le veraging the sparsity of the { o n } ’ s. Thes e s teps lead to the following criterion min M , O , U ∈U 2 N X n =1 C X c =1 u q nc k x n − m c − o n k 2 2 + λ k o n k 2 (6) where U 2 is the set of all U matrices sa tisfying (c3)-(c4). An algorithm for approximately solving (6) is presen ted in Section III-A. Note that a hard partition of X can still be ob tained from the so ft u nc by assigning x n to the ˆ c -th cluster , where ˆ c := arg max c u nc . B. P r o babilistic Clustering An alternativ e way to p erform soft c lustering is by follo wing a p robabilistic approac h [31]. T o this end, a mixture d istrib ution mod el is po stulated for x n , while { u nc } C c =1 are now interpreted as unobse rved May 22, 2018 DRAFT 7 (latent) random v ariables. The centroids { m c } C c =1 are treated as deterministic parameters of the mixture distrib ution, a nd their ML estimates are subsequ ently obtained via the EM a lgorithm. T o accoun t for outliers, probab ilistic clustering is ge neralized to model (2). Su ppose that the { x n } ’ s in (2) are i.i .d. drawn from a m ixture model where the { o n } ’ s are deterministic parameters. The memberships u n := [ u n 1 · · · u nC ] T are laten t random vectors, co rresponding to the rows of U , and take values in { e 1 , . . . , e C } , where e c is the c -th column of I C . If x n is drawn from the c -th mixture compon ent, then u n = e c . As sume further that the class-conditional pdf ’ s are Gauss ian and mod eled as p ( x n | u n = e c ) = N ( x n ; m c + o n , Σ ) for all n an d c . This implies that p ( x n ) = P C c =1 π c N ( x n ; m c + o n , Σ ) with π c := Pr( u n = e c ) . If the x n ’ s are independent, the log -likelihood of the input data is L ( X ; π , M , O , Σ ) := N X n =1 log C X c =1 π c N ( x n ; m c + o n , Σ ) ! (7) where X := [ x 1 · · · x N ] , and π := [ π 1 · · · π C ] T . Controlling the number of outliers (numbe r o f zero o n vectors) suggests minimizing the re gularized nega ti ve log-likelihood as min Θ − L ( X ; Θ ) + λ N X n =1 k o n k Σ − 1 (8) where Θ := { π ∈ P , M , O , Σ ≻ 0 } is the s et of all mo del parameters, P is the proba bility simplex P := { π : π T 1 =1 and π ≥ 0 } , and Σ ≻ 0 mea ns tha t Σ is a pos iti ve definite matrix. An EM- based algorithm for so lving (8) is deriv ed in Se ction III-B. Having es timated the p arameters of the likelihood, the posterior proba bilities γ nc := Pr( u n = e c | x n ) ca n be readily obtained and interpreted as soft membersh ips. Although mo deling a ll clas s cond itionals having a common c ov ariance matrix Σ ma y se em res tricti ve, it gu arantees that the GMM is w ell-posed, thereb y av oiding sp urious unbound ed likelihood values [2, p. 433]. Sp ecifically , it is easy to see that even i f all o n ’ s are se t to zero, the log-likeli hood of a GMM with dif ferent covariance matrices Σ c per mixture grows u nbounde d, e.g., by se tting o ne of the m c ’ s equa l to an x n and letting Σ c → 0 for that particular c . This possibility for unbo undedn ess is also present in (8), and justifies the use of a common Σ . But even with a common c ovari ance matrix, the vectors o n can drive the log-likelihood in (7 ) to infinity . Consider for example, any ( m c , o n ) pair satisfying x n = m c + o n and let Σ → 0 . T o ma ke the problem of maximizing L ( X ; Θ ) we ll-posed, the k o n k Σ − 1 regularizer is introduced. Note also that for λ → ∞ , the optimal O is zero and (8) reduces to the c on ventional MLE estimation of a GMM; whereas for λ → 0 , the cost in (8) beco mes unbounde d from below . May 22, 2018 DRAFT 8 I I I . R O B U S T C L U S T E R I N G A L G O R I T H M S Algorithms for solving the problems formulated in Se ction II are dev eloped he re. Section III- A focuses on the minimization of (6), while the minimization in (5) is obtaine d from (6 ) for q = 1 . In Se ction III-B, an algorithm for minimizing (8) is deri ved base d on the E M approac h. F inally , mod ified versions of the new algo rithms with enhan ced res ilience to outliers are pursued in Section III-C. A. R obust (Soft) K -Means Algorithms Consider first solving (6) for q > 1 . Although the cost in (6) is jointly noncon vex, it is co n vex wrt eac h of M , O , a nd U . T o d ev elop a suboptimum yet practical solver , the aforementioned per- variable conv exity prompted us to devise a BCD algorithm, which minimizes the co st iterati vely wrt each optimization variable while h olding the other two variables fixed. Le t M ( t ) , O ( t ) , and U ( t ) denote the ten tati ve solutions found at the t -th iteration. Also, initialize U (0) randomly in U 2 , an d O (0) to ze ro. In the first step o f the t -th iteration, (6) is op timized wrt M for U = U ( t − 1) and O = O ( t − 1) . The optimization deco uples over the m c ’ s, and every m ( t ) c is the closed -form solution of an LS prob lem as m ( t ) c = N X n =1 ( u ( t − 1) nc ) q x n − o ( t − 1) n N X n =1 ( u ( t − 1) nc ) q . (9) In the se cond s tep, the task is to minimize (6) wrt O for U = U ( t − 1) and M = M ( t ) . The optimization problem decoup les per ind ex n , so that each o n can be found as the minimizer o f φ ( t ) ( o n ) := C X c =1 ( u ( t − 1) nc ) q k x n − m ( t ) c − o n k 2 2 + λ k o n k 2 . (10) The co st φ ( t ) ( o n ) is co n vex b ut non-diff erentiable. Howe ver , its minimizer can be expres sed in close d form as sh own in the ensu ing prop osition. Proposition 1. The op timization pr oblem in (10) is uniqu ely minimized by o ( t ) n = r ( t ) n " 1 − λ 2 k r ( t ) n k 2 # + (11) where [ x ] + := max { x, 0 } , an d r ( t ) n is defin ed a s r ( t ) n := P C c =1 ( u ( t − 1) nc ) q x n − m ( t ) c P C c =1 ( u ( t − 1) nc ) q . (12) May 22, 2018 DRAFT 9 Pr oof: Since P C c =1 ( u ( t ) nc ) q > 0 for all n a nd t d ue to (c3), the first summan d of φ ( t ) ( o n ) in (10) is a strictly conv ex function of o n . Hence, φ ( t ) ( o n ) is a strictly con vex function too and its minimizer is unique. The n, rec all that a vec tor o ( t ) n is a minimizer o f (10) if an d only if 0 ∈ ∂ φ ( t ) ( o ( t ) n ) , where ∂ φ ( t ) ( o n ) is the sub -dif ferential of φ ( t ) ( o n ) . For o n 6 = 0 , where the cost i n (10) is dif ferentiable, ∂ φ ( t ) ( o n ) is simply the gradie nt − 2 P C c =1 ( u ( t − 1) nc ) q x n − m c − 1 + λ 2 k o n k 2 o n . At o n = 0 , the s ub-diff erential of the ℓ 2 -norm k o n k 2 is the set of vectors { v n : k v n k 2 ≤ 1 } by definition, and then the sub-differential of φ ( t ) ( o n ) is ∂ φ ( t ) ( o n ) = n − 2 P C c =1 ( u ( t − 1) nc ) q x n − m c − λ 2 v n : k v n k 2 ≤ 1 o . When the minimizer o ( t ) n is nonz ero, the c ondition 0 ∈ ∂ φ ( t ) ( o ( t ) n ) implies 1 + λ 2 k o ( t ) n k 2 ! o ( t ) n = r ( t ) n (13) where r ( t ) n has be en de fined in (12). Equ ation (13) rev eals that o ( t ) n is a positiv ely s caled version of r ( t ) n . The scaling can b e readily found by taking the ℓ 2 -norm on both s ides of (13), i.e., k o ( t ) n k 2 = k r ( t ) n k 2 − λ/ 2 , which is valid for k r ( t ) n k 2 > λ/ 2 . Substituting this back to (13), yields o ( t ) n = r ( t ) n 1 − λ 2 k r ( t ) n k 2 . For o ( t ) n = 0 , there exists a v ( t ) n for which k v ( t ) n k 2 ≤ 1 and v ( t ) n = (2 /λ ) r ( t ) n . Th is is pos sible wh en k r ( t ) n k 2 ≤ λ/ 2 . These two cases for the minimizer of (10) are compa ctly expres sed via (11). The update for o ( t ) n in (11 ) reveals two interesting po ints: (i) the cost φ ( t ) ( o n ) ind eed fav ors zero minimizers; a nd (ii) the number of outliers is c ontrolled by λ . After upd ating vector r ( t ) n , its norm is compared against the threshold λ/ 2 . If k r ( t ) n k 2 exceeds λ/ 2 , vec tor x n is deemed an outlier , a nd it is compens ated by a nonzero o ( t ) n . Otherwise, o ( t ) n is set to zero and x n is clustered as a regular point. During the last s tep of the t -th iteration, (6) is minimized over U ∈ U 2 for M = M ( t ) and O = O ( t ) . Similar to the conv entional soft K-means, the minimizer is available in c losed form as [1] u ( t ) nc = C X c ′ =1 k x n − m ( t ) c − o ( t ) n k 2 2 + λ k o ( t ) n k 2 k x n − m ( t ) c ′ − o ( t ) n k 2 2 + λ k o ( t ) n k 2 ! 1 q − 1 − 1 . (14) Regarding the robust hard K-means, a s imilar BCD approach for s olving (5) leads to updating M ( t ) and O ( t ) via (9), and (11)-(12) for q = 1 . U pdating U ( t ) boils down to the minimum-distanc e rule u ( t ) nc = 1 , c = arg min c ′ k x n − m ( t ) c ′ − o ( t ) n k 2 0 , otherwise . (15) Note that (15) is the limit case of (14) for q → 1 + . The robust K-means (RKM) algorithm is tabulated as Algorithm 1 . RKM is terminated when k M ( t ) − M ( t − 1) k F / k M ( t ) k F ≤ ǫ s , where k · k F denotes the Frobenius norm of a matrix, and ǫ s is a small positi ve threshold, e.g., ǫ s = 10 − 6 . The comp utational resources need ed by RKM a re summarized next. May 22, 2018 DRAFT 10 Algorithm 1 Robust K-mea ns Require: Input da ta matrix X , number of clus ters C , q ≥ 1 , an d λ > 0 . 1: Initialize O (0) to zero and U (0) randomly in U 2 . 2: f or t = 1 , 2 , . . . do 3: Update M ( t ) via (9). 4: Update O ( t ) via (11)-(12). 5: Update U ( t ) via (14) ( q > 1 ) or (15) ( q = 1 ). 6: end f or Remark 3 ( Computational comp lexit y o f RKM). Suppose for con creteness that: (as1) the number of clusters is small, e.g., C < p ; and (as2) the numbe r of points is much la r ger than the inpu t dimension, i.e., N ≫ p . Wh en (as 2) does not hold, a modification o f RKM is developed in Sec tion IV. Und er (as1)- (as2), the con ventional K-means algorithm performs O ( N C p ) s calar ope rations per iteration, and re quires storing O ( N p ) sca lar variables. For RKM, careful coun ting s hows that the per iteration time-complexity is maintained at O ( N C p ) : (14) requires c omputing the N C Euclidean distances k x n − m ( t − 1) c − o ( t − 1) n k 2 2 and the N norms k o ( t − 1) n k 2 which is O ( N C p ) ; m ( t ) c ’ s are updated in O ( N C p ) ; while (11)-(12) en tail O ( N C p ) operations. Further , the me mory requirements of RKM are of the sa me order as tho se for K-means. Note also that the additional N × p matrix O c an be stored using s parse structures. The RKM iterations are con ver gent un der mild c onditions. Th is follo ws becau se the seque nce of cost function values is non-increas ing. Since the c ost is bound ed below , the function value seq uence s a re guaranteed to co n verge. Con ver genc e of the RKM iterates is ch aracterized in the follo wing p roposition. Proposition 2. The RKM algorithm for q ≥ 1 con verges to a coordinate-wise minimum of (6) . Mor eover , the hard RKM algorithm ( q = 1 ) conver ges to a local minimum of (5) . Pr oof: By d efining f s ( c ) as being zero wh en the Boolean argument c is true, and ∞ otherwise, the problem in (6) c an be written in the u nconstrained form min M , O , U N X n =1 C X c =1 u q nc k x n − m c − o n k 2 2 + λ k o n k 2 + f s ( U ∈ U 2 ) . (16) The cos t in (16), call it f ( M , O , U ) , is a proper and lower semi-continuous function, which implies that its non-empty le vel se ts a re closed. Also , since f is coe rci ve, its lev el sets are bounde d. Hence, the non-empty level sets of f are c ompact. For q > 1 , fun ction f ( M , O , U ) has a uniqu e minimizer per May 22, 2018 DRAFT 11 optimization block variable M , O , and U . Then, con vergence of the RKM algorithm to a coordinate-wise minimum point of (6) follows from [29, Th. 4.1 (c)]. When q = 1 , d efine the firs t s ummand in (16) as f 0 ( M , O , U ) := P N n =1 P C c =1 u nc k x n − m c − o n k 2 2 , which is the dif feren tiable part of f . Function f 0 has an open domain, and the remaining non-dif ferentiable part of f is s eparable wrt the optimization bloc ks. Hen ce, again by [29 , Th . 4.1(c)], the RKM algorithm with q = 1 con verges to a loca l minimum ( M ∗ , O ∗ , U ∗ ) of (6). It has be en shown so far that for q = 1 , a BCD iteration con ver ges to a local minimum o f (6). The BCD step for upd ating U is the hard rule in (15). Hen ce, this BCD algorithm (i) yields a U ∗ with bina ry entries, and (ii) essentially implemen ts the BCD updates for solving (5). Since a local minimum of (6) with binary as signments is also a local minimum of (5) , the claim of the proposition follo ws. B. R obust Probabilistic Clustering Algo rithm An EM approa ch is d eveloped in this subse ction to c arry out the minimization in (8). If U were known, the model parameters Θ co uld be es timated by minimizing the regularized negati ve log-likeli hood of the complete data ( X , U ) ; that is, min Θ − L ( X , U ; Θ ) + λ N X n =1 k o n k Σ − 1 (17) where L ( X , U ; Θ ) := N X n =1 C X c =1 u nc (log π c + log N ( x n ; m c + o n , Σ )) . (18) But since U is not obs erved, the cost in (17) is subop timally minimized b y iterating the two s teps of the EM method . Let Θ ( t ) denote the model parame ter values at the t -th iteration. During the E-step o f the t -th iteration, the expectation Q ( Θ ; Θ ( t − 1) ) := E U | X ; Θ ( t − 1) [ L ( X , U ; Θ ) ] is ev aluated. Since L ( X , U ; Θ ) is a linear function of U , and u nc ’ s are binary ran dom variables, it follows that Q ( Θ ; Θ ( t − 1) ) = N X n =1 C X c =1 γ ( t ) nc (log π c + log N ( x n ; m c + o n , Σ )) (19) where γ ( t ) nc := Pr u n = e c | x n ; Θ ( t − 1) . Using Baye s’ rule, the posterior probabilities γ ( t ) nc are ev aluated in closed form a s γ ( t ) nc = π ( t − 1) c N ( x n ; m ( t − 1) c + o ( t − 1) n , Σ ( t − 1) ) P C c ′ =1 π ( t − 1) c ′ N ( x n ; m ( t − 1) c ′ + o ( t − 1) n , Σ ( t − 1) ) . (20) During the M-step, Θ ( t ) is upda ted a s Θ ( t ) = arg min Θ − Q ( Θ ; Θ ( t − 1) ) + λ N X n =1 k o n k Σ − 1 . (21) May 22, 2018 DRAFT 12 A BCD strategy that upd ates ea ch set of the pa rameters in Θ o ne at a time with a ll other ones fixed, is described next. First, the cost in (21) is minimized wrt π . Given that P C c =1 γ ( t ) nc = 1 for all n , it is eas y to chec k that the minimizer of − P N n =1 P C c =1 γ ( t ) nc log π c over P is foun d in closed form as π ( t ) c = 1 N N X n =1 γ ( t ) nc for all c ∈ N C . (22) Subseq uently , (21) is minimized wrt M while π , O , and Σ are set respectively to π ( t ) , O ( t − 1) , a nd Σ ( t − 1) . The ce ntroids are updated as the minimizers of a weighted LS cos t yielding m ( t ) c = P N n =1 γ ( t ) nc x n − o ( t − 1) n P N n =1 γ ( t ) nc for all c ∈ N C . (23) Then, (21) is minimized wrt O while keeping the rest o f the mode l parameters fixed to their already updated values. Th is optimization decou ples over n , and one has to so lve min o n C X c =1 γ ( t ) nc 2 k x n − m ( t ) c − o n k 2 ( Σ ( t − 1) ) − 1 + λ k o n k ( Σ ( t − 1) ) − 1 (24) for all n ∈ N N . For a full covariance Σ , (24) c an be solved as a secon d-order cone program. For the case of s pherical c lusters, i.e., Σ = σ 2 I p , solving (24) simplifies c onsiderably . Spec ifically , the cost can then be written as P C c =1 γ ( t ) nc k x n − m ( t ) c − o n k 2 2 + 2 λσ ( t − 1) k o n k 2 , which is similar to the cos t in (10) for q = 1 , and for an ap propriately scaled λ . Building o n the solution of (10), the o n ’ s are upd ated as o ( t ) n = r ( t ) n " 1 − λσ ( t − 1) k r ( t ) n k 2 # + (25) after red efining the residua l vector a s r ( t ) n := P C c =1 γ ( t ) nc ( x n − m ( t ) c ) in lieu of (12). Interestingly , the thresholding rule of (25) shows that σ ( t − 1) aff ects the detection o f outliers. In fact, in this probabilistic setting, the thres hold for outlier iden tification is propo rtional to the value o f the o utlier -compens ated standard deviation es timate and, hence , it is adapted to the empirical distribution of the data . The M-step is c oncluded by minimizing (21) wrt Σ for π = π ( t ) , M = M ( t ) , and O = O ( t ) , i.e., min Σ ≻ 0 N X n =1 C X c =1 γ ( t ) nc 2 k x n − m ( t ) c − o ( t ) n k 2 Σ − 1 + N 2 log det Σ + λ N X n =1 k o ( t ) n k Σ − 1 . (26) For a generic Σ , (26) must be solved numerically , e.g., via gradient desce nt or interior point me thods. Considering sp herical clusters for simplicity , the first order optimality condition for (26) req uires s olving a qua dratic eq uation in σ ( t ) . Ignoring the negativ e root of this equation, σ ( t ) is found as σ ( t ) = λ 2 N p N X n =1 k o ( t ) n k 2 + v u u t 1 N p N X n =1 C X c =1 γ ( t ) nc k x n − m ( t ) c − o ( t ) n k 2 2 + λ 2 N p N X n =1 k o ( t ) n k 2 ! 2 . (27) May 22, 2018 DRAFT 13 Algorithm 2 Robust p robabilistic clustering Require: Input da ta matrix X , number of clus ters C , and pa rameter λ > 0 . 1: Randomly initialize M (0) , π (0) ∈ P , an d set Σ (0) = δ I p ( σ (0) = √ δ ) for δ > 0 , and O (0) to zero. 2: f or t = 1 , 2 , . . . do 3: Update γ ( t ) nc via (20) for all n, c . 4: Update π ( t ) via (22). 5: Update M ( t ) via (23). 6: Update O ( t ) by solving (24) ((25)). 7: Update Σ ( t ) ( σ ( t ) ) via (26) ((27 )). 8: end f or The robust probabilistic clustering (RPC) sch eme is tabulated as Algorithm 2. For sph erical clus ters, its complexity remains O ( N C p ) o perations pe r iteration, even though the cons tants in volved are larger than those in the RKM algorithm. Similar to RKM, the RPC iterations are con ver gent un der mild conditions. Con ver gence of the RPC iterates is established in the next proposition. Proposition 3. The RP C iterations c on verg e to a coordinate-wise minimum of the log-likeli hood in (7) . Pr oof: Combining the two steps of the EM a lgorithm, n amely (20) and (21) , it is easy to verify that the algorithm is e quiv alent to a sequence of BCD iterations for o ptimizing min Γ , Θ ′ − N X n =1 C X c =1 γ nc log π c N ( x n ; m c + o n , Σ ) γ nc + λ N X n =1 k o n k Σ − 1 + f s ( Γ ∈ U 2 )+ f s ( π ∈ P )+ f s ( Σ ≻ 0) (28) where Θ ′ := { π , M , O , Σ } , the N × C matrix Γ has e ntries [ Γ ] n,c := γ nc > 0 , and as in (16) that f s ( c ) is zero when co ndition c is true, a nd ∞ otherwise. Th at the { γ nc } are positiv e follows after us ing Bayes ’ rule to de duce that γ nc ∝ π c N ( x n ; m c + o n , Σ ) and noticing that (i) N ( x n ; m c + o n , Σ ) is positive for all x n , and (ii) all π c must be pos iti ve so that the cost in (28) remains fin ite. The o bjectiv e function of this minimization problem is proper , bou nded be low , and lo wer semi- continuous implying, that its non-empty level s ets are closed . Since this function is a lso c oerciv e, its lev el s ets are b ounded . Hence, its no n-empty lev el s ets are compa ct. Moreover , the objectiv e function has a unique minimizer for the optimization block s π , M , and O . In particular , the M block minimizer is unique since P N n =1 γ nc > 0 , for all c ∈ N C . Then, by [29, Th. 4.1 (c)], the RPC algorithm co n verges to a co ordinate-wise minimum point of (7). May 22, 2018 DRAFT 14 Proposition 3 guarantee s tha t the RPC iterations con ver ge. Howe ver , s ince e ach non-differentiable term k o n k Σ − 1 in volves two different optimization variables Σ and o n , the BCD iteration c an be trapped at a coo rdinate-wise local minimum, which is not neces sarily a local minimum of (8). Once the iterations have con verged, the final γ nc ’ s can be interpreted as soft clus ter assignme nts, whe reby hard assignments can be obtaine d via the maximum a posteriori detec tion rule, i.e., x n ∈ X c for c = arg max c ′ γ nc ′ . Remark 4 ( Selec ting λ ). T uning λ is possible if a dditional information, e.g., on the percentage o f outliers, is av ailable. The robust clustering algorithm is ran for a decreas ing sequen ce of λ values { λ g } , using “warm s tarts” [11], un til the exp ected number of outliers is identified. Whe n solving for λ g , warm start refers to the optimization variables initialized to the so lution obtained for λ g − 1 . He nce, running the algorithm over { λ g } bec omes very efficient, beca use few BCD iterations p er λ g suffice for con ver gence . C. W e ighted Robust Clus tering Algorithms As already mentioned, the robust c lustering methods presented so far ap proximate the discontinuou s penalty I( k o n k 2 > 0) by k o n k 2 , mimicking the CS paradigm in whic h I( | x | > 0) is surrogated by the con vex function | x | . Howev er , it has b een argued that n on-con vex functions s uch as log( | x | + ǫ ) for a small ǫ > 0 can offer tighter a pproximants o f I( | x | > 0) [30]. This rationale prompted us to replac e k o n k 2 in (5), (6), and (8), by the penalty log ( k o n k 2 + ǫ ) to further enhanc e b lock sparsity in o n ’ s, and thereby improve resilience to ou tliers. Altering the regularization term modifies the BCD algo rithms on ly when minimizing wrt O . This particular step remains decoup led across o n ’ s, but instea d of the φ ( t ) ( o n ) defined in (10), one minimizes φ ( t ) w ( o n ) := C X c =1 ( u ( t − 1) nc ) q k x n − m ( t ) c − o n k 2 2 + λ log ( k o n k 2 + ǫ ) (29) that is no longer con vex. Th e optimization in (29) is performed using a single iteration of the majorization- minimization (MM) app roach 1 [21]. The cost φ ( t ) w ( o n ) is majorized by a fun ction f ( t ) ( o n ; o ( t − 1) n ) , wh ich means that φ ( t ) w ( o n ) ≤ f ( t ) ( o n ; o ( t − 1) n ) for every o n and φ ( t ) w ( o n ) = f ( t ) ( o n ; o ( t − 1) n ) whe n o n = o ( t − 1) n . Then f ( t ) ( o n ; o ( t − 1) n ) is minimized wrt o n to obtain o ( t ) n . T o find a majorizer for φ ( t ) w ( o n ) , the con cavity of the logarithm is exp loited, i.e., the fact that log x ≤ log x o + x/x o − 1 for a ny pos iti ve x and x o . Applying the last inequality for the penalty and ignoring 1 Note that the MM approach f or minimizing φ ( t ) w ( o n ) at the t -th BCD i teration inv olves sev eral internal MM iterations. Due to the external BCD iterations and to speed up the algorithm, a single MM iteration is performed per BCD iteration t . May 22, 2018 DRAFT 15 the cons tant terms in volved, we e nd up minimizing f ( t ) ( o n ; o ( t − 1) n ) := C X c =1 ( u ( t − 1) nc ) q k x n − m ( t ) c − o n k 2 2 + λ ( t ) n k o n k 2 (30) where λ ( t ) n := λ/ ( k o ( t − 1) n k 2 + ǫ ) . Comparing (30) to (10) shows that the n ew regularization results in a weighted version of the original one. Th e only dif ference b etween the robust a lgorithms prese nted earlier and their henceforth termed we ighted cou nterparts is the de finition of λ . At iteration t , lar ger values for k o ( t − 1) n k 2 lead to smaller thresholds in the thresholding rules (cf. (11), (25)), thereby making o n more likely to be sele cted as nonzero. T he weighted robust clustering a lgorithms initialize o (0) n to the asso ciated o n value the non-weighted a lgorithm c on verged to. Thus, to run the weighted RKM for a s pecific value of λ , the RKM needs to be run fi rst. The n, weighted RKM is run with a ll the vari ables initialized to the values attained by RKM, b ut with the λ (1) n as define d e arlier . The MM step co mbined with the BCD a lgorithms developed hitherto are c on ver gent u nder mild assumptions . T o se e this, no te that the seque nces of objective values for the RKM and RPC algorithms are both non-increas ing. Sinc e the respec ti ve co st functions are bo unded below , thos e se quence s a re guaranteed to conv erge. Characterizing the po ints and speed of con vergence g oes beyond the scope of this pape r . I V . C L U S T E R I N G H I G H - D I M E N S I O N A L A N D N O N L I N E A R LY S E PA R A B L E D A T A The robust clustering algorithms o f Sec tion III are kernelize d here. The a dvantage of kernelization is twofold: (i) yields co mputationally ef ficient algorithms wh en dealing with h igh-dimensional data, and (ii) robustly identifies no nlinearly separab le clus ters. A. R obust K-mean s for High-Dimensional Data The robust clustering algorithms deriv ed s o far in volve generally O ( N C p ) operations p er iteration. Howe ver , s ev eral ap plications en tail c lustering rela ti vely fe w b ut high-dimensiona l data in the presence of ou tliers. In imaging applications, one may wish to cluster N = 500 images of say p = 800 × 600 = 480 , 000 pixels; while in DN A microarray data a nalysis, some tens of (potentially e rroneous o r rarely occurring) DNA samples are to be clus tered b ased on their expression levels over thousands of genes [14]. In su ch clustering scena rios w here p ≫ N , an e f ficient method s hould avoi d storing and proces sing p -dimensional vectors [27]. T o this end, the algo rithms o f Section III are ker nelized h ere [25 ]. It will be shown that the se kernelized algorithms require O ( N 3 C ) operations pe r iteration and O ( N 2 ) spa ce; hence, they are preferable whe n p > N 2 . This kernelization no t only of fers proce ssing s avings in the May 22, 2018 DRAFT 16 high-dimensiona l data regime, but also serves as the b uilding module for identifying nonlinearly sepa rable data clusters as purs ued in the next subse ction. W e focus on kernelizing the robust soft K-means algo rithm; the kernelized robust ha rd K-mea ns ca n then be deri ved after simple modifications. Conside r the N × C matrix U q with entries [ U q ] nc := u q nc , an d the Grammian K := X T X formed by all pairwise inner products betwee n the input vectors. Even thoug h the cost for computing K is O ( N 2 p ) , it is computed only once. Note that the updates (9) , (11), a nd (14) in volve inner produc ts between the p -dimensional vectors { o n , r n } N n =1 , and { m c } C c =1 . If { v i ∈ R p } 2 i =1 is a pair of any of the se vectors, the cost for co mputing v T 1 v 2 is clearly O ( p ) . But if at every BCD iteration the aforementioned vectors lie in range( X ) , i.e., if there exist { w i ∈ R N } 2 i =1 such that { v i = Xw i } 2 i =1 , then v T 1 v 2 = w T 1 Kw 2 , and the inner produ ct can be alternativ ely calcula ted in O ( N 2 ) . Hinging on this observation, it is first s hown that all the p × 1 vectors in volv ed inde ed lie in r ange( X ) . The proof is by induction: if a t the ( t − 1) -st iteration every o ( t − 1) n ∈ range( X ) and U ( t − 1) ∈ U 2 , it will be shown that o ( t ) n , m ( t ) c , r ( t ) n updated by RKM lie in r ange( X ) as we ll. Suppose that a t the t -th iteration, the matrix U ( t − 1) defining U ( t − 1) q is in U 2 , while there exists matrix A ( t − 1) such that O ( t − 1) = XA ( t − 1) . Then, the up date of the cen troids in (9) can be express ed as M ( t ) = ( X − O ( t − 1) ) U ( t − 1) q diag − 1 (( U ( t − 1) q ) T 1 N ) = XB ( t ) (31) where B ( t ) := ( I N − A ( t − 1) ) U ( t − 1) q diag − 1 (( U ( t − 1) q ) T 1 N ) . (32) Before upda ting O ( t ) , the residual vectors { r n } must be upda ted via (12). Concatena ting the residuals in R ( t ) := [ r ( t ) 1 . . . r ( t ) N ] , the up date in (12) can be rewritt en in matrix form a s R ( t ) = X − M ( t ) ( U ( t − 1) q ) T diag − 1 ( U ( t − 1) q 1 C ) = X∆ ( t ) (33) where ∆ ( t ) := I N − B ( t ) ( U ( t − 1) q ) T diag − 1 ( U ( t − 1) q 1 C ) . (34) From (11), e very o ( t ) n is a scaled version of r ( t ) n and the sc aling depen ds on k r ( t ) n k 2 . Ba sed on (33), the latter c an be readily comp uted as k r ( t ) n k 2 = q ( δ ( t ) n ) T K δ ( t ) n = k δ ( t ) n k K , whe re δ ( t ) n stands for the n -th column of ∆ ( t ) . Upon applying the thresho lding operator , o ne arri ves at the u pdate O ( t ) = XA ( t ) (35) where the n -th c olumn of A ( t ) is giv en by α ( t ) n = δ ( t ) n " 1 − λ 2 k δ ( t ) n k K # + , ∀ n. (36) May 22, 2018 DRAFT 17 Having proved the inductiv e step by (35), the a r gumen t is complete if an d only if the outlier variables O are initialized as O (0) = XA (0) for some A (0) , including the p ractically interes ting and meaningful initialization at ze ro. The result just proved ca n be summarized as follows. Proposition 4 . By choosing O (0) = XA (0) for any A (0) ∈ R N × N and U (0) ∈ U 2 , the columns of the matrix variables O , M , and R u pdated by RKM a ll lie in range( X ) ; i.e., there exist kn own A ( t ) , B ( t ) , and ∆ ( t ) , such that O ( t ) = XA ( t ) , M ( t ) = XB ( t ) , and R ( t ) = X∆ ( t ) for all t . What remains to be kernelized are the upda tes for the cluster as signments. For the u pdate step (14 ) or (15), we nee d to comp ute k x n − m ( t ) c − o ( t ) n k 2 2 and k o ( t ) n k 2 . Gi ven that x n = Xe n , where e n denotes the n -th co lumn of I N , and ba sed on the kernelized updates (31) and (35), it is easy to verify that k x n − m ( t ) c − o ( t ) n k 2 2 = k X ( e n − β ( t ) c − α ( t ) n ) k 2 2 = k e n − β ( t ) c − α ( t ) n k 2 K (37) for ev ery n and c , wh ere β ( t ) c is the c -th co lumn of B ( t ) . As in (35), it follo ws that k o ( t ) n k 2 = k X α ( t ) n k 2 = k α ( t ) n k K . (38) The kernelized robust K-means (KRKM) algorithm is summarized as Algorithm 3. As for RKM, the KRKM algorithm is terminated when k M ( t ) − M ( t − 1) k F / k M ( t ) k F ≤ ǫ s for a sma ll ǫ s > 0 . Based on (31 ) and exploiting sta ndard linear algebra properties, the stopp ing cond ition can be e quiv alently expressed as ( P C c =1 k β ( t ) c − β ( t − 1) c k 2 K ) / ( P C c =1 k β ( t ) c k 2 K ) ≤ ǫ 2 s . Notice that this kerne lized algorithm doe s not explicitly update M , R , or O ; actually , the se vari ables are never proces sed. Ins tead, it updates A , B , and ∆ ; while the c lustering assignme nts a re updated via (14), (37), an d (38). Ignoring the cos t for finding K , the co mputations requ ired by this algorithm are O ( N 3 C ) per iteration, whe reas the stored vari ables A , B , ∆ , U q , and K oc cupy O ( N 2 ) space . Note that if the c entroids M are explicitly neede d (e.g ., for interpretati ve purpo ses or for clustering new inp ut data ), they can be acq uired v ia (31) after KRKM ha s terminated. B. Kernelized RKM for Nonlinear ly Se parable Clusters One of the limitations of con ventional K-means i s that clusters should be o f spherical or , more generally , ellipsoidal sh ape. By postulating the s quared Eu clidean distance as the similarit y metric between vectors, the unde rlying clusters are tacitly a ssumed to be linearly sepa rable. GMM-based clustering s hares the same limitation. Kernel K-means h as been proposed to overcome this obstac le [26] b y mapping vectors x n to a high er dimensiona l s pace H throu gh the no nlinear function ϕ : R p → H . The ma pped data May 22, 2018 DRAFT 18 Algorithm 3 Kernelized RKM Require: Grammian matrix K ≻ 0 , number of clus ters C , q ≥ 1 , an d λ > 0 . 1: Initialize U (0) randomly in U 2 , and A (0) to zero. 2: f or t = 1 , 2 , . . . do 3: Update B ( t ) from (32). 4: Update ∆ ( t ) from (34). 5: Update A ( t ) from (36). 6: Update U ( t ) and U ( t ) q from (14) or (15), (37), a nd (38). 7: end f or { ϕ ( x n ) } N n =1 lie in the so-termed feature sp ace which is of d imension P > p or even infinite. The con ventional K-means algorithm is subseq uently applied in its kernelized version o n the trans formed data. Thus , linearly se parable partitions in feature s pace yield nonlinearly se parable partitions in the original spac e. For an algorithm to be kernelizab le, that is to be ab le to operate with inputs in feature spa ce, the inner product be tween any two mapped vectors, i.e., ϕ T ( x n ) ϕ ( x m ) , should be known. For the n on-kernelized versions of K-means , RKM, a nd RPC algorithms, where the linear mapping ϕ ( x n ) = x n can be tri v ially assume d, these inner products are directly comp utable and s tored at the ( n, m ) -th entry of the Grammian matrix K = X T X . When a nonlinea r ma pping is u sed, the so-termed kernel matrix K with e ntries [ K ] n,m := ϕ T ( x n ) ϕ ( x m ) replac es the Grammian matrix and must b e known. By definition, K mu st be positiv e semidefin ite and can b e employed for (robust) clustering, even when ϕ ( x n ) is high-dimensional (cf. Section IV -A), infinite-dimensiona l, or even un known [10]. Of p articular interes t is the c ase whe re H is a reprod ucing kernel H ilbert space. Then, the inn er produc t in H is provided by a known kernel function κ ( x n , x m ) := ϕ T ( x n ) ϕ ( x m ) [25, Ch. 3]. T ypical kernels for vectorial input data are the p olynomial, Gaussian , an d the sigmoid ones; howev er , kernels can be defined for non-vectorial objects as we ll, such as strings or g raphs [25]. After having RKM tailored to the high-dimensiona l input data regime in Se ction IV -A, handling arbitrary kernel functions is now straightforward. Kn owing the input data X and the kerne l func tion κ ( x n , x m ) , the kernel matrix can b e read ily compu ted as [ K ] n,m = κ ( x n , x m ) for n, m ∈ N N . By using the kernel in lieu of the Grammian matrix, Algorithm 3 c arries over readily to the nonlinear clustering regime. May 22, 2018 DRAFT 19 As sh own e arlier , when c lustering high-dimensiona l da ta, the centroids ca n be co mputed after the robust clus tering algo rithm ha s terminated via (31). This is not ge nerally the c ase withrob ust nonlinear clustering. For infin ite-dimensional or even finite dimension al feature space s, such as the one induc ed by a polynomial kernel, ev en if on e is able to recover the c entroid m c ∈ H , its pre-image in the input space may not exist [25, Ch. 1 8]. C. Kernelized Robust Probabilistic Clustering Similar to RKM, the RPC a lgorithm can be kernelized to (i) facilitate computationally ef ficient clustering of high-dimen sional input data, and (ii) enable nonlinearly se parable clustering. T o simplify the prese ntation, the foc us here is on the case of spherical clusters. Kernelizing RPC hinders a major dif ference over the kernelization of RKM: the GMM a nd the RPC updates in Sec tion III-B remain valid for { ϕ ( x n ) ∈ H} only when the fea ture sp ace dimen sion P rema ins finite and known. The implication is elucidated as follows. First, updating the variance in (27) e ntails the underlying vector dimension p – wh ich becomes P w hen it come s to kernelization. Second, the (outlier- aware) mixtures of Gauss ians degenerate when it comes to modeling infinite-dimensional rand om vectors. T o overcome this limitation, the notion o f the emp irical kernel ma p will be exploited [25, Ch . 2.2.6]. Gi ven the fixed set of vectors in X , instead o f ϕ , it is po ssible to conside r the empirical kerne l map ˆ ϕ : R p → R N defined as ˆ ϕ ( x ) := ( K 1 / 2 ) † [ κ ( x 1 , x ) · · · κ ( x N , x )] T , where K is the kernel matrix of the input data X , an d ( · ) † the Moore-Penrose pseu doin verse. Th e fea ture space ˆ H induc ed by ˆ ϕ h as finite dimensiona lity N . It can b e also verified that ˆ ϕ T ( x n ) ˆ ϕ ( x m ) = ϕ T ( x n ) ϕ ( x m ) = κ ( x n , x m ) for all x n , x m ∈ X ; hence, inner products in ˆ H are rea dily computable through κ . In the kernelized proba bilistic setup , vectors { ˆ ϕ ( x n ) } N n =1 are assu med drawn from a mixture of C multi variate Gau ssian d istrib utions with common cov ariance Σ = σ 2 I N for all clusters. Th e EM-based updates of RPC in Section III-B remain valid after replac ing the dimens ion p in (27) by N , a nd the input vectors { x n } by { ˆ ϕ ( x n ) } with the c ritical prope rty tha t on e only ne eds to k now the inner produc ts ˆ ϕ T ( x n ) ˆ ϕ ( x m ) stored a s the ( n, m ) -th e ntries of the kernel matrix K . The kernelization proced ure is similar to the o ne follo wed for RKM: first, the au xiliary matrices A ( t ) , B ( t ) , and ∆ ( t ) are introduced . By ran domly initializing σ (0) , π (0) ∈ P , B (0) ∈ R N × C , an d s etting A (0) to zero, it can be shown as in Propo sition 4, that the kerne lized RPC u pdates for O ( t ) , M ( t ) , a nd R ( t ) have their columns lying in range( Φ ) , where Φ := [ ˆ ϕ ( x 1 ) · · · ˆ ϕ ( x N )] . Instead of the a ssignment matrix U in KR KM, the N × C matrix of posterior proba bility estimates Γ ( t ) is us ed, where [ Γ ( t ) ] n,c := γ ( t ) nc satisfying Γ ( t ) 1 C = 1 N ∀ t . May 22, 2018 DRAFT 20 Algorithm 4 Kernelized RPC Require: Grammian or kernel matrix K ≻ 0 , numbe r of clusters C , an d λ > 0 . 1: Randomly initialize σ (0) , π (0) ∈ P , an d B (0) ; and set A (0) to zero. 2: f or t = 1 , 2 , . . . do 3: Update Γ ( t ) via (20) exp loiting k x n − m ( t − 1) c − o ( t − 1) n k 2 2 = k e n − β ( t − 1) c − α ( t − 1) n k 2 K for all n , c . 4: Update π ( t ) as π ( t ) = ( Γ ( t ) ) T 1 N / N . 5: Update B ( t ) as B ( t ) = ( I N − A ( t − 1) ) Γ ( t ) diag − 1 ( N π ( t ) ) . 6: Update ∆ ( t ) as ∆ ( t ) = I N − B ( t ) ( Γ ( t ) ) T . 7: Update the columns of A ( t ) as α ( t ) n = δ ( t ) n h 1 − λσ ( t − 1) k δ ( t ) n k K i + for all n . 8: Update σ ( t ) via (27) where p is replaced by N , using the ℓ 2 -norms comp uted in Step 3, and exploiting k o ( t ) n k 2 = k α ( t ) n k K for all n . 9: end f or The kernelized RPC (KRPC) a lgorithm is su mmarized as Alg. 4. As with KRKM, its compu tations are O ( N 3 C ) per iteration, whereas the s tored variables A , B , ∆ , Γ , π , K , and σ occ upy O ( N 2 ) s pace. Remark 5 ( Reweighted kernelized algor ithms). Reweighted kernelized algorithms similar to the ones in Section III-C can be de ri ved for KRKM an d KRPC by a simple modification. In both cases, it suffices to introduce a n iteration-dependen t parameter λ ( t ) n = λ/ ( k o ( t − 1) n k 2 + ǫ ) per index n . Note that k o n k 2 ’ s can be readily comp uted in terms of kernels as shown e arlier . V . N U M E R I C A L T E S T S Numerical tests illustrating the p erformance of the n ovel robust c lustering algorithms on both sy nthetic and real datasets are sho wn in t his s ection. Performance is asse ssed through their ability to i dentify outliers and the quality of clustering itself. The latter is measured us ing the adjus ted rand index (ARI) between the partitioning found a nd the true partitioning of the data whe never the latter is av ailable [17]. In eac h experiment, the parameter λ is tuned using the grid s earch outlined in Remark 4 over a t most 1 , 000 values. Thanks to the warm-start technique, the solution pa th for all g rid po ints was computed in an amount of time comp arable to the one us ed for solving for a spe cific v alue of λ . A. S ynthetic Datasets T wo syn thetic datase ts are use d. The first o ne, s hown in Fig. 1(a), consists of a random draw of 2 00 vectors from C = 4 bi variate Gaussian distributi ons (50 vec tors per distributi on), and 8 0 outlying vectors May 22, 2018 DRAFT 21 −15 −10 −5 0 5 10 15 −15 −10 −5 0 5 10 15 x 1 x 2 (a) Dataset with C = 4 spherical cl usters. −20 −15 −10 −5 0 5 10 15 20 −20 −15 −10 −5 0 5 10 15 20 x 1 x 2 (b) Dataset with C = 2 concentric rings. Fig. 1. Synthetic datasets: In-(out-)lier vectors are denoted by circles • (stars ⋆ ). ( N = 280) . T he Gaus sian distributions have d if ferent me ans and a co mmon covariance matrix 0 . 8 I 2 . The se cond data set comprise s points belonging to C = 2 concentric rings as depicted in Fig. 1(b). The inner (outer) ring has 50 (150) points. It a lso contains 60 vectors lying in the areas betwee n the rings an d outside the outer ring correspon ding to outliers ( N = 260) . Clustering this second dataset is ch allenging ev en if outliers were no t present due to the shape and multiscale nature of the clusters. Starting from the data set with the four spherical c lusters, the effect of λ on the n umber of outliers identified is in vestigated. In F ig. 2, the values o f {k o n k 2 } N n =1 are plotted as a func tion of λ . The outlier- norm curves shown in Fig. 2(a) correspo nd to the RKM algorit hm with q = 1 us ing a ran dom initialization. For λ > 17 , all o n ’ s are set to z ero, while as λ approache s zero, more o n ’ s take nonzero v alues . Selecting λ ∈ [6 . 2 , 7 . 6] yields 8 0 outliers. Fig. 2(b) shows {k o n k 2 } N n =1 as λ varies for the RPC a lgorithm assuming Σ = σ 2 I p . The curves for some o n ’ s exhibit a fast transition from zero. In Fig. 3, the number o f outliers identified, i.e., the nu mber of input vectors x n with c orrespond ing k o n k 2 > 0 , is plotted as a function of λ . Proper choice of λ enables both RKM and RPC t o identify exactly the 80 points, which w ere generated as ou tliers in the “ ground truth” model. For the RKM algorithm with q = 1 , there is a platea u for values of λ ∈ [6 . 2 , 7 . 6] . This p lateau de fines a transition region b etween the values of λ that iden tify true outliers and values of λ which erroneously d eem non-outliers as outliers. Although the plateau is not presen t for q > 1 , the c urves show an increas e in their slop e for λ < 5 indicating that non-outliers are erroneo usly labeled a s outliers. RPC with λ = 0 . 91 correctly identifies the 80 o utlying vectors. Notice that the rang e of λ values for which o utliers are c orrectly identified is smaller than the o ne for RKM due to the s caling of λ by σ . May 22, 2018 DRAFT 22 (a) RKM algorithm for q = 1 . (b) RPC algorithm. Fig. 2. Curves of k o n k 2 ’ s as a function of λ for the dataset in Fig. 1(a). 2 4 6 8 10 12 14 16 18 0 50 100 150 200 250 300 80 280 λ Num be r of outliers RPC q = 2 q = 1 . 5 q = 1 Fig. 3. Number of outliers identified as a function of λ for the dataset in Fig. 1(a). T able I s hows the root-mean -squared error (RMSE) o f clus ter center e stimates averaged over 10 0 algorithm initiali zations . T wo lev els o f outlier contamination are con sidered: 40 out of N = 240 points (approximately 17 %), and 80 ou t of N = 280 (approx imately 29%). Apart from the novel algorithms, hard K-means, soft K-means with q = 1 . 5 , an d EM are also included. The robust versions of the ha rd K-means, soft K-mean s, and EM algorithms a chieve lo wer RMSE with extra improv ement effected by the weighted RKM (WRKM) an d the weighted RPC (WRPC) algorithms. Next, we cons ider clustering the second non linearly sep arable d ataset using the Gaussian kernel κ ( x n , x m ) = exp( − α κ k x n − x m k 2 2 ) , whe re α κ > 0 is a s caling pa rameter . The p arameter α − 1 κ is chosen as a robust variance es timate of the entire dataset as des cribed in [6]. Both KRKM and KRPC May 22, 2018 DRAFT 23 T ABLE I R M S E O F C L U S T E R C E N T E R E S T I M A T E S . RMSE Outliers/ N 40 /2 40 80 /280 hard K-means 0.7227 1.0892 soft K-means 0.5530 1.0206 EM 0.6143 1.0032 hard RKM 0.4986 0.8813 hard WRKM 0.4985 0.8812 soft RKM 0.2587 0.6259 soft WRKM 0.0937 0.1758 RPC 0.2789 0.3891 WRPC 0.1525 0.1750 1.5 1.6 1.7 1.8 1.9 2 2.1 0 50 100 150 200 250 60 λ Num b er of outliers q = 1 . 1 , α κ = 0 . 2 q = 1 . 8 , α κ = 0 . 2 q = 1 . 1 , α κ = 0 . 05 q = 1 . 8 , α κ = 0 . 05 (a) KRKM algorithm. 15 15.5 16 16.5 17 17.5 18 18.5 19 0 50 100 150 200 250 60 λ Num b er of outliers α κ = 0 . 2 α κ = 0 . 05 (b) KRPC algorithm. Fig. 4. Number of outliers identified as a function of λ for the dataset in Fig. 1(b). are a ble to identify the 60 outlying p oints. In Fig. 4, the number of ou tliers ide ntified by KRKM and KRPC is plotted a s a function of λ for diff erent values of α κ . Fig. 5 illustrates the values o f k o n k 2 ’ s for WKRKM and WKRPC when s eeking 60 o utliers. Points su rrounded by a circle corresp ond to vectors identified as outliers, a nd each circle’ s radius is proportional to its correspon ding k o n k 2 value. May 22, 2018 DRAFT 24 −20 −15 −10 −5 0 5 10 15 20 −20 −15 −10 −5 0 5 10 15 20 x 1 x 2 15 . 59 · 10 − 3 8 · 10 − 5 (a) KRKM algorithm ( q = 1 . 1) . −20 −15 −10 −5 0 5 10 15 20 −20 −15 −10 −5 0 5 10 15 20 x 1 x 2 17 . 9 · 10 − 3 2 . 1 · 10 − 3 (b) KRPC algorithm. Fig. 5. Clustering results for the dataset in Fig. 1(b) using a Gaussian ke rnel with α κ = 0 . 2 . Points surrounde d by a circle were deemed as outliers; the radius of the circle is proportional to the value of k o n k 2 . Smallest and largest k o n k 2 v alues are sho wn. B. US PS Dataset In this sub section, the robust c lustering algorithms are tested on the U nited S tates Postal Service (USPS) handwritten digit recogn ition corpus. This corpus contains gray -scale digit images of 16 × 16 pixels with intensities normalized to [ − 1 , 1] . It is d i vided to 7,201 training and 2,007 test examples of the digits 0-9. Although the corpus contains c lass labe ls, they are kn own to be inc onsistent: so me digits are erroneous ly labeled, while s ome images are d if ficult to be class ified ev en by hu mans [25, App. A]. In this experiment, the sub set of digits 0-5 is u sed. For ea ch digit, both training and test s ets are combined to a single set and then 300 images a re sa mpled uniformly at ran dom, y ielding a da taset of 1800 image s. Each image is rep resented as a 256-dimen sional vec tor n ormalized to have unit ℓ 2 -norm. Hard RKM ( q = 1) a nd RPC algorithms a re used to pa rtition the datase t into C = 6 clusters a nd identify s = 100 ou tliers. All algorithms we re tested for 2 0 Mon te Carlo runs with random initializations common to all algo rithms. The final partitioning is chos en as the one attaining the smallest cost in (5). The qu ality of the clustering is asse ssed through the ARI after excluding the ou tlier vectors. The ARI values for K-means, K-medians, a nd the propos ed scheme s are shown in T able II. Note that the ARI values for RKM (RPC) and WRKM (WRPC) are equ al. This indicates that the weighted algorithms d o not modify the point-to-cluster ass ignments alread y found. Interestingly , the K-medians a lgorithm was not able to find a partitioning o f the da ta revealing the 6 digits prese nt, even after 10 0 Monte Carlo runs. The USPS datase t was clustered u sing the RKM and WRKM tune d to identify 100 o utliers. WRKM is initialized with the results obtained b y RKM. Although RKM and WRKM yielde d the sa me outlier May 22, 2018 DRAFT 25 T ABLE II A R I C O E FFI C I E N T S F O R T H E U S P S D AT A S E T ( C = 6) Ke rnel K-means K-medians RKM RPC Linear 0.6469 0.5382 0.657 3 0.6508 Polynomial 0.5571 - 0.6978 0.6 965 images, the size of the o n ’ s was dif ferent, be coming nearly u niform for WRKM. The USPS datase t was also clustered using the RPC an d the WRPC algorithms. Fig. 6(a) s hows the clus ter ce ntroids obtaine d by RPC and WRPC. Fig. 6(b) s hows the 100 o utliers identified. The outliers identified by the RPC and WRPC algorithms also c oincide. The pos ition of the outlier images in the mo saic correspon ds to their ranking acc ording to the size of their correspo nding o n (lar gest to smalles t from left to right, top to bottom). Note that all outliers identified h av e a trait that diff erentiates them from the average image in each cluster . Amo ng the 100 outliers de tected by RKM and RPC, 9 7 are common to both ap proaches . A kernelized version of the algorithms was also used on the USPS datase t. Similar to [25], the homogen eous p olynomial kernel of order 3, tha t is κ ( x n , x m ) = ( x T n x m ) 3 , was use d. The ARI sc ores obtained by the kernelized robust clustering algo rithms are shown in T able II. Ba sed on these sco res, two important obse rvations are in order: (i) kernelized K-means is more se nsiti ve to outliers than K-means is; but (ii) KRKM for the particular kernel yields an improved c lustering p erformance over RKM. Fina lly , the 100 ou tliers iden tified by KRKM a re shown in Fig. 6 (c). C. Do lphin’ s Social Network Next, KRKM is use d to partition an d identify outliers in a soc ial n etwork of N = 62 bottlenos e dolphins living in Doubtful S ound, New Ze aland [23]. Links between p airs of nodes (dolphins) repres ent statistically significant frequency assoc iation. The network structure is s ummarized by the N × N adjacen cy ma trix E . T o identify social groups and outliers, the conne ction between kernel K-mean s and spectral clustering for graph partitioning is exploited [27]. Acc ording to this c onnec tion, the con ventional spectral clus tering algorithm is sub stituted by the kernelized K-mean s algorithm with a spec ific kernel matrix. The kernel ma trix used is K = ν I N + D − 1 / 2 ED − 1 / 2 , where D := diag ( E1 N ) and ν is chosen lar ger tha n the minimum eigenv a lue o f D − 1 / 2 ED − 1 / 2 such that K ≻ 0 . Kernel K-mea ns for graph partitioning is prone to being trapped at poor loc al minima, dep ending on initialization [10]. The KRKM a lgorithm with C = 4 clusters is initialized by the spec tral c lustering solution using the symmetric La placian matrix L := I N − D − 1 / 2 ED − 1 / 2 . Th e parame ter λ is tuned to May 22, 2018 DRAFT 26 (a) RPC and W RPC centroids. (b) Outliers identified by RP C and WRPC. (c) Outliers identified by KRKM using the poly- nomial kernel of order 3. Fig. 6. Clustering and outliers for the USP S dataset with C = 6 tuned to identify s = 100 outliers. identify s = 12 outliers. F ig. 7 depicts the network partitioning a nd the o utliers identified. Th e results show that s everal nodes identified a s o utliers have unit degree. Having a single link indicates that nodes are marginally c onnected to their co rresponding clusters thus dee med as outliers. Other outlier instanc es adh ere to more c omplicated s tructures within the network. Node z ig has a single link, yet it is not identified as an o utlier poss ibly due to the reduc ed size of its cluster , esp ecially since four other nodes in the same cluster are identified as outliers. Interestingly , nodes sn89 , sn100 , tr99 and kringel , with node d egrees 2, 7, 7, and 9, respectively , are also identified as outliers. Using gender information about the dolphins [23 ], we obse rve that sn 89 is a female dolphin as signed to a c luster dominated by males (10 males, 3 females, and 2 unob served). Likewi se, the conne ctivi ty o f sn100 and tr99 in the graph shows tha t they sha re many edge s with female dolphins in other clusters whic h diff erentiates them from other female do lphins within the same c luster . Finally , kr ingel is a dolphin conne cted to 6 do lphins in other clusters an d on ly 3 dolphins in its o wn cluster . D. Co lle ge F ootball Network KRKM is use d to p artition a nd identify outliers in a network of N = 115 co llege footba ll teams . The college football network represents the sche dule of Division I games for the s eason in year 2,0 00 [13]. Each node correspond s to a team and a link between two teams exists if they played against each o ther during the s eason . The teams a re di vided into C = 12 co nferences and each team plays g ames with teams May 22, 2018 DRAFT 27 Fig. 7. KRKM clustering of the dolphin’ s social network: outliers are depicted bold-faced ; male, f emale, and unobserv ed gender are represented by squares, circles, and triangles, respectiv ely . T eams T eams 20 40 60 80 100 10 20 30 40 50 60 70 80 90 100 110 Fig. 8. The kernel matrix f or the colleg e f ootball network permuted using KRKM clustering. Zero entries are colored blue and outliers are colored red. in the sa me con ference more often. KRKM is initialized via sp ectral clustering as described in Section V -C, while λ is tuned to identify s = 12 outliers. Fig. 8 shows the entries of the kernel matrix K after being row and column pe rmuted so that teams in the same cluster obtaine d by KRKM are cons ecutive. The ARI coefficient yielde d by KRKM after removing the outliers was 0.9 218. T eams identified as ou tliers sorted in de scend ing order ba sed on their k o n k 2 values are: Co nnecticut, May 22, 2018 DRAFT 28 Fig. 9. C lustering of the college football network obtained by KRKM for C = 12 . Outliers are represented by diamond-shap ed nodes. Navy , Notre Da me, Northern Illinois, T oledo, Miami (Ohio), Bowling Green State, Central Michigan , Eastern Michigan, Kent, Ohio, and Ma rshall. Th ree of them, namely Con necticut, Notre Dame, and Navy , are inde pende nt teams. Co nnecticut is assign ed to the Mid-American co nference, but it doe s not play as many games with teams from this conferen ce (4 games ) as other teams in the same conferenc e do (around 8 game s). Notre Dame an d Navy p lay an equa l n umber of ga mes with teams from two different conference s so they could be as signed to e ither one. Several teams from the Mid-American conference are categorized as o utliers. In hindsight, this can be explained by the subdivision of the co nference into East and W est Mid-American con ferences. T e ams in eac h of the Mid-American sub-co nferences played about the sa me number of game s with teams from their own s ub-conferenc e and the rest of the teams. Interestingly , using KRKM with C = 13 while still se eking for 12 outliers, the sub-partition of the Mid-American conference is identified. In this case, the ARI coefficient for the partition after removing outliers is 0.91 10. The three ind epende nt teams, Conn ecticut, Notre Dame, and Navy , are again amon g the 12 outliers ide ntified. May 22, 2018 DRAFT 29 V I . C O N C L U S I O N S Robust algorithms for clustering ba sed on a principled da ta model accoun ting for outliers were dev el- oped. Both deterministic an d proba bilistic partitional c lustering s etups bas ed on the K-means algorithm and GMM’ s, respectiv ely , were conside red. Exploiting the f act that outliers appear infrequently in the data, a neat c onnection with sparsity-aware signal processing algorithms was made. This led to the development of c omputationally efficient and prov ably conv ergent robust clus tering algorithms. Kernelized versions of the algorithms, well-suited for high-dimens ional da ta or when only similarity information among objects is avail able, were also developed. Th e performance of the robust clustering algorithms was validated via numerical experiments both on synthe tic and rea l datase ts. R E F E R E N C E S [1] J. C. Bezdek, P attern Recognition with Fuzzy Objective Function Algorithms . Norwell, MA: Kluwer , 1981. [2] C. M. Bishop, P attern Recognition and Machine L earning . Ne w Y ork, NY : S pringer , 2006. [3] L. B obro wski and J. C. Bezdek, “C- means clustering wi th the l l and l ∞ norms, ” IEEE Tr ans. Syst., Man, Cybern. , vol. 21, no. 3, pp. 545–554 , May 1991. [4] H.-H. Bock, “Clustering methods: A history of K-means algorithms, ” in Selected C ontribu tions in Data Analysis and Classification , ser . Studies in C lassification, Data Analysis, and Knowledge Organization, P . Brit o, G. C ucumel, P . Bertr and, and F . Carvalho , Eds. Springer Berlin Heidelberg, 2007, pp. 161–172. [5] E. J. Candes and T . T ao, “Near-o ptimal signal reco very from random projections: Uni versal encoding strategies?” IEEE T rans. Inf. Theory , vo l. 52, no. 12, pp. 5406 –5425, Dec. 2006. [6] Y . Chen, X. Dang, H. P eng, and H. L. Bart, “Outlier detection with t he kerne lized spatial depth function, ” IEEE Tr ans. P attern Anal. Mac h. I ntell. , vol. 31, no. 2, pp. 288–30 5, Feb. 2009. [7] S. Dasgupta and Y . Freund, “Random projection tr ees for vector quantization, ” IEE E T rans. Inf. Theory , vol. 55, no. 7, pp. 3229–324 2, Jul. 2009. [8] R. N. Dav ´ e and R . Krishnapuram, “Rob ust clustering methods: a unified vie w , ” IEEE T rans. Fuzzy Syst. , vol. 5, no. 2, pp. 270–29 3, 1997. [9] A. P . Dempster , N. M. Laird, and D. B. Rubin, “Maximum likelihood from incomplete data via the EM algorithm, ” Journal of the Royal Statistical Society . Series B (Methodolog ical) , vol. 39, pp. 1–38, Aug. 1977. [10] I. S. Dhillon, Y . Guan, and B. Kulis, “W eighted graph cuts without eigen vectors: A multilev el approach, ” IE EE T rans. P attern Anal. Mac h. I ntell. , vol. 29, no. 11, pp. 1944–195 7, Nov . 2007. [11] J. F riedman, T . Hastie, H. Hofling, and R. T ibshirani, “Pathwise coordinate optimization, ” Annals of Applied Statistics , vol. 1, no. 2, p. 302, 2007. [12] H. F rigui and R. Krishnapuram, “ A robust competitiv e clustering algorithm with applications in computer vision, ” IE EE T rans. P attern Anal. Mach. Intell. , vol. 21, no. 5, pp. 450–4 65, May 1999. [13] M. Girvan and M. E. J. Newman, “Community structure in social and biological network s, ” Proc. of the National Academy of Sciences of the United States of America , vol. 99, no. 12, pp. 7821–7826, Jun. 2002. May 22, 2018 DRAFT 30 [14] T . Hastie, R. Tibshirani, and J. F riedman, The Elements of Statistical Learning: Data Mining, Infer ence, and Pr ediction , 2nd ed. Springer , 2009. [15] K. Honda, A . Notsu, and H. Ichihashi, “Fuzzy PCA-guided robust k-means clustering, ” IEEE Tr ans. Fuzzy Syst. , vol. 18, no. 1, pp. 67–79, Feb . 2010. [16] P . J. Huber and E. M. Ronchetti, Robust Statistics , 2nd ed. Ne w Y ork: Wile y , 2009. [17] L. Hubert and P . Arabie, “Comparing partitions, ” Journ al of Classification , vol. 2, no. 1, pp. 193–2 18, Dec. 1985. [18] J. M. Jolion, P . Meer , and S. Bataouche, “Robust clustering with applications in computer vision, ” IE EE T rans. P attern Anal. Mach. Intell. , vo l. 13, no. 8, pp. 791–80 2, Aug. 1991. [19] P . Kersten, “Fuzzy order statistics and their application to fuzzy clustering, ” IEEE T rans. F uzzy Syst. , vol. 7, no. 6, pp. 708–71 2, Dec. 1999. [20] R. Krishnapuram and J. M. Keller , “ A possibilistic approach to clustering, ” I EEE T rans. Fuzzy Syst. , vol. 1, no. 2, pp. 98–110 , May 1993. [21] K. Lange, D. Hunter , and I. Y ang, “Optimization t ransfer using surrogate objecti ve functions (with discussion), ” J . of Comp. and Graphical Stat. , vol. 9, pp. 1–59, 2000. [22] S. Lloyd, “Least squares quantization in PCM, ” IEEE T rans. I nf. Theory , vol. 28, no. 2, pp. 129–137, Mar . 1982. [23] D. Lusseau and M. E. J. Newman, “Identifying the role that animals play in their social networks, ” Pr oceedings: B iological Sciences , vol. 271, pp. S477–S481, 2004. [24] N. R. Pal, K. Pal, J. M. Keller , and J. C. Bezdek, “ A possibilistic fuzzy c-means clustering algorithm, ” IEEE T rans. Fuzzy Syst. , vol. 13, no. 4, pp. 517–530, Aug. 2005. [25] B. S ch ¨ olko pf and A. Smola, Learning with Kernels. Support V ector Machines, R e gularization, Optimization, and Beyond . MIT Press, 2002. [26] B. Sch ¨ olkopf, A. Smola, and K. R . M ¨ uller , “Nonlinear componen t analysis as a kernel eigen value problem, ” Neural Computation , vol. 10, no. 5, pp. 1299–13 19, Jul. 1998. [27] I. S. Dhillon, Y . Guan, and B. Kulis, “Kernel k-means: spectral clustering and normalized cuts, ” in Proc. of ACM Intl. Conf. on Knowledge Discovery and Data Mining , Seattle, W A, 2004, pp. 551–55 6. [28] S. Z . Selim and M. A. Ismail, “K-means-type algorithms: A generalized con vergenc e t heorem and characterization of local optimality , ” IEEE T rans. P attern Anal. Mach . Intell. , vo l. 6, no. 1, pp. 81–86, Jan. 1984. [29] P . Tseng, “Con vergence of block coordinate descent method for nondif ferentiable minimization, ” Jo urnal on Optimization Theory and Applications , vol. 109, no. 3, pp. 475–494, Jun. 2001. [30] J. W eston, A. Elisseff, B. Sch ¨ olkop f, and M. Tipp ing, “Use of the zero-norm with linear models and ke rnel methods, ” J ournal of Machine Learning Resear ch , vol. 3, pp. 1439– 1461, Mar . 2003. [31] R. Xu and D. W unsch II, “Survey of clustering algorithms, ” IEEE Tr ans. Neur al Netw . , vol. 16, no. 3, pp. 645– 678, May 2005. [32] M. S. Y ang, K. L. W u, J. N. Hsieh, and J. Y u, “ Alpha-cut implemented fuzzy clustering algorithms and switching regression s, ” IEEE T rans. Syst., Man, Cybern. B , vol. 38, pp. 588–60 3, 2008. [33] M. Y uan and Y . Lin, “Model selection and estimation in regressio n with grouped v ariables, ” J ournal of the Royal Stat. Society: Series B , vol. 68, no. 1, pp. 49–67, Feb. 2006. [34] X. Zhuang, Y . Huang, K. Palaniappan, and Y . Zhao, “Gaussian mixture density modeling, decomposition, and applications, ” T ransactions on Image Pr ocessing , vo l. 5, no. 9, pp. 1293 –1302, Sep. 1996. May 22, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment