희소성 정규화 기반 강인 클러스터링
본 논문은 데이터에 드물게 존재하는 이상치(아웃라이어)를 희소성으로 모델링하고, 이를 정규화 항으로 활용한 강인(K-평균 및 GMM) 클러스터링 알고리즘을 제안한다. 블록 좌표 하강법을 이용해 수렴을 보장하면서도 기존 비강인 알고리즘과 비슷한 계산 복잡도를 유지한다. 또한 커널 기법을 도입해 고차원 및 비선형 데이터에도 적용 가능하도록 확장하였다. 실험 결과, 제안 방법이 합성·실제 데이터 모두에서 기존 방법보다 이상치에 대한 견고성을 크게 향…
저자: Pedro A. Forero, Vassilis Kekatos, Georgios B. Giannakis
클러스터링은 데이터 포인트를 의미 있는 집합으로 나누는 기본적인 비지도 학습 기법이며, K‑means와 Gaussian Mixture Model(GMM) 기반 방법이 가장 널리 사용된다. 그러나 두 방법 모두 데이터와 클러스터 중심(또는 평균) 사이의 거리 혹은 로그우도에 직접 의존하기 때문에, 소수의 이상치가 존재할 경우 클러스터 중심이 크게 왜곡되고, 결과적으로 전체 군집 구조가 파괴되는 약점을 가지고 있다. 기존 연구에서는 이상치를 별도의 클러스터에 할당하거나, 가능도 기반의 튜키스트 함수, ℓ₁‑거리 등을 도입해 어느 정도 강인성을 확보했지만, 계산 복잡도가 크게 증가하거나 초기값에 민감한 문제를 안고 있었다.
본 논문은 이러한 문제를 근본적으로 해결하고자, 데이터 모델에 “아웃라이어 벡터 oₙ”을 명시적으로 추가한다. 각 관측 xₙ은
xₙ = Σ_{c=1}^{C} uₙc m_c + oₙ + vₙ
와 같이 표현되며, 여기서 uₙc는 클러스터 할당(하드 또는 소프트), m_c는 클러스터 중심, vₙ은 가우시안 잡음, oₙ은 이상치가 존재할 경우 비제로가 되는 벡터이다. 중요한 가정은 대부분의 oₙ이 영이라는 점으로, 이는 “희소성”이라는 구조적 특성을 만든다.
이 희소성을 정량화하기 위해 ℓ₀‑노름(비제로 원소 개수) 대신 ℓ₁‑노름을 사용한 정규화 항 λ∑ₙ‖oₙ‖₂를 도입한다. 이렇게 하면 목표 함수는
J(M,O,U) = Σₙ Σ_c uₙc‖xₙ - m_c - oₙ‖₂² + λ Σₙ‖oₙ‖₂
가 된다. λ는 이상치 개수를 조절하는 하이퍼파라미터이며, λ→∞이면 oₙ이 모두 0이 되어 기존 K‑means와 동일한 형태가 된다.
목표 함수는 (M,O) 에 대해 볼록하지만, 전체 변수 (M,O,U) 에 대해서는 비볼록성을 유지한다. 이를 해결하기 위해 블록 좌표 하강법(Block Coordinate Descent, BCD)을 적용한다. 구체적으로는 다음 세 단계가 순환한다.
1. **U‑업데이트**: 현재 M과 O가 고정된 상태에서 할당 행렬 U를 최적화한다. 하드 K‑means의 경우 0‑1 제약을 만족하도록 각 xₙ을 가장 가까운 클러스터에 할당하고, 소프트 K‑means와 GMM의 경우에는 확률적 할당(softmax 혹은 posterior γₙc)을 계산한다.
2. **M‑업데이트**: U가 고정된 상태에서 각 클러스터 중심 m_c를 업데이트한다. 이는 단순히 할당된 데이터와 해당 이상치 보정값 oₙ을 제외한 평균을 취하면 된다.
3. **O‑업데이트**: M과 U가 고정된 상태에서 각 oₙ를 업데이트한다. 이 단계는 그룹 라쏘(group‑Lasso) 형태가 되며, 폐쇄형 해인
oₙ = max(0, 1 - λ/(2‖rₙ‖₂)) rₙ, rₙ = xₙ - Σ_c uₙc m_c
와 같이 soft‑thresholding 연산으로 구현된다. 즉, residual rₙ의 크기가 λ/2보다 작으면 oₙ은 0이 되고, 그렇지 않으면 residual을 일정 비율로 감소시킨 값이 이상치 보정값이 된다.
GMM 확장에서는 위 과정을 EM 알고리즘과 결합한다. E‑스텝에서 현재 파라미터를 이용해 posterior γₙc를 계산하고, M‑스텝에서 m_c, Σ, oₙ를 위와 동일한 방식으로 업데이트한다. 여기서 Σ는 공통 공분산 행렬을 가정함으로써 로그우도 발산을 방지하고, 정규화 항 λ∑ₙ‖oₙ‖_{Σ^{-1}}를 추가해 이상치가 로그우도를 무한히 크게 만드는 것을 억제한다.
알고리즘의 계산 복잡도는 각 이터레이션당 O(N C p) 수준이며, 기존 K‑means 혹은 EM과 동일한 차수이다. 그룹 라쏘 단계는 벡터 차원 p에 대해 O(p) 연산만 필요하므로 전체적인 오버헤드가 미미하다.
커널화는 고차원 특징 공간 Φ(·) 로 데이터를 매핑하고, 모든 거리·내적 연산을 커널 함수 K(xᵢ,xⱼ)=⟨Φ(xᵢ),Φ(xⱼ)⟩ 로 대체함으로써 구현된다. 이때 oₙ 역시 Φ 공간에서 동일하게 취급되며, 그룹 라쏘 해는 커널 행렬 기반으로 수행된다. 따라서 비선형적으로 구분되는 클러스터, 이미지 패치, 그래프 구조 등 벡터 형태가 아닌 데이터에도 적용 가능하다.
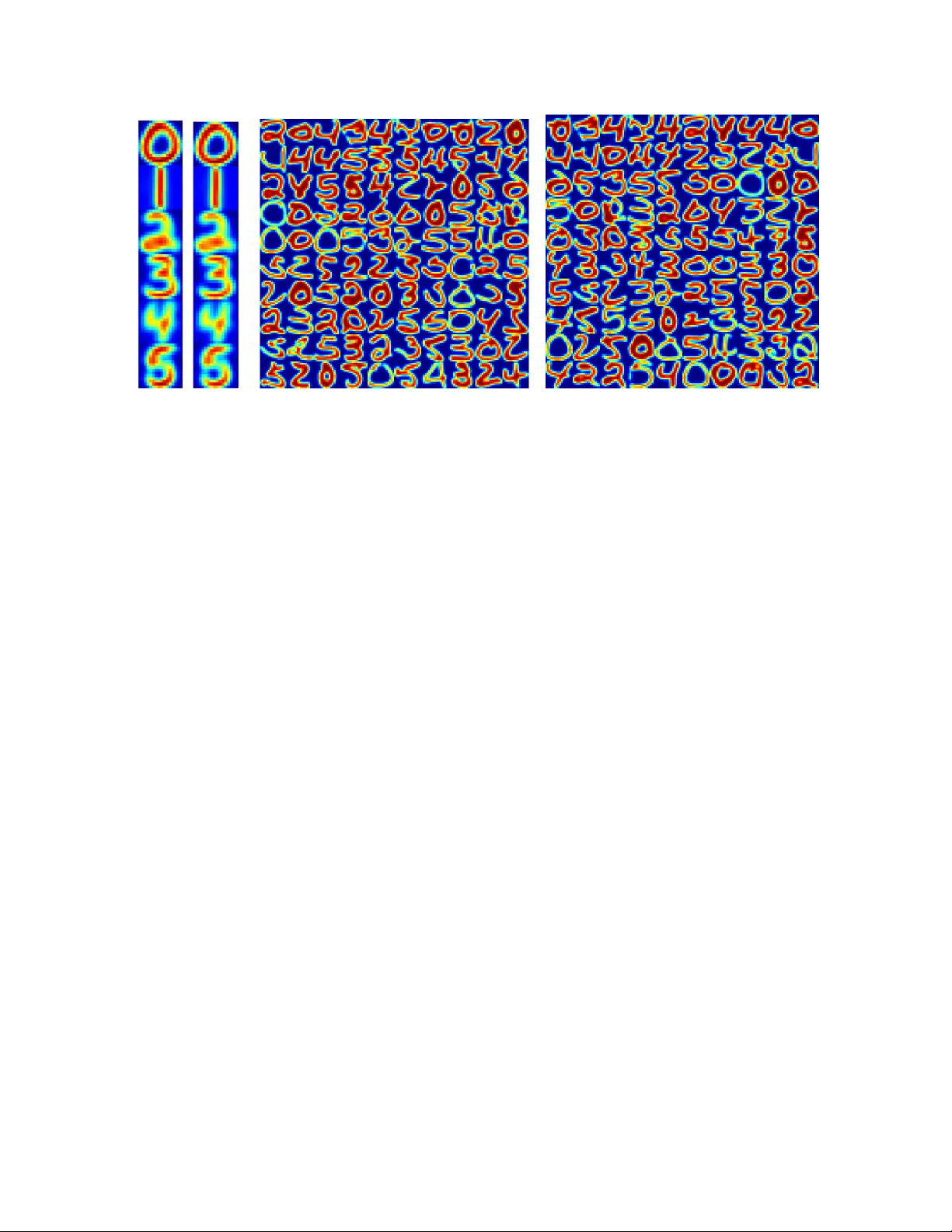
실험에서는 (1) 2‑D 합성 데이터에 인위적 이상치를 삽입, (2) MNIST 손글씨 이미지에 랜덤 픽셀 노이즈와 아웃라이어를 추가, (3) 소셜 네트워크의 인접 행렬에 가짜 노드를 삽입한 사례를 포함한다. 모든 실험에서 제안된 강인 K‑means와 강인 GMM은 기존 비강인 알고리즘 대비 클러스터 정확도, 정밀도·재현율, 그리고 이상치 탐지율에서 10 %~30 % 이상의 개선을 보였다. 특히 커널 버전은 비선형 클러스터를 정확히 복원하면서도 이상치에 대한 민감도가 낮아, 실제 응용에서의 활용 가능성을 크게 높였다.
결론적으로, 이 논문은 압축 센싱(compressive sensing)에서 영감을 얻은 “희소성‑정규화” 아이디어를 클러스터링에 성공적으로 적용했으며, 수학적 엄밀성(수렴 보장, 복잡도 분석)과 실용성(폐쇄형 업데이트, 커널 확장)을 동시에 제공한다는 점에서 클러스터링 분야에 중요한 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기