Scaling and Hierarchy in Urban Economies
In several recent publications, Bettencourt, West and collaborators claim that properties of cities such as gross economic production, personal income, numbers of patents filed, number of crimes committed, etc., show super-linear power-scaling with t…
Authors: Cosma Rohilla Shalizi
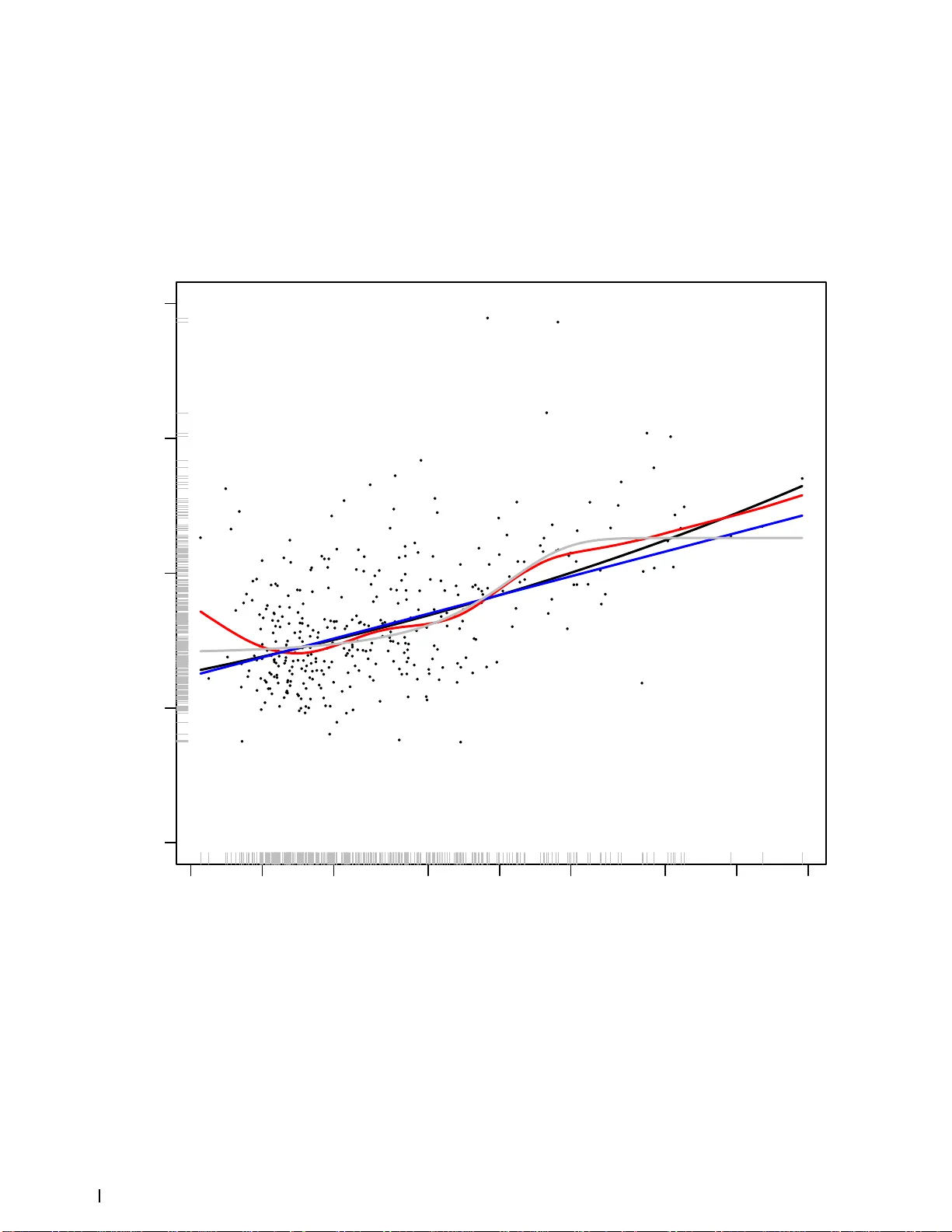
Scaling and Hiera rchy in Urban Economies Cosma Rohilla Shalizi ∗ † ∗ Statistics Department, Ca rnegie Mellon Unive r sity , 5000 F orbes Avenue, Pittsburgh, P A 1513 U SA, a nd † Santa Fe Institute, 1399 Hyde Pa rk Road, Santa Fe, NM 87501 USA Submitted to Pro ceedings of the National Academy of Scie nces of the United States of America In several r ecent public ations, Bettencourt, West and collaborators claim that p rop erties of cities such as gross economic production, per so nal income, numb e r s of patents filed, number of crimes com- mitted, etc., show sup er-linear p ow er-scaling with total population, while measures of resource use show sub-lin ear p ow er-law scaling. Re-analysis of the gross economic production and per sonal income for cities in the United States, ho w ever, sho ws that the data cannot distinguish betw een p ow er la ws and other fun ctional forms, includ- ing logarithmic gr owth, and t hat size predicts relatively little of the variation b etw een cities. The striking appearance of scaling in pre- vious wo rk is largely artifact of using extensive qu antities (city-wid e totals) rather t han intensive ones (per-capita rates). T he remaining dependence of productivity on cit y size is explained by concentration of sp ecialist service i ndustries, with high value-added per wo rker, in larger cities, in acco rdance with the long-standing e co no mic no t ion of the “hiera rchy of central places”. Applied statistics | Model comparison | Urban economics | Urban scaling | Central place hierarchy | Non-parametric smoothing Abbreviations: MSA, metrop ol itan statistical a rea; GMP , gross metrop olitan product; BEA, Bureau of Economic A na lysis; R MS, r oot mean square Intro d u ction R ecent d ramatic adv ances in ex plaining metab olic scaling relations in biology by the p roperties of optimal transp ort netw orks [1, 2] suggest the possibility of examining so cial as- sem blages, esp ecially cities, in similar terms. In a w ell-know n series of papers, Bettencourt, W est and collaborators [ 3, 4] claim th at many social and economic properties of cities — gross economic p rodu ction, total p ersonal income, number of patents filed, num b er of people emplo yed in “sup ercreative” [5] occup ations, num b er of crimes committed, etc. — gro w as sup er-linear p ow ers of population size, while measures of to- tal resource use grow as sub-linear pow ers. These tw o claims imply th at per ca pita output grows as a p ositive p ow er of p opulation, while p er capita resource use shrinks as a nega- tive p ow er. If reliable and precise scaling law s of this type exist, they w ould b e of considerable importance for b oth sci- ence and p olicy [6] 1 . Reasonable arguments from long-standing principles o f economic geography would lead one to exp ect t h at larger cities w ould hav e higher economic outp ut per capita, through a com- bination of the b enefits to firms in related indu stries cluster- ing together (“aggl omeration economies”), and th e tendency of firms and specialists with large increasing returns to scale to b e located high in the “hierarch y of central p laces”. (F or reviews of these concepts, includ in g historical notes, mathe- matical mo dels and empirical evidence, see Refs. [7, 8, 9].) These argumen ts wo uld carry o ver to pro ducing technologi- cally usef ul kno wledge and to “sup ercreative” services as well. How ever, these economic considerations do not p oint to either a particular functional for m f or the growth of per-capita out- put with popu lation, or suggest that it should be very strong. Moreo v er, th ese t h eories do not look at ind iv idual cities as isolated monads, as scaling arguments do, but rather rely on there b eing assem blages of multiple cities (and rural areas), coupled by common economic pro cesses, and assuming dis- tinct roles in those pro cesses through a history of mutual in- teraction and combined and un even devel opment. The purp ose of this note is to argue th at, at least for the United S tates, while th ere is indeed a tend ency for p er- capita economic output to rise with p opulation, p o w er-la w scaling pred icts th e data no b etter t han many other fun c- tional forms, and wors e than some others. F urthermore, th e impressiv e app earance of scaling displa yed in R efs. [3, 4] is largely an aggr egation artifact, arising from looking at exten- sive (city-wide) v ariables rather than intensiv e (p er-capita) ones. The actual abilit y of city size to predict economic out- put, no matter what fun ctional form is used, is quite mod est. These conclusions hold whether economic output is measured by gross metrop olitan prod uct or by total p ersonal income. If we control for metrop olitan areas’ v arying concentration of indu strial sectors, w e find th at the remaining scaling with p opulation is negligi ble, and muc h of the v ariance across ci ties is predicted by the ex tent to whic h th ey host sp ecialist service providers with strongly increasing returns, as predicted b y the idea of th e hierarch y of central p laces. I b egin by re-analyzing th e gross metrop olitan pro duct data, show ing t h at scaling is far weak er than it seemed in Refs. [3 , 4]. I then re-analyzes the data on wa lking sp eed, originating in Ref. [10] and p resented in Ref. [3], which make s the problems with the scaling analysis v ery clear. P er-capita prod uctivity is better predicted by ho w muc h a city dep ends on industrial sectors which indicate a high p osition in the hier- arc hy of sp ecialist service pro vision. This actually eliminates any significant role fo r scaling with si ze. The conclusions sum- marize the scientific imp ort of the data analyses. The supplemental in formation sho ws that (i) scaling also fails for p ersonal i ncome, (ii) th e hyp othesis of p ow er-la w scal- ing cannot b e sav ed by positing a mixture of d istinct scaling relations, and that ( iii) c ontr a Ref. [4], neither a Gaussian nor a Laplace distribut ion is a go od fit to the deviations from the p o w er-la w scaling rela tions. All calculations w ere done using R [11], version 2.12. Co de for reproducing figures and analyses is included in the supple- mental information. Reserved for Pub lication F o otn otes 1 Bettencourt and West sum marize their claims regarding this “unified theory of urban living” [6] thus: “We h a ve recently shown th at th ese general trends [to cities] can be expressed as simple mathematical la ws”; “Our work shows that, despite app earances, cities are appro ximately scaled versions of one another . . . : New Y ork and T oky o are, to a su rprising and predictable degree, non - linearly scaled-up versions of San Francisco in California or Nagoya in Japan . These extraordinary regularities open a window on u nderlying m ech anism, dynamics and stru cture comm on to all cities”; “Surprisingly , siz e is the major determinant of most characteristics of a city; history , geography and design have secondary roles”. www.pnas.org — — PNAS Issue Date Volume Issue Numb er 1 – 7 Mo dels Scaling Mo del s Ref. [3] reported a p ow er-law scaling be- tw een the population of cities in the United States and their economic outpu t. T o b e precise, t he units of anal- ysis are “metropolitan statistical areas” (MSAs) as de- fined by the official statistical agencies 2 . The measure of economic output is the gross domestic pro d uct for each metrop olitan area (“gross metrop olitan prod uct” or GMP), as calculated by the U.S. Bureau of Economic Analysis ( http://www .bea.gov/re gional/gdpmetro/ ), whic h is sup- p osed to b e th e sum of all “incomes earned by labor and capital and the costs incurred in the produ ction of go o ds and services” in t h e metropolitan area [13] 3 . Ref. [3] analyzed data for 200 6, deflated to constant 2001 dolla rs, and I will do lik ewise; the 2008 and 2004 data are not m uc h d ifferent. Ref. [3] prop ose that outp ut scales as a pow er of p opula- tion, Y ∝ N b . This is connected to the data via the linear regression model ln Y = ln c + b ln N + ǫ, [ 1 ] with ǫ b eing a mean-zero n oise term. F or later comparisons, it wil l b e convenien t to denote this by Y ∼ cN b . There is a simple test of the mo del whic h has not, so far as I know, been applied b efore. If pro duction do es scale as some p o w er of p opulation, Y ∼ cN b , then p er-capita pro d uction Y / N ≡ y should also scale , y ∼ c N b − 1 , [ 2 ] and vice v ersa. As shown below, this transformati on drasti- cally c hanges the apparen t fit of the p ow er-la w scaling mo del. It is worth noting that there is no theoretical reason to exp ect a p ow er-law scaling relation of the form of Eq. 1 for urban economies (while there are suc h reaso ns for biological scaling [1, 2]). Accordingly , and unlike R ef. [3], I also consider a log arithmic scaling model, y ∼ r ln N /k [ 3 ] a log istic scaling model, ln y ∼ d 1 + d 2 e ( N − d 3 ) /d 4 1 + e ( N − d 3 ) /d 4 [ 4 ] and finally a non-parametric scaling rela tion, ln y ∼ s (ln N ) [ 5 ] with s an unknown smo oth function, to b e determined by the data. By comparing multiple scaling mo dels, including the fully data-driven Eq. 5, we can see to what extent the data actually provide ev id en ce for particular functional form, or indeed fo r any strong scaling relation at all. Notice that Eq. 2 implies p er-capita output grows with p opulation without limit, and with constan t marginal elastic- it y (the “15 % rule” of [6]); according t o Eq. 3 the gro wth is unlimited, but slo ws as p opulation grows; and according to Eq. 4, p er-capita ou t put is asymptotically constant in p opu- lation. Urban Hi erarc h y An alternativ e to size scaling is hier- arc hical structure. The “hierarch y of central places”, intro- duced by L¨ osc h and Christaller in the 1930s, has b ecome a corner-stone of urban economic geography . In outline, the idea is that developed economies contai n many sp ecialized goo ds, and esp ecially services, th at the mass of consumers need only rarely (such as the serv ices of a surgeon), or indi- rectly (such as the services of a professor of surgery , or a maker of surgical instruments). The provisi on of such services has comparativ ely high fixed costs (the t ime needed to train a surgeon) but low marginal costs (the t ime needed to p erform an operation), leading to increasing retu rns to scale. It thus b ecomes economically efficien t for these sp ecialists t o lo cate in central places, where t h eir fix ed costs can b e distributed o ver large consumer bases, and the more sp ecialized they are, the more cen trally located they need to be, and the larger the customer base they require. This logic leads to th e formation of a hierarc h y of market centers and cities, in which increas- ingly sp ecialized sk ills, with (as it w ere) increasingly increas- ing returns, can be had, and so predicts p ositive associations b etw een the p opulation of urb an cen ters, the con centration of sp ecialist skills within them, and (owing to increasing return s) their p er- capita economic outpu t . Go o d reviews of t he the- ory , including historical citations and connections to mo dern economic mo dels of increasing returns, may b e found in R efs. [7, 9]. F ortunately , the BEA also provides estimates of the shares of gross metropolitan products attributable to differen t indus- trial sectors, some of which corresp on d to the specializations emphasized in central place t heory . I sp ecifically consider “Information, Communicatio n, and T ec hnology (ICT)”, “Fi- nancial activities”, “Profe ssional and tec hnical services” and “Managemen t of companies and en terprises” (industry codes 106, 102, 58 and 62, resp ectively) 4 . W riting the prop ortions of gross metrop olitan pro duct deriving f rom eac h of these sec- tors as x 1 through x 4 , the level of p er-capita pro duction can b e predicted by a log-additive model [15] whic h incorp orates p o w er-la w scaling with city size : ln y = ln c + b ln N + 4 X j =1 f j ( x j ) + ǫ, [ 6 ] where each of the “partial resp onse” functions f j summarizes the contribution of the j th industrial sector. F or comparison with the pow er- law scali ng mod el (Eq. 1), I ha v e constrained the partial resp onse function for size t o b e logarithmic; the other partial resp onse functions can b e n onlinear, though th ey must b e smooth. Statistic al Metho ds P o w er-la w scaling relations, like Eq. 1, were estimated through ordinary least squ ares, i.e., minimizing n − 1 P n i =1 (ln Y i − ln c − b ln N i ) 2 , where the index i runs ov er met rop olitan areas , of which th ere are n = 366. As is wel l known [16], this is a consistent es- timator of regressio n parameters for transformed regressions, even when Gaussian noise assumpt ions are violated, t hough the nominal va lues of standard errors and confidence interv als cannot b e tru sted 5 . The nonlinear but p arametric models (Eq. 3 and 4) w ere fit by nonlinear least squares. 2 T o quote Ref. [12], MS As are “standardized county-based areas that have at least one urbanized area with a pop ulation of 50,000 or more plus adjacent territory that has a high degree of so cial and economic integration with the core, as measured by comm uting ties.” 3 A w ord on the BEA’s procedure is in order [14]. The BEA estimates gross products fo r each industry for each state, and conducts surveys to estimate wh at fraction of each industry’s state- wide earnings is located in each m etropolitan area. Multiplying these ratios by the state-wide gross products, an d summ ing over in d ustries, gives the gross metrop olitan product. The BEA provides no estimates of measurement uncertainty for these nu mbers. 4 The BEA with holds the GMP- contribution figures for some in dustry-MSA combinations, wh en the sector is so concentrated in that city that releasing th e numb er would p rovide consequential business information a b out sp ecific firms. I h ave fi t the model discu ssed b elow for th e 13 3 citi es with compl ete da t a i n the four selected sec tors. Experim enting with v arious forms of imp utation for the missing data did not materially change the results. 5 The analogous procedu re for fit ti ng power-law distributions is not relia ble, due to di fferences between regression and density estimation. 2 www.pnas.org — — Footline Author The non-parametric size scaling relation, Eq. 5, was fit b y means of a smo othing spline [17, 18] on t he logged data. That is, the estimated spline is the function s minimizing n − 1 X i (ln y i − s (ln N i )) 2 + λ Z ( s ′′ ( x )) 2 dx [ 7 ] with the smoothn ess penalty λ > 0 c hosen by cross-v alidation. Smo oth ing splines of this type are universal approximating functions, and p ic king the p enalty by cross-va lidation co ntrols the risk of o ver-fitting non-generali zing asp ects of th e data — see Ref. [18] for details. 6 Finally , the additive mo del (Eq. 6) was es timated b y co m- bining spline smo othing for the non-p arametric partial re- sp on se functions f j , and an iterativ e “bac k-fitting” pro cedure [15]. (I u sed th e mgcv library [19].) This adjusts for the correlations betw een industrial sectors, and b etw een city size and industrial sectors, so th at each estimated partial re sp onse function is, a s far as p ossible, the un ique additive contribution of t hat v ariable to eco nomic output. Results Weakness of Scaling in Gross Metropolitan Pro ducts. Fitting Eq. 1 b y least sq u ares, I estimate b to b e 1 . 12, in agreeme nt with Ref. [3], with a 95% b o otstrap confidence interv al [16] of (1 . 10 , 1 . 15). Figure 1 sho ws the data and the fitted tren d, with both axis p lotted on a l ogarithmic scale, so that a p ow er la w relationship app ears as a straigh t line. The ro ot-mean- squared (RMS) error for predicting ln Y is 0 . 23, and t h e “co- efficien t of determination” R 2 is 0 . 96, i.e., th e fitted va lues retain 96% of the v ariance in the actual data. Visually , this looks like reasonable data collapse. Plot- ting the p er-capita v alues y how ev er, as in Figure 2, reveals a very different picture, th ough the tw o should b e logically equiv alen t un der t h e p ow er-la w model. Figure 2 sho ws a trend curve for the the p ow er- la w scal- ing implied by Ref. [3]. (The exp onent estimated for y is 0 . 12, matching that estimated for Y , as it must.) The fi g- ure also shows the fitted logarithmic scaling relationship ( Eq. 3), whic h is extremely close to the p ow er law ov er the range of the data, t he logistic scaling relationship (Eq. 4), and the non-parametric smo othing spline, corresp onding to the rela- tionship y ∼ e s (ln N ) . Note that the latter curve is not even monotonically increasing in N . While the cu rves in Figure 2 correspond to v ery d ifferent mod eling assumptions — the differences betw een the impli ca- tions of p ow er-la w and logistic scaling are p erhaps esp ecially striking — they al l accoun t for the data about equally well, or rather, equally p o orly , b ecause most of th e v aria tion in per- capita pro du ction is, in fact, unrelated to popu lation. (Note that the vertical axis is linear, not logarithmic.) The R MS errors for ln y of the pow er la w, of logarithmic scaling and of logistic scaling are, respectively , 0 . 232 , 0 . 23 4 and 0 . 22 9, while that of the spline is 0 . 225. They would p redict y , for a ran- domly chosen city , to within ± 26 . 1, ± 26 . 3, ± 25 . 7 and ± 25 . 3 p ercent, resp ectively . Predicting the same va lue of y for all cities, how eve r, h as an RMS error of 0 . 27 , a margin of ± 30%. Thus the R 2 v alues are, re sp ectively , 0 . 24, 0 . 23, 0 . 26 and 0 . 29 . On the linear scale, i.e., in terms of dollars p er p erson-year y , the R MS errors of the pow er la w, logarithmic, logistic and spline curves are, resp ectively , 7 . 9 × 10 3 , 7 . 9 × 10 3 , 7 . 8 × 10 3 and 7 . 7 × 10 3 , as compared to 9 . 2 × 10 3 for pred icting th e mean for all cities. 7 In other w ords, even allow ing for quite arbitrary functional forms, city size do es not pred ict economic output v ery well. The similarit y of the R MS errors, and indeed of th e curves, arises in part from t he limited range of y . The difference b e- tw een the largest and smallest p er- capita pro duct s (6 . 3 × 10 4 dollars/person-year) is “only” a factor of 5.2, i.e., n ot even one order of magnitude. This is too small, with only 366 ob- serv ations, to distinguish among competing functional forms for the trend , while still being quite consequential in human and eco nomic terms. Per-capita pro duction is simply not very strongly related to p opulation. T aking a ny p er-capita (intensiv e) quantit y which is statis- tically in dep endent of p opulation, and lo oking at the corre- sp on d ing aggregate (exten siv e) quantities wil l y ield a scaling exp onent close to one. The o ver whelming ma jorit y of the ap- parent fit of the scaling rela tionship in Figure 1 is j ust suc h an artifact of aggregation. This can be sh o wn in three d ifferent w a ys: by algebra; by extrap olating th e different p er-capita functional forms bac k to city-wide totals; and b y simulati on. Algebraically , supp ose that y was statistically indep en dent of N . Then ln Y = ln y + ln N wo uld be the sum of tw o inde- p endent random v ariables, so its v aria nce would b e th e sum of their v ariances. The R 2 of a linear regres sion of ln Y on ln N , with the slope constrained to be 1, w ould be V ar[ln N ] V ar[ln N ]+ V ar[ln y ] , whic h with this data comes to 0 . 94 [16]. That is, even if in- tensive, p er- capita output w as completely indep endent of cit y size, fi t ting a p ow er-law scaling mo del to th e aggregated data w ould capture 94% of the va riance in the ext ensive, total out- put. The actual R 2 , on the other h and, is only 0 . 96. 8 Figure 3 shows the same d ata and scaling curv e as Figure 1, but three ad d itional trend lines. These are the l ogarithmic, logistic and spline fits to th e per-capita data (from Figure 2) extrap olated bac k to the implied aggregated v alues Y . These are, visually , almost indistinguishable from the fitted p ow er la w; all h a ve R 2 = 0 . 96. Figure 4 d emonstrates in a different wa y that the data do not supp ort the idea of pow er-la w scaling. The circles in th e figure show the actual d ata v alues. The stars, by contrast, are surrogate data simula ted from the fitted logistic scaling mod el, with the actual popu lation sizes. The surrogate p er- capita output val ues ˜ y were set equal to th e fitted v alues un der the model of Eq. 4, and then randomly p erturb ed according to th e empirical distribution of deviations from that mo del. The figure plots the surrog ate aggregate pro ducts ˜ yN , which look very m uc h like the data. If a p ow er-la w scal ing relation is fit to the surrogate data from the logistic-scaling regres sion, then, av eraging ov er many sim ulations, th e median scaling expon ent is 1 . 12, with 95% of the estimates fal ling betw een 1 . 10 and 1 . 15, and t h e m ed ian R 2 of th e p ow er-la w wa s 0 . 96. Recall that the estimate for the actual d ata was 1 . 12, with a 95% confi d ence interv al of (1 . 10 , 1 . 15), and R 2 = 0 . 96. The RMS error for ln y on the real d ata is very slightly lo w er for the logistic mo del ( 0 . 229) th an for the p ow er law (0 . 232). The difference is minute, but is, in fact, statistical ly significan t: when rep eating b oth fits on surrogate d ata sim- ulated from the p ow er law , gaps of th is size or larger occur only ≈ 1% of th e time. Not to o m uc h should b e rea d into this, how ever, owing to the small magnitude of the difference, the large errors around both regression curv es, and the compara- tively small number of observ ations. Reliably discriminating b etw een the t w o models si mply requires more information (in the sense of [23]) than the data p rovides: either m uch smal ler 6 A smoothing spline fi t to the un - transformed data was similar, b ut vi su ally som ewhat m ore jagged. 7 All these measures of error are calculated on the same data used to fit the m odels, exaggerating the mo dels’ predictive p owers. However, using si x-fold cross-validation to approximate the out-of- sample risk gives RMS errors of 0 . 234 for the power law, 0 . 236 for logarithmic scalin g , 0 . 232 for logistic scaling, and 0 . 231 for the spline. Th e differences are small, but bo otstrapping shows they are significan t at the 5% level (at least). 8 Examples li ke th is are why regression textbooks advi se against using R 2 to check goo dness of fit [20, 21, 22]. Footline Author PNAS Issue Date Volume Issue Number 3 fluctuations of y around the regressio n cu rve, or man y more data points. T o sum up these results, the app earance of a strong, super- linear relationship b etw een gross pro d uction Y and p opulation N is mostly driven by pro duction growing in prop ortion to p opulation — that is, linearly . Per-capita pro duction y does not have a strong scaling relationship of any form with N , and the data are unable to distinguish b etw een differen t func- tional forms for such trends as th ere are. The same is true of p ersonal income (SI, section 1). Lacking ready access to the data sets on patents, crime, infrastructure and resource consumption whic h Ref. [3] analyzed in t he same w ay as eco- nomic output and personal income, I cannot sa y whether the rep orted scaling relations for t hose aggregate vari ables suffer from t he same problem. Sup eriorit y of the Urban-Hiera rchy Model. T o address the question of why th ere is a w eak and noisy tendency for p er- capita ou t put to rise with p opulation, I turn to the log- additive mo del, Eq. 6. Fitting to the data y ields the par- tial resp onse funct ions show n in Figure 6. A s exp ected from the urban-hierarch y a rgument, a ll four of the partial response functions are monotonically increasing, so that rising shares of those industries p redict increasing p er capita p rod u ction. V ery notably , ho w ev er, the es timated p o w er-la w scaling expo- nent is actually negativ e, − 2 . 6 × 10 − 3 , but statisticall y indis- tinguishable from zero (standard error 2 . 8 × 10 − 2 ). That is, in the log-additive model, con trolling for these four ind u strial sectors make s pop u lation effectively irrelev an t for p redicting urban pro ductivity . Indeed, dropping p opulation from th e mod el altogether pro duces n o appreciable difference in the fit. At least at the lev el of exp ectation va lues, con trolling for these four industrial sectors “screens off ” th e effects of city size on p er-capita pro d uction. Statistically , there is no question that the log-additive mod el predicts b etter than the simple scaling mo del. The RMS error of the former, on the log scale, is 0 . 218, corresp ond- ing to an R 2 of 38 . 8%, and an accuracy o f ± 24% or $6 . 8 × 10 3 , b etter than any mo del based on size alone. The log-additiv e mod el is a more flexible sp ecification, and so ov er-fitting to t he data is an issue, but th is can be a ddressed b y cross-v alidatio n, whic h directly measures the ability of a model to ex trap olate from one p art of the data to another [17]. The cross-v alidated mean sq uared error of the log-additiv e model is 0 . 0 53, while that of the pure p ow er la w is 0 . 067 , clearly sho wing that the extra complexity of t h e former is being used to capture gen- uinely predictive patterns, and not merely to memorize t he training data 9 . The simple log -additive model is un likel y to b e a fully ad- equate predictor o f systematic differences in urban pro ductiv- it y . If n othing else, these four coarse-grained industrial sectors w ere selected merely for conv enience, as approximate indica- tors of p osition in the urban hierarc h y , and presumably could b e improv ed. Moreo ve r, t he mod el do es n ot even try to rep- resen t the interactiv e pro cesses whic h lead cities to hav e the industrial mixes th at they do. In realit y , these indu stries can b e so concentrated tow ards th e larg est cities, at the top of the hierarc hy (e.g., New Y ork) , and aw ay from low er-rank cities (e.g., San F ra ncisco, Peo ria), only because all these cities are part of a single national, and even in ternational, division of labor [9]. “The Pace of Life”. A further claim of Ref. [3 ] is that the sp eed at which p eople w alk gro ws as a p ositive p ow er of the num ber of p eople in a cit y . The source given for this is Ref. [10], a t w o-page letter to Natur e in 1976. The authors of Ref. [10] we nt to 15 cities, towns and v illages, pick ed lo cations and individ u als whic h seemed to them to be comparable, and timed how long it took them to w alk fifty fee t (15 . 2 meters). Such u nsystematic data, how ev er intrig uing, is to o w eak to supp ort substantial scientific conclusions. Nonetheless, it is instructive to examine it, as in Figure 5. The original plot ( Figure 1 in Ref. [10]) show ed p opula- tion on a l og scale, and sp eed on a linear scale, as in Figure 5. The linear regression, for this transformation o f the data, co r- respond s to assuming that sp eed grows logarithmicall y with p opulation, v ∼ r ln N /k . Figure 2a in Ref. [3] re-plots the same data, but with the v ertical axis on a loga rithmic scale, so the linear regression assumes sp eed grow s as a p ow er of p opulation, v ∼ cN b . (Neith er fi gure included error b ars, though Bornstein and Bornstein giv e the standard deviations in their caption.) As can b e seen from Figure 5, b oth of these regressions, along with logistic scaling, are v ery s imilar in th is data, while they embo dy very different assumpt ions, and at most one can b e righ t. The exp lanation for th is apparent paradox is that the range of reported walking sp eeds is small, from 0 . 7 m/s to 1 . 8 m/s, and if | x | ≪ 1, then ln 1 + x ≈ x . Observ ed o v er a narro w range, then, logarithmic and pow er la w sca ling simply are v ery si milar, and hard to d istinguish. This is a lso wh y th e the p ow er- la w an d logarithmic fits to p er-capita pro duction in Figure 2 w ere so close. Discussion Neither gross metrop olitan pro duct nor p ersonal income scales with p opu lation size f or U .S . metrop olitan area s. The app ear- ance of scali ng in Refs. [3, 4] is an artifact of inappropriately looking at ext ensive v ariables (city-wide totals) rather th an intensiv e ones (p er-capita v alues). S caling is also unp ersua- sive for walking speed. I was not able to examine the other v ariable s claimed to sho w scal ing in Refs. [3, 4], but, as they w ere all extensiv e v ariables , the analyses re p orted there w ould b e su b ject to the same aggregation artif acts. It is also p ossible that cities in the contemporary United States are anomalous, and that scaling of income and economic output holds else- where. It is evident f rom Figures 2 (and Supplemental Figure S1) that there is a w eak tendency for p er-capita output and in- come to rise with population, though the relationship is sim- ply to o loose to qualify as a scaling law. (A rguably , the real trend in those figures is f or the mini mum p er-capita output to rise with p opulation, though I would p ress this p oint.) Q ual- itative ly , this is what one w ould expect from w ell-established findings of economic geography [8]. The d ata do not really supp ort any stronger quantitative s tatement. In p articular, asserting any sp ecific functional form, such as a p ow er law, goes far beyond th e what the data can su pp ort. Nor is there any theory , sup p orted on ind ep endent ground s, which predicts a sp ecific functional form. Accordingly , extrapolations based on suc h claims (e.g. , th e fi nite-time singularit y in the mod el for city growth in [3]) are speculative at best. The amplitude of fl uctuations around the trend lines are, in an y case, so large that predictions based on size alone can h a ve very little u tilit y . By taking account of the shares of just a few industries in the gross metropolitan pro duct, w e can obtain muc h b etter predictions of the lev el of p er-capita pro du ction. In this sta- tistical model, summarized in Eq. 6, p opulation plays no sig- nificant direct role in predicting per capita economic output, and co uld in fact be profitably ig nored. Rath er, the industrial sectors used are chosen as signs of where metrop olitan areas 9 Dropping p opulation size N from the log- additive mo del altogether actually improves the cross- validation score, very slightly, to 0 . 052 . 4 www.pnas.org — — Footline Author stand in the urban hierarc hy , whic h is also related, of course, to size. On e could in terpret this as the mechanism b y which size scaling happ ens (to the ext ent that it d oes), b ut this w ould imply that an exogenous increase in a cit y’s population w ould automatically shift its industrial pattern, which is im- plausible. Indeed, the whole scaling picture for cities see ms to rest on an odd ly monad ic, interaction-free view of metropoli- tan areas. The logic of central place theory , in con trast, relies on cities being part of an in teractiv e assemblage, coup led by processes of pro duction, distribution and exchange. This not only seems more p lausible, but also b etter matches the evi- dence at hand. As Refs. [3, 4, 6] h a ve stressed, developing a sound sci- entific understanding of cities should b e a priority for an in- creasingly urban sp ecies. In seeking such understanding, it is a sound strategy to begin with simple hypotheses, and to reject them in f a vor of more complica ted ones on ly as they p ro ve un - able to explain the data. This is not b ecause the truth is more lik ely to b e simple, in some metaphysical sense, but b ecause this strategy leads u s to the t ru th faster and more reliably than ones which inv oke n eedless complexities [24]. The ele- gan t hyp othesis of p o w er-la w scaling marked a step forwa rd in our u nderstanding of cities, but it is now time to leav e it b ehind. App endix P ersonal Income The BEA also mak es av ailable estimates of p ersonal income by metrop olitan area, a vari able closely related to, but not quite the same as, the gross metrop olitan pro duct. (See http://www .bea.gov/r egional/reis/ for d efinitions, estima- tion techniques, and data.) Ref. [4] reports that total personal income L also scales as a pow er of p opulation, implying p er capita p ersonal income L/ N ≡ l should scale lik ewise. Figure 7 p lots l versus N , w ith the b est-fitting p ow er law, logarithmic relationship, and spline. Once again, the app earance of p ow er-law scaling in the aggregate v ariable is not supported by examination of th e p er- capita v alues. The RMS error, on the log scale, of predicting a constant per capita income o ve r all cities is 0 . 179, while the RMS errors of th e p ow er-law, logarithmic and logistic scal- ing rela tions are 0 . 15 7, 0 . 158 and 0 . 156, and th at of th e spline 0 . 154. Even the sp line th us has an R 2 of on ly 0 . 26. Rep eating the procedures of Figures 3 and 4 from the main text yields similar results. Th us, p ersonal income also fails to display non-trivial scaling with p opulation. Mixtures of Scaling Relations Recall that the p osited scaling relation is y ∼ cN b . As sh own above, th is do es not fit the d ata, at least not assuming, fol- lo wing Ref. [3], that b oth parameters, th e scaling exp onent b and the pre-factor c , are the same for all cities. A natu- ral w a y to try to reconcile the data with the model w ould b e to mo dify th e latter, allo wing c to depend on the typ e of the cit y . The rationale for suc h a regression w ould b e that t h ere are sev eral different kinds of cities, and that cit y t yp e shifts the o ve r-all lev el of production u p or do wn, but, once that is factored out, all cities scale with size in th e same w a y . This common scaling exp onent would n ot, naturally , be the same as the one estimated from the p o oled data. F ormally , w e introd uce a latent v aria ble Z for each cit y , treated as a discrete random v ariable independ ent of N , and consider the statistical mo del y ∼ c Z N b . This leads to a “mixture-of-regressions” or “latent-class regression” mo del, whic h can b e fit by the exp ectation-maximization algorithm [25]. Such fi tting w ould lead not only to estimates of b and the pre-factors c z , but also to the probabilit y that each cit y b elonged to eac h of the differen t city types or mixture com- p onents, categorizing cities inductively from the data. T o investi gate this, I fi t mixtu re-of-regression models to the data fro m Figure 2 in the main text, v arying the num ber of mixture comp onents from 1 to 10, u sing the softw are of Ref. [25]. 10 T o determine the correct number of mixture comp o- nents, I used both Sc hw arz’s “Ba y esian” info rmation criterion and cross-v alidation, whic h are both known to b e consistent for such mixture problems, unlike the Ak aik e informa tion cri- terion, whic h ov er-fits [26]. Both BIC and cross-v alidation strongly fa vo red one mixture comp onent, meaning that the fit to t he data is not actually improve d by allo wing for multi- ple scali ng curves. This do es not completely rule out the y ∼ c Z N b mod el, as only 366 observ ations ma y not hav e enough information to sim ultaneously indu ce approp riate categories and fit scaling relations. A n alternative w ould b e to expand the information a v aila ble, by defi ning th e categorical vari able Z in terms of measurable attrib u tes of cities other than N and y , such as geographic lo cation or the mix of industries. (S ee Ref. [27] on such v ariable-intercept, constant-slope regressions with known categories.) Su ccess with such mo dels hinges on selecting ca t- egories to represen t important f eatures of the d ata-generating process, a task I must le av e to other inquirers. Assuming that suc h a statistical mo del w orks, there w ould still b e the question of its in terpretation. Whet h er one would judge such a mod el to really sho w scaling in urban assemblage s w ould dep end on ho w m uch importance one gives, on th e one hand, to a common scaling exp onent, and on t he other to most of the fit coming from the un-modeled differences across cit y types. Residuals Ref. [4] prop oses ranking cities not b y their p er capita v alues of quantities like economic pro duction or patents or crime, but by the deviation, p ositive or negative, from th e scaling rela- tionship, i.e., by the residuals of t he trend lines. (It does not compare this to ranking b y p er capita v alues. The Spearman rank correlation b etw een the tw o v ariables is 0 . 87 for GMP and 0 . 83 for p ersonal income.) They consider b oth a Gaus- sian distribution for the residuals, i.e., a probability density f ( x ) ∝ e − x 2 / 2 σ 2 , and a Laplace distribution, f ( x ) ∝ e − λ | x | , and claim that b oth fit very w ell. Figure 8 show s the situation for GMP . Visually , nei- ther distribution matches the residuals well. Quantitativ ely , goo dness-of-fit can be c hec ked b y “data-driven smo oth tests” [28], whic h transform th eir inputs so that they will b e uniform if an d o nly if th e p ostulated distribution h olds, and th en mea- sure departures from uniformit y (coefficients from expanding the transformed empirical distribution in a series of orthogo- nal polynomials). Such tests rej ect b oth the Gaussian and the Laplace distribution with hig h confidence ( p - v alues of 1 × 10 − 3 and 8 × 10 − 3 , respectively , calculated using co d e p ro vided by Ref. [29]). 10 Fo r computational reasons, it is easier to fi t the more general specification in which the scaling exponent is also allow ed to vary , y ∼ c Z N b Z . (Sharing a parameter across th e regressions complicates the maximiz ation step of the expectation-maxim ization algorithm.) If the constant- exponent mo del is right, the estimated exponents for each mixture component should agree to within statistical precision. Footline Author PNAS Issue Date Volume Issue Number 5 Results for p ersonal income are similar (Figure 9). The Gaussian distribution can b e rejected with high confidence ( p < 10 − 4 ). While the data do not rule out the Laplace d is- tribution in the same w a y ( p = 0 . 27), the li mited pow er of the test at th e comparativ ely small sample size means th at there is not strong evidence in its fa v or either. (See Ref. [30] on the evidential interpretation of significance tests.) ACKNO WLEDGMENTS . Thanks to Jo rdan Ellenber g fo r valuabl e que stions, and to grants from the NIH (# 2 R01 NS047493) and the Institute for New Economic Thinking for partial supp ort. References 1. Geoffrey B. W est, James H. Bro wn, and Brian J. Enquist. A general mod el for the origin of allometric scaling laws in biology . Scienc e , 276:122–126 , 1997. UR L http://www .santafe.e du/media/workin gpapers/97- 03- 019.pdf . 2. James H. Brown and Geoffrey B. W est, editors. Sc aling in Biolo gy , Ox ford, 2000. Oxford Unive rsit y Press . 3. Lu ´ ıs M. A. Bettencourt , Jos´ e Lob o, Dirk Helbing, Chris- tian K ¨ unhert, and Geoffrey B. W est. Gro wth, innov a- tion, scal ing, and the pace of life in citie s. Pr o c e e di ngs of the National A c ademy of Scienc es (USA) , 104:7301 –7306, 2007. doi: 10.1073/ pnas.0610172104. 4. Lu ´ ıs M. A. Bettencourt, Jos ´ e Lob o, Deb orah Strum- sky , an d Geoffrey B. W est. Urban scaling and its de- viations: R eveal ing the structu re of w ealth, innov ation and crime across cities. PL oS One , 5:e13541, 2010. doi: 10.1371 /journal.pone.0013541. 5. Richard L. Florida. The Rise of t he Cr e ative Class . Basic Books, New Y ork, 2002. 6. Lu ´ ıs M. A. Bettencourt and Geoffrey B. W est. A unified theory of urban living. Natur e , 467:912–9 13, 2010. doi: 10.1038 /467912 a. 7. P aul R . Krugman. The Self-Or ganizing Ec onomy . Black- w ell, Oxford, 1996. 8. J. V ernon Henderson, Zmarak Shalizi, and An - thony J. V enables. Geograph y and develo p- ment. Journal of Ec onomic Ge o gr aphy , 1:81– 105, 2001. doi: 10.1093 /jeg/1. 1.81. URL http://pap ers.ssrn.c om/sol3/papers. cfm?abstract_id=632526 . 9. Masahisa F ujita, Paul Krugman, and Anthony J. V en- ables. The Sp atial Ec onomy: Cities, R e gions, and Inter- national T r ade . MIT Press, Cambridge, Massac h usetts, 1999. 10. Marc H . Bornstein and Helen G. Bornstein. The p ace of life. Natur e , 259 :557–559 , 1976. doi: 10.1038/2 59557a0. 11. R D evel opment Core T eam. R: A L anguage and En- vir onment for Statistic al Computing . R F oundation for Statistical Computing, Vienna, A ustria, 2010. URL http://www .R- project.org . ISBN 3-90005 1-07-0. 12. Matthew J. McCormic k, Sharon D. P anek, and Ralph M. Ro driguez. Gross domestic prod uct by metrop olitan area: A ccelerated statistics for 2008, new statistics for 2007, and rev ised statistics for 2005–2006. Survey of Curr ent Business , pages 100–128, Octob er 2009. URL http://www .bea.gov/s cb/pdf/2009/10% 20October/1009_gdpmetro.pdf . 13. S la vea Assenov a, John Brod a, and S hane T aylor. Gross domestic prod uct b y state: Adv ance statistics for 2009 and rev ised statistics for 1963–2008 . S urvey of Curr ent Business , pages 72–77, Decemb er 2010. URL http://www .bea.gov/s cb/pdf/2010/12% 20December/1210_gdp_state- text.pdf . 14. S haron D. P anek, F rank T. Baumgardner, and Matthew J. McCormick. Introducing new measures of th e metrop olitan economy: Protot yp e gdp - by- metrop olitan-area estimates for 2001–2005. Survey of Curr ent Business , pages 79–114, Nov em b er 2007. UR L http://www .bea.gov/s cb/pdf/2007/11%20November/1107_gdpmetro. p d f . 15. A ndreas Buja, T rev or Hastie, and Rob ert Tib- shirani. Linear smoothers and additive mo d- els. Ann als of Statistics , 17:453–5 55, 1989. UR L http://pro jecteuclid .org/euclid.aos/1176347115 . 16. Larry W asserman. Al l of Statistics: A Concise Course in Statistic al Infer enc e . Sp ringer-V erlag, Berlin, 2003. 17. T revor Hastie, R ob ert Tibshirani, and Jerome F riedman. The Elements of Statistic al L e arn- ing: Data Mining, Infer enc e, and Pr e diction . Springer, Berlin, second edition, 2009. URL http://www - stat.stanford.edu/ ~ tibs/ElemS tatLearn/ . 18. Grace W ahba. Spline Mo dels for Observational Data . So- ciet y for Industrial and Applied Mathematics, Philadel- phia, 1990 . 19. S imon N . W o o d . S t able and efficient multi- ple smo othing parameter estima tion for general- ized additive mo dels. Journal of the Americ an Statistic al Asso ciation , 99:673–68 6, 2004. URL http://www .maths.bat h.ac.uk/ ~ sw283/simo n/papers/m agic.pdf . 20. Michael H. Birnbaum. The d ev il rides again: Correla- tion as an index of fit. Psycholo gic al Bul letin , 79:239–2 42, 1973. d oi: 10.1037/h0033 853. 21. N orman H. An derson and James Shanteau. W eak infer- ence with linear models. Psycholo gic al B ul l etin , 84:1155– 1170, 1977. doi: 10.1037/0033- 2909.84.6.1155. 22. R ic hard A. Berk. R e gr ession Analysis: A Constructive Critique . S age, Thousand Oaks, Califo rnia, 2004. 23. S olomon Kullback. Information The ory and Statistics . Dov er Books, New Y ork, 2nd edition, 1968. 24. Kev in T. Kelly . Simplicit y , truth, and prob- abilit y . In Prasanta Bandyopadh ya y and Mal- colm F orster, editors, Handb o ok on the Philoso- phy of Statistics . Elsevier, Dordrech t, 2010. URL http://www .andrew.cm u.edu/user/kk3n/ockham/prasanta- submit- f i n a l . p d f . 25. T atiana Benaglia, Didier Chauveau, David R. Hunter, and Derek S. Y oung. mixto ols: An R p ac k age for analyzing mixture models. Journal of Statistic al Softwar e , 32, 2009. URL http: //www.jstat soft.org/v3 2/i06 . 26. Gerda Claeske ns and N ils Lid Hjort. Mo del Sele ction and Mo del A ver aging . Cam bridge Universit y Press , Cam- bridge, England, 2008. 27. A ndrew Gelman and Jennifer Hill. Data Analysis Us- ing R e gr ession and Multilevel/Hier ar chic al Mo dels . Cam- bridge Univers ity Press, Cambridge, England, 20 06. 28. Wilb ert C. M. Kallenberg and T eresa Led wina. D ata- driven smo oth tests when th e hyp othesis is comp osite. Journal of the A meric an Statistic al Asso ciation , 92:1094– 1104, 1997. URL http:/ /doc.utwen te.nl/62408 / . 29. Przemysla w Biecek and T eresa Ledwina. ddst: Data driven smo oth test , 2010. URL http://CRA N.R- project.org/packag e=ddst . R pac k age, versi on 1.02. 30. D eb orah G. Ma y o and D. R. Co x. F requentist statistics as a theory of inductive inference. In Ja vier Ro jo, editor, Optimal ity: The Se c ond Erich L. L ehmann Symp osium , pages 77–97 , Bethesda, Mary- land, 2006. Institute of Mathematical Statistics. UR L http://arx iv.org/abs /math.ST/0610846 . 31. Jeffrey S. Simonoff. Smo othing M etho ds in Statistics . Springer-V erlag, Berli n, 1996. 6 www.pnas.org — — Footline Author 5e+04 1e+05 2e+05 5e+05 1e+06 2e+06 5e+06 1e+07 2e+07 1e+09 5e+09 5e+10 5e+11 MSA population Gross product (2001 dollars/year) Fig. 1. Horizontal axis: population of the 366 US metrop olitan statistical areas in 2006, log scale; vertical axis, 2006 gross pro duc t of each MSA, in c onstant 2001 dolla rs, log scale. (In all figures, grey inner ticks on ax e s ma rk observed values.) Solid line: ordinary least squa res regression of log gross metrop olitan product on log p opulation, i.e., the regression Y ∼ cN b , with estimated exp onent ˆ b = 1 . 12 . Footline Author PNAS Issue Date Volume Issue Number 7 5e+04 1e+05 2e+05 5e+05 1e+06 2e+06 5e+06 1e+07 2e+07 0 20000 40000 60000 80000 MSA population Gross product per capita (2001 dollars/person−year) Fig. 2. Ho rizontal axis: p opulation, as in Figure 1, log scale. Vertical axis: gross p roduct pe r capita, but on a linear and not a logarithmic scale. The tw o largest values are 7 . 8 × 10 4 dollars/person-yea r ( in Bridgeport-Stamfo rd-No rw alk, CT, a center fo r hedge funds and other financial firms) and 7 . 7 × 10 4 dollars/person-yea r ( in San Jose-Sunnyvale-Santa Clara, CA, i.e., Silicon Valley), and the smallest are 1 . 5 × 10 4 dollars/person-yea r (in McAllen-Edi nburg- Mission, TX and P alm Coast, FL). Black line: fitted p ower-la w scaling relation. Blue line: fitted logarithmic scaling relationship. Grey li ne : logistic scaling. Red line: smoothing spline fitted to the logged data. 8 www.pnas.org — — Footline Author 5e+04 1e+05 2e+05 5e+05 1e+06 2e+06 5e+06 1e+07 2e+07 1e+09 5e+09 5e+10 5e+11 MSA population Gross product (2001 dollars/year) Fig. 3. As in Figure 1, but w ith the addition of curves sho wing the scaling relations from Figure 2, ex trap olated to aggregate rather than p er-capita values. These are visually all but indistinguishable. Footline Author PNAS Issue Date Volume Issue Number 9 5e+04 1e+05 2e+05 5e+05 1e+06 2e+06 5e+06 1e+07 2e+07 1e+09 5e+09 5e+10 5e+11 MSA population Gross product (2001 dollars/year) * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * Fig. 4. A xes: as in Figure 1 and 3. Circles: Actual values. Stars: simulated values, with pe r-capita production figures drawn f rom the logistic (not p ow er-la w) scaling mo del. 10 www.pnas.org — — Footline Author 5e+02 5e+03 5e+04 5e+05 0.5 1.0 1.5 2.0 P opulation P edestr ian speed (m/s) Fig. 5. Horizontal axis: c ity p opulation, logarithmic scale. Vertical axis: e stimated p edes- trian sp eed in meters/second, plus or minus one standard deviation, linear scale. Blue line: the regression v ∼ r ln N /k , as proposed b y Ref . [ 10]. Black line: the regression v ∼ cN b , as proposed b y Ref. [3]. Gre y line: logistic scaling. (Da ta from R ef. [10], who report the mean and standard deviation of the time taken to walk 50 fee t = 15.2 meters; I calcula ted standard deviations by propagation of error.) Footline Author PNAS Issue Date Volume Issue Number 11 0.0 0.1 0.2 0.3 0.4 −0.5 0.0 0.5 1.0 ict par tial response (log scale) 0.05 0.10 0.15 0.20 0.25 0.30 0.35 −0.5 0.0 0.5 1.0 finance par tial response (log scale) 0.05 0.10 0.15 −0.5 0.0 0.5 1.0 prof essional.and.technical par tial response (log scale) 0.00 0.01 0.02 0.03 0.04 0.05 −0.5 0.0 0.5 1.0 management par tial response (log scale) Fig. 6. Pa rtial resp onse functions for the log-additive model (Eq. 6). Horizontal axes indicate the fraction of each metropol itan area’s gr oss product derived from each industry , while the ve rtical ax i s shows the predicted logarithmic increase, or dec rease, to pe r capita output, relative to the baseline of the mean over a ll cities. Solid curv es are the main e stimate, with da shed curves a t ± 2 standard erro rs i n the partial response function. Dots sho w “pa rtial residuals”, the diffe rence betw een actua l ln y val ues and those predicted by the model i n c luding all the other variables. 12 www.pnas.org — — Footline Author 5e+04 1e+05 2e+05 5e+05 1e+06 2e+06 5e+06 1e+07 2e+07 0 20000 40000 60000 80000 P opulation P er−capita P ersonal Income (2006 dollars/person−year) Fig. 7. P ersonal income p er capi t a versus p opulat i on, 2006. Ho rizontal axis: population of MSAs (log scale). Vertical axis: p ersonal income per capita, in nominal 2006 dollars (linear scale). Bla c k line: p ow er-la w scaling curve (estimated exp onent 0 . 082 ). Blue line: loga rithmic scaling curve. Grey li ne : logistic scaling curv e . Red line: spline fit to logged data. Footline Author PNAS Issue Date Volume Issue Number 13 −1.0 −0.5 0.0 0.5 1.0 0.0 0.5 1.0 1.5 2.0 2.5 3.0 residual from log−log regression Density Fig. 8. Ho rizontal axis: magnitude of residual s from p ow er-law scaling of gross metrop olitan product on p opulati on, i.e., from regressing l n Y on ln N . Vertical axis: p robability de nsity of the residual distribution. Solid line: Nonparametric kernel density estimate (Gaussian kernel, default bandwidth c hoice — see Ref. [31] ) . Dashed line: maxi mum lik eliho o d Gaussian fit to residuals. Dotted line : maximum likelihoo d Laplace (double-exp onentia l ) fit to residuals. 14 www.pnas.org — — Footline Author −0.5 0.0 0.5 0 1 2 3 4 5 residual from log−log regression Density Fig. 9. As in Figure 8, but showing the deviations of p ersonal income fr om p ow er-la w scaling. Footline Author PNAS Issue Date Volume Issue Number 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment