Statistique et Big Data Analytics; Volumetrie, LAttaque des Clones
This article assumes acquired the skills and expertise of a statistician in unsupervised (NMF, k-means, SVD) and supervised learning (regression, CART, random forest). What skills and knowledge do a statistician must acquire to reach the "Volume" sca…
Authors: Philippe Besse (IMT), Nathalie Villa-Vialaneix (MIAT INRA)
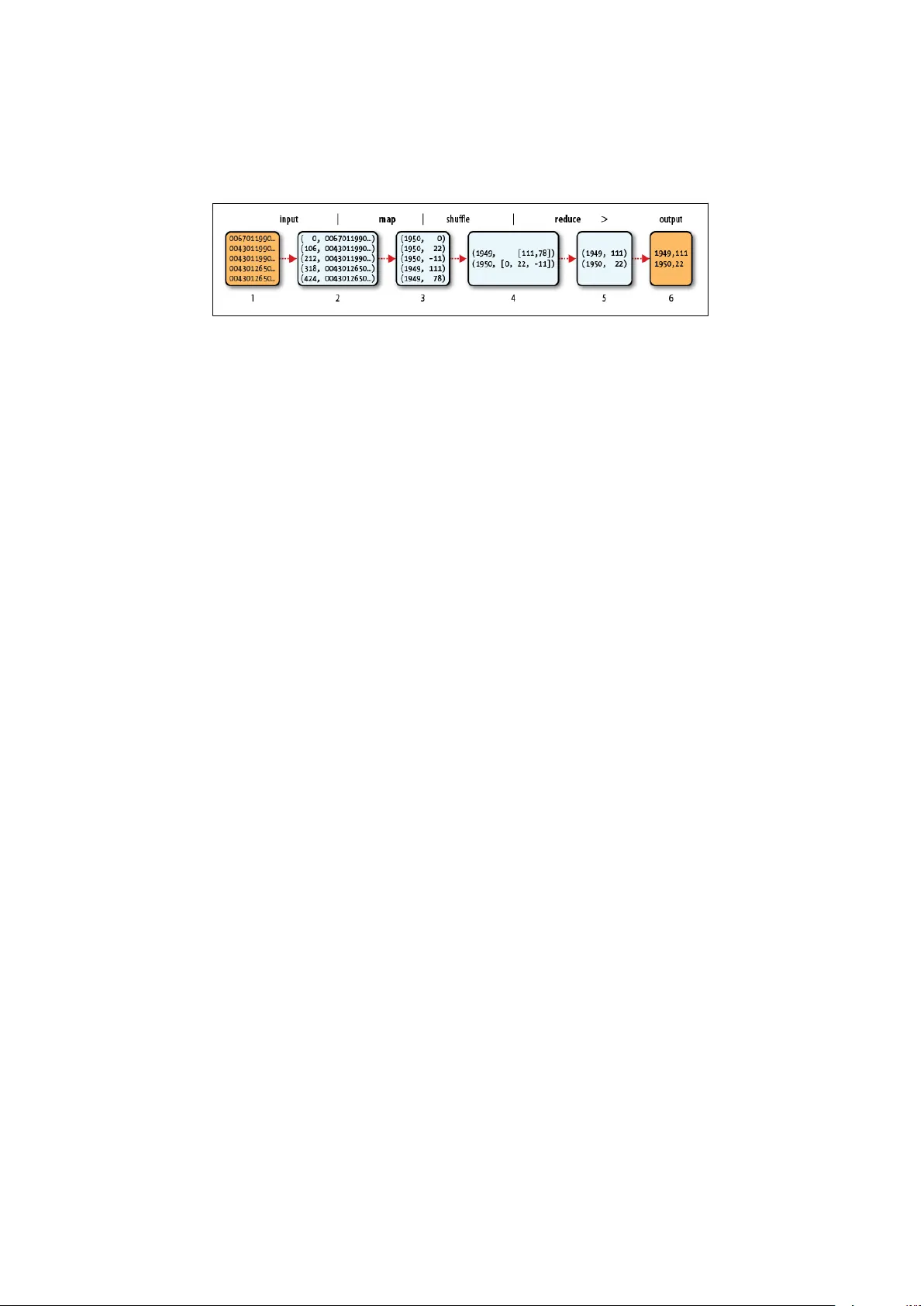
Statistique et Big Data Analytics V olumétrie – L ’Attaque des Clones Philippe Besse ∗ Nathalie V illa-V ialaneix † 7 octobre 2014 Résumé : Cet article suppose acquises les compétences et expertises d’un statisticien en apprentissage non supervisé ( NMF , k -means , svd ) et supervisé ( régression , cart , random forest ). Quelles compétences et sav oir faire ce statisticien doit-il acquérir pour passer à l’échelle “ V o- lume ” des grandes masses de données ? Après un rapide tour d’ho- rizon des différentes stratégies of fertes et principalement celles im- posées par l’en vironnement Hadoop , les algorithmes des quelques méthodes d’apprentissage disponibles sont brièvement décrits pour comprendre comment ils sont adaptés aux contraintes fortes des fonc- tionnalités Map-Reduce . La prochaine étape sera sans doute de les ré- écrire dans le langage matriciel similaire à R des communautés Ma- hout , Spark , Scala . Mots-clefs : Statistique ; Fouille de Données ; Grande Dimension ; Apprentissage Statistique ; Datamasse ; algorithmes ; Hadoop, Map- Reduce ; Scalability . Abstract : This article assumes acquired the skills and expertise of a statistician in unsupervised (NMF , k-means, SVD) and supervised learning (regression, CAR T , random forest). What skills and kno w- ledge do the statistician must acquire it to reach the "V olume" scale of big data ? After a quick ov erview of the different strategies av ai- lable and especially those imposed by Hadoop, algorithms of some av ailable learning methods are outlined to understand how they are adapted to high stresses of Map-Reduce functionalities. The next step will probably be to re write them using the R like matricial language which is de velopped by the communities Mahout , Spark and Scala . ∗ Univ ersité de T oulouse – INSA, Institut de Mathématiques, UMR CNRS 5219 † INRA – UR875 MIA-T 1 F I G U R E 1 – Armée de clones , baies de serveurs, alignés par milliers dans le han- gar d’un centr e de données de Google . K eywords : Statistics ; Data Mining ; High Dimension ; Statistical learning ; Big Data ; algorithms ; Hadoop ; Map-Reduce ; Scalability . 1 Intr oduction 1.1 Motiv ations L ’historique récent du traitement des données est schématiquement relaté à trav ers une odyssée : Retour vers le Futur III (Besse et al. ; 2014)[ 2 ] montrant comment un statisticien est successi vement devenu prospecteur de données, bio- informaticien et maintenant data scientist , à chaque fois que le v olume qu’il a vait à traiter était multiplié par un facteur mille. Cette présentation rappelle ég alement les trois aspects : volume, variété, vélocité, qui définissent généralement le Big Data au sein d’un écosystème , ou plutôt une jungle, e xcessiv ement complex e, concurrentielle voire, conflictuelle, dans laquelle le mathématicien / statisticien peine à se retrouv er ; ce sont ces difficultés de béotiens qui moti vent la présentation d’une nouvelle saga : Data W ar en 5 v olets dont seulement trois seront interprétés. La Menace F antôme est jouée av ec la NSA dans le rôle de Big Br other , L ’Attaque des Clones contre la V olumétrie est l’objet du présent article avec les baies ou conteneurs d’empilements de serveurs dans le rôle des clones (cf. figure 1 ). La Rev anche des Maths intervient dans la vignette (à venir) consacrée à la V a- riété (courbes, signaux, images, trajectoires, chemins...) des données qui rend indispensable des compétences mathématiques en modélisation, no- tamment pour des données industrielles, de santé publique... Le Nouvel Espoir est d’aider au transfert des technologies et méthodes ef ficaces issues du e-commerce v ers d’autres domaines (santé, climat, éner gie...) et à 2 d’autres buts que ceux mercantiles des origines. L ’Empire Contre-Attaque a vec GAF A 1 dans le rôle principal de la vignette (à venir) qui aborde les problèmes de flux ou Vélocité des données. 1.2 En vir onnement informatique A v ant d’aborder le cœur du sujet, l’analyse à proprement parler , de données massi ves, nous introduisons en décriv ant brièvement le panorama de la manière dont les données sont stockées et gérées d’un point de vue informatique. En effet, le contexte technique est étroitement lié aux problèmes posés par l’analyse de données massi ves et donc indispensable pour en appréhender les enjeux. Nous faisons, dans cette présentation, une place particulière à Hadoop , qui est l’un des standards informatiques de la gestion de données massi ves sur lequel nous av ons pris le parti de nous appuyer pour illustrer cet article. Le contexte général de cet article est celui de la distrib ution des ressources informatiques. On parle de système distribué dans le cadre où une collection de postes (ordinateurs ou nœuds) autonomes sont connectés par un réseau. Ce type de fonctionnement permet de partager les capacités de chacun des postes, capacités qui se déclinent en : – partage des ressources de calcul ou calcul distrib ué , parta gé ou parallèle . Il s’agit ici de répartir un calcul (une analyse de données au sens statistique du terme, par exemple) sur un ensemble d’ententités de calcul indépendantes ( cœurs d’un micro-processeur par exemple). Ces entités peuvent être situés sur un même ordinateur ou, dans le cas qui nous préoccupe dans cet ar- ticle, sur plusieurs ordinateurs fonctionnant ensemble au sein d’un cluster de calcul . Cette dernière solution permet d’augmenter les capacités de cal- cul à moindre coût comparé à l’in vestissement que représente l’achat d’un super-calculateur ; – partage des r essour ces de stockage des données . Dans le cadre d’un calcul distribué, on distingue deux celui où la mémoire (où sont stockées les don- nées à analyser) est accédée de la même manière par tous les processeurs (mémoire partagée) et celui où tous les processeurs n’accèdent pas de la même manière à toutes les données (mémoire distribuée). Dans les deux cas, des en vironnements logiciels (c’est-à-dire, des ensemble de programmes) ont été mis en place pour permettre à l’utilisateur de gérer le calcul 1. Google, Apple, Facebook, Amazon 3 et la mémoire comme si il n’av ait à faire qu’à un seul ordinateur : le programme se charge de répartir les calculs et les données. Hadoop est un de ces en vironne- ments : c’est un ensemble de programmes (que nous décrirons plus précisément plus tard dans cet article) programmés en jav a, distribués sous licence libre et destinés à faciliter le déploiement de tâches sur plusieurs milliers de nœuds. En particulier , Hadoop permet de gérer un système de fichiers de données distribués : HDFS (Hadoop Distributed File System) permet de gérer le stockage de très gros volumes de données sur un très grand nombre de machines. Du point de vue de l’utilisateur , la couche d’abstraction fournie par HDFS permet de manipuler les données comme si elles étaient stockées sur un unique ordinateur . Contrairement aux bases de données classiques, HDFS prend en charge des données non struc- turées , c’est-à-dire, des données qui se présentent sous la forme de textes simples comme des fichiers de log par ex emples. L ’av antage de HDFS est que le système gère la localisation des données lors de la répartition des tâches : un nœud donné rece vra la tâche de traiter les données qu’il contient afin de limiter le temps de transfert de données qui peut être rapi- dement prohibitif lorsque l’on trav aille sur un très grand nombre de nœuds. Pour ce faire, une approche classique est d’utiliser une décomposition des opérations de calcul en étapes « Map » et « Reduce » (les détails de l’approche sont donnés plus loin dans le document) qui décomposent les étapes d’un calcul de manière à faire traiter à chaque nœud une petite partie des données indépendamment des traitements ef fectuées sur les autres nœuds. Une fois les données stockées, ou leur flux or ganisé, leur valorisation nécessite une phase d’analyse ( Analytics ). L ’objectif est de tenter de pénétrer cette jungle pour en comprendre les enjeux, y tracer des sentiers suiv ant les options possibles afin d’aider à y faire les bons choix. Le parti est pris d’utiliser , si possible au mieux, les ressources logicielles (langages, librairies) open source existantes en tentant de minimiser les temps de calcul tout en évitant la programmation, souvent re-programmation, de méthodes au code par ailleurs ef ficace. Donc minimiser , certes les temps de calcul, mais également les coûts humains de développement pour réaliser des premiers prototypes d’analyse. La littérature électronique sur le sujet est, elle aussi, massiv e (même si assez redondante) et elle fait émer ger un ensemble de : 1.3 Questions La première part du constat que, beaucoup des exemples traités, notamment ceux des besoins initiaux, se résument principalement à des dénombrements, d’oc- currences de mots, d’événements (décès, retards...) de co-occurences (règles d’as- sociation). Pour ces objectifs, les architectures et algorithmes parallélisés avec MapReduce sont ef ficaces lorsqu’ils traitent l’ensemble des données même si 4 celles-ci sont très v olumineuses. Aussi, pour d’autres objectifs, on s’interroge sur la réelle nécessité, en terme de qualité de prévision d’un modèle, d’estimer celui- ci sur l’ensemble des données plutôt que sur un échantillon représentatif stockable en mémoire. La deuxième est de sa voir à partir de quel volume un en vironnement spécifique de stockage comme Hadoop s’a vère nécessaire. Lorsque les données peuvent être stockés sur un cluster de calcul “classique”, cette solution (qui limite le temps d’accès aux données) est plus ef ficace. T outefois, au delà d’un certain volume, Hadoop est une solution pertinente pour gérer des données très volumineuses ré- parties sur un très grand nombre de machines. Ainsi, av ant de se diriger vers une solution de type Hadoop , il faut se demander si un accroissement de la mémoire physique et/ou l’utilisation d’une librairie (R) simulant un accroissement de la mémoire vi ve ne résoudrait pas le problème du traitement des données sans faire appel à Hadoop : dans beaucoup de situations, ce choix s’avèrera plus judicieux et plus efficace. La bonne démarche est donc d’abord de se demander quelles sont les ressources matérielles et logicielles disponibles et quels sont les algo- rithmes de modélisation disponibles dans l’en vironnement utilisé. On se limitera au choix de Hadoop lorsque celui-ci est imposé par le v olume des données ou bien que Hadoop est l’en vironnement donné a priori comme contrainte à l’analyste de données. Pour une partie de ces questions, les réponses dépendent de l’objectif. S’il semble pertinent en e-commerce de considérer tous les clients potentiels en pre- mière approche, ceci peut se discuter pas-à-pas en fonction du domaine et de l’ob- jectif précis : clustering , score, système de recommandation..., visé. Dans le cas d’un sous-échantillonnage des données, le volume peut dev enir gérable par des programmes plus simples et plus ef ficaces qu’ Hadoop . En conclusion, il est conseillé d’utiliser Hadoop s’il n’est pas possible de faire autrement, c’est-à-dire si : – on a pris le parti de vouloir tout traiter , sans échantillonnage, av ec impossi- bilité d’ajouter plus de mémoire ou si le temps de calcul de vient rédhibitoire av ec de la mémoire virtuelle, – le volume des données est trop important ou les données ne sont pas struc- turées, – la méthodologie à déployer pour atteindre l’objectif se décompose en for- mulation MapReduce , – l’en vironnement Hadoop est imposé, existe déjà ou est facile à faire mettre en place par les personnes compétentes, – un autre en vironnement plus performant n’a pas déjà pris le dessus. 5 1.4 Prépondérance de Hadoop ? Le traitement de grandes masses de données impose une parallélisation des calculs pour obtenir des résultats en temps raisonnable et ce, d’autant plus, lors du traitement en temps réel d’un flux ( str eaming ) de données. Les acteurs majeurs que sont Google, Amazon, Y ahoo, T witter ... développent dans des centres de don- nées ( data centers ) des architectures spécifiques pour stocker à moindre coût de grande masses de données (pages web, listes de requêtes, clients, articles à v endre, messages...) sous forme brute, sans format ni structure relationnelle. Ils alignent, dans de grands hangars, des empilements (conteneurs ou baies) de cartes mère standards de PC “bon marché” 2 , reliées par une connexion réseau (cf. figure 1 ). Hadoop est une des solutions les plus populaires pour gérer des données et des applications sur des milliers de nœuds 3 en utilisant des approches distrib uées. Hadoop est composé de son propre gestionnaire de fichiers (HDFS : Hadoop Dis- tributed File System) qui gère des données sur plusieurs nœuds simultanément en permettant l’abstraction de l’architecture physique de stockage (c’est-à-dire que l’utilisateur n’a l’impression de tra vailler que sur un seul ordinateur alors qu’il manipule des données réparties sur plusieurs nœuds). Hadoop dispose aussi d’al- gorithmes permettant de manipuler et d’analyser ces données de manière paral- lèle, en tenant compte des contraintes spécifiques de cette infrastructure, comme par ex emple MapReduce (Dean et Ghema wat ; 2004)[ 4 ], HBase, ZooKeeper , Hi ve et Pig. Initié par Google, Hadoop est maintenant développé en version libre dans le cadre de la fondation Apache . Le stockage intègre également des propriétés de duplication des données afin d’assurer une tolérance aux pannes. Lorsqu’un trai- tement se distribue en étapes Map et Reduce , celui-ci de vient “échelonnable” ou scalable , c’est-à-dire que son temps de calcul est, en principe, di visé par le nombre de nœuds ou serveurs qui ef fectuent la tâche. Hadoop est diffusé comme logiciel libre et bien qu’écrit en jav a, tout langage de programmation peut l’interroger et exécuter les étapes MapReduce prédéterminées. Comparati vement à d’autres solutions de stockage plus sophistiquées : cube, SGBDR (systèmes de gestion de base de données relationnelles), disposant d’un langage (SQL) comple xe de requêtes, et comparati vement à d’autres architectures informatiques parallèles dans lesquelles les div ers ordinateurs ou processeurs par- 2. La facture énergétique est le poste de dépense le plus important : l’électricité consommée par un serveur sur sa durée de vie coûte plus que le serveur lui-même. D’où l’importance que Google apporte aux question en vironnementales dans sa communication . 3. Un nœud est une unité de calcul, par exemple, pour simplifier , un ordinateur au sein d’un réseau d’ordinateurs. 6 tagent des zones mémoires communes (mémoire partagée), Hadoop est perçu, sur le plan académique, comme une régression. Cette architecture et les fonctionnali- tés très restreintes de MapReduce ne peuvent ri valiser avec des programmes uti- lisant des langages et librairies spécifiques aux machines massiv ement parallèles connectant des centaines, voire milliers, de cœurs sur le même b us. Néanmoins, le poids des acteurs qui utilisent Hadoop et le bon compromis qu’il semble réa- liser entre coûts matériels et performances en font un système dominant pour les applications commerciales qui en découlent : les internautes sont des prospects à qui sont présentés des espaces publicitaires ciblés et vendus en temps réel aux annonceurs dans un système d’enchères automatiques. Hormis les applications du e-commerce qui dépendent du choix préalable, souvent Hadoop , MongoDB ..., de l’architecture choisie pour gérer les données, il est légitime de s’interroger sur le bon choix d’architecture (SGBD classique ou non) de stockage et de manipulation des données en fonction des objectifs à réali- ser . Ce sera notamment le cas dans bien d’autres secteurs : industrie (maintenance préventi ve en aéronautique, prospection pétrolière, usages de pneumatiques...), transports, santé (épidémiologie), climat, énergie (EDF , CEA...)... concernés par le stockage et le traitement de données massi ves. 1.5 Une R-éférence Comme il existe de très nombreux systèmes de gestion de données, il existe de nombreux environnements logiciels open sour ce à l’interface utilisateur plus ou moins amicale et acceptant ou non des fonctions écrites en R ou autre langage de programmation : KNIME , T AN A GRA , W eka ,... Néanmoins, pour tout un tas de raisons dont celle d’un large consensus au sein d’une très grande communauté d’utilisateurs, le logiciel libre R [ 14 ] est une réfé- rence pour l’analyse ou l’apprentissage statistique de données conv entionnelles, comme pour la recherche et le développement, la diffusion de nouvelles méthodes. Le principal problème de R (version de base) est que son exécution nécessite de charger toutes les données en mémoire vi ve. En conséquence, dès que le volume est important, l’exécution se bloque. Aussi, une première façon de procéder av ec R, pour analyser de grandes masses, consiste simplement à extraire une table, un sous-ensemble ou plutôt un échantillon r eprésentatif des données av ec du code jav a, Perl, Python, Ruby ... av ant de les analyser dans R. Une autre solution consiste à utiliser une librairie permettant une extension virtuelle sur disque de la mémoire viv e (ce qui a pour contre-partie d’alourdir les 7 temps d’accès aux données donc les temps de calcul). C’est le rôle des packages ff, bigmemory , mais qui ne gèrent pas la distribution du calcul en parallèle, et également aussi de ceux interfaçant R et Hadoop qui seront plus précisément décrits ci-dessous. Par ailleurs, la richesse des outils graphiques de R ( i.e. ggplot2 ) permettra alors de visualiser de f açon très élaborée les résultats obtenus. T outefois, compter des occurrences de mots, calculer des moyennes... ne nécessitent pas la richesse méthodologique de R qui prendrait beaucoup plus de temps pour des calculs ru- dimentaires. Adler (2010)[ 1 ] compare trois solutions pour dénombrer le nombre de décès par sex e aux USA en 2009 : 15 minutes a vec RHadoop sur un cluster de 4 serveurs, une heure avec un seul serveur , et 15 secondes, toujours sur un seul serveur , mais av ec un programme Perl. Même si le nombre restreint de serveur (4) de l’expérience reste réduit par rapport aux volumes habituels d’ Hadoop , cette e x- périence montre bien qu’utiliser systématiquement RHadoop n’est pas pertinent. En résumé, Hadoop permet à R d’accéder à des gros volumes de données en des temps raisonnables mais il faut rester conscient que, si c’est sans doute la stra- tégie la plus “simple” à mettre en œuvre, ce ne sera pas la solution la plus efficace en temps de calcul en comparaison a vec d’autres en vironnements comme Mahout ou Spark introduits ci-après et qui finalement con vergent vers les fonctionnalités d’un langage matriciel identique à R. Dans le cas contraire, les compétences nécessaires à l’utilisation des méthodes décrites dans les parties Exploration et Apprentissage de wikistat suffisent. Seule la forte imbrication entre structures et v olumes de données, algorithmes de calcul, méthodes de modélisation ou apprentissage, impose de poursuivre la lecture de cet article et l’acquisition des apprentissages qu’il développe. Cet article se propose de décrire rapidement l’écosystème, surtout logiciel, des grandes masses de données a vant d’aborder les algorithmes et méthodes de mo- délisation qui sont employés. L ’objectif est d’apporter des éléments de réponse en conclusion, notamment en terme de formation des étudiants. Les principes des méthodes d’apprentissage ne sont pas rappelés, ils sont décrits sur le site coopé- ratif wikistat . 2 En vironnements logiciels 2.1 Hadoop Hadoop est un projet open sour ce de la fondation Apache dont voici les prin- cipaux mots clefs : 8 HDFS ( hadoop distributed file system ) système de fichiers distrib ués sur un en- semble de disques (un disque par nœud ou serveur) mais manipulés et vus de l’utilisateur comme un seul fichier . Réplication des données sur plusieurs hôtes pour la fiabilité. HDFS est fault tolerant , sans faire appel à des dupli- cations, si un hôte ou un disque a des problèmes. MapReduce est un principe de programmation informatique qui est au cœur de la parallélisation des traitements dans Hadoop et qui comprend deux étapes : map et reduce. Il est décrit plus précisément dans la section 3.3 de ce docu- ment. Hive langage développé par Facebook pour interroger une base Hadoop a vec une syntaxe proche du SQL ( hql ou Hive query langua ge ). Hbase base de données orientée “colonne” et utilisant HDFS. Pig langage développé par Y ahoo similaire dans sa syntaxe à Perl et visant les objectifs de Hive en utilisant le langage pig latin . Sqoop pour (Sq)l to Had(oop) permet le transfert entre bases SQL et Hadoop . Plusieurs distributions Hadoop sont proposées : Apache , Cloudera , Hortonworks à installer de préférence sous Linux (des solutions existent toutefois pour instal- ler Hadoop sous W indo ws). Ces distributions proposent également des machines virtuelles pour faire du Hadoop a vec un nombre de nœuds très limité (un seul par ex emple) et donc au moins tester les scripts en local av ant de les lancer en vraie grandeur . La mise en place d’un tel en vironnement nécessite des compétences qui ne sont pas du tout abordées. Pour un essai sur un système distribué réel, il est possible d’utiliser les services d’A WS ( Amazon W eb Services ) : c’est souv ent cette solution qui est utilisée par les start-up qui prolifèrent dans le e-commerce mais elle ne peut être retenue par une entreprise industrielle pour des contraintes évidentes de confidentialité, contraintes et suspicions qui freinent largement le déploiement de clouds . 2.2 Hadoop streaming Bien qu’ hadoop soit écrit en jav a, il n’est pas imposé d’utiliser ce langage pour analyser les données stockées dans une architecture Hadoop . T out langage de programmation (Python, C, jav a... et même R) manipulant des chaînes de ca- ractères peut servir à écrire les étapes MapReduce pour enchaîner les traitements. Bien que sans doute plus efficace, l’option de traitement en str eaming n’est pour l’instant pas développée dans cet article pour fa voriser celle nécessitant moins de compétences ou de temps de programmation. 9 2.3 Mahout Mahout (Owen et al. 2011)[ 11 ] est également un projet de la fondation Apache. C’est une Collection de méthodes programmées en jav a et destinées au machine learning sur des architectures av ec mémoire distribuée, comme Ha- doop. Depuis a vril 2014, Mahout n’inclut plus dans ses nouveaux développements d’algorithmes conçus pour la méthodologie de programmation Hadoop - MapRe- duce 4 Mahout intègre des programmes pour la recommandation utilisateur , la NMF , la classification non supervisée par k -means, la régression logistique, les forêts aléatoires... La communauté de développeurs se décrit comme dynamique mais des compétences en Jav a sont indispensables pour utiliser les programmes. T outefois, les développements en cours a vec l’abandon de Hadoop et le rap- prochement a vec Spark ci-dessous autour d’un langage matriciel similaire à R ouvre de nouveaux horizons. 2.4 Spark L ’architecture de fichiers distribuée de Hadoop est particulièrement adaptée au stockage et à la parallélisation de tâches élémentaires. La section suiv ante, sur les algorithmes, illustre les fortes contraintes imposées par les fonctionnalités MapReduce pour le déploiement de méthodes d’apprentissage. Dès qu’un algo- rithme est itératif, ( i.e. k -means), chaque itération communique avec la suiv ante par une écriture puis lecture dans la base HDFS. C’est extrêmement contraignant et pénalisant pour les temps d’exécution, car c’est la seule façon de faire com- muniquer les nœuds d’un cluster en dehors des fonctions MapReduce . Les temps d’exécution sont généralement et principalement impactés par la comple xité d’un algorithme et le temps de calcul. A v ec l’architecture Hadoop et un algorithme itératif, ce sont les temps de lecture et écriture qui de viennent très pénalisants. Plusieurs solutions, à l’état de prototypes ( HaLoop , T wister ...), ont été proposées pour résoudre ce problème. Spark semble la plus prometteuse et la plus soutenue par une communauté acti ve. 4. V oir https://mahout.apache.org : “ The Mahout community decided to move its codebase onto modern data pr ocessing systems that offer a richer pr ogramming model and more efficient execution than Hadoop MapReduce . Mahout will therefor e reject new MapReduce algo- rithm implementations fr om now on. W e will howe ver keep our widely used MapReduce algorithms in the codebase and maintain them. ” 10 Spark est dev enu un projet open sour ce de la fondation Apache dans la conti- nuité des trav aux du laboratoire amplab de l’Université Berkle y . L ’objectif est simple mais son application plus comple xe surtout s’il s’agit de préserv er les pro- priétés de tolérance aux pannes. Il s’agit de garder en mémoire les données entre deux itérations des étapes MapReduce . Ceci est fait selon un principe abstrait de mémoire distribuée : Resilient Distributed Datasets (Zaharia et al. 2012)[ 16 ]. Cet en vironnement est accessible en jav a, Scala 5 , Python et bientôt R (librairie SparkR). Il est accompagné d’outils de requêtage (Shark), d’analyse de graphes (GraphX) et d’une bibliothèque en développement (MLbase) de méthodes d’ap- prentissage. L ’objectif af fiché 6 par les communautés Mahout et Spark de la fondation Apache est l’utilisation généralisée d’un langage matriciel de syntaxe identique à celle de R. Ce langage peut manipuler(algèbre linéaire) des objets (scalaires, vecteurs, matrices) en mémoire ainsi que des matrices dont les lignes sont distri- buées sans que l’utilisateur ait à s’en préoccuper . Un optimisateur d’expression se charge de sélectionner les opérateurs physiques à mettre en œuvre pour , par ex emple, multiplier des matrices distribuées ou non. 2.5 Librairies R R parallèle Le traitement de données massi ves oblige à la parallélisation des calculs et de nombreuses solutions sont of fertes dont celles, sans doute les plus efficaces, utilisant des librairies ou extensions spécifiques des langages les plus courants (Fortran, jav a, C...) ou encore la puissance du GPU (Graphics Processing Unit) d’un simple PC. Néanmoins les coûts humains d’écriture, mise au point des pro- grammes d’interface et d’analyse sont à prendre en compte. Aussi, de nombreuses librairies ont été dév eloppées pour permettre d’utiliser au mieux, à partir de R, les capacités d’une architecture (cluster de machines, machine multi-cœurs, GPU) ou d’un en vironnement comme Hadoop . Ces librairies sont listées et décrites sur la page dédiée au High-Performance and Parallel Computing with R [ 14 ] du CRAN ( Comprehensi ve R Archiv e Network ). La consultation régulière de cette page est indispensable car , l’ écosystème R est très mouvant, voire volatile ; des librairies 5. Langage de programmation développé à l’EPFL (Lausanne) et e xécutable dans un environ- nement ja va. C’est un langage fonctionnel adapté à la programmation d’application parallélisable. 6. https ://mahout.apache.org/users/sparkbindings/home.html 11 plus maintenues disparaissent à l’occasion d’une mise à jour de R (elles sont fré- quentes) tandis que d’autres peuvent de venir dominantes. Le parti est ici pris de s’intéresser plus particulièrement aux librairies dédiées simultanément à la parallélisation des calculs et aux données massi ves. Celles permettant de gérer des données hors mémoire viv e comme bigmemory d’une part ou celles spécifiques de parallélisation comme parallel, snow ... d’autre part, (cf. McCallum et W eston ; 2011 )[ 9 ] sont volontairement laissées de côté. R & Hadoop Prajapati (2013)[ 13 ] décrit dif férentes approches d’analyse d’une base Ha- doop à partir de R. Rhipe développée à l’univ ersité Purdue n’est toujours pas une librairie officielle de R et son développement semble en pause depuis fin 2012. HadoopStreaming permet comme son nom l’indique de faire du str eaming hadoop à partir de R ; les programmes sont plus complex es et, même si plus ef ficace, cette solution est momentanément laissée de côté. hive Hadoop InteractiVE est une librairie récente (02-2014), dont il faut suivre le développement, év aluer les facilités, performances. Elle pourrait se sub- stituer aux services de Rhadoop listé ci-dessous. segue est dédiée à l’utilisation des services d’Amazon (A WS) à partir de R. RHadoop Re volution Analytics est une entreprise commerciale qui propose autour de R du support, des services, des modules d’interface (SAS, SPSS, T eradata, W eb, A WS,...) ou d’en vironnement de dév eloppement sous W indo ws, de calcul intensif. Comme produit d’appel, elle soutient le développement de Rhadoop , ensemble de librairies R d’interface a vec Hadoop . Cet ensemble de librairies, développés sous licence libre, comprend : rhdfs pour utiliser les commandes HDFS d’interrogation d’une base Hadoop . rhbase pour utiliser les commandes HBase d’interrogation. rmr2 pour exécuter du MapReduce ; une option permet de tester des scripts (si- muler un cluster) sans hadoop . plyrmr utilise la précédente et introduit des facilités. 12 Certains de ces librairies ne fonctionnent qu’av ec Hadoop installé (contrairement à rmr2 qui dispose de l’option backend="local" pour fonctionner locale- ment, c’est à dire en utilisant la mémoire vi ve comme si il s’agissait d’un système de fichier HDFS) et sont donc dépendantes du package rJava . Quelques res- sources pédagogiques sont disponibles notamment pour installer RHadoop sur une machine virtuelle cloudera . Revolution Analytics promeut les librairies de RHadoop a vec l’argument rece- v able que cette solution conduit à des programmes plus courts, comparati vement à HadoopStreaming, RHipe, hive , donc plus simples et plus rapides à mettre en place mais pas nécessairement plus efficaces en temps de calcul. Une expérimentation en vraie grandeur réalisée par EDF 7 montre des exécutions dix fois plus longues de l’algorithme k -means a vec RHadoop qu’av ec la librairie Ma- hout . SparkR Le site collaboratif de SparkR fournit les premiers éléments pour installer cette librairie. Celle-ci étant très récente (jan vier 2014), il est dif ficile de se faire un point de vue sans e xpérimentation en vraie grandeur . Son installation nécessite celle préalable de Scala , Hadoop et de la librairie rJava . 3 Algorithmes Le développement de cette section suit nécessairement celui des outils dispo- nibles. Elle sera complétée dans les v ersions à venir de cet article et est accompa- gnée par un tuteuriel réalisé a vec RHadoop pour aider le statisticien à s’initier aux arcanes de MapReduce . 3.1 Choix en présence Après av oir considéré le point de vue “logiciel”, cette section s’intéresse aux méthodes programmées ou programmables dans un en vironnement de données massi ves géré principalement par Hadoop . Certains choix sont fait a priori : – Si un autre SGBD est utilisé, par ex emple MySQL , celui-ci est très géné- ralement interfacé a vec R ou un langage de requête permet d’en e xtraire les données utiles. Autrement dit, mis à part les questions de parallélisa- 7. Leeley D. P . dos Santos, Alzennyr G. da Silva, Bruno Jacquin, Marie-Luce Picard, David W orms,Charles Bernard (2012). Massive Smart Meter Data Storage and Processing on top of Hadoop. W orkshop Big Data , Conférence VLDB (V ery Large Data Bases), Istamb ul, T urquie. 13 tion spécifiques à Hadoop (MapReduce), les autres aspects ne posent pas de problèmes. – Les li vres et publications consacrées à Hadoop détaillent surtout des ob- jectifs élémentaires de dénombrement. Comme déjà écrit, ceux-ci ne né- cessitent pas de calculs complex es et donc de programmation qui justifient l’emploi de R. Nous nous focalisons sur les méthodes dites d’apprentissage statistique, supervisées ou non. La principale question est de sav oir comment un algorithme s’articule a vec les fonctionnalités MapReduce afin de passer à l’échelle du v olume. La contrainte est forte, ce passage à l’échelle n’est pas toujours simple ou efficace et en consé- quence l’architecture Hadoop induit une sélection brutale parmi les très nombreux algorithmes d’apprentissage. Se trouvent principalement décrits dans – Mahout : système de recommandation, panier de la ménagère, SVD, k - means, régression logistique, classifieur bayésien naïf, random forest, SVM (séquentiel), – RHadoop : k -means, régression, régression logistique, random forest. – MLbase de Spark : k -means, régression linéaire et logistique, système de recommandation, classifieur bayésien naïf et à venir : NMF , CAR T , random forest. T rois points sont à prendre en compte : la rareté des méthodes d’apprentis- sage dans les librairies et même l’absence de certaines méthodes très connues comparati vement à celles utilisables en R, les grandes dif ficultés quelques fois évoquées mais pas résolues concernant les réglages des paramètres par validation croisée ou bootstrap (complexité des modèles), la possibilité d’estimer un modèle sur un échantillon représentatif. T outes ces raisons rendent indispensable la dis- ponibilité d’une procédure d’échantillonnage simple ou équilibré pour anticiper les problèmes. La plupart des nombreux documents disponibles insistent beaucoup sur l’ins- tallation et l’implémentation des outils, leur programmation, moins sur leurs pro- priétés, “statistiques”. Mahout est développé depuis plus longtemps et les applica- tions présentées, les stratégies développées, sont très fouillées pour des volumes importants de données. En re vanche, programmés en ja va et très peu documentés, il est dif ficile de rentrer dans les algorithmes pour apprécier les choix réalisés. Pro- grammés en R les algorithmes de Rhadoop sont plus abordables pour un béotien qui cherche à s’initier . 3.2 Jeux de données Cette section est à compléter notamment av ec des jeux de données hexago- naux. La politique de l’état et des collecti vités locales d’ouvrir les accès aux don- nées publiques peut y contribuer de même que le site de concours “ data science ” 14 mais rien n’est moins sûr car la CNIL veille, à juste raison, pour rendre im- possible les croisements de fichiers dans l’attente d’une anonymisation efficace (Bras ; 2013)[ 3 ]. Chacun de ceux-ci peut comporter beaucoup de lignes pour fi- nalement très peu de variables ; il sera difficile de trouver et extraire des fichiers consistants. Par ailleurs des sites proposent des jeux de données pour tester et comparer des méthodes d’apprentissage : UCI.edu , mldata.org , mais qui, pour l’essentiel, n’atteignent pas les caractéristiques (v olume) d’une grande datamasse. D’autres sont spécifiques de données volumineuses. – mahout.apache.org proposent un catalogue de ressources dont beaucoup sont textuelles, – kaggle.com propose régulièrement des concours, – kdd.org or ganise la compétition la plus en vue. – hadoopilluminated.com est un li vre en ligne pointant des ensembles de don- nées publiques ou des sites ouverts à de telles données. – ... V oici quelques jeux de données utilisés dans la littérature. – La meilleure prévision (cité par Prajapati ; 2013)[ 13 ] d’enchères de bulldo- zers disponibles sur le site kaggle utilise les forêts aléatoires. – Données publiques de causes de mortalité en 2009 aux USA cité par Adler (2010)[ 1 ], – Statistiques des consultations de W ikipédia . Les données brutes sont libre- ment accessible et déjà prétraitées par le site stats.grok.se que McIver et Bro wnstein (2014)[ 10 ] utilisent pour concurrencer Google dans la prévi- sion des épidémies de grippe mais sans précision de localisation. – à compléter ... 3.3 MapReduce pour les nuls Principe général Lors de la parallélisation “standard” d’un calcul, chacun des nœuds impliqués dans le calcul a accès de manière simple à l’intégralité des données et c’est uni- quement le calcul lui-même qui est distribué (c’est-à-dire découpé) entre les di- verses unités de calcul. La différence lors d’une parallélisation “MapReduce” est que les données sont elles-mêmes distribuées sur des nœuds différents. Le coût d’accession des données est donc prohibitif et le principe de MapReduce consiste essentiellement à imposer qu’un nœud, dans la phase “map”, ne trav aille que sur des données stockées dans un seul cluster pour produire en sortie un ordonance- ment des données qui permet de les répartir de manière efficace sur des nœuds dif férents pour la phase de calcul elle-même (phase “reduce”). 15 The Shuffle 1. At the end of the Map phase, the machines all pool their results. Every key/value pair is assigned to a pile, based on the key. (You don’t supply any code for the shuffle. All of this is taken care of for you, behind the scenes.) ‡ Reduce Phase 1. The cluster machines then switch roles and run the Reduce task on each pile. You supply the code for the Reduce task, which gets the entire pile (that is, all of the key/value pairs for a given key) at once. 2. The Reduce task typically, but not necessarily, emits some output for each pile. Figure 5-1 provides a visual representation of a MapReduce flow. § Consider an input for which each line is a record of format (letter)(number) , and the goal is to find the maximum value of (number) for each (letter) . (The figure only shows letters A, B, and C, but you could imagine this covers all letters A through Z.) Cell (1) depicts the raw input. In cell (2), the MapReduce system feeds each record’s line number and content to the Map process, which decomposes the record into a key (letter) and value (number) . The Shuffle step gathers all of the values for each letter into a common bucket, and feeds each bucket to the Reduce step. In turn, the Reduce step plucks out the maximum value from the bucket. The output is a set of ( letter),(maximum number) pairs. Figure 5-1. MapReduce data flow This may still feel a little abstract. A few examples should help firm this up. Thinking in MapReduce: Some Pseudocode Examples Sometimes the toughest part of using Hadoop is trying to express a problem in Map- Reduce terms. Since the payoff—scalable, parallel processing across a farm of com- modity hardware—is so great, it’s often worth the extra mental muscle to convince a problem to fit the MapReduce model. ‡ Well, you can provide code to influence the shuffle phase, under certain advanced cases. Please refer to Hadoop: The Definitive Guide for details. § A hearty thanks to Tom White for letting us borrow and modify this diagram from his book. Thinking in MapReduce: Some Pseudocode Examples | 61 www.it-ebooks.info F I G U R E 2 – Flots des données dans les étapes MapReduce (Adler ; 2010)[ 1 ]. Les cinq étapes de parallélisation des calculs se déclinent selon le schéma ci- dessous. Selon l’algorithme concerné et l’architecture (nombre de serveurs) uti- lisée, toutes ne sont pas nécessairement exécutées tandis que certaines méthodes nécessitent des itérations du processus jusqu’à con vergence. Les fonctions Map et Reduce sont écrites dans un quelconque langage, par ex emple R. 1. Préparer l’entrée de la phase Map . Chaque serveur lit sa part de la base de données ligne par ligne et construit les paires (clef, valeur) pour produire Map input: list (k1, v1) . 2. Exécuter le programme utilisateur de la fonction Map() pour émettre Map output: list (k2, v2) . 3. Répartir ( shuffle, combine ou tri) la liste précédente vers les nœuds réduc- teurs en groupant les clefs similaires comme entrée d’un même nœud. Pro- duction de Reduce input: (k2, list(v2)) . Il n’y a pas de code à fournir pour cette étape qui est implicitement prise en charge. 4. Pour chaque clef ou chaque pile, un serveur exécute le programme utilisa- teur de la fonction Reduce() . Émission de Reduce output: (k3, v3) . 5. Le nœud maître collecte les sorties et produit, enregistre dans la base, les résultats finaux. Adler (2010)[ 1 ] schématise av ec la figure 2 le flot des données. Exemple trivial Considérons un fichier fictif de format texte où les champs, qui décrivent des appels téléphoniques, sont séparés par des virgules et contiennent, entre autres, les informations sui vantes. {date},{numéro appelant},...,{numéro appelé},...,{durée} Map – reçoit une ligne ou enregistrement du fichier , – utilise un langage de programmation pour extraire la date et la durée, 16 – émet une paire : clef (date) et valeur (durée). Reduce – reçoit une paire : clef (date) et valeur (durée 1 ... durée n ), – programme une boucle qui calcule la somme des durées et le nombre d’appels, – calcule la moyenne, – sort le résultat : (date) et (moyenne, nombre d’appels). Si l’objectif est maintenant de compter le nombre d’appels par jour et par numéro d’appel, la clef de l’étape Map se complique tandis que l’étape Reduce se réduit à un simple comptage. Map – reçoit une ligne ou enregistrement du fichier , – extrait la date et le numéro d’appel, – émet une paire : clef (date, numéro) et valeur (1). Reduce – reçoit une clef : (date, numéro) et valeur (1...1), – boucle qui calcule la somme des valeurs égale au nombre d’appels, – sort le résultat : (date, numéro) et (nombre). T oute l’astuce réside donc dans la façon de gérer les paires (clef, valeur) qui défi- nissent les échanges entre les étapes. Ces paires peuvent contenir des objets com- plex es (vecteurs, matrices, listes). 3.4 Échantillonnage aléatoire simple Des outils de base sont indispensables pour e xtraire un échantillon d’une base Hadoop et re venir à un en vironnement de trav ail classique pour disposer des outils de modélisation, choix et optimisation des modèles. Reservoir Sampling L ’objectif est d’extraire, d’une base de taille N (pas nécessairement connu), un échantillon représentatif de taille n par tirage aléatoire simple en s’assurant que chaque observ ation ait la même probabilité n/ N d’être retenue. Attention, la répartition des observations selon les serveurs peut-être biaisée. La contrainte est celle d’ Hadoop , pas de communication entre les serveurs, et il faut minimiser le temps donc se limiter à une seule lecture de l’ensemble de la base. L ’algorithme dit de r eservoir sampling (V itter ; 1985) tient ces objectifs si l’échantillon retenu tient en mémoire dans un seul nœud. Malheureusement cette méthode est par principe séquentielle et les aménagements pour la paralléliser 17 av ec MapReduce peut poser des problèmes de représentativité de l’échantillon, notamment si les capacités de stockage des nœuds sont déséquilibrées. Requis s : ligne courante de la base (lue ligne à ligne) Requis R : matrice réservoir de n lignes 1: Pour i = 1 À n Fair e 2: Retenir les n premières lignes : R i ← s ( i ) 3: Fin Pour 4: i ← n + 1 5: Répéter 6: T irer un nombre entier j aléatoirement entre 1 et i (inclus) 7: Si j ≤ n Alors 8: R i ← s ( i ) 9: Fin Si 10: i ← i + 1 11: Jusqu’à toutes les observations ont été lues ( ⇔ i est la taille de s ) La phase Map est triviale tandis que celle Reduce, tire un entier aléatoire et assure le remplacement conditionnel dans la partie “valeur” de la sortie. Les clefs sont sans importance. V itter (1985)[ 15 ] montre que cet algorithme conçu pour échantillonner sur une bande magnétique assure le tirage avec équiprobabilité. Des v ariantes : pondérées, équilibrées, stratifiées, e xistent mais celle échelonnable pour Hadoop pose des problèmes si les donnéees sont mal réparties sur les nœuds. Par tri de l’échantillon Le principe de l’algorithme est très élémentaire ; N nombres aléatoires uni- formes sur [0 , 1] sont tirés et associés : une clef à chaque observ ation ou valeur . Les paires (clef, observation) sont triées selon cette clef et les n premières ou n dernières sont retenues. L ’étape Map est facilement définie de même que l’étape Reduce de sélection mais l’étape intermédiaire de tri peut être très lourde car elle porte sur toute la base. ScanSRS Xiangrui (2013)[ 8 ] propose de mixer les deux principes en sélectionnant un sous-ensemble des observations les plus raisonnablement probables pour réduire le volume de tri. L ’inégalité de Bernstein est utilisée pour retenir ou non des ob- serv ations dans un réservoir de taille en 0( n ) car nécessairement plus grand que dans l’ex emple précédent ; observations qui sont ensuite triées sur leur clef av ant de ne conserv er que les n plus petites clefs. Un paramètre règle le risque de ne pas obtenir au moins n observ ations tout en contrôlant la taille du réservoir . 18 3.5 F actorisation d’une matrice T ous les domaines de datamasse produisent, entre autres, de très grandes ma- trices creuses : clients réalisant des achats, notant des films, relevés de capteurs sur des avions, voitures, te xtes et occurrences de mots... objets avec des capteurs, des gènes av ec des e xpressions. Alors que ces méthodes sont beaucoup utilisés en e-commerce, les acteurs se montrent discrets sur leurs usages et les codes exécu- tés, de même que la fondation Apache sur la NMF . Heureusement, la recherche en biologie sur fonds publics permet d’y remédier . SVD Les algorithmes de décomposition en v aleurs singulières ( SVD ) d’une grande matrice creuse, sont connus de longue date mais exécutés sur des machines massi- vement parallèles de calcul intensif pour la résolution de grands systèmes linéaires en analyse numérique. Leur adaptation au cadre MapReduce et leur application à l’ analyse en composantes principales ou l’ analyse des correspondances , ne peut se faire de la même façon et conduit à d’autres algorithmes. Mahout propose deux implémentations MapReduce de la SVD et une autre version basée sur un algorithme stochastique. En juin 2014, RHadoop ne propose pas encore d’algorithme, ni Spark . NMF La factorisation de matrices non négativ es (Paatero et T apper ; 1994[ 12 ], Lee et Seung ; 1999[ 6 ]) est plus récente. Sûrement très utilisée par les entreprises com- merciales, elle n’est cependant pas implémentée dans les librairies ouvertes ( RHa- doop, Mahout ) basées sur Hadoop . Il existe une librairie R ( NMF ) qui exécute au choix plusieurs algorithmes selon deux critères possibles de la factorisation non négati ve et utilisant les fonctionnalités de parallélisation d’une machine (multi cœurs) grâce à la librairie parallel de R. Elle n’est pas interfacée a vec Hadoop alors que celle plus rudimentaire dév eloppée en jav a par Ruiqi et al. (2014)[ 7 ] est associée à Hadoop . 3.6 k -means L ’algorithme k -means et d’autres de classification non supervisée sont adap- tés à Hadoop dans la plupart des librairies. Le principe des algorithmes utilisés consiste à itérer un nombre de fois fixé a priori ou jusqu’à con ver gence les étapes Map-Reduce . Le principal problème lors de l’exécution est que chaque itération 19 prov oque une réécriture des données pour ensuite les relire pour l’itération sui- v ante. C’est une contrainte imposée par les fonctionnalités MapReduce de Ha- doop (à l’exception de Spark ) pour toute exécution d’un algorithme itératif qui évidemment pénalise fortement le temps de calcul. Bien entendu, le choix de la fonction qui calcule la distance entre une matrice de k centres et une matrice d’individus est fondamental. 1. L ’étape Map utilise cette fonction pour calculer un paquet de distances et re- tourner le centre le plus proche de chaque individu. Les indi vidus sont bien stockés dans la base HDFS alors que les centres, initialisés aléatoirement restent en mémoire. 2. Pour chaque clef désignant un groupe, l’étape Reduce calcule les nouv eaux barycentres, moyennes des colonnes des indi vidus partageant la même classe / clef. 3. Un programme global exécute une boucle qui itère les étapes MapReduce en lisant / écri v ant (sauf pour Spark ) à chaque itération les indi vidus dans la base et remettant à jour les centres. 3.7 Régr ession linéair e Est-il pertinent ou réellement utile, en terme de qualité de prévision, d’estimer un modèle de régression sur un échantillon de très grande taille alors que les prin- cipales dif ficultés sont généralement soulevées par les questions de sélection de v ariables, sélection de modèle. De plus, les fonctionnalités offertes sont très limi- tées, sans aucune aide au diagnostic. Néanmoins, la façon d’estimer un modèle de régression illustre une autre façon d’utiliser les fonctionnalités MapReduce pour calculer notamment des produits matriciels. Soit X la matrice ( n × ( p + 1)) ( design matrix ) contenant en première co- lonne des 1 et les observations des p variables explicati ves quantitativ es sur les n observ ations ; y le vecteur des observ ations de la variable à e xpliquer . On considère n trop grand pour que la matrice X soit chargée en mémoire mais p pas trop grand pour que le produit X 0 X le soit. Pour estimer le modèle y = X β + ε , l’algorithme combine deux étapes de MapReduce afin de calculer chaque produit matriciel X 0 X et X 0 y . Ensuite, un appel à la fonction solve de R résout les équations normales X 0 X = X 0 y et fournit les estimations des paramètres β j . 20 Le produit matriciel est décomposé en la somme (étape Reduce) de la liste des matrices issues des produits (étape Map) X 0 i X j ( i, j = 1 , ..., p ) (ces produits sont calculés pour des sous-ensembles petits de données puis sommés). 3.8 Régr ession logistique Les mêmes réserv es que ci-dessus sont f aites pour la régression logistique qui est obtenue par un algorithme de descente du gradient arrêté après un nombre fixe d’itérations et dont chacune est une étape MapReduce . L ’étape Map calcule la contribution de chaque individu au gradient puis l’écrit dans la base, l’étape Reduce est une somme pondérée. Chaque itération prov oque donc n lectures et n écritures dans la base. Des améliorations pourraient être apportées : adopter un critère de con ver- gence pour arrêter l’algorithme plutôt que fixer le nombre d’itérations, utilisé un gradient conjugué. La faiblesse de l’algorithme reste le nombre d’entrées/sorties à chaque itération. 3.9 Random f orest Random Forest , cas particulier de bagging , s’adapte particulièrement bien à l’en vironnement d’ Hadoop lorsqu’une grande taille de l’ensemble d’apprentis- sage fournit des échantillons indépendants pour estimer et agréger (moyenner) des ensembles de modèles. Comme en plus, random for est semble insensible au sur-apprentissage, cette méthode ne nécessite généralement pas de gros ef forts d’optimisation de paramètres, elle évite donc l’un des principaux écueils des ap- proches Big Data en apprentissage. Principe Soit n la taille totale (grande) de l’échantillon d’apprentissage, m le nombre d’arbres ou modèles de la forêt et k la taille de chaque échantillon sur lequel est estimé un modèle. Les paramètres m et k , ainsi que mtry (le nombre de v ariables aléatoirement sélectionnées parmi les variables initiales pour définir un nœud dans chacun des arbres) sont en principe à optimiser mais si n est grand, on peut espérer qu’ils auront peu d’influence. Il y a en principe trois cas à considérer en fonction de la taille de n . – k × m < n toutes les données ne sont pas utilisées et des échantillons indépendants sont obtenus par tirage aléatoire sans remise, – k × m = n des échantillons indépendants sont exactement obtenus par tirages sans remise, 21 – k × m > n correspond à une situation où un ré-échantillonnage avec remise est nécessaire ; k = n correspond à la situation classique du bootstrap . L ’astuce de Uri Laserson est de traiter dans un même cadre les trois situations en considérant des tirages selon des lois de Poisson pour approcher celui multinomial correspondant au bootstrap. L ’idée consiste donc à tirer indépendamment pour chaque observ ation selon une loi de Poisson. Échantillonnage L ’objectif est d’éviter plusieurs lectures, m , de l’ensemble des données pour réaliser m tirages av ec remise et également le tirage selon une multinomiale qui nécessite des échanges de messages, impossible dans Hadoop , entre serveurs. Le principe de l’approximation est le sui vant : pour chaque observation x i ( i = 1 , .., n ) tirer m fois selon une loi de Poisson de paramètre ( k /n ) , une valeur p i,j pour chaque modèle M j ( j = 1 , ..., m ) (correspondant à l’arbre j dans le cadre des forêts aléatoires) qui correspond à l’arbre j . L ’étape Map est ainsi constituée : elle émet un total de p i,j fois la paire (clef, valeur) ( j, x i ) ; p i,j pouv ant être 0. Même si les observ ations ne sont pas aléatoirement réparties selon les serveurs, ce tirage garantit l’obtention de m échantillons aléatoires dont la taille est approximati ve- ment k . D’autre part, approximati vement exp( − k m/n ) des données initiales ne seront présentes dans aucun des échantillons. L ’étape de tri ou shuffle redistribue les échantillons identifiés par leur clef à chaque serv eur qui estime un arbres (ou plusieurs successiv ement). Ces arbres sont stockés pour constituer la forêt nécessaire à la prévision. Cette approche, citée par Prajapati (2010)[ 13 ], est testée sur les enchères de bulldozer de Kaggle par Uri Laserson qui en dév eloppe le code. Conclusion Quelques remarques pour conclure ce tour d’horizon des outils permettant d’exécuter des méthodes d’apprentissage supervisé ou non sur des données v olu- mineuses. – Cet aperçu est un instantané à une date donnée, qui va évoluer rapidement en fonction des développements du secteur et donc des en vironnements, notamment ceux Mahout et Spark à suivre attentiv ement. C’est l’av antage d’un support de cours électronique car adaptable en temps réel. – L ’apport pédagogique important et dif ficile concerne la bonne connaissance des méthodes de modélisation, de leurs propriétés, de leurs limites. Pour cet objectif, R reste un outil à privilégier . Largement interfacé a vec tous les 22 systèmes de gestion de données massi ves ou non, il est également utilisé en situation “industrielle”. – Une remarque fondamentale concerne le réglage ou l’optimisation des pa- ramètres des méthodes d’apprentissage : nombre de classes, sélection de v ariables, paramètre de complexité. Ces problèmes, qui sont de réelles dif- ficultés pour les méthodes en question et qui occupent beaucoup les équipes trav aillant en apprentissage (machine et/ou statistique), sont largement pas- sés sous silence. Que de viennent les procédures de validation croisée, boots- trap , les échantillons de v alidation et test, bref toute la réflexion sur l’opti- misation des modèles pour s’assurer de leur précision et donc de leur vali- dité ? – Si R, éventuellement précédé d’une phase d’échantillonnage (C, jav a, py- thon, perl) n’est plus adapté au volume et – Si RHadoop s’avère trop lent, – Mahout et Spark sont à tester car semble-t-il nettement plus efficaces. Un apprentissage élémentaire de jav a, s’avère donc fort utile pour répondre à cet objectif à moins que la mise en exploitation du langage matriciel pro- gresse rapidement. – Si ce n’est toujours pas suf fisant, notamment pour prendre en compte les composantes V ariété et Vélocité du Big Data , les compétences acquises per - mettent au moins la réalisation de prototypes av ant de réaliser ou faire réa- liser des dév eloppements logiciels plus conséquents. Néanmoins le passage à l’échelle est plus probant si les prototypes anticipent la parallélisation en utilisant les bons langages comme scala ou clojure . Ce rapide descriptif technique des outils d’analyse de la datamasse n’aborde pas les très nombreuses implications sociétales largement traitées par les médias “grand public” qui alimente une large confusion dans les objectifs poursuivis, par ex emple entre les deux ci-dessous. – Le premier est d’ordre “clinique” ou d’“enquête de police”. Si une informa- tion est présente dans les données, sur le web, les algorithmes d’exploration exhaustifs v ont la trouver ; c’est la NSA dans la La Menace F antôme . – Le deuxième est “prédictif ”. Apprendre des comportements, des occur - rences d’évènements pour prévoir ceux à venir ; c’est GAF A dans L ’Empir e Contr e Attaque . Il faut ensuite distinguer entre : – prévoir un comportement moyen, une tendance moyenne, comme celle souvent citée de l’év olution d’une épidémie de grippe ou encore de v entes de jeux vidéos, chansons, films... (Goel et al., 2010)[ 5 ] à partir des fré- quences des mots clefs associés recherchés sur Google et – prévoir un comportement individuel, si M. Martin habitant telle adresse v a ou non attraper la grippe, acheter tel film ! 23 Il est naïf de penser que l’efficacité obtenue pour l’atteinte du premier objectif peut se reporter sur le deuxième pour la seule raison que “toutes” les données sont traitées. La fouille de données ( data mining ), et depuis plus longtemps la Statis- tique, poursuiv ent l’objectif de prévision av ec des taux de réussite, ou d’erreur , qui atteignent nécessairement des limites que ce soit av ec 1000, 10 000 ou 10 millions... d’observ ations. L ’estimation d’une moyenne, d’une variance, du taux d’erreur , s’affinent et con vergent vers la “vraie” valeur (loi des grands nombres), mais l’erreur d’une prévision individuelle , et son taux reste inhérents à une varia- bilité intrinsèque et irréductible, comme celle du vi vant. Le Retour du J edi est, ou sera, celui du hasard ou celui du libr e arbitr e . En résumé : Back to the Futur et Star W ar , mais pas Mino- rity Report . En rev anche et de façon positi ve, l’accumulation de données d’origines dif fé- rentes, sous contrôle de la CNIL et sous réserve d’une anonymisation rigoureuse empêchant une ré-identification (Bras ; 2013)[ 3 ], permet d’étendre le deuxième objectif de prévision à bien d’autres champs d’application que ceux commer - ciaux ; par e xemple en santé publique, si le choix politique en est fait et les données publiques ef ficacement protégées. Le domaine de l’assurance 8 illustre bien les enjeux, bénéfices et risques po- tentiels associés au traitement des données massiv es. La fouille de données est déjà largement utilisée depuis la fin du siècle dernier pour cibler la communica- tion aux clients mais comment la réglementation va ou doit évoluer si ces masses d’informations (habitudes alimentaires, localisation géographiques, génome, po- domètre et usages sportifs, réseaux sociaux...) de viennent utilisables pour segmen- ter et adapter la tarification des contrats, autos, vie, complémentaires de santé ou lors de prêts immobiliers. L ’ assurance ou la mutualisation des risques repose sur un principe d’ asymétrie d’information . Si celle-ci est in versée au profit de l’assu- reur , par ex emple si GAF A propose des contrats, ce serait à l’encontre de toute idée de mutualisation des risques. Référ ences [1] Joseph Adler, R in a nutshell , O’Reilly, 2010. 8. Lire à ce propos un résumé des interventions (P . Thourot et F . Ewald, Revue Banque , N°315, juin 2013) ou les actes d’un colloque : Big Data Défis et Opportunités pour les Assureurs. 24 [2] Philippe Besse, Aurélien Garivier et Jean Michel Loubes, Big Data Analytics - Retour vers le Futur 3 ; De Statisticien à Data Scientist , http://hal. archives- ouvertes.fr/hal- 00959267 , 2014. [3] Pierre Louis Bras, Rapport sur la gouvernance et l’utilisation des don- nées de santé , http://www.social- sante.gouv.fr/IMG/pdf/ Rapport_donnees_de_sante_2013.pdf , 2013. [4] Jeffre y Dean et Sanjay Ghemawat, MapReduce : Simplified Data Pr ocessing on Lar ge Clusters , Proceedings of the 6th Conference on Symposium on Opearting Systems Design & Implementation - V olume 6, OSDI’04, 2004. [5] Sharad Goel, Jake M. Hofman, Sébastien Lahaie, Da vid M. Pennock et Dun- can J. W atts, Pr edicting consumer behavior with W eb sear ch , Proceedings of the National Academy of Sciences (2010). [6] D. Lee et S. Seung, Learning the parts of objects by non-negative matrix factorization , Nature (1999). [7] Ruiqi Liao, Y ifan Zhang, Jihong Guan et Shuigeng Zhou, CloudNMF : A MapReduce Implementation of Nonne gative Matrix F actorization for Lar ge-scale Biological Datasets , Genomics, Proteomics & Bioinformatics 12 (2014), n o 1, 48 – 51. [8] Xiangrui M., Scalable Simple Random Sampling and Statified Sampling , Proceedings of the 30th International Conference on Machine Learning, 2013. [9] E. McCallum et S. W eston, P ar allel R , O’Reilly Media, 2011. [10] David McIv er et John Brownstein, W ikipedia Usage Estimates Pr evalence of Influenza-Like Illness in the United States in Near Real-T ime , PLoS Comput Biol 10 (2014), n o 4, http://dx.doi.org/10.1371%2Fjournal. pcbi.1003581 . [11] Sean Owen, Robin Anil, T ed Dunning et Ellen Friedman, Mahout in Action , Manning Publications Co., 2011. [12] Pentti Paatero et Unto T apper , P ositive matrix factorization : A non-ne gative factor model with optimal utilization of err or estimates of data values , En vi- ronmetrics 5 (1994), n o 2, 111–126. [13] V ignesh Prajapati, Big Data Analytics with R and Hadoop , Packt Publishing, 2013. [14] R Core T eam, R : A Langua ge and En vir onment for Statistical Computing , R Foundation for Statistical Computing, 2014, http://www.R- project. org/ . [15] V itter J. S., Random sampling with a r eservoir , A CM transaction on Mathe- matical Software 11 :1 (1985), 37–57. 25 [16] Matei Zaharia, Mosharaf Cho wdhury , T athagata Das, Ankur Dav e, Justin Ma, Murphy McCauly , Michael J. Franklin, Scott Shenker et Ion Stoica, Resilient Distributed Datasets : A F ault-T olerant Abstraction for In-Memory Cluster Computing , Presented as part of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12) (San Jose, CA), USENIX, 2012, p. 15–28, ISBN 978-931971-92-8, https://www. usenix.org/conference/nsdi12/technical- sessions/ presentation/zaharia . 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment