빅데이터 시대 통계학자의 기술 전환
본 논문은 통계학자가 대용량 데이터(볼륨) 환경에 적응하기 위해 필요로 하는 기술·지식 체계를 정리하고, Hadoop 기반 Map‑Reduce 구조에 맞게 기존 통계·머신러닝 알고리즘을 재구성하는 방법을 제시한다.
저자: Philippe Besse (IMT), Nathalie Villa-Vialaneix (MIAT INRA)
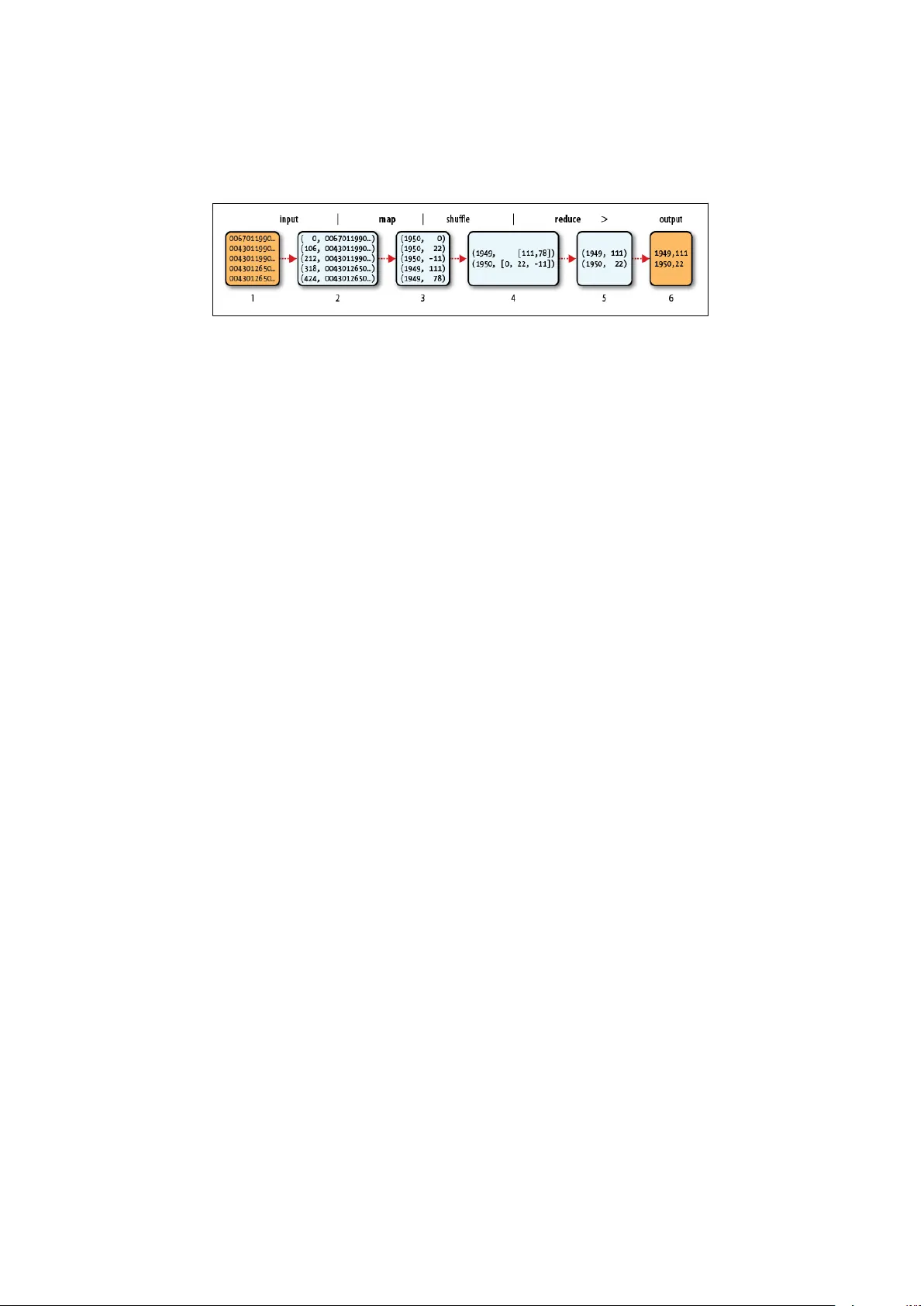
이 논문은 “볼륨” 규모의 빅데이터를 다루기 위해 통계학자가 습득해야 할 기술·지식 체계를 체계적으로 정리한다. 서론에서는 빅데이터의 3V(Volume, Variety, Velocity)를 소개하고, 특히 데이터 양이 급증하면서 전통적인 통계 분석 도구가 메모리 한계에 부딪히는 문제를 제기한다. 저자는 통계학자가 데이터 과학자·머신러닝 엔지니어로 전환하기 위해서는 분산 저장·연산 환경에 대한 이해가 필수적이라고 강조한다.
본 논문의 핵심은 Hadoop 생태계와 Map‑Reduce 패러다임을 중심으로 기존 통계·머신러닝 알고리즘을 어떻게 재구성할 수 있는지를 상세히 설명한다. 먼저 Hadoop의 핵심 구성요소인 HDFS와 Map‑Reduce 모델을 소개한다. HDFS는 데이터를 여러 노드에 복제·분산 저장함으로써 데이터 로컬리티를 확보하고, Map‑Reduce는 계산을 “Map” 단계에서 데이터 파티션별로 독립적으로 수행하고, “Reduce” 단계에서 결과를 집계하는 방식으로 확장성을 제공한다.
다음으로 비지도 학습 알고리즘을 다룬다. k‑means 클러스터링은 각 파티션에서 거리 계산과 클러스터 할당을 수행한 뒤, Reduce 단계에서 클러스터 중심을 재계산한다. 이 과정을 반복하면서 전역 수렴을 확인한다. NMF와 SVD와 같은 행렬 분해 기법은 행렬을 블록으로 나누어 블록별 특이값·특이벡터를 계산하고, Reduce 단계에서 블록 결과를 합쳐 전체 특이값을 추정한다. 이러한 접근은 대규모 행렬 연산을 메모리 제한 없이 수행할 수 있게 한다.
지도 학습 부분에서는 회귀, CART, Random Forest를 Map‑Reduce에 맞게 변형한다. 회귀 분석은 파티션별로 충분통계량(합, 제곱합, 교차항 등)을 구하고, Reduce 단계에서 전역 통계량을 합산해 최소제곱 해를 도출한다. CART는 각 파티션에서 후보 분할점을 평가하고, 전역 최적 분할을 선택하기 위해 Reduce 단계에서 정보이득을 집계한다. Random Forest는 트리마다 독립적인 학습이 가능하므로, 각 트리를 별도의 Map 작업으로 수행하고, 최종 모델을 Reduce 단계에서 통합한다.
알고리즘 재구성 외에도 실무에서 활용 가능한 도구와 라이브러리를 비교한다. R은 풍부한 통계 함수와 시각화 도구를 제공하지만 메모리 내 연산에 제한이 있다. 이를 보완하기 위해 RHadoop, SparkR, sparklyr와 같은 R‑Hadoop 인터페이스가 제안된다. Java/Scala 기반 Mahout와 Spark는 원시 Map‑Reduce보다 고수준 API를 제공해 반복 연산과 인메모리 연산을 효율적으로 수행한다. 특히 Spark는 RDD와 DataFrame을 이용해 메모리 내 캐시를 지원함으로써 반복적인 머신러닝 작업에서 큰 성능 향상을 보인다.
논문은 또한 교육적 함의를 제시한다. 통계학자는 데이터베이스(SQL, NoSQL), 분산 파일 시스템(HDFS), 클라우드 서비스(AWS EMR, Google Cloud Dataproc) 등에 대한 기본 이해를 갖추어야 하며, 프로그래밍 언어(Java, Scala, Python)와 병렬·분산 알고리즘 설계 원칙을 학습해야 한다. 이러한 멀티디스플리너리 역량이 없으면 빅데이터 환경에서 기존 통계 방법을 그대로 적용하기 어렵다.
결론에서는 빅데이터 분석을 위한 최적의 전략을 제시한다. 데이터 규모가 메모리 한계를 초과하고, 데이터가 비정형이거나 실시간 스트리밍이 요구될 경우 Hadoop·Spark와 같은 분산 플랫폼을 선택한다. 반면, 데이터가 충분히 작은 경우에는 기존 R·Python 환경에서 샘플링·서브셋 추출을 통해 분석하는 것이 비용 효율적이다. 또한, 알고리즘 선택 시 Map‑Reduce에 적합한 구조(단계별 독립 연산, 최소 데이터 이동)를 우선 고려하고, 필요 시 파라미터 서버·집계 메커니즘을 도입해 병목을 최소화한다. 최종적으로 저자는 통계학자가 빅데이터 시대에 살아남기 위해서는 통계 이론과 동시에 시스템 엔지니어링, 클라우드 컴퓨팅, 최신 프로그래밍 기술을 통합적으로 학습해야 한다고 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기