Further heuristics for $k$-means: The merge-and-split heuristic and the $(k,l)$-means
Finding the optimal $k$-means clustering is NP-hard in general and many heuristics have been designed for minimizing monotonically the $k$-means objective. We first show how to extend Lloyd's batched relocation heuristic and Hartigan's single-point r…
Authors: Frank Nielsen, Richard Nock
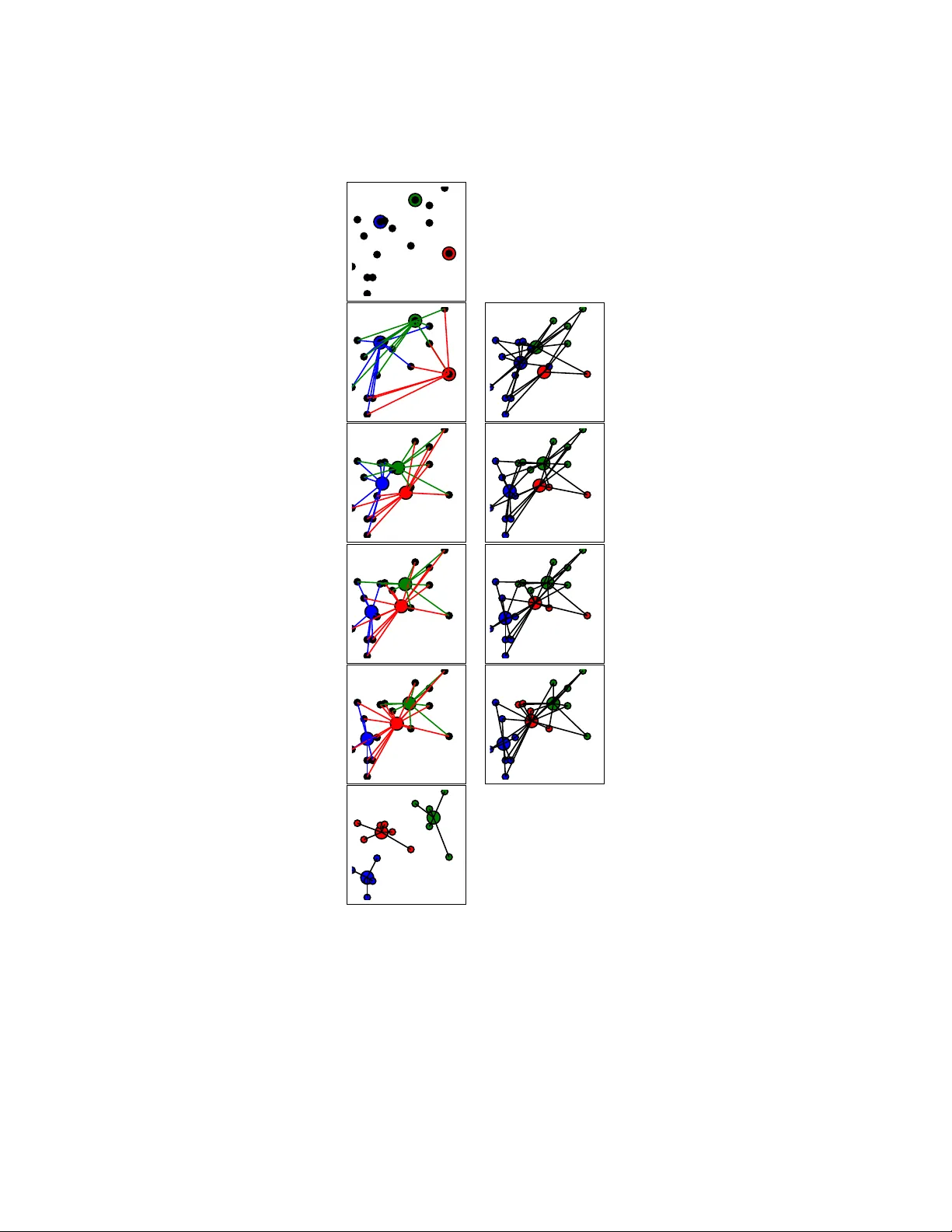
F urther heuristics for k -means: The merge-and-split heuristic and the ( k , l )-means F rank Nielsen Son y Computer Science Lab oratories, Japan ´ Ecole P olytec hnique, F rance Frank.Nielsen@acm.org Ric hard No c k NICT A, Australia Richard.Nock@nicta.com.au Abstract The k -means clustering problem asks to partition the data in to k clusters so as to minimize the sum of the squared Euclidean distances of the data p oin ts to their closest cluster center. Finding the optimal k -means clustering of a d -dimensional data set is NP-hard in general and man y heuristics hav e b een designed for minimizing monotonically the k -means ob jectiv e func- tion. Those heuristics got trapp ed into lo cal minima and thus hea vily dep end on the initial seeding of the cluster cen ters. The celebrated k -means++ algorithm is suc h a randomized seed- ing method which guarantees probabilistically a go o d initialization with resp ect to the global minim um. In this pap er, we first sho w how to extend Llo yd’s batc hed relocation heuristic and Hartigan’s single-p oint relo cation heuristic to take into accoun t empt y-cluster and single-p oint cluster even ts, resp ectively . Those even ts tend to increasingly o ccur when k or d increases, or when p erforming several restarts of the k -means heuristic with a different seeding at each round in order to k eep the b est clustering in the lot. W e show that those sp ecial even ts are a blessing b ecause they allo w to partially re-seed some cluster centers while further minimizing the k -means ob jective function. Second, we describ e a nov el heuristic, called merge-and-split k -means, that consists in merging t w o clusters and splitting this merged cluster again with tw o new centers provided it improv es the k -means ob jectiv e. Hartigan’s heuristic can improv e a Llo yd’s heuristic when it reac hes a lo cal minimum, and similarly this no v el heuristic can im- pro ve Hartigan’s k -means when it has conv erged to a lo cal minimum. W e show empirically that this merge-and-split k -means improv es o v er the Hartigan’s heuristic which is the de facto metho d of c hoice. Finally , w e prop ose the ( k , l )-means ob jective that generalizes the k -means ob jectiv e by associating the data p oints to their l closest cluster centers, and show ho w to either directly conv ert or iteratively relax the ( k, l )-means in to a k -means in order to reach better lo cal minima. 1 In tro duction Clustering is the task that consists in grouping data into homogeneous clusters with the goal that intra-cluster data should b e more similar than in ter-cluster data. Let P = { p 1 , ..., p n } b e a set of n points 1 in R d . Let C 1 , ..., C k b e the k non-empty clusters partitioning P and denote b y 1 F or the sak e of clarity and without loss of generality , we do not consider weigh ted p oin ts. 1 K = { c 1 , ..., c k } the set of k cluster cen ters, the cluster pr ototyp es . k -Means is one of the oldest and y et prev alent clustering technique that consists in minimizing: e ( P , K ) = n X i =1 k min j =1 D ( p i , c j ) = n X i =1 D ( p i , c l i ) = k X j =1 X p ∈K j D ( p, c j ) , (1) where D ( p, q ) = k p − q k 2 denotes the squar e d Euclidean distance, and l i the index (or lab el) of the center of K that is the closest nearest neigh b or to p i (sa y , in case of ties, choose the minimum in teger). Finding an optimal clustering minimizing globally min K e ( P , K ) is NP-hard when d > 1 and k > 1 [21, 8], and p olynomial when d = 1 using dynamic programming [4] or when k = 1 setting c to the cen ter of mass. Note that there is an exp onential numb er of optimal k -means clustering yielding the same optimal ob jective function: Indeed, consider an equilateral triangle with n = 3 and k = 2, w e th us get 3 equiv alent optimal clustering related b y rotational symmetries. Then mak e s far a w a y separated copies so that n = 3 s and consider k = 2 s , we end up with 3 s = 3 n 2 optimal k -means clustering. Minimizing the k -means function of Eq. 1 is equiv alen t to minimizing the sum of in tra-cluster squared distances or maximizing the sum of in ter-cluster squared distances: min K e ( P , K ) ≡ min K k X j =1 X p i ,p j ∈C j k p i − p j k 2 ≡ max K k X j =1 X p i ∈C j ,p j 6∈C j k p i − p j k 2 (2) Man y heuristics hav e b een prop osed to ov ercome the NP-hardness of k -means. They can b e classified into t w o main groups: The lo c al se ar ch heuristics and the glob al heuristics that can b e used to initialize the lo cal heuristics. F or example, the follo wing four heuristics are classically 2 implemen ted: • F orgy [10] (random): Dra w uniformly at random k p oin ts from P to set the cluster pro- tot yp es K inducing the partition. It can b e prov ed that this b est discr ete k -means (with K ⊂ P ) yields a 2-appro ximation factor compared to the ordinary k -means using a pro of by con tradiction based on the varianc e-bias de c omp osition : e ( P , c 0 ) = v ( P ) + n k c 0 − c k 2 , where v ( X ) = P n i =1 k p i − c k 2 = P n i =1 k p i k 2 − n k c k 2 denotes the v ariance and c = 1 n P n i =1 p i the cen troid. In fact, e ( P , K ) = P k j =1 v ( C j ), the sum of in tra-cluster v ariances (and e ( P , K ) = P n i =1 k p i k 2 − P k j =1 n j k c j k 2 ). • MacQueen [20] (online): F rom a giv en initialization of the k centers defining singleton clusters (sa y , C j = { p j } for the k clusters), we add a new p oint at a time to the cluster that contains the closest cen ter, up date that cluster centroid, and reiterate un til con vergence. This heuristic is also called the online or single-p oin t k -means [11]. • Llo yd [19] (batched): F rom a given initialization of cluster prototypes, (1) assign p oints to their closest cluster, (2) relo cate cluster centers to their cluster centroids, and reiterate those t w o steps until con vergence. • Hartigan [12, 13] (single-p oint relo cation): F rom a given initialization, find ho w to mo v e a p oin t from a cluster to another cluster so that the k -means cost of Eq. 1 strictly decreases and reiterate those single-p oint relo cations un til con vergence is reached. Note that a p oint ma yb e assigned to a cluster whic h cen ter is not its closest cen ter [24]. 2 See for example the R language for statistical computing, http://www.r- project.org/ 2 In general, a k -means clustering tec hnique partitions the data in to pairwise non-o v erlapping con v ex hulls CH( C 1 ) , ..., CH( C k ): The V or onoi p artition . A partition is said stable when a lo cal impro v emen t of the heuristic cannot improv e its k -means score. Let P F,Q,L,H ( n, k ) denotes the maxim um num b er of stable k -means partitions obtained b y F orgy’s, MacQueen’s, Lloyd’s and Hartigan’s schemes, resp ectively . F act 1 (V oronoi partitions) We have P F ( n, k ) ≤ n k and P H ( n, k ) ≤ P L ( n, k ) ≤ P CH ( n, k ) << P ( n, k ) , wher e P ( n, k ) = 1 k ! P k i =0 ( − 1) k − i k i i n denotes the numb er of p artitions of n elements into k non-empty subsets (that is, the Stirling numb ers of the se c ond kind) and P CH ( n, k ) denotes the numb er of p artitions with non-overlapping (and non-empty) c onvex hul ls (that is, the numb er of k -V or onoi p artitions). Hartigan’s single-p oin t relo cation heuristic ma y improv ed Lloyd’s clustering but not the con- v erse [23]. Note that Llo yd’s heuristic ma y require an exp onential n um b er of iterations to con- v erge [25]. It is an op en question [24] to b ound the maximum num b er of Hartigan’s iterations. On one hand, for those local heuristics performing pivots on V oronoi partitions using primitives, initialization (i.e., the initial V oronoi partition) is crucial [7] to obtain a go o d clustering, and several restarts, denoted b y mstart, are p erformed in practice to choose the b est clustering. In practice, F orgy’s initialization has b een replaced by k -means++ [2] which pro vides an exp e cte d ¯ O (log k ) comp etitiv e initialization. Ho w ev er, it was shown that there exits p oin t sets (ev en in 2D) for whic h the probabilit y to get such a go o d initialization is exp onentially lo w [6] (and thus requiring exp onen tially many initialization restarts to reach a go o d V oronoi partition with high probability). On the other hand, the glob al k -me ans [18, 26] builds incremen tally the clustering b y adding one seed at a time. Giv en a curren t s -clustering it c ho oses the p oint in P that minimizes the ( s + 1)-means ob jectiv e function. Thus initialization is limited to choosing the first p oint, and all p oints can b e considered as this first starting p oint. How ever, Global k -means requires more computation. In this paper, we do not address the problem of choosing the most appropriate num b er, k , of clusters: This mo del selection problem has b een in v estigated in [22, 17]. W e also consider the squared Euclidean distance although the results apply to any other Bregman div ergence [3, 23]. The pap er is organized as follows: W e in v estigate the blessing of empt y-cluster exceptions in Llo yd’s heuristic in Section 2, and of single-p oin t-cluster exceptions in Hartigan’s sc heme in Section 3. In Section 4, w e describ e our nov el heuristic merge-split-cluster k -means and rep ort on its p erformances with resp ect to Hartigan’s heuristic. In Section 5, w e present a generalization of the k -means ob jectiv e function where each p oin t is asso ciated to its l closest clusters: the ( k , l )- means clustering. W e show how to directl conv ert or iterativ ely relax a sequence of ( k , l )-means to a k -means and compare exp erimentally those solutions with a direct k -means. Finally , Section 6 wrap ups the contributions and discusses further p ersp ectives. 2 The blessing of empt y-cluster exceptions in Lloyd’s batc hed k - means Llo yd’s k -means [19] starts b y initializing the seeds of the cluster cen ters K = { c 1 , ..., c k } , and then iterates b y assigning the data to their closest cluster cen ter with resp ect to the squared 3 Euclidean distance, and then relo cates the cluster centers to their centroids. Those batched assign- men t/relo cation iterations are repeated until conv ergence is reached: The k -means cost monotoni- cally decreases with guaranteed conv ergence after a finite num b er of iterations [15]. The complexity of Llo yd’s k -means is O ( ndk s ) where s denotes the num b er of iterations. It has b een pro v ed that Llo yd’s k -means p erforms a maximum n umber s of iterations exp onential [25] or p olynomial in n , d and the spread 3 of the p oint set [16]. Some 1D p oin t set are rep orted to take Ω( n ) iterations ev en for k = 2, see [11]. W e first, rep ort a lo wer b ound on the n um b er of Lloyd’s stable optima P L ( n, k ): F act 2 (Exp onen tially many Lloyd’s k -means minima) Lloyd’s k -me ans may have P L ( n, k ) = Ω(2 n 2 k ) stable lo c al minima. The pro of follows from the gadget illustrated in Figure 1. (a) (b) (c) (d) (a) (b) (c) (d) Figure 1: T op: Llo yd’ s k -means may hav e an exp onential num b er of stable optima: Use lo cally the k = 2 p -gon (here p = 3) gadget that admits 2 global solution (a) and (b). Llo yd’s k -means can b e trapp ed in to a lo cal minim um: Cost in (c) and (d) is ∼ 0 . 5417 compared to the global minima 0 . 375) in (a) and (b). Centroids are depicted b y large colored disks. Bottom: Lloyd’s k -means lo cal optimization tec hnique ma y pro duce empty cluster exc eptions . Consider n = 5 p oints and k = 3 clusters: p 1 = (0 , 0), p 2 = (0 . 25 , 0 . 19), p 3 = (0 . 03 , 0 . 92), p 4 = (0 . 66 , 0 . 79) and p 5 = (0 . 6 , 0 . 85) with k = 3 and “random” F orgy initialization: c 1 = p 3 , c 2 = p 4 and c 3 = p 5 . Then the initial k -means cost (a) is 1 . 3754, the first iteration (b) and (c) yields cost 0 . 6877 and then at the second iteration w e hav e an empty cluster exception in (d): The green cluster. 3 The spread ∆ is the ratio of the maximum p oint inter-distance o ver the minimum p oint inter-dist ance. 4 Data : P = { ( w 1 , p 1 ) , ..., ( w n , p n ) } a data set of size n , k ∈ N : n umber of clusters Result : A clustering partition C 1 , ..., C k where each p oint belongs to exactly one cluster (hard membership) Initialization: Get k cluster cen ters C = { c 1 , ..., c k } b y choosing cluster protot yp es at random from P (e.g., F orgy or k -means++); Iter ← 0; while not c onver ge d do Incremen t Iter, e = 0; (a) Assign each p oint p i to its closest cluster C a i ; /* iNN denotes the index of the nearest neighbor */ a i = iNN( p i ; K ) . (b) Relocate each cluster protot yp e c j b y taking the center of mass of its assigned p oints; C j = { p ∈ P : j = iNN( p ; C ) } , n j = X p l ∈C j w l . if n j > 0 then Non-empt y cluster and centroid relocation: c j = 1 n j X p l ∈C j w l p l else e ← e + 1; end (c) New seeding ; /* Empty cluster exception (may have occured overall Ω( k ) times) */ 1 Cho ose e new seeds for the empt y clusters using k -means++ or global k -means, etc.; Chec k for conv ergence by c hecking if at least one a i is different from the previous iteration; if Iter > maxIter then break; end end Algorithm 1: Extended Lloyd’s k -means clustering: batched up dates handling empt y cluster exceptions. The Hartigan’s heuristic [12, 13] pro ceeds by relo cating a single p oin t b etw een tw o clusters pro vided that the k -means cost function decreases. It can thus further decrease the k -means score when Lloyd’s batched algorithm is stuck into a lo cal minim um (but not the conv erse). Recently , Hartigan’s heuristic [23] was suggested to replace Lloyd’s heuristic on the basis that Hartigan’s lo cal minima is a subset of Lloyd’s optima (Theorem 2.2 of [24]). W e argue that this is true only when no Empty Cluster Exc eptions (ECEs) are met by Llo yd’s iterations. Figure 1 illustrates a toy data set where Lloyd’s k -means meets suc h an empty-cluster exception. In general at the end of the relo cation stage, when p oints are assigned to their closest curren t cen troids, w e may hav e some 5 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 30 35 40 45 50 frequency k Empty cluster exception (Iris data set) F orgy k -means++ k e = 1 e = 2 e = 3 e = 1 3 48 2 5 957 26 10 1305 8 1 1 20 2718 17 98 30 12525 71 130 40 34936 382 92 50 72193 1467 7 106 Figure 2: Left: Graph plot of the frequency of empty-cluster exceptions ( e > 0) for Llo yd’s k -means using F orgy’s initialization on the normalized Iris data set computed b y av eraging ov er a million runs. Righ t: Num b er of ECEs depend on the initialization method: At k = 50, w e observ e a frequency of 7 . 2% for one empty cluster, 0 . 014% for tw o empty clusters, etc. for F orgy’s seeding but k -means++ initialization pro duces less suc h exceptions. empt y clusters. F act 3 (empty-cluster exceptions) Lloyd’s b atche d k -me ans may pr o duc e e = Ω( k ) empty clus- ter exc eptions in a r ound. Pro of follo ws from Figure 1 by creating s = n/ 5 far apart (non-interacting) copies of the gadget and setting k = 3 s . Ho w ev er, those empt y-cluster exceptions are a blessing because w e may add e new seeds that will further decrease significan tly the cost of k -means: This is a partial re-seeding. Thus the extended Llo yd’s heuristic is: (a) assignmen t, (b) relo cation, and (c) partial reseeding to k eep exactly k non-empt y clusters for the next stage. W e may use v arious heuristics for partially re-seeding like the incremental global k 0 -means [26] starting from k 0 = k − e to k 0 = k , etc. T o ev aluate the frequency at which those empt y-cluster exceptions o ccur and their num b er e , let us take the Iris data set from the UCI rep ository [1]: It consists of n = 351 samples with d = 4 features (classified in to k = 3 lab els) that w e first renormalize the data-set so that co ordinates on each dimension hav e zero mean and unit standard deviation. Let us run Lloyd’s k -means with (F orgy’s) random seed initialization (with a maximum num b er of 1000 iterations) for mstart = 1000000. W e count the num b er of empt y cluster exceptions and rep ort their frequency in the graph of Figure 2. W e observ e that the larger the k , and the more frequent the exceptions. This phenomenon w as also noticed in [5]. F urthermore, e increases with the dimension d to o [5]. Ho w ev er, note that this is a tendency and the n umber of empty-cluster exceptions v ary a lot from a data set to another one (giv en an initialization heuristic). Let us now run mstart = 1000000 k -means and rep ort the empiric al fr e quency of having e = 1 , 2 , 3 , ... simultane ous empty-cluster exceptions. (Note that our replicated toy data-sets of Figure 1 ma y provide Ω( k ) v alues). The empty-cluster frequency depends on the initialization sc heme: It is higher when using F orgy’s heuristic and low er when using k -means++ or global k -means. T able 2 demonstrates empirically this observ ation. As noticed in [5], the num b er of cluster-empty exceptions rise with k and d and the authors [5] a v oided this problem by setting minimum input 6 k / metho d classic Lloyd Llo yd+partial reseeding #ECEs a vg min a vg min 30 12 . 86 9 . 88 12 . 86 9 . 88 7685 40 9 . 72 7 . 30 9 . 72 7 . 28 23633 50 7 . 5 5 . 47 7 . 5 5 . 47 55726 T able 1: Comparing Llo yd’s k -means heuristics without or without partial reseeding (F orgy) when meeting empty-cluster exceptions on Iris dataset with a million restart using the same F orgy’s initialization at each round. Observe that some b etter lo cal minima are reached when using partial reseeding at empty-cluster exceptions. size on clusters. They surprisingly sho w empirically that k -means with constrain ts gav e b etter clustering than k -means without constrain ts in practice! Finally , let us compare the b est minim um k -means score when performing Llo yd’s heuristic (and stopping when w e meet an empty cluster exception), and the extended Llo yd’s heuristic that partially reseeds the curren t clustering when the algorithm meets empty-cluster exceptions. Partial reseeding can b e done in many wa ys by starting from the current num b er of cluster centers the usual seeding methods (F orgy , k -means++ or global k -means). T able 1 presents the results for the pro of of concept using F orgy’s re-seeding: W e observe that partial reseeding at ECEs allows to reac h (slightly) b etter lo cal minima (see k = 40 in T able 1). 3 The blessing of single-p oin t cluster exceptions in Hartigan’s heuristic Hartigan’s heuristic [24] consider relo cating a single-p oin t pro vided that it decreases the k -means ob jectiv e function. In [23], a synthetic noisy data-set is built so that with probability tending to 1 (as the dimension tends to infinity) any initial random partition is stable wrt. Lloyd’s k -means while Hartigan’s con verges to the correct solution. W e recall that Hartigan’s lo cal minima are a subset of Lloyd’s minima [24] pr ovide d that Llo yd’s heuristic did not encoun ter empt y-cluster exceptions. Note that a single-p oint cluster (with asso ciated cluster having zero v ariance) cannot b e relo cated to other clusters since it necessarily increases the k -means energy (sum of intra-cluster v ariances): e ( P , K ) = k X j =1 v ( C j ) = n X i =1 k p i k 2 − n j k X j =1 k c j k 2 , k X j =1 n j = n. (3) T able 2 provides statistics on the Hartigan’s k -means score and the n umber of single-point- cluster exceptions (SPCEs) met when performing Hartigan’s heuristic. Consider the case of Single-p oint-Cluster Exc eptions (SCEs) in Hartigan’s sc heme where w e decide to merge this single-p oint cluster C i = { x } with another cluster C j and redra w another cen ter from P (that can thus decrease significan tly the v ariance of the c hange cluster). W e accept this relo cation iff. this merge&re-seed op eration decreases the k -means loss. F or example, when k = 30 (and mstart = 1000), the classical Hartigan’s b est clustering has k -means score 9 . 75 while the heuristic with partial reseeding (asso ciating the single-p oint clusters to their closest other clusters), 7 k Hartigan’s k -means Single-p oint cluster exceptions min a vg max min a vg max 30 9 . 74 11 . 28 15 . 66 3 20893 . 27 34007 35 8 . 20 9 . 48 13 . 27 6 43700 . 20 75911 40 6 . 98 8 . 06 12 . 69 12 61437 . 81 103407 45 5 . 79 6 . 92 11 . 23 9 83113 . 54 163344 50 5 . 06 5 . 95 8 . 96 13 204222 . 78 367437 T able 2: Some statistics on Hartigan’s heuristic on the Iris data set: min/a vg/max k -means score and min/a vg/max num b er of single-p oint cluster exceptions (SPCEs). w e obtain 9 . 65. W e keep the exp eriments short here since the next Section improv es Hartigan’s heuristic with detailed exp eriments. 4 A no v el heuristic: The merge-and-split-cluster k -means This nov el heuristic pro ceeds by considering pairs of clusters ( C i , C j ) with corresp onding centers c i and c j . The b asic lo c al se ar ch primitive (pivot) consists in computing the b est k -means score difference by mer ging and splitting again C i,j = C i ∪ C j with tw o new cen ters c 0 i and c 0 j . Let C 0 i and C 0 j denote the V or onoi p artition of C i,j induced b y c 0 i and c 0 j . Since the clusters other than C i and C j are un touched, the difference of the k -means score is written as: ∆( C i , C j ) = e 1 ( C i , c i ) + e 1 ( C j , c j ) − ( e 1 ( C 0 i , c 0 i ) + e 1 ( C 0 j , c 0 j )) , (4) where e 1 ( C , c ) denotes the 1-means ob jective function: namely , the cluster v ariance of C with respect to cen ter c . There are several w a ys (randomized or deterministic) to implement the merge-and-split op eration: F or example, the tw o new centers can b e found by computing: • a 2-means: A brute-force method computes all hyperplanes 4 passing through d + 1 (extreme) p oin ts and the induced sum of v ariances of the b elo w-ab ov e clusters in O ( n d +2 )-time. Using top ological sw eep [15], it can b e reduced to O ( n d ) time. Note that for k = 2 and unfixed d , 2-means is NP-hard [8]. W e can also use coresets to get a (1 + )-appro ximation of a 2-means [9] in linear time O ( nd ). • a discrete 2-means: W e choose among the n i,j = n i + n j p oin ts of C i,j the tw o b est centers (naiv ely implemented in O ( n 3 )). This yields a 2-approximation of 2-means. • a 2-means++ heuristic: W e pick c 0 i at random, then pic k c 0 j randomly according to the normalized distribution of the squared distances of the p oin ts in C i,j to c 0 i , see k -means++ [2]. W e rep eat a given num b er α of rounds this initialization (say , α = 1 + 0 . 01 n i,j 2 ) and keeps the b est one. When ∆( C i , C j ) > 0, we accept replacing ( C i , c i ) and ( C j , c j ) by ( C 0 i , c 0 i ) and ( C 0 j , c 0 j ), resp ectively . Otherwise, we consider another pair of clusters and stop iterating when all pairs do not pro duce 4 W e do not need to compute explicitly the equation of the h yp erplane since clockwise/coun terclo ckwise orientation pr e dic ates are used instead. Those predicates rely on computing the sign of a ( d + 1) × ( d + 1) matrix determinan t. 8 Data set Hartigan Discrete Hartigan Merge&Split cost #ops cost #ops cost #ops Iris(d=4 , n=150 , k=3) 112 . 35 35 . 11 101 . 69 33 . 54 83 . 95 31 . 36 Wine(d=13 , n=178 , k=3) 607303 97 . 88 593319 100 . 02 570283 100 . 47 Y east(d= , n=1484 , k=10) 47 . 10 1364 . 0 57 . 34 807 . 83 50 . 20 190 . 58 Data set Hartigan++ Discrete Hartigan++ Merge&Split++ cost #ops cost #ops cost #ops Iris(d=4 , n=150 , k=3) 101 . 49 19 . 40 90 . 48 18 . 93 88 . 56 8 . 84 Wine(d=13 , n=178 , k=3) 3152616 18 . 76 2525803 24 . 61 2498107 9 . 67 Y east(d=8 , n=1484 , k=10) 47 . 41 1192 . 38 54 . 96 640 . 89 51 . 82 66 . 30 T able 3: Average p erformance ov er 1000 trials of the merge-and-split k -means heuristic compared to Hartigan’s and discrete Hartigan’s heuristics. T op: Common F orgy’s initialization and the MSC k -means has b een implemented using an optimal discrete 2-means. Bottom: Common k -means++ initialization and the MSC k -means has b een implemen ted using a 2-means++ with α = 0 . 01%. W e observ e exp erimentally that MSC heuristic yields alwa ys b etter p erformance than Hartigan’s discrete single-p oin t relo cation heuristic, and is often signigicantly better than Hartigan’s heuristic. Note that k -means++ seeding performs b etter than F orgy’s seeding a low er k -means score. This heuristic can b e classified as a macro kind of Hartigan-type heuristic that is not based on local V oronoi assignment. Indeed, Hartigan’s heuristic mov es a p oint x from a cluster C i to a cluster C j and up date the tw o centroids corresp ondingly . Our heuristic also change these t wo clusters but can accept further impro v emen ts with respect to a 2-means op eration on C i,j . Th us at the last stage of a Hartigan’s heuristic, w e can p erform this merge-and-split heuristic to further impro v e the clustering. (This heuristic can further b e generalized by sim ultaneous merging- and-splitting of r clusters.) Theorem 1 The mer ge-and-split k -me ans heuristic de cr e ases monotonic al ly the obje ctive function and c onver ges after a finite numb er of iter ations. Since each pivot step b etw een V oronoi partitions strictly decreases the k -means score e ( P , K ) ≥ 0 b y ∆( C i , C j ) > 0 and that min C i , C j ∆( C i , C j ) > 0 is low er b ounded, it follows that the merge- and-split k -means con v erges after a finite n umber of iterations. W e compare our heuristic with b oth Hartigan’s ordinary and discrete v ariants that consists in mo ving a p oin t to another cluster iff. the tw o recomputed medoids of the selected clusters yield a b etter k -means score. Heuristic p erformances are compared with the same initialization (F orgy’s or k -means++ seeding) and b y a v eraging ov er a num b er of rounds: Observe in T able 3 that our heuristic (MSC for short) alwa ys outp erforms discrete Hartigan’s metho d not suprisingly . Although the num b er of basic primitives (#ops) is low er for MSC, each such op eration is more costly . Thus MSC k -means is o v erall more time consuming but gets better lo cal optima solutions. Note that the discrete 2-means medoid splitting pro cedure is very well suited for the k -mo des algorithm [14], a k -means extension w orking on categorical data sets. 9 5 Clustering with the ( k , l ) -means ob jectiv e function Let us generalize the k -means ob jectiv e function as follo ws: F or each data p i ∈ P , w e asso ciate p i to its l nearest cluster centers NN l ( p i ; K ) (with iNN l denoting the cluster center indexes), and ask to minimize the following ( k, l )-means ob jective function (with 1 ≤ l ≤ k ): e ( P , K ; l ) = n X i =1 X a ∈ iNN l ( p i ; K ) k p i − c a k 2 . (5) When l = 1, this is exactly the k -means ob jectiv e function of Eq. 1. Otherwise the clusters o v erlap and | ∪ k j =1 C j | = nl . Note that when l = k , since NN k ( p i ; K ) = K all cluster centers c 1 , ..., c k coincide to the c entr oid ¯ p = 1 n P i p i (or barycen ter), the c enter of mass . W e observe that: F act 4 e ( P , K ; l ) ≥ l × e ( P , K ; 1) with e quality r e ache d when l = k . Both Lloyd ’s and Hartigan’s heuristics can b e adapted straightforw ardly to this setting. Theorem 2 Lloyd’s ( k , l ) -me ans de cr e ases monotonic al ly the obje ctive function and c onver ge after a finite numb er of steps. Pro of: Let c 2 t and c 2 t +1 denote the cost at round t , for the as signmen t ( c 2 t ) and relo cation ( c 2 t +1 ) stages. Let c 0 b e the initial cost (say , from F orgy’s initialization of K 0 ). F or t > 0, we hav e: In the ass ignmen t stage 2 t , eac h p oint p i is ass igned to its l nearest neigh b or cen ters NN l ( p i ; K t − 1 ). Therefore, we hav e c 2 t = P n i =1 P c ∈ NN l ( p i ; K t − 1 ) D ( p i , c ) ≤ c 2 t − 1 . In the relocation stage 2 t + 1, eac h cluster C t j is up dated by taking its centroid c t +1 j . Th us w e hav e c 2 t +1 = P k j =1 P p ∈C t j D ( p, c t +1 j ) ≤ P k j =1 P p ∈C t j D ( p, c t j ) ≤ c 2 t . When K t +1 = K t (and thus c 2 t = c 2 t − 1 ), w e stop the batc hed iterations. Figure 3 illustrates a ( k , 2)-means on a toy data-set. Since c t ≥ 0 for all t and the iterations strictly decreases the score function, the algorithm con v erges. Moreov er, since the n um b er of different cluster sets induced by ( k , l ) means is upp er b ounded by O ( n kl ), and that cluster sets cannot be repeated, it follows that ( k , l )-means con verges after a finite numb er of iterations. The b ound can further b e improv ed b y considering the l -order w eigh ted V oronoi diagrams, similarly to [15]. Note that the basic Llo yd’s ( k , l )-means may also pro duce empt y-cluster exceptions although those b ecome rarer as l increase (c hec k ed exp erimen- tally). Although ( k , l )-means is interesting in its own (se e Discussion in Section 6), it can also b e used for k -means. Indeed, instead of running a lo cal search k -means heuristic that may be trapp ed to o so on into a “bad” lo cal minimum, we prefer to run a ( k , l ) means for a prescrib ed l . W e can then con v ert a ( k, l )-means b y assigning to each point p i its closest neigh b or (among the l assigned at the end of the ( k , l )-means), and then compute the centroids and launc h a regular Llo yd’s k -means to finalize: Let ( k , l ) ↓ -means denote this con v ersion. F or example, for k = 6 and l = 2, the conv erted ( k , 2)-means b eats the k -means 80% of the time for mstart = 10000 using F orgy’s initialization on Iris . T able 4 sho ws exp erimen tally that conv erted ( k , 2)-means b eats on aver age the regular k -means (for the Iris data-set) and this phenomenon increases not surprisingly with k . How ever the best minim um score is often obtained b y classical k -means. Th us it suggests that ( k, l ) p erforms b etter when the n umber of restarts is limited. In fact, ( k , l )-means tend to smo oth the k -means optimization landscap e and pro duce less local minima but also smo oth the b est minima. 10 Figure 3: ( k , 2)-means: Eac h data p oint is asso ciated to its two closest cluster center neighbors. After conv erging, we relax the ( k , 2)-means solution by k eeping only the closest neighbor on the curren t cen troids and run the classic k -means. Alternativ ely , w e can relax iteratively the ( k , m ) means into a ( k , m − 1)-means until we get a k -means. 11 k win k -means ( k , 2) ↓ -means min a vg min avg 3 20 . 8 78 . 94 92 . 39 78 . 94 78 . 94 4 24 . 29 57 . 31 63 . 15 57 . 31 70 . 33 5 57 . 76 46 . 53 52 . 88 49 . 74 51 . 10 6 80 . 55 38 . 93 45 . 60 38 . 93 41 . 63 7 76 . 67 34 . 18 40 . 00 34 . 29 36 . 85 8 80 . 36 29 . 87 36 . 05 29 . 87 32 . 52 9 78 . 85 27 . 76 32 . 91 27 . 91 30 . 15 10 79 . 88 25 . 81 30 . 24 25 . 97 28 . 02 k l win k -means ↓ ( k , l )-means min avg min avg 5 2 58 . 3 46 . 53 52 . 72 49 . 74 51 . 24 5 4 62 . 4 46 . 53 52 . 55 49 . 74 49 . 74 8 2 80 . 8 29 . 87 36 . 40 29 . 87 32 . 54 8 3 61 . 1 29 . 87 36 . 19 32 . 76 34 . 04 8 6 55 . 5 29 . 88 36 . 189 32 . 75 35 . 26 10 2 78 . 8 25 . 81 30 . 61 25 . 97 28 . 23 10 3 82 . 5 25 . 95 30 . 23 26 . 47 27 . 76 10 5 64 . 7 25 . 90 30 . 32 26 . 99 28 . 61 T able 4: Comparing k -means with ( k , 2) ↓ -means (left) and with ↓ ( k, l )-means (right). The p ercen tage of times it outp erforms k -means is denoted by win. W e can also perform a cascading conv ersion of ( k , l )-means to k -means: Once a local minimum is reached for ( k, l )-means, w e initialize a ( k , l − 1) means b y dropping for each p oint p i its farthest cluster, p erform a Llo yd’s ( k , l − 1)-means, and we reiterate this scheme until w e get a ( k , 1)- means: An ordinary k -means. Let ↓ ( k , l )-means denote this scheme. T able 4 (righ t) presen ts the p erformance comparisons of a regular Lloyd’s k -means with a Lloyd’s ( k , l ↓ 1)-means for v arious v alues of l with the initialization of b oth algorithms p erformed by the same seeding for fair comparisons. 6 Discussion W e hav e extended the classical Lloyd’s and Hartigan’s heuristics with partial re-seeding and pro- p osed new lo cal heuristics for k -means. W e summarize our contributions as follo ws: First, we sho w ed the blessing of empty-cluster even ts in Lloyd’s heuristic and of single-p oint-cluster ev en ts in Hartigan’s heuristic. These ev ents happ en increasingly when the num b er of cluster k or the dimension d increase, or when running those heuristics a given n umber of trials to choose the b est solution. Second, we proposed a nov el mer ge-and-split-cluster k -me ans heuristic that improv es ov er Hartigan’s heuristic that is currently the de facto metho d of choice [23]. W e sho w ed exp erimentally that this metho d brings b etter k -means result at the exp ense of computational cost. Third, w e generalized the k -means ob jectiv e function to the ( k, l )-means ob jective function and show how to directly conv ert or iteratively relax a ( k , l )-means heuristic to a k -means av oiding p otentially b eing trapp ed in to to o man y lo cal optima. ( k , l )-Means is yet another explor atory clustering technique for browsing the space of hard clustering partitions. F or example, when k -means is trapp ed, we ma y consider a ( k , l )-means to get out of the lo cal minim um and then con vert the ( k , l )-means to a k -means to explore a new (lo cal) minimum. References [1] D.J. Newman A. Asuncion. UCI mac hine learning rep ository , 2007. [2] D. Arthur and S. V assilvitskii. k -means++ : the adv antages of careful seeding. In SODA , pages 1027 – 1035, 2007. 12 [3] A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh. Clustering with Bregman div ergences. Journal of Machine L e arning R ese ar ch , 6:1705–1749, 2005. [4] R. Bellman. A note on cluster analysis and dynamic programming. Mathematic al Bioscienc es , 18(3-4):311 – 312, 1973. [5] K. Bennett, P aul S. Bradley , and Ayhan Demiriz. Constrained k -means clustering. MSR-TR- 2000-65, 2000. [6] A. Bhattac hary a, R. Jaiswal, and N. Ailon. A tight lo w er b ound instance for k -means++ in constan t dimension. In The ory and Applic ations of Mo dels of Computation , LNCS 8402, pages 7–22, 2014. [7] S. Bub ec k, M. Meila, and U. von Luxburg. Ho w the initialization affects the stabilit y of the k -means algorithm. ESAIM: Pr ob ability and Statistics , 16:436–452, 1 2012. [8] S. Dasgupta. The hardness of k -means clustering. CS2007-0890, Univ ersity of California, USA, 2007. [9] D. F eldman, M. Monemizadeh, and C. Sohler. A PT AS for k -means clustering based on weak coresets. In SoCG , pages 11–18. 2007. [10] E. W. F orgy . Cluster analysis of m ultiv ariate data: efficiency vs interpretabilit y of classifica- tions. Biometrics , 1965. [11] S. Har-P eled and B. Sadri. How fast is the k -means metho d? In SODA , pages 877–885. SIAM, 2005. [12] J. A. Hartigan. Clustering Algorithms . John Wiley & Sons, Inc., New Y ork, NY, USA, 99th edition, 1975. [13] J. A. Hartigan and M. A. W ong. Algorithm AS 136: A k -means clustering algorithm. Journal of the R oyal Statistic al So ciety. Series C , 28(1):100–108, 1979. [14] Z. Huang. Extensions to the k -means algorithm for clustering large data sets with categorical v alues. Data Min. Know l. Disc ov. , 2(3):283–304, Septem b er 1998. [15] M. Inaba, N. Katoh, and H. Imai. Applications of weigh ted Voronoi diagrams and random- ization to v ariance-based k -clustering. In SoCG , pages 332–339, 1994. [16] T. Kanungo, D. M. Moun t, N. S. Netan y ah u, C. Piatko, R. Silverman, and A. Y W u. The analysis of a simple k -means clustering algorithm. In SoCG , pages 100–109. 2000. [17] B. Kulis and M. I. Jordan. Revisiting k -means: New algorithms via Bay esian nonparametrics. In ICML , 2012. [18] A. Lik as, N. Vlassis, and J. J V erb eek. The global k -means clustering algorithm. Pattern r e c o gnition , 36(2):451–461, 2003. [19] S. P . Llo yd. Least squares quan tization in PCM. T echnical rep ort, Bell Lab oratories, 1957. reprin ted in IEEE T ransactions on Information Theory , March 1982. 13 [20] J. B. MacQueen. Some methods of classification and analysis of multiv ariate observ ations. Pr o c e e dings Fifth Berkeley Symp osium on Mathematic al Statistics and Pr ob ability , 1967. [21] M. Maha jan, P . Nimbhork ar, and K. V aradara jan. The planar k -means problem is NP-hard. In W ALCOM: Algorithms and Computation , pages 274–285. Springer, 2009. [22] D. Pelleg and A. W. Mo ore. X -means: Extending k -means with efficient estimation of the n um b er of clusters. In Pr o c e e dings of the Sevente enth International Confer enc e on Machine L e arning , pages 727–734, 2000. [23] N. Slonim, E. Aharoni, and . Crammer. Hartigan’s k -means versus Llo yd’s k -means: Is it time for a change? In IJCAI , pages 1677–1684, 2013. [24] M. T elgarsky and A. V attani. Hartigan’s method: k -means clustering without Voronoi. In International Confer enc e on Artificial Intel ligenc e and Statistics , pages 820–827, 2010. [25] A. V attani. k -means requires exp onentially many iterations even in the plane. Discr ete & Computational Ge ometry , 45(4):596–616, 2011. [26] J. Xie, S. Jiang, W. Xie, and X. Gao. An efficien t global k -means clustering algorithm. Journal of c omputers , 6(2), 2011. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment