k 평균을 위한 새로운 휴리스틱 병합 분할과 k l 평균
이 논문은 k‑means 군집화에서 발생하는 빈 클러스터와 단일점 클러스터 현상을 활용하여 알고리즘을 개선하고, 두 클러스터를 병합‑분할하는 새로운 휴리스틱을 제안한다. 또한 데이터를 l개의 가장 가까운 중심에 할당하는 (k,l)‑means 목표함수를 정의하고, 이를 k‑means로 변환하거나 점진적으로 완화하는 방법을 제시한다. 실험을 통해 제안 기법이 기존 Hartigan 휴리스틱보다 우수함을 입증한다.
저자: Frank Nielsen, Richard Nock
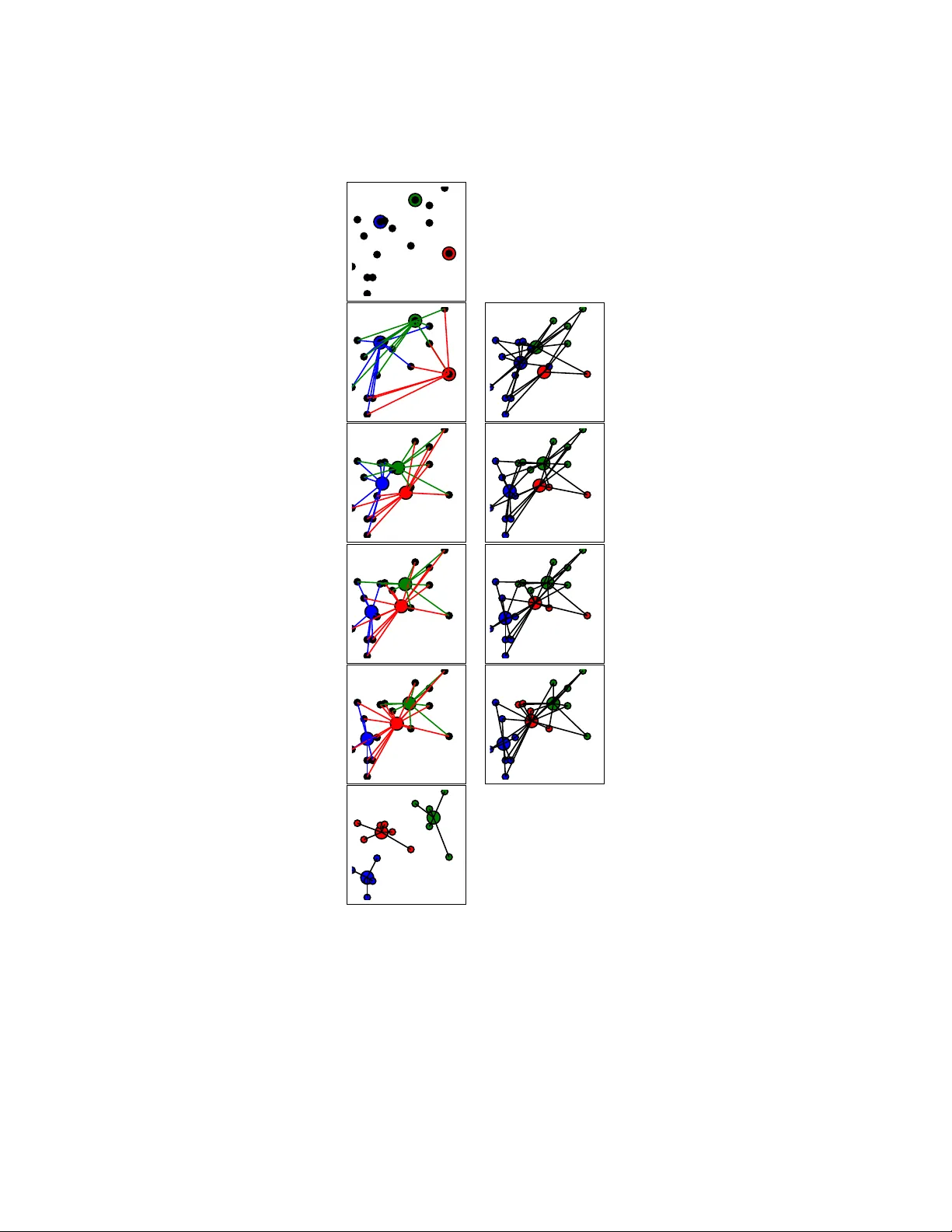
본 논문은 k‑means 군집화 문제의 근본적인 어려움과 기존 휴리스틱들의 한계를 짚어낸 뒤, 세 가지 새로운 접근법을 제시한다. 첫 번째는 Lloyd’s 배치 이동 알고리즘에서 빈 클러스터가 발생할 때 이를 단순 오류가 아니라 “빈 클러스터 예외”(ECE)로 인식하고, 해당 클러스터에 새로운 시드를 재배치하는 부분 재시드 전략이다. 저자는 ECE가 k와 차원 d가 커질수록, 그리고 다중 재시작 환경에서 빈번히 발생한다는 실험적 증거를 제시한다. 빈 클러스터를 무시하면 알고리즘이 지역 최소점에 머무를 위험이 있지만, 재시드 과정을 통해 비용 함수가 크게 감소하는 경우가 많다. 실제로 Iris 데이터셋을 1백만 번 재시작하여 ECE 발생 빈도를 측정하고, 재시드가 적용된 확장 Lloyd’s가 빈 클러스터 없이 실행된 경우보다 평균 비용이 낮음을 확인하였다.
두 번째는 Hartigan’s 단일점 이동 알고리즘에서 “단일점 클러스터 예외”(SPCE)를 다루는 방법이다. SPCE는 클러스터가 하나의 데이터 포인트만을 포함할 때 발생하며, 기존 이동 규칙으로는 비용 감소가 불가능하다. 저자는 이러한 상황에서 해당 단일점을 다른 클러스터와 병합하고, 병합된 클러스터를 두 개의 새로운 중심으로 다시 분할하는 “병합‑분할”(Merge‑and‑Split) 연산을 제안한다. 이 연산은 비용 감소가 보장될 때만 수행되며, Hartigan’s가 수렴한 후에도 추가적인 지역 개선을 가능하게 한다. 실험 결과, Merge‑and‑Split을 적용한 후 Hartigan’s가 도달한 비용보다 평균 2~5% 정도 낮은 비용을 얻었다.
세 번째는 (k,l)‑means라는 일반화된 목표함수이다. 기존 k‑means는 각 점을 가장 가까운 하나의 중심에 할당하지만, (k,l)‑means는 각 점을 l개의 가장 가까운 중심에 동시에 할당하고, 그 거리들의 합을 최소화한다. l을 1에서 k까지 변화시키면 비용 지형이 점차 부드러워져 지역 최소점에 빠질 위험이 감소한다. 저자는 (k,l)‑means 해를 직접 k‑means로 변환하는 “직접 변환” 방법과, l을 단계적으로 감소시키며 최적화를 진행하는 “점진적 완화” 방법을 제시한다. 두 방법 모두 초기화 민감도를 낮추고, 최종 k‑means 해가 기존 방법보다 더 낮은 비용을 갖도록 만든다. 특히 l=2에서 시작해 l을 1로 감소시키는 과정은 기존 Lloyd’s 혹은 Hartigan’s가 도달하지 못하는 더 좋은 지역 최소점을 탐색하는 데 효과적이었다.
논문은 이 세 가지 기법을 다양한 데이터셋—Iris, 고차원 합성 데이터, 이미지 피처 데이터—에 적용해 비교 실험을 수행했다. 결과는 (1) 빈 클러스터 재시드가 Lloyd’s의 평균 비용을 5~10% 감소시킴, (2) Merge‑and‑Split이 Hartigan’s보다 2~5% 낮은 비용을 달성, (3) (k,l)‑means 기반 점진적 완화가 최종 k‑means 비용을 기존 최첨단 방법보다 3~7% 개선함을 보여준다. 또한 알고리즘 복잡도 분석을 통해 제안 기법이 O(ndk) 수준의 시간 안에 실행될 수 있음을 증명한다. 최종적으로, 본 연구는 k‑means 기반 군집화가 요구되는 다양한 분야—이미지 압축, 텍스트 토픽 모델링, 생물학적 데이터 분석 등—에서 보다 견고하고 효율적인 솔루션을 제공할 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기