Supervised Dictionary Learning by a Variational Bayesian Group Sparse Nonnegative Matrix Factorization
Nonnegative matrix factorization (NMF) with group sparsity constraints is formulated as a probabilistic graphical model and, assuming some observed data have been generated by the model, a feasible variational Bayesian algorithm is derived for learni…
Authors: Ivan Ivek
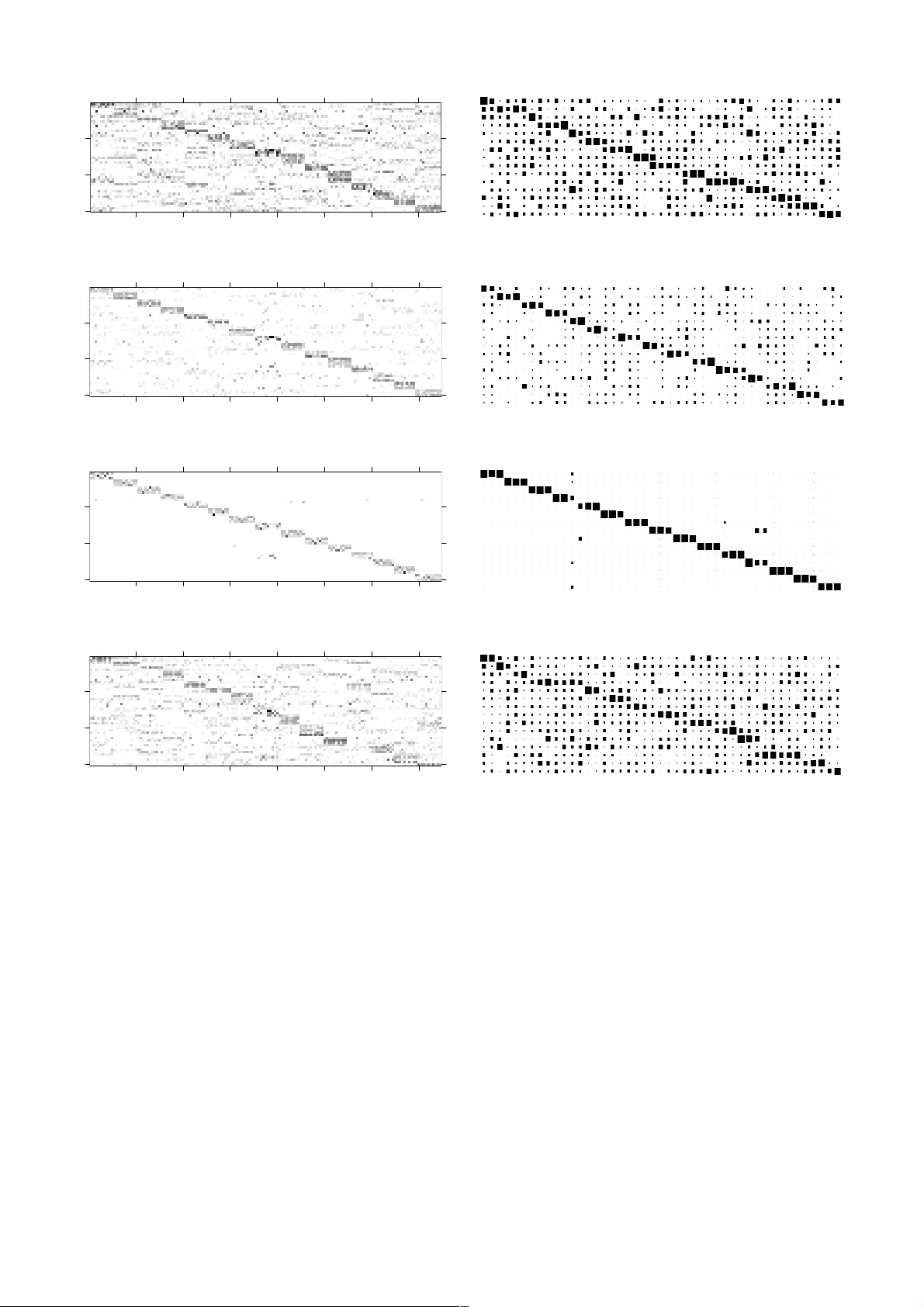
1 S u p e r v i s ed D i ct i o n a r y L e a r n in g b y a V a r i a t i o n a l B a y es i a n Gr o u p S p a r s e N o n n e g at i v e M at r i x F a ct o r i z at i o n I va n I v ek A bstract — Nonnegative matrix fa ctorization (NMF) with group sparsity con straints is for mulated as a proba bilistic graphical model and, assu ming some observe d data have been gener ated by the model, a feasible variational Bayesian algorith m is derived for learning model para meters. When used in a supervised lear ning scenario, NMF is mo st often utilized a s an unsupervised feature extractor foll owed by classification in the obtained feature subspace. Hav ing mapped the class labels to a more general concept of groups wh ich underlie sparsity o f the coef ficients, what the pro posed group sp arse NMF model allow s is incorporating cla ss label information to find low dimension al label-driv en dictionaries which no t only aim to represent the data faithfully , but are also sui table for class discrimination . Exp eriments performed in face recognition and f acial expression recognition domains point to advan tages of classification in such label-d riven feature subspace s over classification in feature subspaces obtained in an unsupervised manner . Index T erms — Face and ge sture r ecognition, Markov rand om fields, Pattern ana lysis 1 I NTRODUCTION INCE the appearance of the seminal paper [1], NMF has become a popular data decompo sition technique due to succesful a pplications in a still growing number of fields where data are n onnegative, such as pixel intensities in com puter vision, amplitude spectra in audi o signal a nalysis and EEG signal analysis, t erm counts in document clustering problems, and item ratings in collaborative filtering. NMF aims at decompositions , where , and are all nonnegati ve matrices. Throughou t this paper will be regarded a s a collection of data samples organiz ed columnwise, as a dictionary of features organized columnwise, and as matrix o f coefficients when is projected onto the dictionary . Under assumptions of linearity and nonnegativity, when underlying dimensionality is lower t han dimensionality of the original space of the data , dim ensionality reduct ion of the data ca n effectively be achieved this way . Although the decomposition is nonunique in general, NMF is ab le to produce strictly additive decomposition s perceived a s part-based by adding a dditional b ias in the model [1], [2]. To this end, different sparsity promoting regularizers have been proposed for divergence-based NMF [3]. Also, to include higher order data descriptions, many other variants have been dev eloped, e.g. Local NMF [4 ] with locality constraints, Non-smooth NMF [5] with regula rization for sparse and localized features, NMF with smoothness constraints [6], graph reg ularized NMF [7], [8 ] m anifold reg ularized NMF [9]. More recent- ly, alternative formulations of NM F in probabilistic framework have been developed [10], [11], allowing for explicit modeling of richer structural constrain ts a s graphical models [12], [13 ], [14], [15]. 1.1 Context and Contribut ions Closely related to work in this paper are NMF formula- tions and extensions with group sparsity constraints. Addressing EE G classificat ion where problem is to classi- fy different task s being performed b y different sub jects, in [16] a divergence based NMF with mixed-norm regula ri- zation imposed on dictionary elements to to get task- related (common) features that are as close as possible and, separatedly, features which reflect task-independent (individual) characte ristics, r equired to be a s fa r a s possi- ble, ha s been prop osed. An other divergence based algo - rithm but with group spar sity penaliza tions on the coeffi - cient matrix has b een propo sed in [17 ]. In [18] a genera- tive model with the same aim, enforcing two groups of features with the previously mentioned pro perties, i s trained using a variational Bayesian approach. In [19] a NMF va riant with Itakura-Saito dive rgence with a direct group-sparsity enforcing penaliza tion of co efficient ma- trix has been succesfully applied to blind audio source separation. Very recently, in [20] a gene rative mode l trained w ith Ma rkov chain Monte Carlo is proposed to separate features into groups of com mon bases and indi- vidual bases w ith Laplacian scale mixt ure distributions a s priors for the two groups, and applied to blind music source separation. Work presented in t his pa per had come out of the proba- bilistic NMF modeling track of research, with group sparsity constraint s as exponentia l scale mixture distribu- tions imposed on coef ficient matrix directly rat her than seeking group spar sity by constra ining the two groups of features as in [16], [18], [ 20]. Comparatively, it may be ——————— ————————— • Ivek, I. is wit h the Division of Elect ronics, Rudjer B oskovic Institute, Croatia . E - mail: ivan.ivek @ irb.hr S 2 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION noted tha t algorithms [16], [17], [19] are not of Bayesian type. Althoug h it aims t o im pose group sparsity through common and individua l features, most re semblance to the here presented model bea rs [20] because of Laplacian scale mixture as a prior for the two groups, but it uses Metropolis-Hastings a lgorithm for paramet er estimation due to choices of distribut ions in t heir hiera rchical model. Group sparse NMF present ed in this paper however, is engineered in a w ay that it allows efficient learning, her e performed using mean-field variational Bayesian meth- odology, which is determini stic and fea tures explicit vari- ational bound calculation based upon which model com- parison and selection ca n be made [11 ]. Most commonly, NMF is u tilized in two scenarios: unsu- pervised lea rning, to get decompositions suitable for clustering, and superv ised l earning, where N MF is used as a n u nsupervised feature extractor followed by classifi- cation in the obtain ed feature space. In both those cases NMF does not incorporate label information. Applica- tions presented in this paper are focused on the latte r case, but, instead of ignoring the data labeling, the pro- posed grou p sparse NMF model i s put in a setup where it is l abel-driven in an at tempt to bring out potentia l infor - mation in the labeling to find fea ture subspace s which aid classification. One remaining scenario is NMF in semi- supervised learning applications, which divergence based algorithms [21 ], [22], [23], [24] ha ve been developed for, also possessing the ability to include and use labe l in for- mation. 1.2 Probabilistic Fo rmulat ions of NM F It has been shown in [10] that maximum-likelihood (ML) estimation of factor matrices and under different noise distrib utions are equivalent to NMF algorithms with different corre sponding divergences. Mo re precisely, ML estimation of proba bilistic NMF under Gaus sian, Poissonian, and G amma noise correspon d t o m inimiza- tion of Euclidean, Kullback-Leib ler (KL) a nd I takura-Saito divergences, respectively. In case of maximum-a- posteriori (MAP) estimation, ex ponential prior on a factor corresponds to sparsity prom oting l1 regula rization. An- other connection betwe en probabilistic modeling and NMF worth noting is that Probabilistic Laten t Semantic Analysis, which i s an expect ation-maximization algo- rithm, is equiv alent to KL-NMF algorithm using multipli- cative update s [25]. Apart from ML, M AP and EM estima - tors, Ba yesian methods (Monte Carlo, variational Bayes ) have successfully been employed for efficient NMF pa- rameter learning [11], [14], [15]. 1.3 V ariation al Bayesian Learning Consider the objective of minimizing dissimilarity between conditional distribu tion , where denotes hidden variab les in the model, observed variables and model parameters, and its instrumental variational approximation , qua ntified by Kullback- Leibler divergence . (1) Equation (1) can b e be rewritten as !" . Because KL divergence is nonnegativ e, it turns out that " is lower boun d on the marginal loglikelihood of the observed data . On the other hand, because is constant, the objectiv e of minimizing KL div ergence can be reformulated a s maximization of " . By expanding the expres sion for the variat ional bound " ! # $ % , (2) where % denotes entropy of t he approximation , and supposing that the approximativ e variational distribution takes a factorized form & ' ()* , it ca n be shown t hat iterative local u pdates a lternating over + of form ' ,-. / 0123 # $ 45 6 7 , (3) improve lower bound on the marginal loglikelihood monotonically, with 4' & 58 58 5 . Should the mode be conjugate-exponential, all the expec- tations in (3) necessarily as sume analytica l forms [26]. 2 M ETHODOLOGY 2.1 Exponential Scale Mixtu re Distribution Let ra ndom varia ble 9 be a product of reciprocal of some positive random va riable : and exponentially distribut ed random variab le ; with scale 1 , 9 : <. ; . Supposing in dependency of = and > , conditioned on = , ? is exponentially distribu ted with scale = <. , ? = @ABCDCEFGH ? = <. . (4) and its marginal distribution assumes form of a continuous mixture with mixing variable = , ? ? = = = I J . Note that, should t he distribution of the mixing variable be discrete, the above expression collapses to a discrete mixture of exponentia ls with specific shape param eters. Because exponential distribution can b e obtain ed by truncation only of Laplacian distribution, it f ollows that exponential scale mixtu re is a special case of Laplacian scale mixture distribut ion [20], [27]. 2.2 Group Spar sity Mod el Placing exponential scale mixture in setting o f IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 3 probabilistic inference and learning, feasibility of related algorithms depend s on t he choice of prior = an d, as feasibility is prioritiz ed, this choice of suitab le priors gets narrowed down. As (3) sug gests, conjuga cy is desireab le when computational complexity is taken into consideration. For examples of how conjugate- exponential models are u sed for v ariational Bayesian NMF, the interested reader is referred to [11], [ 14] and also [15 ], where a variational family more ge neral tha n one which conjugate m odel would suggest to get analytical expressions appropriate for optimization. In this paper p rior = is engineered as a hierarchical graphical model with a discrete mixtu re = = K L M = ! N M L ! O = K P QR. (5) of S gam ma distributed va riables = K , 3= K TG K U V K U 7 WGXXG 3 = K TG K U V K U 7 , YZ[\ ] ] ] S ^ (6) with L as a categorical m ixture selector variable. According to (4), (5) and (6), ? is exponentially di stributed with different scale parameters = K <. for different selec- tions of L . To clarify on relationship to group sparsity, suppose first that multiple variab les ? _ exist organized in groups [\ ] ] ] S ^ , their affiliation indica ted by variables L _ ` [\ ] ] ] S ^ . Beca use reciprocals of the va riables = K , rep- resenting me an va lues of the exponential distributions in the mixture and being interpr eted as continuou s indica - tors of how large the averaged outcomes in a group are, have inve rse gamma probability density functions, the masses o f these density func tions can be tuned to be con- centrated on small valu es. Such priors a ct as constraints in a way that only the m inority of the groups are ex pected to ha ve exponentia l distributions w ith significantly large mean values, w hich is a suitable way to describe group sparse processes consistently in a probabilistic setu p. 2.3 Probabilistic NMF with Group Sparsit y Prior The proposed generative NMF model consi st of: 1) mixing stage w ith dimensionality reducti on effect under Poissonian noise A ab c adb M A ab ! e c afb g c afb E af ? fb BFccBC c hg_ i E hg ? g_ , 2) gamma priors for the left matrix T E hg G hg j G hg j WGXXG E hg G hg j V hg j 3) group spar sity structural constraints over the right matrix ? fb L _ = gd @ABC DCEFGH ? fb e M L _ ! O = fK Q <. 3= fK TG fK U V fK U 7 WGXXG3= fK TG fK U V fK U 7 . Both the mixing stage and t he ga mma priors over a re designed as in [11], while t he structural constraints over are introduced as a novelty. Joint distribution of the proposed model is k lmn o p o n q p q L r k k n o p o s m l L r lTn q p q , with k t A h_ c ad_ h_ k t c h d_ E hg ? g_ h_ n o p o t E hg G hg j V hg j hg ml L r t ? g_ = gd L _ f_ lTn q p q t 3= fK TG fK U V fK U 7 fQ . 2.4 V ariation al Learning A lgorithm In order to obtain convenien t analytical forms of itera tive updates, the va riational distribution is chosen to be fac- torized as k l k l , with k t c adb h_ t E af hg t ? fb g_ l & = fK fQ . As t he proposed learning algorithm will be layed out in matrix form with computationally efficient mat rix opera- tions, hype rparameters a nd v ariational parameters of the model are orga nized as matrices according to Tab le 1 and Table 2, respectively . u v ab A ab u w v _Q M L _ ! O u n o v hg G hg j u n q v gQ G fK U u p o v hg V hg j u p q v gQ V fK U Table 1. Parameters and hyperpar ameters of the proposed model x y o , z hg # E hg $ , x y { , z f b # ? f b $ , x | o , z hg # E hg $ , x | { , z f b # ? f b $ , x } o , z hg N # c hg_ $ , _ x y q , z gQ # = fK $ , x } { , z g_ N # c hg_ $ , h x | q , z gQ # = fK $ , Table 2. Variationa l parameters of the proposed mode l To derive iterative alternating updates for c adb ,-. , applying (5) yields c adb ,-. / 012 # $ ~ • 6 ~ € •d‚ 6 ƒ>HEFCBXFGH c h d_ A ab afb , with natura l parameters afb , „…†#‡ˆ‰j •Š $ 6 -#‡ˆ‰‹ Œ• $ 6 N „…†#‡ˆ‰j •Š $ 6 -#‡ˆ‰‹ Œ• $ 6 Š . Analytically, variational factor c adb ,-. assumed form of a multinomial distribution. Using analytical form of expectation of sufficient statistics of a multinomial distri- bution, they get updated according to #c afb $ ,-. A ab afb , . (7) 4 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION Specifically, as w ill be seen later, alternating updates for other hidden variables in the model will r equire those expectations in forms N #c afb $ ,-. h and N #c afb $ ,-. b , which, by putting summation over (7) and by simple algebraic ma nipulation, compactly become N # c afb $ ,-. h 012 # ? fb $ , Ž 012 # E hg $ , • ab , h (8) N # c afb $ ,-. b 012 # E hg $ , Ž • ab , 012 # ? fb $ , _ , (9) with repeating term substituted as • ab , • ‘• Ž „ …† # ‡ˆ‰j •Š $ 6 „…† # ‡ˆ‰‹ Œ• $ 6 Š . (10) Rewritten in matrix notation, ex pressions (8), (9 ) a nd (10) now become } { ,-. 01 2 | { , ]s 012| o , ’ s “ , ) } o ,-. 01 2 | o , ]s “ , s 012| { , ’ ) “ ,-. ] 012| o , s 012| { , ” . Approached i n the same ma nner, E hg ,-. analytically assumes form of a ga mma probability density function: E hg ,-. / 012# $ ~ • 6 ~ 3 • •Š 7 6 WGXXG E hg – af j , — af j , with shape and scale para meters – af j , G hg j N #c hg_ $ , _ — af j , 3V hg j <. N #? g_ $ , _ 7 <. , respectively. Again, it suffices to update an d store the expectations of sufficient sta tistics of E hg ,-. , #E hg $ ,-. = – af j , — af j , #E hg $ ,-. ˜– af j , — af j , . In matrix notation, these updates assume forms ™ o , š]s n o } o , › o , \] \] p o ” š s y { , ’ ” y o ,-. ™ o , ]s › o , | o ,-. ˜™ o , › o , , where b y š a unity matrix of appropriate size i s den oted and ˜ ] is elementwise digam ma function. Likewise, iterative update equa tions for ? g_ ,-. are derived as follows: ? g_ ,-. / 012# $ ~ • 6 ~ 3 œ Š‚ 7 6 WGXXG 3? g_ – g_ ‹ , — g_ ‹ , 7 , – g_ ‹ , \ N #c afb $ , h — g_ ‹ , 3N M L _ ! O , #= fK $ , Q N #E hg $ , h 7 <. , and the corresponding up dates are to be done as #? g_ $ ,-. – g_ ‹ , — g_ ‹ , #? g_ $ ,-. ˜– g_ ‹ , — g_ ‹ , , or, in matrix form, ™ { • š } { • › { • š] y q • s w • ž y o • s š ” y { •-š ™ { • ]s › { • | { •-š Ÿ™ { • ¡¢ › { • . Iterative update equations for : a re derived as follows: = fK ,-. / 012 # $ ~ • 6 ~ 3 £ Œ¤ 7 6 / e # ? g_ = gd L _ $ b # 3= fK TG fK U V fK U 7 $ where all the expectations are taken with respect to ? g_ , ¥ U Œ¤ 6 ¦ U Œ¤ 6 L r , , not explicitly noted for cla rity. The first term, e # 2 ? g_ = gd L _ $ b / e ! # ? fb $ e M L _ ! O = fK Q b e # e M L _ ! O = fK Q $ b , is seemingly mo re difficu lt than what has been encountered so far du e t o expecta tion opera tor over the logarithmic function. Lu ckily, by observing tha t logarithmic function is conc ave, the lower bound ca n be relaxed using Jensen's inequ ality, # N M L _ ! O = fK Q $ § e M L _ ! O # = fK $ Q . In this relaxed lower bound, coordinate ascent now ad- mits a closed form = fK ,-. WGXXG = fK – gQ U , — gQ U , , – gQ U , G fK U N M L _ ! O _ — gQ U , V fK U <. N #? fb $M L _ ! O _ <. . The corresponding expectations of natural parame ters are updated according to #= fK $ ,-. – gQ U , — gQ U , # = fK $ ,-. ˜ – gQ U , — gQ U , , which can compactly b e rewritten in ma trix form as ™ q , n U w , s š p q , \]¨3\]¨p U y { , s w , 7 y q ,-. ™ q , ]s p q , | q ,-. ˜™ q , p q , . The learning algorithm in matrix form is recapitulated in Appendix C of the paper, with the iterativ e updates in the same order as presented a bove. In the presented algo rithm, g roup affiliation varia bles L _ are assumed to be fully observed, i.e. groups are to be explicitly defined beforehand depending on the applica - tion, a s the model d oes not atte mpt to learn the group affiliations. 2.5 V ariation al Bound Expression for the variational lower bound on the marginal loglike lihood of the observed da ta is obtained by expanding (2), a s presented in Appendix B. IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 5 3 E XPERIMENTS In this subsection performa nce of a simple cla ssification method based on the proposed group sparse N MF a lgo- rithm is investigated on three publicly available bench- mark datasets, Ya le [28] and ORL [29], [30] for face recog- nition and JAFFE [31 ] for facial expression recogn ition. Yale dataset consists of 11 grayscale ima ges per subject of 15 subjects, one image per different facial expression of configuration: center-light, w/gla sses, ha ppy, left-light, w/no glasses, normal, right-light, sad, sleepy, surprised and wink. ORL dataset consists of 10 different images of 40 dis tinct subjects, taken at different times, va rying the lightning, facial expressions (open or close eyes, smiling or not smiling) and fa cial de tails (glasses or no gla sses). JAFFE da taset is a collection of 2 13 images of 7 facia l ex- pressions - angry, disgust, fear, happy, neutral, sad sur- prise - posed by 10 Japanese female models. Results a re compared to classificat ion methods based on PCA and relate d N MF algorithms, a nd a lso, where ava il- able, to releva nt published results on the same da tasets with different approaches. MATLAB/Octave implementation of the algorithm as well a s scripts u sed to gen erate the results are available from the author's homepage or will have been received upon request. 3.1 Data Prep rocessing Images in Yale dataset used in the experiments have been prepared by the MIT media labora tory [32] - aligned by rotation and centering of th e manually det ermined loca- tions of the eyes and then cropped. Additionaly, specifi- cally for this paper, after d ownsampling the image s by factor 0. 5 to alleviate computational load, pixelwise ma sk- ing has been applied to remove most of the background , torso a nd t he hair. Finally, histograms of masked imag es have bee n equalized. In case of ORL data set, because faces have been taken a t different angles, centering ha s not been atte mpted. Imag- es have only been downsampled b y factor of 0.5 , with histogram equaliz ation. Images from JAFFE da taset have first been roug hly aligned by conge aling [33], [34], then resized by fa ctor 0.75 and masked leaving only pixels w hich roughl y corre - spond t o loca tions of faces, followed by histogram equali- zation. For all datasets, image s have been vectorized in a way that each image is a colum n vector of input m atrix which is to be fa ctorized. Examples of preproces sed images are shown in Fig. 1. 3.2 Experimental Setting The classificat ion method consists of three consecutiv e stages: im age pr eprocessing stage, dictionary learning stage and cla ssification sta ge. Preprocessing is dependent on the dataset and has been des cribed in detail in the preceeding subsection. In t he dictionary le arning sta ge a dictionary is obtained by the proposed grou p sparse NMF algorithm, or PCA or the standard sp arse NMF alg o- rithms; only in case of the probabilistic group sparsity NMF algorithm are the class labels taken into account, while in other cases the algorithms cannot include this information straightforwardly and is therefore done in a fully unsupervised manner, which is exact ly w here the comparative advantage of the proposed algorithm for classification problems lie s. a) b) c) Fig. 1. Examples of preprocessed fac e samples (in negative): a) Yale, b) ORL, c) JAFFE. To put more weight on role of the quality of the decom- position obtained in the dictionary learning stage, in a sense o f cla ss-to-class discrimina tive information it is a ble to bring out by itself rather than on the role of t he classif i- er, the simple cla ssifier of choice in the classification stag e is 1-nearest neighbor with cosine distance metric. Performance quantifiers have be en obtained b y 5 runs of 10-fold cro ssvalidation for 1 0 different random restarts of NMF algorithms; a t ea ch pass dictiona ry learning by one of the algorithms had been performe d on the tra ining set only, followed by obtaining the representation of th e test set in the feature space (in which the classifier had be en built) by linear least squares with nonnegativit y con- straints [35 ]. NMF parameter optimiza tion has been done using paramete r sweeps u sing the previously mentione d crossvalidation scheme to o btain performance mea sures; the criterion for parameter selection is c hosen to be high- est crossvalidated estimate of maximal accu racy out of 10 NMF restarts with ra ndom initia lizations. Hav ing found the best set of parameters for each of the NMF algorithms, reported accuracies are 1) crossvalidated estimates of maximal accuracy (the criterion itself) out of 1 0 random restarts 2) mean and v ariance of accuracies of the entire crossvalidation scheme. 6 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION nmf_gs : G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª a) nmf_gs : G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª b) nmf_gs : G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) nmf_vb : G hg j © ] ¼ , V hg j «© , G g b ‹ \ , V g b ‹ \© d) Fig. 2 . Yale dataset, samples in feature space, i.e. the coefficient matrix @ ‹ , appropriatedly sorted: a), b) and c) nmf_gs with i ncreas- ing parameter G ‡®½‰„ U ; d ) nmf_vb , with parameters listed below their corresponding subimages. The d arker the shade of grey, the hi gher the magnitude. Number of iterations for family of NM F algorithms has been set to 300. In case o f P CA, data i s projected t o space of most signif icant principal co mponents, and the crossvali dated estimate o f the accuracy is r eported. Decomposition a lgorithms used in t he experiments fo r comparison will be referred t o in short as 1) pca , principal component analysis [36] 2) nmf_kl , NMF with KL-divergence that inclu des a weighted penalty term to e ncourage sparsity in the right matrix [6 ] •¾¿ À Á i G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª à nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª Ä nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) nmf_vb : G hg j © ] ¼ , V hg j «© , G g b ‹ \ , V g b ‹ \© d) Fig. 3. Controlling prevalences of features in labels on Yale dataset - Hinton diagrams of normalized l1 no rm o f the coefficient matrix @ ‹ accumulated accross labels: a), b) and c) nmf_gs with increasing parameter G ‡®½‰„ U ; d) nmf_vb , with param eters listed below their co rre- sponding subimages. Rows correspond to labels and c olumns to features. 3) nmf_vb , a variational Bayesian NMF which ca n model sparse decompositions [11 ] 4) nmf_gs , the proposed varia tional Bayesian NMF with group sparsity constraints. The implementa tion n mf_vb is av ailable from [37 ] a nd nmf_kl is short for nmf_kl_s parse_v , a part of NMFlib v0.1.3 library for MA TLAB [38]. 3.3 Result s and Discussion First, effect of hyperpriors – gQ U and — gQ U on continuous indi- cators of presence of a feature accross group labels, = fK are 15 30 45 20 40 60 80 100 120 140 15 30 45 20 40 60 80 100 120 140 15 30 45 20 40 60 80 100 120 140 15 30 45 20 40 60 80 100 120 140 IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 7 going to the exa mined. S pecifically, it will b e sh own ho w features representative of spe cific group l abels, i.e. w hich are prevalent in specific group labels, can be extracted from data this wa y. Consider the hyperpriors Å U and Æ U of forms n q Ç G . U r È G . U r G É U r È G É U r È G P U r È G P U r Ê Ë , G . U r x G ¬-®‡‡ U G ‡®½‰„ U È G ‡®½‰„ U G ‡®½‰„ U z Ë , G É U r x G ‡®½‰„ U G ¬-®‡‡ U È G ‡®½‰„ U G ‡®½‰„ U z Ë , Ì G P U r x G ‡®½‰„ U G ‡®½‰„ U È G ‡®½‰„ U G ¬-®‡‡ U z Ë , u p q v gQ V U , (11) where S d enotes number of groups . If G ¬-®‡‡ U is sma ller than G ‡®½‰„ U , the hyperprior is such t hat rows o f Å U which contain G Q U r at some set of indices Í will bias the corre- sponding = fK <. F`Í tow a rds larger values, w hich hie rar- chically propagat es to the relate d hidden factors ? fd F`Í , giving their ele ments ? f τ a sparse prior with large ex- pected value if L _ O and with small ex pected value oth - erwise. Thus, such a hyperprior describes the tendency of the coefficient s ? f τ to b e sign ificantly la rge in sample s belonging to a single group only . I n the presented exper- iments numb er of such representative coefficients is cho- sen to be equally distributed among groups, i.e. each group w ill ha ve the same number of representative fea- tures bound. Behavior of prior (11) on the Y a le dataset can be eyeballed from Fig. 2, Fig. 3 and Fig. 4, which all correspond to an d visualize qualitatively typical mappings in th e feature space, representative of seve ral chosen para meter setups. Specifically , enforced by the prior (11) here are 3 repre- sentative features per each label; note that the dataset has 15 la bels, which tota ls to 45 f eatures. The number of sam- ples in the training set is 1 49. Fig. 2 presents samples in th e feat ure space as hea tmaps, having the samples sorted according to their labels and the coe fficients according to their cumulat ive l1 norm per label averaged by number of samples per la bel. As a base- line, an example of nmf_vb decomposition is presented in Fig. 2d). What is observed is that via magnitu de of difference be- tween G ‡®½‰„ U and G ¬-®‡‡ U degree of mixing between specified group-prevalent featu res ca n be controlled. When G ‡®½‰„ U G ¬-®‡‡ U , group sparse decom positions a re obtained with no prior which would bias distinct fea tures to be prevalent accros s s pecific g roups, as depicted b y Fig. 2a ). The case when G ‡®½‰„ U Î G ¬-®‡‡ U resembles th e result of con- catenating the NMF decom positions obta ined for ea ch label separately, i.e. each label has its group of features which are groupwise very s trictly se parated in terms of mixing, represented by Fig. 2 c). Between those two ex- tremes, a sweet spot for obtaining representation spaces with good discriminative properties may b e found, a case which relates to Fig. 2b). I ndicative of t he justifiedness of this line of rea soning is the f act that Fig. 2b) has been obtained using para meters which yielded the best crossvalidated cla ssification performance, as reported in Table 3. nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª a) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª b) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) Fig. 4 . Yale dataset, Hinton diagrams of l1 norm o f th e reciprocal of group indicator vari ables @ U <. accumulated ac cross labels for nmf_ gs with increas ing parameter G ‡®½‰„ U : a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Rows correspond to labels and columns to featur es. From a different pers pective, the same structural pattern over la bels can be recognized using qua ntifiers as in Fig. 3 where, rathe r than presented directly accross sample s, l1 norm of the coefficients ha s been a ccumulated a ccross samples hav ing same label then normalized by cardinali- ties of the corresp onding labels. Furthermore, in Fig. 4 diagrams of the sam e type but h aving the reciprocal of the group indicat or mat rix, @ U <. , as the target variable bear resemblance of a high degree to Fig. 3 a) b ) and c) , reason for which is that @ U directly specifies the prevalences of the features in ea ch of the groups and propagates them hierarchica lly to va riables ? fb , a ccording to (5). Impact of choice of G ¬-®‡‡ U and G ‡®½‰„ U on classification per- formance is illustrated on Fig. 6, Fig. 7 and Fig. 10 for Yale, OR L and JAFFE datasets, resp ectively. On Yale dataset, for a fixed G ¬-®‡‡ U as G ‡®½‰„ U increases the accuracy improves, hitting a peak a fter which it begins to deterio - rate, but not below the case w hen G ¬-®‡‡ U = G ‡®½‰„ U . Qualita- tively similar is t he beha vior on ORL dataset, but the 8 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION accuracy improveme nt is more modest. On JAFFE da- taset, improvement in the accuracy is notable but, more significantly, a pronounced droop when G ‡®½‰„ U Î G ¬-®‡‡ U is present. a) b) c) Fig. 5. Y ale dataset, extracted features (in negative) for nmf_gs with increasing parameter G ‡®½‰„ U ; a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Other parameters are G hg j ©]ª , V hg j «© , G ¬-®‡‡ U ¯« , V U \¶ª . Explanation for this effect is tha t, on JAFFE da taset, the droop is caused by a t oo restrictive mixing (Fig. 8c)), re- sulting in decomposition s w here same subjects with dif - ferent expressions exhibit hardly any co mmon features, i.e. expression-independent and subject- specific infor- mation is not shared betw een groups, and, consequently , the fea tures are forced to be too holistic to extract expres- sions exclusively, (Fig. 9c)). The same ef fect is behin d th e behavior with the Yale data set, howeve r, Yale da taset is such that distances be tween same subjects hav ing differ- ent expressions or c onfiguration is sma ller than distances between different subjects with same expres sions or un- der same configuration, allowing satisfactory cla ss dis- crimination even with such extremely holistic features (Fig. 5 ). To rem ind the rea der, the goal on Yale dataset is subject recognition regar dless of different expres sions and configuration and on JAFFE face expression recognition regardless of the subject ma king it. Experimental results on the Ya le dataset are summarized in Table 3. Compared to the classification using nmf_kl and nmf_ vb , improvement in the performance turned out to be significant when cl assification is performe d in fea - ture subspaces obtained by nmf_gs. It showed significant- ly higher average peak performa nce and higher a verage performance, with smaller variance also. Fig. 6. Yale dataset, dependency of mean cla ssific ation accuracy using nmf_gs on G ¬-®‡‡ U and G ‡®½‰„ U . Error bars represent crossvalidated estimates of maximal and minimal accuracies of a number of nmf_gs runs. Other parame ters are fixed as G hg j ©]ª , V hg j «© , V U \¶ª . Algorithm pca nmf_kl nmf_vb nmf_gs Accuracy maximum 0.7987 0.9267 0.8875 0.9825 m ean ± variance 0.7987 ± 0.0000 0.8690 ± 0.0054 0.8246 ± 0.0077 0.9417 ± 0.0036 Subspace dimension 73 120 60 45 Table 3. Classificat ion results on the Yale d ataset On ORL dataset, a s shown in Ta ble 4, improvements are still observed, but to a far lesser extent. In the community, classification problem on the ORL dataset is known to lay on the easier side, as pca alone gives high accuracy. Re- garding NMF algorithms, it can be concluded that sparsity constrain s only are su fficient to g ive performance of high quality, leaving little space for improvement by group sparsity constraints. Similar a re t he results on JAFFE dat aset, pre sented in Table 5, but the improvement when using gsNMF i s less marginal - compa red to the result s in Table 6 it can be seen that in this case nmf_ gs in conjunction with 1-N N classifier can output cla ssification results on the level of [39], where discrete wavelet tran sform w ith 2D linear discriminant ana lysis (LDA ) is used to find features fol- lowed by clas sification using support v ector machines with different kernel choice s. Somewha t lower accura cies have been reported in [40] and [41]: experimental setup used in [40 ] consists of processing the samples by Ga bor filtering, then sampling at fiducial points followed by PCA to get t he features, fina lized by LDA as classifier, and [41 ] uses Gabor filtering to g et the features a nd two- layered perceptron for la bel discrimination. I n [42] the authors use classifier based on Gaussian proces ses in th e original pixel space. IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 9 Fig. 7. ORL dataset, dependency of mean classification accuracy using nmf_gs on G ¬-®‡‡ U and G ‡®½‰„ U . Error bars represent crossvalidated estimates of maximal and minimal accuracies of a number of nmf_gs runs. Other parame ters are fixed as G hg j ©]Ï , V hg j \© , V U \¶ª . Algorithm pca nmf_kl nmf_vb nmf_gs Accuracy maximum 0.9605 0.9775 0.9780 0.9885 m ean ± variance 0.9605 ± 0.0000 0.9529 ± 0.0013 0.9511 ± 0.0013 0.9750 ± 0.0006 Subspace dimension 67 140 60 16 0 Table 4. Classificat ion results on the ORL dataset Several other reported resul ts on the same d atasets are known to the author but are unfortun ately of little use as the results have been evaluat ed nonuniformly accross publications. From the practical point of view, however, even thou gh peak perform ance of classifi cation wit h nmf_gs is admira- ble, the problem of a priori selection of a nmf_ gs decompo- sition which is bound to pro duce this peak rem ains open. This problem is not characteristic only of n mf_gs , but a lso of other NMF methods due to dependency of decom posi- tions on initial values. Even though variational Bayes methodology allows calculat ion of variat ional bound which model comparisons can be made based upon, in the presented experiments the va riational bound has bee n found to be uncorrelated w ith the classif ication accuracy, which is attributed to the f act th at the classifier s tands outside the Bayesian framew ork, i.e. that no objective directly connected with the class ification had b een em- bedded in the probabilistic m odel. Still, a solut ion always remains, which is to evaluate classification performance on a separate valida tion set and use i t as an optimaliity indicator to determine w hich dictionary to select. nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª a) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª b) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) Fig. 8. Controlling prevalences of features in la bels on JAFFE dataset - H inton diagrams of normalized l1 norm of the coefficient matrix @ ‹ accumulated accross l abels for nmf_gs with increasing pa ramete r G ‡®½‰„ U : a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Rows corre- spond to labels and c olumns to featur es. a) b) c) Fig. 9. JAFFE dataset, extracted features (in negative) for nmf_gs with increasing parameter G ‡®½‰„ U : a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Other parameters are G hg j ©]ª , V hg j «© , G ¬-®‡‡ U ¯« , V U \¶ª . 4 C ONCLUSION A probabilistic formu lation of NM F with group sp arsit y constraints has been laye d out w ith an efficient varia tion- al Bayesian algorithm for approximate learning of the model paramet ers. It has been shown how preva lence of specific featu res accros s groups and the degree of t heir mixing betw een groups can be controlled. Having ident i- ty-mapped the class labels to a more general notion of groups, th e presented model ha s be en u tilized as a super- vised feature ext ractor in face recognition and facial ex- pression recognition applications an d b eneficial effects o f such decomposition subspaces on classification perfor- mance hav e been observed. 10 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION Fig. 10. JAFFE dataset, dependency of mean classification accuracy using nmf_gs on G ¬-®‡‡ U and G ‡®½‰„ U . Error bars represent crossvalidated estimates of maximal and minimal accuracies of a number of nmf_gs runs. Other parame ters are fixed as G hg j ©]Ï , V hg j «© , V U \¶ª . To contribute to commun ity where easily rep roducible research is apprecia ted, the impleme ntation used in th e experiments is made publicly availab le (which unfortu- nately is not the case still too often). Algorithm Pca nmf_kl nmf_vb nmf_gs Accuracy maximum 0.9067 0.9267 0.9295 0.9438 m ean ± variance 0.9067 ± 0.0000 0.8690 ± 0.0054 0.8597 ± 0.0063 0.8789 ± 0.0051 Subspace dimension 18 28 14 42 Table 5. Classificat ion results on the JAFF E dataset Method Shih et al. [39] Lyons et al. [40] Zhang et al. [41] Cheng et al. [42] Accuracy 0.9413 0.92 0.901 0.86 89 Table 6. Relevant classification results on the JAFFE dataset reported in the literature where accuracy has been obtained by 10-fold crossvalidation Future work on the presented subject includes pursuing modifications of the group sparse formulation which would work in semi-supervised settings. The model should ideally allow efficient inference and learning o f the labels of u nlabeled data, avoiding sampling tech- niques for execution speed if possible. A CKNOWLEDGMENTS This work was su pported by the Croatian Ministry of Science, Education and Sports through the project "Com- putational Intelligence M ethods in Mea surement Sys - tems”, No. 098-0982560-2565 B IBLIOGRAPHY [1] D. D. Lee and H. S. Seung, “ Learning the parts of objects by non-negative matr ix factorization.,” N ature , vol. 401, pp. 7 88– 791, 1999. [2] D. Donoho and V. Stodden, “When does non-negative m atrix factorization give a correct decompo sition into parts?,” NIPS , vol. 16, pp. 1141– 1148, 2003. [3] P. O. Hoyer , “Non-negat ive matrix factori zation with sparseness cons traints,” Journal of M achine Learning Rese arch , vol. 5, pp. 1457–1 469, 2004. [4] S. Z. Li, X. Hou, H. Zhang, and Q. Cheng, “Learn ing spatially localized, parts-based rep resentati on,” Proceedings of t he 2001 IEEE Computer Soc iety Conference o n Computer Vision an d Pattern Recognition CVPR 2 001 , vol. 1, pp. 207 –212, 2001. [5] A. Pascu al-Montano, J. M. C arazo, K. Kochi, D. Lehmann, and R. D. Pascual-Mar qui, “Nonsmoo th nonnegative matrix factorization (nsNMF ).,” IEEE Tra nsactions on Pattern Analysis and Machine Intelli gence , vol. 28, no. 3, pp. 403–15, Mar. 200 6. [6] T. V. T. V irtanen, “Monaura l sound sou rce separation by nonnegative matr ix factorization with temporal continu ity and sparseness criteria, ” IEEE Transact ions On Audio Speec h And Language Processing , vo l. 15, pp. 10 66–1074, 2007. [7] R. Zhi, M. Flierl, Q. Ruan, and W. B. Kleijn, “Graph-p reserving sparse monnegative matrix factori zation with applicat ion to facial expression re cognition,” IEEE Trans actions on Systems, Man and Cybernetics , vol. 41, pp. 38–52, 20 11. [8] D. Cai, X . He, J. Han, and T . S. Huang, “Gr aph regularized non- negative matrix fa ctorization for d ata representation. ,” IEEE Transactions on Pattern An alysis an d Machine Intelligence , vol. 33, pp. 1548–1560, 201 0. [9] Z. Zh ang and K. Zhao, “Low-r ank matr ix approximation with manifold regulari zation.,” IEEE Transact ions on Pattern Ana lysis and Machine Intelli gence , vol. 35, pp. 17 17–29, 2013. [10] C. Fevotte and T. Cemgi l, “Nonnegative m atrix factorizat ion as probabilistic inference in composite models,” Proc. 17th European Signal Process ing Conferen ce (EUSIPCO’09) , pp . 1–5, 2009. [11] A. T. Cemgil, “Bayesian infer ence fo r nonnegative matrix factorisation models, ” Computation al Intelligence and Neuroscience , vol. 20 09, Jan. 2009. [12] O. Dikmen and C. Fevotte , “Maximum margina l likelihood estimation for nonneg ative dictionary le arning in the gamm a- Poisson mo del,” IEEE Transactions on Si gnal Processing , vol . 60, no. 10, pp. 5163–5 175, Oct. 2012. [13] M. N. Schmidt and H. L aurberg, “Nonnegative matrix factorization with G aussian process priors,” Computational intelligence and neurosc ience , 2008. IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 11 [14] T. Virtanen, A. T. Cemgi l, and S. Go dsill, “Bayesian extens ions to non-negative matr ix factorisation fo r audio signal modelling,” 2008 IE EE International Conference on Acoust ics Speech and Signal Process ing , pp. 1 825–1828, 2008. [15] D. Blei, P. Cook, and M. Ho ffman, “Bayes ian nonparametr ic matrix factorization for recorded mu sic,” In Proceedings of t he International Conference on Machine Learning (ICML) , pp . 439– 446. [16] H. Lee and S. Choi, “Gro up nonnegative matrix f actorization for EEG classific ation,” Journal of Mach ine Learning Research - Proceedings , vol. 5, pp . 320–327, 20 09. [17] J. Kim, R. Monteiro, and H. Park, “Gro up sparsity in nonnegative matr ix factorization,” In proc. of the 201 2 SIAM International Conference on Data Mi ning (SDM) , pp. 8 51–862, 2012. [18] B. Shin and A. Oh, “Bayes ian group nonnegat ive matrix factorization for EEG analysis,” ar Xiv:1212.4347 , 20 12. [19] A. Lefevre, F. Bach, and C. Févotte, “Itakur a-Saito nonnegative matrix factorization with group spars ity,” IEEE Internationa l Conference on Acoust ics Speech and S ignal Processing , vol . 31, pp. 1–4, 2011. [20] J.-T. Chien and H.-L. Hsieh, “Bayesian gro up sparse learning for music sou rce separation,” EUR ASIP Journal on Au dio, Speech, and Music Processin g , vol. 18, p. 15, 2 013. [21] S. Zafeiriou, A. Tefas, I. Buc iu, and I. Pitas, “E xploiting discriminant informa tion in nonne gative matrix facto rization with application to fr ontal face verificat ion,” IEEE Transacti ons on Neural Networks , vo l. 17, pp. 683–69 5, 2006. [22] Y. Zhu, L. Jing, and J. Yu, “Te xt clustering via cons trained nonnegative matr ix factorization,” 2011 IEEE 11th Internat ional Conference on Data M ining , vol. 0, pp . 1278–1283, 2011. [23] R. He, W.-S. Zheng, B.-G. Hu, and X.-W. Kong , “Nonneg ative sparse coding for d iscriminative sem i-supervised learning, ” CVPR 2011 , pp. 28 49–2856, 2011. [24] H. Liu, Z. Wu, S. Member, a nd X. Li, “Constra ined nonnegative matrix factorization for image repr esentation,” IEEE Transactions on Pattern An alysis an d Machine Intelligence , vol. 34, pp. 1299–1311, 201 2. [25] C. Goutte and E. Gaussier, “Relatio n between PLSA and NMF and implications, ” Proceedings of th e 28th Annual Internat ional ACM SIGIR Conferen ce on Research and Deve lopment in Information Retrieva l , pp. 601–602, 200 5. [26] J. M. Winn, “Variational me ssage passing and its applications, ” Ph.D. thesis, Department of Physics, Un iversity of Cambridge , 2003. [27] P. J. Garrigues and B. A. O lshausen, “Gro up sparse coding with a Laplacian scale m ixture prior,” Advanc es in Neural Informati on Processing Systems , vol. 23, pp. 1–9, 2010. [28] “Yale face database.” [Onl ine]. Available: http://cvc.yale.edu/ projects/yalefa ces/yalefaces.html. [Ac cessed: 01-Jul-2013]. [29] F. S. Samaria and A. C. H arter, “Paramete risation of a stoch astic model for human fa ce identificatio n,” Proceedings of 19 94 IEEE Workshop on Applicati ons of Comput er Vision , vol. 13, pp. 138–142, 1994. [30] AT&T Laboratories Cambr idge, “The d atabase of faces,” 2 002. [Online]. Available : http://www.cl.cam.a c.uk/research/ dtg/attarchive/faced atabase.h tml. [Accessed: 01-Jul- 2013]. [31] M. J. Lyons, M. Kamachi, and J. Gyoba, “Jap anese female facial expressions (JAF FE), database of digita l images,” 1997. [Online]. Available : http://www.k asrl.org/jaffe.html. [Acc essed: 01-Jul-2013]. [32] Vision and Modeling Gro up MIT Media Labor atory, “The normalized Yale face database.” [ Online]. Available: http://vismod.medi a.mit.edu/vismo d/classes/mas622- 00/datasets/. [Access ed: 01-Jul-2013]. [33] G. B. Huang, V. Jain, and E. Learned-Miller, “Unsu pervised joint alignment of comp lex images ,” IEEE 11th Internat ional Conference on Computer V ision (200 7) , pp. 1–8, 2007. [34] University of Massachuss etts Vision Labor atory, “Methods and theory,” Congealin g - source code . [Online]. Available: http:// vis- www.cs.umass.edu/ congeal.html. [Accessed: 01-Jul-2 013]. [35] C. L. Lawson and R. J. H anson, “Solving le ast squares problems,” vol. 1 5, Prentice-Hall, 197 4, p. 337. [36] H. Hotelling, “Analysis of a complex of statist ical variables into principal components, ” Journal of Educati onal Psychology , vol. 24, pp. 417–441, 1933. [37] A. T. Cemgil, “Variation al Bayesian nonneg ative matrix factorization.” [Online]. Available: http://www.cmpe.bo un.edu.tr/~ce mgil/bnmf/. [Accessed: 01- Jul-2013]. [38] G. Grindlay, “NMFLib - Eff icient Matlab library implementing a number of common NMF variants.” [ Online]. Availab le: https://code.goo gle.com/p/nmflib/. [Accessed: 01-Jul-2 013]. [39] F. Y. Shih, C. F. Chuang, an d P. S. P. Wang, “Performance comparisons of fac ial expression r ecognition in JAFFE database,” Internation al Journal of Patte rn Recognition and Artificial Intelligence , vol. 22, pp. 44 5–459, 2008. [40] M. J. Lyons, J. Budynek, and S. Akamatsu, “Automatic classification of sing le facial image s,” IEEE Transactions on Pattern Analysis an d Machine Intelligence , vol. 21, pp. 135 7–1362, 1999. [41] Z. Zhang, M. Lyons, M. Sc huster, and S. Ak amatsu, “Comparison between geo metry-b ased and Gabor-w avelets- based facial express ion recognitio n using multi-layer perceptron,” Proceed ings Third IEE E International Conferenc e on Automatic Face an d Gesture Recognit ion , pp. 454–459, 1 998. [42] F. C. F. Cheng, J. Y. J. Yu, an d H. X. H. Xiong , “Facial expression recognit ion in JAFFE d ataset based on Gauss ian process classificat ion,” IEEE Transactions on Neural Networks , vol. 21, pp. 1685– 1690, 2010. Ivan Ivek received his B.S. in electrical engineering from the Faculty of Electrical Engineering and Computing, University of Zagreb, Zagreb, Croatia in 200 7. He joined the Ru đ er B oškovi c Institute in 2008, where his current position is Research Assistant for the Computational Intelligenc e Methods in Measurement Systems project. Currently, he is pursuing his P h.D. in electronics at the Faculty of Electrical Engineering and Computing, University of Zagreb, Croatia. 12 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION Appendix A - Probab ility Densit y Functions By \ r (column) vector of one s and by ˜ ] elementwise digam ma function, ˜A Ñ Ñ… ÒA . BFccBC A = 012 ! = A = ! Ó A \ , with = Ô © # A $ = ; WGXXG A G V 012 ! . Õ A G ! \ A ! G V ! Ó G , with G Ô © V Ô © ; # A $ GV , # A $ Ö G V ; % A ! G ! \ × G V G Ó G ; @ABCDCEFGH A V WGXXG A \ V ; ƒ>HEFCBXFGH Ø Ù A . Ì A * Ú Û c Ù . Ì * Ú Ü M c ! e A g g 012 Ó c \ e A g g ! Ó A g \ g , with e g g \ , e A g g c ; Ù # A . $ Ì # A * $ Ú c Ù . Ì * Ú ; % A r ! Ó c \ ! e # A g $ g g N # Ó A g \ $ g ! # M c ! e A g g $ ; FÝFOÞHDE ØÙ A . Ì A * Ú Ù > . Ì > P ÚÜ 012 ßÙ > . ! \ Ì > P ! \ Ú ’ Ù A . Ì A * Ú Ó e > Q P Q ! N Ó > g P Q à , with e A Q Q =1, > Q Ô © ; Ù # A . $ Ì # A * $ Ú Ù Ö > . Ì Ö > P Ú ! Ö e > Q P Q ; % Ø A Ù A . Ì A * Ú Ü ! Ó e > Q P Q R. Ó e > Q P QR . e > Q P Q R. ! S × e > Q P QR . ! N > Q ! \ × > Q P Q R. ; FcOÝDED A Ù . Ì * Ú 012 ß Ù . Ì * Ú ’ Ù M A ! \ Ì M A ! S Ú à , with e g g \ ; Ù # M A ! \ $ Ì # M A ! S $ Ú Ù . Ì P Ú ’ ; % A ! e Q Q P Q R . ; IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 13 Appendix B - V ariationa l Bound Applying (2) on the presente d model, the b ound is expanded as " , Ž # A ab c h d_ $ á •d‚ 6 h_ Ž # c afb E af ? fb $ á ‘Œ• 6 j ‘Œ 6 ‹ Œ• 6 h g_ N % c afb , h g _ Ž # E af G hg j V hg j $ j ‘Œ 6 h g N % E af , h g Ž # ? fb L _ = g d $ ‹ Š‚ 6 â ‚ 6 U Šd 6 g _ N % ? g_ , g _ Ž # = fK G fK U V fK U $ U Œ¤ 6 g Q N % = fK , g Q Ž #L _ ã bd $ â ‚ 6 ä •d 6 _Q N % L _ , _ Ž # u ã b. È ã _P v ’ u > b. È > bP v ’ $ ä •d 6 _ N % u ã b. È ã _P v ’ , _ . With update expressions o rdered as in Appendix C and bound calcula ted where marked, substituti ons ˜ – af j , # E hg $ ,-. ! — af j , ˜ – g_ ‹ , # ? g_ $ ,- . ! — g_ ‹ , – af j , G hg j N #c hg_ $ , _ – g_ ‹ , \ N #c afb $ , h can be used to eliminate more costly evalu ations of digamma functi on. Then, the bound adopts the form " , ! Ž y o , y { , Ó \ 3012 | o , s 012 | { , 7 h_ Ž å! ]s 3012 | o , ]s | o , 7 s 012 | { , 012 | o , s 3012 | { , ]s | { , 7] 3012 | o , s 012 | { , 7 æ ç h _ Ž 3 !\] p o ] ” s y o , ! Ó n o ! n o ]s p o ™ o , ]s 3 › o , \7 Ó 3™ o , 77 h g Ž !y q , s w , ’ ]s y { , y q , s w , ’ ! n { ]s p { ™ { , ]s 3 › { , \7 Ó 3™ { , 7 g _ Ž 3!\] p q ] ” s y q , 3n q ! \7]s | q , ! n q ]s p q ! Ó 3n q 77 g Q Ž 3\ ! ™ q , 7 s ×3™ q , 7 › q , ™ q , Ó 3™ q , 7 g Q Ž è ! \ ]s é , ’ _Q Ž è s \ r ! e \ Q ]s ×è s \ r _ ! Ž è ! \ ]s ×è _Q , (14) where by e \ Q the number of columns of ; is de noted. 14 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION Appendix C - Summary of the Learning A lgorith m Inputs: n o p o n q p q è Initialize (randomly): y o J | o J y { J | { J } o J } { J w J y q J | q J é J ê J ë r u ë . È ë g È v ’ ë g F C © ; Repeat: “ ,-. ] 012| o , s 012| { , ” } { ,-. 012 | { , ]s 012| o , ’ s “ , } o ,-. 012 | o , ]s “ , s 012| { , ’ ™ o , \]s n o } o , › o , \] \] p o ” š s y { , ’ ” y o ,-. ™ o , ]s › o , ™ { , \ } { , › { , \] y q , s w , Ë y o , ’ s š ” y { ,-. ™ { , ]s › { , Optional: calcula te bound according to (14) | o ,-. ˜™ o , › o , | { ,-. ˜™ { , › { , ™ q , n q w , s š p q , \]¨3\]¨p q y { , s w , 7 y q ,-. ™ q , ]s p q , | q ,-. ˜™ q , p q , ì , é , y o , Ë s y q , š s | q , w ,-. ì , ]¨ì , s š ê , è , w , é ,-. × 3ê , 7 ! × ê , s š C C \ until termina tion criterion not satisfied. IVEK, I.: SUPERV ISED DICT IONARY LEARN ING BY A VARIAT IONAL BAYESIAN GR OUP SPARS E NONNEGAT IVE MATRIX FACTO RIZATION 15 Appendix D - Additional Figures CXí À îc i G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª à nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª Ä nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) Fig. 1 1. Controlling prevalences of features in labels on Yale dataset - Hinton diagrams o f normalized l1 norm of the coefficient matrix @ ‹ accumulated accross labels, with corresponding features overlayed, for nmf_gs with increasing parameter G ‡®½‰„ U ; a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Rows correspond to l abels and columns t o features. 16 IVEK, I.: SU PERVISED DICTIONAR Y LEARN ING B Y A VARIATIONAL BAYESIAN GROUP S PARSE NONNEGATIVE MATRIX FACTO RIZATION nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q ´µ , V U \ ¶ ª a) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ·¸ , V U \ ¶ ª b) nmf_gs ; G hg j © ] ª , V hg j «© , G ¬-®‡‡ U ¯« , ° ±²¢³ q µ¹º» , V U \ ¶ ª c) Fig. 12. Controlling prevalences of features in labels o n JAFFE dataset - Hinton d iagrams o f normalized l1 norm o f the co efficient matrix @ ‹ accumulated accross labels, with corresponding features overlayed, for nmf_gs with increasing parameter G ‡®½‰„ U : a) G ‡®½‰„ U ¯« , b) G ‡®½‰„ U «Ïª , c) G ‡®½‰„ U «©Ð¼ . Rows corr espond to labels and columns to featur es.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment