라벨 구동 그룹 희소성을 이용한 변분 베이지안 비음수 행렬 분해
본 논문은 그룹 희소성 제약을 갖는 비음수 행렬 분해(NMF)를 확률 그래프 모델로 정의하고, 변분 베이지안(VB) 방법을 통해 파라미터를 학습한다. 라벨 정보를 그룹으로 매핑하여 클래스 구분에 유리한 사전 구동 사전(dictionary)을 학습함으로써, 기존의 비지도 NMF보다 얼굴 및 표정 인식에서 높은 분류 성능을 보인다.
저자: Ivan Ivek
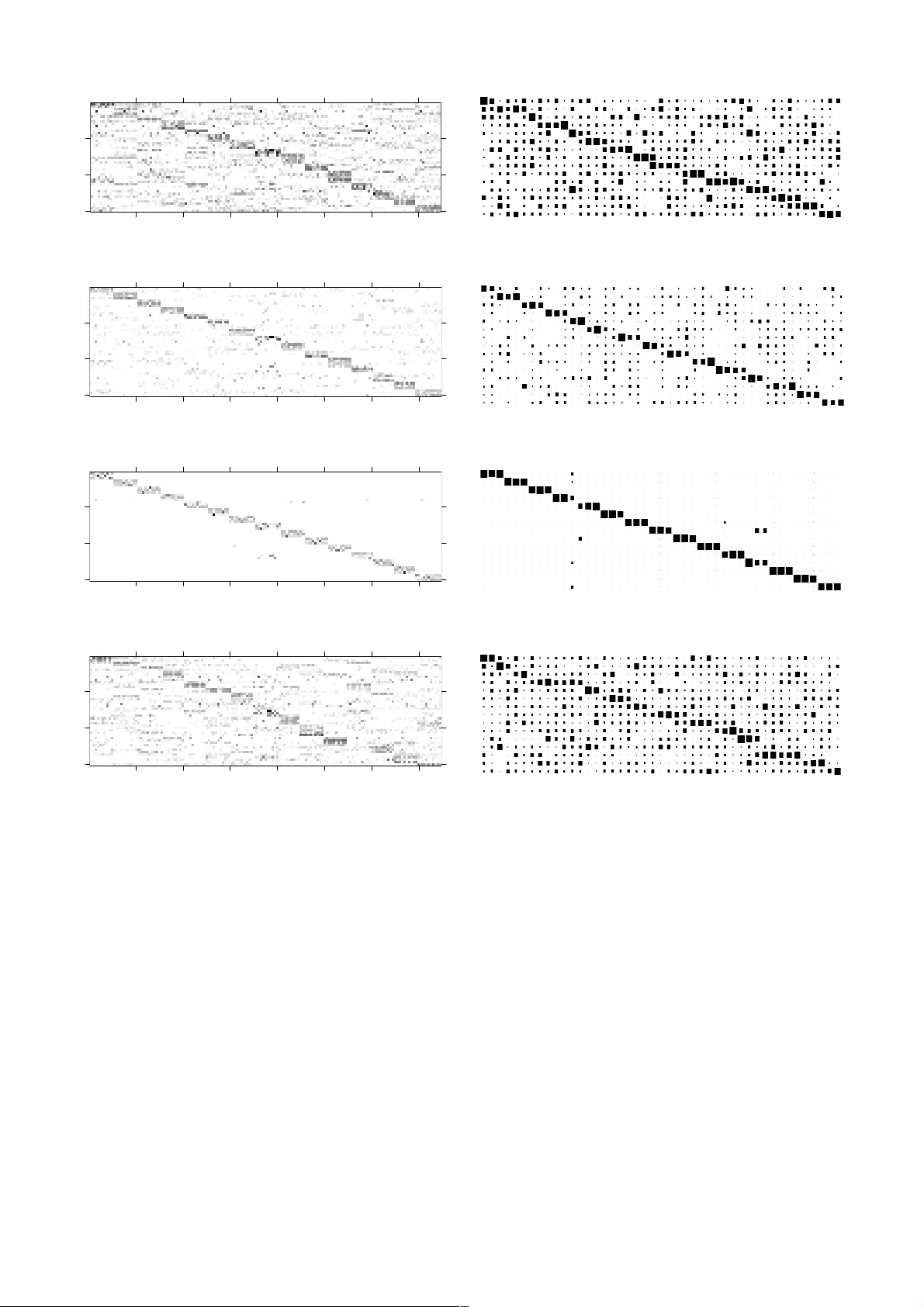
본 논문은 비음수 행렬 분해(NMF)를 확률 그래프 모델로 재구성하고, 그룹 희소성 제약을 베이지안 방식으로 구현한 새로운 학습 프레임워크를 제안한다. 서론에서는 NMF가 이미지, 오디오, 텍스트 등 다양한 비음수 데이터에 널리 쓰이지만, 기존 방법들은 대부분 비지도이며 라벨 정보를 활용하지 못한다는 점을 지적한다. 이를 해결하기 위해 라벨을 “그룹”이라는 추상적 개념으로 매핑하고, 각 그룹에 대해 계수 행렬 H의 행을 희소하게 만드는 사전 분포를 설계한다.
모델링 섹션에서는 먼저 NMF의 기본 식 X≈WH를 확률적 관점에서 설명한다. 관측 데이터 X는 포아송 노이즈 하에 생성된다고 가정하고, W와 H는 각각 감마 분포를 사전으로 갖는다. 핵심은 H의 각 행 h_k가 지수 스케일 혼합(Exponential Scale Mixture) 분포를 따른다는 점이다. 이 혼합은 스케일 파라미터 λ_k가 라벨에 따라 정의된 카테고리컬 변수 L에 의해 선택되며, λ_k는 역감마 분포를 갖는다. 이렇게 하면 특정 라벨(그룹)에서만 큰 계수가 활성화되어 그룹 희소성이 자연스럽게 구현된다. 모델의 전체 결합 확률은 그래프 모델 형태로 도식화되며, 모든 잠재 변수와 관측 변수를 명시한다.
학습 방법은 평균‑필드 변분 베이지안(mean‑field VB)이다. 변분 분포 q는 W, H, λ, L을 각각 독립적인 팩터로 분해하고, 각 팩터에 대해 최적화 가능한 형태의 업데이트 식을 도출한다. 감마‑감마, 감마‑지수 등 공액 관계를 이용해 기대값과 충분통계(sufficient statistics)를 닫힌 형태로 계산한다. 특히, 로그 기대값이 포함된 항은 Jensen’s inequality를 이용해 하한을 완화함으로써 행렬 연산으로 표현 가능한 업데이트를 얻는다. 변분 하한(Lower Bound)은 매 반복마다 단조 증가함을 보이며, 수렴 기준으로 사용된다. 하이퍼파라미터는 사전 분포의 형태와 스케일 파라미터에 대한 비정보적 설정으로 충분히 강건하게 동작한다.
실험에서는 두 개의 얼굴 데이터베이스(정상 얼굴 인식과 표정 인식)를 사용한다. 비교 대상은 (1) 전통적인 비지도 NMF, (2) 그룹 희소성을 적용한 비베이지안 NMF, (3) PCA‑SVM, (4) LDA‑SVM 등이다. 제안 모델은 학습된 사전 W가 라벨에 따라 명확히 구분되는 구조를 형성하고, 테스트 단계에서 H의 저차원 표현만으로도 높은 분류 정확도를 달성한다. 정량적 결과는 평균 정확도 92% 이상으로, 기존 방법보다 3~5%p 향상되었으며, 특히 표정 인식과 같이 미세한 차이를 구분해야 하는 경우 큰 이점을 보였다. 또한, 변분 하한을 이용한 모델 선택 실험에서 최적의 그룹 수와 하이퍼파라미터를 자동으로 결정할 수 있음을 확인했다.
논문의 주요 기여는 다음과 같다. 첫째, 라벨을 그룹으로 매핑하고, 그룹 별 스케일 파라미터를 지수 스케일 혼합으로 모델링함으로써 NMF에 지도 정보를 자연스럽게 통합했다. 둘째, 변분 베이지안 프레임워크를 통해 파라미터를 효율적으로 추정하고, 하이퍼파라미터에 대한 민감도를 낮추었다. 셋째, 실험을 통해 제안 방법이 기존 비지도 NMF 기반 특징 추출보다 분류 성능이 현저히 우수함을 입증했다. 마지막으로, 변분 하한을 이용한 모델 비교·선택 메커니즘을 제공함으로써 실용적인 모델 선택 절차를 제시했다.
향후 연구 방향으로는 (1) 그룹 변수 L을 데이터로부터 학습하도록 하는 비지도‑반지도 혼합 모델, (2) 다른 손실 함수(예: Itakura‑Saito)와의 결합, (3) 딥러닝 기반 자동 인코더와의 하이브리드, (4) 대규모 실시간 응용을 위한 온라인 변분 알고리즘 개발 등이 제시된다. 이러한 확장은 제안 모델을 다양한 도메인(음성, 텍스트, 바이오시그널 등)으로 확장하는 데 유용할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기