Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Despite the widespread practical success of deep learning methods, our theoretical understanding of the dynamics of learning in deep neural networks remains quite sparse. We attempt to bridge the gap between the theory and practice of deep learning b…
Authors: Andrew M. Saxe, James L. McClell, Surya Ganguli
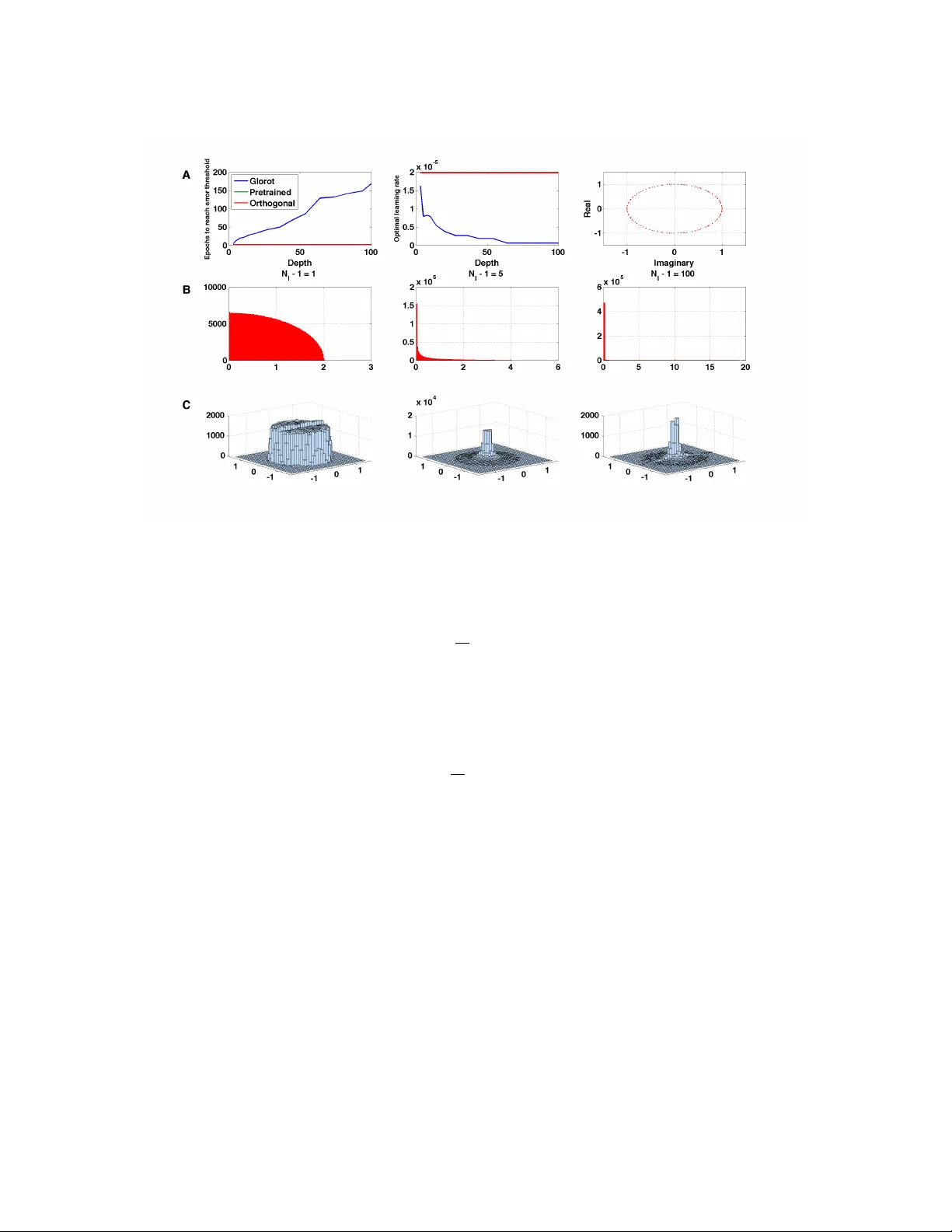
Exact solutions to the nonlinear dynamics of lear ning in deep linear neural networks Andrew M. Saxe (asaxe@stanf ord.edu) Department of Electrical Engineering James L. McClelland (mcclelland@stanf ord.edu) Department of Psychology Surya Ganguli (sganguli@stanf ord.edu) Department of Applied Physics Stanford Univ ersity , Stanford, CA 94305 USA Abstract Despite the widespread practical success of deep learning methods, our theoretical under- standing of the dynamics of learning in deep neural networks remains quite sparse. W e attempt to bridge the gap between the theory and practice of deep learning by systemati- cally analyzing learning dynamics for the restricted case of deep linear neural networks. Despite the linearity of their input-output map, such networks hav e nonlinear gradient de- scent dynamics on weights that change with the addition of each new hidden layer . W e show that deep linear networks e xhibit nonlinear learning phenomena similar to those seen in simulations of nonlinear networks, including long plateaus followed by rapid transitions to lo wer error solutions, and faster con vergence from greedy unsupervised pretraining ini- tial conditions than from random initial conditions. W e provide an analytical description of these phenomena by finding new exact solutions to the nonlinear dynamics of deep learning. Our theoretical analysis also rev eals the surprising finding that as the depth of a network approaches infinity , learning speed can nev ertheless remain finite: for a special class of initial conditions on the weights, v ery deep networks incur only a finite, depth independent, delay in learning speed relati ve to shallo w networks. W e sho w that, under certain conditions on the training data, unsupervised pretraining can find this special class of initial conditions, while scaled random Gaussian initializations cannot. W e further ex- hibit a ne w class of random orthogonal initial conditions on weights that, lik e unsupervised pre-training, enjoys depth independent learning times. W e further show that these initial conditions also lead to faithful propagation of gradients ev en in deep nonlinear networks, as long as they operate in a special re gime known as the edge of chaos. Deep learning methods have realized impressiv e performance in a range of applications, from visual object classification [1, 2, 3] to speech recognition [4] and natural language processing [5, 6]. These successes have been achiev ed despite the noted difficulty of training such deep architectures [7, 8, 9, 10, 11]. Indeed, many explanations for the difficulty of deep learning hav e been adv anced in the literature, including the presence of many local minima, lo w curvature regions due to saturating nonlinearities, and exponential gro wth or decay of back-propagated gradients [12, 13, 14, 15]. Furthermore, many neural network simulations ha ve observed 1 strikingly nonlinear learning dynamics, including long plateaus of little apparent improvement follo wed by almost stage-like transitions to better performance. Howe ver , a quantitati ve, analytical understanding of the rich dynamics of deep learning remains elusi ve. For example, what determines the time scales over which deep learning unfolds? How does training speed retard with depth? Under what conditions will greedy unsupervised pretraining speed up learning? And how do the final learned internal representations depend on the statistical regularities inherent in the training data? Here we provide an exact analytical theory of learning in deep linear neural networks that quantitatively answers these questions for this restricted setting. Because of its linearity , the input-output map of a deep linear network can always be re written as a shallo w network. In this sense, a linear network does not gain ex- pressiv e power from depth, and hence will underfit and perform poorly on complex real w orld problems. But while it lacks this important aspect of practical deep learning systems, a deep linear network can nonetheless exhibit highly nonlinear learning dynamics, and these dynamics change with increasing depth. Indeed, the training error, as a function of the network weights, is non-con vex, and gradient descent dynamics on this non-con vex error surface exhibits a subtle interplay between different weights across multiple layers of the network. Hence deep linear networks provide an important starting point for understanding deep learning dynamics. T o answer these questions, we deriv e and analyze a set of nonlinear coupled differential equations describing learning dynamics on weight space as a function of the statistical structure of the inputs and outputs. W e find exact time-dependent solutions to these nonlinear equations, as well as find conserved quantities in the weight dynamics arising from symmetries in the error function. These solutions provide intuition into how a deep network successi vely b uilds up information about the statistical structure of the training data and embeds this information into its weights and internal representations. Moreo ver , we compare our analytical solutions of learning dynamics in deep linear netw orks to numerical simulations of learning dynamics in deep non-linear networks, and find that our analytical solutions provide a reasonable approximation. Our solutions also reflect nonlinear phenomena seen in simulations, including alternating plateaus and sharp pe- riods of rapid improvement. Indeed, it has been sho wn pre viously [16] that this nonlinear learning dynamics in deep linear networks is sufficient to qualitativ ely capture aspects of the progressiv e, hierarchical differ - entiation of conceptual structure seen in infant de velopment. Ne xt, we apply these solutions to inv estigate the commonly used greedy layer-wise pretraining strategy for training deep networks [17, 18], and recover conditions under which such pretraining speeds learning. W e show that these conditions are approximately satisfied for the MNIST dataset, and that unsupervised pretraining therefore confers an optimization advan- tage for deep linear networks applied to MNIST . Finally , we exhibit a ne w class of random orthogonal initial conditions on weights that, in linear networks, provide depth independent learning times, and we show that these initial conditions also lead to faithful propagation of gradients ev en in deep nonlinear networks. W e further show that these initial conditions also lead to f aithful propagation of gradients e ven in deep nonlinear networks, as long as they operate in a special regime known as the edge of chaos. In this regime, synaptic gains are tuned so that linear amplification due to propagation of neural acti vity through weight matrices exactly balances dampening of activity due to saturating nonlinearities. In particular, we show that ev en in nonlinear networks, operating in this special regime, Jacobians that are in volved in backpropagating error signals act like near isometries. 1 General learning dynamics of gradient descent W 21 W 32 x ∈ R N 1 h ∈ R N 2 y ∈ R N 3 Figure 1: The three layer network analyzed in this section. W e be gin by analyzing learning in a three layer network (in- put, hidden, and output) with linear activ ation functions (Fig 1). W e let N i be the number of neurons in layer i . The input- output map of the network is y = W 32 W 21 x . W e wish to train the network to learn a particular input-output map from 2 a set of P training e xamples { x µ , y µ } , µ = 1 , . . . , P . Training is accomplished via gradient descent on the squared error P P µ =1 y µ − W 32 W 21 x µ 2 between the desired feature output, and the network’ s feature output. This gradient descent procedure yields the batch learning rule ∆ W 21 = λ P X µ =1 W 32 T y µ x µT − W 32 W 21 x µ x µT , ∆ W 32 = λ P X µ =1 y µ x µT − W 32 W 21 x µ x µT W 21 T , (1) where λ is a small learning rate. As long as λ is suf ficiently small, we can take a continuous time limit to obtain the dynamics, τ d dt W 21 = W 32 T Σ 31 − W 32 W 21 Σ 11 , τ d dt W 32 = Σ 31 − W 32 W 21 Σ 11 W 21 T , (2) where Σ 11 ≡ P P µ =1 x µ x µT is an N 1 × N 1 input correlation matrix, Σ 31 ≡ P P µ =1 y µ x µT is an N 3 × N 1 input-output correlation matrix, and τ ≡ 1 λ . Here t measures time in units of iterations; as t varies from 0 to 1, the netw ork has seen P examples corresponding to one iteration. Despite the linearity of the network’ s input-output map, the gradient descent learning dynamics given in Eqn (2) constitutes a complex set of coupled nonlinear differential equations with up to cubic interactions in the weights. 1.1 Learning dynamics with orthogonal inputs Our fundamental goal is to understand the dynamics of learning in (2) as a function of the input statistics Σ 11 and input-output statistics Σ 31 . In general, the outcome of learning will reflect an interplay between input correlations, described by Σ 11 , and the input-output correlations described by Σ 31 . T o begin, though, we further sim plify the analysis by focusing on the case of orthogonal input representations where Σ 11 = I . This assumption will hold exactly for whitened input data, a widely used preprocessing step. Because we hav e assumed orthogonal input representations ( Σ 11 = I ), the input-output correlation matrix contains all of the information about the dataset used in learning, and it plays a piv otal role in the learning dynamics. W e consider its singular v alue decomposition (SVD) Σ 31 = U 33 S 31 V 11 T = P N 1 α =1 s α u α v T α , (3) which will be central in our analysis. Here V 11 is an N 1 × N 1 orthogonal matrix whose columns contain input-analyzing singular vectors v α that reflect independent modes of v ariation in the input, U 33 is an N 3 × N 3 orthogonal matrix whose columns contain output-analyzing singular vectors u α that reflect independent modes of variation in the output, and S 31 is an N 3 × N 1 matrix whose only nonzero elements are on the diagonal; these elements are the singular values s α , α = 1 , . . . , N 1 ordered so that s 1 ≥ s 2 ≥ · · · ≥ s N 1 . Now , performing the change of variables on synaptic weight space, W 21 = W 21 V 11 T , W 32 = U 33 W 32 , the dynamics in (2) simplify to τ d dt W 21 = W 32 T ( S 31 − W 32 W 21 ) , τ d dt W 32 = ( S 31 − W 32 W 21 ) W 21 T . (4) T o gain intuition for these equations, note that while the matrix elements of W 21 and W 32 connected neurons in one layer to neurons in the next layer , we can think of the matrix element W 21 iα as connecting input mode v α to hidden neuron i , and the matrix element W 32 αi as connecting hidden neuron i to output mode u α . Let a α be the α th column of W 21 , and let b αT be the α th row of W 32 . Intuitiv ely , a α is a column vector of N 2 synaptic weights presynaptic to the hidden layer coming from input mode α , and b α is a column vector of 3 N 2 synaptic weights postsynaptic to the hidden layer going to output mode α . In terms of these variables, or connectivity modes, the learning dynamics in (4) become τ d dt a α = ( s α − a α · b α ) b α − X γ 6 = α b γ ( a α · b γ ) , τ d dt b α = ( s α − a α · b α ) a α − X γ 6 = α a γ ( b α · a γ ) . (5) Note that s α = 0 for α > N 1 . These dynamics arise from gradient descent on the ener gy function E = 1 2 τ X α ( s α − a α · b α ) 2 + 1 2 τ X α 6 = β ( a α · b β ) 2 , (6) and display an interesting combination of cooperati ve and competitive interactions. Consider the first terms in each equation. In these terms, the connectivity modes from the two layers, a α and b α associated with the same input-output mode of strength s α , cooperate with each other to drive each other to larger magnitudes as well as point in similar directions in the space of hidden units; in this fashion these terms drive the product of connecti vity modes a α · b α to reflect the input-output mode strength s α . The second terms describe competition between the connecti vity modes in the first ( a α ) and second ( b β ) layers associated with different input modes α and β . This yields a symmetric, pairwise repulsi ve force between all distinct pairs of first and second layer connecti vity modes, driving the network to a decoupled regime in which the different connectivity modes become orthogonal. 1.2 The final outcome of learning The fix ed point structure of gradient descent learning in linear networks was worked out in [19]. In the language of the connecti vity modes, a necessary condition for a fix ed point is a α · b β = s α δ αβ , while a α and b α are zero whenev er s α = 0 . T o satisfy these relations for undercomplete hidden layers ( N 2 < N 1 , N 2 < N 3 ), a α and b α can be nonzero for at most N 2 values of α . Since there are rank (Σ 31 ) ≡ r nonzero values of s α , there are r N 2 families of fixed points. Ho wev er , all of these fixed points are unstable, except for the one in which only the first N 2 strongest modes, i.e. a α and b α for α = 1 , . . . , N 2 are acti ve. Thus remarkably , the dynamics in (5) has only saddle points and no non-global local minima [19]. In terms of the original synaptic variables W 21 and W 32 , all globally stable fixed points satisfy W 32 W 21 = P N 2 α =1 s α u α v T α . (7) −2 −1 0 1 2 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 a b Figure 2: V ector field (blue), stable manifold (red) and two solution tra- jectories (green) for the two dimen- sional dynamics of a and b in (8), with τ = 1 , s = 1 . Hence when learning has conv erged, the network will represent the closest rank N 2 approximation to the true input-output correlation matrix. In this work, we are interested in understanding the dynami- cal weight trajectories and learning time scales that lead to this final fixed point. 1.3 The time course of learning It is dif ficult though to exactly solve (5) starting from arbitrary initial conditions because of the competitiv e interactions between different input-output modes. Therefore, to gain intuition for the general dy- namics, we restrict our attention to a special class of initial conditions of the form a α and b α ∝ r α for α = 1 , . . . , N 2 , where r α · r β = δ αβ , with all other connectivity modes a α and b α set to zero (see [20] for 4 0 500 1000 0 20 40 60 80 t (Epochs) mode strength 0 5 10 15 20 25 30 −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 Input−output mode (t half −t analy )/t analy Linear Tanh Figure 3: Left: Dynamics of learning in a three layer neural netw ork. Curves show the strength of the network’ s representation of seven modes of the input-output correlation matrix over the course of learning. Red traces sho w analytical curves from Eqn. 12. Blue traces sho w simulation of full dynamics of a linear network (Eqn. (2)) from small random initial conditions. Green traces sho w simulation of a nonlinear three layer network with tanh activ ation functions. T o generate mode strengths for the nonlinear network, we computed the nonlinear network’ s e volving input-output correlation matrix, and plotted the diagonal elements of U 33 T Σ 31 tanh V 11 ov er time. The training set consists of 32 orthogonal input patterns, each associated with a 1000-dimensional feature vector generated by a hierarchical diffusion process described in [16] with a fiv e level binary tree and flip probability of 0.1. Modes 1, 2, 3, 5, 12, 18, and 31 are plotted with the rest excluded for clarity . Network training parameters were λ = 0 . 5 e − 3 , N 2 = 32 , u 0 = 1 e − 6 . Right: Delay in learning due to competiti ve dynamics and sigmoidal nonlinearities. V ertical axis shows the difference between simulated time of half learning and the analytical time of half learning, as a fraction of the analytical time of half learning. Error bars show standard deviation from 100 simulations with random initializations. solutions to a partially overlapping but distinct set of initial condi- tions, further discussed in Supplementary Appendix A). Here r α is a fixed collection of N 2 vectors that form an orthonormal basis for synaptic connections from an input or output mode onto the set of hidden units. Thus for this set of initial conditions, a α and b α point in the same direction for each alpha and differ only in their scalar magnitudes, and are orthogonal to all other connectivity modes. Such an initialization can be obtained by computing the SVD of Σ 31 and taking W 32 = U 33 D a R T , W 21 = RD b V 11 T where D a , D b are diagonal, and R is an arbitrary orthogonal matrix; howe ver , as we show in subsequent experiments, the solutions we find are also excellent approximations to trajectories from small random initial conditions. It is straightforward to verify that starting from these initial conditions, a α and b α will remain parallel to r α for all future time. Furthermore, because the dif ferent activ e modes are orthogonal to each other, they do not compete, or even interact with each other (all dot products in the second terms of (5)-(6) are 0 ). Thus this class of conditions defines an in variant manifold in weight space where the modes e volv e indepen- dently of each other . If we let a = a α · r α , b = b α · r α , and s = s α , then the dynamics of the scalar projections ( a, b ) obeys, τ d dt a = b ( s − ab ) , τ d dt b = a ( s − ab ) . (8) Thus our ability to decouple the connectivity modes yields a dramatically simplified two dimensional non- linear system. These equations can by solv ed by noting that they arise from gradient descent on the error , E ( a, b ) = 1 2 τ ( s − ab ) 2 . (9) This implies that the product ab monotonically approaches the fixed point s from its initial v alue. Moreov er, E ( a, b ) satisfies a symmetry under the one parameter family of scaling transformations a → λa , b → b λ . This symmetry implies, through Noether’ s theorem, the existence of a conserved quantity , namely a 2 − b 2 , 5 which is a constant of motion. Thus the dynamics simply follo ws hyperbolas of constant a 2 − b 2 in the ( a, b ) plane until it approaches the hyperbolic manifold of fixed points, ab = s . The origin a = 0 , b = 0 is also a fixed point, b ut is unstable. Fig. 2 shows a typical phase portrait for these dynamics. As a measure of the timescale of learning, we are interested in how long it takes for ab to approach s from any gi ven initial condition. The case of unequal a and b is treated in the Supplementary Appendix A due to space constraints. Here we pursue an explicit solution with the assumption that a = b , a reasonable limit when starting with small random initial conditions. W e can then track the dynamics of u ≡ ab , which from (8) obeys τ d dt u = 2 u ( s − u ) . (10) This equation is separable and can be integrated to yield t = τ Z u f u 0 du 2 u ( s − u ) = τ 2 s ln u f ( s − u 0 ) u 0 ( s − u f ) . (11) Here t is the time it takes for u to trav el from u 0 to u f . If we assume a small initial condition u 0 = , and ask when u f is within of the fixed point s , i.e. u f = s − , then the learning timescale in the limit → 0 is t = τ /s ln ( s/ ) = O ( τ /s ) (with a weak logarithmic dependence on the cutoff). This yields a key result: the timescale of learning of each input-output mode α of the correlation matrix Σ 31 is in versely proportional to the correlation strength s α of the mode. Thus the stronger an input-output relationship, the quicker it is learned. W e can also find the entire time course of learning by in verting (11) to obtain u f ( t ) = se 2 st/τ e 2 st/τ − 1 + s/u 0 . (12) This time course describes the temporal evolution of the product of the magnitudes of all weights from an input mode (with correlation strength s ) into the hidden layers, and from the hidden layers to the same output mode. If this product starts at a small v alue u 0 < s , then it displays a sigmoidal rise which asymptotes to s as t → ∞ . This sigmoid can exhibit sharp transitions from a state of no learning to full learning. This analytical sigmoid learning curve is sho wn in Fig. 3 to yield a reasonable approximation to learning curves in linear networks that start from random initial conditions that are not on the orthogonal, decoupled in variant manifold–and that therefore exhibit competitiv e dynamics between connecti vity modes–as well as in nonlinear networks solving the same task. W e note that though the nonlinear networks behav ed similarly to the linear case for this particular task, this is likely to be problem dependent. 2 Deeper multilayer dynamics The network analyzed in Section 1 is the minimal example of a multilayer net, with just a single layer of hidden units. How does gradient descent act in much deeper networks? W e make an initial attempt in this direction based on initial conditions that yield particularly simple gradient descent dynamics. In a linear neural network with N l layers and hence N l − 1 weight matrices indexed by W l , l = 1 , · · · , N l − 1 , the gradient descent dynamics can be written as τ d dt W l = N l − 1 Y i = l +1 W i ! T " Σ 31 − N l − 1 Y i =1 W i ! Σ 11 # l − 1 Y i =1 W i ! T , (13) where Q b i = a W i = W b W ( b − 1) · · · W ( a − 1) W a with the special case that Q b i = a W i = I , the identity , if a > b . 6 T o describe the initial conditions, we suppose that there are N l orthogonal matrices R l that diagonalize the starting weight matrices, that is, R T l +1 W l (0) R l = D l for all l , with the special case that R 1 = V 11 and R N l = U 33 . This requirement essentially demands that the output singular vectors of layer l be the input singular vectors of the next layer l + 1 , so that a change in mode strength at any layer propagates to the output without mixing into other modes. W e note that this formulation does not restrict hidden layer size; each hidden layer can be of a different size, and may be undercomplete or ov ercomplete. Making the change of variables W l = R l +1 W l R T l along with the assumption that Σ 11 = I leads to a set of decoupled connectivity modes that e volve independently of each other . In analogy to the simplification occurring in the three layer network from (2) to (8), each connecti vity mode in the N l layered network can be described by N l − 1 scalars a 1 , . . . , a N l − 1 , whose dynamics obe ys gradient descent on the energy function (the analog of (9)), E ( a 1 , · · · , a N l − 1 ) = 1 2 τ s − N l − 1 Y i =1 a i ! 2 . (14) This dynamics also has a set of conserved quantities a 2 i − a 2 j arising from the energetic symmetry w .r .t. the transformation a i → λa i , a j → a j λ , and hence can be solv ed exactly . W e focus on the in variant submanifold in which a i ( t = 0) = a 0 for all i , and track the dynamics of u = Q N l − 1 i =1 a i , the overall strength of this mode, which obeys (i.e. the generalization of (10)), τ d dt u = ( N l − 1) u 2 − 2 / ( N l − 1) ( s − u ) . (15) This can be integrated for any positiv e integer N l , though the expression is complicated. Once the ov erall strength increases sufficiently , learning explodes rapidly . Eqn. (15) lets us study the dynamics of learning as depth limits to infinity . In particular , as N l → ∞ we hav e the dynamics τ d dt u = N l u 2 ( s − u ) (16) which can be integrated to obtain t = τ N l 1 s 2 log u f ( u 0 − s ) u 0 ( u f − s ) + 1 su 0 − 1 su f . (17) Remarkably this implies that, for a fixed learning rate, the learning time as measured by the num- ber of iterations required tends to zero as N l goes to infinity . This result depends on the con- tinuous time formulation, howe ver . Any implementation will operate in discrete time and must choose a finite learning rate that yields stable dynamics. An estimate of the optimal learn- ing rate can be deriv ed from the maximum eigen value of the Hessian over the re gion of interest. 0 50 100 0 50 100 150 200 250 N l (Number of layers) Learning time (Epochs) 0 50 100 0 0.2 0.4 0.6 0.8 1 1.2 x 10 −4 Optimal learning rate N l (Number of layers) Figure 4: Left: Learning time as a function of depth on MNIST . Right: Empirically optimal learning rates as a function of depth. For linear networks with a i = a j = a , this optimal learn- ing rate α opt decays with depth as O 1 N l s 2 for lar ge N l (see Supplementary Ap- pendix B). Incorporating this dependence of the learning rate on depth, the learning time as depth approaches in- finity still surprisingly re- mains finite: with the opti- mal learning rate, the dif fer- ence between learning times 7 for an N l = 3 network and an N l = ∞ network is t ∞ − t 3 ∼ O ( s/ ) for small (see Supplementary Appendix B.1). W e emphasize that our analysis of learning speed is based on the number of iterations re- quired, not the amount of computation–computing one iteration of a deep network will require more time than doing so in a shallow netw ork. T o verify these predictions, we trained deep linear networks on the MNIST classification task with depths ranging from N l = 3 to N l = 100 . W e used hidden layers of size 1000, and calculated the iteration at which training error fell belo w a fixed threshold corresponding to nearly complete learning. W e optimized the learning rate separately for each depth by training each network with twenty rates logarithmically spaced between 10 − 4 and 10 − 7 and picking the fastest. See Supplementary Appendix C for full experimental details. Networks were initialized with decoupled initial conditions and starting initial mode strength u 0 = 0 . 001 . Fig. 4 shows the resulting learning times, which saturate, and the empirically optimal learning rates, which scale like O (1 / N l ) as predicted. Thus learning times in deep linear networks that start with decoupled initial conditions are only a finite amount slower than a shallow network regardless of depth. Moreover , the delay incurred by depth scales in versely with the size of the initial strength of the association. Hence finding a way to initialize the mode strengths to large v alues is crucial for fast deep learning. 3 Finding good weight initializations: on greediness and randomness The previous subsection rev ealed the existence of a decoupled submanifold in weight space in which con- nectivity modes ev olve independently of each other during learning, and learning times can be independent of depth, ev en for arbitrarily deep netw orks, as long as the initial composite, end to end mode strength, denoted by u above, of e very connectivity mode is O (1) . What numerical weight initilization procedures can get us close to this weight manifold, so that we can exploit its rapid learning properties? A breakthrough in training deep neural networks started with the discov ery that greedy layer-wise unsu- pervised pretraining could substantially speed up and improve the generalization performance of standard gradient descent [17, 18]. Unsupervised pretraining has been shown to speed the optimization of deep networks, and also to act as a special regularizer towards solutions with better generalization performance [18, 12, 13, 14]. At the same time, recent results have obtained excellent performance starting from carefully- scaled random initializations, though interestingly , pretrained initializations still exhibit faster conv ergence [21, 13, 22, 3, 4, 1, 23] (see Supplementary Appendix D for discussion). Here we examine analytically how unsupervised pretraining achie ves an optimization adv antage, at least in deep linear networks, by finding the special class of orthogonalized, decoupled initial conditions in the pre vious section that allow for rapid supervised deep learning, for input-output tasks with a certain precise structure. Subsequently , we analyze the properties of random initilizations. W e consider the following pretraining and finetuning procedure: First, using autoencoders as the unsuper- vised pretraining module [18, 12], the network is trained to produce its input as its output ( y µ pre = x µ ). Subsequently , the network is finetuned on the ultimate input-output task of interest (e.g., a classification task). In the follo wing we consider the case N 2 = N 1 for simplicity . During the pretraining phase, the input-output correlation matrix Σ 31 pre is simply the input correlation matrix Σ 11 . Hence the SVD of Σ 31 pre is PCA on the input correlation matrix, since Σ 31 pre = Σ 11 = Q Λ Q T , where Q are eigen vectors of Σ 11 and Λ is a diagonal matrix of v ariances. Our analysis of the learning dynamics in Section 1.1 does not directly apply , because here the input correlation matrix is not white. In Supplementary Appendix E we generalize our results to handle this case. During pretraining, the weights approach W 32 W 21 = Σ 31 (Σ 31 ) − 1 , but since the y do not reach the fix ed point in finite time, they will end at W 32 W 21 = QM Q T where M is a diagonal matrix that is approaching the identity matrix during 8 0 100 200 300 400 500 1 1.5 2 2.5 3 x 10 4 Epoch Error Pretrain Random 2000 4000 6000 8000 0 5 10 15 x 10 5 Figure 5: MNIST satisfies the consistency condition for greedy pretraining. Left: Submatrix from the raw MNIST input correlation matrix Σ 11 . Center: Submatrix of V 11 Σ 11 V 11 T which is approximately diagonal as required. Right: Learning curves on MNIST for a fi ve layer linear network starting from random (black) and pretrained (red) initial conditions. Pretrained curve starts with a delay due to pretraining time. The small random initial conditions correspond to all weights chosen i.i.d. from a zero mean Gaussian with standard deviation 0.01. learning. Hence in general, W 32 = QM 1 / 2 C − 1 and W 21 = C M 1 / 2 Q T where C is any inv ertible matrix. When starting from small random weights, though, each weight matrix will end up with a roughly balanced contribution to the overall map. This corresponds to ha ving C ≈ R 2 where R 2 is orthogonal. Hence at the end of the pretraining phase, the input-to-hidden mapping will be W 21 = R 2 M 1 / 2 Q T where R 2 is an arbitrary orthogonal matrix. Now consider the fine-tuning phase. Here the weights are trained on the ultimate task of interest with input-output correlations Σ 31 = U 33 S 31 V 11 . The matrix W 21 begins from the pretrained initial condition W 21 = R 2 M 1 / 2 Q T . For the fine-tuning task, a decoupled initial condition for W 21 is one that can be written as W 21 = R 2 D 1 V 11 T (see Section 2). Clearly , this will be possible only if Q = V 11 . (18) Then the initial condition obtained from pretraining will also be a decoupled initial condition for the finetun- ing phase, with initial mode strengths D 1 = M 1 / 2 near one. Hence we can state the underlying condition required for successful greedy pretraining in deep linear networks: the right singular vectors of the ultimate input-ouput task of interest V 11 must be similar to the principal components of the input data Q . This is a quantitativ ely precise instantiation of the intuitive idea that unsupervised pretraining can help in a subsequent supervised learning task if (and only if) the statistical structure of the input is consistent with the structure of input-output map to be learned. Moreov er, this quantitative instantiation of this intuiti ve idea gives a simple empirical criterion that can be ev aluated on any new dataset: giv en the input-output correlation Σ 31 and input correlation Σ 11 , compute the right singular vectors V 11 of Σ 31 and check that V 11 Σ 11 V 11 T is approximately diagonal. If the condition in Eqn. (18) holds, autoencoder pretraining will hav e properly set up decoupled initial conditions for W 21 , with an appreciable initial association strength near 1 . This argu- ment also goes through straightforwardly for layer-wise pretraining of deeper networks. Fig. 5 shows that this consistency condition empirically holds on MNIST , and that a pretrained deep linear neural network learns f aster than one started from small random initial conditions, e ven accounting for pretraining time (see Supplementary Appendix F for e xperimental details). W e note that this analysis is unlik ely to carry over completely to nonlinear networks. Some nonlinear networks are approximately linear (e.g., tanh nonlin- earities) after initialization with small random initializations, and hence our solutions may describe these dynamics well early in learning. Howe ver as the network enters its nonlinear regime, our solutions should not be expected to remain accurate. As an alternative to greedy layerwise pre-training, [13] proposed choosing appropriately scaled initial condi- tions on weights that would preserv e the norm of typical error vectors as the y were backpropagated through the deep network. In our context, the appropriate norm-preserving scaling for the initial condition of an N by N connectivity matrix W between any two layers corresponds to choosing each weight i.i.d. from a 9 Figure 6: A Left: Learning time (on MNIST using the same architecture and parameters as in Fig. 4) as a function of depth for dif ferent initial conditions on weights (scaled i.i.d. uniform weights chosen to preserv e the norm of propagated gradients as proposed in [13] (blue), greedy unsupervised pre-training (green) and random orthogonal matrices (red). The red curve lies on top of the green curve. Middle: Optimal learning rates as a function of depth for different weight initilizations. Right: The eigen value spectrum, in the complex plane, of a random 100 by 100 orthogonal matrix. B Histograms of the singular v alues of products of N l − 1 independent random Gaussian N by N matrices whose elements themselves are chosen i.i.d. from a zero mean Gaussian with standard de viation 1 / √ N . In all cases, N = 1000 , and histograms are taken over 500 realizations of such random product matrices, yielding a total 5 · 10 5 singular v alues in each histogram. C Histograms of the eigen value distributions on the complex plane of the same product matrices in B . The bin width is 0.1, and, for visualization purposes, the bin containing the origin has been removed in each case; this bin would otherwise dominate the histogram in the middle and right plots, as it contains 32% and 94% of the eigen values respecti vely . zero mean Gaussian with standard deviation 1 / √ N . W ith this choice, h v T W T W v i W = v T v , where h·i W denotes an average ov er distribution of the random matrix W . Moreov er, the distribution of v T W T W v con- centrates about its mean for lar ge N . Thus with this scaling, in linear networks, both the forward propagation of acti vity , and backpropagation of gradients is typically norm-preserving. Howe ver , with this initialization, the learning time with depth on linear networks trained on MNIST grows with depth (Fig. 6A, left, blue). This gro wth is in distinct contradiction with the theoretical prediction, made above, of depth independent learning times starting from the decoupled submanifold of weights with composite mode strength O (1) . This suggests that the scaled random initialization scheme, despite its norm-preserving nature, does not find this submanifold in weight space. In contrast, learning times with greedy layerwise pre-training do not gro w with depth (Fig. 6A, left, green curve hiding under red curve), consistent with the predictions of our theory (as a technical point: note that learning times under greedy pre-training initialization in Fig. 6A are faster than those obtained in Fig. 4 by explicitly choosing a point on the decoupled submanifold, because there the initial mode strength was chosen to be small ( u = 0 . 001 ) whereas greedy pre-training finds a composite mode strength closer to 1 ). 10 Is there a simple random initialization scheme that does enjoy the rapid learning properties of greedy- layerwise pre-training? W e empirically show (Fig. 6A, left, red curve) that if we choose the initial weights in each layer to be a random orthogonal matrix (satisifying W T W = I ), instead of a scaled random Gaussian matrix, then this orthogonal random initialization condition yields depth independent learning times just like greedy layerwise pre-training (indeed the red and green curv es are indistinguishable). Theoretically , why do random orthogonal initializations yield depth independent learning times, b ut not scaled random Gaussian initializations, despite their norm preserving nature? The answer lies in the eigen value and singular v alue spectra of products of Gaussian versus orthgonal random matrices. While a single random orthogonal matrix has eigen value spectra lying exactly on the unit circle in the complex plane (Fig. 6A right), the eigen value spectra of random Gaussian matrices, whose elements hav e variance 1 / N , form a uniform distribution on a solid disk of radius 1 the complex plane (Fig. 6C left). Moreov er the singular v alues of an orthogonal matrix are all exactly 1 , while the squared singular v alues of a scaled Gaussian random matrix hav e the well known Marcenko-Pasteur distrib ution, with a nontrivial spread e ven as N → ∞ , (Fig. 6B left sho ws the distrib ution of singular v alues themselves). Now consider a product of these matrices across all N l layers, representing the total end to end propagation of acti vity across a deep linear network: W T ot = N l − 1 Y i =1 W ( i +1 ,i ) . (19) Due to the random choice of weights in each layer, W T ot is itself a random matrix. On average, it preserves the norm of a typical vector v no matter whether the matrices in each layer are Gaussian or orthogonal. Howe ver , the singular value spectra of W T ot differ markedly in the two cases. Under random orthogonal initilization in each layer, W T ot is itself an orthogonal matrix and therefore has all singular values equal to 1 . Howe ver , under random Gaussian initialization in each layer , there is as of yet no complete theoretical characterization of the singular value distribution of W T ot . W e hav e computed it numerically as a function of different depths in Fig. 6B, and we find that it develops a highly kurtotic nature as the depth increases. Most of the singular v alues become v anishingly small, while a long tail of very large singular v alues remain. Thus W T ot preserves the norm of a typical, randomly chosen vector v , but in a highly anisotropic manner , by strongly amplifying the projection of v onto a v ery small subset of singular vectors and attenuating v in all other directions. Intuitively W T ot , as well as the linear operator W T T ot that would be closely related to backpropagation of gradients to early layers, act as amplifying projection operators at large depth N l . In contrast, all of the eigen values of W T ot in the scaled Gaussian case concentrate closer to the origin as depth increases. This discrepancy between the behavior of the eigen values and singular values of W T ot , a phenomenon that could occur only if the eigen vectors of W T ot are highly non-orthogonal, reflects the highly non-normal nature of products of random Gaussian matrices (a non-normal matrix is by definition a matrix whose eigen vectors are non-orthogonal). While the combination of amplification and projection in W T ot can preserve norm, it is clear that it is not a good way to backpropagate errors; the projection of error vectors onto a high dimensional subspace corre- sponding to small singular values would be strongly attenuated, yielding v anishingly small gradient signals corresponding to these directions in the early layers. This ef fect, which is not present for random orthogonal initializations or greedy pretraining, would naturally explain the long learning times starting from scaled random Gaussian initial conditions relati ve to the other initilizations in Fig. 6A left. For both linear and nonlinear networks, a more lik ely appropriate condition on weights for generating fast learning times would be that of dynamical isometry . By this we mean that the product of Jacobians associated with error signal backpropagation should act as a near isometry , up to some o verall global O (1) scaling, on a subspace of as high a dimension as possible. This is equiv alent to ha ving as man y singular v alues of the product of Jacobians as possible within a small range around an O (1) constant, and is closely related to the notion of restricted isometry in compressed sensing and random projections. Preserving norms is a necessary but not sufficient condition for achieving dynamical isometry at large depths, as demonstrated in Fig. 6B, and we 11 hav e sho wn that for linear networks, orthogonal initializations achie ve exact dynamical isometry with all singular values at 1 , while greedy pre-training achiev es it approximately . W e note that the discrepancy in learning times between the scaled Gaussian initialization and the orthogonal or pre-training initializations is modest for the depths of around 6 used in large scale applications, but is magnified at larger depths (Fig. 6A left). This may explain the modest improvement in learning times with greedy pre-training versus random scaled Gaussian initializations observ ed in applications (see discussion in Supplementary Appendix D). W e predict that this modest improvement will be magnified at higher depths, ev en in nonlinear networks. Finally , we note that in recurrent networks, which can be thought of as infinitely deep feed-forward networks with tied weights, a very promising approach is a modification to the training objectiv e that partially promotes dynamical isometry for the set of gradients currently being back-propagated [24]. 4 Achieving appr oximate dynamical isometry in nonlinear networks W e ha ve sho wn abo ve that deep random orthogonal linear networks achiev e perfect dynamical isometry . Here we show that nonlinear versions of these networks can also achiev e good dynamical isometry proper- ties. Consider the nonlinear feedforward dynamics x l +1 i = X j g W ( l +1 ,l ) ij φ ( x l j ) , (20) where x l i denotes the acti vity of neuron i in layer l , W ( l +1 ,l ) ij is a random orthogonal connectivity matrix from layer l to l + 1 , g is a scalar gain factor , and φ ( x ) is any nonlinearity that saturates as x → ±∞ . W e show in Supplementary appendix G that there exists a critical value g c of the gain g such that if g < g c , activity will decay aw ay to zero as it propagates through the layers, while if g > g c , the strong linear positi ve gain will combat the damping due to the saturating nonlinearity , and acti vity will propagate indefinitely without decay , no matter ho w deep the network is. When the nonlinearity is odd ( φ ( x ) = − φ ( − x ) ), so that the mean activity in each layer is approximately 0 , these dynamical properties can be quantitatively captured by the neural population variance in layer l , q l ≡ 1 N N X i =1 ( x l i ) 2 . (21) Thus lim l →∞ q l → 0 for g < g c and lim l →∞ q l → q ∞ ( g ) > 0 for g > g c . When φ ( x ) = tanh( x ) , we compute g c = 1 and numerically compute q ∞ ( g ) in Fig. 8 in Supplementary appendix G. Thus these non- linear feedforward networks exhibit a phase-transition at the critical gain; above the critical gain, infinitely deep networks exhibit chaotic percolating activity propagation, so we call the critical gain g c the edge of chaos, in analogy with terminology for recurrent networks. Now we are interested in ho w errors at the final layer N l backpropagate back to earlier layers, and whether or not these gradients e xplode or decay with depth. T o quantify this, for simplicity we consider the end to end Jacobian J N l , 1 ij ( x N l ) ≡ ∂ x N l i ∂ x 1 j x N l , (22) which captures ho w input perturbations propagate to the output. If the singular v alue distrib ution of this Jacobian is well-behav ed, with few extremely large or small singular v alues, then the backpropagation of gradients will also be well-beha ved, and exhibit little e xplosion or decay . The Jacobian is ev aluated at a particular point x N l in the space of output layer activations, and this point is in turn obtained by iterating (20) starting from an initial input layer acti vation vector x 1 . Thus the singular value distrib ution of the 12 0 1 2 3 x 10 −5 0 50 100 q = 0.2 g = 0.9 0 2 4 6 x 10 −3 0 20 40 60 g = 0.95 0 0.1 0.2 0.3 0.4 0 10 20 30 40 g = 1 0 0.5 1 1.5 2 0 50 100 g = 1.05 0 2 4 6 0 100 200 300 400 g = 1.1 0 1 2 3 x 10 −5 0 10 20 30 40 q = 1 0 1 2 3 4 x 10 −3 0 10 20 30 40 0 0.1 0.2 0.3 0.4 0 10 20 30 40 0 0.5 1 1.5 0 50 100 0 1 2 3 4 0 100 200 300 400 0 1 2 3 x 10 −5 0 10 20 30 40 q = 4 0 1 2 3 4 x 10 −3 0 10 20 30 0 0.1 0.2 0.3 0.4 0 10 20 30 40 0 0.5 1 1.5 0 50 100 150 0 1 2 3 0 200 400 600 Figure 7: Singular value distribution of the end to end Jacobian, defined in (22), for various v alues of the gain g in (20) and the input layer population variance q = q 1 in (21). The network architecture consists of N l = 100 layers with N = 1000 neurons per layer , as in the linear case in Fig. 6B. Jacobian will depend not only on the gain g , b ut also on the initial condition x 1 . By rotational symmetry , we expect this distrib ution to depend on x 1 , only through its population v ariance q 1 . Thus for large N , the singular value distribution of the end-to-end Jacobian in (22) (the analog of W T ot in (19) in the linear case), depends on only two parameters: gain g and input population variance q 1 . W e hav e numerically computed this singular value distrib ution as a function of these two parameters in Fig. 7, for a single random orthogonal nonlinear network with N = 1000 and N l = 100 . These results are typical; replotting the results for dif ferent random networks and different initial conditions (with the same input v ariance) yield very similar results. W e see that belo w the edge of chaos, when g < 1 , the linear dampening ov er many layers yields extremely small singular v alues. Abov e the edge of chaos, when g > 1 , the combination of positive linear amplification, and saturating nonlinear dampening yields an anisotropic distribution of singular values. At the edge of chaos, g = 1 , an O (1) fraction of the singular value distribu- 13 tion is concentrated in a range that remains O (1) despite 100 layers of propagation, reflecting appoximate dynamical isometry . Moreover , this nice property at g = 1 remains valid ev en as the input variance q 1 is increased far beyond 1 , where the tanh function enters its nonlinear regime. Thus the right column of Fig. 7 at g near 1 indicates that the useful dynamical isometry properties of random orthogonal linear networks described above survi ves in nonlinear networks, even when activity patterns enter deeply into the nonlinear regime in the input layers. Interestingly , the singular value spectrum is more robust to perturbations that increase g from 1 relati ve to those that decrease g . Indeed, the anisotropy in the singular v alue distrib ution at g = 1 . 1 is relati vely mild compa red to that of random linear netw orks with scaled Gaussian initial conditions (compare the bottom ro w of Fig. 7 with the right column of panel B in Fig. 6). Thus ov erall, these numerical results suggest that being just beyond the edge of orthogonal chaos may be a good regime for learning in deep nonlinear networks. 5 Discussion In summary , despite the simplicity of their input-output map, the dynamics of learning in deep linear net- works re veals a s urprising amount of rich mathematical structure, including nonlinear hyperbolic dynamics, plateaus and sudden performance transitions, a proliferation of saddle points, symmetries and conserv ed quantities, in variant submanifolds of independently e volving connectivity modes subserving rapid learning, and most importantly , a sensiti ve but computable dependence of learning time scales on input statistics, ini- tial weight conditions, and network depth. W ith the right initial conditions, deep linear networks can be only a finite amount slower than shallo w networks, and unsupervised pretraining can find these initial conditions for tasks with the right structure. Moreover , we introduce a mathematical condition for faithful backprop- agation of error signals, namely dynamical isometry , and show , surprisingly that random scaled Gaussian initializations cannot achie ve this condition despite their norm-preserving nature, while greedy pre-training and random orthogonal initialization can, thereby achieving depth independent learning times. Finally , we show that the property of dynamical isometry survives to good approximation ev en in extremely deep non- linear random orthogonal networks operating just beyond the edge of chaos. At the cost of expressivity , deep linear networks gain theoretical tractability and may prov e fertile for addressing other phenomena in deep learning, such as the impact of carefully-scaled initializations [13, 23], momentum [23], dropout regulariza- tion [1], and sparsity constraints [2]. While a full analytical treatment of learning in deep nonlinear networks currently remains open, one cannot reasonably hope to mo ve to wards such a theory without first completely understanding the linear case. In this sense, our work fulfills an essential pre-requisite for progress tow ards a general, quantitativ e theory of deep learning. References [1] A. Krizhevsk y , I. Sutske ver , and G.E. Hinton. ImageNet Classification with Deep Conv olutional Neural Networks. In Advances in Neur al Information Pr ocessing Systems 25 , 2012. [2] Q.V . Le, M.A. Ranzato, R. Monga, M. Devin, K. Chen, G.S. Corrado, J. Dean, and A.Y . Ng. Build- ing high-le vel features using large scale unsupervised learning. In 29th International Conference on Machine Learning , 2012. [3] D. Ciresan, U. Meier , and J. Schmidhuber . Multi-column Deep Neural Networks for Image Classifica- tion. In IEEE Conf. on Computer V ision and P attern Reco gnition , pages 3642–3649, 2012. [4] A. Mohamed, G.E. Dahl, and G. Hinton. Acoustic Modeling Using Deep Belief Netw orks. IEEE T ransactions on Audio, Speech, and Langua ge Pr ocessing , 20(1):14–22, January 2012. [5] R. Collobert and J. W eston. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Pr oceedings of the 25th International Conference on Machine Learning , 2008. 14 [6] R. Socher , J. Bauer, C.D. Manning, and A.Y . Ng. Parsing with Compositional V ector Grammars. In Association for Computational Linguistics Confer ence , 2013. [7] S. Hochreiter . Untersuchung en zu dynamischen neur onalen Netzen. PhD thesis, TU Munich, 1991. [8] Y . Bengio, P . Simard, and P . Frasconi. Learning Long-T erm Dependencies with Gradient Descent is Difficult. IEEE T ransactions on Neural Networks , 5(2):157–166, 1994. [9] Y . LeCun, L. Bottou, G.B. Orr , and K.R. M ¨ uller . Efficient BackProp. Neural networks: T ricks of the trade , 1998. [10] Y . Bengio and Y . LeCun. Scaling learning algorithms tow ards AI. In L. Bottou, O. Chapelle, D. De- Coste, and J. W eston, editors, Lar ge-Scale K ernel Machines , number 1, pages 1–41. MIT Press, 2007. [11] D. Erhan, P .A. Manzagol, Y . Bengio, S. Bengio, and P . V incent. The Difficulty of T raining Deep Ar- chitectures and the Effect of Unsupervised Pre-Training. In 12th International Confer ence on Artificial Intelligence and Statistics , v olume 5, 2009. [12] Y . Bengio. Learning Deep Architectures for AI. 2009. [13] X. Glorot and Y . Bengio. Understanding the difficulty of training deep feedforward neural networks. 13th International Confer ence on Artificial Intelligence and Statistics , 2010. [14] D. Erhan, Y . Bengio, A. Courville, P .A. Manzagol, and P . V incent. Why does unsupervised pre-training help deep learning? Journal of Mac hine Learning Researc h , 11:625–660, 2010. [15] Y .N. Dauphin and Y . Bengio. Big Neural Networks W aste Capacity. In International Conference on Learning Repr esentations , 2013. [16] A.M. Saxe, J.L. McClelland, and S. Ganguli. Learning hierarchical category structure in deep neural networks. In Pr oceedings of the 35th Annual Conference of the Co gnitive Science Society , 2013. [17] G.E. Hinton and R.R. Salakhutdinov . Reducing the dimensionality of data with neural networks. Sci- ence , 313(5786):504–7, July 2006. [18] Y . Bengio, P . Lamblin, D. Popovici, and H. Larochelle. Greedy Layer-W ise Training of Deep Net- works. Advances in Neur al Information Pr ocessing Systems 20 , 2007. [19] P . Baldi and K. Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural Networks , 2(1):53–58, January 1989. [20] K. Fukumizu. Effect of Batch Learning In Multilayer Neural Netw orks. In Pr oceedings of the 5th International Confer ence on Neural Information Pr ocessing , pages 67–70, 1998. [21] J. Martens. Deep learning via Hessian-free optimization. In Pr oceedings of the 27th International Confer ence on Machine Learning , 2010. [22] O. Chapelle and D. Erhan. Improv ed Preconditioner for Hessian Free Optimization. In NIPS W orkshop on Deep Learning and Unsupervised F eatur e Learning , 2011. [23] I. Sutsk ever , J. Martens, G. Dahl, and G.E. Hinton. On the importance of initialization and momentum in deep learning. In 30th International Confer ence on Machine Learning , 2013. [24] Razv an Pascanu, T omas Mikolov , and Y oshua Bengio. On the difficulty of training recurrent neural networks. T echnical report, Universite de Montreal, 2012. [25] P . Lamblin and Y . Bengio. Important gains from supervised fine-tuning of deep architectures on large labeled sets. In NIPS W orkshop on Deep Learning and Unsupervised F eature Learning , 2010. 15 Supplementary Material A Hyperbolic dynamics of learning In Section 1.3 of the main te xt we treat the dynamics of learning in three layer networks where mode strengths in each layer are equal, i.e, a = b , a reasonable limit when starting with small random initial conditions. More generally , though, we are interested in how long it takes for ab to approach s from an y giv en initial condition. T o access this, given the hyperbolic nature of the dynamics, it is useful to make the hyperbolic change of coordinates, a = √ c 0 cosh θ 2 b = √ c 0 sinh θ 2 for a 2 > b 2 (23) a = √ c 0 sinh θ 2 b = √ c 0 cosh θ 2 for a 2 < b 2 . (24) Thus θ parametrizes the dynamically in variant manifolds a 2 − b 2 = ± c 0 . F or any c 0 and θ , this coordinate system cov ers the region a + b > 0 , which is the basin of attraction of the upper right component of the hyperbola ab = s . A symmetric situation exists for a + b < 0 , which is attracted to the lower left component of ab = s . W e use θ as a coordinate to follow the dynamics of the product ab , and using the relations ab = c 0 sinh θ and a 2 + b 2 = c 0 cosh θ , we obtain τ dθ dt = s − c 0 sinh θ . (25) This differential equation is separable in θ and t and can be integrated to yield t = τ Z θ f θ 0 dθ s − c 0 sinh θ = τ p c 2 0 + s 2 " ln p c 2 0 + s 2 + c 0 + s tanh θ 2 p c 2 0 + s 2 − c 0 − s tanh θ 2 # θ f θ 0 . (26) Here t is the amount of time it takes to trav el from θ 0 to θ f along the hyperbola a 2 − b 2 = ± c 0 . The fixed point lies at θ = sinh − 1 s/c 0 , but the dynamics cannot reach the fixed point in finite time. Therefore we introduce a cutoff to mark the endpoint of learning, so that θ f obeys sinh θ f = (1 − ) s/c 0 (i.e. ab is close to s by a factor 1 − ). W e can then av erage over the initial conditions c 0 and θ 0 to obtain the expected learning time of an input-output relation that has a correlation strength s . Rather than doing this, it is easier to obtain a rough estimate of the timescale of learning under the assumption that the initial weights are small, so that c 0 and θ 0 are close to 0 . In this case t = O ( τ /s ) (with a weak logarithmic dependence on the cutoff (i.e. ln(1 / ) ). This modestly generalizes the result given in the main text: the timescale of learning of each input-output mode α of the correlation matrix Σ 31 is in versely proportional to the correlation strength s α of the mode even when a and b differ slightly , i.e., c 0 small. This is not an unreasonable limit for random initial conditions because | c 0 | = | a · a − b · b | where a and b are random vectors of N 2 synaptic weights into and out of the hidden units. Thus we expect the lengths of the two random vectors to be approximately equal and therefore c 0 will be small relativ e to the length of each vector . These solutions are distinctly different from solutions for learning dynamics in three layer networks found in [20]. In our notation, in [20], it was sho wn that if the initial vectors a α and b α satisfy the matrix identity P α a α a α T = P α b α b α T then the dynamics of learning becomes equiv alent to a matrix Riccatti equation. Howe ver , the hyperbolic dynamics deriv ed here arises from a set of initial conditions that do not satisfy the restrictions of [20] and therefore do not arise through a solution to a matrix Ricatti equation. Moreover , in going beyond a statement of the matrix Riccatti solution, our analysis provides intuition about the time- scales ov er which the learning dynamics unfolds, and crucially , our methods extend beyond the three layer case to the arbitrary N l layer case, not studied in [20]. 16 B Optimal discr ete time learning rates In Section 2 we state results on the optimal learning rate as a function of depth in a deep linear network, which we deriv e here. Starting from the decoupled initial conditions giv en in the main text, the dynamics arise from gradient descent on E ( a 1 , · · · , a N l − 1 ) = 1 2 τ s − N l − 1 Y k =1 a k ! . (27) Hence for each a i we hav e ∂ E ∂ a i = − 1 τ s − N l − 1 Y k =1 a k ! N l − 1 Y k 6 = i a k ≡ f ( a i ) (28) The elements of the Hessian are thus ∂ 2 E ∂ a i a j = 1 τ N l − 1 Y k 6 = j a k N l − 1 Y k 6 = i a k − 1 τ s − N l − 1 Y k =1 a k ! N l − 1 Y k 6 = i,j a k (29) ≡ g ( a i , a j ) (30) for i 6 = j , and ∂ 2 E ∂ a 2 i = 1 τ N l − 1 Y k 6 = i a k 2 ≡ h ( a i ) (31) for i = j . W e now assume that we start on the symmetric manifold, such that a i = a j = a for all i, j . Thus we have E ( a ) = 1 2 τ s − a N l − 1 , (32) f ( a ) = − 1 τ s − a N l − 1 a N l − 2 , (33) g ( a ) = 2 τ a 2 N l − 4 − 1 τ sa N l − 3 (34) h ( a ) = 1 τ a 2 N l − 4 (35) The Hessian is H ( a ) = h g · · · g g g h · · · g g . . . . . . . . . g g · · · h g g g · · · g h . (36) One eigen vector is v 1 = [11 · · · 1] T with eigen value λ 1 = h + ( N l − 2) g , or λ 1 = (2 N l − 3) 1 τ a 2 N l − 4 − ( N l − 2) 1 τ sa N l − 3 . (37) 17 Now consider the second order update (Ne wton-Raphson) (here we use 1 to denote a vector of ones) a t +1 1 = a t 1 − H − 1 f ( a t )1 (38) = a t 1 − f ( a t ) H − 1 1 (39) a t +1 = a t − f ( a t ) /λ 1 ( a t ) (40) Note that the basin of attraction does not include small initial conditions, because for small a the Hessian is not positiv e definite. T o determine the optimal learning rate for first order gradient descent, we compute the maximum of λ 1 ov er the range of mode strengths that can be visited during learning, i.e., a ∈ [0 , s 1 / ( N l − 1) ] . This occurs at the optimum, a opt = s 1 / ( N l − 1) . Hence substituting this into (37) we ha ve λ 1 ( a opt ) = ( N l − 1) 1 τ s 2 N l − 4 N l − 1 . (41) The optimal learning rate α is proportional to 1 /λ 1 ( a opt ) , and hence scales as α ∼ O 1 N l s 2 (42) for large N l . B.1 Learning speeds with optimized lear ning rate How does the optimal learning rate impact learning speeds? W e compare the three layer learning time to the infinite depth limit learning time, with learning rate set inv ersely proportional to Eqn. (41) with proportion- ality constant c . This yields a three layer learning time t 3 of t 3 = c ln u f ( s − u 0 ) u 0 ( s − u f ) (43) and an infinite layer learning time t ∞ of t ∞ = c log u f ( u 0 − s ) u 0 ( u f − s ) + s u 0 − s u f , (44) Hence the difference is t ∞ − t 3 = cs u 0 − cs u f ≈ cs (45) where the final approximation is for u 0 = , u f = s − , and small. Thus very deep netw orks incur only a finite delay relativ e to shallow networks. C Experimental setup f or MNIST depth experiment W e trained deep linear networks on the MNIST dataset with fifteen different depths N l = { 3 , 5 , 8 , 10 , 14 , 20 , 28 , 36 , 44 , 54 , 64 , 74 , 84 , 94 , 100 } . Given a 784-dimensional input example, the netw ork tried to predict a 10-dimensional output vector containing a 1 in the index for the correct class, and zeros elsewhere. The network was trained using batch gradient descent via Eqn. (13) on the 50,000 sample MNIST training dataset. W e note that Eqn. (13) makes use of the linearity of the network to speed training and re- duce memory requirements. Instead of forward propagating all 50,000 training examples, we precompute 18 Σ 31 and forward propagate only it. This enables experiments on very deep networks that otherwise would be computationally infeasible. Experiments were accelerated on GPU hardw are using the GPUmat package. W e used ov ercomplete hidden layers of size 1000. Here the overcompleteness is simply to demonstrate the applicability of the theory to this case; o vercompleteness does not improv e the representational power of the network. Networks were initialized with decoupled initial conditions and starting initial mode strength u 0 = 0 . 001 , as described in the text. The random orthogonal matrices R l were selected by generating ran- dom Gaussian matrices and computing a QR decomposition to obtain an orthogonal matrix. Learning times were calculated as the iteration at which training error fell below a fix ed threshold of 1 . 3 × 10 4 corresponding to nearly complete learning. Note that this level of performance is grossly inferior to what can be obtained using nonlinear networks, which reflects the limited capacity of a linear network. W e optimized the learning rate λ separately for each depth by training each network with twenty rates logarithmically spaced between 10 − 4 and 10 − 7 and picking the one that yielded the minimum learning time according to our threshold crite- rion. The range 10 − 4 and 10 − 7 was selected via preliminary e xperiments to ensure that the optimal learning rate always lay in the interior of the range for all depths. D Efficacy of unsupervised pr etraining Recently high performance has been demonstrated in deep networks trained from random initial conditions [21, 13, 22, 3, 4, 1, 23], suggesting that deep networks may not be as hard to train as previously thought. These results sho w that pretraining is not necessary to obtain state-of-the-art performance, and to achiev e this they make use of a v ariety of techniques including carefully-scaled random initializations, more sophis- ticated second order or momentum-based optimization methods, and specialized con volutional architectures. It is therefore important to evaluate whether unsupervised pretraining is still useful, even if it is no longer necessary , for training deep networks. In particular , does pretraining still confer an optimization advantage and generalization adv antage when used in conjunction with these new techniques? Here we revie w results from a v ariety of papers, which collecti vely sho w that unsupervised pretraining still confers an optimization advantage and a generalization adv antage. D.1 Optimization advantage The optimization adv atage of pretraining refers to faster con vergence to the local optimum (i.e., faster learn- ing speeds) when starting from pretrained initializations as compared to random initializations. Faster learn- ing speeds starting from pretrained initial conditions have been consistently found with Hessian free opti- mization [21, 22]. This finding holds for two carefully-chosen random initialization schemes, the sparse connectivity scheme of [21], and the dense scaled scheme of [13] (as used by [22]). Hence pretraining still confers a conv ergence speed adv antage with second order methods. Pretrained initial conditions also result in f aster conv ergence than carefully-chosen random initializations when optimizing with stochastic gradient descent [22, 13]. In light of this, it appears that pretrained initial conditions confer an optimization advantage beyond what can be obtained currently with carefully-scaled random initializations, re gardless of optimization technique. If run to con ver gence, second order methods and well-chosen scalings can erase the discrepancy between the final objectiv e v alue obtained on the training set for pretrained relative to random initializations [21, 22]. The optimization advantage is thus purely one of conv ergence speed, not of finding a better local minimum. This coincides with the situation in linear networks, where all methods will ev en- tually attain the same global minimum, but the rate of con ver gence can vary . Our analysis shows why this optimization advantage due to pretraining persists o ver well-chosen random initializations. Finally , we note that Sutske ver et al. sho w that careful random initialization paired with carefully-tuned momentum can achieve excellent performance [23], but these experiments did not try pretrained initial conditions. Krizhevsk y et al. used con volutional architectures and did not attempt pretraining [1]. Thus 19 the possible utility of pretraining in combination with momentum, and in combination with con volutional architectures, dropout, and large supervised datasets, remains unclear . D.2 Generalization advantage Pretraining can also act as a special regularizer , improving generalization error in certain instances. This generalization advantage appears to persist with ne w second order methods [21, 22], and in comparison to gradient descent with careful random initializations [13, 22, 25, 4]. An analysis of this effect in deep linear networks is out of the scope of this work, though promising tools hav e been developed for the three layer linear case [20]. E Learning dynamics with task-aligned input corr elations In the main text we focused on orthogonal input correlations ( Σ 11 = I ) for simplicity , and to draw out the main intuitions. Howe ver our analysis can be extended to input correlations with a very particular structure. Recall that we decompose the input output correlations using the SVD as Σ 31 = U 33 S 31 V 11 T . W e can generalize our solutions to allow input correlations of the form Σ 11 = V 11 D V 11 T . Intuitively , this condition requires the ax es of v ariation in the input to coincide with the axes of v ariation in the input-output task, though the variances may dif fer . If we take D = I then we recov er the whitened case Σ 11 = I , and if we take D = Λ , then we can treat the autoencoding case. The final fixed points of the weights are giv en by the best rank N 2 approximation to Σ 31 (Σ 11 ) − 1 . Making the same change of variables as in Eqn. (4) we now obtain τ d dt W 21 = W 32 T ( S 31 − W 32 W 21 D ) , τ d dt W 32 = ( S 31 − W 32 W 21 D ) W 21 T . (46) which, again, is decoupled if W 32 and W 21 begin diagonal. Based on this it is straightforward to generalize our results for the learning dynamics. F MNIST pretraining experiment W e trained networks of depth 5 on the MNIST classification task with 200 hidden units per layer, starting either from small random initial conditions with each weight drawn independently from a Gaussian distribu- tion with standard deviation 0.01, or from greedy layerwise pretrained initial conditions. F or the pretrained network, each layer w as trained to reconstruct the output of the ne xt lower layer . In the finetuning stage, the network tried to predict a 10-dimensional output v ector containing a 1 in the index for the correct class, and zeros else where. The network was trained using batch gradient descent via Eqn. (13) on the 50,000 sam- ple MNIST training dataset. Since the network is linear, pretraining initializes the network with principal components of the input data, and, to the e xtent that the consistenc y condition of Eqn. (18) holds, decouples these modes throughout the deep network, as described in the main text. G Analysis of Neural Dynamics in Nonlinear Orthogonal Networks W e can deriv e a simple, analytical recursion relation for the propagation of neural population variance q l , defined in (21), across layers l under the nonlinear dynamics (20). W e hav e q l +1 = 1 N N X i =1 ( x l +1 i ) 2 = g 2 1 N N X i =1 φ ( x l i ) 2 , (47) 20 due to the dynamics in (20) and the orthogonality of W ( l +1 ,l ) . Now we know that by definition, the layer l population x l i has normalized v ariance q l . If we further assume that the distrib ution of activity across neurons in layer l is well approximated by a Gaussian distribution, we can replace the sum ov er neurons i with an integral o ver a zero mean unit variance Gaussian v ariable z : q l +1 = g 2 Z D z φ p q l z 2 , (48) where D z ≡ 1 √ 2 π e − 1 2 z 2 dz is the standard Gaussian measure. This map from input to output v ariance 0 0.5 1 1.5 2 0 0.2 0.4 0.6 0.8 q in q out Input to Output Variance Map at g=1 0 0.5 1 1.5 0 0.5 1 1.5 2 g q ∞ (g) Stable population variance versus gain Figure 8: Left : The map from v ariance in the input layer q in = q l to v ariance in the output layer q out = q l +1 in (48) for g = 1 and φ ( x ) = tanh( x ) . Right : The stable fixed points of this map, q ∞ ( g ) , as a function of the gain g . The red curve is the analytic theory obtained by numerically solving (49). The blue points are obtained via numerical simulations of the dynamics in (20) for networks of depth N l = 30 with N = 1000 neurons per layer . The asymptotic population v ariance q ∞ is obtained by av eraging the population variance in the last 5 layers. is numerically computed for g = 1 and φ ( x ) = tanh( x ) in Fig. 8, left (other values of g yield a simple 21 multiplicativ e scaling of this map). This recursion relation has a stable fixed point q ∞ ( g ) obtained by solving the nonlinear fixed point equation q ∞ = g 2 Z D z φ √ q ∞ z 2 . (49) Graphically , solving this equation corresponds to scaling the curv e in Fig. 8 left by g 2 and looking for intersections with the line of unity . For g < 1 , the only solution is q ∞ = 0 . For g > 1 , this solution remains, but it is unstable under the recurrence (48). Instead, for g > 1 , a new stable solution appears for some nonzero value of q ∞ . The entire set of stable solutions as a function of g is shown as the red curve in Fig. 8 right. It constitutes a theoretical prediction of the population variance at the deepest layers of a nonlinear network as the depth goes to infinity . It matches well for example, the empirical population variance obtained from numerical simulations of nonlinear networks of depth 30 (blue points in Fig. 8 right). Overall, these results indicate a dynamical phase transition in neural activity propagation through the non- linear network as g crosses the critical value g c = 1 . When g > 1 , acti vity propagates in a chaotic manner , and so g = 1 constitutes the edge of chaos. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment