깊은 선형 신경망 학습 역학의 정확한 해
이 논문은 깊은 선형 신경망의 가중치 공간에서 발생하는 비선형 경사하강 동역학을 정확히 풀어내어, 학습 과정에서 나타나는 장기간 정체와 급격한 전이, 깊이 증가에 따른 학습 속도 변화, 그리고 사전학습이 가져오는 가속 효과 등을 이론적으로 설명한다. 특히, 특정 초기조건(정규 직교 혹은 사전학습)에서는 네트워크 깊이에 관계없이 유한한 학습 속도를 유지함을 증명한다.
저자: Andrew M. Saxe, James L. McClell, Surya Ganguli
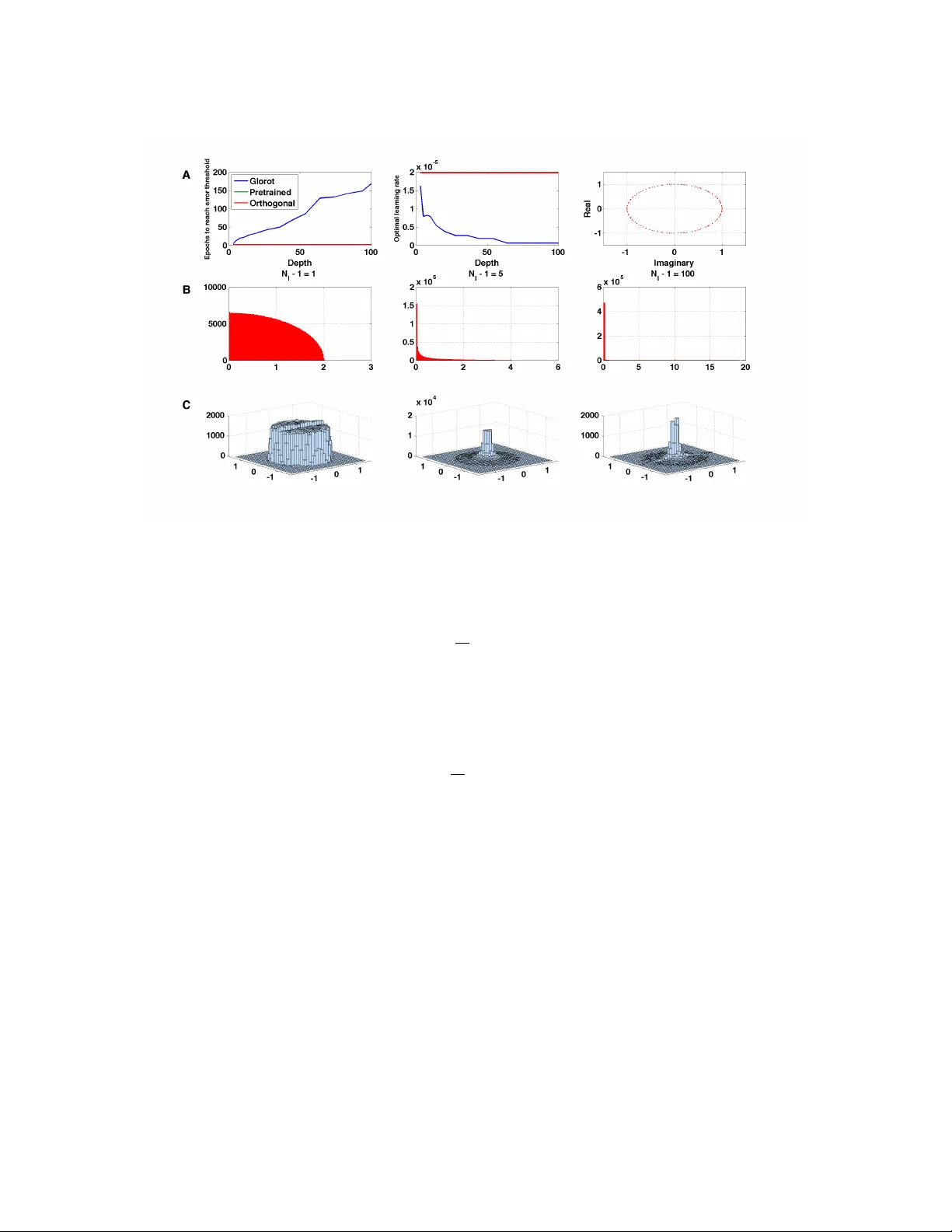
본 연구는 깊은 선형 신경망이 비선형 학습 동역학을 보이는 현상을 정확히 수학적으로 분석한다. 먼저, 입력‑출력 관계를 정의하는 상관행렬 Σ₃₁을 특이값 분해하여 각 모드의 강도 sα와 좌·우 특이벡터(uα, vα)를 도출한다. 입력 데이터가 백색화(Σ₁₁=I)된 경우, 가중치 행렬을 특이벡터 기반으로 회전시켜 동역학을 단순화한다. 이때 얻어지는 연립 비선형 미분 방정식은 두 층 사이의 연결 모드 aα와 bα가 서로 협력하면서 동일 모드의 곱 aα·bα를 sα에 맞추고, 서로 다른 모드 간에는 경쟁적으로 직교성을 유지하도록 만든다.
학습의 최종 고정점은 모든 활성 모드에 대해 aα·bα = sα이며, 이는 Σ₃₁의 강도 순위에 따라 가장 큰 N₂개의 모드만이 활성화되는 형태이다. 따라서 깊은 선형 네트워크는 결국 입력‑출력 상관행렬의 최저 차원 근사(rank N₂)로 수렴한다.
동역학을 정확히 풀기 위해 저자는 특수 초기조건을 고려한다. aα와 bα가 동일한 정규 기저 rα에 평행하고 서로 직교하도록 설정하면, 경쟁 항이 사라져 각 모드가 독립적인 2차원 시스템으로 분리된다. 이 시스템은 에너지 함수 E=½τ(s−ab)²의 그래디언트 흐름이며, a²−b²가 보존량이다. a=b인 경우 u=ab에 대한 동역학은 τ·du/dt = 2u(s−u) 로, 해는 로그 형태의 시간 적분식으로 표현된다. 초기값이 매우 작을 때 학습 시간은 τ/s·ln(s/u₀) 로, 모드 강도 s에 역비례한다는 중요한 결과를 얻는다. 즉, 데이터 내 강한 입력‑출력 관계는 빠르게 학습되고, 약한 관계는 장기간 정체 후 급격히 학습된다. 이러한 시그모이드 형태의 학습 곡선은 실제 비선형 네트워크 시뮬레이션에서도 관찰된다.
깊이가 무한대로 증가하는 경우에도, 위와 같은 정규 직교 초기조건을 사용하면 각 층의 스케일 변환이 상쇄되어 전체 학습 속도는 깊이에 독립적이다. 반면, 일반적인 스케일된 가우시안 초기화는 층마다 스케일이 누적돼 학습 지연이 깊이에 비례한다. 저자는 무작위 직교 초기화(orthogonal initialization)가 깊이와 무관한 학습 시간을 제공함을 증명하고, 이러한 초기조건이 비선형 네트워크에서도 ‘혼돈의 가장자리(edge of chaos)’ regime에서 그래디언트가 소실되지 않고 전파될 수 있음을 실험적으로 확인한다.
또한, 논문은 사전학습(greedy layer‑wise unsupervised pretraining)이 위의 특수 초기조건을 효과적으로 생성한다는 점을 보인다. 실제 MNIST 데이터에 대해 사전학습을 적용하면, 초기 가중치가 강한 모드에 맞춰 정렬되어 학습 속도가 크게 향상된다.
전체적으로, 이 연구는 깊은 선형 네트워크가 비선형 학습 현상을 어떻게 구현하는지, 학습 시간 스케일이 입력‑출력 모드 강도와 초기조건에 어떻게 의존하는지를 정확히 해석한다. 이러한 분석은 깊은 비선형 네트워크의 학습 역학을 이해하고, 효과적인 초기화 및 사전학습 전략을 설계하는 데 이론적 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기