Extension of Sparse Randomized Kaczmarz Algorithm for Multiple Measurement Vectors
The Kaczmarz algorithm is popular for iteratively solving an overdetermined system of linear equations. The traditional Kaczmarz algorithm can approximate the solution in few sweeps through the equations but a randomized version of the Kaczmarz algor…
Authors: Hemant Kumar Aggarwal, Angshul Majumdar
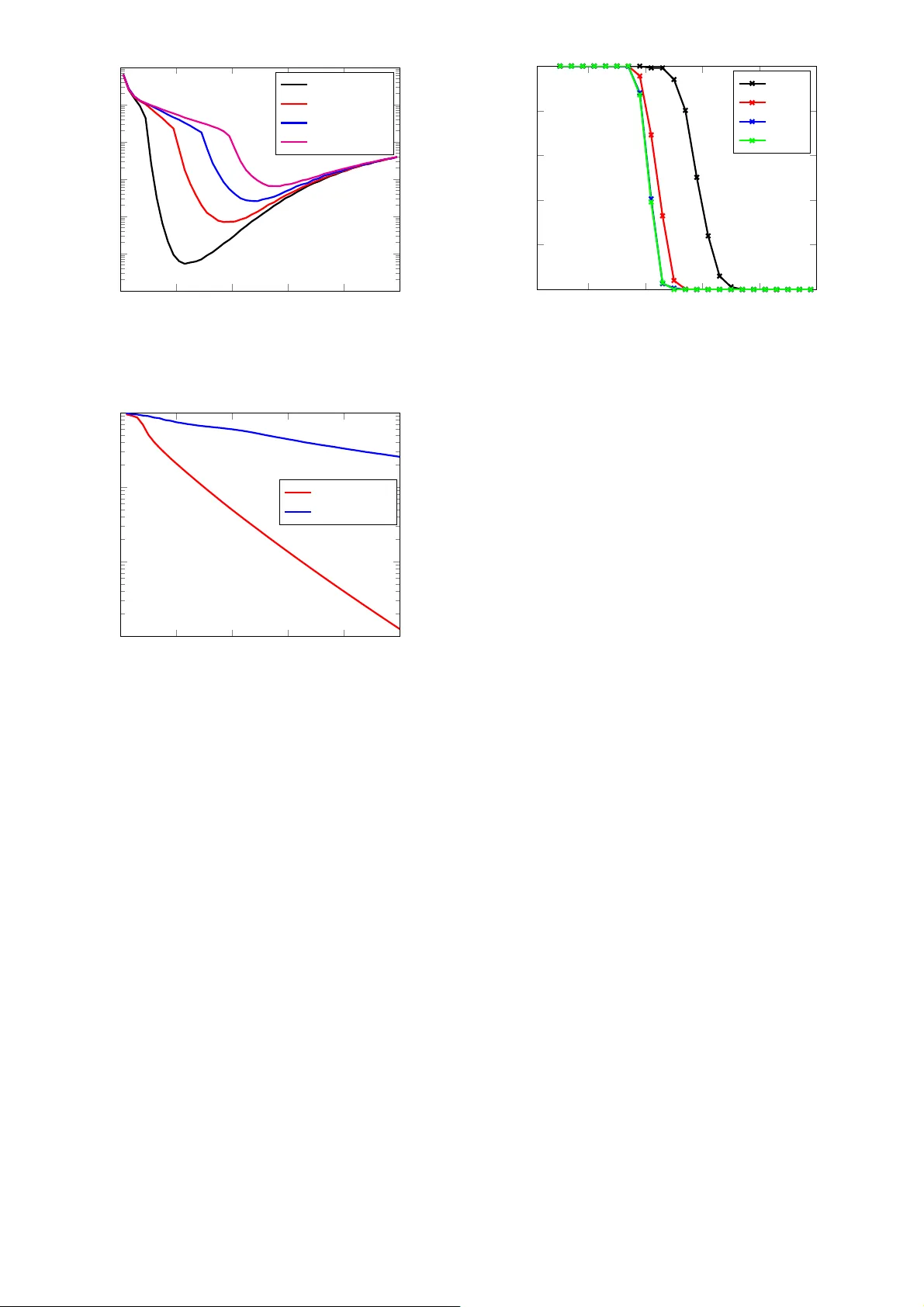
1 Extension of Sparse Randomized Kaczma rz Algorithm for Multiple Measurement V ectors Hemant Kumar Aggarwal and Angs hul Majumdar Indraprastha Institute of Information T echnolog y-Delhi, India Email: { he manta,angs hul } @iiitd.ac.in Abstract —The Kaczmarz algorithm is popular f or iterati vely solving an overdetermined system of equations. The traditi onal Kaczmarz algorithm can approx imate the solution in few swee ps through the equations but a randomized v ersion of th e Kaczmarz algorithm was shown to conv er ge exponentially and independ ent of number of equations. Recently an algorithm for fi nding sparse solution to a linear system of equ ations h as b een proposed based on weighted randomized Kaczmarz algorithm. T hese algorithms solves single measurement ve ctor problem; howev er there ar e applications wer e m ultiple-measurements are a va ilable. In this work, the objective is to solve a mul tiple measurement vector problem with common sparse support by modifying the random- ized Kaczmarz algorithm. W e h a ve also modeled th e problem of face recognition fr om video as the multip le m easurement vector problem and solved usin g ou r proposed technique. W e hav e compared the p roposed algorithm with state-of-art spectral projected gradient algorithm for multiple measurement vector s on both real and synthetic datasets. Th e Monte Carlo simu lations confirms that our proposed algorithm ha ve better reco ver y and con v ergence rate than the MMV version of spectral projected gradient algorithm u nder fairness constraints. I . I N T RO D U C T I O N The Kacz marz algorith m [1] iteratively solves a n overdeter- mined system o f linear equ ations. It is known for its speed, simplicity and memo ry efficiency . It has applications in various areas of sign al processing such as computed tomog raphy [2], nonlinear in verse pr oblems fo r semicond uctor equatio ns an d schlieren tomograp hy [3]. The Kaczmarz algorithm is also known as Algebr aic Reconstruction T echniq ue (AR T ) that can be u sed to solve problem of three-d imensional r econstruction from projectio ns in electron mic roscopy and r adiology [4]. The co n vergence of Kacz marz algorith m can be accelerated to an exponential ra te [5] by ran dom row selectio n criterion rather than seq uential selection. The rando mized Kacz marz (RK) algorithm was applied for reconstru ction of band -limited function s f rom nonu niform sam ples. This pa per [5] also proves that RK alg orithm can co n verge faster than co njugate g radient algorithm . Solving a linear system of e quations is gener ally termed as linear r egression. The Kac zmarz alg orithm provides a least squares solutio n to the regression problem. It is well known that the least squ ares solution is d ense. Such a d ense so lution lacks interpret- ability; i.e. the ob servations are in terpreted in terms of a ll the explan atory variables. This is not u seful in practice; ideally we would like to know the f e w variables which have co ntributed to the observations. In othe r words we seek a sparse solution. T o overcome the d eficiencies of least- squares solution s, the least ab solute shrinkage and selection operator (LASSO) was pro posed [6]. The LASSO problem try to minimize the sum of square erro r with an addition al sp arsity constraint o n regression variables to promote a sparse solution. The sparse so lution o f a linear system of equations is of particular interest in many different are as o f engineering and sciences including com pressed sensing [7]. Th ere ar e various approa ches to find sparse solutions. The mo st well known approa ch is to regulariz e the least squares solution by a sp arsity promo ting term such a s ℓ 1 -norm [8]. There are other gr eedy ap- proach es wh ich solve f or sparse outcome heuristically [9]. Re- cently th e spa rse ra ndomized Kaczmar z (SRK) algorith m [10] was pro posed to add ress the same p roblem. The SRK algor ithm is somewhere between the optim ization based app roach and the g reedy me thod. It yields an acc urate solution (similar to the op timization b ased a pproach ) but at speeds com parable to the gr eedy metho ds. SRK algorithm have been experimentally shown to conv erge faster than SPGL1 algo rithm un der fairness constraint of h aving almost eq ual number of vector-vector multiplications. There are application s such as neu ro-mag netic imaging [ 2] where multiple measur ements vectors (MMV) are ob tained and a solution is sought which has common sparse suppor t i.e. when all the measureme nt vectors are stacked as c olumns of a matrix , the solution will b e row-sparse owing to the requirem ent of common sparse sup port. The pro blem of spar se r ecovery from multiple measurem ents have been studied in [11]–[14]. In this work we p ropose a modification of SRK algorithm [10] for solving row-sparse MMV problem s. W e empirically show th at our propo sed algorith m have high recovery r ate and con verges faster than M MV version o f spectral pro jected grad ient a lgo- rithm [11] un der fairness co nstraint. W e h av e also shown the application of proposed algorithm to han dle sp arse classification [ 15] p roblems. In pa rticular we have m odeled the prob lem o f face recognition fro m video as multiple measurement problem and s olved it using our proposed technique . C omparison with MMV version of spectral projected gradient algor ithm [1 1] have also been done. The rest of th e p aper is organized into se veral sections. Section II describes the mathem atical p roblem formulation . The prop osed algo rithm is discussed in sectio n III. Section I V describes the sparse classification p roblem. Section V shows various experim ental results. The conclusion s of the work are discussed in sectio n VI. I I . M A T H E M A T I C A L R E P R E S E N T A T I O N The linear system of equ ations can be rep resented as b = Ax (1) where A ∈ R m × n and x ∈ R n . Howe ver th e analytical so lution to the overdetermined system of eq uations can b e fou nd by minimizing ℓ 2 -norm of er ror . Th is can be explicitly written as the u nconstrain ed conve x optimization pro blem (also called least-square pr oblem) : min x k b − Ax k 2 2 whose analytical solu tion is given by x = ( A T A ) − 1 A T b 2 Algorithm 1: SRK Algo rithm [10] 1 Input b = Ax , wher e A ∈ R m × n , b ∈ R m , estimated support size ˆ k , max imum iterations J 2 Output x j 3 Initialize S = { 1 , . . . , n } , j = 0 , x 0 = 0 4 while j ≤ J do 5 j = j + 1 6 Choose the r ow vector a i indexed by i ∈ { 1 , 2 , . . . , m } with pr obability k a i k 2 2 k A k 2 F 7 Identify the supp ort e stimate S , such that S = supp x j − 1 | max { ˆ k,n − j +1 } 8 Generate the weig ht vector w j such that w j ( ℓ ) = ( 1 , ℓ ∈ S 1 √ j ℓ ∈ S c 9 x j = x j − 1 + b i −h w j ⊙ a i ,x j − 1 i k w j ⊙ a i k 2 2 ( w j ⊙ a i ) T 10 end but when A is very large or when A is no t explicitly av ailable as a matrix but as a fast ope rator, e.g. Fourier , wavelet trans- form then it is comp utationally expensive to invert the matrix therefor e instead of analytica l solution the iterative solu tion is prefer red. The Kaczmarz algor ithm can find th e solu tion to (1) iteratively b y starting with some initial r andom estima te of solutio n and then sequentially moves fro m one equatio n to another . In this alg orithm, at every step the previous iter ate x k − 1 is orthog onally projected o n to th e space of all poin ts u ∈ C n defined by hyperp lane h a i , u i = b i . i.e: x k +1 = x k + b i − h a i , x k i k a i k 2 2 a T i where a i represents the i th row of A , b i represents the i th element o f vector b , an d i = k m o d m + 1 . Th e rate of con - vergence o f Kaczmarz method has been imp roved to expected exponential rate in the RK algor ithm. Strohmer and V ershynin’ s RK algorithm [5] random ly selects a ro w based on the r elevance of that r ow . T he p robability o f i th row was defined as k a i k 2 2 k A k 2 F , where k · k F represents the Frob enius norm of the matrix. T he benefit o f ran domly selecting a row is that th e r andomize d version conv erges very fast as com pare to seq uential Kaczmar z. Almost sure conv ergence of RK a lgorithm have also been proved in [1 6]. The set S 0 which contain s the ind exes of nonzer o entries in x is called the true supp ort o f vector x , more for mally S 0 can be wr itten as : S 0 = { i : x i 6 = 0 , x ∈ R n , i = 1 , . . . , n } The numb er of elements in the sup port set S 0 is den oted as K which rep resents the nu mber of non zero e lements in the vector x . This is also called sparsity of the solution. The variation of RK alg orithm to find the sparse solution of (1) is shown in Algorith m 1. This SRK algor ithm can find sparse solutio n in even lesser nu mber of iterations than RK algorithm . Since the support and sparsity are unknown there fore the SRK algorith m starts with a initial estimate of the sparsity with all the elements in the supp ort set. The n in e very iteratio n, the SRK algo rithm u pdates the estimated sup port set with the indexes of vector x which are larger in mag nitude and redu ce it by on e. The weightin g criterio n in j th iteration of SRK algorithm is: w j ( ℓ ) = ( 1 , ℓ ∈ S 1 √ j ℓ ∈ S c Algorithm 2: SRK-MMV Algorithm 1 Input B = AX , w here A ∈ R m × n , B ∈ R m × L , X ∈ R n × L estimated sup port size ˆ k , maximum iteration s J 2 Output X j 3 Initialize S = { 1 , . . . , n } , j = 0 , x 0 = 0 4 while j ≤ J do 5 j = j + 1 6 Find in dex idx of rows which are largest in ℓ 2 -norm 7 Choose nu mber of elemen ts in suppo rt set from i dx as max { ˆ k, n − j + 1 } 8 Choose the row vector a i indexed by i ∈ { 1 , 2 , . . . , m } with pr obability k a i k 2 2 k A k 2 F 9 Generate the weight vector w j such that w j ( ℓ ) = ( 1 , ℓ ∈ S 1 √ j ℓ ∈ S c 10 f or i = 1 to L do 11 x ( i ) = x ( i − 1) + b i −h w j ⊙ a i ,x ( i − 1) i k w j ⊙ a i k 2 2 ( w j ⊙ a i ) T 12 end 13 14 X J = [ x 1 , x 2 , . . . , x L ] 15 end It ensures that the undesired rows are r emoved from actual support as well as any missed row gets inclu ded in successive iterations. Th is is a heuristic m ethod an d does no t follow fr om any o ptimization theo ry . Howe ver , it work s amaz ingly well in practice. I I I . P RO P O S E D A L G O R I T H M In this work, we have extend the SRK algorithm to han dle multiple measurem ent vectors. The pr oblem o f m ultiple mea- surement vectors can be defined as follows: B = AX (2) where A ∈ R m × n and X ∈ R n × L and B ∈ R m × L . The matrices B , X a re c alled multip le measurem ent matr ix and source matrix respectively . Here L represen ts total number of multiple measurement vectors. This prob lem (2) can be decomp osed into several sing le m easurement vector ( SMV) problem s as: b ℓ = Ax ℓ ℓ = 1 , . . . , L where X = [ x 1 , . . . , x L ] and B = [ b 1 , . . . , b L ] , wh ich can b e individually solved usin g SRK algorithm but in th at case com- mon sparsity co nstraint may be v iolated as descr ibed in [12]. W e have changed two step s in th e SRK algo rithm to ha ndle multiple measurem ent vectors. T he first chang e we did is the way of selecting the supp ort set. T o ach iev e the commo n sparsity goal, we have updated the suppor t set with the in dexes of those rows of matr ix X which are largest in ℓ 2 -norm . The second chang e we did is th e proje ction step. W e did the projection for each of th e m ultiple measuremen ts to reach close to the solutio n in every sweep. The modified p rojection step which u pdates the matrix X can be co nsidered a s doing the ind i vidual pr ojections L times i.e. x ( i ) = x ( i − 1) + b i − h w j ⊙ a i , x ( i − 1) i k w j ⊙ a i k 2 2 ( w j ⊙ a i ) T i = 1 , . . . , L All th ese projec tions can be combined into matrix X as X = [ x 1 , x 2 , . . . , x L ] . W e refer to this propo sed m odified 3 SRK alg orithm as SRK-MMV alg orithm and is shown in Algorithm 2. I V . S PA R S E C L A S S I FI C AT I O N The Spar se Classification (SC) ap proach was first introd uced in [15]. It is assumed that the new test sample of a particular class can be expr essed as a lin ear combina tion of th e train ing samples belon ging to that c lass. For examp le if the test samp le belongs to class k, then v test = α k, 1 v k, 1 + · · · + α k,n v k,n (3) where v k,i represents th e i th sample of the k th class, v test is the test samp le (assum ed to be in the k th class) and α k,i is a linear weight. Equation 3 rep resents the test sample by th e training samp les of the correct class only . It can also be r epresented in terms of training samples of all classes (assuming there are c classes) a s v test = α 1 , 1 v 1 , 1 + · · · + α 1 ,n v 1 ,n + · · · + α k, 1 v k, 1 + . . . + α k,n v k,n + · · · + α c, 1 v c, 1 + · · · + α c,n v c,n (4) In a co ncise matrix-vector notation (4) can b e expressed as: v test = V α (5) V = v 1 , 1 | . . . | v 1 ,n | | {z } V 1 . . . v c, 1 | . . . | v c,n | {z } V c α = α 1 , 1 , . . . α 1 ,n | {z } α 1 , . . . , α c, 1 , . . . α c,n | {z } α c T The test sample ( v test ) is known, an d the m atrix f ormed b y stacking the training sam ples as column s ( V ) is also kn own. The linear weights vector ( α ) is unk nown. In [15], the first step tow ards c lassification is the comp utation of the linea r we ights by solving t he in verse problem (5 ). According to the assumption in [15], th e vecto r α will be sparse, i.e. it will have zeroes ev erywhere except f or α k , i.e. n on-zero values corre sponding to the co rrect class (assumed to be k ) . Solving α is the first step in the SC appro ach. W e do no t go into the detailed m echanism of the solu tion. It can b e solved u sing LASSO or greedy algo rithms like OMP . After α is obtained , in the next step the residu al for eac h class is computed as f ollows, res ( i ) = k v test − V i α i k 2 , ∀ i ∈ { 1 , c } The test sample is assigned to the class having the lowest residual. The term V i α i is the representative sample f or the i th class. Th e assumptio n is that, fo r the correct class ( k ), the representative samp le will b e similar to the test sample, and therefor e the resid ual error will b e the least. This app roach is suitable for image b ased r ecognition tasks in fact, it was a ctually ap plied fo r face recognitio n. T his p rob- lem was generalize d to the video b ased r ecognition pr oblem in [17]. It is assumed that there is a single tra ining video sequence av ailable for each per son. This is a realistic assump- tion, since in practical situations, e.g . custome r authen tication in ban ks, the training seq uence will be co mprised of o nly on e video sequ ence. Each frame of the v ideo sequ ence is an image that will be considered as a sample. When all the tr aining samples are stacked as column s, the ma trix V is the same as in ( 5). But instead o f a single te st samp le, will b e com prised of n fram es, i.e. ˆ v test = h v (1) test | . . . | v ( n ) test i Extendin g the assump tion in [15], each frame o f the test seq uence is assumed to be a linear combinatio n of the training fram es i.e . v ( j ) test = V α k , ∀ j ∈ { 1 , n } (6) Considering all the v ( j ) test in compact matr ix-vector notation, (6) can be expressed as the following Multip le Me asurement V ector (MMV) f ormulation , ˆ v test = V ˆ α (7) where ˆ α = α (1) | . . . | α ( n ) According to the assumption of SC, each of th e α ( i ) ’s will be sparse, i.e. they will have non- zero values only f or the co rrect class. Theref ore, the matrix will be r ow spar se, i.e. will it will have non-zero values on rows that c orrespon d to the correct class and zeros elsewhere. W e are not intere sted in the algorithm used f or e stimating ˆ α . On ce ˆ α is solved , finding th e class of the training sequen ce proc eeds similar to [ 15]. T he r esidual error is com puted f or each class, res ( i ) = k ˆ v test − V i ˆ α i k 2 , ∀ i ∈ { 1 , c } The class with the lowest residual error is assumed to be the class of th e training samp le. V . E X P E R I M E N T S A N D R E S U LT S Experime nts were done with synthetic an d real datasets which are described in following subsections. A. Synthe tic Da ta W e had conduc ted three sets o f experiments to find out perfor mance of the SRK-MMV algor ithm. T he first experiment was don e to estimate the e ffect of initial estimate of sparsity ( ˆ K ) on th e r elati ve error . The second experimen t was done to see the ef fect of in creasing th e n umber of iterations on the relativ e err or . T he th ird expe riment was do ne to see th e pe rfor- mance by varying the sparsity for different n umber o f multiple measuremen t vectors. In the second a nd th ird exper iment we also com pared our propo sed SRK-MMV algorithm with SPG- MMV [11] alg orithm. Effect of initia l sparsity estimate: The SRK algor ithm is dependen t on th e initial estimate of the true sparsity and theref ore our p roposed SRK-MMV alg orithm is also dep endent on in itial estimate of the tru e sparsity level. In the first experiment we show how th e perfo rmance o f SRK- MMV algorith m g ets affected by the c hange in estimated sparsity level. This experimen t gives a rough idea of what can be th e best approx imation of initial sp arsity level. W e gene rated random gaussion matrices A ∈ R m × n , X ∈ R n × L , B = AX with m = 5 00 , n = 10 0 , L = 5 , J = 5 . The to tal numb er of iter ations was set to be J × m i.e. total fiv e sweeps were done th rough all the rows of matrix A . Matr ix X was used only for ev aluation purpo se. Each colu mn o f X was K sp arse with common supp ort i.e. the in dexes of no nzero entries we re same fo r all co lumns of X . W e varied th e estimated sp arsity lev el ( ˆ K ) f rom 1 to 100 with a g ap of 2 and for each v alue of ˆ K a total o f 100 simu lations w ere carried out with different configur ations o f A, X and B . Th e pro cess was rep eated for 4 different values of K = 10 , 20 , 30, and 4 0. Figure 1 sho ws the effect of initial estimate of true sparsity ˆ K on th e relati ve roo t mean square error f or f our different spa rsity values K . Th e relative r oot mean squ are error is defined as Relati ve Error = k X − ˆ X k 2 F k X k 2 F 4 0 20 40 60 80 100 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 10 1 Estimated no. o f nonzero rows Relati ve Error Sparsity=10 Sparsity=20 Sparsity=30 Sparsity=40 Fig. 1. Effect of estimat ed number of nonzero ro ws on the relati ve error for dif feren t s parsity lev els on the proposed SRK-MMV algori thm 0 10 20 30 40 50 10 − 3 10 − 2 10 − 1 10 0 Sweeps ( 1 sweep = m iterations) Relati ve Error SRK-MMV SPG-MMV Fig. 2. Effe ct of increasin g the number of sweeps on the relati ve error for SRK-MMV and SPG-MMV algorithms in under-de termine d system where ˆ X is th e recovered matrix. I t is clea r fro m the figu re that fo r fewer n on-zero rows (i.e . K=10 or 20) relativ e err or is less if the estimated sup port is app roximately twice the a ctual support. However for comp arativ ely large nu mber of non -zero rows (K=30 or 4 0) this is not true a s fo r K = 4 0 the best initial estimated suppo rt ˆ K is about 50 and not 8 0. Effect of iterat ions: This exper iment was done for und er-determined system with following co nfiguratio ns: m = 1 00 , n = 400 , L = 5 , J = 50 , K = 10 , and estimated spar sity level of 20. The rela ti ve error was calculated f or each sweep of SRK-MMV an d SPG- MMV alg orithms f or a total o f 50 sweeps. This p rocess was repeated 5 00 times in different co nfiguration s and then the av erage erro r was p lotted against the num ber of sweeps as shown in Figure 2. The number o f iterations of SPG-MMV was limited to the number of iterations of SRK-MMV divide by m so as to e nsure fairness con straint [10]. Fro m the Figure 2 it is clear tha t SRK-MMV can converge faster as com pared to SPG-MMV . Effect of sparsity: This set of simulations we re carr ied out to fin d the effect of varying spar sity on the recovery rate of the algo rithm with different numb er of multip le measuremen t vectors. The experi- ment was done f or both overdetermined an d under-determin ed case. The experimental configur ation for overdeter mined case was 10 20 30 40 50 0 20 40 60 80 100 No. of nonzer o rows Recovery Rate L=2 L=5 L=10 L=15 Fig. 3. Ef fect of Decrea sing Sparsity for diffe rent Multiple Measurement V ec tors in overdet ermined system the following: m = 500 , n = 10 0 , J = 5 . Success threshold was set to 1 × 10 − 3 which means that if the relative error is less than th e su ccess thresho ld then r ecovery is termed as successful. The n umber of no n-zero rows were varied from 5 to 50 with step size of two. Initial estimated support was set to a ctual value o f suppo rt plus fifteen. For each sparsity level experiment was repeated 500 t imes with dif ferent co nfiguratio ns and the recovery r ate was calcula ted. This whole experiment was rep eated for fo ur different values o f m ultiple-measur ement vectors ( L =2, 5, 10 an d 15). Figure 3 sho ws h ow recovery rate varies as we increase the numbe r of no n-zero rows for different num ber o f multiple measuremen t vectors in the overdeter mined case. The results shows th at 100 % recovery rate can be achieved fo r fewer n on- zero rows (upto 20% of total nu mber of r ows) howe ver a s the numb er of non-zer o rows is increased the recovery rate decreases b ecomes zero whe n the nu mber of n on-zero rows is more tha n 40% of the total nu mber of rows. When m ultiple measuremen t vectors becom e large (i.e. 10 and 15) then the SRK-MMV alg orithm perfo rms well till abo ut the po int where the num ber of non-ze ro rows is 20 % of the to tal number of rows. The same exp eriment was repeated for under-determined case with the following con figurations: m = 50 , n = 20 0 , J = 50 and with th ree different values of multiple mea surements as L = 2 , 5 , and 10. Recovery rate was calculated for each sparsity lelvel K . Th e values o f K were varied from 1 to 25 with a gap of two. The value of estimated support was set to twice of a ctual sup port. Success threshold was set to 1 × 10 − 3 as before and this experimental setup was repeated 50 0 time s for three different values o f mu ltiple mea surements. W e also did compariso n with rec overy rate of SPG-M MV algorithm. Figure 4 shows the result of co mparison of recovery ra tes for SRK-MM V and SPG-MMV a lgorithms a s we increase the numb er of no nzero r ows f or different nu mber of m ultiple measuremen t vectors in the und er-determined case. The results shows that under th e fairness constrain t the recovery rate o f SRK-MMV alg orithm is high er than SPG-M MV algo rithm for different values of multiple m easurement vectors. B. Real Data W e choo se to use the V idTIMIT [18] d atabase which is designed for reco gnition of human faces f rom fr ontal views. The same database was used in th e previous work [1 7]. The dataset is com prised of vid eos and their correspon ding au dio 5 5 10 15 20 25 0 20 40 60 80 100 No. of no nzero rows Recovery Rate SRK-MMV(2) SPG-MMV(2) SRK-MMV(5) SPG-MMV(5) SRK-MMV(10) SPG-MMV(10) Fig. 4. Effe ct of increasin g the number of sweeps on the relati ve error for SRK-MMV and SPG-MMV algorithms in under-de termine d system T ABLE I R E CO G N I T I O N R A T E S I N % Method Number of Eigenfaces 20 40 60 80 SPG MMV [11] 78.04 90.01 94.55 97.28 SRK-MMV (proposed) 78.04 91.29 95.76 98.24 recordin gs for 4 3 people, reciting short sentence s. For each person ther e are 13 sequen ces; 3 seque nces contain he ad movements (n o audio) while 10 seque nces contain frontal vie ws reciting sho rt senten ces. The reco rding was done in an office en vironmen t using a broadcast quality digital video c amera. The video o f each pe rson is stored as a num bered sequence o f JPEG images with a resolution of 512 × 384 p ixels. quality setting of 90% was used d uring the creation of the JPEG frame images. In th is work, we work with the 10 sequen ces containing frontal faces. Leave-One-Out cross validation (LOO) is used for evaluation. For each person, a single sequence is used for training a nd the r emaining 9 sequences are u sed fo r testing. W e comp ute the ˆ α in (7) using two metho ds. In [1 7], th e spectral pro jected gr adient algorithm was used fo r so lving (7). In this work , we u se the prop osed SRK-MMV alg orithm for the same. I n T able I, the r ecognition rates fro m the two algorithm s are shown. The results a re shown for different lower dimensiona l Eig enface projections. The results show that the propo sed method fairs over MMV e specially wh en the num ber of Eigenfaces are large V I . C O N C L U S I O N The pro posed SRK-MMV algor ithm ca n handle the applica- tions were mu ltiple measuremen ts a re av ailable and the signal have same sparsity structure. Th e ℓ 2 -norm of each row was used as a heur istic to achieve row sp arsity . The algo rithm works fo r both over-determined and under-determin ed system of equations. Ex perimentally it was shown that high recovery rate can be achieved when d ata is su fficiently sparse ev en wh en we ha ve many multiple m easurement v ectors. Since SRK-MMV algorithm requir es a n initial estimate of actual sparsity therefore experimentally it was found that a goo d approximation of initial sparsity value is the twice of actu al spa rsity fo r sufficiently sparse d ata. Mon te Carlo simulations show tha t for the sam e number of vector-vector multiplications th e propo sed algorith m conv erges faster than state o f art SPG-MMV alg orithm. The sparse classification p roblem hav e also been considere d in this paper in particula r the prob lem of face recognitio n fr om v ideo was mod eled as the multip le measuremen t vector pro blem and solved using our prop osed tech nique SRK-MMV . Ex periments had shown that SRK-MMV alg orithm works well whe n number of Eigenfaces are large. Follo wing the philo sophy of reprodu cible research, our Matlab implementatio n of SRK-MMV algorithm is av a ilable from Matlab-Central website or via email to correspon ding author (A vailable from: http://www .math works.in/matlabcen tral/fileexchange/ 44 710- sparse-rand omized-k aczmarz-for-multiple-measurement- vectors). R E F E R E N C E S [1] Stefan Kaczmarz. Angen ¨ a herte aufl ¨ osung von systemen linearer gleichun- gen. Bulletin International de lAcademie P olonai se des Sciences et des Lettr es , 35:355–357, 1937. [2] Irina F . Gorodn itsky , John S. Geor ge, and Bhaskar D. Rao. Neuromagnetic source imaging with FOCUSS: a recursi ve weighted minimum norm algo- rithm. Electr oencephalo graph y and Clinica l Neur ophysi olog y , 95(4):231– 251, 1995. [3] Otmar Scherzer , Antonio Leit ˜ ao, Richard Ko w ar , and Markus Haltmeier . Kaczmarz methods for regul arizi ng nonlinea r ill-posed equati ons II: Applica tions. In ver se Pro blems and Imaging , 1(3):507–523, 2007. [4] Richard Gordon, Robert Bender , and Gabor T Herman. Algebraic recon- structio n techniques (AR T) for thre e-dimensi onal electron microscopy and x-ray photography . Journal of theor etic al Biology , 29(3):471 –481, 1970. [5] Thomas Strohmer and Roman V ershyni n. A Randomize d Kaczmarz Algorith m with Exponential Con ver genc e. Journal of F ourier Analysis and Applicat ions , 15(2):262–278, April 2008. [6] Robert Tibshiran i. Re gression Shrinkage and Selecti on via the Lasso. J ournal of the Royal Statistical Society , 58(1):267–288, 1996. [7] Emmanuel Candes, Justin Romberg, and T erenc e T ao. Stable Signal Re- cov ery from Incomplete and Inaccurat e Measurements. Communications on Pure and Applied Mathe matics , 59(8):1207–1223, 2006. [8] Ewout V an Den Berg and Michael P Friedland er . Probin g the pareto frontier for basis pursuit solu tions. SIAM J ournal on Scie ntific Computing , 31(2):890– 912, 2008. [9] Joel A Tropp and Anna C Gilbe rt. Signal Recov ery From Random Measurement s V ia Orthogonal Matching Pursuit. IEEE T ransactions on Informatio n Theory , 53(12):46 55–4666, 2007. [10] Hassan Mansour and O zgur Y ilmaz. A Fast Randomized Kaczmarz Algorith m for Sparse Solutions of Consistent Linear Systems. arX- i vID:1305.380 3v1, 2013. [11] Ewout v an den Berg and Michae l P . Friedlander . T heoret ical and Empirical Results for Recov ery From Multiple Measurements. IEEE T ransactions on Informatio n Theory , 56(5):25 16–2527, May 2010. [12] Shane F Cotter , Bhaskar D Rao, Kjersti E ngan, and Ke nneth Kreutz- delgado . Sparse Solution to Linear In verse Problems With Multiple Mea- surement V ectors. IE EE T ran sactions on Signal Pro cessing , 53(7):2477 – 2488, 2005. [13] Angshul Majumdar and Rabab K. W ard. Synthesis and analysis prior algorit hms for joint-spa rse recov ery. In IEEE International Confer ence on Acoustics, Speech, and Signal Proce ssing , pages 3421–3424. IEEE, 2012. [14] Andreas Argyriou, Theodoros Evgeniou, and Massimiliano Pontil. Con- ve x multi-ta sk feature learnin g. Machi ne L earning , 73(3):2 43–272, January 2008. [15] John Wright, Allen Y . Y ang, ARvin d Ganesh, S Shnkar Sastry , and Y i Ma. Robust fac e recogni tion via sparse representati on. IEEE transaction s on P attern Analysis and Machine Intellige nce , 31(2):210–227, February 2009. [16] Xuemei Chen and Alexa nder M Powe ll. Almost sure con ve rgenc e of the Kaczmarz algorith m with random measurements. J ournal of F ourier Analysis and A pplic ations , 18(6):1195–1214, 2012. [17] Angshul Majumdar and Rabab K. W ard. Face Recognitio n from V ideo : An MMV Recov ery Approach. In IEEE International Confer ence on Acoustics, Speec h, and Signal Pro cessing , pages 2221–2224, 2012. [18] C. Sanderson. Biometric P erson R eco gnitio n: F ace , Speech and Fusion. VDM-V er lag, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment