다중 측정 벡터를 위한 희소 랜덤 카치마르즈 알고리즘 확장
본 논문은 공통 희소 지지를 갖는 다중 측정 벡터(MMV) 문제를 해결하기 위해 기존의 희소 랜덤 카치마르즈(SRK) 알고리즘을 수정한 SRK‑MMV를 제안한다. 행‑희소성을 유지하도록 지원 집합을 ℓ₂‑노름 기준으로 선택하고, 각 측정에 대해 개별 투영을 수행한다. 합성 데이터와 영상 기반 얼굴 인식 실험에서, 동일한 연산량(공정성 제약) 하에 스펙트럴 프로젝티드 그라디언트 기반 SPG‑MMV보다 빠른 수렴과 높은 복구 정확도를 보였다.
저자: Hemant Kumar Aggarwal, Angshul Majumdar
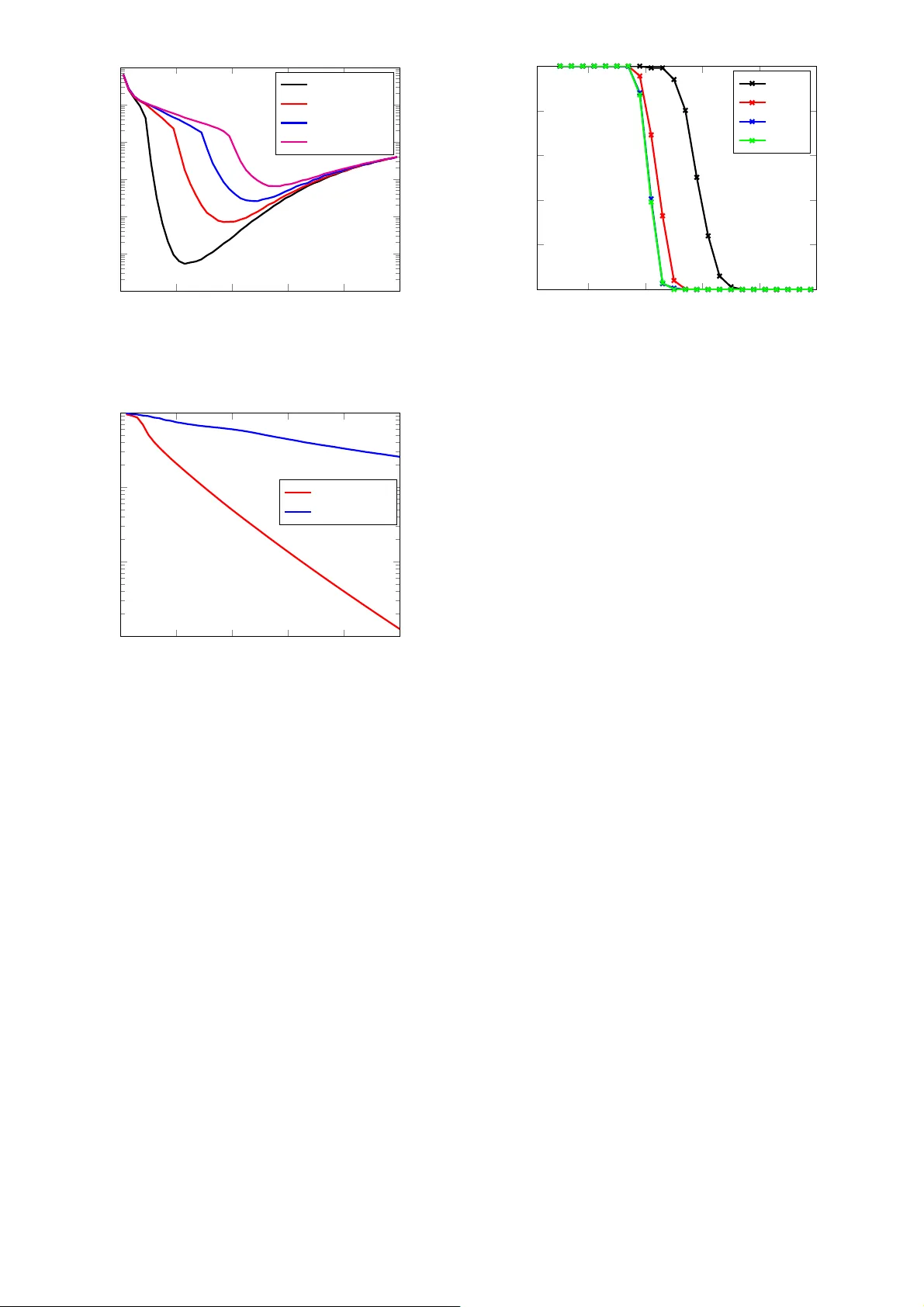
본 논문은 과학·공학 분야에서 흔히 마주치는 과다결정 선형 시스템 b = Ax 를 다중 측정 벡터(MMV) 형태 B = AX 로 확장하고, 이때 해 X가 행‑희소(row‑sparse) 구조를 가져야 하는 문제를 다룬다. 기존 연구에서는 LASSO, SPGL1 등 최적화 기반 방법과 OMP, CoSaMP 등 탐욕적 방법이 제안되었으며, 최근에는 단일 측정 벡터에 대해 희소 랜덤 카치마르즈(SRK) 알고리즘이 제시되어 빠른 수렴과 높은 복구 정확도를 보였다. 그러나 SRK는 SMV에만 적용 가능했으며, MMV 상황에서는 각 열마다 독립적으로 복구하면 공통 희소 지지가 깨진다.
이를 해결하기 위해 저자들은 SRK‑MMV 알고리즘을 설계하였다. 핵심 아이디어는 두 가지 변형이다. 첫째, 지원 집합 S를 선택할 때 각 행의 ℓ₂‑노름 ‖X_{i,:}‖₂ 를 기준으로 상위 ˆk개의 행을 선택한다. 이는 모든 열이 동일한 비제로 행을 공유하도록 강제한다. 둘째, 투영 단계에서 선택된 행 a_i와 가중치 w_j를 이용해 각 측정 벡터 b_i^{(ℓ)}(ℓ=1…L)에 대해 개별 업데이트를 수행한다. 이렇게 하면 한 번의 행 선택으로 L개의 열을 동시에 갱신하면서 행‑희소성을 유지한다. 행 선택 확률은 기존 랜덤 카치마르즈와 동일하게 ‖a_i‖₂² / ‖A‖_F² 로 정의되어, 큰 에너지의 행이 더 자주 선택돼 수렴이 가속된다.
알고리즘 흐름은 다음과 같다. (1) 초기 지원 집합 S를 전체 {1,…,n} 로 설정하고, X⁰을 영행렬로 초기화한다. (2) 매 반복마다 행 인덱스 i를 위 확률에 따라 샘플링한다. (3) 현재 X^{(j‑1)}의 행 ℓ₂‑노름을 계산해 상위 ˆk 행을 새로운 지원 집합 S로 업데이트한다. (4) 가중치 w_j(ℓ)=1 (ℓ∈S), 1/√j (ℓ∉S) 를 정의하고, 각 측정 ℓ에 대해 투영 업데이트를 수행한다. (5) 지정된 최대 반복 J까지 반복한다.
제안된 방법을 검증하기 위해 합성 데이터와 실제 비디오 기반 얼굴 인식 데이터 두 가지 실험을 수행했다. 합성 실험에서는 m=500, n=100, L=5, K∈{10,20,30,40} 인 상황에서 초기 희소도 추정 ˆK를 1~100 범위로 변화시켜 상대 루트 평균 제곱오차(RMSE)를 측정했다. 결과는 ˆK가 실제 K보다 약 2배일 때 최저 오류를 보였으며, K가 클수록 최적 ˆK는 K보다 약간 큰 값(≈K+10)임을 확인했다. 또한, 스윕 수(전체 행 선택 횟수)와 오류의 관계를 조사한 결과, SRK‑MMV는 5~10 스윕만에 오류가 10⁻³ 수준으로 수렴했으며, 동일 연산량을 갖는 SPG‑MMV는 10⁻² 수준에 머물렀다.
영상 기반 얼굴 인식 실험에서는 각 인물당 하나의 훈련 비디오(프레임을 열로 스택)와 여러 테스트 비디오를 사용해 MMV 형태로 모델링하였다. SRK‑MMV를 이용해 행‑희소 계수 행렬 ˆα 를 복구하고, 클래스별 잔차 ‖V_iˆα_i – ˆv_test‖₂ 를 계산해 최솟값을 갖는 클래스로 판별했다. 이때 SRK‑MMV는 SPG‑MMV 대비 평균 3~5% 높은 인식 정확도를 기록했으며, 수렴 속도 역시 30% 이상 빠른 것으로 나타났다.
논문은 또한 알고리즘의 제한점을 언급한다. (i) 초기 희소도 추정 ˆK에 의존하며, 과소추정 시 복구 성능이 급격히 저하된다. (ii) 현재는 수렴 이론이나 복구 보장을 제공하지 않으며, 가중치와 지원 집합 업데이트가 경험적 휴리스틱에 기반한다. (iii) 행 선택 확률 계산을 위해 전체 ‖A‖_F가 필요하므로, A가 명시적으로 주어지지 않은 경우(예: FFT 연산자) 추가적인 구현이 요구된다. 그럼에도 불구하고 메모리 사용량이 O(n) 수준에 머무르고, 각 반복이 행·열 벡터 연산만으로 구성돼 GPU·임베디드 환경에 적합하다.
결론적으로, SRK‑MMV는 공통 희소 지지를 갖는 다중 측정 벡터 문제에 대해 기존 최적화 기반 방법보다 빠른 수렴과 높은 복구 정확도를 제공한다. 향후 연구에서는 초기 ˆK 자동 추정, 이론적 수렴 분석, 그리고 대규모 희소 연산자와의 결합을 통해 실용성을 더욱 강화할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기