Near-separable Non-negative Matrix Factorization with $ell_1$- and Bregman Loss Functions
Recently, a family of tractable NMF algorithms have been proposed under the assumption that the data matrix satisfies a separability condition Donoho & Stodden (2003); Arora et al. (2012). Geometrically, this condition reformulates the NMF problem as…
Authors: Abhishek Kumar, Vikas Sindhwani
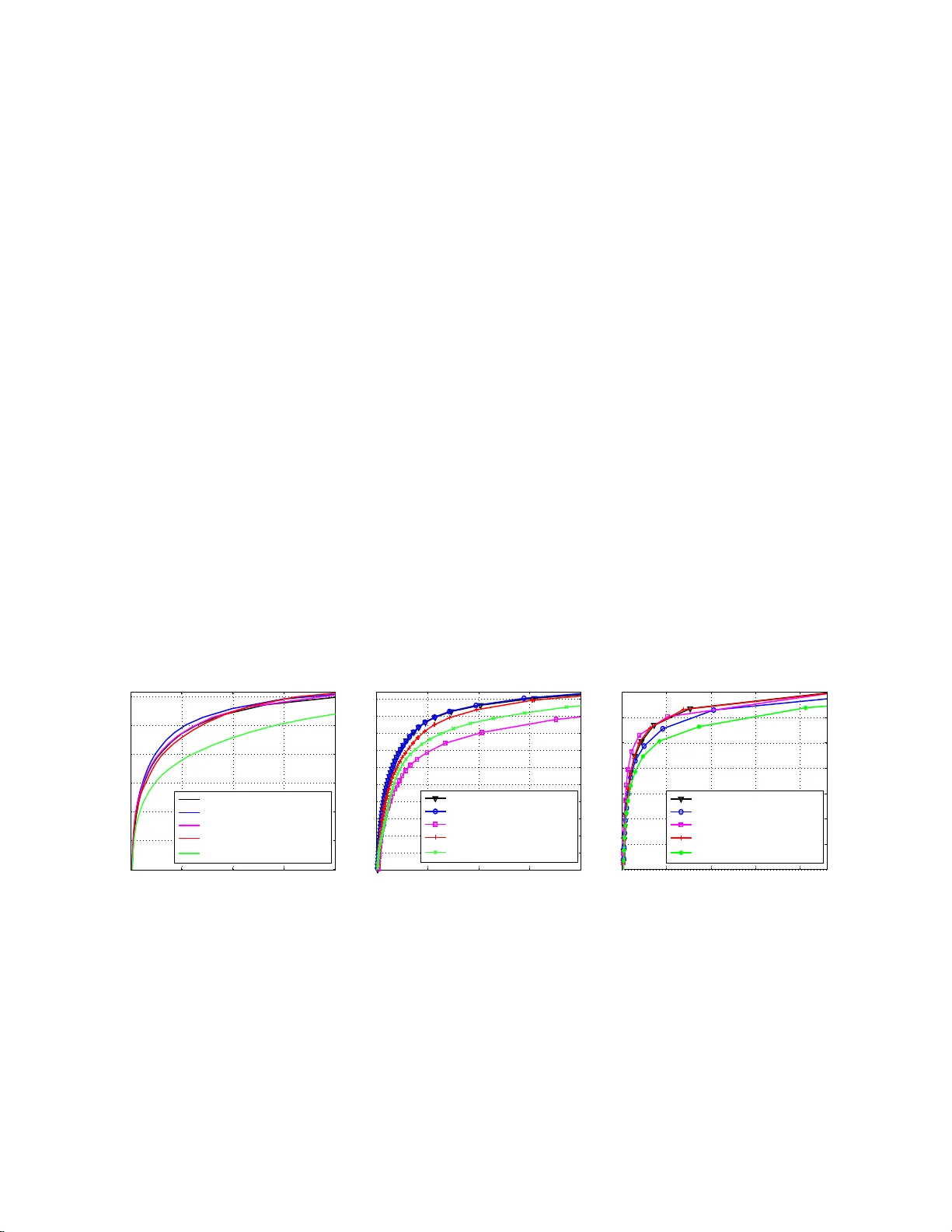
Near-separable Non-negativ e Matrix F actorization with ℓ 1 - and Bregman Loss F unctions Abhishek Kumar Vik as Sindh wani { abhishk,vsindh w } @us.ibm.com IBM T.J. W atson Researc h Center, Y orkto wn Heigh ts, NY 105 98 USA Abstract Recently , a family of tractable NMF algo rithms ha ve been pr op osed under the assumption that the data matr ix satisfies a separ ability condition Donoho & Sto dden (2 0 03); Arora et al. (2012). Geometrically , this condition reformulates the NMF problem as that of finding the extreme ra ys o f the conical h ull of a finite set of vectors. In this pap er, w e dev elop sev eral ex- tensions of the conical hu ll pro cedures of Kumar et a l. (20 13) for robust ( ℓ 1 ) appr oximations and Bregman div ergences . O ur metho ds inherit all the adv antages of Kumar et al. (2013) including scalability and noise- tolerance. W e sho w that on for eground-ba ckground separation pro blems in computer vision, robust near-separable NMFs match the p e rformance of Robust PCA, c o n- sidered sta te o f the a r t on these pr o blems, with an order of mag nitude faster training time. W e also demonstra te applica tions in ex e mpla r selection settings. 1 In tro duction The problem of non-negativ e matrix facto rization (NMF) is to expr ess a non-negativ e matrix X of size m × n , either exactly or appro x im ately , as a pro d uct of t wo non-negativ e matrice s, W of size m × r and H of size r × n . App ro ximate NMF attempts to minimize a measur e o f diverge nce b et we en the matrix X and the fac torization WH . The inner-dimension of the factoriza tion r is usually tak en to b e m uch smaller th an m and n to g et in terp retable part-based represen tation of data Lee & Seung (199 9 ). NMF is used in a wide range of applications, e.g., topic mo d eling and text m ining, h yp er-sp ectral image analysis, audio s ource separation, and microarra y data analysis Cic h o c ki et al. (20 09). The exact and approximat e NMF problem is NP-hard. Hence, traditionally , algorithmic w ork in NMF h as fo cused on treating it as an instance of non-con ve x optimization C ic h o c ki et al. (2009); Lee & S eung (1999); Lin (2007); Hsieh & Dhillon (20 11) leading to al gorithms lac king optimal- it y guarante es b ey ond con v ergence to a stationary p oin t. Promising alternativ e app roac h es ha v e emerged rece ntly b ased on a sep ar ability assumption o n the d ata Arora et al. (2012 ); Bittorf et al. (2012); Gillis & V a v asis (2012); Kum ar et al. (2013); Esser et al. (2012) w hic h enables the NMF problem to b e solv ed efficien tly and exactly . Und er this assumption, the data matrix X is said to b e r -separable if all column s of X are con tained in the conical hull generated by a subset of r columns of X . In other words, if X admits a factorizatio n WH then the separability assump tion states that the columns of W are p resen t in X at p ositions giv en by an u nkno wn index set A of 1 Figure 1: Robu st Xra y applied to video b ac kgroun d-foreground separation problem size r . Equiv alent ly , the corresp ond ing columns of the right factor matrix H constitute the r × r iden tit y matrix, i.e., H A = I . W e refer to these columns in d exed by A as anchor c olumns . The separability assump tion wa s fi rst inv estigated by Donoho & Sto dden (2003) in the con- text of deriving conditions f or u n iqueness of NMF. NMF u n der separab ility assump tion has b een studied for topic mo deling in text Kumar et al. (2 013 ); Arora et al. (2013) and h yp er-sp ectral imaging Gillis & V av asis (2012); Esser et al. (2012 ), an d s ep arabilit y has tur ned out to b e a r ea- sonable assumption in these t w o applications. In the context of topic mo deling where X is a do cument- word matrix and W , H are do cument-t opic and topic-w ord asso ciations resp ectiv ely , it translates to assuming that there is at least one w ord in eve ry topic that is unique to itself and is not presen t in ot her topics. Our starting p oin t in this pap er is the family of conical h ull fin ding pro cedur es calle d Xr a y intro- duced in Ku m ar et al. (2013) for n ear-separable NMF p roblems with F r ob enius norm loss. Xra y fi nds anc hor columns one after the other, increment ally expandin g the cone and using exterior columns to lo cate the next anc hor. Xra y has seve ral app ealing f eatures: (i) it r equires no more than r iterations eac h of w hic h is parallelizable, (ii) it emp ir ically demons tr ates noise-tolerance, (iii) it ad- mits efficien t mo del selection, and (iv) it d o es not requ ire normalizatio ns or prep r o cessing needed in other methods . Ho w ev er, in the presence of outliers or d ifferen t noise c haracteristics, the use of F rob enius norm approximat ions is not optimal. In this p ap er, we extend Xra y to p ro vide robu st factorizat ions w ith resp ect to ℓ 1 loss, and appro ximations w ith resp ect to the family of Bregman dive rgences. Figure 1 sho ws a motiv ating application fr om compu ter vision. Giv en a sequen ce of video frames, the goal is to sep arate a n ear- stationary bac kground from the foreground of mo ving ob jects that are relativ ely mo re dynamic across frames b ut span only a few pixels. In this setti ng, it is n atural to seek a lo w -rank bac kground matrix B that minimizes k X − B k 1 where X is th e frame-b y-pixel video matrix, and the ℓ 1 loss imp oses a sparsity pr ior on the residu al f oreground. Unlike the case of lo w -rank approximat ions in F r ob enius or sp ectral norms, this problem d o es not admit an S VD-lik e tractable solution. The Robust Principal Comp onen t Analysis (RPC A), considered state of the art for this application, uses a nuclear-norm conv ex relaxation of the lo w-rank constrain ts. In th is pap er, w e instead reco ver tractabilit y by imp osing the separable NMF assump tion on the b ackg roun d matrix. This imp lies that the v ariabilit y of pixels across the frames can b e ”explained” in terms of observ ed v ariabilit y in a small set of anchor pixels. Under a more restrictiv e setting, this can b e sho wn to b e equiv alen t to m edian filtering on the video frames, while a full near-separable NMF mo del imp arts more degrees of freedom to mo del the b ac kgroun d. W e sh o w that the pr op osed near-separable NMF algorithms with ℓ 1 loss are comp etitiv e with RPCA in separat ing foreground fr om bac kground while outp erforming it in terms of computational efficiency . Our algorithms are empirically sho wn to b e robus t to noise (deviations from the pure s epara- bilit y assum p tion). I n ad d ition to the b ac k grou n d-foreground prob lem, we also d emons trate our algorithms on the exemplar select ion problem. F or iden tifying exemplars in a data set, the pr op osed 2 Figure 2: Geometrical illustration of the alg orithm algorithms are ev aluated on text do cuments with classification accuracy as a p erformance metric and are sho wn to outp erform the rece ntly prop osed method of Elhamifar et al. (2012). Related W ork: Existing separable NMF metho ds work either with only a limited num b er of loss fun ctions on the factorizatio n error such as F r ob enius norm loss Kumar et al. (2013), ℓ 1 , ∞ norm loss Bittorf et al. (2 012), or maximize pr oxy criteria such as vo lume of the con vex p olyhedr on with an chor column s as vertice s Gillis & V a v asis (2012 ) and d istance b etw een successive anchors Arora et al. (2013) t o select the anchor column s . On the other h and, local sea rc h based NMF metho ds Cic ho c ki et al. (2009) ha ve b een prop osed for a wide v ariet y of loss functions on the factorizat ion error includin g ℓ 1 norm loss Guan et al. (2012); Kim & P ark (2007) and instances of Bregman diverge nce Li et al. (2012); Sra & Dhillon (2005). In this pap er, we close this gap and prop ose alg orithms for near-separable NMF that min imize ℓ 1 loss and Bregman div ergence for the factorizat ion. 2 Geometric In tuition The goal in exact NMF is to find a matrix W such that the cone generated by its columns (i.e., their non-negativ e linear combinations) con tains all columns of X . Under separabilit y assumption, the columns of m atrix W are to b e p ic ked d irectly from X , also known as anc hor columns. The algorithms in this pap er b uild the cone incremen tally b y pic king a column fr om X in ev ery iteration. The algo rithms execute r su c h iterat ions for constructing a factoriz ation of inner-dimension r . Figure 2 shows the cone after three iterations of the algorithm when three anc hor columns hav e b een identi fied. An extreme ray { t x : t > 0 } is asso ciated with ev ery anchor p oin t x . T he p oints on an extreme ra y cannot b e expressed as conic com bin ations of other p oin ts in the cone th at do not themselv es lie on that extreme ray . T o id en tify the next anchor column, the algorithm pic ks a p oint outside the cur ren t cone (a green p oint) and pro jects it to the cur ren t cone so that th e distance b et we en the p oin t and the pr o jectio n is minimized in term s of the desired measure of distance. This pro jection is th en used to setup a sp ecific sim p le criteria which when maximized o v er the data p oint s, ident ifies a n ew anchor. This n ew anchor is then added to the current set of anc hors and the cone is expand ed iterat iv ely until all anc hors ha v e b een pic ked. These geometric in tuitions are inspired b y Clarkson (19 94); Dula et al. (199 8 ) who presen t linear programming (LP) based algorithms for general conv ex and conical hull pr oblems. Their algorithms use ℓ 2 pro jections of exterior p oin ts to the cu rrent co ne and are also applicable in our NMF setting if the data matrix X satisfies r -separabilit y exactly . In this case, the ℓ 2 pro jection and co rresp onding resid ual vec tor of any sin gle exterior p oint can b e used to expand the cone and 3 al l r an chors will b e reco vered correctly at the end of the algorithm. When X do es n ot satisfy r - separabilit y exactly , anchor selec tion criteria derived from multiple r esiduals demonstrate sup erior noise robustness as empirically shown by Kumar et al. (2013 ) wh o consider the case of Gauss ian i.i.d. n oise. How ev er, the algorithms of Kumar et al. (2013 ) are not s uitable for noise distributions other than Gaussian (e.g., other member s of the exp onentia l family , sparse noise) as they minimize k X − X A H k 2 F . In the follo wing sections, we p resen t algorithms for near-separable NMF that are targeted p r ecisely to w ards this goal and emp irically demonstrate t heir sup eriorit y o v er existing algorithms under differen t noise distribu tions. 3 Near-separable NMF with ℓ 1 loss This section consid ers the case when th e pur e s ep arable structure is p erturb ed by sparse noise. Hence our aim is to minimize k X − X A H k 1 for H ≥ 0 where k·k 1 denotes ele ment- wise ℓ 1 norm of the matrix and X A are the columns o f X indexed by set A ⊂ { 1 , 2 , . . . , n } . W e denote i th column of X b y X i . The prop osed algorithm pr o ceeds b y iden tifying one an chor column in eac h iteration and addin g it to the current set of anchors, thus expand ing the cone generated by anc hors. Eac h iteration consists of tw o steps: (i) anchor sele ction step that finds the column of X to b e added as an anc hor, and (ii) a pr oje ction step wh er e all data p oin ts (columns of X ) are p ro jected to the current cone in terms of minimizing the ℓ 1 norm. Algorithm 1 outlines the steps of the p r op osed algorithm. Selection Step : In th e selection step, we normalize all the p oints to lie on the h yp er p lane p T x = 1 ( Y j = X j p T X j ) for a strictly p ositiv e ve ctor p and ev aluate th e selection criterion of Eq. 3 to select the next anc hor column . Note that an y exterior p oin t ( i : k R i k 1 ≥ 0) can b e used in the selection criterion – Algorithm 1 sh o ws tw o p ossibilities for c ho osing the exterior p oint. T aking the p oint with maximum residual ℓ 1 norm to b e the exterior p oin t turn s out to b e far more robust to noise than randomly choosing the exterior p oint , as observ ed in our n umerical sim ulations. Pro jection Step : The pro jection step, Eq. 4, in v olv es solving a multi v ariate least absolute devitations problems with non-negativit y constrain ts. W e w e use alternating direction metho d of m ultipliers (ADMM) Bo yd et al. (2011) and reform u late the p roblem as min B ≥ 0 , Z k Z k 1 , su ch that X A B + Z = X . Th us the non-negativit y co nstraints are d ecoupled from the ℓ 1 ob jectiv e and th e ADMM optimiza- tion pr o ceeds by alternating b et ween t w o sub-problems – a standard ℓ 1 p enalized ℓ 2 pro ximit y problem in v ariable Z wh ic h has a closed f orm solution usin g the soft-thresholding op erator, and a n on-negativ e least squares p roblem in v ariable B that is solv ed using a cyclic co ord inate d escen t approac h (cf. Algorithm 2 in Kumar et al. (201 3 )). The standard p rimal and du al residuals based criteria is used to d eclare conv ergence Bo yd et al. (2 011). T h e ADMM pro cedure co nv erges to the global optim u m since the pr oblem is conv ex. W e now show that Algorithm 1 correctly iden tifies all the anc hors in pu r e separb le case. Lemma 3.1. L et R b e the r esidual matrix obtaine d after ℓ 1 pr oje ction of c olumns of X onto the curr ent c one and D b e the se t of matric es su ch D ij = sig n ( R ij ) if R ij 6 = 0 else D ij ∈ [ − 1 , 1] . Then, ther e exists at le ast one D ⋆ ∈ D such that D ⋆ T X A ≤ 0 , wher e X A ar e anchor c olumns sele cte d so far by Algorithm 1. 4 Algorithm 1 Robust Xra y : Near-separable NMF with ℓ 1 loss Input: X ∈ R m × n + , inner dimensio n r Output: W ∈ R m × r , H ∈ R r × n , r indices in A such that: X = WH , W = X A Initialize: R ← X , D ⋆ ← X , A ← {} while | A | < r do 1. Anchor Sel e ction step : First, pick any p o int exterior to the curren t cone. Two p oss ible cr iteria ar e r and : any random i : k R i k 1 > 0 (1) max : i = arg m ax k k R k k 1 (2) Cho ose a suitable D ⋆ i ∈ D i where D j i = si g n ( R j i ) if R j i 6 = 0, else D j i ∈ [ − 1 , 1] (see Remar k (1)). Select an anchor as follows ( p is a str ictly p ositive vector, not co llinear with D ⋆ i (see Remark (3))): j ⋆ = arg max j D ⋆ T i X j p T X j (3) 2. Up date: A ← A ∪ { j ⋆ } (see Remark (2)) 3. Pr oje ction step : Pr oje ct onto curr ent c one. H = arg min B ≥ 0 k X − X A B k 1 (ADMM) (4) 4. Up date Residuals: R = X − X A H end whi le Pr o of. Residuals are give n by R = X − X A H , where H = arg min B ≥ 0 k X − X A B k 1 . F orming the Lagrangian for Eq. 4, we get L ( B , Λ ) = k X − X A B k 1 − tr ( Λ T B ), where the matrix Λ con tains the n on-negativ e Lagrange m ultipliers. The Lag rangian is not smooth ev eryw h ere and its sub-differentia l is giv en b y ∂ L = − X T A D − Λ where D is as defined in the lemma. A t the optimum B = H , we hav e 0 ∈ ∂ L ⇒ − Λ ∈ X T A D . S ince Λ ≥ 0, this means that th ere exists at least one D ⋆ ∈ D for wh ic h D ⋆ T X A ≤ 0. Lemma 3.2. F or any p oint X i exterior to the curr ent c one, ther e exists at le ast one D ⋆ ∈ D such that it satisfies the pr evious lemma and D ⋆ T i X i > 0 . Pr o of. Let R = X − X A H , wh ere H = arg min B ≥ 0 k X − X A B k 1 and X A are the cur ren t set of anc h ors. F rom the pro of of previous lemma, − Λ T ∈ D T X A . Hence, − Λ T i ∈ D T i X A ( i th ro w of b oth left and right side matrices). F r om the complementary slac kness condition, we ha ve Λ j i H j i = 0 ∀ j, i . Hence, − Λ T i H i = 0 ∈ D T i X A H i . Since all KKT conditions are met at the optim um, there is at least one D ⋆ ∈ D th at satisfies previous lemma and for wh ic h D ⋆ T i X A H i = 0. F or this D ⋆ , we hav e D ⋆ T i X i = D ⋆ T i ( R i + X A H i ) = D ⋆ T i R i = k R i k 1 > 0 since R i 6 = 0 f or an exte rior p oin t. Using the ab ov e t wo lemmas, w e prov e the follo wing theorem regarding the correctness of Algorithm 1 in pu re sep arable case. Theorem 3.1. If the maximizer in Eq. 3 is uniq u e, the data p oint X j ⋆ adde d at e ach iter ation in the Sele ction step of Algo rithm 1, is an anchor that has not b e en sele cte d in one of the pr ev ious iter ations. 5 Pr o of. Let the ind ex set A denote all the anchor columns of X . Und er the separability assumption, w e ha v e X = X A H . L et the index set A t iden tify the curren t set o f anc hors. Let Y j = X j p T X j and Y A = X A [ diag ( p T X A )] − 1 (since p is strictly p ositiv e, the inv erse exists). Hence Y j = Y A [ diag ( p T X A )] H j p T X j . Let C j = [ diag ( p T X A )] H j p T X j . W e also h a v e p T Y j = 1 and p T Y A = 1 T . Hence, w e hav e 1 = p T Y j = p T Y A C j = 1 T C j . Using Lemma 3.1, Lemma 3.2 and the fact that p is strictly p ositiv e, w e hav e max 1 ≤ j ≤ n D ⋆ T i Y j = max j / ∈ A t D ⋆ T i Y j . In deed, for all j ∈ A t w e ha v e D ⋆ T i Y j ≤ 0 using Lemma 3.1 and there is at least one j = i / ∈ A t for which D ⋆ T i Y j > 0 usin g Lemma 3.2. Hence th e maxim um lies in t he s et { j : j / ∈ A t } . F urth er , w e h a ve max j / ∈ A t D ⋆ T i Y j = max j / ∈ A t D ⋆ T i Y A C j ≤ max j ∈ ( A \ A t ) D ⋆ T i Y j . The second inequalit y is the resu lt of the fact that k C j k 1 = 1 and C j ≥ 0. T his implies that if there is a unique maxim um at a j ∗ = arg ma x j / ∈ A t D ⋆ T i Y j , then X j ∗ is an anc h or that has not b een selecte d so far. Remarks : (1) F or the correctness of Algo rithm 1, the anc h or selec tion step requires c h o osing a D ⋆ i ∈ D i for whic h Lemma 3.1 and Lemma 3.2 hold true. Here w e give a metho d to fi n d one suc h D ⋆ i using linear programming. Usin g KKT conditions, the D ⋆ i satisfying − X T A D ⋆ i = Λ i ∈ R | A | + is a cand idate. W e kno w Λ j i = 0 if H j i > 0 and Λ j i > 0 if H j i = 0 (complemen tary slac kness). Le t Z = { j : H j i > 0 } and e Z = { j : H j i = 0 } . Let I = { j : R j i = 0 } . Let u r epresen t the elemen ts of D ⋆ i that w e need to find, i.e., u = { D ⋆ j i : j ∈ I } . Finding u is a f easibilit y pr ob lem that can b e solv ed using an LP . Since there can b e multiple feasible p oint s, we can c ho ose a dummy cost function P k u k (or an y other random lin ear function of u ) for the LP . More formally , the LP ta ke s th e form: min − 1 ≤ u ≤ 1 1 T u , suc h that − X T A D ⋆ i = Λ i , Λ j i = 0 ∀ j ∈ Z , Λ j i > 0 ∀ j ∈ e Z In principle, the num b er of v ariables in this LP is the n umber of zero ent ries in residual v ector R i whic h can b e as large as m − 1. In practice, we a lwa ys hav e the num b er of zeros in R i m uc h less than m since w e alwa ys pic k the exterior p oin t with maxim um ℓ 1 norm in the Anc hor Selection step of Algorithm 1. The n umb er of constrain ts in the LP is also ve ry small (= | A | < r ). In our implemen tation, we simply set u = − 1 which, in pr actice, almost alw a ys satisfies Lemma 3.1 and Lemma 3.2. The LP is called wheneve r Lemma 3.2 is violated whic h hap p ens r arely (n ote that Lemma 3.1 w ill nev er viola te w ith this setting of u ). (2) If the maxim um of Eq. 3 o ccurs at tw o p oin ts j ∗ 1 and j ∗ 2 , b oth these p oints X j ∗ 1 and X j ∗ 2 generate the extreme rays of the data cone. Hence b oth are add ed to anc h or set A . I f the m aximum o ccurs at more th an tw o p oin ts, some of these are the anc hors and others are conic combinatio ns of these anc hors. W e can id entify th e anc hors of this subset o f p oint s b y calling Algo rithm 1 recursiv ely . (3) In Algorithm 1, the vec tor p needs to satisfy p T x i > 0 , i = 1 . . . n . In our implemen tation, w e simply us ed p = 1 + δ ∈ R m where δ is small p ertur bation v ector with ent ries i.i.d. ac cording to a u niform distribu tion U (0 , 10 − 5 ). Th is is done to a vo id the p ossibilit y of p being co llinear with D ⋆ i . 6 4 Near-separable NMF with B regman div ergence Let φ : S 7→ R b e a str ictly con v ex function on d omain S ⊆ R w hic h is d ifferen tiable on its non- empt y relativ e interio r r i ( S ). Bregman d iv ergence is then defined as D φ ( x, y ) = φ ( x ) − φ ( y ) − φ ′ ( y )( x − y ) w here φ ′ ( y ) is the con tin uous fi rst deriv ativ e of φ ( · ) at y . Here w e will also assume φ ′ ( · ) to b e smooth whic h is true for most Bregman div ergences of in terest. A Bregman divergence is alwa ys con v ex in the first argument . Some instances of Bregman diverge nce are also con v ex in the second argument (e.g., KL dive rgence). F or t w o matrices X and Y , we w ork w ith d iv ergence of the f orm D φ ( X , Y ) := P ij D φ ( X ij , Y ij ). Here we consider t he ca se when the en tries of data matrix X are g enerated from an e xp o- nen tial family distribution with paramete rs satisfying the separability assumption, i.e. , X ij ∼ P φ ( W i H j ) , W ∈ R m × r + , H = [ I H ′ ] ∈ R r × n + ( W i and H j denote the i th row of W and the j th column of H , resp ectiv ely). Ev ery mem b er distribu tion P φ of the exp onen tial family has a unique Bregman div ergence D φ ( · , · ) associated with it Banerjee et al. (2005), and solving min Y D φ ( X , Y ) is equiv alent to maximum lik eliho o d estimation for p arameters Y ij of the d istribution P φ ( Y ij ). Hence, the pro jection step in Algorithm 1 is c hanged to H = arg m in B ≥ 0 D φ ( X , X A B ). W e use the coord inate descen t based metho d of Li et al. (2012) to solv e the pro jectio n s tep. T o select the anc hor columns with Bregma n pr o jectio ns X A H , w e mo d if y the selectio n cr iteria as j ⋆ = arg max j ( φ ′′ ( X A H i ) ⊙ R i ) T X j p T X j (5) for any i : k R i k > 0, where R = X − X A H and φ ′′ ( x ) is the vecto r of second deriv ativ es of φ ( · ) ev aluated at ind ivid ual elemen ts of the ve ctor x (i.e., [ φ ′′ ( x )] j = φ ′′ ( x j )), an d ⊙ denotes element- wise pro du ct of v ectors. W e can sho w the follo wing resu lt regarding the anc hor selection prop ert y of this crite ria. Recall that an anchor is a column that can not b e expr essed as co nic combinatio n of other column s in X . Theorem 4.1. If the maximizer of Eq . 5 is unique, the data p oint X j ⋆ adde d at e ach iter ation in the Sele c tion step, is an anchor that has not b e en sele c te d in one of the pr evious iter ations. The p ro of is pr ovided in the App endix. Again, an y exterior p oin t i can b e c hosen to select the next anc hor b ut our sim ulations s h o w that taking exterior p oint to b e i = arg max k D φ ( X k , X A H k ) giv es muc h b etter p er f ormance under noise than randomly c ho osing the exterior p oin t. Note that for the Bregman d iv ergence induced by function φ ( x ) = x 2 , the selection criteria of Eq. 5 r educes to the selec tion criteria of Xra y prop osed in Kumar et al. (2013). Since Bregman dive rgence is not generally symmetric, it is also p ossible to ha v e the pro jec- tion step as H = arg min B ≥ 0 D φ ( X A B , X ). In this case, the sele ction criteria will c hange to j ⋆ = arg max j ( φ ′ ( X i ) − φ ′ ( X A H i )) T X j p T X j for any p oin t i exterior to the current cone, wher e φ ′ ( x ) op er- ates elemen t-wise on vec tor x . Ho we ve r this v arian t do es not h a ve as meaningful a probabilistic in terpretation as the one d iscussed earlie r. 5 Empirical Observ ations In this section, w e pr esen t exp erimen ts on s y nthetic and real datasets to d emonstrate the effectiv e- ness of the prop osed algorithms und er noisy conditions. In addition to comparing ou r algorithms with existing s eparable NMF metho d s Bittorf et al. (2012); Gillis & V a v asis (2012); Kumar et al. 7 0 0.5 1 1.5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Noise level (std. dev. δ ) Fraction of anchors correctly recovered RobustXRAY XRAY− L 2 Hottopixx SPA 0 2 4 6 8 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Mean Parameter ( λ ) Fraction of anchors correctly recovered XRAY−IS XRAY−L 2 Hottopix SPA Figure 3 : Left: Anc hor reco v ery rate v ersus noise lev el for s p arse n oise case, Righ t: Anchor reco very r ate v ersus mean p arameter for data matrix generated from exp onen tial distribution (b est view ed in colo r) (2013), w e also b enc hmark them against Robu s t PC A an d lo cal-searc h based lo w -rank factorizati on metho ds, wherev er applicable, for the s ak e of providing a more complete picture. 5.1 Anc hor r eco v ery under noise Here w e test the prop osed algorithms for reco v ery of anc hors wh en the separable structur e is p ertur b ed by noise. W e compare w ith metho d s prop osed in Gillis & V a v asis (2012) (abbrv. as SP A for Successive Pro jection Appr o ximation), Bittorf et al. (2012) (abbrv. as Hottopixx ) and Kumar et al. (2013) (abbrv. as Xra y - ℓ 2 ). First, we consid er the case wh en the separable stru cture is p ertur b ed by addition of a spars e noise matrix, i.e., X = WH + N , H = [ I H ′ ]. Eac h entry of matrix W ∈ R 200 × 20 + is generated i.i.d. from a u niform distribution b etw een 0 and 1 . The matrix H ∈ R 20 × 210 is ta ke n to b e [ I 20 × 20 H ′ 20 × 190 ] w here eac h co lumn of H ′ is s ampled i.i.d. from a Diric hlet d istribution w h ose parameters are generated i.i.d. from a un iform distrib ution b et we en 0 an d 1. It is clear from the structure of matrix H that first tw ent y columns are the anchors. T he data matrix X is generate d as WH + N w ith N = max( N 1 , 0) ∈ R 200 × 210 + , w here eac h en try of N 1 is generated i.i.d. from a Laplace distribution havi ng zero mean and δ standard deviation. Since L aplace distr ibution is symmetric around mean, a lmost half of the en tries in m atrix N are 0 du e to the max op eration. The std. d ev. δ is v aried from 0 to 1 . 5 w ith a step size of 0 . 02. Fig. 3 p lots the fr action of correctly reco v ered anc hors av eraged ov er 10 r u ns f or eac h v alue of δ . The pr op osed Robu st Xra y (Alg orithm 1 ) outp erforms all other metho ds including Xra y - ℓ 2 b y a huge margin as the noise lev el increases. This highligh ts the imp ortance of u sing the righ t loss function in the pr o jectio n step that is suitable for the noise mo del (in this case ℓ 1 loss of Eq. 4 ). Next, we consider the case where the non-negativ e data matrix is generated from an exp onential family distribu tion other than the Gaussian, i.e. , X ij ∼ P φ ( W i H j ) , W ∈ R m × r + , H = [ I H ′ ] ∈ R r × n + ( W i and H j denote the i th ro w of W and th e j th column of H , resp ectiv ely). As m en tioned earlier, ev ery mem b er distribu tion P φ of the exp onen tial family h as a u nique Bregman diver- gence D φ asso ciated with it. Hence w e minimize th e corresp onding Bregman d iv ergence in the pro jection step of the algorithm as discussed in Section 4, to reco v er the anchor column s. Two most commonly used Bregman div ergences are generalized KL-dive rgence and I takur a-Saito (IS) 8 20 40 60 80 100 120 140 50 60 70 80 90 100 # Selected samples Prediction accuracy Reuters (# training samples: 3645, # classes: 10) Full training data SMRS SPA XRAY−L 2 RobustXRAY 20 40 60 80 100 120 140 40 50 60 70 80 90 100 # Selected samples Prediction accuracy BBC (# traning samples: 1114, # classes: 5) Full training data SMRS SPA Robust XRAY XRAY−L 2 Figure 4: Ac curacy of SVM trained with selected exemplars on R euters data (left) and BBC data (right) (b est view ed in colo r) div ergence Sra & Dh illon (2005); Banerjee et al. (2005); F ´ ev otte et al. (2009) that corresp ond to P oisson and E xp onentia l distributions, resp ectiv ely . W e d o not rep ort results with generalized KL - div ergence here since th ey w ere not very informativ e in highligh ting the differences among v arious algorithms that are considered. The r eason is that Poisson distrib ution with parameter λ has a mean of λ and std. dev. of √ λ , and in creasing the n oise (std. dev.) actually increases the s ignal to n oise r atio 1 . Hence anc hor reco ve ry gets b etter w ith incr easing λ (p erfect reco very after certain v alue) and almost all algorithms p erform as we ll as Xra y -KL for the full λ r ange. The anc hor reco very results w ith IS-div ergence are shown in Fig. 3. The en tries of d ata matrix X are generated as X ij ∼ exp( λ W i H j ) W ∈ R 200 × 20 + , H = [ I 20 × 20 H ′ ] ∈ R 20 × 210 + . The matrices W and H are generated as describ ed in the p revious paragraph. Th e p arameter λ is v aried fr om 0 to 10 in the steps of 0 . 5 and we rep ort th e a ve rage ov er 10 r uns for eac h v alue of λ . Th e Xra y -IS algorithm significan tly outp erforms other metho ds including Xra y - ℓ 2 Kumar et al. (2013) in correctly r e- co vering the an chor column indices. The reco very rate d o es not c hange muc h with increasing λ since exp onen tial distribu tion with mean paramete r λ has a std. dev. of λ and the s ignal-to-noi se ratio practica lly sta ys almost same w ith v arying λ . 5.2 Exemplar Selection The pr oblem of exemplar selection is concerned with find in g a few r epresen tativ es fr om a d ataset that can summarize the dataset well. Exemplar selecti on can b e used in man y applications includ- ing summarizing a video sequence, selecting represent ativ e image s or text do cum en ts (e.g., t wee ts) from a collection, etc. If X denotes the data matrix where eac h c olumn is a data p oin t, the exem- plar s election problem translates to selecting a few columns fr om X th at can a ct as represen tativ es for all th e columns. Th e separable NMF algorithms can b e used for this task, w orking under the assumption that all d ata p oints (c olumns of X ) can b e expressed as n on-negativ e linear com b ina- tions of the exemplars (the anc hor columns ). T o b e able to compare the q u alit y of the selected exemplars by differen t algorithms in an ob jectiv e manner, we test them on a classification task (as- suming that eve ry data p oint has an associated lab el). W e randomly partition the data in training and test sets, a nd u se only training s et in selecting the exemplars. W e train a multiclass SVM 1 P oisson distribu tion with parameter λ closely resembles a Gaussian distribution with mean λ and std. dev . √ λ , for large v alues of λ . 9 classifier F an et al. (2008) with the s elected exemplars an d lo ok at its accuracy on the held-out test set. The ac curacy of the classifier trained with the full training set is taken a s a b enc hm ark and is also rep orted. W e also compare with Elhamifar et al. (2012) who recen tly prop osed a method for exemplar sele ction, n amed as Sparse Modeling Represen tativ e Selection (SMRS). Th ey assume th at the data p oin ts can b e exp ressed as a con ve x linear com b ination of the exemplars and minimize k X − XC k 2 F + λ k C k 1 , 2 s.t. 1 T C = 1 T . T he columns of X co rresp onding to the non-zero r ows of C are sele cted as exemplars. W e use the co de pro vided b y the authors for SMRS . There are m u ltiple p ossibilities f or anc hor sele ction criteria in the prop osed Robu s t Xra y and Xr a y - ℓ 2 Kumar et al. (2013) and w e use max criterion for b oth the algorithms. W e rep ort results with t w o text datasets: Reuters Reuters and BBC Greene & Cunningham (2006). W e use a subset of Reuters data corresp onding to the most frequen t 10 c lasses whic h amoun ts to 7285 d o cuments and 18221 words ( X ∈ R 18221 × 7285 + ). Th e BBC data consists of 2225 do cuments and 9635 words with 5 classes ( X ∈ R 9635 × 2225 + ). F or b oth datase ts, we ev enly split the do cuments into training and test set, and selec t the exemplars from the training set using v arious algorithms. Fig. 4 and Fig. 4 sho w the plot of SVM accuracy on the test set against the num b er of selected exemplars that are used for training the classifier. The n umb er of selected anc hors is v aried from 10 to 150 in the steps of 10. The accuracy using the full trainin g set is also sho w n (dotted blac k line). F or Reu ters data, the pr op osed Robust Xr a y algo rithm outp erforms other metho ds by a significan t margin for th e w hole range of selected anc hors. All method s seem to p erform comparably on BBC data. An adv antag e of SP A and Xra y family of metho ds is that there is no need f or a cleaning step to r emo v e n ear-duplicate exemplars as needed in SMRS Elh amifar et al. (2012). Another adv antag e is of computational sp eed – in all our exp eriments, SP A and Xra y metho d s are ab out 3–10 times faster than SMRS. It is remark able that ev en a lo w num b er o f selected exemplars give r easonable classification accuracy for all metho ds – SMRS giv es 50% accuracy for Reuters data using 10 exemplars (on a v erage 1 training samp le p er class) while Robu st Xra y giv es more than 70 %. 0 0.05 0.1 0.15 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 False positives True positives ROC curve (Restaurant) RobustXRAY Robust NMF (local−search) Robust Low−rank (local−search) Robust PCA XRAY−L 2 0 0.05 0.1 0.15 0.2 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 False positives True positives ROC curve (Airport Hall) RobustXRAY Robust NMF (local−search) Robust Low−rank (local−search) Robust PCA XRAY−L 2 0 0.05 0.1 0.15 0.2 0.6 0.65 0.7 0.75 0.8 0.85 0.9 False positives True positives ROC curve (Lobby) RobustXRAY Robust NMF (local−search) Robust Low−rank (local−search) Robust PCA XRAY−L 2 Figure 5: F oreground -bac k grou n d separation: ROC curv es with v arious metho ds for R estaur ant , Airp ort Hal l and L obby video sequences. Th e ranges for X and Y axes are chosen to b etter highligh t the differences amo ng the R OC curve s. (b est viewed in color) 10 5.3 F oreground-bac kground Separation In this section, we consid er the problem of foreground -b ac kgroun d separation in video. The camera p osition i s assumed to b e almost fixed t hrou gh ou t the vid eo. In all video frames, the camera captures the b ac kgroun d scene sup erimp osed with a limite d foreground activit y (e.g., mov emen t of p eople or ob jects). Bac kground is assum ed to b e stationary or slowly v arying across frames (v ariations in illumination and sh ado ws du e to ligh ting or time of day) while foreground is assumed to b e co mp osed of ob jects that mov e across fr ames but span only a few pixels. If we v ectorize all video frames and stac k them as ro ws to form the matrix X , the foregroun d -bac kground sep aration problem can b e mo d eled as decomp osing X int o a lo w-rank matrix L (mo deling the bac kground) and a sparse matrix S (mo deling the foreground). Connection to Median Filtering: Median fi ltering is on e of th e most commonly used bac kground mod eling tec hniques Sen-Ch in g & Kamath (2004 ), w hic h simply mo d els the bac k- ground as the pixel-wise med ian of the video frames. Th e assumption is that eac h pixel lo cation sta ys in the bac kground for more than half of the vid eo f rames. Consider th e NMF of inner- dimension 1: min w ≥ 0 , h ≥ 0 k X − w h k 1 . If we constrain the ve ctor w to b e all ones, the solution h ∗ = arg min w = 1 , h ≥ 0 k X − w h k 1 is nothing bu t the elemen t-wise median of all ro ws of X . More generally , if w is constrained to b e suc h that w i = c > 0 ∀ i , the solutio n h ∗ is a scale d version of the elemen t-wise median vect or. Hence Robust NMF under this v ery restrictive setting is equiv a- len t to med ian filtering on the video frames, and w e can hop e that loosening this assumption and allo wing for h igher inner-dimension in th e factorizatio n can help in mo d eling more v ariations in th e bac kground. W e u se three video sequences for ev aluation: R estaur ant , A irp ort Hal l and L obby Li et al. (2004). Restauran t and Airp ort Hall are v id eos tak en at a buffet restauran t and at a hall of an airp ort, resp ectiv ely . The ligh ting are distributed from th e ceilings and signican t shadows of mo ving p ers on s cast on the ground surfaces from different directions can b e observ ed in the videos. Lobb y video sequence w as captured fr om a lobby in an office building and has b ac kgroun d c hanges due to light s b eing sw itc h ed on/off. The ground truth (whether a p ixel b elongs to foreground or bac kground) is also a v ailable for these video sequences and w e use it to generate the R OC cur v es. W e mainly compare Robust Xra y with Robu st PCA whic h is wid ely considered state of the art metho dology for this task in the Compu ter Vision comm unit y . In addition, we also compare with t w o lo cal-searc h based approac hes: (i) R obust NM F (lo c al-se ar ch) which solv es min W ≥ 0 , H ≥ 0 k X − WH k 1 using lo cal searc h, and (ii) R obust L ow-r ank (lo c al-se ar ch) w hic h s olves min W , H k X − WH k 1 using lo cal s earc h . W e use an ADMM based optimization pro cedure f or b oth these lo cal-searc h metho ds. W e also sho w r esults with Xra y - ℓ 2 of K umar et al. (2013) to highlight the imp ortance of ha ving near-separable NMFs with ℓ 1 loss for this pr oblem. F or b oth Xra y - ℓ 2 and Robust Xra y , w e do 1 to 2 refitting s teps to refine the solution (i.e., solv e H = min B ≥ 0 k X − X A B k 1 then solv e W = min C ≥ 0 k X − CH k 1 ). F or all the metho ds, w e d o a grid searc h on the parameters (inner- dimension or rank p arameter for the factorization method s and λ p arameter f or Robust P CA) and rep ort the best results for eac h metho d . Fig. 5 sh o ws the R OC plots for the thr ee video dat asets. F or Restaurant dat a, all robust metho ds (those with ℓ 1 p enalt y on the fo reground ) p er f orm almost simil arly . F or Airp ort Hall data, Robust Xra y is tied with lo cal-searc h based Robu st NMF and these t wo are b etter than other metho ds. Surprisin gly , Xra y - ℓ 2 p erforms b etter than lo cal-searc h based Robust Lo w-rank whic h migh t b e du e to bad initialization. F or Lobb y data, lo cal -searc h b ased Robust low-rank, Robust PCA and Robust Xra y p erform almost sim ilarly , and are b etter than lo cal-searc h based 11 Robust NMF. The results on these th r ee datasets sh o w that Robust Xra y is a promising metho d for the problem of foreground-backg round separation w h ic h has a h u ge adv an tage ov er Robust PCA in terms of sp eed. Our MA TLAB implementati on w as at least 10 times f aster than the inexact Augmen ted Lagrange Multiplier (i-A LM) implementat ion of Lin et al. (20 10). 6 Conclusion and F uture W ork W e hav e prop osed generalized conical hull algorithms to extend near-separable NMFs to r obust ( ℓ 1 ) loss fun ction and Bregman divergence s. Empirical resu lts on exemplar selection and video bac kground-foreground mo deling problems su ggest that this is a promising metho d ology . Aven ues for f u ture w ork include formal theoretical analysis of noise robustn ess and applications to online settings. References Arora, Sanjeev, Ge, Rong, Ka nnan, Ravi, and Moitra , Ankur. Computing a nonnegative matr ix factoriza tion – prov ably . In STOC , 20 12. Arora, Sanjeev, Ge, Rong , Halp ern, Y oni, Mimno, David, Moitr a, Ankur, Son tag, David, W u, Yic hen, and Zhu, Mic hael. A pr actical algo rithm for to pic mo deling with prov able guarantees. 2 013. Banerjee, Ar inda m, Mer ugu, Srujana, Dhillon, Inder jit S, a nd Ghosh, J oydeep. Clustering with bregma n divergences. Jour n al of Machine L e arning R ese ar ch , 6:1705 –174 9 , 2005 . Bittorf, Victor, Rech t, Benjamin, Re, Christopher, and T ropp, Jo el A. F actoring nonnega tive matric e s with linear progr ams. In N IPS , 2 012. Boyd, Stephen, Parikh, Neal, Ch u, Eric, Peleato, B orja, and E ckstein, Jonathan. D istributed optimization and s tatistical learning via the a lternating dir ection metho d of mu ltipliers. F oundations and T r ends R in Machine L e arning , 3(1):1–1 22, 201 1 . Cichocki, A., Zdunek, R., P han, A. H., a nd Amari, S. Non-ne gative Matrix and T ensor F actorizations . Wiley , 20 09. Clarkso n, K. Mor e o utput-sensitive geometric alg orithms. In FOCS , 1994 . Donoho, D. and Sto dden, V. When does non-negative matrix factorization g ive a correct decompo sition into parts? In N IPS , 2003 . Dula, J. H., Hegalson, R. V., and V enugopal, N. An algor ithm for iden tifying the frame of a p ointed finite conical hull. INFORMS Jour . on Comp. , 10(3):323–33 0, 1998. Elhamifar, Ehsa n, Sapir o , Guillermo, and Vidal, Rene. See all by lo oking at a few: Sparse mo deling for finding repres ent ative ob jects. In CVPR , 201 2. Esser, Er nie, Mller, Mich ael, Osher, Stanley , Sapiro , Guillermo, a nd Xin, J ack. A conv ex mo del for no n- negative matr ix factorizatio n and dimensionality r eduction on physical space. IEEE T r ansactions o n Image Pr o c essing , 21(10):3239 – 325 2, 201 2. F a n, R.-E., Chang, K .- W., Hsieh, C.-J., W ang, X.-R., and Lin, C.-J. Liblinear: A library for larg e linear classification. JMLR , 2008. 12 F ´ evotte, C´ edric, Ber tin, Nancy , and Durrieu, Jean-Louis. Nonnega tive matrix factoriza tion with the itak ura- saito divergence: With application to music ana lysis. Neura l c omputation , 21(3 ):793–8 30, 2 009. Gillis, Nicolas a nd V a v as is , Stephen A. F a st and robust re c ursive algorithms for separ able nonnegative matrix factorization. arXiv:1208.1 237v2 , 2 012. Greene, Derek and Cunningham, P ´ adra ig. Practical s olutions to the pr oblem of diago nal dominance in kernel do cument clustering. In ICML , 2 006. Guan, Naiy ang, T ao , Dacheng, L uo , Zhigang, a nd Shawe-T aylor, J ohn. Mahnmf : Manhattan non-neg ative matrix factoriza tio n. CoRR abs/1207. 3438 , 201 2. Hsieh, C. J . a nd Dhillon, I. S. F ast co ordinate descent metho ds with v ariable s election for non-negative matrix factoriza tio n. In KDD , 201 1. Kim, Hyunso o and Park, Haesun. Sparse non-negative matrix factor izations via alternating non-negativity- constrained least squa res for micr oarr ay data a nalysis. Bioinformatics , 2 3:1495 –150 2 , 20 07. Kumar, Abhishek, Sindh wani, Vik as, and Kambadur, P rabhanjan. F as t conical hull alg orithms for nea r- separable non-nega tive matrix factor ization. In ICML , 20 13. Lee, D. and Seung, S. Learning the pa rts o f ob jects by non-negative matrix factor ization. Natu r e , 401(67 55): 788–7 91, 1999. Li, Liangda , Leba non, Guy , and Park, Ha e sun. F ast breg ma n div erg ence nmf using taylor ex pansion and co ordinate descent. In KDD , 201 2 . Li, Liyuan, Huang, W eimin, Gu, Irene Y u-Hua, and Tian, Qi. Sta tistical mo deling of co mplex ba ckgrounds for foregr o und ob ject detectio n. Image Pr o c essing, IEEE T r ansactions on , 1 3(11):145 9–14 7 2, 200 4. Lin, C.-J. P ro jected gra dient methods for non-neg ative matrix fac to rization. Neur al Comp utation , 2 007. Lin, Zho uchen, Chen, Minming, and Ma, Yi. The augmented lagrang e m ultiplier metho d for exact r ecov ery of co rrupted low-rank matrice s . arXiv pr eprint arXiv:1009.505 5 , 2 010. Reuters. arc hive. ics.uc i.edu/ml/datasets/Reuters- 21578+Text+Categorization+Collection . Sen-Ching, S Cheung and K amath, Chandr ik a. Robust techn iques for background subtraction in urba n traffic video. In Ele ctr onic Imaging 2004 , pp. 881–892, 2004 . Sra, Suvr it and Dhillon, Inder jit S. Generalized no nnegative matrix approximations with bregma n diver- gences. In Ad vanc es in n eur al information pr o c essing systems , pp. 283–290, 20 05. A Near-separable NMF with B regman div ergence Let A b e the set of anc hors selected so far b y the algorithm. Let φ ( · ) b e the strictly con vex function that induces the Bregman div er gence D φ ( x, y ) = φ ( x ) − φ ( y ) − φ ′ ( y )( x − y ). F or tw o matrices X and Y , w e consider the Bregman diverge nce of the form D φ ( X , Y ) := P ij D φ ( X ij , Y ij ). W e make the follo win g assump tions for the pr o ofs in this section whic h are satisfied by almost all the Bregman div ergences of in terest: Assumption 1: The first deriv ativ e of φ , φ ′ , is s mo oth. 13 Assumption 2: The second deriv ativ e of φ , φ ′′ , is p ositiv e at all nonzero p oin ts, i.e., φ ′′ ( x ) > 0 for x 6 = 0. Note that strict conv exit y does not n ecessarily im p ly φ ′′ ( x ) > 0 f or all x w hile th e con v erse is true. Here w e consider the p ro jection step H = arg min B ≥ 0 D φ ( X , X A B ) , (6) and the follo wing s electio n criteria to iden tify the n ext anc h or column : j ⋆ = arg max j ( φ ′′ ( X A H i ) ⊙ R i ) T X j p T X j (7) for any i : k R i k > 0, where R = X − X A H and φ ′′ ( x ) is the vecto r of second deriv ativ es of φ ( · ) ev aluated at individu al elemen ts of the v ector x (i.e., [ φ ′′ ( x )] j = φ ′′ ( x j )), p is an y strictly p ositiv e v ector not collinear with ( φ ′′ ( X A H i ) ⊙ R i ), and ⊙ d enotes element-wise p ro duct of ve ctors. F or a matrix X , X ij denotes ij th elemen t, X i denotes i th column and X A denotes the columns of X indexed b y set A . X A ij denotes ij th column of matrix X A . Here we sh o w the foll o wing result regarding the anc hor sele ction prop ert y of Eq. 7. Recall th at an anc hor is a column that can not b e expressed as co nic com bination of other columns in X . Theorem A.1. If the maximizer of Eq . 7 is unique, the data p oint X j ⋆ adde d at e ach iter ation in the Sele c tion step, is an anchor that has not b e en sele c te d in one of the pr evious iter ations. The pr o of of this theorem follo ws th e same style as the pro of of Th eorem 3 . 1 in th e main p ap er. W e need the follo wing lemmas to pro v e Theorem A.1. Lemma A.1. L et R b e the r e sidual matrix obtaine d after Br e gman pr oje ction of c olumns of X onto the curr ent c one. Then, ( φ ′′ ( X A H ) ⊙ R ) T X A ≤ 0 , wher e X A ar e anchor c olumns sele cte d so far by the algorithm. Pr o of. Residuals are give n by R = X − X A H , where H = arg min B ≥ 0 D φ ( X , X A B ). F orming the Lagrangian f or Eq. 6, we get L ( B , Λ ) = D φ ( X , X A B ) − tr ( Λ T B ), where the matrix Λ con tains the non-negativ e Lagrange m ultipliers. A t the optim u m B = H , w e ha v e ∇L = 0 whic h means ∂ ∂ B mn D φ ( X , XB ) B = H = Λ mn ⇒ X i − X A im φ ′ (( X A H ) in ) − X A im φ ′′ (( X A H ) in )( X in − ( X A H ) in ) + φ ′ (( X A H ) in ) X A im = Λ mn ⇒ X i − X A im φ ′′ (( X A H ) in )( X in − ( X A H ) in ) = Λ mn ⇒ φ ′′ ( X A H ) ⊙ ( X − X A H ) T n X A m = − Λ mn ⇒ φ ′′ ( X A H ) ⊙ ( X − X A H ) T X A = − Λ T ≤ 0 , where φ ′′ ( · ) is the second deriv ativ e of φ ( · ) that operates elemen t-wise on the argumen t (v ector or matrix). 14 Lemma A.2. F or any p oint X i exterior to the curr ent c one, we have ( φ ′′ ( X A H ) ⊙ R ) T i X i > 0 . Pr o of. F or a ve ctor v > 0 and an y vec tor z , we ha v e ( v ⊙ z ) T z = P i v i z 2 i > 0. T aking v to b e φ ′′ ( X A H i ) and z to b e R i , w e ha v e ( φ ′′ ( X A H i ) ⊙ R i ) T R i > 0 ⇒ ( φ ′′ ( X A H i ) ⊙ R i ) T ( X i − X A H i ) > 0 (8) By complementa ry slac kn ess co nd ition a t t he optim um, w e ha v e Λ j i H j i = 0. F rom the KKT condition in the p ro of of p revious lemma, we ha ve [ φ ′′ ( X A H i ) ⊙ R i ] T X A = − Λ T i . Hence [ φ ′′ ( X A H i ) ⊙ R i ] T X A H i = − Λ T i H i = 0. Hence Eq 8 redu ces to ( φ ′′ ( X A H i ) ⊙ R i ) T X i > 0. Using the ab o ve t wo lemmas, w e can pro v e Theorem A.1 as follo ws. Pr o of. Denoting D ⋆ i := ( φ ′′ ( X A H i ) ⊙ R i ) in the pro of of Theorem 3.1 of the main pap er, all the statemen ts of the pro of directly apply in the ligh t of Lemma A.1 and Lemma A.2. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment