Separable Approximations and Decomposition Methods for the Augmented Lagrangian
In this paper we study decomposition methods based on separable approximations for minimizing the augmented Lagrangian. In particular, we study and compare the Diagonal Quadratic Approximation Method (DQAM) of Mulvey and Ruszczy\'{n}ski and the Paral…
Authors: Rachael Tappenden, Peter Richtarik, Burak Buke
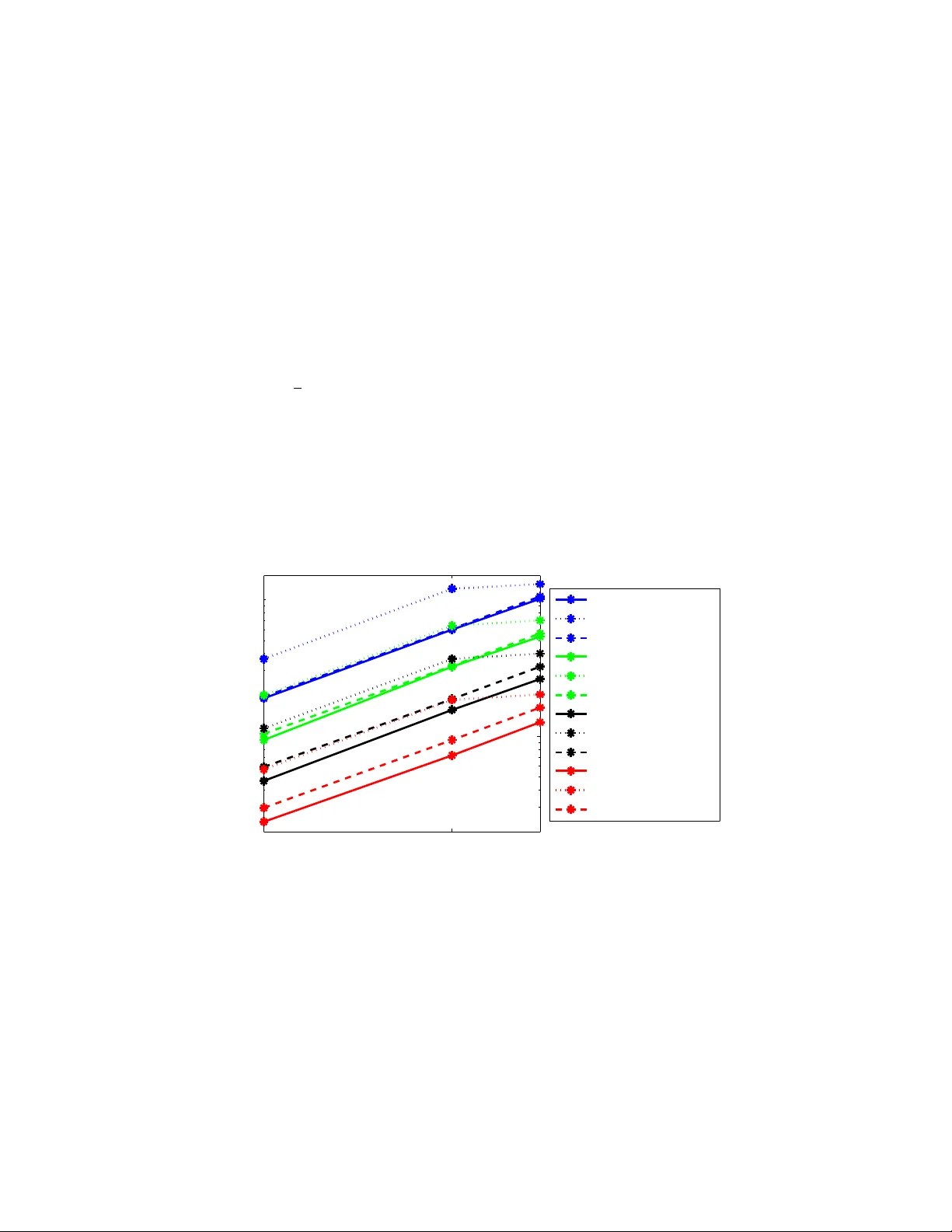
Separable Appro ximations and Decomp osition Metho ds for the Augmen ted Lagrangian Rac hael T app enden P eter Ric ht´ arik Burak B ¨ uk e ∗ August 30, 2013 Abstract In this pap er we study decomp osition metho ds based on separable approximations for mini- mizing the augmen ted Lagrangian. In particular, w e study and compare the Diagonal Quadratic Appro ximation Metho d (DQAM) of Mulv ey and Ruszczy ´ nski [13] and the Parallel Coordinate Descen t Metho d (PCDM) of Ric ht´ arik and T ak´ aˇ c [23]. W e sho w that the t wo metho ds are equiv alen t for feasibility problems up to the selection of a single step-size parameter. F urther- more, w e pro ve an improv ed complexity b ound for PCDM under strong conv exity , and sho w that this b ound is at least 8( L 0 / ¯ L )( ω − 1) 2 times b etter than the b est known b ound for DQAM, where ω is the degree of partial separabilit y and L 0 and ¯ L are the maxim um and a verage of the blo c k Lipschitz constants of the gradient of the quadratic p enalt y app earing in the augmented Lagrangian. 1 In tro duction With the rise and ubiquit y of digital and data tec hnology , practitioners in nearly all industries need to solv e optimization problems of increasingly larger sizes. As a consequence, new to ols and metho ds are required to solv e these big data problems, and to do so efficiently . In this work, we are concerned with conv ex optimization problems with an ob jectiv e func- tion that is separable in to blo c ks of v ariables and where these blo c ks are linked b y a subset of constrain ts which nevertheless make the problem nonseparable. Nonseparabilit y is a source of dif- ficult y in solving these very large optimization problems. This structure is particularly relev an t in sto c hastic optimization problems where each blo c k relates to a certain scenario and inv olves only v ariables related to that particular scenario. The ob jectiv e function expressed as an exp ectation is separable in these blo c ks and the linking constraints (called non-anticipativit y constrain ts) enco de the natural requirement that decisions b e based only on information av ailable at the time of de- cision making. Applications that can b e mo deled as large scale sto chastic optimization problems include multicommodity netw ork flo w problems, financial planning problems and airline routing. A classical approach to solving suc h problems is to use the augmen ted Lagrangian b y relaxing the linking constrain ts. The augmented Lagrangian idea was first introduced indep enden tly by ∗ All authors: James Clerk Maxw ell Building, Sc ho ol of Mathematics, The Universit y of Edinburgh, United King- dom. The work of all three authors w as supported b y the EPSRC grant EP/I017127/1 (Mathematics for V ast Digital Resources). The work of PR and R T w as also partially supp orted by the Cen tre for Numerical Algorithms and In telligent Softw are (funded by EPSRC grant EP/G036136/1 and the Scottish F unding Council). 1 Hestenes [7] and P ow ell [19] and conv ergence of the asso ciated augmented Lagrangian metho d was established later b y Ro c k afellar [25, 26]. Adv antages of this approach include the simplicity and stabilit y of the multiplier iterations, the p ossibilit y of starting from an arbitrary multiplier, and the fact that there is no master problem to solv e. How ev er, the augmented Lagrangian is nonseparable, so the problem is still difficult to solve. The nonseparabilit y of the augmented Lagrangian has motiv ated the developmen t of decomp o- sition techniques. In an early work, Stephanop oulos and W este rberg [34] suggest decomp osing the augmen ted Lagrangian using linear approximations and W atanab e et al. [38] use a transformation metho d to deal with the nonseparable cross pro ducts. The progressive hedging algorithm of Ro c k- afellar and W ets [27] also aims to tackle the nonseparability of the augmented Lagrangian. In a more recent line of work, Ruszczy ´ nski [28, 29] and Mulvey and Ruszczy ´ nski [13, 14] prop ose and analyze a diagonal quadratic approximation (DQA) to the augmented Langrangian and an asso ci- ated diaginal quadratic approximation metho d (DQAM). By approximating the original problem b y one that is separable into blo c ks, these tec hniques make a significan t difference in terms of solv abilit y b ecause the problem is brok en down in to a n umber of problems of a more manageable size. Decomp osition tec hniques ha ve b ecome even more attractiv e with the adv ances in parallel computing: since the decomp osed subproblems can b e solv ed indep enden tly , parallelism is p ossible and this leads to acceleration. A recen t developmen t in the area of decomp osition tec hniques is the Exp ected Separable Over- appro ximation (ESO) of Ric ht´ arik and T ak´ aˇ c and the asso ciated parallel coordinate descen t method (PCDM) presented in [23] (this is discussed in detail in Section 5). (Blo c k) co ordinate descen t metho ds, early v arian ts of which can b e traced back to a 1870 pap er of Sch w arz [30] and b ey ond, ha ve recently become very p opular due to their lo w p er-iteration cost and go o d scalability prop erties. While con vergence results w ere established sev eral decades ago, iteration complexit y b ounds w ere not studied until recen tly [37]. Randomized co ordinate and block co ordinate descent metho ds w ere prop osed and analyzed in several settings, suc h as for smo oth con vex minimization problems [17, 22, 24], L 1 -regularized problems [31], comp osite problems [11, 22, 36], nonsmo oth con vex problems [6], nonconv ex problems [12, 18] and problems with separable constrain ts [15, 16]. P arallel co ordinate descent metho ds were developed and analyzed in [4, 23, 35, 5, 32], primal-dual metho ds in [33, 35] and inexact methods in [36]. The metho ds are used in a num b er of applications, including linear classification [8, 3, 35], compressed sensing [10], truss top ology design [21], solving linear systems of equations [9] and group lasso problems [20]. 1.1 Augmen ted Lagrangian Our work is motiv ated b y the need to solv e huge scale instances of constrained conv ex optimization problems of the form min x (1) ,...,x ( n ) n X i =1 g i ( x ( i ) ) (1a) sub ject to n X i =1 A i x ( i ) = b (1b) x ( i ) ∈ X i , i = 1 , 2 , . . . , n, (1c) where for i = 1 , 2 , . . . , n w e assume that X i ⊆ R N i are con vex and closed sets, g i : R N i → R ∪ { + ∞} are conv ex and closed extended real-v alued functions and A i ∈ R m × N i . 2 While the ob jectiv e function (1a) and the constraints (1c) are separable in the decision v ectors x (1) , . . . , x ( n ) , the linear constraint (1b) links them together, which makes the problem difficult to solv e. Moreov er, w e are interested in the case when n is v ery large (millions, billions and more), whic h introduces further computational c hallenges. It will b e useful to think of the decision vectors { x ( i ) } as “blo cks” of a single decision vector x ∈ R N , with N = P i N i . This can b e achiev ed as follo ws. W e first partition the N × N identit y matrix I column wise into n submatrices U i ∈ R N × N i , i = 1 , 2 , . . . , n , so that I = [ U 1 , . . . , U n ], and then set x = P i U i x ( i ) . That is, x is the vector comp osed b y stacking the vectors x ( i ) on top of eac h other. It is easy to see that x ( i ) = U T i x ∈ R N i . Moreov er, if w e let A def = n X i =1 A i U T i ∈ R m × N , then (1b) can b e written compactly as Ax = b . Note also that A i = AU i , i = 1 , 2 , . . . , n. (2) If we now write g ( x ) def = P i g i ( x ( i ) ) and X def = P i U i X i ⊆ R N , then problem (1a)–(1c) tak es the follo wing form: min x ∈ R N g ( x ) (3a) sub ject to Ax = b (3b) x ∈ X . (3c) A typical approac h to ov ercoming the issue of nonseparability of the linking constraint (3b) is to drop it and instead consider the augmente d L agr angian , F π ( x ) def = g ( x ) + h π , b − Ax i + r 2 k b − Ax k 2 , where π ∈ R m is a v ector of Lagrange multipliers, r > 0 is a p enalt y parameter and k u k = h u, u i 1 / 2 = ( P j u 2 j ) 1 / 2 is the standard Euclidean norm. No w, the Method of Multipliers [2, 7] can b e employ ed to solve problem (1) as describ ed b elo w (Algorithm 1). Algorithm 1 (Metho d of Multipliers) 1: Initialization: π 0 ∈ R m and iteration counter k = 0 2: while the stopping condition has not b een met do 3: Step 1: Fix the m ultiplier π k and solve z k ← min x ∈ X F π k ( x ) . (4a) 4: Step 2: Up date the multiplier π k +1 ← π k + r ( b − Az k ) , (4b) and up date the iteration coun ter k ← k + 1. 5: end while 3 2 The Problem and Our Contributions The focus of this pap er is on the optimization problem (4a). Hence, we need not b e concerned ab out the dep endence of F on π and will henceforth refer to the ob jective function, dropping the constan t term h π , b i , as F ( x ). Ignoring the constan t term h π , b i , problem (4a) is a c onvex c omp osite optimization problem, i.e., a problem of the form min x ∈ R N { F ( x ) def = f ( x ) + Ψ( x ) } , (5) where f is a smo oth conv ex function and Ψ is a separable (possibly nonsmo oth) conv ex function. Indeed, we may set f ( x ) def = r 2 k b − Ax k 2 = r 2 b − n X i =1 A i x ( i ) 2 , (6) and Ψ( x ) def = ( g ( x ) − h π , Ax i , x ∈ X , + ∞ , otherwise. The main purp ose of this w ork is to dra w links b et ween t w o existing decomp osition methods for solving (5), one old and one new, both based on separable appro ximations to the ob jective function. In particular, we consider DQAM of Mulv ey and Ruszczy ´ nski [13, 14, 29] and PCDM of Rich t´ arik and T ak´ a ˇ c [23], resp ectiv ely . Our main contributions (not in order of significance) include: 1. Tw o measures of separabilit y . W e sho w that the parameter “num ber of neighbours”, used in the analysis of DQAM [29], and the degree of partial separability , used in the analysis of PCDM [23], coincide up to an additive constan t in the case of quadratic f . 2. Tw o generalizations of DQAM. W e provide a simplified deriv ation of the diagonal quadratic appro ximation, whic h enables us to prop ose tw o generalizations of DQAM (Section 4.2) to non-quadratic functions f , based on (i) a finite difference separable approximation to the augmented Lagrangian (Algorithm 3), and (ii) a quadratic approximation with the Hessian matrix replaced by an approximation of its blo c k diagonal (Algorithm 4). W e do not study the complexity of these algorithms in this pap er. 3. Equiv alence of PCDM and DQAM for smo oth problems. W e iden tify a situation in whic h the second of our generalizations of DQAM (Algorithm 4) coincides with a “fully parallel” v ariant of PCDM (Algorithm 6) for an appropriate selection of parameters of the metho d (see Section 6.4, Theorem 8). This happ ens for problems with arbitrary smo oth f and Ψ ≡ 0. 4. Impro v ed complexity of PCDM under strong conv exit y . W e derive an improv ed complexit y res ult for PCDM in the case when F is strongly con vex (Section 7, Theorem 11). The result is m uc h better than that in [23] in situations where the strong conv exity constan t of F is muc h larger than the sum of the strong con vexit y constants of the constituent functions f and Ψ. 4 5. V ersatilit y of PCDM. PCDM enjoys complexity guaran tees ev en in the case when F is merely con vex, as opp osed to it being strongly conv ex. Moreov er, PCDM is flexible in that it allows for an arbitr ary num b er of blo c k up dates p er iteration, whereas DQAM needs to up date al l blo cks . 6. Complexit y in the strongly con v ex case. W e study the newly developed complexit y guaran tees for (fully parallel v arian t of ) PCDM (Algorithm 6) and the existing con vergence rates for DQAM and show that even though DQAM is sp ecifically designed to approximate the augmen ted Lagrangian, PCDM has muc h b etter theoretical guarantees (Section 7.3). In particular, if F is strongly con vex, b oth DQAM and PCDM con verge linearly; that is, F ( x k +1 ) ≤ q F ( x k ), where q dep ends on the metho d. Ho wev er, we show that q is m uch b etter (i.e., smaller) for PCDM than for DQAM, which then leads to v ast sp eedups in terms of iteration c omplexit y . In particular, w e sho w that the theoretical b ound for the n umber of iterations required to find an -approximate solution is at least 16( ω − 1) 3 ω × L 0 ¯ L ( ≥ 8 L 0 ¯ L ( ω − 1) 2 for ω ≥ 2) (7) times lar ger for DQAM than for (fully parallel) PCDM. Here, ω is the degree of partial separabilit y 1 of f (defined in Section 3), and L 0 and ¯ L are the maxim um and a verage of the constan ts L i = r k A T i A i k , i = 1 , 2 , . . . , n , resp ectiv ely . Note that the sp eedup factor (7) is larger than 1000 for ω = 10 ev en in the case when L 0 = ¯ L . In practice, how ev er, L 0 will t ypically b e larger than ¯ L , often muc h larger. The form of the sp eedup factor (7) comes from the fact that DQAM dep ends on ( ω − 1) 3 and L 0 (while PCDM depends on ω and ¯ L ), whic h adversely affects its theoretical complexit y rate. Let us comment that Mulvey and Ruszczy ´ nski [13] remarked that the dep endence of DQAM on ω is in practice muc h b etter than cubic, although this was not previously established theoretically . W e th us answer their conjecture in the affirmative, alb eit for a (as w e shall see, not so very) differen t metho d. T o the b est of our knowledge, no impro ved results were a v ailable in the literature up to this p oin t. 7. Optimal n umber of blo ck up dates p er iteration. W e sho w that under a simple parallel computing mo del it is optimal for PCDM to update as many blo c k in a single iteration as there are parallel pro cessors (Section 7.4, Theorem 14). As a consequence, the DQAM approach of up dating al l blo c ks in a single iteration is less than optimal. 8. Computations. W e also provide preliminary n umerical results that show the practical adv an tages of PCDM. 3 Tw o Measures of Separabilit y In this section we pro vide a link b et w een the measures of separability of f utilized in the analysis of DQAM [13] and PCDM [23]. In the first case, the quantit y is defined sp ecifically for a quadratic ob jective; in the second case the definition is general. As we shall see, b oth quan tities coincide in the quadratic case. As the complexity of the tw o metho ds dep ends on these quantities, our 1 The multiplicativ e impro vemen t factor (7) is only v alid for ω ≥ 2 as DQAM was not analyzed in the case ω = 1. 5 observ ation allo ws us to compare the conv ergence rates. Both measures of separability are to b e understo od with resp ect to the fixed blo c k structure introduced b efore. W e first define a separabilit y measure in tro duced for the con vex quadratic f ( x ) = r 2 k b − Ax k 2 b y Ruszczy ´ nski [29, Section 3] (and called the “n umber of neighbors” therein). Let A j i b e the j -th row of matrix A i . Let m i b e the n umber of nonzero ro ws in A i and for each i define an m × m i matrix E i as follows: E i j l = 1 if A j i is the l -th consecutiv e nonzero row of the matrix A i , and 0 otherwise. Note that E i is a matrix containing zeros and m i ones, one in eac h column. F urther, for an y i ∈ { 1 , 2 , . . . , n } and u ∈ { 1 , 2 , . . . , m i } define V ( i, u ) def = { ( i 0 , u 0 ) : i ∈ { 1 , 2 , . . . , n } , u 0 ∈ { 1 , 2 , . . . , m i 0 } , k 6 = i, h E i u , E i 0 u 0 i 6 = 0 } , (8) where E i u is the u -th column of matrix E i . Definition 1 (Ruszczy ´ nski separability) . The Ruszczy´ nski de gr e e of sep ar ability of the function f define d in (6) is ω R = max {| V ( i, u ) | : i = 1 , 2 , . . . , n, u = 1 , 2 , . . . , m i } . (9) W e now define the measure of separability used b y Rich t´ arik and T ak´ aˇ c [23] in the analysis of PCDM. Definition 2 (Partial separabilit y) . A smo oth c onvex function f : R N → R is p artial ly sep ar able of de gr e e ω if ther e exists a c ol le ction J of subsets of { 1 , 2 , . . . , n } such that f ( x ) = X J ∈J f J ( x ) and max J ∈J | J | ≤ ω , (10) wher e for e ach J , f J is a smo oth c onvex function that dep ends on x ( i ) for i ∈ J only. Our first result says that in the case of con vex quadratics, the t wo measures of separability defined ab o ve coincide. This will allow us to provide a direct comparison of the complexit y results of PCDM and DQAM. Theorem 3. F or c onvex quadr atic function f given by (6) we have ω = ω R + 1 . Pr o of. First, w e can write f ( x ) = r 2 m X j =1 b j − n X i =1 A j i x ( i ) ! 2 , (11) where b j is the j -th en try of b . Note that all summands in the decomp osition are conv ex and smo oth. Moreov er, summand j dep ends on x ( i ) if and only if A j i 6 = 0. If we now let ω j = |{ i : A j i 6 = 0 }| , j = 1 , 2 , . . . , m, (12) then we conclude that f is partially separable of degree ω = max j ∈{ 1 , 2 ,...,m } ω j . (13) In the rest of the pro of we pro ceed in t wo steps. 6 (i) Let us fix i ∈ { 1 , 2 , . . . , n } , u ∈ { 1 , 2 , . . . , m i } and le t j = j ( i, u ) b e such ro w index for whic h E i j u = 1. Note that, since E i is a 0-1 matrix with exactly one entry of each column equal to 1, w e hav e E i j 0 u = 0 for all j 0 6 = j . This means that for any i 0 ∈ { 1 , 2 , . . . , n } and u 0 ∈ { 1 , 2 , . . . , m i 0 } , h E i u , E i 0 u 0 i 6 = 0 ⇔ E i 0 j u 0 = 1 . (14) Lik ewise, E i 0 has at most entry equal to 1 in eac h row. Moreo ver, the j -th row of E i 0 con tains 1 precisely when A j i 0 6 = 0. This means that |{ u 0 : E i 0 j u 0 = 1 }| = ( 1 if A j i 0 6 = 0 , 0 if A j i 0 = 0 . (15) W e no w hav e | V ( i, u ) | (8) = |{ ( i 0 , u 0 ) : i 0 6 = i, h E i u , E i 0 u 0 i 6 = 0 }| (14) = |{ ( i 0 , u 0 ) : i 0 6 = i, E i 0 j u 0 = 1 }| = X i 0 6 = i |{ u 0 : E i 0 j u 0 = 1 }| (15)+(12) = ω j − 1 . (16) (ii) Building on the result from part (i), we can no w write ω R (9) = max {| V ( i, u ) | : i ∈ { 1 , 2 , . . . , n } , u ∈ { 1 , 2 , . . . , m i }} (16) = max { ω j ( i,u ) − 1 : i ∈ { 1 , 2 , . . . , n } , u ∈ { 1 , 2 , . . . , m i } = max j ∈{ 1 , 2 ,...,m } ω j − 1 (13) = ω − 1 . In the third identit y ab o v e we used the simple observ ation that every row j ∈ { 1 , 2 , . . . , m } for whic h ω j 6 = 0 can b e written as j = j ( i, u ) for an y i for whic h A j i 6 = 0, and some u (which dep ends on i ). Let us remark that b esides (11), we could hav e decomp osed f also as f ( x ) = r 2 k b k 2 − 2 n X i =1 h b, A i x ( i ) i + n X i =1 n X j =1 h A i x ( i ) , A j x ( j ) i , (17) with eac h summand dep ending on at most 2 blo c ks of x . Ho wev er, w e c annot conclude that f is partially separable of degree 2 b ecause the terms are not all conv ex, which is required in the definition of partial separability . 7 4 Diagonal Quadratic Appro ximation Metho d In this section we presen t the Diagonal Quadratic Approximation Metho d (DQAM) that w as in- tro duced and analysed in a series of pap ers by Mulvey and Ruszczy ´ nski [13, 14], Ruszczy ´ nski [29] and Berger, Mulvey and Ruszczy ´ nski [1]. As explained in Section 1.1, the augmen ted Lagrangian is nonseparable b ecause of the cross pro ducts h A i h ( i ) , A j h ( j ) i app earing in f ( x + h ). The DQAM pro vides a separable approximation of f ( x + h ) by ignoring these cross terms; this appro ximation is referred to as the diagonal quadratic approximation (DQA). This mak es Step 1 of the metho d of m ultipliers ((4a) in Algorithm 1) significantly easier to solve, and amenable to parallel pro cessing. First, notice that we can write f ( x + h ) = r 2 k b − A ( x + h ) k 2 = r 2 k b k 2 − r h b, A ( x + h ) i + r 2 k Ax k 2 + 2 h Ax, Ah i + k Ah k 2 = f ( x ) + h f 0 ( x ) , h i + r 2 k Ah k 2 = f ( x ) + h f 0 ( x ) , h i + r 2 n X i =1 k A i h ( i ) k 2 + r 2 ( k Ah k 2 − n X i =1 k A i h ( i ) k 2 ) = f ( x ) + n X i =1 h ( f 0 ( x )) ( i ) , h ( i ) i + r 2 n X i =1 k A i h ( i ) k 2 + r 2 X i 6 = j h A i h ( i ) , A j h ( j ) i . (18) No w observ e that it is only the last term in (18), comp osed of pro ducts h A i h ( i ) , A j h ( j ) i for i 6 = j , whic h is not separable. Ignoring these terms, we get a separable appro ximation of f ( x + h ) in h , f ( x + h ) ≈ f DQA ( x + h ) def = f ( x ) + h f 0 ( x ) , h i + r 2 n X i =1 k A i h ( i ) k 2 , (19) whic h in turn leads to a separable approximation of F ( x + h ) in h : F ( x + h ) (5) = f ( x + h ) + Ψ( x + h ) (19) ≈ f DQA ( x + h ) + Ψ( x + h ) . (20) Mulv ey and Ruszczy ´ nski [13] prop ose a slightly less transparent construction of the same ap- pro ximation. F or a fixed x , they approximate f ( y ) via replacing the cross-pro ducts h A i y ( i ) , A j y ( j ) i , for i 6 = j , b y h A i y ( i ) , A j x ( j ) i + h A i x ( i ) , A j y ( j ) i − h A i x ( i ) , A j x ( j ) i . (21) Clearly , this is equiv alent to what we do ab o ve, which can b e v erified by substituting y = x + h in to (21). 4.1 The algorithm W e no w presen t the DQA metho d (Algorithm 2). The algorithm replaces Step 1 of the Metho d of Multipliers (Algorithm 1). In what follows, θ ∈ (0 , 1) is a user defined parameter. 8 Algorithm 2 (DQAM: Diagonal Quadratic Appro ximation Metho d) 1: for k = 0 , 1 , 2 , . . . do 2: Step 1a: Solve for h k h k ← arg min h ∈ R N f DQA ( x k + h ) + Ψ( x k + h ) (22a) 3: Step 1b: Determine in termediate vector y k y k ← x k + h k (22b) 4: Step 1c: F orm the new iterate x k +1 x k +1 ← (1 − θ ) x k + θ y k (22c) 5: end for Let us now commen t on the individual steps of Algorithm 2. Step 1a is easy to execute b ecause the function that is b eing minimized in (22a) is separable in h , and hence the problem decomp oses in to n indep enden t lower-dimensional problems: h ( i ) k = arg min h ( i ) ∈ R N i n h ( f 0 ( x k )) ( i ) , h ( i ) i + r 2 k A i h ( i ) k 2 + Ψ i ( x ( i ) k + h ( i ) ) o , i = 1 , 2 , . . . , n. Moreo ver, the problems are indep endent , and hence the up dates h (1) k , · · · h ( n ) k can b e computed in p ar al lel. In (22b) an in termediate v ector y k is formed, and then in (22c) a conv ex combination of the curren t iterate x k and the intermediate vector y k is tak en to pro duce the new iterate x k +1 . Step (22c) is needed b ecause DQAM uses a lo cal approximation, so if the new p oin t x k + h k is far from x k , the approximation error may b e to o big and a reduction in the ob jectiv e function v alue is not guaran teed. This w ould lead to serious stability and con vergence problems in general, and hence, Step 1c is employ ed as a correction step for regularizing the metho d. 4.2 Tw o generalizations DQAM was originally designed and analyzed for conv ex quadratics. Here w e prop ose tw o general- izations of the metho d to non-quadratic conv ex functions f . Our generalizations are based on the follo wing simple result. Prop osition 4. If f ( x ) = r 2 k b − Ax k 2 , then for al l x, h ∈ R N , f DQA ( x + h ) = f ( x ) + n X i =1 h f ( x + U i h ( i ) ) − f ( x ) i (23) and f DQA ( x + h ) = f ( x ) + n X i =1 h h ( f 0 ( x )) ( i ) , h ( i ) i + 1 2 h C i ( x ) h ( i ) , h ( i ) i i , (24) wher e C i ( x ) = U T i f 00 ( x ) U i . 9 Pr o of. First note that n X i =1 h f ( x + U i h ( i ) ) − f ( x ) i = n X i =1 h r 2 k b − Ax − A i h ( i ) k 2 − r 2 k b − Ax k 2 i = n X i =1 h r h Ax − b, A i h ( i ) i + r 2 k A i h ( i ) k 2 i = h f 0 ( x ) , h i + r 2 n X i =1 k A i h ( i ) k 2 , whic h, in view of (19), establishes (23). Finally , (24) follows from (19) and the fact that r 2 k A i h ( i ) k 2 = 1 2 h U T i f 00 ( x ) U i h ( i ) , h ( i ) i , whic h in turn follo ws from the identities f 00 ( x ) = r A T A and A i = AU i . Our t wo generalized methods are obtained b y replacing f DQA ( x + h ) in Step 1 of Algorithm 2 b y one of the tw o approximations (23) and (24) (in the second case we allow for C i ( x ) to b e an arbitrary p ositiv e semidefinite matrix and not necessarily U T i f 00 ( x ) U i ), leading to Algorithm 3 and Algorithm 4, resp ectively . Algorithm 3 (Generalization of DQAM: Finite Differences Appro ximation) 1: for k = 0 , 1 , 2 , . . . do 2: Step 1a: Solve for h k h k ← arg min h ∈ R N ( f ( x k ) + n X i =1 h f ( x k + U i h ( i ) ) − f ( x k ) i + Ψ( x k + h ) ) (25a) 3: Step 1b: Determine in termediate vector y k y k ← x k + h k (25b) 4: Step 1c: F orm the new iterate x k +1 x k +1 ← (1 − θ ) x k + θ y k (25c) 5: end for Algorithm 3 is based on a finite difference appro ximation, and is applicable to (p ossibly) non- smo oth functions. Algorithm 4 is based on a separable quadratic approximation. T o the b est of our kno wledge, these algorithms ha ve not b een previously prop osed, with the exception of the case when f is a conv ex quadratic when b oth metho ds coincide with DQAM. 10 Algorithm 4 (Generalization of DQAM: Separable Quadratic Appro ximation) 1: for k = 0 , 1 , 2 , . . . do 2: Step 1a: Solve for h k h k ← arg min h ∈ R N ( f ( x k ) + h f 0 ( x k ) , h i + 1 2 n X i =1 h C i ( x k ) h ( i ) , h ( i ) i + Ψ( x k + h ) ) (26a) 3: Step 1b: Determine in termediate vector y k y k ← x k + h k (26b) 4: Step 1c: F orm the new iterate x k +1 x k +1 ← (1 − θ ) x k + θ y k (26c) 5: end for In this pap er we do not analyze any of these methods. Instead, w e prop ose that DQAM b e replaced by PCDM, describ ed in the next section. 5 P arallel Co ordinate Descen t Metho d As discussed in the in tro duction, we prop ose that instead of implementing Step 1 of the Metho d of Multipliers (Algorithm 1) using DQAM, a parallel co ordinate descent metho d (PCDM) b e used instead. This section is devoted to describing the metho d, dev elop ed b y Rich t´ arik and T ak´ aˇ c [23]. 5.1 Blo c k samplings As w e shall see, unlik e DQAM where all blo cks are up dated at each iteration, PCDM allows for an (almost) arbitrary random subset of blo c ks to b e up dated at each iteration. The purp ose of this section is to formalize this. In particular, at iteration k only blo c ks i ∈ S k ⊆ { 1 , 2 , . . . , n } are up dated, where { S k } , k ≥ 0, are iid random sets having the following t wo prop erties: P ( i ∈ S k ) = P ( j ∈ S k ) for all i, j ∈ { 1 , 2 , . . . , n } , (27) P ( i ∈ S k ) > 0 for all i ∈ { 1 , 2 , . . . , n } . (28) It is easy to see that, necessarily , P ( i ∈ S k ) = E [ | S k | ] n . F ollo wing [23], for simplicit y we refer to an arbitrary random set-v alued mapping with v alues in the p o wer set 2 { 1 , 2 ,...,n } b y the name blo ck sampling , or simply sampling . A sampling S k is called uniform if it satisfies (27) and pr op er if it satisfies (28). In [23], PCDM was analyzed for all prop er uniform samplings. Ho wev er, b etter complexity results w ere obtained for so called doubly uniform samplings, which belong to the family of uniform samplings. F or brevit y purp oses, in this pap er w e concentrate on a sub class of doubly uniform samplings called τ -nic e samplings, which we now define. 11 Definition 5 ( τ -nice sampling) . L et τ b e an inte ger b etwe en 1 and n . A sampling ˆ S is c al le d τ -nic e if for al l S ⊆ { 1 , 2 , . . . , n } , P ( ˆ S = S ) = 0 , | S | 6 = τ , 1 ( n τ ) , otherwise. A natural candidate for τ is the num b er of a v ailable pro cessors/threads as then up dates to the τ blo cks of x k can b e computed in parallel. As we shall later see, this is also the optimal choice from the complexity p oin t of view (Theorem 14). 5.2 Exp ected Separable Ov erappro ximation (ESO) Fixing pos itiv e scalars w 1 , . . . , w n (w e write w = ( w 1 , . . . , w n )), let us define a separable norm on R N b y k x k w def = n X i =1 w i k x ( i ) k 2 ( i ) ! 1 / 2 , x ∈ R N , (29) where for each i = 1 , 2 , . . . , n w e fix a p ositiv e definite matrix B i ∈ R N i × N i and set k t k ( i ) def = h B i t, t i 1 / 2 , t ∈ R N i . (30) W e can no w define the concept of exp ected separable ov erapproximation. Definition 6 (Exp ected Separable Overappro ximation (ESO) [23]) . L et β and w 1 , . . . , w n b e p osi- tive c onstants and ˆ S b e a pr op er uniform sampling. We say that f : R N → R admits a ( β , w ) -ESO with r esp e ct to ˆ S (and, for simplicity, we write ( f , ˆ S ) ∼ E S O ( β , w ) ) if for al l x, h ∈ R N , E f x + P i ∈ ˆ S U i h ( i ) ≤ f ( x ) + E [ | ˆ S | ] n h f 0 ( x ) , h i + β 2 k h k 2 w . (31) In Section 5.3 w e describ e how the ESO is used to design a parallel co ordinate descent metho d for solving problem (5). The issue of how the parameters w and β giving rise to an ESO can b e determined/computed will b e discussed in Section 5.4. 5.3 The algorithm Unlik e with DQAM, w ere f is replaced by f DQA and Ψ is kept intact, PCDM replaces b oth f and Ψ. This is b ecause in PCDM we compute an approximation to E h F ( x + P i ∈ ˆ S U i h ( i ) ) i = E h f ( x + P i ∈ ˆ S U i h ( i ) ) + Ψ( x + P i ∈ ˆ S U i h ( i ) ) i , (32) whic h (unless | ˆ S | = n ) affects Ψ as w ell. It can b e verified (see [23, Section 3]) that due to separabilit y of Ψ the follo wing identit y holds: E h Ψ( x + P i ∈ ˆ S U i h ( i ) ) i = 1 − E [ | ˆ S | ] n ! Ψ( x ) + E [ | ˆ S | ] n Ψ( x + h ) . (33) 12 Substituting (33) and (31) in to (32), we obtain E h F ( x + P i ∈ ˆ S U i h ( i ) ) i ≤ F ESO ( x + h ) def = 1 − E [ | ˆ S | ] n ! F ( x ) + E [ | ˆ S | ] n H β ,w ( x + h ) , (34) where H β ,w ( x + h ) def = f ( x ) + h f 0 ( x ) , h i + β 2 k h k 2 w + Ψ( x + h ) , (35) whic h is separable in h : H β ,w ( x + h ) (29)+(30) = f ( x ) + n X i =1 h ( f 0 ( x )) ( i ) , h ( i ) i + β w i 2 h B i h ( i ) , h ( i ) i + Ψ i ( x ( i ) + h ( i ) ) . (36) W e are no w ready to present the parallel co ordinate descent metho d (Algorithm 5). Algorithm 5 (PCDM: Parallel Co ordinate Descent Metho d) 1: Initialization: x 0 ∈ R N , ESO parameters ( β , w ) 2: for k = 0 , 1 , 2 , . . . do 3: Step 1a: Solve h k ← arg min h ∈ R N F ESO ( x k + h ) (37a) 4: Step 1b: Up date x k x k +1 ← x k + X i ∈ S k U i h ( i ) k (37b) 5: end for Giv en an iterate x k , in (37a) we compute h k = h ( x k ) def = arg min h ∈ R N F ESO ( x k + h ) (34) = arg min h ∈ R N H β ,w ( x k + h ) . (38) F urther, note that (37b) is equiv alen t to writing x ( i ) k +1 = ( x ( i ) k , i / ∈ S k , x ( i ) k + h ( i ) k , i ∈ S k . That is, only blocks b elonging to the random set S k are up dated. This means that in (37a) we need not compute all blocks of h k . In view of (36) and (38), this is possible, and hence (37a) can b e replaced by h ( i ) k ← arg min h ( i ) ∈ R N i h ( f 0 ( x k )) ( i ) , h ( i ) i + β w i 2 h B i h ( i ) , h ( i ) i + Ψ i ( x ( i ) k + h ( i ) ) , i ∈ S k . (39) 13 5.4 ESO for partially separable smo oth con v ex functions In order for PCDM to b e implementable, one needs first to compute the parameters w 1 , . . . , w n (defining the norm k · k w ) and β > 0 for which ( f , ˆ S ) ∼ E S O ( β , w ), i.e., for whic h (31) holds. Clearly , the parameters β and w dep end on f and ˆ S . In what follo ws we will assume that the gradien t of f is blo c k Lipschitz. That is, there exist p ositiv e constants L 1 , . . . , L n suc h that for all x ∈ R N , i ∈ { 1 , 2 , . . . , n } and h ( i ) ∈ R N i , k ( f 0 ( x + U i t )) ( i ) − ( f 0 ( x )) ( i ) k ∗ ( i ) ≤ L i k t k ( i ) , (40) where k s k ∗ ( i ) def = max {h s, x i : k x k w = 1 } = h B − 1 i s, s i 1 / 2 is the conjugate norm to k · k w . Theorem 7 (Theorem 14 in [23]) . Assume f is c onvex, p artial ly sep ar able of de gr e e ω , and has blo ck Lipschitz gr adient with c onstants L 1 , L 2 , . . . , L n > 0 . F urther, assume that ˆ S is a τ -nic e sampling, wher e τ ∈ { 1 , 2 , . . . , n } . Then ( f , ˆ S ) ∼ E S O ( β , w ) , wher e β = 1 + ( ω − 1)( τ − 1) max { 1 , n − 1 } , w i = L i , i = 1 , 2 , . . . , n. (41) In Section 7 we study the complexity of PCDM in the case cov e red by the ab o ve theorem (and under a further strong conv exit y assumption). Consider now the special case of conv ex quadratic f giv en by (6). If the matrices A T i A i , i = 1 , 2 , . . . , n , are all p ositiv e definite, we can choose B i = r A T i A i , i = 1 , 2 , . . . , n , in which case we will hav e L i = 1 for all i . Otherwise w e can choose B i to b e the N i × N i iden tity matrix, and then L i = r k A T i A i k def = r max k h ( i ) k≤ 1 k A T i A i h ( i ) k , (42) where b oth norms in the definition are the standard Euclidean norms in R N i . 5.5 F ully parallel co ordinate descen t metho d PCDM used with an n -nice sampling ˆ S resem bles DQAM in t wo wa ys: i) it up dates al l blo c ks during each iteration, ii) it is not randomized. Indeed, X i ∈ ˆ S U i h ( i ) = n X i =1 U i h ( i ) = h, (43) and hence F ( x + h ) (43) = E F ( x + P i ∈ ˆ S U i h ( i ) ) (34) ≤ F ESO ( x + h ) (34)+(35) = f ( x ) + h f 0 ( x ) , h i + β 2 k h k 2 w + Ψ( x + h ) . In particular, in the setting of Theorem 7 w e ha ve β = ω and w = L = ( L 1 , . . . , L n ), and Algorithm 5 sp ecializes to Algorithm 6. 14 Algorithm 6 (F ully Parallel Co ordinate Descent Metho d) 1: Initialization: x 0 ∈ R N 2: for k = 0 , 1 , 2 , . . . do 3: Step 1a: Solve h k ← arg min h ∈ R N ( f ( x k ) + h f 0 ( x k ) , h i + ω 2 n X i =1 h L i B i h ( i ) , h ( i ) i + Ψ( x k + h ) ) (44a) 4: Step 1b: Up date x k +1 ← x k + h k (44b) 5: end for 6 Links Bet w een DQAM and PCDM In this section w e discuss and compare DQAM and PCDM. W e highlight some of the main differ- ences b etw een the tw o metho ds, and describ e a sp ecial case where the metho ds coincide. 6.1 F ully parallel vs partially parallel up dating One of the main differences b et ween DQAM and PCDM is the num b er of blo cks that m ust b e up dated at each iteration. A t each iteration of DQAM, al l n blo c ks must b e up dated. This highligh ts the fact that DQAM uses a ful ly p ar al lel up date scheme. On the other hand, PCDM is more flexible as it is able to up date τ blo c ks at each iteration where 1 ≤ τ ≤ n . This is b eneficial b ecause in practice there are usually few er pro cessors than the num b er of blocks. So, PCDM can act as a serial metho d if τ = 1, a ful ly p ar al lel method if τ = n , or it can b e optimized to the n umber of pro cessors p (so τ = p ). The adv antages of up dating τ = p blo c ks at each iteration of PCDM is established theoretically in Section 7. Because DQAM up dates all n blo c ks at each iteration, it is a Jacobi type method, whereas PCDM can b e interpreted as a Jacobi type metho d when τ = n , a Gauss-Seidel type metho d when τ = 1, or a hybrid Jacobi-Gauss-Seidel metho d when 1 < τ < n . 6.2 Flexibilit y of PCDM PCDM can be applied to a general conv ex comp osite function. Sp ecifically , f is only assumed to b e smo oth and con vex. F urther, the algorithm is guaranteed to conv erge when applied to a general smo oth con vex function, and can b e equipp ed with iteration complexit y b ounds (see [23]). On the other hand, the conv ergence results for DQAM hav e b een only deriv ed under the assumption that f is quadratic and strongly conv ex; there are no con vergence guarantees for a function f with any other structure. Complexity estimates for b oth metho ds are discussed in detail in Section 7. Notice that DQAM has b een tailored sp ecifically for an augmented Lagrangian ob jectiv e func- tion so it is reasonable that the function f is assumed to b e quadratic and strongly conv ex in this con text. How ever, this assumption restricts the range of problems that can b e solv ed using DQA, while PCDM can b e applied to a muc h wider class of problems. 15 6.3 Appro ximation t yp e and algorithm philosophy In DQAM, a local tw o-sided appro ximation to the cross pro ducts is emplo yed. The error associated with the approximation is of the order o ( k h k 2 2 ), which explains that, if the up date h k is to o large, then the mo del loses accuracy . This justifies the need for a correction step (22c) so as to ensure that x k +1 is not to o far from x k . This ensures a reduction in the ob jective v alue and ultimately , algorithm conv ergence. The need for a correction scheme within DQAM is also apparent from the finite differences formulation presented in Algorithm 3. Consider the summation in (25a), and for simplicit y assume that Ψ ≡ 0. Then the block update h ( i ) k is that whic h minimizes the function v alue difference in the i -th block coordinate direction, independently of all the other blo c ks j 6 = i . Clearly , this will not guarantee that F ( x k + h k ) ≤ F ( x k ) b ecause the function F is not blo c k separable. A simple 2D quadratic example showing that this approac h is do omed to fail was describ ed in [35]. In con trast to the DQAM sc heme, PCDM employs a one-sided glob al exp ected separable ov er- appro ximation of the augmen ted Lagrangian function (5), which guarantees to pro duce a new random iterate x k +1 that, on a verage, decreases the ob jectiv e function. That is, x k +1 satisfies E [ F ( x k +1 ) | x k ] ≤ F ( x k ). It turns out that this is sufficient to obtain a high probabilit y complexity result and therefore there is no need for a correction step in PCDM. In fact, as we shall see in Section 6.4, a “correction step” is already embedded in the approximation in the form of the ESO parameter β . Note that, b esides DQAM, there are man y other algorithms that follow a “step-then-correct” strategy . One example are trust region metho ds, where a solution to some subproblem is found, the “go odness” of the solution is measured, and then the size of the trust region is adjusted to reflect the “go odness”. A second example is the conditional gradient algorithm, which builds a linear approximation to the ob jective function, finds the minimizer of the linearized problem (the “step”) and then “corrects” b y taking a conv ex combination of the previous p oin t and the step to reduce the ob jective v alue. This correction step is implicitly built-in for PCDM, in the c hoice of the constant β . 6.4 A sp ecial case in whic h the metho ds coincide So far we ha v e highligh ted some of the differences b et w een DQAM and PCDM. How ev er, in this section we present a sp ecial case where the tw o metho ds coincide. Theorem 8. Assume f is p artial ly sep ar able of de gr e e ω , and has blo ck Lipschitz gr adient with c onstants L 1 , L 2 , . . . , L n > 0 . F urther, assume Ψ ≡ 0 . Then Algorithm 4 (gener alization of DQAM) c oincides with A lgorithm 6 (ful ly p ar al lel PCDM) under the fol lowing choic e of p ar ameters: C i ( x k ) ≡ L i B i ( i = 1 , 2 , . . . , n ) , θ = 1 ω . (45) Pr o of. In Algorithm 4 w e hav e x k +1 = (1 − θ ) x k + θ ( x k + h k ), where h k = arg min h ∈ R N {h f 0 ( x k ) , h i + 1 2 n X i =1 h C i ( x k ) h ( i ) , h ( i ) i} . (46) Due to separabilit y of the ob jectiv e function in (46) and the choice of parameters (45), we see that h ( i ) k = − 1 L i B − 1 i ( f 0 ( x k )) ( i ) , i = 1 , 2 , . . . , n , and hence x ( i ) k +1 = (1 − θ ) x ( i ) k + θ ( x ( i ) k + h ( i ) k ) = x ( i ) k − 1 ω L i B − 1 i ( f 0 ( x k )) ( i ) . (47) 16 In Algorithm 6 we hav e x k +1 = x k + h k , where h k = arg min h ∈ R N ( h f 0 ( x k ) , h i + ω 2 n X i =1 h L i B i h ( i ) , h ( i ) i ) . (48) Using separabilit y of the ob jectiv e function in (48), w e again obtain the same form ula (47) for x k +1 , establishing the equiv alence of the tw o metho ds. A few remarks: • In the con text of the original problem (1), the case co vered b y the ab o ve theorem corresponds to a feasibility problem (Ψ ≡ 0 means that g ≡ 0). • DQAM was analyzed in [29] only for the parameter θ in the interv al (0 , 1 2( ω − 1) ). F or ω > 1 this leads to smal ler steps than the PCDM default choice θ = 1 ω , which then translates to slo wer conv ergence for DQAM. 7 Complexit y of DQAM and PCDM under Strong Con v exit y In this section we study and compare the conv ergence rates of DQAM and PCDM under the assumption of strong con vexit y of the ob jectiv e function. W e limit ourselves to this case as com- plexit y estimates for DQAM are not a v ailable otherwise. Both DQAM and PCDM b enefit from linear conv ergence, but the rate is muc h b etter for PCDM than for DQA. Strong conv exity . W e assume that F is strongly conv ex with resp ect to the norm k · k w for some v ector of p ositive weigh ts w = ( w 1 , . . . , w n ) sp ecified in the results, with (strong) conv exity parameter µ F > 0. A function φ : R N → R ∪ { + ∞} is strongly conv ex with resp ect to the norm k · k w with conv exity parameter µ φ = µ φ ( w ) ≥ 0 if for all x, y ∈ dom φ , φ ( y ) ≥ φ ( x ) + h φ 0 ( x ) , y − x i + µ φ 2 k y − x k 2 w , (49) where φ 0 ( x ) is any subgradien t of φ at x . The case with µ φ ( w ) = 0 reduces to conv exit y . It will b e useful to note that for any t > 0, µ φ ( tw ) = µ φ ( w ) t . (50) Strong conv exit y of F ma y come from f or Ψ or b oth and w e will write µ f (resp. µ Ψ ) for the strong conv exity parameter of f (resp. Ψ). It is easy to see that µ F ≥ µ f + µ Ψ . (51) Note that the strong con vexit y constant of F can b e arbitr arily lar ger than the sum of the strong conv exity constants of the functions f and Ψ. Indeed, consider the following simple 2D example ( N = n = 2): f ( x ) = µ 2 ( x (1) ) 2 , Ψ( x ) = µ 2 ( x (2) ) 2 , where µ > 0. Let k x k w b e the standard Euclidean norm (i.e., B i = 1 and w i = 1 for i = 1 , 2). Clearly , neither f nor Ψ is strongly con vex ( µ f = µ Ψ = 0). How ever, F is strongly conv ex with constant µ F = µ . In the rest of the section we will rep eatedly use the following simple res ult. Lemma 9. L et ξ 0 > > 0 and γ ∈ (0 , 1) . If k ≥ 1 γ log ξ 0 , then (1 − γ ) k ξ 0 ≤ . Pr o of. (1 − γ ) k ξ 0 = (1 − 1 1 /γ ) (1 /γ )( γ k ) ξ 0 ≤ e − γ k ξ 0 ≤ e − log ( ξ 0 / ) ξ 0 = . 17 7.1 PCDM W e now deriv e a new improv ed complexit y result for PCDM. In [23, Theorem 20] the authors prov e an iteration complexit y b ound based on the assumption that µ f + µ Ψ > 0. Here w e obtain a new and tighter complexity result under the weak er assumption µ F > 0. As discussed ab o v e, µ F can b e substan tially bigger than µ f + µ Ψ , which implies that our complexity b ound can b e muc h b etter. The following auxiliary result is an improv ement on Lemma 17(ii) in [23] and will b e used in the pro of of our main complexit y result. Lemma 10. If µ F ( w ) > 0 and β ≥ µ f ( w ) , then for al l x ∈ dom F H β ,w ( x + h ( x )) − F ∗ ≤ β − µ f ( w ) µ F ( w ) + β − µ f ( w ) ( F ( x ) − F ∗ ) . (52) Pr o of. Let µ F = µ F ( w ), µ f = µ f ( w ) and µ Ω = µ Ω ( w ). By Lemma 16 in [23], we hav e H β ,w ( x + h ( x )) ≤ min y ∈ R N F ( y ) + β − µ f 2 k y − x k 2 w . (53) Using this, we can further write H β ,w ( x + h ( x )) (53) ≤ min y = λx ∗ +(1 − λ ) x, λ ∈ [0 , 1] F ( y ) + β − µ f 2 k y − x k 2 w = min λ ∈ [0 , 1] F ( λx ∗ + (1 − λ ) x ) + ( β − µ f ) λ 2 2 k x − x ∗ k 2 w ≤ min λ ∈ [0 , 1] λF ∗ + (1 − λ ) F ( x ) − µ F λ (1 − λ ) − ( β − µ f ) λ 2 2 k x − x ∗ k 2 w , (54) where in the last step we ha v e used strong conv exit y of F . Notice that λ ∗ def = µ F / ( µ F + β − µ f ) ∈ (0 , 1] and that µ F (1 − λ ∗ ) − ( β − µ f ) λ ∗ = 0. It now only remains to substitute λ ∗ in to (54) and subtract F ∗ from the resulting inequality . W e now present our main complexity result. It gives a b ound on the num b er of iterations required b y PCDM (Algorithm 5) to obtain an solution with high probability . The result is generic in the sense that it applies to an y smo oth conv ex function and prop er uniform sampling as long as the parameters β and w giving rise to an ESO are known. Theorem 11. Assume that F = f + Ψ is str ongly c onvex with r esp e ct to the norm k · k w ( µ F ( w ) > 0 ) and let S 0 , S 1 , . . . b e iid pr op er uniform samplings satisfying ( f , S 0 ) ∼ E S O ( β , w ) . Cho ose an initial p oint x 0 ∈ R N , tar get c onfidenc e level ρ ∈ (0 , 1) , tar get ac cur acy level 0 < < F ( x 0 ) − F ∗ and iter ation c ounter K ≥ n E [ | S 0 | ] β + µ F ( w ) − µ f ( w ) µ F ( w ) log F ( x 0 ) − F ∗ ρ . (55) If { x k } , k ≥ 0 , ar e the r andom p oints gener ate d by PCDM (Algorithm 5) as applie d to pr oblem (5) , then P ( F ( x K ) − F ∗ ≤ ) ≥ 1 − ρ. 18 Pr o of. Let α = E [ | S 0 | ] n and ξ k = F ( x k ) − F ∗ . Then for all k ≥ 0, E [ ξ k +1 | x k ] (34) ≤ (1 − α ) ξ k + α ( H β ,w ( x k + h ( x k )) − F ∗ ) (Lemma 10) ≤ 1 − αµ F ( w ) µ F ( w )+ β − µ f ( w ) | {z } def = γ ξ k . (56) Note that Lemma 10 is applicable as the assumption β ≥ µ f ( w ) is satisfied due to the fact that ( f , ˆ S ) ∼ E S O ( β , w ) (see [23, Section 4]). F urther, note that γ > 0 since α > 0 and µ F ( w ) > 0. Moreo ver, γ ≤ 1 since α ≤ 1 and β ≥ µ f ( w ). By taking exp ectation in x k through (56), we obtain E [ ξ k ] ≤ (1 − γ ) k ξ 0 . Applying Marko v inequalit y , Lemma 9 and (55), we obtain P ( ξ K > ) ≤ E [ ξ K ] ≤ (1 − γ ) K ξ 0 ≤ ρ, establishing the result. In order to compare the complexity of PCDM with that of DQAM, which is a fully parallel metho d, w e no w deriv e a specialized complexity result for the fully parallel v ariant of PCDM (Algorithm 6). The metho d is no longer sto c hastic in this situation, i.e., the sequence of vectors { x k } , k ≥ 0, is deterministic. Hence, w e give a standard complexity result as opp osed to a high probabilit y one. Finally , we mak e use of the fact that for partially separable functions f , the parameters β and w are kno wn. Theorem 12. Assume f : R N → R is p artial ly sep ar able of de gr e e ω , and has blo ck Lipschitz gr adient with c onstants L 1 , L 2 , . . . , L n > 0 . F urther assume that F = f + Ψ is str ongly c onvex with µ F ( L ) > 0 , wher e L = ( L 1 , . . . , L n ) . Final ly, let { x k } k ≥ 0 b e the se quenc e gener ate d by ful ly p ar al lel PCDM (Algorithm 6). Then for al l k ≥ 0 , F ( x k +1 ) − F ∗ ≤ q PCDM ( F ( x k ) − F ∗ ) , (57) wher e q PCDM = 1 − µ F ( L ) ω + µ F ( L ) − µ f ( L ) . (58) Mor e over, if we let < F ( x 0 ) − F ∗ and k ≥ 1 1 − q PCDM log F ( x 0 ) − F ∗ , (59) then F ( x k ) − F ∗ ≤ . Pr o of. Let ˆ S b e the fully parallel sampling, i.e., the n -nice sampling. Applying Theorem 7, we see that ( f , ˆ S ) ∼ E S O ( β , w ), with β = ω and w = L . F ollo wing the first part of the pro of of Theorem 11, w e hav e α = 1 and ξ k +1 ≤ (1 − γ ) ξ k , where γ = µ F ( L ) / ( µ F ( L ) + ω − µ f ( L )), establishing (57). The second statement follows directly by applying Lemma 9. 19 7.2 DQAM W e no w present a complexity result for DQAM, established in [29]. Theorem 13 (Theorem 2 in [29]) . L et f ( x ) = r 2 k b − Ax k 2 b e p artial ly sep ar able of de gr e e ω > 1 . Assume that F ( = f + Ψ ) is str ongly c onvex with µ F ( e ) > 0 , wher e e ∈ R n is the ve ctor of al l ones. F urther assume that the sets X i , i = 1 , . . . , n , ar e b ounde d. L et { x k } , k ≥ 0 , b e the se quenc e gener ate d by DQAM (Algorithm 2) with θ = 1 2( ω − 1) . Then for al l k ≥ 0 , F ( x k +1 ) − F ∗ ≤ q DQAM F ( x k ) − F ∗ , wher e q DQAM = 1 − µ F ( e ) 16 L 0 ( ω − 1) 3 + 4( ω − 1) µ F ( e ) , (60) and L 0 def = max 1 ≤ i ≤ n r k A i k 2 . Mor e over, if we let < F ( x 0 ) − F ∗ and k ≥ 1 1 − q DQAM log F ( x 0 ) − F ∗ , (61) then F ( x k ) − F ∗ ≤ . Ruszczy ´ nski analyzed DQAM for a range of parameters θ : θ ∈ (0 , 1 / ( ω − 1)) [29, Theorem 1; µ = 0]. Ho w ever, the choice θ = 1 / (2( ω − 1)) is optimal [29, Eq (5.11)], and the ab o ve theorem presen ts Ruszczy ´ nski’s result for this optimal c hoice of the stepsize parameter. A table translating the notation used in this pap er and [29] is included in App endix B. 7.3 Comparison of the Linear Rates of DQAM and PCDM W e now compare the con vergence rates q DQAM and q PCDM defined in (60) and (58), resp ectiv ely , and the resulting iteration complexit y guaran tees. W e will argue that q PCDM can b e m uch b etter (i.e., smaller) than q DQAM , leading to v astly improv ed iteration complexity bounds. Ho wev er, as w e shall see, in practice the fully parallel PCDM method and DQAM b eha v e similarly , with PCDM b eing ab out twice as fast as DQAM. Before we start with the comparison, recall from (42) that the gradien t of f ( x ) = r 2 k b − Ax k 2 (i.e., f co vered b y Theorem 13) is blo c k Lipschitz with constants L i = r k A T i A i k , i = 1 , 2 , . . . , n . Hence, L 0 = max i L i , which dra ws a link b et w een the quantities L i , i = 1 , 2 , . . . , n , app earing in Theorem 12 and L 0 app earing in Theorem 13. • Iden tical Lipsc hitz constants. Assume no w that L i = L 0 for all i = 1 , 2 , . . . , n and let L = ( L 1 , . . . , L n ), as in Theorem 12. Using (50) we observe that µ φ ( L ) = µ φ ( L 0 e ) = 1 L 0 µ φ ( e ) , (62) whence q PCDM (58)+(62) = 1 − µ F ( e ) L 0 ω + µ F ( e ) − µ f ( e ) . (63) 20 W e can no w directly compare q PCDM and q DQAM b y comparing (63) and (60). Clearly 2 , 16 L 0 ( ω − 1) 3 ≥ L 0 ω and 4( ω − 1) µ F ( e ) ≥ µ F ( e ) − µ f ( e ) , (64) and hence q PCDM ≤ q DQAM . How ever, b oth inequalities in (64) can b e v ery lo ose, whic h me ans that q PCDM can b e m uch b etter than q DQAM . F or instance, in the case when µ F ( e ) = µ f ( e ), w e hav e 1 − q PCDM 1 − q DQAM = 16 L 0 ( ω − 1) 3 + 4( ω − 1) µ F ( e ) L 0 ω ≥ 16( ω − 1) 3 ω . (65) In view of (59) and (61), this means that the num b er of DQAM iterations needed to obtain an -solution is larger than that for PCDM by at le ast the multiplic ative factor 16( ω − 1) 3 /ω . F or instance, the theoretical iteration complexity of DQAM is more than 1000 times worse than that of PCDM for ω = 10. • V arying Lipsc hitz Constan ts. If the constants L 1 , . . . , L n are not all equal, it is somewhat difficult to compare the complexity rates as we cannot directly compare the strong conv exity constan ts µ φ ( L ) and µ φ ( e ) (for φ = F and φ = f ). What w e can do, how ever, is to at least make sure that the “scaling” is identical in b oth. Here is what we mean by that. Recall that µ φ ( w ) is the strong conv exity constant of φ wrt a weighte d norm k x k w defined b y (29). As we hav e remarked in (50), if w e scale the weigh ts b y a p ositive factor t > 0, the corresp onding strong conv exity constant scales b y 1 /t . Hence, µ φ ( L ) and µ φ ( e ) cannot b e considered comparable unless P i L i = P i e i = n . Of course, even if this was the case, it is p ossible that the strong conv exity constan ts might b e very differen t. How ever, in this case there is at least no reason to susp ect a-priori that one might be larger than the other, and hence they are comparable in that sense. If we let ¯ L = 1 n P i L i and w i = L i / ¯ L for i = 1 , 2 , . . . , n , then P i w i = n , and hence, as explained ab ov e, µ φ ( w ) ≈ µ φ ( e ) . (66) F urthermore, since w = L/ ¯ L , we hav e µ φ ( L ) = µ φ ¯ Lw (50) = 1 ¯ L µ φ ( w ) ≈ 1 ¯ L µ φ ( e ) . The ab o v e is an analogue of (62) and w e can therefore now conti nue our comparison in the same wa y as w e did for the case with iden tical Lipsc hitz constan ts. In particular, if µ F ( e ) = µ f ( e ) (for simplicity), then as ab o ve w e can argue that 1 − q PCDM 1 − q DQAM = 16 L 0 ( ω − 1) 3 + 4( ω − 1) µ F ( e ) ¯ Lω ≥ 16( ω − 1) 3 ω L 0 ¯ L . (67) Therefore, PCDM has an even more dramatic theoretical adv antage compared to DQAM in the case when the maximum Lipschitz constan t L 0 is muc h larger than the av erage ¯ L . 2 This holds as long as ω > 1, which is the case cov ered by Theorem 13 and hence assumed here. 21 7.4 Optimal num b er of blo c k up dates In this section we prop ose a simplified mo del of parallel computing and in it study the p erformance of a family of parallel coordinate descen t methods parameterized b y a single parameter: the n umber of blo cks b eing up dated in a single iteration. In particular, consider the family of PCDMs where S k is a τ -nice sampling and τ ∈ { 1 , 2 , . . . , n } . No w assume w e hav e p ∈ { 1 , 2 , . . . , n } pro cessors/threads a v ailable, each able to compute and apply to the curren t iterate the update h ( i ) ( x k ) for a single block i , in a unit of time. PCDM, as analyzed, is a synchronous metho d. That is, a new parallel iteration can only start once the previous one is finished, and hence up dating τ blo c ks will take d τ p e amount of time. On the other hand, the iteration complexit y of PCDM is b etter for higher τ . Indeed, by Theorem 7, f satisfies an ESO with resp ect to ˆ S with parameters w = L = ( L 1 , . . . , L n ) and β = β ( τ ) = 1 + ( ω − 1)( τ − 1) n − 1 , where ω is degree of partial separabilit y of f (we assume n > 1). If, moreo ver, µ F ( L ) = µ f ( L ), which is often the case as Ψ is often not strongly con vex, then Theorem 11 says that PCDM needs n τ β ( τ ) c iterations, where c is a constant independent of τ , to solve (5) with high probabilit y . Hence, the total amount of time needed for PCDM to solv e the problem is equal to T ( τ ) = d τ p e n τ β ( τ ) c. W e can no w ask the follo wing natural question: what τ ∈ { 1 , 2 , . . . , n } minimizes T ( τ )? W e no w show that the answ er is τ = p . Theorem 14. Assume f : R N → R is c onvex, p artial ly sep ar able of de gr e e ω , and has blo ck Lipschitz gr adient with c onstants L 1 , L 2 , . . . , L n > 0 , wher e n > 1 . F urther assume µ F ( L ) = µ f ( L ) > 0 and c onsider the family of p ar al lel c o or dinate desc ent metho ds with τ -nic e sampling, wher e τ ∈ { 1 , 2 , . . . , n } , applie d to pr oblem (5) . Under the p ar al lel c omputing mo del with p ∈ { 1 , 2 , . . . , n } pr o c essors describ e d ab ove, the metho d with τ = p is optimal. Pr o of. W e only need to show that p = arg min { T ( τ ) : τ = 1 , 2 , . . . , n } . It is easy to see that n τ β ( τ ) is decreasing in τ . Since d τ p e is constan t for k p + 1 ≤ τ ≤ k p , it suffices to consider τ = k p for k = 1 , 2 , . . . only . Finally , T ( k p ) = n p β ( k p ) c is increasing in k since β ( · ) is increasing, and we conclude that k = 1 and hence τ = p is optimal. 8 Numerical Results In this section we presen t t wo n umerical exp erimen ts that supp ort the findings of this pap er. In b oth exp erimen ts we c ho ose f ( x ) = 1 2 k b − Ax k 2 and Ψ ≡ 0. The first exp erimen t considers the p erformance of DQAM and the fully parallel v ariant of PCDM in the ab o ve setting where w e know that the t wo metho ds coincide up to he selection of the stepsize parameters ω and θ (recall Section 6.4). Here w e fo cus on comparing the effects of using the DQAM stepsize θ = 1 / (2( ω − 1)) versus the larger PCDM stepsize θ = 1 /ω . The second exp eriment compares DQAM, fully parallel v ariant of PCDM (i.e., PCDM used with n -nice sampling) and PCDM used with τ -nice sampling, in the situation when the num b er of a v ailable pro cessors is τ , while v arying ω (degree of partial separabilit y of f ) and τ . 22 8.1 Impact of the differen t stepsizes of DQAM and PCDM Supp ose that A has primal blo c k angular structure A = C D = C 1 . . . C n D 1 . . . D n , where C i , D i are matrices of appropriate sizes. Notice that when D = 0, the problem is partially separable of degree ω = 1 (i.e., it is fully separable) with resp ect to the natural blo c k structure (i.e., blo cks corresp onding to the column submatrices [ C i ; 0; D i ]). If D is completely dense, the problem is nonseparable ( ω = n ). In general, the degree of separability of f is equal to the num b er of matrices D i that contain at least one nonzero entry . In this (small scale) exp erimen t w e set n = 100 and let C 1 , . . . , C 100 b e 10% dense matrices of size 150 × 100. Subsequen tly , A is a 15 , 001 × 10 , 000 sparse matrix. The degree of separability of f v aries, and is controlled by setting a subset of the matrices D 1 , . . . , D n to zero. Tw ent y fiv e random pairs ( A, b ) were generated for each ω ∈ { 2 , 4 , 8 , 16 , 32 } , and DQAM and fully parallel v ariant of DQAM were applied to each problem instance. A stopping condition of f ( x ) ≤ 10 − 4 b T b was employ ed; the results of this exp erimen t are presented in Figure 8.1. All data p oin ts are av erages o ver 25 runs. 2 4 8 16 32 0 400 800 1200 1600 2000 Degree of separability Number of epochs DQAM PCDM Student Version of MATLAB Figure 1: This plot shows the num b er of epo chs (a full sw eep through the data, i.e., all i = 1 , . . . , n blo c ks of x are up dated in one ep och) needed to solve the problem as a function of the degree of separabilit y ω . Notice that when ω = 2, DQAM and PCDM require the same num b er of ep ochs to solv e the problem. This is b ecause θ = 1 / (2( ω − 1)) = 1 / 2 = 1 /ω . Then as ω grows, PCDM p erforms far b etter than DQAM, requiring almost 50% fewer ep o c hs than DQAM. 23 8.2 Comparison of full vs partial parallelization Recall that unlike DQAM, PCDM is able to up date τ blo c ks at eac h iteration, for an y τ in the set { 1 , 2 , . . . , n } , demonstrating useful flexibilit y of the algorithm. By PCDM( τ ) w e denote the v ariant of PCDM in which τ blo c ks are up dated at each iteration, using a τ -nice sampling. In this exp erimen t we inv estigate the p erformance of DQAM, PCDM( n ) (which in the plots we refer to simply as PCDM) and PCDM( τ ), for a selection of parameters τ (the num b er of pro cessors), and ω (the degree of partial separability). Let us call the time taken for all τ pro cessors to up date a single blo c k, one “time unit”. Then, after one time unit of PCDM( τ ), new gradient information is av ailable to b e utilized during the next time unit, whic h is m uch earlier than if all n blo c ks need to be up dated in each iteration. On the other hand, for DQAM and PCDM, one iteration corresp onds to all n blo c ks of x b eing up dated. Subsequently , if there are τ pro cessors av ailable, one iteration of DQAM or PCDM (one ep och) corresp onds to d n τ e time units. Ho wev er, PCDM( τ ) will need to p erform more iterations than b oth DQAM and PCDM. When b oth of these factors are taken in to account, w e hav e shown in Theorem ??? that PCDM( τ ) is optimal in terms of ov erall complexity if there are τ pro cessors. The purpose of this exp erimen t is to inv estigate this phenomenon n umerically . F urther, let A b e a 2 · 10 4 × 10 4 sparse matrix, with at most ω nonzero entries p er ro w. Let the stopping condition b e f ( x ) ≤ 10 − 4 b T b . The exp eriment was run for three instances: ω = 20 , 60 , 100, and for each ω and v arying τ , the av erage num b er of time units required by DQAM, PCDM and PCDM( τ ) were recorded. The results are shown in Figure 2. 20 60 100 10 4 10 5 Number of time units Degree of separability PCDM(8) DQAM on 8 cores PCDM on 8 cores PCDM(16) DQAM on 16 cores PCDM on 16 cores PCDM(32) DQAM on 32 cores PCDM on 32 cores PCDM(64) DQAM on 64 cores PCDM on 64 cores Student Version of MATLAB Figure 2: F or eac h fixed τ ∈ { 8 , 16 , 32 , 64 } , PCDM( τ ) (solid line) is b etter than PCDM (dashed line), and noth are far b etter than DQAM (dotted line). The colors in Figure 2 correspond to differen t v alues of τ . The solid lines corresp ond to PCDM( τ ), while the dotted line (resp ectiv ely dashed line) corresp onds to DQAM (resp ectiv ely PCDM) run with τ processors a v ailable. As ω increases, all algorithms require a higher num b er of time units. F urther, as the num b er of a v ailable pro cessors increases, the num b er of time units decreases. More imp ortantly , for any fixed τ , PCDM( τ ), requires far fewer time units than PCDM, 24 and both require many few er time units than DQAM. (Notice the log scale.) This demonstrates the practical adv antage of ‘optimizing’ PCDM( τ ) to the num b er of a v ailable pro cessors, as describ ed in Section 7.4. W e hav e also recorded the av erage cpu time, and the resulting curv es are visually indistinguish- able from those in Figure 2; only the scale of the vertical axis changes. References [1] Arno J. Berger, John M. Mulvey , and Andrzej Ruszczy´ nski. An extension of the DQA algorithm to con vex stochastic programs. SIAM Journal on Optimization , 4(4):735–753, Nov em b er 1994. [2] Dimitri Bertsek as. Constr aine d Optimization and L agr ange Multiplier Metho ds . Athena Sci- en tific, 1996. [3] Mathieu Blondel, Kazuhiro Seki, and Kuniaki Uehara. Blo ck co ordinate descent algorithms for large-scale sparse multiclass classification. Machine L e arning , 2013. [4] Joseph K. Bradley , Aap o Kyrola, Danny Bickson, and Carlos Guestrin. Parallel co ordinate descen t for L1-regularized loss minimization. In 28th International Confer enc e on Machine L e arning , 2011. [5] Olivier F erco q. Parallel co ordinate descent for the Adab o ost problem. T echnical rep ort, July 2013. [6] Olivier F erco q and Peter Rich t´ arik. Smo othed parallel coordinate descent metho d. T ec hnical rep ort, 2013. [7] Magn us R. Hestenes. Multiplier and gradient metho ds. Journal of Optimization The ory and Applic ations , 4:303–320, 1969. [8] Cho-Jui Hsieh, Kai-W ei Chang, Chih-Jen Lin, S Sathiy a Keerthi, and S Sundarara jan. A dual co ordinate descent metho d for large-scale linear svm. In ICML 2008 , pages 408–415, 2008. [9] Yin T at Lee and Aaron Sidford. Effcient accelerated co ordinate descent metho ds and faster algorithms for solving linear systems. arXiv:1305:1922v1 , 2013. [10] Yingying Li and Stanley Osher. Coordinate descen t optimization for l 1 minimization with application to compressed sensing; a greedy algorithm. Inverse Pr oblems and Imaging , 3:487– 503, August 2009. [11] Zhaosong Lu and Lin Xiao. On the complexity analysis of randomized blo c k-co ordinate descent metho ds. T echnical rep ort, May 2013. [12] Zhaosong Lu and Lin Xiao. Randomized blo c k co ordinate non-monotone gradien t metho d for a class of nonlinear programming. T echnical rep ort, June 2013. [13] John M. Mulvey and Andrzej Ruszczy ´ nski. A diagonal quadratic approximation metho d for large scale linear programs. Op er ations R ese ar ch L etters , 12:205–215, 1992. 25 [14] John M. Mulvey and Andrzej Ruszczy ´ nski. A new scenario decomp osition metho d for large scale s tochastic optimization. Op er ations R ese ar ch , 43(3):477–490, 1995. [15] Ion Necoara, Y urii Nesterov, and F rancois Glineur. Efficiency of randomized coordinate descent metho ds on optimization problems with linearly coupled constraints. T ec hnical rep ort, June 2012. [16] Ion Necoara and Andrei Patrascu. A random co ordinate descen t algorithm for optimization problems with comp osite ob jective function and linear coupled constrain ts. T echnical rep ort, Univ ersity Politehnica Buc harest, 2012. [17] Y urii Nesterov. Efficiency of co ordinate descen t metho ds on huge-scale optimization problems. SIAM Journal on Optimimization , 22(2):341–362, 2012. [18] Andrei Patrascu and Ion Necoara. Efficient random co ordinate descen t algorithms for large- scale structured nonconv ex optimization. T echnical rep ort, Universit y P olitehnica Bucharest, Ma y 2013. [19] Mic hael J. D. Po well. A metho d for nonlinear constraints in minimization problems. In Roger Fletc her, editor, Optimization , pages 283–298. Academic Press, 1972. [20] Zhiw ei (T ony) Qin, Kat ya Schein b erg, and Donald Goldfarb. Efficient blo c k-co ordinate descent algorithms for the group lasso. T echnical rep ort, Department of Industrial Engineering and Op erations Research, Colum bia Universit y , 2010. [21] P eter Ric ht´ arik and Martin T ak´ aˇ c. Efficient serial and parallel coordinate descent metho ds for huge-scale truss top ology design. In Op er ations R ese ar ch Pr o c e e dings 2011 , pages 27–32. Springer, 2012. [22] P eter Ric ht´ arik and Martin T ak´ aˇ c. Iteration complexity of randomized blo ck-coordinate de- scen t metho ds for minimizing a composite function. Mathematic al Pr o gr amming, Ser. A , 2012. [23] P eter Ric ht´ arik and Martin T ak´ aˇ c. Parallel coordinate descen t metho ds for big data optimiza- tion. T ec hnical rep ort, Nov ember 2012. [24] P eter Ric ht´ arik and Martin T ak´ aˇ c. Efficiency of randomized coordinate descen t methods on minimization problems with a comp osite ob jectiv e function. In 4th Workshop on Signal Pr o c essing with A daptive Sp arse Structur e d R epr esentations , June 2011. [25] R. Tyrell Ro c k afellar. The multiplier metho d of Hestenes and P ow ell applied to con vex pro- gramming. Journal of Optimization The ory and Applic ations , 12:555–562, 1973. [26] R. T yrell Ro c k afellar. Augmented Lagrangians and applications of the pro ximal p oin t algo- rithm in conv ex programming. Mathematics of Op er ations R ese ar ch , 1:97–116, 1976. [27] R. Tyrell Ro c k afellar and Roger J.-B. W ets. Scenarios and p olicy aggregation in optimization under uncertaint y . Mathematics of Op er ations R ese ar ch , 16:1–23, 1991. [28] Andrzej Ruszczy ´ nski. An augmen ted Lagrangian metho d for blo c k diagonal linear program- ming problems. Op er ations R ese ar ch L etters , 8:287–294, 1989. 26 [29] Andrzej Ruszczy´ nski. On conv ergence of an augmented Lagrangian decomp osition metho d for sparse conv ex optimization. Mathematics of Op er ations R ese ach , 20(3):634–656, 1995. [30] Hermann Sch warz. ¨ Ub er einen Grenz ¨ ubergang durch alternierendes V erfahren. Vierteljahrss- chrift der Naturforschenden Gesel lschaft in Z ¨ urich , 15:272–286, 1870. [31] Shai Shalev-Sh wartz and Ambuj T ew ari. Stochastic metho ds for l 1 regularized loss minimiza- tion. In 26th International Confer enc e on Machine L e arning , 2009. [32] Shai Shalev-Sh wartz and T ong Zhang. Accelerated mini-batc h stochastic dual coordinate ascen t. T echnical rep ort, May 2013. [33] Shai Shalev-Shw artz and T ong Zhang. Sto c hastic dual co ordinate asce n t metho ds for regular- ized loss minimization. Journal of Machine L e arning R ese ar ch , 14:567–599, 2013. [34] George Stephanop oulos and Arth ur W. W esterb erg. The use of Hestenes’ metho d of m ultipliers to resolve dual gaps in engineering system optimization. Journal of Optimization The ory and Applic ations , 15:285–309, 1975. [35] Martin T ak´ aˇ c, Avleen Bijral, P eter Rich t´ arik, and Nathan Srebro. Mini-batch primal and dual metho ds for SVMs. In 30th International Confer enc e on Machine L e arning , 2013. [36] Rac hael T app enden, Peter Rich t´ arik, and Jacek Gondzio. Inexact co ordinate descent: com- plexit y and preconditioning. T ec hnical rep ort, April 2013. [37] P aul Tseng. Con vergence of a blo c k co ordinate descen t metho d for nondifferentiable mini- mization. Journal of Optimization The ory and Applic ations , 109:475–494, June 2001. [38] N. W atanab e, Y. Nishimura, and M. Matsubara. Decomp osition in large system optimization using the metho d of m ultipliers. Journal of Optimization The ory and Applic ations , 25:181–193, 1978. 27 A Notation Dictionary F or the reader interested in comparing our w ork with the pap er [29] directly , we ha ve included a brief dictionary translating some of the key notation (T able 1). T able 1: Notation dictionary . Ruszczy ´ nski [29] This pap er L n N ω − 1 x i x ( i ) ˜ x x x y x − ˜ x h = y − x τ θ ρ r ρα 2 L 0 γ µ F ( e ) / 2 1 2 r k b − P n i =1 A i x i k 2 2 f ( x ) f i ( x i ) − h A T i π , x i i Ψ i ( x ( i ) ) (= g i ( x i ) − h A T i π , x i i ) Λ( x ) F ( x ) = f ( x ) + Ψ( x ) Λ i ( x i , ˜ x ) f ( x + U i h ( i ) ) + Ψ i ( y ( i ) ) ˜ Λ( x, ˜ x ) f ( x ) + P n i =1 [ f ( x + U i h ( i ) ) − f ( x )] + Ψ( x + h ) 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment