Robust Support Vector Machines for Speaker Verification Task
An important step in speaker verification is extracting features that best characterize the speaker voice. This paper investigates a front-end processing that aims at improving the performance of speaker verification based on the SVMs classifier, in …
Authors: Kawthar Yasmine Zergat, Abderrahmane Amrouche
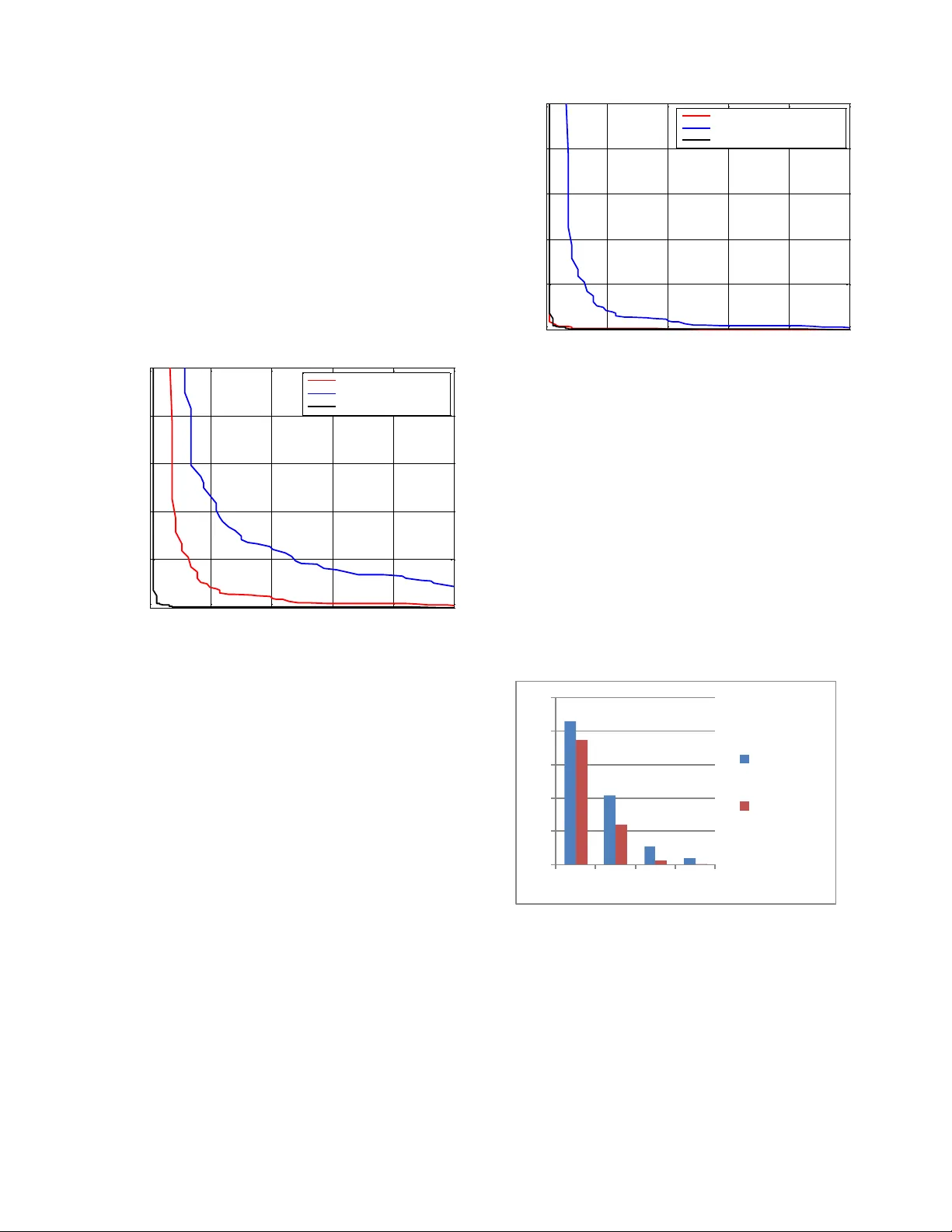
R o b u s t S u p p o r t V e c t o r M a c h i n e s f o r S p e a k e r V e r i f i c a t i o n T a s k Kawthar Yasm ine ZERGAT 1 , Abderr ahma ne AMROUCHE 1 1 Speech Com. & Signal Proc. Lab.-LCPTS Faculty of Electronics and Computer Sciences, USTHB, Bab Ezzouar, 16 111, Algeria. Abstract An important step in speaker verification is extracting features that best characterize the speak er voice. This pap er investigates a front-end p rocessing that aims at impro ving the performa n ce of speaker ve rification base d on the SVMs classifier, in tex t independen t m o de. This app roach combines features b ased on conventional Mel-cepstral Coef ficients (MFCCs) and Line Spectral Frequencies (LSFs) to constitute robust multivariate feature vectors. To reduce the high dimensionality re q uired for training these feature vectors, w e use a dim ensio n reduction method called principal component analy sis (PCA). In order to evaluate the robustness of these syste ms, different noisy environments hav e been used. The obtained results using TIMIT database showed that, using the paradigm that c o mbines these spectral cues leads to a significant im pro vem ent in verifica ti on a ccuracy, especially w ith PCA reduction for low signal- to -noise ratio no isy environme n t. Keywords: SVM, Noisy environ ment, LSF, MFCC, PCA. 1. Introduction A ty p ical speaker verification system usually co nsists of two phases: an enro llmen t phase, and an Authentication phase. In the enrollm ent phase, the system extracts speaker-specific information from the speech signal to be used to build a model for the speaker [ 1], where the purpose of the testing phase is to determine wh ether the speech samples b elong to the perso n that claims his/her identity or not. In all audio p rocessing, the s p eech input is converted into a feature vector r epresentation [2]. Linear Predic tion Cepstral Coefficients (LPCC) and Perceptual L inear Prediction Cepstral Coeff icients (PLPCC), th e Mel Frequency Cepstral Coefficients (MFCC) [3 ] approac h has been the most employed for feature extraction. For modeling, Suppo rt Vector Machine ( SVM) [ 4] represents a discrim inative classifier w hich has achieved im pressive results in several pattern recognition tasks. In d eed, the SVMs are interestin g because they discr imin ate b etween classes (speaker/impostor) and could be used to train non- linear decision b oundaries in an efficien t mann er. In this paper, for speaker verification, we investigate on SVM classifier based on Principal Component Analysis (PCA) [5] to get the efficiently reduced dim ension of feature vectors. First, the MFCC, Lin e Spectral Fre quen cy (LSF) features ar e extracted from the speech voice sample. The concatenation of these features vectors (MFCC-LSF) is made. Secondly, th e new f ea ture vectors w ith reduced dimension are o btained by applying P CA dimensionality reduction to each speaker vec tors. Finally , theses transformed feature vectors are used as input to the SVM system for text independent speaker verification task. To validate the influen ce of PCA dimensionality reduction, we have evaluated the robustness of b oth SVM and PCA- SVM system s in different noisy environm ents at different levels of SNRs. The rest of the pap er is as follows. In sections 2, w e describe the Feature Extraction process used and discuss the p rinciples of SVM in section 3. Section 4 and 5 are the experimental setup and the results of the experiments conducted on a subset of TIMIT Database. Finally, w e co nclude in Section 6. 2. Feature Extraction 2.1 Mel Frequency Cepstral Coeffici ent (MFCC) MFCCs were introduced in early 1980 s for speech recognition applications. The key steps in volved in computing MFCC features are sh own in Fig. 1. The speech sig nal is first p re-emphasized by ap plying the fo llowing filter [1], ), 1 ( ) ( ) ( t ay t y t x Wh ere ] 98 . 0 , 95 . 0 [ a (1) The goal of the filter is to enhance the high frequencies of the spectrum, w hich is diminish ed during the speech production p rocess. Follo win g the pre -emphasis stage is a win do win g step, the spee ch samples are weig hed by a suitable w indowing function, The Hamming w indow is extensively used in speaker verification to taper the original signal on the sides witch reduce the side eff ects [6]. Fig. 1 MFCC features extraction. The result of window ing the signal is show n below: , 1 2 c os 46 . 0 54 . 0 ) ( N n n W 1 0 N n (2) Once the speech signal has been window ed its fast Fourier transform (FFT) is calculated . Finally , the modulus o f the FFT is extracted and a power spectrum is obtained [6]. The ob tained spectrum is then multiplied b y filterbank. The filters that are generally used in MFCC computation are triangular f ilters, and their center f r equencies are chosen accor ding a logarithm ic frequency scale als o know n as Mel-frequency sca le witch co nforms to response obs erved in hum an auditory sys tems. T he localization of the central frequencies of the filters is given by [ 1]: 2 l og ) 1000 / 1 l og ( . 1000 LI N ME L f f (3) An additional transform, is to obtain the spectral vectors by taking the log of the spectral envelope and mu ltiply each coefficient b y 20 in o rder to get the spec tral envelope in dB [6 ]. Finally , the cosine discrete transf o rm (DCT) is applied to the spectr al vectors w itch yields cepstral coefficients frequencies, and is given by [6]: , ] ) 2 1 ( c os[ 1 K k k n k k n S c L n ,...., 2 , 1 (4) Where K is the number of log-spectral coefficients calculated in pr evious step, k S are the log-spectral coefficients, and L is the num ber of ce pstral coefficients to calculate. 2.2 Line Spectral Frequency Cues (LSF) The starting point for deriving the LSF’s is the respo nse of the prediction error filter. P k k k z a z A 1 1 ) ( (5) Where P represe nt s the pred iction ord er, and k a are the LPC filter coefficients. In the LPC the m ean squared error between the linearly predicted speech sample and the actual one is minim ized over a finite interval [7]. The transfer fu nction of the LPC filter w ith a gain G is given by: , 1 ) ( 1 P k k k z a G z H (6) From ) ( z H , a sy mmetric poly nomial (z ) S 1 P and an antisy mmetric polyn omial (z ) 1 P are calculated by adding and subtracting the tim e -reversed system function. ), ( ) ( S 1 ) 1 ( 1 P z A z z A p p p And ), ( ) ( 1 ) 1 ( 1 z A z z A p p p p (7) The p olynom ials contain trivial zero s for even values of p at 1 z and at 1 z . These roo ts can be removed in order to derive the followin g quantities [7]: , ... ) 1 ( (z ) S ) ( ~ 1 1 0 1 P p p p z z z z S And , ... ) 1 ( (z ) ) ( ~ 1 1 0 1 P p p p z z z z (8) The LSFs ar e the r oots of ) ( ~ z S and ) ( ~ z and alternate with each o ther on the unit circle [7]. 3. Support Vector Machine Support Vector Machine (SVM) is a binary linear classifier in its b asic form. It has bee n recently adopted in speaker reco gnition task. Given a set of linearly separable two- class training d ata, there are many possible solutions fo r a discriminative classifier [8 ]. An SVM seeks to fin d the Optimal Separating Hyperplane (OSH) betw een Pre- emphasis Hamm ing win do w FFT Cepstral tr an s f o r m 20*log Filterbank classes by focusing on the training cases that lie at the edge of the class distributions, the suppor t vecto rs, with the other training cases effectively discarded [8 ]. Formally , the discriminant function of SVM is given by : b x x K y sig n x c l ass x f i i N i t i ) , ( ) ( ) ( (9) Here 1 , 1 i y are the ideal output values, 0 i N i t i y and 0 i . The suppo rt vectors i x , their corresponding weights i and the bias term b. To calculate the classification function class (x) we use the dot prod uct in feature space that can also be expressed in the in p ut space by the kernel function K(·, ·) . Am ong the most w idely used cores we fin d : RBF kernel: e i x x y x k 2 ) , ( Polynomial k ernel: ) 1 . ( ) , ( y x y x k T Finally , the classification of data is m ad e as follow: 2 1 c l as s e Cl as s e x if Othe r wi s e X 0 4. Experime ntal Protocol 4.1 Description of the Dat abase The co rpus used in this work is issued from the TIMIT database. This database includes time-align ed orthographic, phonetic and w ord transcriptions as w ell as a 16-bit, 16 kHz speech file f or each utterance and is recorded in “.ADC” format, where each sentence has 3s of length spoken in English language. We h ave selected a set o f 90 speakers, for b oth tr aining and testing phases, each of w hom reads 5 phonetically rich sentences for training task and 3 utterances for testing task. T o simu late the impostors, 50 un known speakers (25 female and 25 male) are used from the sam e d atabase ( TIMIT ) and ar e different from the 90 speakers used previously, with five utterances spoken by each unk nown speaker. 4.2 Parameterization Phase In this w ork, we have in cluded as man y speakers’ characteristics as po ssible. So, o ur first feature space is made w ith 1 2 MFCC coefficients plus Energy parameter and the f irst and second d erivatives, which yield 3 9 - dimensional feature vector, extracted from the middle win do w every 1 0ms. A voice activity detector is used to elimin ate silence and noise frames from the training and testing signals in order to avoid modeling and detecting the environment rather than the speaker. In the seco nd part, 1 2 LSF coefficients were extracted. Finally , th e first feature space (MFCCs +E+ + ) was co mbined with 12 LSF coefficients to constitute a m ulti-dimensional feature set. The dim ension of the co mbined vectors is then equal to 51 . Once the feature vectors have been calculated, they can be centered, using Cepstral Mean Subtraction (CMS), this is carried out by estimating a mean vector for the extracted set of cepstral features and subtracting it from all the feature vectors. In the other hand, the size of the vectors of parameters is an important problem that ar ises w hen adding parameters. T o address this, technique to red uce the number of parameters w as used, these include PCA dimens io nality r eduction. 4.3 Modeling Phase For the enrolment phase, we did however make use o f a RBF kernel function for the SVM classifier. In order to evaluate the p erformance of the sy stem, tw o ty pes of additive noise pro duced b y a Speech B abble and a Subw ay noises reaching high levels of SNR and derived from the NOISEX-92 database ( NATO: AC 24 3/RSG 10) are added to the test speech signal of the TIMIT database. In speaker verification task, th er e are two types o f erro rs; false accep tance (FA) and false rejection (FR) . T he Equal Error Rate (ERR) is the point where the rate of FR’s is equal to the r ate of FA’ s. For classification, T he Detection Erro r T radeoff (DE T) curve is a popular way of g rap hically r epresenting the performance of speaker verification sy stem. 5. Experime nt Results 5.1 Speaker Verification using Original Speech Waveforms To show the effectiveness of the proposed method, w e performed two exp eriments using speech data w ithout and usi ng the PCA dimensionality red uction for the SVM classifier in speaker verification task. In bo th experiments we used Equal Error R ate (EER) as the performance criterion. For the first exper imen t a com p arative stu dy show s the contribution o f the concatenation between the MFCC and the LSF f eatures. As show n in Fig. 2, the concatenated feature vector brings the less EER eq ual to 0.54% against the LSF and MFCC feature vectors with an EER equal to 7.39 % and 3.69% resp ectively. 0 5 10 15 20 25 0 5 10 15 20 25 False Ac c eptation Ra t e (%) False Re jec t Rate (%) DET c urv e MFCC: EE R=3.69% . LSF: E ER=7.39% . MFCC- LSF: E ER=0. 54% . Fig. 2 Performance evaluation for SVM b ased speaker verification task. Speaker verification experiment with P CA based SVM classifier has been performed too with these various feature space components. Fro m the following fig. 3 , it’s clearly seen that PCA improves s ignificantly the recognition accuracy, until an EER=0.51% for the concatenated (MFCC, LSF) feature vectors. 0 5 10 15 20 25 0 5 10 15 20 25 False A c ceptati on Ra t e (%) False Re jec t Rate (%) DET c urv e MFCC- PCA: E ER=0. 63% . LSF-PCA: EE R=2.56% . MFCC- LSF-PCA: E ER=0.51% . Fig. 3 Perfo rmanc e eval ua tion for PCA-SVM based speaker ve rificat ion task. 5.2 Ve rification Accuracy under Noisy Environm ent s The main goal of the experiments done in this section is the study o f the verification performances of both SVM and PCA-SVM sys tems in different noisy environmen ts, for this, two noisy environm ents which are Sp eech Babble and Subway noises were used. We evaluated the error rate b y applying dimensionality reduction by P CA algorithm on the concatenated MFCC-LSF feature vectors. The results are shown in the f o llowin g figures. 0 10 20 30 40 50 0 5 10 15 MF CC-L S F MF CC-L S F- PCA Fig. 4 Perfo rmanc es eval u ation for SVM and PCA-SVM in noisy environment corrupted by Babble speech noise. 0 10 20 30 40 50 0 5 10 15 MF CC - L S F MF CC - L S F - PC A Fig. 5 Perfor man ces eval u ation for SVM and PCA-SVM in noisy environment corrupted by Subw ay noise. As show n in the above figures, it is clearly seen that applying PCA algorithm on featur e vectors lead s to an interesting increase of speaker verification accuracy. Quantify ing the input data by other Algorithm s such as LBG and k-m eans, q uantify all the data including th e insignif icant and repeated items p resented in the speech signal [9] , by cons, when using PCA dimensionality reduction , we pro ject the data into low er dimen sional space, where the low variance co mponents are elimin ated . The obtained results co nfirm the effect of PCA, fo r example, in case of noisy environment co rrupted by Babble speech noise at SNR = 0 dB, the EER decrease from 42.87% to 37 .39% which rep resents an interesting improvem ent in bad conditions. 6. Conclusion This pap er has presented and evaluated a text- independent spea ker verification system s based on SVM classifier. T o attain better performance, tw o system s were trained, the SVM and the PCA-SVM sy stems. In this study, we have ex amined the influ ence of feature vectors and PCA dimensionality reduction o n speaker verification rate in b oth clean and noisy environmen ts . C ar ried out on TIMIT database , it is noticed that, the combination between MFCC and LSF outperforms the conventional MFCC parameters. In the other hand, for the P CA-SVM model, the recognition accuracy has increase significantly comparing to the SVM model, esp ecially in hard conditions (SNR= 0dB). W e are currently continuin g the effort towards the optimization of this sy stem u sing other dimensionally reduction method. References [1] C. Turnera, A. Josephb, M. Aksuc, and H. Langdonda, "The Wavelet and Fou rier Transforms in F eature Extraction for Text-Dependent, F ilterbank Based S peaker Recognition ", Complex Adapti ve Systems , Vol. 1 , 2011 , pp. 12 4- 129. [2] T. Mazibuko, and D. Marshao, "Feature extraction and dimensionality reduction in SVM speaker recognition", So uthern A frican Telecommunica tions an d Applicatio ns Conference (SATNAC 2006 ), 2006 . [3] S. Davis, and P . Mermelstein, "Comparison of parametric representations for monosyllabic w o rd recognition in continuo usly spoken sentences" , IEEE Tra nsaction on Acoustics, Speech, and Sign al Pro cessing , 1 , 1 980, Vol. 28 , pp. 357 - 366. [4] R. Dehak, N. De h ak, P. Kenn y, and P. Dumouchel, "L in ear and non linear kernel GMM supervector machines for speaker verif ication ", Proc. Interspeech, Antwerp , 2 007, pp. 302 – 305. [5] C. Hanilci, and F. Ertas, " VQ -UBM based speaker verifica ti on thro ugh dimension red uction u sing local PCA", 19 th Eu ropean Signal Processing conference (EUSIPCO) , 2011. [6] F. Bimbot, J. F. Bonastre, C. Fredouille, G. G ravier, I. M. Chagnolleau, S. Meignier, T. Merlin, J. Ortega- Garcıa, D. Petrovska-Delacretaz, an d D. A. Reynolds, "A tuto rial on text-independent sp eaker verif ication ", EURASIP Journa l on Advan ces in Signal Processing , 2 004, pp . 430 - 451. [7] D. Addou , S. A. S elouani, K. Kifaya , M. Boudraa, and B. Boudraa, "A noise-ro bust front- end for distrib uted speech recognition in mobile comm un ications" , Internatio nal Journal of Sp eech Techn ology Springer Science , Vol. 10 , 2007, pp. 167 -1 73 . [8] W. M. Campbell, D. E Sturim, D. A . Reynolds, and A. Solomonoff, "SV M b ased speaker verification usin g a GMM supervector kernel and NAP variability compensation" , Proceedings of ICAS SP , 2006 . [9] T. Kinnunen, and H. Li, "An overview of text-ind ependent speaker recognition: From features to supervectors ", S peech Communicatio , Vol. 52 , 20 10, pp. 12 - 40 . Kawthar Yasmine Zergat Received her Master II degree in Communication and Multimedia from t he University of Science and Technology Houari Boum edienne (USTHB), Algiers in 20 10. Currently, she is pursuing the P h.D. degree in, Telecommunicat ions and I nformation Processing in the Communication System s and Speech Processing Laboratory , USTHB. Her current research concentrates on robust speaker recognition and speech processing. A bderrahmane A m rouche W as born in Algeria. He received his “diplome d’ingenieur” (enginee r degree) in Electronics from the National Polytechnic school of Algiers in 1980. He receive d his “Magister” degree in 1995 and Doctorat d’E tat” (Ph.D) in Real Time Systems in 2007 from the University of Science and Technology Houa ri B oumedienne (USTHB). He is an Assis tant Professor in Communication Systems and Speech Processing Laboratory , USTHB. His research interests include pattern recognition, speech processing, Multilingual speech recognition, neural netw orks, prosodic modelling.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment