노이즈 환경에서도 강인한 스피커 검증을 위한 SVM·PCA 기반 시스템
본 논문은 MFCC와 LSF를 결합한 다변량 특징 벡터에 PCA 차원 축소를 적용하고, 이를 SVM 분류기에 입력함으로써 텍스트‑독립 스피커 검증 성능을 향상시키는 방법을 제안한다. TIMIT 데이터베이스와 다양한 잡음(SNR 0‑20 dB) 환경에서 실험한 결과, MFCC‑LSF 결합 특징이 단일 특징보다 EER을 크게 낮추었으며, 특히 PCA 적용 시 저 SNR 상황에서 EER 감소가 두드러졌다.
저자: Kawthar Yasmine Zergat, Abderrahmane Amrouche
본 논문은 텍스트‑독립 스피커 검증 시스템의 성능을 향상시키기 위해 두 가지 전통적인 음성 특징인 멜 주파수 켑스트럼 계수(MFCC)와 라인 스펙트럴 주파수(LSF)를 결합하고, 차원 축소 기법인 주성분 분석(PCA)을 적용한 후 서포트 벡터 머신(SVM) 분류기에 입력하는 전처리 파이프라인을 제안한다.
1. **배경 및 목적**
스피커 검증은 화자의 신원을 확인하기 위해 음성 신호에서 화자 고유의 특징을 추출하고, 이를 모델링·판별하는 두 단계(등록·인증)로 구성된다. 기존 연구에서는 MFCC, LPCC, PLPCC 등 단일 특징을 사용했으며, SVM은 비선형 경계 학습에 강점을 보여왔다. 그러나 단일 특징은 잡음에 취약하고, 고차원 특징 벡터는 학습 데이터가 제한될 경우 과적합 위험이 있다. 따라서 본 연구는 MFCC와 LSF를 동시에 사용해 스펙트럼 정보를 보완하고, PCA를 통해 차원을 효율적으로 감소시켜 잡음에 대한 강인성을 확보하고자 한다.
2. **특징 추출**
- **MFCC**: 사전 강조(pre‑emphasis) 필터(α=0.98) 후 25 ms Hamming 윈도우와 10 ms 오버랩으로 프레임을 나누고, FFT를 수행해 파워 스펙트럼을 얻는다. 멜 필터뱅크(삼각형 필터)로 변환 후 로그를 취하고, DCT를 적용해 12개의 켑스트럼 계수와 1개의 에너지, 그리고 1차·2차 차분(Δ, ΔΔ)까지 포함해 39차원 특징을 만든다.
- **LSF**: LPC(선형 예측 코효) 계수를 이용해 대칭·반대칭 다항식을 구성하고, 이들의 근을 구해 LSF 파라미터 12개를 추출한다. LSF는 LPC 파라미터보다 안정성이 높고, 주파수 해상도가 뛰어나 화자 구분에 유리하다.
두 특징을 결합하면 39 + 12 = 51차원 벡터가 된다.
3. **차원 축소**
고차원 벡터는 학습 복잡도와 잡음 민감도를 증가시킨다. 따라서 PCA를 적용해 공분산 행렬의 고유값을 기준으로 주요 성분을 선택한다. 실험에서는 20~30개의 주성분을 유지했으며, 이는 전체 분산의 95% 이상을 보존한다. PCA는 저분산 성분(주로 잡음에 의해 발생)을 제거해 특징의 신호‑대‑잡음 비율을 향상시킨다.
4. **분류기 설계**
SVM은 RBF 커널(kernel = exp(−γ‖x−x′‖²))을 사용해 비선형 결정 경계를 학습한다. 훈련 단계에서는 각 화자마다 긍정(본인)와 부정(다른 화자) 샘플을 라벨링해 이진 분류 모델을 만든다. 테스트 단계에서는 입력 음성의 특징 벡터를 모델에 투입해 점수를 계산하고, 사전 정의된 임계값을 초과하면 인증, 미달이면 거부한다.
5. **실험 설정**
- **데이터**: TIMIT 데이터베이스에서 90명의 화자를 선택해 각 5문장을 훈련, 3문장을 테스트에 사용하였다. 임시 화자(impostor) 50명을 동일 데이터베이스에서 추출해 부정 샘플로 활용했다.
- **노이즈 조건**: NOISEX‑92에서 추출한 Speech Babble 및 Subway 잡음을 SNR 0, 5, 10, 15, 20 dB 수준으로 합성해 테스트하였다.
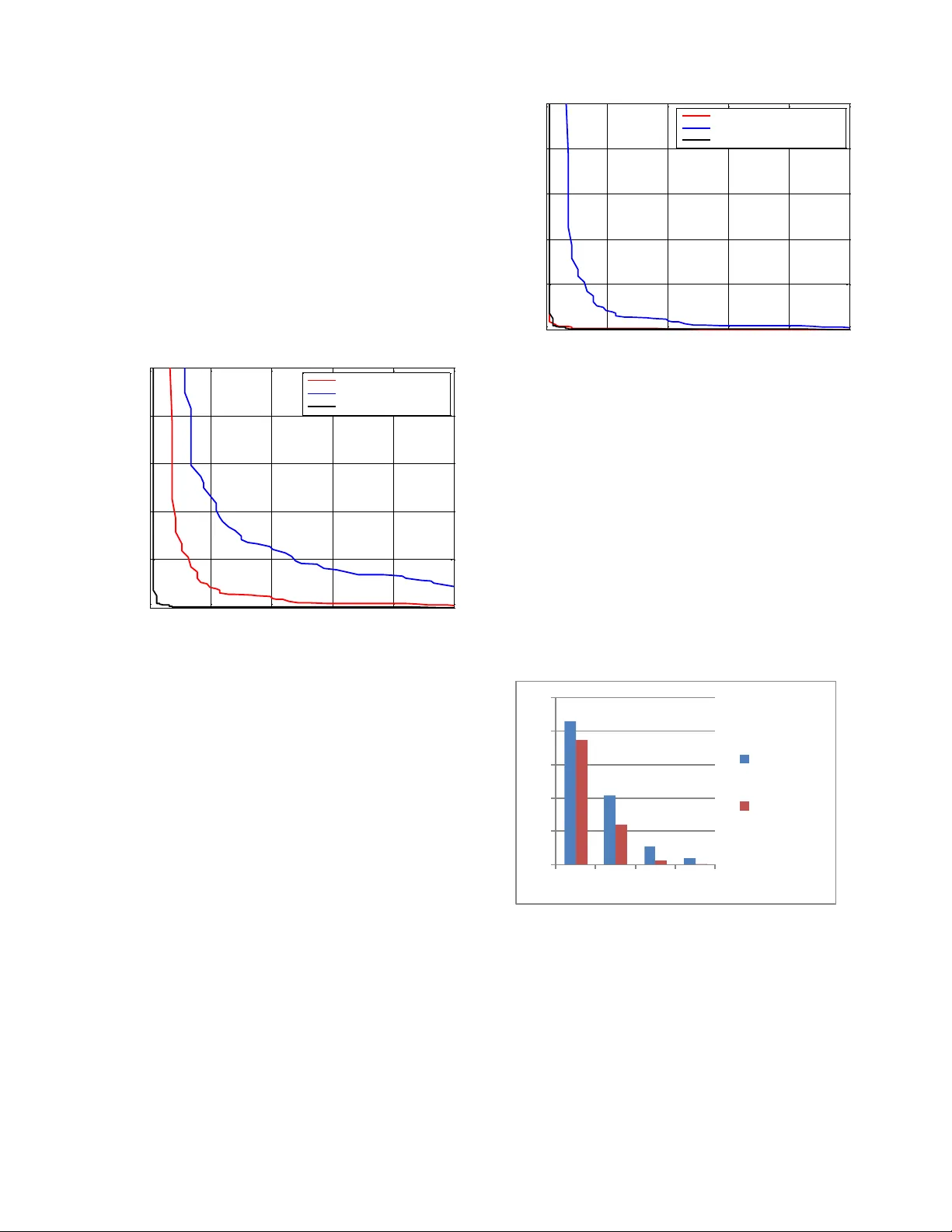
- **평가 지표**: Equal Error Rate(EER)와 Detection Error Tradeoff(DET) 곡선을 사용했다.
6. **결과**
- **청정 환경**: MFCC 단독 EER = 3.69%, LSF 단독 EER = 7.39%였으며, MFCC‑LSF 결합 시 EER = 0.54%로 크게 개선되었다. PCA 적용 후에도 비슷한 수준(EER = 0.51%)을 유지하면서 차원을 30 이하로 줄였다.
- **노이즈 환경**: Babble 잡음 0 dB에서 원본 SVM은 EER ≈ 42.87%였으나, PCA‑SVM은 37.39%로 약 5.5%p 감소했다. Subway 잡음에서도 유사한 경향을 보였으며, SNR이 높아질수록 두 모델 모두 성능이 회복되었다.
- **전반적 해석**: MFCC와 LSF의 상보적 특성 덕분에 화자 고유 정보를 풍부하게 포착했으며, PCA가 잡음에 의해 왜곡된 차원을 억제해 저 SNR 상황에서도 안정적인 판별이 가능했다.
7. **한계 및 향후 연구**
- PCA 차원 선택 기준이 경험적이며, LDA, ICA, NMF 등 다른 차원 축소 기법과의 비교가 부족하다.
- 실시간 구현을 위한 연산량 분석이 없으며, 모바일·임베디드 환경에서의 적용 가능성을 검증해야 한다.
- 잡음 종류가 제한적이므로, 실제 통신 채널 잡음, 회전 잡음 등 다양한 환경에서의 평가가 필요하다.
- 향후 연구에서는 적응형 잡음 억제, 딥러닝 기반 특징 추출(예: x‑vector)과의 융합, 그리고 다중 커널 SVM을 통한 성능 향상을 모색한다.
8. **결론**
본 논문은 MFCC와 LSF를 결합한 다변량 특징에 PCA 차원 축소를 적용하고, 이를 RBF‑SVM에 입력함으로써 텍스트‑독립 스피커 검증 시스템의 정확도를 크게 향상시켰음을 입증하였다. 특히 저 SNR의 잡음 환경에서도 EER 감소 효과가 두드러졌으며, 차원 축소를 통한 모델 경량화가 실용적인 시스템 설계에 기여한다는 점을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기