The Expressive Power of Word Embeddings
We seek to better understand the difference in quality of the several publicly released embeddings. We propose several tasks that help to distinguish the characteristics of different embeddings. Our evaluation of sentiment polarity and synonym/antony…
Authors: Yanqing Chen, Bryan Perozzi, Rami Al-Rfou
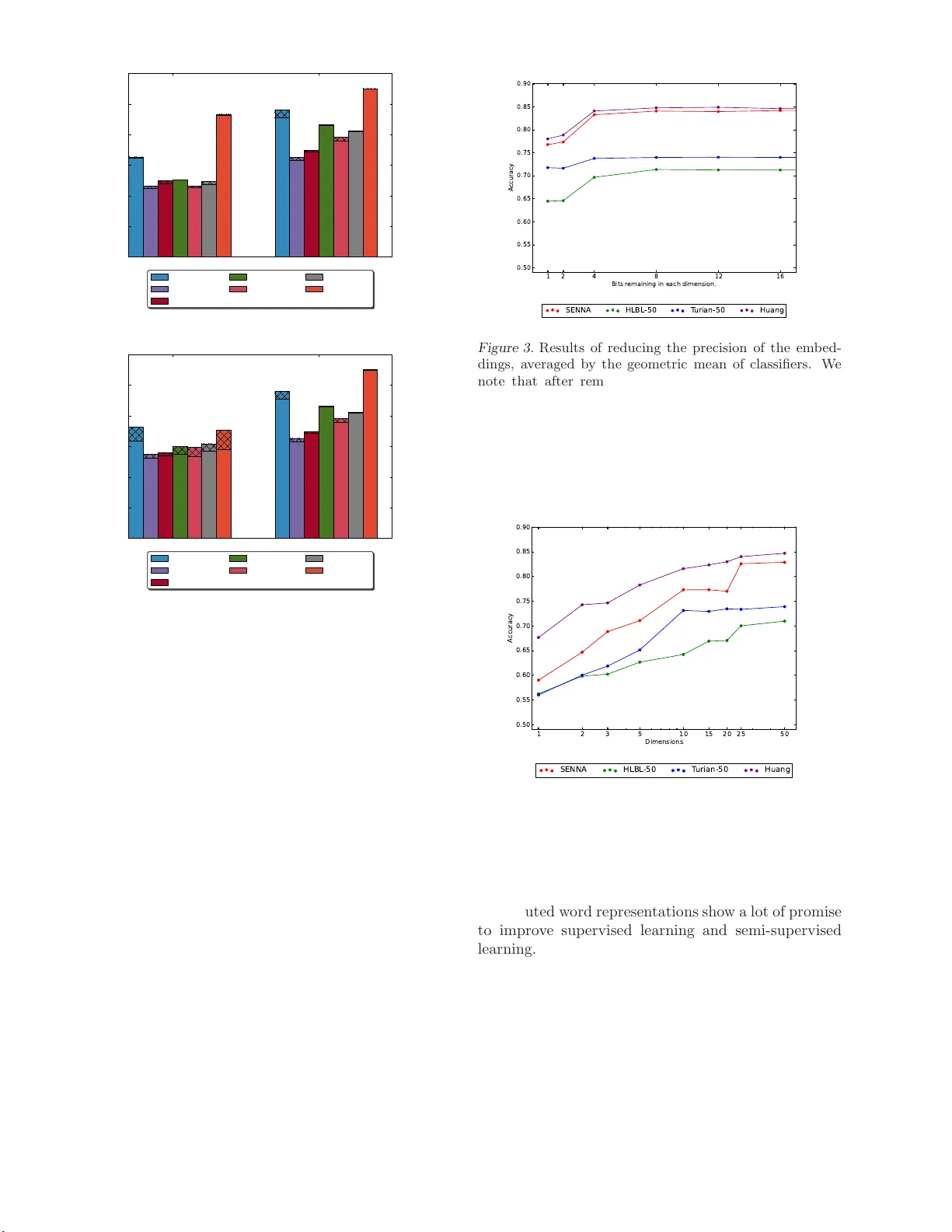
The Expressiv e P o w er of W ord Em b eddings Y anqing Chen cy anqing@cs.stonybr ook .edu Bry an P erozzi bper oz zi@cs.stonybr ook .edu Rami Al-Rfou’ ralfrou@cs.stonybr ook .edu Stev en Skiena skiena@cs.stonybrook.edu Computer Science Dept. Stony Bro ok Universit y Stony Bro ok, NY 11 794 Abstract W e seek to b etter understand the informa- tion enco ded in w or d embeddings. W e pro- po se several tasks that help to distinguish the characteristics of different publicly r eleased embeddings. O ur ev aluatio n s ho ws that em- bedding s ar e able to capture surpr isingly nu- anced semantics even in the a bs ence of sen- tence structure. Moreover, benchmarking the embeddings sho ws g reat v ariance in quality and c har acteristics o f the se ma n tics captured by the tes ted embeddings. Finally , w e show the impact o f v ary ing the n umber of dimen- sions and the r esolution of each dimension on the effective useful features captured by the embedding spa ce. Our contributions high- light the imp ortance of embeddings fo r NLP tasks and the effect of their qualit y on the final results. 1. In tro duction Distributed w ord repr esen tations (embeddings) cap- ture s eman tic and syntactic features of words out of raw text co rpus without h uma n interv ention or language dep e nden t pro cessing. The featur es em- bedding capture are tas k indep enden t which make them ideal for la ng uage mo deling. How ever, em- bedding s are ha r d to interpret and und e r stand. De- spite the efforts of vis ualizing the w o rd em b eddings ( V an der Maaten and Hinton , 2008 ), po ints in high di- mensional space s carry a lot of information that is hard to quantify . Additionally , publicly a v aila ble embed- dings generated by multiple resear ch g roups use dif- ferent data a nd training pro cedures a nd ther e is no t yet a n understanding ab out the b est wa y to learn these Pr o c e e dings of the 30 th International Confer enc e on Ma- chine L e arning , Atlanta, Georgia , USA, 20 13. JMLR: W&CP volume 28. Copyrigh t 2013 by the author(s). representations. In this paper , we in vestigate four public relea sed w o rd embeddings: (1) HLBL, (2) SENNA, (3) T urian’s and (4) Huang’s. W e use context-free cla s sification tasks rather than sequence lab eling task s (such as part of sp eec h ta g ging) to isola te the effects of context in mak- ing decisions a nd eliminate the c omplexit y of the lea r n- ing metho ds. Sp ecifically , our work ma k es the follo w- ing c on tributions: • W e show through ev alua tion that em b eddings a re able to capture semantics in the abse nc e of sen- tence structure and that there is a difference in the characteristics of the publicly released word embeddings. • W e explo re the impact of the num be r of dimen- sions and the reso lution of e a c h dimension o n the quality of the informa tio n that can b e enco ded in the embeddings space. That shows that mini- m um e ff e c tiv e space needed to capture the useful information in the embeddings. • W e demonstrate the imp ortance of word pair ori- ent a tion in enco ding useful linguistic informa tio n. W e r un t wo pair classificatio n tas k s and provide an example with one of them wher e pair pe r for- mance greatly exceeds that of individual words. The r est of the work pro ceeds as follows: Fir st we de- scrib e the word embeddings we consider. Next we dis- cuss our classifica tion exper imen ts, a nd present their results. Finally we discuss the effects o f sc a ling down the size of the embeddings space. 2. Related W ork The original work for generating w o rd embeddings was presented by Bengio et. al. in ( Bengio et al. , 2 003a ). The embeddings were a seco ndary output when g en- erating language model. Since ( Bengio et al. , 2003a ), 3 EXPERIMENT AL SETUP 2 there has been a significant in ter e st in sp e eding up the generation pro cess ( Bengio et al. , 2003 b ; 20 09 ). These original langua ge models w ere ev aluated using perplex- it y . W e argue that while p erplexity is a g oo d metric of language mo deling, it is not insightful ab out ho w well the embeddings capture diverse types of informa tion. SENNA’s embeddings ( Collob ert , 2 011 ) are gener- ated using a mo del that is discriminating a nd non- probabilistic. In eac h training up date, w e read an n-gram from the corpus, concatenating the learned embeddings of these n words. Then a cor rupted n- gram is used by replacing the word in the middle with a rando m o ne from the vo cabulary . On top of the tw o phrases, the mo del learns a scor ing function that sc ores the or iginal phrases lower than the cor- rupted one. The loss function used for training is hinge loss. ( Collob ert et al. , 2011 ) shows that embed- dings a re able to p erform well o n several NLP ta sks in the absence of any other featur es. The NLP tasks considered b y SENNA all co nsist of sequence labeling, which imply that the model mig ht learn fro m seq ue nc e depe ndencie s. Our work enriches the discussion by fo- cusing on term classifica tio n problems. In ( T urian et a l. , 2 010 ), T urian et. al. duplicated the SENNA embeddings with so me differences; they cor - rupt the last w o rd of each n-gram instead of the word in the middle. They also show that using embeddings in conjunction with typical NLP features improves the per formance on the Named Entit y Reco gnition task. An additional result o f ( T urian et al. , 20 10 ) sho ws that most of the embeddings ha ve similar effect when added to an existing NLP task. This giv e s the wrong impr es- sion. O ur work illus tr ates that not a ll embeddings are created equal and there are significa n t difference s in the information captured b y eac h publicly released mo del exist. Mnih and Hin to n ( Mnih and Hinton , 2007 ) prop osed a log-bilinear loss function to model la ng uage. Given an n-gram, the mo del c oncatenates the em b eddings of the n- 1 first w o rds, and lea rns a linear mo de l to predict the embedding of the last word. Mnih and Hinton later prop osed Hiera rc hical log- bilinear (HLBL) mo del em- bedding s ( Mnih and Hinton , 20 09 ) to sp eed up mo del ev aluation dur ing training and testing b y using a hierarchical a pproach (similar to ( Morin and Bengio , 2005 )) that prune the sear c h space for the next word by dividing the prediction into a s eries o f predictio ns that filter regio n of the space. The lang uage mo del even tually is ev aluate us ing p erplexity . A fundamental challenge for neural la nguage mo dels inv olves repr e sen ting words which have multiple mean- ings. In ( Huang et al. , 201 2 ), Huang et. al. incorp orate global context to deal with challenges raised by words with m ultiple meanings. Recent work by Mik o lo v et. al. ( Mikolo v et al. , 2013 ) inv estigates linguistic reg ularities captur ed b y the rel- ative p ositions of p oints in the embedding space. O ur results re garding pair classification are complemen- tary . 3. Exp erimen tal setup W e will construct three term cla ssification problems and tw o pair clas s ification problems to quantify the quality of the embeddings. 3.1. Ev aluation T asks Our ev aluation tasks are as follows: • Sentimen t Polarit y : W e use Lydia’s sen timent lexicon ( Go dbole et al. , 2007 ) to create sets of words which have p ositive or nega tiv e c o nnota- tions and construct the 2-class sentim e n t po la rit y test. The da ta size is 6923 w o rds. • Noun Gender : W e use Bergsma’s data set ( Bergsma and Lin , 2 006 ) to compile a list of mas- culine and feminine proper nouns. Names tha t co- refer more fr equen tly with she / he a re resp ectiv ely considered feminine/ma sculine. Strings that co- refer the most with it , a ppear less than 300 times in the co rpus, or cons ist of multiple words are ig - nored. The tota l size is 2133 words. • Plurality : W e use W o rdNet ( F ellbaum , 2010 ) to extract nouns in their singular and plural forms. The data consists of 3012 words. • Synon ym s and An tonyms : W e use W ord- Net to ex tract sy no n ym and a n tonym pair s and chec k whether we can part one kind from the others. The r elation is symmetric thus we put each word pair together with their order -rev er sed- counterparts. Ther e a re 3446 differen t word pairs. • Regi onal Sp ellings : W e collect the words that differ in sp elling b e t ween UK Eng lish a nd the America n counterpart from an online source ( Limited , 20 0 9 ). W e make this task be a pair classification task to emphasize relative distances betw e en e mbedding s. W e ha ve 1565 pairs in this task. W e ensur e that for all tas k s the cla s s lab els a re bal- anced. This allow our ba seline ev aluation to b e either 3.3 Classification 3 Sent iment Noun Gender Plurality Positiv e Negative F e minine Masculine Plural Singular Samples goo d bad Ada Steve cats cat talent stupid Ir e na Roland tab les tab le amazing flaw Linda Leonardo system s system Synonyms a nd Anton yms Regional Sp ellings Synonyms Anton yms UK US Samples store shop rear f ron t colou r color virgin pure p olite impol ite driveable driv able p ermit l icense frie nd fo e smash-up smashup T able 1. Example input from eac h task the random clas s ifier or the most frequent label clas- sifier. E ither of them will give a n accuracy of 50%. T able 1 s hows e xamples of e a c h o f the 2-clas s ev alua - tion task s. The cla ssifier is asked to iden tify which of the classes a term or pair b elongs to . 3.2. Embeddings ’ Datasets W e choos e the following publicly a v aila ble embeddings datasets for ev aluation. • SENNA’ s embeddi ngs co vers 130,000 w o rds with 50 dimensions for each word. • T uri an’s embe ddings covers 268,81 0 words, each re presen ted either with 25, 5 0 or 10 0 dimen- sions. • HLBL’s embeddi ngs cov er s 246,12 2 w o rds. These embeddings were trained o n same da ta used for T uria n e m b e dding fo r 10 0 ep ochs (7 days), a nd hav e b een induced in 50 or 10 0 dimensions. • Huang’s embe ddings cov ers 100,232 w or ds, in 50 dimensions . Huang’s embeddings require con- text to disambiguate which prototype to use fo r a word. Our tasks ar e context free s o we av erag e the multiple prototypes to a single point in the space. (This w as the appr oac h which worked b est in our testing.) It sho uld be emphasized that e ac h o f these mo dels has bee n induced under substantially different tr a ining pa- rameters. Ea ch mo del has its own vocabular y , used a different context size, a nd w a s trained for a different nu mber of ep o c hs o n its training s et. While the control of thes e v ariables is o utside the s cope of this study , we hop e to mitigate one of these c halleng e s by running our exp erimen ts o n the v o cabulary shared by all these em- bedding s. The size of this sha red vocabula ry is 58,411 words. 3.3. Classification F or class ific a tion we used Lo gistic Regr ession and a SVM with the RBF-kernel as linear and non-linear classifiers . There is a mo del-selection pro cedure by running a grid-search on the parameter space with the help o f the developmen t data. All exp erimen ts were written using the Python pack a ge Scikit- L earn ( Pedregosa et al. , 2011 ). F or the term classification tasks we offere d the classifier o nly the embedding of the word as an input. F or pair wise exper imen ts, the input consists of the embeddings of the t wo words con- catenated. The average of four folds of cr oss v alidatio n is used to ev aluate the perfor mance of each cla ssifier on eac h task. 50%, 25%, 25 % of the data ar e used, as tra in- ing, developmen t a nd testing datasets resp ectiv ely , for ev aluation and mo del selection. 4. Ev aluation Results Here we present the ev aluation of both our term and pair classificatio n results. 4.1. T erm Classification Figure 1 shows the results ov er all the 2-class term classification tasks using logis tic regression and RBF- kernel SVM. It is sur prising that a ll the embeddings we considered did muc h b etter than the baseline, even on a se emingly har d tes ts like sentimen t detection. What’s mo r e, there is stro ng perfor mance from b oth the SENNA and Huang embedding s. SENNA embed- dings seem to capture the plurality r elationship b etter, which may b e from the emphasis that the SENNA em- bedding s place on shallow s y n tactic features. Sentiment Gender Plurality 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Accuracy SENNA HLBL-50 HLBL-100 T ur ian-25 T ur ian-50 T ur ian-100 Huang Figure 1. Results of the term-based tasks considered, shaded areas represent impro vements using kernel SVM. 5 INF O RMA TION REDUCTION 4 T able 2 shows examples of words from the test datasets after clas s ifying them using logistic regres s ion on the SENNA embeddings. The top a nd b ottom r o ws show the words that the clas s ifier is confident classifying, while the rows in the middle show the words that lie close to the decision b oundary . F or example, r esilient could hav e p ositiv e and negative connota tions in text, therefore, we find it c lose to the region were the words are more neutral than b eing p olarized. F or SENNA, the b est p erforming task was the Plural- it y tas k. That explains the ob vio us contrast b et ween the proba bilities given to the w or ds. The top words are given almos t 100 % probability and the b ottom ones are given a lmost 0%. The results of regional sp e lling task is shown here in the term-wise setup. Despite not per forming as well as the pair -wise sp elling, we ca n see tha t classifier shows meaningful r esults. W e can clearly notice that the Br itish sp ellings of words fav or the usage of hyphens, s over z and l l ov er l . Positiv e Prob British Prob Sent iment w orld -famous 99.85 Regional Sp el lin g kick-off 92.37 aw ard-winning 99.83 hauliers 91.54 high-quality 99.83 re-exp orted 89.46 achiev e men t 99.81 bullet-pr o of 88.69 athletic 99.81 initialle d 88.42 resilient 50.14 paralysed 50.16 ragged 50.11 italiciz e d 50.04 discrimin ating 50.10 exorcise 50.03 stout 49.97 fusing 49.90 lose 49.83 lacklustre 49.78 b ored 49.81 subsidizin g 49.77 blo odshed 0.74 signaling 32.04 burglary 0.68 hemorrh agi c 21.69 robb ery 0.58 tumor 21.69 panic 0.45 homologue 19.53 stone-throwing 0.28 lo calize 17.50 Negative 1.0-Prob American 1.0-Prob T able 2. Examples of the results of the logistic regression classifier on different tasks. 4.2. P air Classification Sometimes how ever, the choice to use pair classifica - tion can ma k e quite a difference in the results. Fig ure 2a shows that classifying individual w or ds acco rding to their regio nal usage p erforms p o orly . W e can redefine the problem such that the clas sifier is asked to decide if the firs t w o rd, in a pa ir of words, is the American sp elling o r not. Fig ur e 2a shows that perfor mance im- prov es a lot. This hints tha t the words under this crite- ria a re not separable by a hyp er-plane in any subspace of the or iginal embeddings space. Instead, we draw a similar conclusion as ( Mikolo v et al. , 201 3 ) that the pairs’ p ositions relative to each other is what enco des such information but not their absolute co ordinates, and rela tio nship b et ween words often indicate the rel- ative difference vector b et ween cor responding p o in ts. In our pr evious Plura lit y test, the SENNA em b ed- dings significantly outper formed Huang’s. How ever in our r e gional sp elling task (whic h migh t seem s imilar), Huang’s em b eddings outper fo rm SENNA in b oth term and pair classificatio n setups. W e believe that Huang’s approach for building word proto t yp es from significant differences in context provide a significant adv antage on this task. W e note that it is surprising that neur al lang uage mo d- els may ca pture the r e lation betw een a synonym a nd anton ym. Both the languag e mo deling of HLBL a nd the w ay tha t SE NNA/T ur ian corrupted their exam- ples fav o r words that can syntactically replace each other; e.g. b ad can re pla ce go o d as easily as exc el lent can. The result of this syn ta ctic interc hang eabilit y is that b oth b ad and exc el lent are close to go o d in the embedding space. 5. Information reduction Distributed w o rd representation exis t in con tinuous space, which is quite different from co mmo n language mo deling techniques. Beside the powerful expres siv e- ness that we demonstrated previously , another key ad- v an ta ge of distributed represe ntations is their size - they r equire far less memory a nd disk storag e than other techniques. In this s e ction we seek to under- stand e xactly how m uch spa ce word em b eddings need in o rder to serve as useful features. W e also in vestigate whether the p ow erful repr esen tation that embeddings offer is a re s ult o f having real v alue co ordinates or the exp onen tial num b er of r egions which can be descr ibed using m ultiple indep endent dimensions . 5.1. Bit wi se T runcation T o r educe the r esolution o f the real num b ers that make up the em b eddings matrix. First we scale them to 32 bit int eg er v alues, then we divide the v alues by 2 b , where b is the num b er o f bits we wish to remove. Fi- nally , w e scale the v alues ba c k to lie betw een ( − 1 , 1). After this prepr ocessing we giv e the new v alues as fea- tures to our classifiers. In the extr eme c a se, when we truncate 31 bits, the v alues will b e all either { 1 , − 1 } . Figure 3 shows that when w e r emo ve 31 bits (i.e, v al- ues are { 1 , − 1 } ), the p erformance of an embedding dataset drops no more than 7%. This reduced res o- lution is equiv alent to 2 50 regions which can b e en- co ded in the new spa ce. This is still a huge resolution, but surpr isingly seems to b e sufficient at so lving the tasks w e propo sed. A na ¨ ıve approximation of this trick which may b e of interest is to simply take the the sign of the embedding v alues as the repre sen tation o f the 6 CONCLUSION 5 Spellings(term) Spellings(pair) 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Accuracy SENNA HLBL-50 HLBL-100 T ur ian-25 T ur ian-50 T ur ian-100 Huang (a) UK/US term vs. pair Synonym Spellings 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Accuracy SENNA HLBL-50 HLBL-100 T ur ian-25 T ur ian-50 T ur ian-100 Huang (b) 2-class pair results Figure 2. Results of the pair-based tests. Figure 2a sh ows the d i ff erence b et ween treating the UK/US spellings as a single word problem, or using a p ai r of emb eddings. Figure 2b sho ws th e results of the 2-class pair tests, shaded areas represent imp ro vemen ts using kernel SVM. embeddings themselves. 5.2. Principle Com ponent Analysis The bit wise trunca tion e x periment indica tes that the nu mber o f dimensions could b e a key facto r in to the per formance of the embeddings. T o experiment on this further, w e run PCA ov er the embeddings datase ts to ev aluate task p erformance on a reduced num b er of di- mensions. Fig ure 4 s hows that reducing the dimen- sions dr o ps the accura cy of the classifier s sig nifican tly across all embedding datasets . Another key difference b et ween the truncation exp er- imen t and the P CA exp erimen t is that the trunca- tion exp erimen t may preser v e rela tionships captured by non-linearities in the em b edding space. Linear PCA 1 6 1 2 8 4 2 1 Bit s r e ma in in g i n e a c h d i me n sio n . 0 . 5 0 0 .5 5 0 . 6 0 0 .6 5 0 . 7 0 0 .7 5 0 . 8 0 0 .8 5 0 . 9 0 A c c u ra c y S E N N A H L B L - 5 0 T u ri a n - 5 0 H u a n g Figure 3. Results of reducing the precision of the em b ed- dings, av eraged by th e geometric mean of classi fi ers. W e note that after removing 31 b its, eac h dimension of the em b eddings is a b in a ry feature. can not offer such g uaran tees and this weakness ma y contribute to the difference in p erformance. 1 2 3 5 1 0 1 5 2 0 2 5 5 0 Di me n si o n s 0 .5 0 0 . 5 5 0 .6 0 0 . 6 5 0 .7 0 0 . 7 5 0 .8 0 0 . 8 5 0 .9 0 A c c u r a c y S E N N A H L B L - 5 0 T u r i a n - 5 0 H u a n g Figure 4. Results of redu cing the dimensions of t he emb ed- dings through PCA, av eraged by the geometric mean. 6. Conclusion Distributed word representations show a lot of promise to impro ve sup ervised learning and semi-supe r vised learning. The pra ctical adv ant a ges of having dense representations make them ideal for industria l appli- cations and softw ar e developmen t. The pr evious w or k mainly foc us ed on sp eeding up the tra ining pr ocess with one metric for ev aluation, pe r plexit y . W e s how that this metric is not able to provide a nuanced view of their quality . W e develop a suite of linguistic or i- REFERENCES 6 ent e d tasks which might ser v e as a pa r t of a com- prehensive b enc hmar k for w o rd embedding ev aluation. The tas ks fo cus o n w or ds or pa irs of them in iso la tion to the actual text. The g oal here is not to build a useful classifier as muc h as it is to understa nd how m uch su- per vised learning can benefit from the features whic h are enco ded in the embeddings. W e succeed in showing that the publicly av aila ble datasets differ in their quality and usefulness, and our results are consistent acr oss tasks and class ifiers. O ur future w o rk will tr y to address the factor s that lead to such div ers e quality . The effect of training c o rpus s ize and the c ho ic e of the ob jective functions are tw o main areas where b etter understa nding is needed. While our tasks are simple, the differences among task per formance s hed light o n the features enco ded b y em- bedding s. W e show ed that in addition to the shallow syntactic features like plural and gender a greemen t, there are significant seman tic pa rtitions reg arding s e n- timen t and syno nym/anton ym mea ning . Our curren t tasks fo cus on nouns and adjectives, a nd the suite of tasks has to be extended to include tasks that address verbs and other parts of sp eec h. Ac knowledgm ents This resea r c h was partia lly supp orted by NSF Gra n ts DBI-1060 572 and IIS-1 017181, with a dditional sup- po rt from T exe lT ek, Inc. References Y. Bengio, R. Duc har me, P . Vincent, and C. Jauvin. A neural probabilis tic language mo del. J o u rnal of Machine L e arning R ese ar ch , 3:1137 –1155, 2 003a. Y. Bengio, J .S. Sen ´ ecal, et al. Quic k training of proba- bilistic neural nets by impor tance sampling. In AIS- T A TS Confer enc e , 200 3b. Y. Beng io, J. Louradour , R. Collob ert, and J. W es ton. Curriculum learning. In Pr o c e e dings of the 26th an- nual int ernatio n al c onfer enc e on machine le arning , pages 4 1–48. ACM, 20 09. Shane Bergsma and Dek ang Lin. Bo otstrapping path- based pronoun r esolution. In Pr o c e e dings of the 21st International Confer enc e on Computational Lin- guistics and 44th A n nual Me eting of the Asso ciation for Computational Linguistics , pag es 33 –40, Sydney , Australia, July 2 006. Asso ciation for Computational Linguistics. R. Collob ert. Deep lear ning for efficien t discriminative parsing. In In ternational Confer enc e on Artificial Intel ligenc e and Statistics (AIST A TS) , 201 1. R. Collob ert, J. W es ton, L. Bo ttou, M. Karle n, K. Kavukcuoglu, a nd P . Kuksa. Natural language pro cessing (almost) from scratch. The Journal of Machine L e arning Re s e ar ch , 1 2 :2493–253 7, 20 11, JMLR. org . C. F ellbaum. W ordnet. The ory and Applic ations of Ontolo gy: Computer Applic ations , pages 231 –243, 2010, Springer. N. Go dbole, M. Sr iniv asa iah, and S. Skiena. La rge- scale sent iment analysis for news and blogs. In Pr o- c e e dings of t he International Confer enc e on Weblo gs and S o cial Me dia (ICWSM) , volume 2 , 2007 . Eric H. Huang , Ric hard So cher, Christopher D. Man- ning, and Andrew Y. Ng. Improving word represen- tations via global context and multiple w o rd pro- totypes. In Pr o c e e dings of the 50th Annual Me et- ing of the Asso ciation for Computational Linguis- tics: L ong Pap ers - V olume 1 , ACL ’12, pages 873– 882, Stroudsburg, P A, USA, 20 12. Ass ociation for Computational Linguistics. W ords W orldwide Limited. W ord list of us/uk spelling v ariants, Ma y 200 9. URL http:/ /www.word s w orldwide.co . uk/docs/Words- Worldwide- Wor d - T omas Mik olov, W en-tau Yih, and Geoffrey Zweig. Linguistic regular ities in co n tinuous s pace word rep- resentations. In Pr o c e e dings of NAACL-HL T , 2013. A. Mnih and G. Hin ton. Three new g raphical mo dels for statistical langua ge mo delling. In Pr o c e e dings of the 24th international c onfer enc e on Machine le arn- ing , pages 641 – 648. ACM, 2007. A. Mnih and G.E. Hin ton. A scala ble hierarchical dis- tributed languag e mo del. Ad vanc es in neur al in- formation pr o c essing syst ems , 21 :1081–108 8 , 2009, Citeseer. F. Morin and Y. Bengio. Hiera r c hical probabilistic neural netw or k languag e mo del. In Pr o c e e dings of the international workshop on artificial int elligenc e and st atistics , pages 24 6–252, 2005. F. Pedregosa, G. V aro quaux, A. Gramfor t, V. Mic hel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V. Dubourg , J. V a nderplas, A. Pas- sos, D. Cournap eau, M. Brucher, M. Perrot, and E. Duc hesnay . Scikit-learn: Machine learning in Python. Journal of Machine L e arning Rese ar ch , 12 : 2825– 2830, 20 11. REFERENCES 7 J. T ur ian, L. Ratinov, a nd Y. Bengio . W o rd repre- sentations: a simple and gener al metho d for semi- sup e rvised lear ning. Urb ana , 51 :6 1801, 2010. L. V a n der Maaten and G. Hin to n. Visualizing da ta using t-sne. Journal of Ma chine L e arning Rese ar ch , 9(2579 -2605):85, 2008. SUPPLEMENT AL MA TERIALS 8 Supplemen tal Materials 3-class T es ts T o strengthen these results, w e p erformed a 3-class version of the sentimen t test, in which we ev aluated the abilit y to cla s sify words as ha ving p ositiv e, neg a- tive, or neutral sen timent v alue. The res ults a r e pre- sented in Figure 5 . T he results ar e consistent with those from our 2-lab el test, and all e m b eddings p er- form m uch higher than the baseline score of 33%. Sentiment 3-Sentment 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Accuracy SENNA HLBL-50 HLBL-100 T uri an - 25 T uri an - 50 T uri an - 10 0 Huang Figure 5. The p erformance on the 3-class version of the senti m ent task, shaded areas represen t impro vemen ts u si n g kernel SVM. In or der to inv e s tigate the depth to which synonyms and anton yms ar e c a ptured, we conducted a 3-cla ss version of the same test. W e now ev alua te betw ee n pairs of w ords that are synon y ms, anton yms, or hav e no suc h relation. While such a task is muc h ha rder for the embeddings, the results in Figure 6 s ho w that a nonlinear c la ssifier can ca ptur e the re la tionship, par- ticularly with the SENNA embeddings. An analy- sis of the confusion matrix for the nonlinear SVM show ed that error s o ccurred roughly evenly b et ween the cla s ses. W e b eliev e that this finding regarding the enco ding of synonym/anton ym relationships is an in- teresting contribution of our work. Dimensio nal Reduction by task Lo oking at Figure 8a , reducing the words em b eddings to p oint s on a real line almo st deletes all the fea tures that are relev ant to the pair classification and to les s a degree the s e ntimen t features . Despite the 10%-20% drop in ac c ur acy in the Plurality and Gender tasks, the classification is still higher than ra ndom. The re- sults show that when tha t sha llo w sy n tactic features such as gender and num b er agr eemen t a re preserved at Synonym 3-Synonym 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Accuracy SENNA HLBL-50 HLBL-100 T uri an - 25 T uri an - 50 T uri an - 10 0 Huang Figure 6. The performance of the 3-class syn- onym/an tonym task, shaded areas represent improv ements using kernel S V M. 1 6 1 2 8 4 2 1 Bits r e ma in in g in e a c h d ime n sio n . 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 0 . 9 0 A c c u ra c y S p e l l i n g s S y n o n y m G e n d e r P l u r a l S e n t i m e n t Figure 7. Results of reducing the precision of the em b ed- dings, a veraged b y the geometric mean of classifiers across- ing tasks the exp ense of more subtle semantic features such as sentimen t p olarity . This gives us insight into what the hierarchical structure of the embeddings space lo oks like. Shallow semantic features a re present in all as- pec ts o f the spa c e, a nd when PCA choo ses to maximize this v ariance of the feature spa ce it is at the e xpense of the other semantic prop erties. W e als o illustra te this phenomenon in Figure 8b , by showing how the p erformance of the linear and non- linear cla ssifiers conv erge for our ha rder tasks (senti- men t and synonym) as we reduce the num b er of di- mensions with PCA. SUPPLEMENT AL MA TERIALS 9 1 2 3 5 1 0 1 5 2 0 2 5 5 0 Di m e n si o n s 0 . 5 0 0 .5 5 0 . 6 0 0 .6 5 0 . 7 0 0 .7 5 0 . 8 0 0 .8 5 0 . 9 0 A c cu r a cy S p e l l i n g s S y n o n y m G e n d e r P l u r a l S e n ti m e n t (a) By task 1 2 3 5 10 1 5 2 0 2 5 50 Dim e n sio ns 0 .5 0 0 .5 5 0 .6 0 0 .6 5 0 .7 0 0 .7 5 0 .8 0 0 .8 5 0 .9 0 A c c urac y S y n o n y m (R B F) P l u ra l (R B F) S en t i m en t (R B F) S y n o n y m (l i n ea r) P l u ra l (l i n ea r) S en t i m e n t (l i n e a r) (b) Linear vs. Nonlinear Figure 8. Results of reducing the dimensions of the em b eddings through PCA, av eraged by the geometric mean acro ss tasks ( 8a ). Figure 8b shows the difference b etw een linear (dashed) and non-linear (solid) classifiers for our harder tasks (sentimen t and synonym) and an easy task (p lural ). The p erformance of the linear and nonlinear classifiers conv erges as PCA remo ves more dimensions. This results in significantly degraded performance on nuanced tasks like sentimen t analysis. This figure "bit_reduction_by_embedding_after_normalization.png" is available in "p ng" format from: This figure "bit_reduction_by_task_after_normalization.png" is available in "png" for mat from:
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment