단어 임베딩의 표현력
본 논문은 공개된 네 종류의 단어 임베딩(HLBL, SENNA, Turian, Huang)을 다양한 2‑클래스 분류 및 쌍 분류 과제에 적용해 품질을 비교한다. 감성 polarity, 명사 성별, 복수형, 동의·반의어, 영국·미국 철자 차이 등 5개의 과제를 통해 임베딩이 문맥 없이도 의미를 포착함을 보였으며, 차원 수와 각 차원의 해상도가 성능에 미치는 영향을 실험한다. 결과는 임베딩마다 포착하는 의미가 다르고, 최소 50‑100 차원, 2‑…
저자: Yanqing Chen, Bryan Perozzi, Rami Al-Rfou
본 논문은 “The Expressive Power of Word Embeddings”라는 제목으로, 공개된 네 종류의 단어 임베딩(HLBL, SENNA, Turian, Huang)의 표현력을 체계적으로 평가한다. 연구 동기는 다양한 데이터와 학습 방식으로 생성된 임베딩이 실제 NLP 작업에서 얼마나 차별화된 의미 정보를 제공하는지, 그리고 차원 수와 각 차원의 해상도가 성능에 어떤 영향을 미치는지를 규명하고자 함에 있다.
먼저 5개의 평가 과제를 정의한다. (1) 감성 polarity: Lydia’s sentiment lexicon을 이용해 긍정·부정 단어 6,923개를 2‑클래스 분류한다. (2) 명사 성별: Bergsma & Lin 데이터에서 남·여 고유명사를 2,133개 선정한다. (3) 복수형: WordNet에서 단수·복수 형태의 명사 3,012개를 사용한다. (4) 동의·반의어: WordNet에서 3,446쌍을 추출해 동의어와 반의어를 구분한다. (5) 영국·미국 철자 차이: 온라인 자료에서 1,565쌍을 수집해 지역 철자 변형을 다룬다. 모든 과제는 라벨이 균형을 이루도록 전처리하였다.
임베딩 데이터는 각각 다음과 같다. SENNA는 130k 단어를 50 차원, Turian은 268,810 단어를 25·50·100 차원, HLBL은 246,122 단어를 50·100 차원, Huang은 100,232 단어를 50 차원으로 제공한다. 각 임베딩은 서로 다른 코퍼스, 컨텍스트 윈도우, 학습 에포크 등을 사용했으며, 연구자는 공유 어휘(58,411 단어)만을 대상으로 실험을 진행했다.
분류 모델은 로지스틱 회귀와 RBF‑커널 SVM을 사용했으며, 하이퍼파라미터는 개발 데이터로 그리드 서치를 수행했다. 단어 수준 과제에서는 각 단어의 임베딩 벡터만을 입력으로, 쌍 수준 과제에서는 두 단어 임베딩을 연결(concatenate)한 2배 차원의 벡터를 입력으로 사용했다. 4‑폴드 교차 검증을 통해 평균 정확도를 측정했으며, 데이터는 50% 훈련, 25% 개발, 25% 테스트 비율로 나누었다.
실험 결과, 모든 임베딩이 베이스라인(무작위 혹은 가장 빈도 라벨)보다 현저히 높은 정확도를 보였다. 특히 SENNA와 Huang 임베딩은 감성 및 복수형 과제에서 0.9에 가까운 정확도를 기록했으며, HLBL은 전반적으로 중간 수준의 성능을 보였다. 영국·미국 철자 차이와 같은 지역 변형 과제에서는 단어 자체를 분류할 때보다 쌍으로 판단할 때 정확도가 크게 상승했으며, 이는 절대 좌표보다는 두 벡터 간 상대적 차이가 의미 정보를 전달한다는 것을 의미한다.
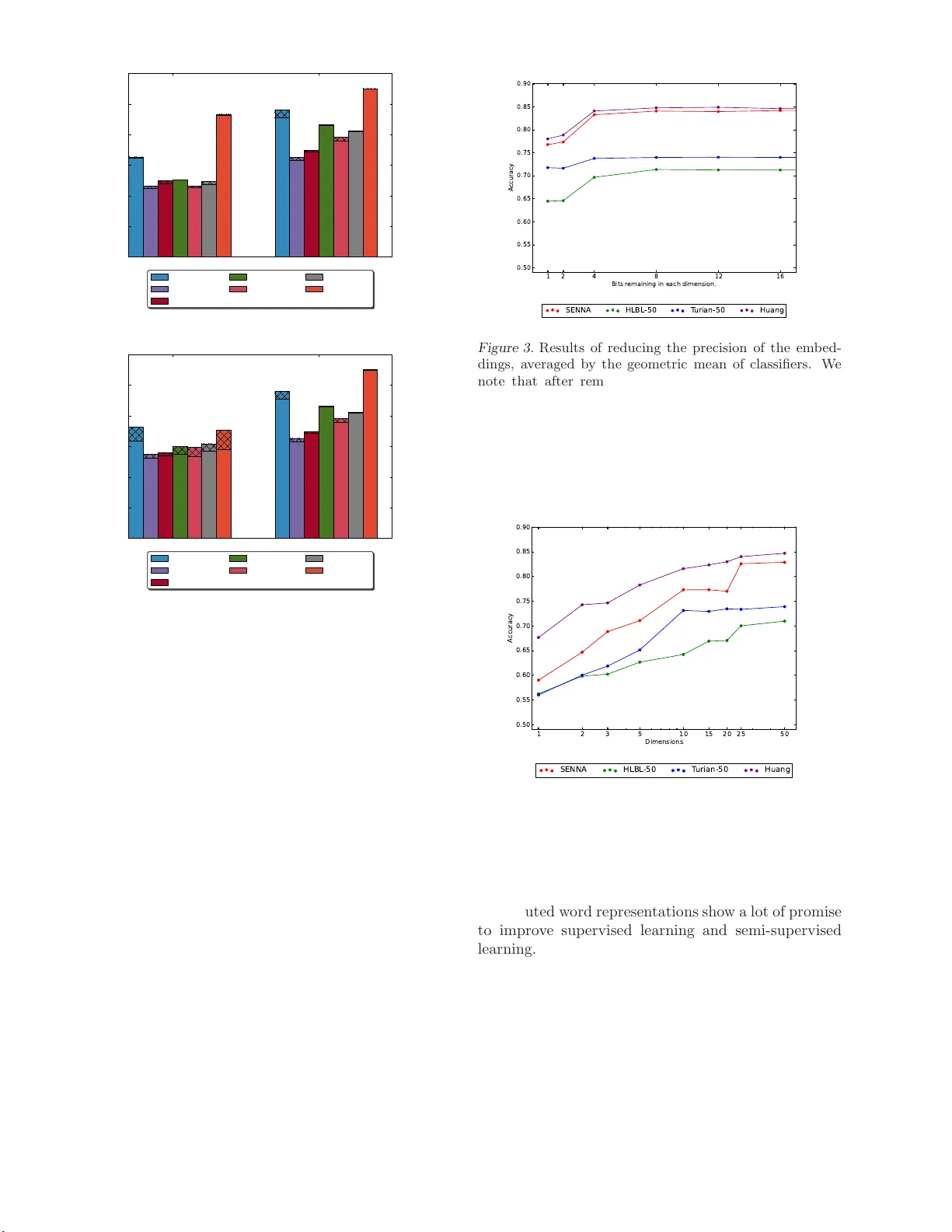
다음으로 차원 수와 정밀도에 대한 두 가지 축소 실험을 수행했다. 비트 트렁케이션 실험에서는 임베딩 값을 32‑bit 정수로 스케일링한 뒤, 원하는 비트 수만큼 오른쪽 시프트하여 정밀도를 낮추었다. 31비트를 제거해 각 차원을 {+1, -1} 이진값으로 만든 경우에도 전체 정확도 감소가 7% 이하에 머물렀다. 이는 임베딩이 실제로는 고해상도 실수값보다 부호와 같은 거친 정보만으로도 충분히 의미 구분을 수행함을 보여준다. 반면, 주성분 분석(PCA)으로 차원을 선형적으로 축소하면 정확도가 급격히 떨어졌으며, 이는 비선형 구조가 의미 관계를 유지하는 데 핵심적임을 시사한다.
결론적으로, 단어 임베딩은 문맥이 없는 상황에서도 의미를 효과적으로 포착한다는 점을 확인했으며, 임베딩마다 강조하는 의미 영역이 다르다는 점을 실험적으로 입증했다. 또한 최소 50‑100 차원과 2‑3 비트 정밀도만으로도 대부분의 평가 과제를 해결할 수 있음을 보여, 메모리·연산 효율성을 고려한 차원·정밀도 축소가 실용적임을 제시한다. 이러한 결과는 NLP 시스템 설계 시 임베딩 선택과 차원·정밀도 조절이 작업 특성에 맞게 최적화될 필요가 있음을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기