Finding Non-overlapping Clusters for Generalized Inference Over Graphical Models
Graphical models use graphs to compactly capture stochastic dependencies amongst a collection of random variables. Inference over graphical models corresponds to finding marginal probability distributions given joint probability distributions. In gen…
Authors: Divyanshu Vats, Jose M. F. Moura
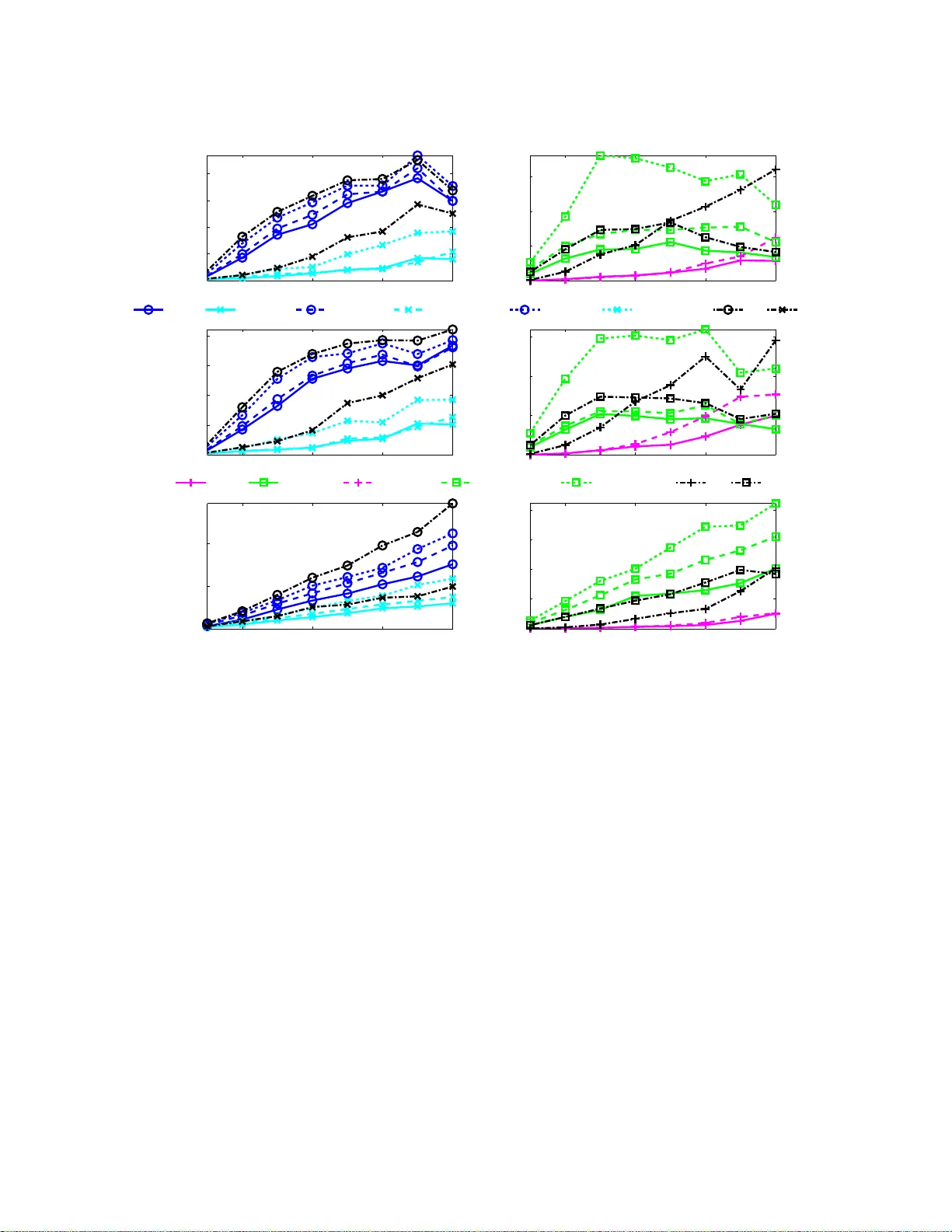
1 Finding Non-o v erla pping Clusters for Generaliz ed Inference Over Gra phical Models Divyanshu V ats and Jos ´ e M. F . Moura Abstract Graphical models use graphs to compactly capture stochastic dependencies amongst a collection of random v ariables. Inferen ce ov er graph ical models cor respond s to finding marginal proba bility distribu- tions giv en joint pr obability d istributions. I n gene ral, th is is comp utationally intractable, which has led to a quest for finding efficient approxim ate inf erence algor ithms. W e pro pose a framework for gener alized inference over graphical models that can be u sed as a wr apper for imp roving the estimates of app roximate inference algorithm s. Instead of apply ing an inf erence alg orithm to th e original grap h, we apply the inference alg orithm to a block-gr aph, d efined as a graph in which the nodes are n on-overlapping clu sters of nodes from the original graph. This results in marginal estimates of a cluster of nodes, which we further marginalize to get the marginal estimates of each node . Our prop osed block- graph con struction algorith m is simple, efficient, an d motiv ated by the observation that app roximate inference is more accura te on graphs with lon ger cycles. W e pr esent extensiv e nume rical simu lations that illustra te our block -graph framework with a variety of inferen ce algor ithms (e.g., those in th e lib D AI software pack age). These simulations show the improvements provided by o ur fr amew ork. Index T erms Graphical Models, Markov R andom Fields, Belief Propaga tion, Generalized Belief Propag ation, Approx imate Inference, Block-Trees, Block-Graphs. Divy anshu V ats is with the In stitute for Mathe matics an d i ts Applications, University of Minnesota - T win Citi es, Minneapolis, MN, 55 455, USA (email: dvats@ima.umn .edu) Jos ´ e M. F . Moura is wit h the Department of Electrical and Computer E ngineering, Carnegie Mellon University , P ittsbur gh, P A, 15213, USA (email: moura@ece.cmu.edu, ph: ( 412)-268 -6341, fax: (412)-26 8-3980). 2 Alg ( p ( x ) , G ) { b p s ( x s ) } Alg { b p V i ( x V i ) } Block-Graph ( p ( x ) , G ) Process ( p ( x ) , G ) { b p s ( x s ) } Generalized Alg Fig. 1. Alg is an inferenc e algorithm that esti mates marginal distributions given a graphical model. W e propose a frame work that gen eralizes Alg using block -graphs to improve the accuracy of t he marginal estimates. I . I N T R O D U C T I O N A graphical mode l is a prob ability distribution de fined on a g raph suc h that each node repres ents a random variable (or multiple ran dom variables), a nd edges in the g raph rep resent c onditional independen- cies 1 . The underlying graph structure in a graphical model leads to a factorization of the joint probability distrib ution. Grap hical models a re used in many applications suc h as s ensor networks, image processing , computer vision, bioinformatics, speech proce ssing, social ne twork analysis, an d ec ology [1]–[3], to name a few . Inferenc e over graphical models corresp onds to finding the marginal distribution p s ( x s ) for ea ch random variable given t he joint probability distrib ution p ( x ) . It is well known that inferenc e ov er graphical models is c omputationally tractab le for only a small c lass of graphical models (graph s with low treewidth [4]), which has le d to much work to deri ve e f ficient a pproximate inference algo rithms. A. Summary of C ontributions Our main c ontrib ution in this pape r is a framew ork that can be used as a wrapper for improving the accuracy of a pproximate inferen ce algorithms. Instead of app lying an inferenc e algorithm to the original graph, we apply the inference a lgorithm to a b lock-graph, defined as a graph in which the nodes are n on-overlapping cluste rs of nod es from the original graph. Th is results in marginal e stimates of a clus ter of nodes of the original g raph, which we further mar ginalize to ge t the marginal estimates of ea ch node. L arger clus ters, in g eneral, lead to more accurate inferenc e algorithms at the c ost of increased computational co mplexity . Fig. 1 i llustrates our p roposed block-graph framework for generalized infer ence . 1 In a graphical model ov er a graph G , for each edge ( i, j ) / ∈ G , X i is conditionally independent of X j gi ven X V \{ i,j } , where V index es all the nodes in the graph. W e can also say that for each ( i, j ) ∈ G , X i is dependent on X j gi ven X S , for all S such that S ⊆ V \{ i, j } . 3 The key co mponent in our framew ork is to construct a block -graph. It has been e mpirically o bserved that app roximate inference is more a ccurate on grap hs with long er cycles [5]. This mo ti v ates our propos ed block-graph co nstruction algorithm wh ere we first find no n-overlapping c lusters suc h that the grap h over the clusters is a tree. W e refer to the resu lting block-graph as a b lock-tree. The block-tree cons truction algorithm runs in linear time b y using two passe s of breadth-first s earch over the graph . The se cond step in our block -graph cons truction algorithm is to split large clusters 2 in the bloc k-tree. Using numerica l simulations, we show how our proposed algorithm for splitting large clusters leads to superior inference algorithms when compa red to an algorithm that randomly sp lits large clusters in the bloc k-tree and an algorithm that u ses grap h p artitioning to find non-overlapping clusters [6]. As an examp le, cons ider a pplying our block-graph framework to be lief propaga tion (BP) [7], which finds the mar ginal distributi on a t eac h n ode by iterativ ely pass ing me ssage s betwee n nodes. If the graph is a tree, BP compu tes the exact ma r ginal distrib utions, howev er , for general graphs with cycles, BP only approximates the true marginal distrib ution. Ou r frame work for inference (see Fig. 1) ge neralizes BP so that messa ge passing oc curs between c lusters of nodes , where the clusters a re non-overlapping. The estimates o f the ma r ginal distribution a t ea ch no de ca n be computed by mar ginalizing the approx imate marginal distrib ution of e ach clus ter . Our framework is no t limited to BP and can be used as a wrap per for any inferen ce algo rithm on graphica l models a s we show in Section V. Using numerical simulations, we show how our block -graph framework improves the ma r ginal d istrib ution e stimates co mputed by current inference a lgorithms in the literature: BP [7], c onditioned belief propagation (CBP) [8], loop corrected belief propa gation (LC) [9], [10], tree-structured expectation p ropagation (TreeEP), iterati ve join-graph propagation (IJGP) [11], and gene ralized belief propag ation (GBP) [12]–[15]. B. Related W ork There has been sign ificant work in extending the BP algorithm of me ssage pa ssing be tween nod es to messag e pass ing be tween clusters. It is known that the true marginal distrib utions of a grap hical model minimize the Gibbs free en ergy [16 ]. In [12], [17], the au thors show that the fixed p oints of the BP algorithm minimize the Bethe free energy , which is an approximation to the Gibbs free energy . Th is moti vated the generalized belief propa gation (GBP) algorithm that minimizes the Kikuch i free energy [18], a better approximation to the Gibbs free ene r gy . In G BP , mes sage passing is be tween clus ters of nodes that are overlapping. A more gen eral approac h to GBP is proposed in [14] using region graphs 2 For discrete graphical models, the complexity of inferenc e is ex ponential in the maximum cluster size, which is why using the blo ck-tree directly for inference may no t be computationally tractable if the maximum cluster size is large. 4 and in [15] using the cluster variation metho d (CVM). Reference s [19], [20 ] p ropose so me gu idelines for c hoosing clusters in GBP . Re ference [11] proposes a framework for GBP , called iterati ve join-graph propagation (IJGP), tha t first constructs a junction tree, a tree-structured represe ntation of a graph with overlapping clus ters, a nd then splits larger clus ters in the junction tree to p erform mess age pa ssing over a set o f overlapping clusters . In the o riginal pape r describing GBP [17 ], the authors gi ve an example of h ow non-ov erlapping clusters can be used for GBP , since, when applying the block-graph framew ork to BP , the resulting inference algorithm (B m -BP , wh ere m is the cluster s ize) be comes a class o f GBP algorithms whe re the set of overlapping clusters correspo nds to cliques in the block-graph. Our numerical simulations identify cases where B m -BP leads to superior mar ginal estimates when compared to a GBP algorithm tha t uses overlapping c lusters. Moreover , since our fr amew ork can be applied to any inference algorit hm, we show that the ma r ginal es timates computed by GBP base d algo rithms can be improved by a pplying the GBP based algo rithm to a bloc k-graph. Our block-graph frame work is n ot limited to generalizing BP and we show this in our numerical simulations where we gene ralize cond itioned belief propa gation (CBP) and loop co rrected belief prop agation (LC). Both these algorithms have been shown to emp irically perform better than GBP for certain graphical models [8], [10]. In [6], [21], the authors propose using graph partitioning algo rithms for finding n on-overlapping clusters for ge neralizing the mean field algorithm for inference [16]. Our nu merical results sh ow that our algorithm for finding non-overlapping clusters leads to superior ma r ginal estimates. W e note that ou r work differs from so me other works o n studying g raphical models defined over graphs with n on-overlapping clusters. For example, [22] cons ider the p roblem of learning a Gaussian grap hical model defined over some block-graph. Simi lar efforts hav e been made in [23] for discrete valued graphical models. In [24], the author an alyzes properties of a graph ical model defined on a block-tree. In all of the above w orks, the und erlying graphical model is assu med to be block -structured. In our work, we assu me a graphical model defined on an arb itrary graph and then find a representation of the graphica l mode l on a block-graph to en able more acc urate inference algorithms. This paper is motiv ated by our ea rlier work in study ing tree s tructures for Markov random fields (MRFs) indexed over c ontinuous ind ices [25]. In [26 ], we have shown that a natural tree-like represen- tation for such MRFs exists over n on-overlapping hy persurface s within the co ntinuous index set. Using this repres entation, we de ri ved extension s o f the Kalman -Bucy filter [27] a nd the Rauch-T ung-Striebel smoother [28] to Ga ussian MRFs indexed over continuou s indices. 5 x 3 x 9 x 1 x 4 x 2 x 5 x 6 x 7 x 8 A B C Fig. 2. An example of a graphical mod el. T he global Marko v property states that x A is independent of x C gi ven x B since all paths from A to C pass through B . C. P ap er Organization Section II revie ws grap hical models and the inference problem. Section III outlines ou r proposed algorithm for constructing block-trees, a tree-structured graph over non-overlapping clusters . Section IV presents our algo rithm for splitting larger clusters in a block-tree to c onstruct a block-graph . Se ction V outlines our block-grap h framew ork for genera lizing inference algorithms. S ection VI presents extensiv e numerical resu lts ev aluating our frame work on various inference algorithms. Se ction VII s ummarizes the paper and outlines s ome future res earch directions . I I . B A C K G R O U N D : G R A P H I C A L M O D E L S A N D I N F E R E N C E A gra phical mode l is defined using a graph G = ( V , E ) , whe re the n odes V = { 1 , 2 , . . . , p } index a collection o f random variables x = { x s ∈ Ω d : s ∈ V } and the edges E ⊆ V × V encode statistical independ encies [3], [29]. T he set of ed ges c an be directed, undirected , or b oth. Sinc e directed g raphical models, also known as Baye sian networks, can be map ped to undirected graph ical models by moralizing the graph , in this pa per , we on ly cons ider undirected graphica l models, also known as Markov random fields or Ma rkov networks. The edge s in a grap hical model imply Markov properties ab out the co llection of rand om variables. The local Markov property states that x s is indep endent of { x r : r ∈ V \{N ( s ) ∪ s }} gi ven x N ( s ) , where N ( s ) is the set of ne ighbors of s . For example, in Fig. 2, x 2 is indepe ndent of { x 3 , x 6 , x 7 , x 8 , x 9 } giv en { x 1 , x 4 , x 5 } . T he g lobal Markov pr operty , which is e quiv alent to the local Markov prope rty for non-degenerate prob ability distrib utions, states that, for a collection of disjoint nodes A , B , a nd C , if B separates A and C , x A is indepe ndent of x C giv en x B . An exa mple of the se ts A , B , and C is shown in Fig. 2. From the Hammersle y-Clif for d theorem [30], the Markov prope rty leads to a factorization o f 6 the joint p robability distrib ution over c liques (fully conn ected subs ets of nodes ) in the graph, p ( x 1 , x 2 , . . . , x p ) = 1 Z Y C ∈C ψ C ( x C ) , (1) where C is the s et of all cliques in the grap h G = ( V , E ) , ψ C ( x C ) > 0 are potential functions de fined over cliques, a nd Z is the partition fun ction, a n ormalization co nstant. Inference in g raphical models correspo nds to finding marginal distrib utions, say p s ( x s ) , given the probability distrib ution p ( x ) for x = { x 1 , . . . , x p } . This p roblem is of extreme importance in ma ny domains. A classical example is in estimation when we are given no isy observations y of x a nd we want to es timate the un derlying rando m vector . T o find the minimum mean square error (mmse ) estimate, we need to marginalize the conditional proba bility distribution p ( x | y ) to find the marginals p s ( x s | y ) . An algorithm for mar ginalizing p ( x ) ca n be use d for marginalizing p ( x | y ) . In genera l, exac t inference is computationally intractab le, however , there h as b een sign ificant p rogress in deri ving efficient approx imate inference algo rithms. The main contribution in this pa per is the bloc k-graph framew ork for g eneralizing inference algorithms (see Fig. 1) so that the performance of a pproximate inference algorithms can be improved. I I I . B L O C K - T R E E S : F I N D I N G T R E E S O V E R N O N - OV E R L A P P I N G C L U S T E R S Section III-A outlines o ur algorithm for cons tructing bloc k-trees. Se ction III-B defines the notion o f optimal bloc k-trees by using c onnections betwee n block-trees a nd junc tion trees. S ection III-C outlines greedy a lgorithms for finding optimal block-trees . A. Main Algorithm Definition 1 (Block-Graph and Block-T r ee): For a graph G = ( V , E ) , a block-graph G = ( V , E ) is a graph over clusters o f n odes in V suc h that each node in V is a ssociated with only o ne cluster in V . In other words, the c lusters in V are no n-overlapping. If the e dge s et E ⊆ V × V is tree-structured , we call the block-graph a block-tr ee . Algorithm 1 outlines o ur construction of a bloc k-tree G g i ven an a rbitrary grap h G = ( V , E ) . W ithout loss in g enerality , we ass ume tha t G is connec ted, i.e., there exists a path between a ll n on adjacent n odes. The original graph G and a set of nodes V 1 ⊂ V are the input. The output is the block -tree G . W e refer to V 1 as the r oot clus ter . The a lgorithm first find s a n initial set of clusters and then sp lits the se c lusters to find the fi nal bloc k-tree. W e explain the steps of the algorithm. 7 Forward step : Find c lusters V 1 , V 2 , . . . , V r using b readth-first s earch (BFS) s o that V 2 = N ( V 1 ) , V 3 = N ( V 2 ) \{ V 1 ∪ V 2 } , . . . , V r = N ( V r ) \{ V r − 2 ∪ V r − 1 } . These clusters serve a s initi al clusters for the block- tree. Du ring the BFS s tep, split ea ch clus ter V k into its co nnected c omponents { V 1 k , . . . , V m k k } using the subgraph G ( V k ) , which denotes the grap h on ly over the nodes in V k (Line 2). Backward s step : W e now merge the c lusters in each V k to fin d the final b lock-tree. The key intuition in this step is that each cluster V k should be connected to a single c luster in V k − 1 . If this is not the c ase, we merge clusters in V k − 1 accordingly . Starting a t V r = { V 1 r , V 2 r , . . . , V m r r } , for each V j r , j = 1 , . . . , m r , find all clus ters C ( V j r ) in V r − 1 that are con nected to V j r (Line 6). Combine all clusters in C ( V j r ) into a single cluster and update the clusters in V j r − 1 accordingly . Repea t the above steps for all the clusters in V r − 1 , V r − 2 , . . . , V 3 . Algorithm 1 : Co nstructing Bloc k-T rees: BlockTree( G , V 1 ) Data : A g raph G = ( V , E ) and a set o f n odes V 1 . Result : A block-tree G = ( C , E ) 1 Find succ essive neighbors of V 1 to construct a se quence of r clus ters V 1 , V 2 , . . . , V r such tha t V 2 = N ( V 1 ) , V 3 = N ( V 2 ) \{ V 1 ∪ V 2 } , . . . , V r = N ( V r ) \{ V r − 2 ∪ V r − 1 } . 2 { V 1 k , . . . , V m k k } ← Find m k connec ted componen ts of V k using subgraph G ( V k ) . 3 for i = r , r − 1 , . . . 3 do 4 f or j = 1 , 2 , . . . m i do 5 C ( V j i ) ← N ( V j i ) ∩ V i − 1 ; All n odes in V i − 1 connec ted to V j i . 6 Combine C ( V j i ) into one cluster a nd u pdate V i − 1 . 7 V ← S r k =1 { V 1 k , V 2 k , . . . , V m k k } 8 E ← ed ges be tween all the clusters in V The first part of Algorithm 1 find s success i ve non-overlapping ne ighbors of the root cluster . This leads to an initial estimate of the block-tree gra ph. I n the ba ckwards step, we sp lit clusters to form a block -tree. W e illustrate Algorithm 1 with examp les. Example: Cons ider the g rid graph o f Fig. 3(a). Choos ing V 1 = { 1 } , we get the initial estimates o f the clusters as shown in Fig. 3 (a). Running the back wards step to identify the fi nal clusters (see Fig. 3(b)), we g et the block-tree in Fig. 3(c). Example: In the previous exa mple, the initial estimates of the clusters match ed the fin al estimates and the final block-tree w as a chain-structured graph. W e no w consider an e xample where the final block -tree will in fact be tree-structured. Co nsider the partial grid graph of Fig. 4(a). Ch oosing V 1 = { 7 } , we get the initial es timates of the clusters in Fig. 4(a). W e now run the bac kwards step o f the algorithm. Since V 5 = { 3 } is c onnected to 2 and 6 , C ( V 5 ) = { 2 , 6 } . Thus, { 2 , 6 } become a single c luster . W e now find 8 1 4 2 7 5 3 8 6 9 V 1 V 2 V 3 V 4 V 5 (a) 1 4 2 7 5 3 8 6 9 (b) 1 2 4 3 5 7 6 8 9 (c) Fig. 3. (a) Original estimates of th e clu sters in a g rid g raph when run ning th e fo rward pass of Algo rithm 1. (b) The final clusters after runn ing the ba ckwards pass of Algorith m 1. (c) Fina l block- tree. 7 8 4 9 5 1 6 2 3 V 1 V 2 V 3 V 4 V 5 (a) 7 8 4 9 5 1 6 2 3 (b) 7 4 8 5 9 1 2 6 3 (c) Fig. 4. (a) Origin al estimate s of the c lusters in a p artial grid when ru nning the fo rward pass of Algorithm 1. (b ) The final clusters after runn ing the ba ckwards pass of Algorith m 1. (c) Fina l block- tree. neighbors o f { 2 , 6 } in V 3 = { 9 , 5 , 1 } . It is clear that only { 9 , 5 } are conne cted to { 2 , 6 } , so { 9 , 5 } b ecome a s ingle c luster . In this way , we hav e split V 3 into two clusters: V 1 3 = { 9 , 5 } an d V 2 3 = { 1 } . Con tinuing the algorithm, we fin d the remaining clusters as shown in Fig. 4(b). The final block -tree is sh own in Fig. 4(c). The follo wing p roposition c haracterizes the time c omplexity and correctness of Algo rithm 1. Pr oposition 1: Algorithm 1 runs in time O ( | E | ) and always outputs a block-tree. Pr oof: Bo th the forward step an d the ba ckwards s tep in v olve a breadth first s earch, which has complexity O ( | E | ) . Algorithm 1 always ou tputs a b lock-tree since each c luster in V k is only connec ted to a single c luster in V k − 1 . Block-trees a re close ly related to junction trees. In the next Se ction, we explore this c onnection to define optimal b lock-trees. B. Optimal Block-T r ees Junction trees , also known as clique trees or join trees, a re tree-structured represen tations of g raphs using a set of overlapping clusters [31], [32]. The width of a graph is the maximum cardinality of a 9 1 2 4 2 4 3 5 7 3 5 7 6 8 6 8 9 (a) 7 4 8 1 4 8 5 9 4 8 2 6 5 9 3 2 6 (b) Fig. 5. (a) Junction tree for t he block-tree in Fig. 3(c) (b) Junction tree for the block -tree in Fig. 4(c) cluster in the junction tree minus on e. The tr eewidth of a grap h is the minimum width of a graph over all poss ible junction tree representations . It is well known tha t several graph related prob lems tha t are computationally intractable in general can b e solved e f ficiently when the grap h has low treewidth. For the problem of inferen ce over g raphical mo dels, [4] s howed h ow junction trees c an be used for exact inference over graph ical mod els d efined over graphs with small treewidth. Gi ven a block-tree G = ( V , E ) , an equiv alent jun ction tree represe ntation ca n be easily computed by combining all clusters conne cted alon g edges into a s ingle cluster . For exa mple, the jun ction tree representation for the bloc k-trees in Fig. 3(c) and Fig. 4(c) are g i ven in Fig. 5(a) and Fig. 5(b) , respectiv ely . Using this junction tree, we ca n deri ve e xact inference algorithms for graphical models paramete rized by block-trees. It is eas y to s ee tha t the complexity o f inference using block-trees will depend on the maximum sum of cluster sizes o f adjacent clus ters in the bloc k-tree (sinc e this will co rrespond to the width of the eq uiv a lent junction tree). Thus , an optimal block-t r ee can be d efined as a block-tree G = ( V , E ) for which max ( i,j ) ∈E ( | V i | + | V j | ) is minimized. F rom Algorithm 1, the construction of the block-tree depend s on the choice of the root cluster V 1 . Th us, fin ding an optimal block-tr e e is equiv alent to finding an optimal root cluster . This problem is computationally intractable since we need to search over all possible c ombinations o f roo t clusters V 1 . As an example illustrating how the choice of V 1 alters the block-tree, con sider finding a b lock-tree for the pa rtial grid in Fig. 4(a). In Fig. 4 (c), we cons tructed a block-tree using V 1 = { 7 } a s the roo t cluster . T he maximum sum of adjacen t c luster sizes in Fig. 4(c) is four . Instea d of choo sing V 1 = { 7 } , let V 1 = { 7 , 4 } . The initial estimate of the clus ters a re shown in Fig. 6(a). The final block -tree is shown in Fig. 6(c). Sinc e the clusters { 9 , 6 , 2 } and { 8 , 5 } are a djacent, the maximum su m of adjacen t clusters is fiv e. 10 7 4 8 5 1 9 6 2 3 V 1 V 2 V 3 V 4 (a) 7 4 8 5 1 9 6 2 3 (b) 7 4 8 5 1 9 6 2 3 (c) Fig. 6. (a) Original estimates of the clusters in the partial grid using V 1 = { 7 , 4 } as the root cluster . (b) Splitting of clusters. (c) Final block-tree. C. Gr eedy Algor ithms for F inding Optimal Block-T rees In the previous Section, we s aw that finding optimal block-trees is c omputationally intractable. In this Section, we p ropose three greedy algorithms for finding optimal block -trees that have varying d egrees of computational complexity . Minimal degree no de - Mi nDegree : In this approach , which we call Mi nDegree , we find the n ode with minimal degree and use that node a s the root cluster . Th e intuition behind this is that the minimal degree node may lead to the smallest numb er of nod es being add ed in the clusters. The c omplexity of this approach is O ( n ) , whe re n is the nu mber of nod es in the graph. The next two algorithms are ba sed on the relations hip b etween jun ction trees a nd block-trees outlined in Section III-B. Recall that for ev ery block-tree, we c an find a jun ction tree. This means that a n optimal junction tree (a junction tree with minimal width) may b e used to find an approximate optimal b lock- tree. Further , finding o ptimal junction trees correspon ds to finding optimal e limination orders in graphs [33]. Th us, we ca n ma ke use of greedy algorithms for finding op timal e limination orders to find optimal block-trees. Using an elimination order - GreedyDegree : One of the s implest algorithms for finding an approximate optimal elimination order is kn own as GreedyDegree [34], [35 ], where the elimination o rder correspo nds to the sorted list of nodes in increas ing degree. The co mplexity of GreedyDegree is O ( n log n ) sinc e we just need to sort the n odes. U sing the elimination order , we triangulate 3 the grap h to find the c liques. These c liques corresp ond to the set of c lusters in the junction tree representation. W e s earch over a constant n umber o f c liques to fi nd a n op timal root clus ter . Using a n e limination ord er - GreedyFillin : An other pop ular greedy algorithm is to find an optimal 3 A graph is triangulated if each cycle of length four or more has an edge connecting non adjacent nodes. 11 100 200 300 400 500 0 10 20 30 40 50 60 Number of nodes Width of Block−Tree Exhaustive Search MinDegree GreedyDegree GreedyFillin Fig. 7. Plot showing the performance of three different greed y heuristics for finding optimal block-trees. elimination o rder such that at each step in the triangu lation a lgorithm, we c hoose a node that adds a minimal numb er of extra ed ges in the graph . This is kn own as GreedyFillin [36] an d has polynomial complexity . Thus, GreedyFil lin is in g eneral slower than GreedyDegree , but does lead to slightly better elimination orde rs on average. T o find the block-tree, we a gain search over a cons tant number of cliques over the triangu lated grap h. W e n ow evaluate the three d if ferent g reedy algorithms, MinDegree , GreedyDegree , and GreedyFillin , for fin ding op timal bloc k-trees in F ig. 7. T o d o this, we create clusters of size k such tha t the total numbe r of nod es is n (one cluster may h av e less tha n k node s). W e then form a tree over the clus ters and a ssociate a c lique be tween two clusters co nnected to eac h other . W e then remove a c ertain fraction of edges over the graph (not the block-tree), but make s ure that the graph is still c onnec ted. By construction, the width of the graph co nstructed is at most 2 k . Fig. 7 shows the performance of Min Degree , GreedyDegree , and GreedyFillin over graph s with d if ferent n umber of nodes and diff erent values o f k . W e clearly see that both GreedyDegree and GreedyFillin comp ute widths that a re c lose to optimal. The ma in idea in this Section is that we ca n use various known algorithms for find ing o ptimal junction tree s to find optimal block-trees. D. Exact Infer ence Using Block-T r ees In the literature, exact inferenc e over graphical mod els using non-overlapping c lusters is referred to as the Pea rl’ s c lustering a lgorithm [7]. In [37] an d [38], the authors use non-overlapping clus tering for some pa rticular directed graphical mod els for an ap plication in me dical diagnos tics. F or lattices, [39]–[41] deriv e inference algorithms by scanning the lattice horizontally (or vertically). Our bloc k-tree construction algorithm provides a principled way of finding non-overlapping clusters over arbitrary grap hs. 12 Inference over graphical mod els define d on bloc k-trees can b e done by extend ing the belief prop agation (BP) algorithm [7]. The compu tational co mplexity of BP will depen d on m ax ( i,j ) ∈E ( | V i | + | V j | ) . On the other hand, the computational complexity of exact inference u sing other frame works tha t use overlapping clusters depends on the width of the g raph [4], [42]–[44], which is in g eneral less than or equal to max ( i,j ) ∈E ( | V i | + | V j | ) . T he ma in a dvantage of us ing bloc k-trees for exact inference i s tha t the complexity of cons tructing block-trees is O ( | E | ) , whereas the complexity o f co nstructing tree-de compositions for inference using frameworks that use overl apping clus ters is worse tha n O ( | E | ) [33], [44], [45]. Thus, block-trees a re suitable for exact inference over time-v arying graphical models [46 ], [47] such that the clusters in the b lock-tree a re sma ll. I V . B L O C K - G R A P H : S P L I T T I N G C L U S T E R S I N A B L O C K - T R E E In this Section, we outline a greedy a lgorithm for splitting lar ge clusters in a block-tree to form a block-graph. This is an important step in ou r propos ed framew ork (see Fig. 1) for generalizing inferenc e algorithms since we a pply the inferenc e algorithm to the bloc k-graph as oppose d to the o riginal graph. Note that we c an use t he block-tree itself for inference; ho we ver , for many graphs this is co mputationally intractable since the complexity o f inference for discrete graphical m odels using a block-tree is exponential in max ( i,j ) ∈E ( | V i | + | V j | ) . Thus, whe n the size o f one c luster in the block-tree is lar ge, exact inference using block-trees will b e c omputationally intractable 4 . W e mod ify Algorithm 1 for c onstructing bloc k-trees to co nstruct block-graph s such that all c lusters have ca rdinality a t mos t m . Step 1 . Using an initial cluster of nodes V 1 , find c lusters V 1 , V 2 , . . . , V r using breadth-first search (BFS) such that V 2 = N ( V 1 ) , V 3 = N ( V 2 ) \{ V 1 ∪ V 2 } , . . . , V r = N ( V r ) \{ V r − 2 ∪ V r − 1 } . While doing the BFS , write V k as the set of all c onnected c omponents in the s ubgraph G ( V k ) . Thus, V k is a set of clusters. Step 2 . For V r , if there exists any cluster that has cardinality g reater than m , partition those c omponen ts. Let V r = { V 1 r , V 2 r , . . . , V m r r } b e the fin al se t o f c lusters. Step 3 . Perform the next steps for each k = r − 1 , r − 2 , . . . , 1 , s tarting at k = r − 1 . Let f V k be the set of all clusters V k that have cardinality greater than m . Partition all clusters in f V k into ap propriate size clusters o f s ize a t most m . 4 Our algorithm for finding optimal block-trees uses t he junction tr ee construction algorithm, so even if max ( i,j ) ∈E ( | V i | + | V j | ) is larg e and the treewidth of the graph is small, we can detect this and use junction trees for inference . 13 1 2 3 4 5 6 7 8 (a) 1 4 2 3 5 6 7 8 (b) 1 2 3 4 5 6 7 8 (c) Fig. 8. Explaining Step 4 in the block-graph construction algo rithm. Giv en the block-graph in (a), if we merge nodes 2 and 3 , we get the block-gra ph i n (b). If we merg e nodes 3 and 4 , we get the block -graph in (c). The block-graph in (c) has just one loop. 1 2 3 4 5 6 7 (a) 3 1 2 4 5 6 7 (b) Fig. 9. (a). Ori ginal graph. (b) Block-graph represe ntation of the graph in (a). Step 4 . Mer ge the c lusters in the se t V k \ e V k . Th e idea us ed in merging clusters is tha t if two clus ters are connec ted to the sa me cluster in V k +1 , by merging these two clusters, we reduce one edge in the final block-graph. Fu rther , if tw o clusters in V k are not co nnected to the same c luster in V k +1 , we do not merge these two clus ters, s ince the numb er of edges in the final block -graph will remain the sa me. The fi nal clus ters constructed us ing the ab ove r ules is denoted as V k = { V 1 k , . . . , V m k k } . Step 5 . The block -graph is giv en by the c lusters V = { V 1 k , V 2 k , . . . , V m k k } k =1 ,...,r and the set of edge s E between clusters. The key step in the a bove a lgorithm is Step 4, where we c luster node s a ppropriately . Fig. 8 explains the intuition behind me r ging clusters with an exa mple. Su ppose, we use the block-graph c onstruction algorithm up to Step 3 and now we want to mer ge clusters in V 2 = { 2 , 3 , 4 } . If we ignore Step 4 and merge clusters randomly , we might get the block-grap h in Fig. 8(b) on merging nodes 2 and 3 . If we use Step 4, sinc e nodes 3 and 4 are conne cted to the sa me node, we merge these to get the block-graph in Fig. 8(c). Th e graph in Fig. 8(c) h as a sing le cycle with five ed ges, whereas the grap h in Fig. 8(b) has two cycles of size four and three. It has bee n ob served that inferen ce over g raphs with longer cycles is more accu rate tha n inference over graphs with s horter cycles [5]. Thu s, our propose d algorithm leads to block-graphs that are fav orable for inference . 14 V . I N F E R E N C E U S I N G B L O C K - G R A P H S Define a graphica l mod el on a graph G = ( V , E ) using a collection of p random variables x = ( x 1 , . . . , x p ) , whe re eac h x k takes values in Ω d , where d ≥ 1 . Let G = ( V , E ) be a block-graph representation of the graph G = ( V , E ) . T o deri ve inference algorithms over the bloc k-graph, we need to define appropriate potentials (or factors) asso ciated with each clique in the block-graph. This ca n be done by mapping the poten tials from the original graph to the block-graph. As an example, let G b e the graph in F ig. 9(a) a nd let the probability distributi on over G be given by p ( x ) = 1 Z ψ 1 , 2 ( x 1 , x 2 ) ψ 1 , 4 ( x 1 , x 4 ) ψ 1 , 3 ( x 1 , x 3 ) ψ 2 , 4 , 5 ( x 2 , x 4 , x 5 ) ψ 4 , 5 , 6 , 7 ( x 4 , x 5 , x 6 , x 7 ) ψ 3 , 6 ( x 3 , x 6 ) . (2) Let the c lusters in the bloc k-graph representation of G in Fig. 9 (b) be V 1 = { 1 , 2 } , V 2 = { 4 , 5 } , V 3 = { 3 } , and V 4 = { 6 , 7 } . The probability distrib ution in (2) can be writt en in terms o f the block-graph as follows: p ( x ) = 1 Z Ψ 1 , 2 ( x V 1 , x V 2 )Ψ 1 , 3 ( x V 1 , x V 3 )Ψ 2 , 4 ( x V 2 , x V 4 )Ψ 2 , 4 ( x V 2 , x V 4 ) ψ 3 , 4 ( x V 3 , x V 4 ) , (3) where Ψ 1 , 2 ( x V 1 , x V 2 ) = ψ 1 , 2 ( x 1 , x 2 ) ψ 1 , 4 ( x 1 , x 4 ) ψ 2 , 4 , 5 ( x 2 , x 4 , x 5 ) (4) Ψ 1 , 3 ( x V 1 , x V 3 ) = ψ 1 , 3 ( x 1 , x 3 ) (5) Ψ 2 , 4 ( x V 2 , x V 4 ) = ψ 4 , 5 , 6 , 7 ( x 4 , x 5 , x 6 , x 7 ) (6) Ψ 2 , 4 ( x V 3 , x V 4 ) = ψ 3 , 6 ( x 3 , x 6 ) . (7) Let Alg be an algorithm for inferen ce over graphical models. Inference over the graph G can be performed u sing Alg w ith inpu ts being the p otentials in (2). Inference over the block-graph ca n be performed us ing Alg with inp ut being the potentials in (4)-(7). T o get the ma r ginal distributions from the block-graph, we need to further marginalize the joint probab ility distribution over each cluster . Remark 1: Both the representations (2) and (3) a re eq uiv a lent, so we are not making any a pproxima- tions when pa rameterizing the g raphical mode l u sing b lock-graphs. Remark 2: There is a trade-of f in c hoosing the s ize of the clus ters in the bloc k-graph. Generally , as observed in our numerical simulations, larger c lusters lead to better estimates at the cost of more computations. Remark 3: W e prese nted the block-graph framew ork using undirec ted graphical mo dels. The results can be ea sily g eneralized to settings where the p robability distrib ution is repres ented a s a factor graph 15 [48]. V I . N U M E R I C A L S I M U L A T I O N S In this Section, we provide n umerical simulations to show how our prop osed b lock-graph framew ork for ge neralizing inferen ce algorithms can b e used to improve the performance of current approximate inference algorithms that hav e been proposed in the literature. Throug hout this Se ction, we ass ume x s ∈ {− 1 , +1 } and the proba bility distribution over x factorizes as p ( x ) = 1 Z p Y i =1 φ i ( x i ) Y ( i,j ) ∈ E ψ ij ( x i , x j ) . (8) The nod e p otentials are given by φ i ( x i ) = exp( − a i x i ) , where a i ∼ N (0 , 0 . 1) and the edge poten tials are g i ven by Repulsive (REP): ψ ij ( x i , x j ) = exp( − | b ij | x i x j ) (9) Attracti ve (A TT): ψ ij ( x i , x j ) = exp( | b ij | x i x j ) (10) Mixed (MIX): ψ ij ( x i , x j ) = exp( − b ij x i x j ) , (11) where b ij ∼ N (0 , σ ) and σ is the interac tion streng th. For distrib utions with attracti ve (repulsive) poten- tials, neighboring rand om variables are more lik ely t o take the same ( opposite) v a lue. For distributions wi th mixed potentials, some neighbors a re att racti ve, whereas some are repuls i ve. W e study se veral approximate inference algorithms tha t ha ve bee n prop osed in the literature: Belief Propa gation (BP) [7], Iterati ve J oin- Graph Propa gation (IJGP- i ) [11], Generalized Belief Propaga tion (GBP- i ) [13], [14], Conditioned Belief Propagation (CBP- l ) [8], Loop Corrected Belief Propaga tion (LC) [10], Tr ee-Structured Expec tation Propagation ( T reeEP) [49]. In IJGP- i and GBP- i , the integer i refers to the maximum size of the clusters, where the clusters in thes e algorithms are overlapping. T he clus ters in GBP- i a re selec ted by fin ding cycles of length i in the graph . In CBP- l , l is an integer that refers to the numbe r o f c lamped vari ables when performing inference: lar ger l in g eneral leads to more accurate ma r ginal estimates. W e u se the libD AI so ftware p ackage [50 ] for all the inference algorithms except for IJGP , where we use the software provided b y the authors at [51]. For an inferen ce algorithm Alg, we refer to the gene ralized inference algorithm as B m -Alg, where the m is a n integer deno ting the maximum size of the cluster in the block- graph. W e consider two types of grap hs: (i) grid graphs and (ii) rand om regular graphs, wh ere ea ch n ode in the graph has the sa me degree and the edge s are chose n randomly . Both these graphs have bee n 16 used extensiv ely in the literature for ev aluating inferen ce algorithms [8], [10]. W e comp are inferenc e algorithms using the mea n a bsolute error: Error = 1 p p X s =1 X x s ∈{− 1 , +1 } | b p s ( x s ) − p s ( x s ) | , (12) where b p s is the marginal estimate co mputed b y an a pproximate inferenc e algorit hm and p s ( x s ) is the true marginal distrib ution. T o e valuate t he compu tational complexity , we me asure the time taken in run ning the inference algorithms on a 2.66GHz Intel(R) Xeon(R) X5355 proc essor with 32 GB me mory . Sinc e a ll the approximate inference a lgorithms we considered are iterati ve a lgorithms, we s et the max imum number o f iterations to be 1000 an d stopped the inferenc e algorithm when the me an absolute dif feren ce between the new and old mar ginal es timates is less than 10 − 9 . All the c ode and graphical mod els used in the nu merical simulations can be downloaded from http://www .ima.umn.ed u/ ∼ dvats/GeneralizedInference.h tml . A. Evaluating the Block-Graph Constr uction Algorithm W e fi rst ev a luate ou r proposed algorithm for co nstructing bloc k-graphs (see Section IV) where we split large clus ters in a block-tree. Fig. 10 s hows the results of applying ou r block -graph framew ork to generalize BP , CBP , LC, and T reeEP on a 5 × 5 grid graph. W e compare our algorithm to an algorithm that randomly sp lits the c lusters in a block -tree and an algorithm proposed in [6 ] that us es graph partitioning to find n on-overlapping clusters. In Fig. 10, the solid lines correspond to our algorithm (se e legen d B2- BP), the dashe d lines co rrespond to rand om splitting o f clus ters (see legend Ran dB2-BP), and the do tted lines correspond to grap h pa rtitioning (see legen d GP-B2-BP). The results rep orted are averages over 1 00 trials. Remark 4: It is clear that the graph parti tioning approach p erforms t he w orst amongst the thr ee dif ferent algorithms (the do tted line is a bove the solid and dashe d line). For T reeEP , we obs erve that the graph partitioning a pproach performs worse than the original algorithm tha t d oes not us e block-graph s. This sugges ts that the graph partitioning a lgorithm in [6] is n ot su itable for the inference algo rithms cons idered in Fig. 10. W e did not apply the g raph partitioning algorithm to LC since the co rresponding inferenc e algorithm was very s low . Remark 5: In most cas es, our proposed algorithm for con structing b lock-graphs performs better than using an a lgorithm that rand omly s plits clusters (the so lid line is below the dashe d line). Interestingly , for T reeEP , the random algorithm pe rforms worse than the original algorithm. W e a lso o bserved that both the random algorithm a nd the graph partitioning algorithm took more time tha n our propo sed a lgorithm. This 17 0.5 1 1.5 2 0 0.1 0.2 0.3 0.4 Error 0.5 1 1.5 2 0.02 0.04 0.06 0.5 1 1.5 2 0 0.1 0.2 0.3 0.4 Error 0.5 1 1.5 2 0.02 0.04 0.06 0.5 1 1.5 2 0 0.1 0.2 Error Interaction Strength 0.5 1 1.5 2 0.02 0.04 0.06 0.08 Interaction Strength B2−BP B2−CBP−2 RandB2−BP RandB2−CBP−2 GP−B2−BP GP−B2−CBP−2 BP CBP−2 B2−LC B2−TreeEP RandB2−LC RandB2−TreeEP GP−B2−TreeEP LC TreeEP Fig. 10. Eva luating the block-graph construction algorithm in Section IV on a 5 × 5 grid graph. The solid lines, denoted by B m -Alg f or an inferen ce algorithm Alg, correspond to using our prop osed block-graph construction algo rithm. The dashed lines correspond to an inference algorithm that randomly splits larger clusters in a block-tree. The dotted lines correspond to an i nference algorithm that uses grap h partit ioning to find clusters. The plots in the t op, mi ddle, and bottom row correspond to repulsi ve, att ractiv e, and mixed potentials, respectiv ely . sugges ts that our prop osed block-graph cons truction algo rithm leads to block-grap hs that are fav orable for inferen ce. B. Grid Graphs T a bles I, II, III , IV, and V sh ow resu lts of applying the bloc k-graph framew ork for inference over graphical models defined on grid graph s. Remark 6: In gene ral, we obse rve that for a ll cas es considered, applying the b lock-graph framewor k leads to better marginal estimates. This is shown in the T ables, where for ea ch inference algorithm, we 18 0.5 1 1.5 2 0.1 0.2 0.3 0.4 Error 10x10 Grid Graph (Repulsive) B2−BP IJGP−4 B3−BP IJGP−6 B2−IJGP−3 B2−IJGP−4 IJGP−8 0.5 1 1.5 2 0.15 0.2 0.25 0.3 0.35 0.4 10x10 Grid Graph (Attractive) 0.5 1 1.5 2 0.05 0.1 0.15 0.2 0.25 0.3 10x10 Grid Graph (Mixed) Error Interaction Strength 0.5 1 1.5 2 0.1 0.2 0.3 0.4 0.5 0.6 15x15 Grid Graph (Repulsive) Interaction Strength Fig. 11. Comparing the performance of B P , IJGP , and GBP . Algorithms with the same message passing comple xity are plotted in the same color . highlight the a lgorithm lea ding to the smallest me an err or in b old. For example, wh en u sing block-graphs of size two for BP , the e rror dec reases by a s muc h as 25% (see BP vs. B 2 -BP), whereas when using block-graphs of size three for BP , the e rror dec reases by as much as 50% (see BP vs. B 3 -BP). Remark 7: It is interesting to co mpare BP , IJGP , an d GBP , where both IJGP an d GBP are based on fi nding overlapping clusters and IJGP first constructs a jun ction tree an d then splits clusters in the junction tree to find overlapping clusters. No te that for the class of g raphical models co nsidered in (8), B m -BP belongs to the class of GBP- 2 m algorithms since we can map the block-graph into an equiv alent graph with overlapping clusters as do ne so when c on vert ing a block-tree into a junction tree (see Fig. 5). Further , IJBP- 2 m is also a GBP- 2 m algorithm [11]. Thus, we want to co mpare B m -BP , IJGP- 2 m , an d BP- 2 m . It is clea r that GBP- 2 m lead s to su perior marginal estimates, howev er , this co mes at the cost of significantly more computations. Fig. 11 compares B m -BP to IJGP- 2 m . W e obs erve tha t for many c ases, B m -BP lea ds to better marginal estimates than IJGP- 2 m . W e note tha t comp aring B m -BP to IJGP- 2 m may no t be appropriate since the stopping criteria for the IJG P ma y be dif ferent than that of the BP 19 algorithm 5 . Remark 8: W e can apply the block-graph framework to ge neralize GBP based algorithms. Our results show that this leads to be tter ma r ginal estimates, see GBP-4 vs. B2-GBP-4, IJGP-3 vs . B2-IJGP-3, an d IJGP-4 vs . B2-IJGP-4. More specific ally , looking at T able V, we notice that the performance of using block-graphs of size two on GBP results in the error being reduce d to nearly 15% of the original error . Remark 9: In Fig. 11, we see that for many ca ses the p erformance of B2-IJGP-3 (B2-IJGP-4) is b etter than IJGP-6 (IJGP-8). This s uggests that the set of overl apping clus ters chosen using the bloc k-graph framew ork may be better than the clus ters c hosen using the IJGP framework. Remark 10: Overall, we observe tha t block-graph versions of Tr eeEP lead to the best estimates with reasona ble comp utational time. For example, in T able IV, with σ = 1 , B2-T reeEP results in a mean error of 0 . 1583 running in an average of 0 . 455 second s. In c omparison, GBP- 4 takes an average of about 95 secon ds an d the mean error is 0 . 0884 . When co mpared to other a lgorithms, B 3 -CBP- 2 runs in 0 . 32 seconds and resu lts in a mea n error of 0 . 2657 . For mixed p otentials in T able III , we ob serve that the gen eralized versions of T reeEP d o not lead to significan t improvements in the marginal estimates although the p erformance of other algorithms does improve. Referenc e [20] propose s a gen eralization of T reeEP and gives guidelines for c hoosing clusters in the GBP algorithm. As shown for IJGP an d GBP , our framew ork can be used in c onjunction with frameworks that use overlapping clusters. Remark 11: T o our knowledge, there have be en no algorithms for generalizing LC a nd CBP- l . The computational comp lexity of LC is exponential in the maximum degree of the graph [10], s o it is only feasible to apply LC to a limited numb er of grap hs. W e only u sed LC for the 5 × 5 grid g raph example in Fig. 1 0. W e observe tha t the CBP- l algorithm improv es the estimates of the BP algorithm. Moreover , for regimes whe re the interaction s trength is small, the pe rformance of ge neralized versions of CBP is comparable to that of T reeEP . For example, in T able IV, for σ = 0 . 5 , the best TreeEP a lgorithm has a mean error o f 0 . 0694 and the b est CBP based algorithm h as a me an error of 0 . 0864 . As a nother example, in T able V, for σ = 0 . 5 , the bes t TreeEP algorithm h as a mean error of 0 . 0624 a nd the best CBP algorithm has a mea n error of 0 . 0608 . Remark 12: Fig. 12 sh ows how the error scales a s the s ize of the cluster in the block-graph increases for the 20 × 20 grid g raph. It is clea r that the e rror in ge neral decrea ses as the c luster size increa ses; howe ver , for some cases, the error does s eem to inc rease especially wh en the interac tion strength is large. 5 For IJGP , we used the software av ailable at [51]. W e could specify the maximum number of iterations, but not the stopping criteria. 20 T AB LE I 10 × 10 G R I D G R A P H W I T H R E P U L S I V E P OT E N T I A L S : 3 0 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error Time (s) Error T i me ( s) Error Time (s) BP 0.2122 0.0457 0.3714 0.0237 0 .4773 0.0150 0.4220 0.012 0 B2-BP 0.1405 0.0213 0.3080 0.0073 0.3379 0.0057 0.2978 0.003 7 B3-BP 0.1065 0.0193 0.2509 0.0133 0.3019 0.0033 0.3565 0.002 0 IJGP-3 0.1864 - 0.3784 - 0.4560 - 0.4254 - B2-IJGP-3 0.1073 - 0.2827 - 0.3789 - 0.3044 - IJGP-6 0.1441 - 0.3442 - 0.2761 - 0.4232 - IJGP-4 0.1856 - 0.4300 - 0.4128 - 0.4230 - B2-IJGP-4 0.0997 - 0.2394 - 0.2873 - 0.3245 - IJGP-8 0.1038 - 0.2349 - 0.2407 - 0.4088 - CBP-2 0.1345 0.2507 0.2757 0.1710 0.4405 0.1240 0.3801 0.113 7 B2-CBP-2 0 .0740 0.1687 0.2109 0.1147 0.3263 0.0870 0.2871 0.0660 B3-CBP-2 0 .0490 0.1583 0.1872 0.1213 0.2701 0.0890 0.3756 0.0767 CBP-3 0.1056 0.5223 0.2224 0.3537 0.4176 0.2603 0.3459 0.231 3 B2-CBP-3 0 .0561 0.3470 0.1726 0.2483 0.2824 0.1863 0.2752 0.1470 CBP-4 0.0866 1.0303 0.2094 0.6913 0.3420 0.5337 0.3195 0.465 0 B2-CBP-4 0 .0437 0.6810 0.1229 0.5067 0.2438 0.3800 0.2744 0.3123 T reeEP 0.0678 0.1993 0.1499 0.2513 0.1475 0.1680 0.1067 0.1630 B2-T reeEP 0.0547 0.1110 0.1273 0.1343 0.0489 0.1400 0.0551 0.1120 B3-T reeEP 0.0542 0.1463 0.0878 0.1683 0.0485 0.1447 0.0414 0.1527 GBP-4 0.0110 21.0497 0.0439 28.8153 0.0532 25.7290 0.0379 25.5437 B2-GBP-4 0.0005 16.7593 0.0026 25.5223 0.0021 28.8153 0.0018 33.1343 T AB LE I I 10 × 10 G R I D G R A P H W I T H A T T R A C T I V E P O T E N T I A L S : 30 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error Time (s) Error T ime (s) Error T ime (s) BP 0.2337 0.0600 0.4482 0.0217 0.3857 0.0160 0.3537 0.0113 B2-BP 0.1778 0.0227 0.3975 0.0080 0.3 597 0.0083 0.25 67 0.0053 B3-BP 0.1358 0.0173 0.2622 0.0080 0.2 799 0.0090 0.16 40 0.0027 IJGP-3 0.2125 - 0.3710 - 0.30 88 - 0.3 232 - B2-IJGP-3 0.1316 - 0.3406 - 0.2275 - 0.2044 - IJGP-6 0.1755 - 0.3846 - 0.27 41 - 0.2 967 - IJGP-4 0.2171 - 0.3708 - 0.36 74 - 0.3 912 - B2-IJGP-4 0.1259 - 0.3161 - 0.2211 - 0.1360 - IJGP-8 0.1291 - 0.3287 - 0.28 31 - 0.4 102 - CBP-2 0.1468 0.2543 0.3710 0.1590 0.3 389 0.1337 0.32 52 0.1007 B2-CBP-2 0.0687 0.1647 0.2913 0.1127 0.3177 0.0877 0.2521 0.0707 B3-CBP-2 0.0506 0.1607 0.1979 0.1143 0.2539 0.0943 0.1092 0.0763 CBP-3 0.1028 0.5243 0.3289 0.3300 0.2 648 0.2713 0.28 55 0.2180 B2-CBP-3 0.0490 0.3423 0.2522 0.2400 0.3006 0.1893 0.2416 0.1577 CBP-4 0.0784 1.0373 0.2595 0.6690 0.2 182 0.5497 0.26 62 0.4593 B2-CBP-4 0.0382 0.6737 0.1839 0.4723 0.2847 0.3857 0.1682 0.3233 T reeEP 0.0804 0.2300 0.2153 0.2470 0.11 28 0.1720 0.08 03 0.1977 B2-T reeEP 0.0499 0.1327 0.1390 0.1787 0.1104 0.1133 0.0552 0.1020 B3-T reeEP 0.0427 0.1407 0.0989 0.2117 0.0686 0.2090 0.0546 0.1337 GBP-4 0.0085 21.4370 0.0500 30.0877 0.0501 25.9627 0.0340 24.5683 B2-GBP-4 0.0005 16.7007 0.0033 26.8110 0.0022 28.9640 0.0012 32.2330 21 T AB LE I II 10 × 10 G R I D G R A P H W I T H M I X E D P O T E N T I A L S : 30 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error Time (s) Error T ime (s) Error Time (s) BP 0.0514 0.0237 0.1542 0.2863 0.3178 0.4313 0.3728 0.4750 B2-BP 0.0337 0.0057 0.0955 0.031 0 0.1862 0.1653 0.2422 0.2320 B3-BP 0.0243 0.0057 0.0824 0.036 3 0.1364 0.1217 0.1851 0.1883 IJGP-3 0.0431 - 0.1362 - 0.2719 - 0.3588 - B2-IJGP-3 0.0264 - 0.0820 - 0.15 31 - 0.1905 - IJGP-6 0.0325 - 0.1015 - 0.2042 - 0.2612 - IJGP-4 0.0434 - 0.1330 - 0.2639 - 0.3449 - B2-IJGP-4 0.0246 - 0.0675 - 0.14 79 - 0.1479 - IJGP-8 0.0243 - 0.0703 - 0.1567 - 0.1911 - CBP-2 0.0391 0.2240 0.0988 0.372 7 0.1789 0.3817 0.2184 0.3913 B2-CBP-2 0.0240 0.1190 0.0692 0.2107 0.11 07 0.2583 0.1572 0.2653 B3-CBP-2 0.0164 0.1230 0.0505 0.1957 0.10 20 0.2440 0.1212 0.2600 CBP-3 0.0351 0.4950 0.0879 0.808 3 0.1549 0.8327 0.1984 0.8497 B2-CBP-3 0.0208 0.2660 0.0642 0.4753 0.09 88 0.5790 0.1325 0.6020 CBP-4 0.0314 1.0173 0.0780 1.666 7 0.1484 1.7300 0.1755 1.7780 B2-CBP-4 0.0191 0.5620 0.0541 0.9970 0.09 86 1.1933 0.1004 1.2360 T reeEP 0.0124 0.1190 0.0350 0.1650 0.0610 0.2177 0.0864 0.2743 B2-T reeEP 0.0124 0.0837 0.0386 0.1353 0 .0573 0.1467 0.0825 0.2340 B3-T reeEP 0.0125 0.1057 0.0342 0.1490 0 .0681 0.1980 0.0887 0.2413 GBP-4 0.0009 10.8840 0.0054 17.2403 0.0091 22.2760 0.0139 23.1837 B2-GBP-4 0.0000 10.8890 0.0002 15.1400 0.0008 17.8040 0.0013 18.6687 T AB LE I V 15 × 15 G R I D G R A P H W I T H R E P U L S I V E P OT E N T I A L S : 2 0 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error T ime (s) Error T ime (s) Error Time (s) BP 0.2187 0.1550 0 .3977 0.08 70 0.5307 0.0760 0.5737 0.0575 B2-BP 0.1848 0.0745 0 .3836 0.05 90 0.4598 0.0400 0.4500 0.0385 B3-BP 0.1314 0.0700 0 .3020 0.04 55 0.5541 0.0360 0.5140 0.0445 IJGP-3 0.2052 - 0.42 39 - 0.4846 - 0.5706 - B2-IJGP-3 0.1346 - 0.2683 - 0.3805 - 0.4571 - IJGP-6 0.1671 - 0.39 03 - 0.5354 - 0.3411 - IJGP-4 0.2187 - 0.44 06 - 0.5065 - 0.6234 - B2-IJGP-4 0.1367 - 0.3103 - 0.3515 - 0.4842 - IJGP-8 0.1566 - 0.41 15 - 0.5518 - 0.5451 - CBP-2 0.1774 0.6895 0 .3609 0.49 40 0.4802 0.4440 0.5789 0.3435 B2-CBP-2 0.1335 0.4550 0.3161 0 .3390 0.4749 0.2705 0.4517 0.2425 B3-CBP-2 0.0887 0.4520 0.2657 0 .3200 0.5948 0.3115 0.4910 0.2515 CBP-3 0.1578 1.4245 0 .3234 1.00 85 0.4503 0.8665 0.5113 0.7035 B2-CBP-3 0.0946 0.9670 0.2964 0 .6650 0.3852 0.5590 0.4319 0.5080 CBP-4 0.1382 2.9145 0 .2904 1.99 85 0.4150 1.6810 0.5364 1.3610 B2-CBP-4 0.0864 1.9710 0.2713 1 .3210 0.3778 1.1395 0.3966 1.0225 T reeEP 0.0954 0.8500 0 .2831 0.79 95 0.5025 0.5895 0.7151 0.4345 B2-T reeEP 0.0888 0.5265 0.1583 0.4550 0.3566 0.4135 0.4293 0.3530 B3-T reeEP 0.0694 0.7530 0.1600 0.7835 0.2584 0.5290 0.1375 0.6025 GBP-4 0.0151 88.3395 0.0884 9 5.5370 0.0918 86.9865 0.063 9 88.9645 B2-GBP-4 0.0014 81.1430 0.0120 117.4050 0.0105 117.1510 0.00 62 120.3190 22 1 2 3 4 5 6 0.05 0.1 0.15 0.2 0.25 Bm−BP Bm−TreeEP Bm−CBP−4 (a) σ = 0 . 5 1 2 3 4 5 6 0 0.1 0.2 0.3 0.4 (b) σ = 1 . 0 1 2 3 4 5 6 0 0.2 0.4 0.6 0.8 (c) σ = 1 . 5 Fig. 12. Error as the size of the cluster increases in the 20 × 20 grid graph. The horizontal axis denotes the cluster size i n the block-graph and vertical axis denotes the mean error . T AB LE V 20 × 20 G R I D G R A P H W I T H R E P U L S I V E P OT E N T I A L S : 1 0 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 BP 0.2174 0.3182 0.7014 0.5926 CBP-2 0.2028 0.3222 0.7034 0.5550 B2-BP 0.1608 0.3412 0.6623 0.5117 B2-CBP-2 0.1387 0.3023 0 .6497 0.4465 B6-BP 0.0874 0.1320 0.4904 0.3102 B6-CBP-2 0.0638 0.0952 0 .5348 0.2926 T reeEP 0.0946 0.1243 0.4201 0.5124 CBP-3 0.1893 0.3042 0.6634 0.5569 B2-T reeEP 0.0969 0.2184 0.2736 0.5154 B2-CBP-3 0.1248 0.2385 0 .5538 0.4057 B6-T reeEP 0.0624 0.1330 0.1868 0.0574 B6-CBP-3 0.0637 0.0545 0 .4947 0.2919 GBP-4 0.0175 0.0285 0.1188 0.0259 CBP-4 0.1806 0.2450 0.6571 0.5409 B2-GBP-4 0.0015 0.0034 0.0264 0.0038 B2-CBP-4 0.1160 0.2842 0 .5563 0.3990 B3-GBP-4 0.0003 0.0005 0.0021 0.0017 B6-CBP-4 0.0608 0.0451 0 .4871 0.3116 C. Random Re gular Graphs T a bles VI and VII s how results of applying the block-grap h framework for inference over graph ical models d efined on rando m regular grap hs with attractive p otentials. T ab le VI considers graphs with 50 nodes and degree 3 a nd T able VII conside rs graphs with 70 node s and degree 3 . Just like the grid graph case, we ob serve tha t o ur gen eralized framework le ads to better marginal es timates. This is shown by highlighting the a lgorithm that lead s to minimal mean error for eac h inference algorithm. W e obs erve that both CBP a nd TreeEP base d algorithms perform the best, even when compared to GBP . V I I . S U M M A RY W e proposed a framework for generalizing inference (co mputing marginal distrib utions given the joint probability distrib ution) algorithms over graphical models (see Fig. 1). T he key compon ents in our framework are (i) c onstructing a block -tree, a tree-structured graph over no n-overlapping clusters, and (ii) constructing a block-grap h, a g raph over n on-overlapping clusters. W e p roposed a linear time algorithm for constructing block-trees an d sh owed h ow large clusters in a block-tree can be split in a 23 T AB LE VI R A N D O M R E G U L A R G R A P H W I T H p = 50 N O D E S , D E G R E E 3 , A N D A T T R A C T I V E P O T E N T I A L S : 30 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error Time (s) Error Time (s) Error T ime (s) BP 0.0290 0.0020 0.1683 0.0050 0.1514 0.0023 0.280 9 0.0020 B2-BP 0.0217 0.0010 0.1513 0.003 7 0.1414 0.0023 0.252 0 0.0000 B3-BP 0.0167 0.0000 0.1407 0.003 3 0.1394 0.0023 0.281 7 0.0000 CBP-2 0.0073 0.0630 0.0330 0.082 7 0.0712 0.0610 0.238 9 0.0467 B2-CBP-2 0.0058 0.0500 0.0272 0.0653 0.0647 0.0487 0.19 77 0.0397 B3-CBP-2 0.0056 0.0530 0.0235 0.0670 0.0469 0.0560 0.15 90 0.0450 CBP-3 0.0052 0.1357 0.0194 0.165 3 0.0358 0.1313 0.107 4 0.1097 B2-CBP-3 0.0040 0.1093 0.0131 0.1347 0.0368 0.1103 0.09 19 0.0947 T reeEP 0.0101 0.0323 0.0687 0.0473 0.0815 0.0437 0.067 5 0.0487 B2-T reeEP 0.0100 0.0320 0.0845 0.0553 0.0878 0.0543 0 .0728 0.0457 B3-T reeEP 0.0096 0.0350 0.0576 0.0587 0.0650 0.0907 0 .0443 0.0780 GBP-3 0.0290 1.1053 0.1683 1.4173 0.1514 1.0257 0.229 9 0.7763 B2-GBP-3 0.0217 0.8870 0.1513 1.252 0 0.1414 0.9837 0.228 0 0.6937 GBP-4 0.0230 1.0157 0.1548 1.4403 0.1439 1.1250 0.228 6 0.7587 T AB LE VI I R A N D O M R E G U L A R G R A P H W I T H p = 70 N O D E S , D E G R E E 3 , A N D A T T R A C T I V E P O T E N T I A L S : 20 T R I A L S Algorithm σ = 0 . 5 σ = 1 σ = 1 . 5 σ = 2 . 0 Error T ime (s) Error Time (s) Error T ime (s) Error Time (s) BP 0.0172 0.0070 0.1313 0.0200 0.2144 0.0100 0.2410 0.0100 B2-BP 0.0154 0.0040 0.1211 0.0120 0.2 071 0.0090 0.2895 0.0040 B3-BP 0.0106 0.0025 0.0871 0.0120 0.1 866 0.0065 0.2037 0.0040 CBP-2 0.0069 0.0990 0.0397 0.1425 0.1 036 0.1185 0.1833 0.0965 B2-CBP-2 0.0069 0.0870 0.0459 0.1220 0.0923 0.1080 0.2571 0.0875 B3-CBP-2 0.0063 0.0870 0.0271 0.1135 0.0882 0.1065 0.1542 0.0880 CBP-3 0.0057 0.2120 0.0247 0.2840 0.0 811 0.2465 0.1547 0.2050 B2-CBP-3 0.0063 0.1875 0.0264 0.2545 0.0727 0.2285 0.0897 0.1925 T reeEP 0.0044 0.0500 0.0404 0.0860 0.10 28 0.0985 0.0741 0.1025 B2-T reeEP 0.0054 0.0575 0.0484 0.1130 0.1016 0.0990 0.0969 0.1000 B3-T reeEP 0.0049 0.0715 0.0341 0.1005 0.0682 0.1575 0.0548 0.1730 GBP-3 0.0150 1.4935 0.1081 3.0275 0.2100 2.2155 0.2149 2.0235 B2-GBP-3 0.0127 1.4910 0.0939 2.8880 0.1998 2.1770 0.2046 1.6230 systematic manner to construct block-graphs that are fa v orable for inference. Using numerical simulations, we showed that our framew ork for generalized inference in general leads to improved ma r ginal estimates for ma ny app roximate inference algorithms implemented in the libD AI software pack age. This sug gests that the gen eralized inference framework can be us ed as a wrappe r for improving the performance of approximate inference a lgorithms. All the code an d g raphical mo dels used in the nume rical s imulations can b e d ownloaded from http://www .ima.umn.edu/ ∼ dvats/GeneralizedInference.h tml . Although the focus in this pap er was on comp uting marginal estimates, our proposed b lock-graph bas ed framew ork ca n also 24 be us ed to generalize algo rithms for computing the partition function ( Z in (1)) [52], [53 ] or for the problem o f MAP inferen ce [54 ]–[57]. There are several interesting research directions that c an be further p ursued to impro ve ou r generalized inference framew ork. O ur algorithm for constructing block-graphs only used the structure of t he graph in computing the set o f non-overlapping c lusters. Using the pa rameters of the graphical mode l may res ult in improved marginal e stimates. Further , it may be of interest to des ign b lock-graphs that are sp ecific to the inference algo rithm of interest. Anothe r interesting resea rch d irection is to c ombine framew orks that choose overlapping clus ters with the block-grap h framew ork. R E F E R E N C E S [1] H. Rue and L. Held, Gaussian Marko v Random F ields: T heory and Applications (Mono gr aphs on Statistics and Applied Pr obability) , 1st ed. Chapman & Hall/CRC, February 2005. [2] M. J. W ainwright and M. I. Jordan, Graphical Models, Exponential F amilies, an d V ariational Infer ence . Hano v er , MA, USA: No w P ublishers Inc., 2008. [3] D. K oller and N. Friedman, Proba bilistic Gr aphical Models: P rinciples and T echn iques . The MIT Press, 2009. [4] S. L. L auritzen and D. J. Spiegelhalter , “Local computations with probabilities on graphical structures and their application to expert sy stems, ” J ourna l of the R oyal Statisti cal Society . Series B (Methodolo gical) , v ol. 50, no . 2, pp. 15 7–224, 1988. [5] E. Fabre and A. Guyader , “Dealing with short cycles in graphical codes, ” in IEEE International Symposium on Information Theory (ISIT) , June 2000, p. 10. [6] E. P . Xing, M. I. Jordan, and S. Russell, “Graph partiti on strategies for generalized mean field i nference, ” i n P r oceed ings of the 20th confer ence on Uncertainty in artificial intelligence , ser . U AI ’04. Arli ngton, V irg inia, United S tates: A UAI Press, 2004 , pp. 602– 610. [Online]. A vailable: http://portal.acm.or g/citation.cfm?id=103 6843.103 6916 [7] J. Pearl, Proba bilistic Reasoning in Intelligent Systems: Networks of Plausible Infer ence . Morg an Kaufmann , 1988. [8] F . Eaton and Z. Ghahramani, “Choosing a variable to clamp: Approximate inference using conditioned belief propagation, ” in Pr oceedings of the T welfth International Confer ence on Artificial Intell igence an d Statistics , 2009, pp. 145 –152. [9] A. Montanari and T . Rizzo, “Ho w to compute loop corrections to the Bethe approximation, ” Journal of Statistical Mecha nics: Theory and Experiment , vol. 2005, no. 10, p. P10011, 2005. [10] J. M. Mooij and H. J. Kappen, “Loop corrections for approximate inference on factor graphs, ” J. Mach. Learn. Res. , vol. 8, pp. 1113 –1143, May 200 7. [11] R. Mateescu, K. Kask, V . Gogate, and R . Dechter , “Join-graph propagation algorithms, ” Jo urnal of Artificial Intelligen ce Resear c h , v ol. 37, pp. 279–32 8, 2010. [12] J. S. Y edidia, W . T . Freeman , and Y . W eiss, “Generalized belief propa gation, ” in NIPS , 2001, pp. 689 –695. [13] T . Heskes, K. Albers, and B. Kapp en, “ Approximate inference and constrained optimization, ” in UAI , 2003, pp. 313–320. [14] J. S . Y edidia, W . T . Freeman, and Y . W eiss, “Con structing free energy approximations and generalized belief propagation algorithms. ” IEEE T ransactions on Information Theory , vol. 51, no. 7, pp . 2282–2 312, July 2005. [15] A. Pelizzola, “Cluster variation method i n st atistical physics and probabilistic graphical models, ” Journ al of P hysics A: Mathematical an d General , vol. 38, no. 33, pp. R309–R339, 2005. 25 [16] M. Jordan, Z. Ghahramani, T . Jaakkola, and L . Saul, “ An introduction to variational methods for graphical models, ” Mach ine Learning , v ol. 37, no. 2, pp. 183–233, Nov 1999. [17] J. Y edidia, W . Fr eeman, and Y . W eiss, “Bethe free energy , Kikuchi approximations, and belief propagation algorithms, ” Mitsubishi Electric R esearch Labora tories, T ech. R ep. TR200 1-16, 2001. [18] R. Kikuchi, “ A theory of cooperativ e phenom ena, ” Phys. Rev . , vol. 81, no. 6, pp. 988– 988– 1003, 1951. [19] M. W elling, “On the choice of regions for generalized belief propagation , ” in Proc eedings of the 20th confer ence on Uncertainty in A rtificial Intelligence , 2004, p p. 585–5 92. [20] M. W elling, T . Minka, and Y . W . T eh, “Structured region graphs: Morphing EP into GBP, ” i n Pr oceed ings of the International Confer ence on Uncertainty in Artificial Intelligence , vol. 21 , 2005. [21] E. P . Xing, M. I. Jordan, and S. Russell, “ A generalized mean field algorithm for v ariational inference in exponential families, ” in Pr oceeding s of the 20th confer ence on Uncertainty in artificial intelligence , ser . U AI ’ 04. Arlington, V irginia, United S tates: A U AI Press, 2003, pp. 602–610. [Online]. A vailable: http:// portal.acm.org/citation.cfm?id= 103684 3.103691 6 [22] B. M. Marlin and K. P . Murphy , “Sparse Gaussian graphical models with unknown block structure, ” in International Confer enc e on Mac hine Learning , 2009, pp. 89–712. [23] A. Jalali, P . Raviku mar , V . V asuki, and S. S angha vi, “On learning discrete graphical models using group-spa rse regularization, ” in International Confer ence on Mac hine Learning , 2011, pp. 89– 712. [24] D. Malioutov , “ Approximate inference i n Gaussian graphical models, ” Ph.D. dissertation, Department of E lectrical Engineering and C omputer Science, Massachusetts Institute of T echnology , 2008. [25] P . L ´ evy , “ A special problem of Brownian motion, and a general theo ry of Gaussian r andom functions, ” in Pr oceedings of the Third Berkele y Symposium on Mathematical Statistics and Pro bability , 1954–1 955, vol. II . Berkele y and Los Angeles: Univ ersity o f California Press, 1956, pp. 13 3–175 . [26] D. V ats and J. M. F . Moura, “T elescop ing recursiv e representations and estimation of Gauss-Mark ov random fields, ” T ran s. on Information Theory , vol. 57, no. 3, pp. 1645 – 1663, 2011. [27] R. E. Kalman and R. Buc y , “Ne w results in linear filtering and pred iction theory , ” T ransa ctions of the ASME–J ournal of Basic Enginee ring , vol. 83, no. S eries D, pp. 95–108, 1960. [28] H. E. Rauch, F . Tung, and C . T . St ribel, “Maximum l ikelihood estimates of l inear dynamical systems, ” AIAA J. , vo l. 3, no. 8, pp. 1445–1 450, August 1965. [29] S. L. Laurit zen, Graphical Models . Oxford Univ ersity Pr ess, USA, 1996. [30] J. Besag, “Spatial interaction and the statisti cal analysis of latt ice systems, ” J ournal of the Royal Statistical Society . Series B (Method ologica l) , vol. 36, no. 2, pp . 192–23 6, 1974. [31] R. Halin, “S -functions for graphs, ” Jo urnal of Geometry , vol. 8, pp. 171–1 86, 1976, 10 .1007/BF01917 434. [32] N. Robertson and P . D. Seymour , “Graph minors. II. Algorithmic aspects of tree-width, ” Journa l of Algorithms , vol. 7, no. 3, pp. 309 – 322, 1986. [33] F . Jensen and F . Jensen, “Optimal junction trees, ” in Proce edings of the 10th Annual Confer ence on Uncertainty i n Artificial Intelligence (UAI-94) . San Francisco, C A: Mor gan Kaufmann, 1994, pp. 360–36. [34] H. M. Mark o witz, “The elimination f orm of the in ve rse and its application to linear programming, ” Mana g ement Science , vol. 3, no. 3, pp. 255–26 9, 1957. [35] A. Berry , P . Heggern es, and G. Si monet, “The minimum degree heuristic and t he minimal triangulation process, ” in Graph- Theor etic Concepts in Computer Scienc e , ser . Lecture Notes in Computer Science, H. Bod laender , Ed. Springer B erlin / Heidelberg, 2003, vol. 2880, pp. 58–70 . 26 [36] U. B. K jaerulf f, “T riangulation of graphs - algorithms giv ing small total state space, ” Department of Mathematics and Computer Science, Aalborg Uni v ersity , Denmark, T ech. Rep. Research Report R- 90-09, 19 90. [37] G. F . Cooper , “Nestor: A computer-based medical diagnostic ai d that integrates causal and probabilistic kno wledge, ” Ph.D. dissertation, Department of Computer Science, S tanford Uni v ersity , 1984 . [38] Y . Peng and J. A. Reggia, “Plausibility of diagnostic hypotheses, ” in National Confer ence on Artificial Intelligence (AAAI’86) , 198 6, pp. 14 0–145. [39] J. W . W oods and C. Radewa n, “Kalman fi ltering in two dimensions, ” IEEE T rans. Inf. T heory , vol. 23, no. 4, pp. 473–482 , Jul 19 77. [40] J. M. F . Moura and N. Balram, “Recursi ve str ucture of noncausal Gauss-M arko v random fields, ” IEE E T ran s. Inf. Theory , vol. IT -38, no. 2, pp. 334 –354, March 199 2. [41] B. C. Le vy , M. B. Adams, and A. S. Willsky , “Solution and linear estimation of 2-D nearest-neighbor models, ” Proc. IEEE , v ol. 78, no. 4, pp. 627–641, Apr . 1990. [42] G. Shafer and P . P . Shenoy , “Probability propagation, ” Annals of Mathematics and Artificial Intelligence , no. 1-4, pp. 327–35 2, 1990. [43] N. Zhang and D. Poole, “ A simple approach to Bayesian network computations, ” in Pro ceedings of the T enth Canadian Confer enc e on Artificial I ntelligence , 1994, pp. 17 1–178. [44] R. Dechter, “Bucket elimination: A unifying framework for reasoning, ” Artificial I ntelligence , vol. 113, no. 1-2, pp. 41–85, Sep 19 99. [45] K. Kask, R. Dechter , J. Larrosa, and F . Cozman, “Bu cket-tree elimination for a utomated reasoning , ” Univ ersity of California, Irvine, T ech. Rep. R92, 2001. [46] M. K olar, L . S ong, A. Ahmed, and E. P . Xing, “Estimating time-v arying ne tworks, ” Annals of Applied Statistics , 2009. [47] S. Z hou, J. Lafferty , and L. W asserman, “Time varying undirected graphs, ” Machine Learning , vol. 80, pp. 295–31 9, 2010, 10.1007/s10 994-010 -5180-0. [48] F . Kschischang, B. Frey , and H.-A. L oeliger , “Factor graphs and the sum-product algorithm, ” IEEE T ransactions on Information Theory , vol. 47, no. 2, pp. 498 –519, feb 20 01. [49] T . Minka and Y . Qi, “T ree-structured approximations by expectation propagation, ” in Proc . Neura l Information Processing Systems Conf . (NIPS) , 2003, p. 2003 . [50] J. M. Mooij, “libDAI: A free and open source C++ li brary for discrete approximate inference in graphical models, ” Journa l of Mac hine Learning Resear ch , v ol. 11, pp. 2169 –2173, Aug. 2010 . [51] V . Gogate, “Iterati ve joint graph propagation, ” http://www .hlt.utdallas.edu/ ∼ vgogate/ijgp.html. [52] M. J. W ainwright, T . S. Jaakk ola, and A. S. Willsk y , “ A new class of upper boun ds on the log partition function, ” IEE E T r ans. on Information Theory , v ol. 51, no. 7, pp. 2313 – 2335, July 200 5. [53] Q. L iu and A. Ihler , “Bounding the partiti on function using Holder’ s inequality , ” in Proce edings of the 28th International Confer enc e on Mac hine Learning , L. Getoor and T . Schef fer , Eds., June 2011, pp. 849–85 6. [54] M. J. W ainwright, T . S. Jaakkola, and A. S. Willsky , “MAP estimation via agreement on (hyper)trees: Message-passing and linear programming approaches , ” IEE E Tr ans. Inf. Theory , vol. 51, no. 11, pp. 36 97–371 7, Nov . 2005. [55] V . Ko lmogoro v , “Con ve rgent tree-reweigh ted message passing for energy minimization, ” IEEE T r ansactions on P attern Analysis and Machine Intelligen ce , vo l. 28, pp. 1568–15 83, 2006. [56] D. Sontag and T . Jaakkola, “Tree block coordinate descent for MAP in graphical models, ” Jo urnal of Mach ine Learning Resear c h , v ol. 5, pp. 544–551 , 2009. 27 [57] T . Jebara, “MAP estimation, message passing, and perfect graphs, ” in Proc eedings of the T wenty-F ifth Confer ence on Uncertainty in A rtificial Intelligence , ser . U AI ’ 09, 2009, pp. 258–2 67.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment