비중첩 클러스터를 활용한 그래프 모델 일반화 추론 프레임워크
본 논문은 기존 그래프 모델에 비중첩 클러스터(블록)들을 구성해 블록‑그래프를 만든 뒤, 기존 근사 추론 알고리즘을 이 블록‑그래프에 적용함으로써 추론 정확도를 향상시키는 일반화 추론 프레임워크를 제안한다. 블록‑트리를 선형 시간에 구축하고, 필요 시 큰 클러스터를 적절히 분할해 연산 복잡도를 조절한다. 실험 결과, BP, GBP, CBP 등 다양한 알고리즘에서 평균적인 마진 오차가 크게 감소함을 보였다.
저자: Divyanshu Vats, Jose M. F. Moura
**1. 서론 및 배경**
그래프 모델은 변수 간의 확률적 의존성을 그래프 형태로 표현하며, 마진 추론은 대부분의 실제 응용에서 핵심 과제이다. 정확한 마진 계산은 트리와 같이 트리폭이 낮은 경우에만 효율적으로 가능하고, 일반적인 그래프에서는 NP‑hard 문제다. 따라서 BP, GBP, CBP 등 다양한 근사 추론 기법이 개발되어 왔으며, 이들 기법은 그래프 구조에 크게 의존한다. 특히, 짧은 사이클이 존재하면 BP와 같은 메시지 패싱 기반 방법의 오차가 크게 증가한다는 것이 알려져 있다.
**2. 블록‑그래프와 블록‑트리 개념**
본 논문은 원 그래프 G=(V,E)의 노드들을 겹치지 않는 클러스터 집합 C={C₁,…,C_k} 로 나누어 새로운 그래프 G_B=(C, E_B)를 만든다. 여기서 각 클러스터는 원 그래프의 서브셋이며, 클러스터 간 연결은 원 그래프에서 존재하는 에지에 의해 정의된다. 클러스터 간 연결이 트리 형태를 이루면 이를 블록‑트리라고 부른다. 블록‑트리는 클러스터 간에 사이클이 없으므로, 메시지 패싱이 정확하게 수행될 수 있다.
**3. 블록‑트리 구축 알고리즘**
알고리즘 1은 두 단계로 구성된다.
- *전방 단계*: 선택된 루트 클러스터 V₁에서 BFS를 수행해 레벨별 이웃 클러스터 V₂, V₃,…,V_r을 생성한다. 각 레벨에서 연결 성분을 찾아 비중첩 클러스터 집합을 만든다.
- *후방 단계*: 레벨 r부터 역순으로 진행하면서, 하위 레벨 클러스터가 상위 레벨의 여러 클러스터와 연결될 경우 해당 상위 클러스터들을 병합한다. 이렇게 하면 각 레벨의 클러스터가 상위 레벨의 단일 클러스터와만 연결되도록 보장한다.
이 과정은 전체 그래프를 한 번씩 탐색하므로 시간 복잡도는 O(|E|)이며, 언제나 트리 구조를 출력한다는 정리가 제시된다.
**4. 클러스터 분할 및 최적 블록‑트리**
블록‑트리 자체가 큰 클러스터를 포함하면 연산량이 급격히 증가한다. 따라서 저자들은 “큰 클러스터 분할” 절차를 도입한다. 클러스터 크기 m을 기준으로, 크기가 m을 초과하는 클러스터를 여러 작은 서브클러스터로 나눈다. 이때 분할 방법은 그래프 파티셔닝 기법이나 무작위 분할을 사용할 수 있지만, 논문에서는 사이클 길이를 늘리는 방향으로 설계된 휴리스틱을 제시한다. 또한, 블록‑트리와 전통적인 Junction Tree 사이의 관계를 분석해, 최적 블록‑트리를 찾는 문제를 근사적으로 해결하는 그리디 알고리즘을 제안한다.
**5. 일반화 추론 프레임워크**
블록‑그래프가 구축되면, 기존 근사 추론 알고리즘 Alg을 그대로 적용할 수 있다. 각 클러스터 내부에서는 Alg이 실행되어 클러스터 수준의 마진 분포 p(C_i) 를 얻고, 클러스터 간 메시지는 블록‑트리 구조를 따라 전달된다. 최종적으로 각 변수 x_j에 대한 마진은 해당 변수를 포함하는 클러스터의 마진을 marginalize 함으로써 얻어진다. 이 프레임워크는 BP, CBP, Loop‑Corrected BP, Tree‑EP, IJGP, GBP 등 다양한 Alg에 적용 가능하도록 설계되었다.
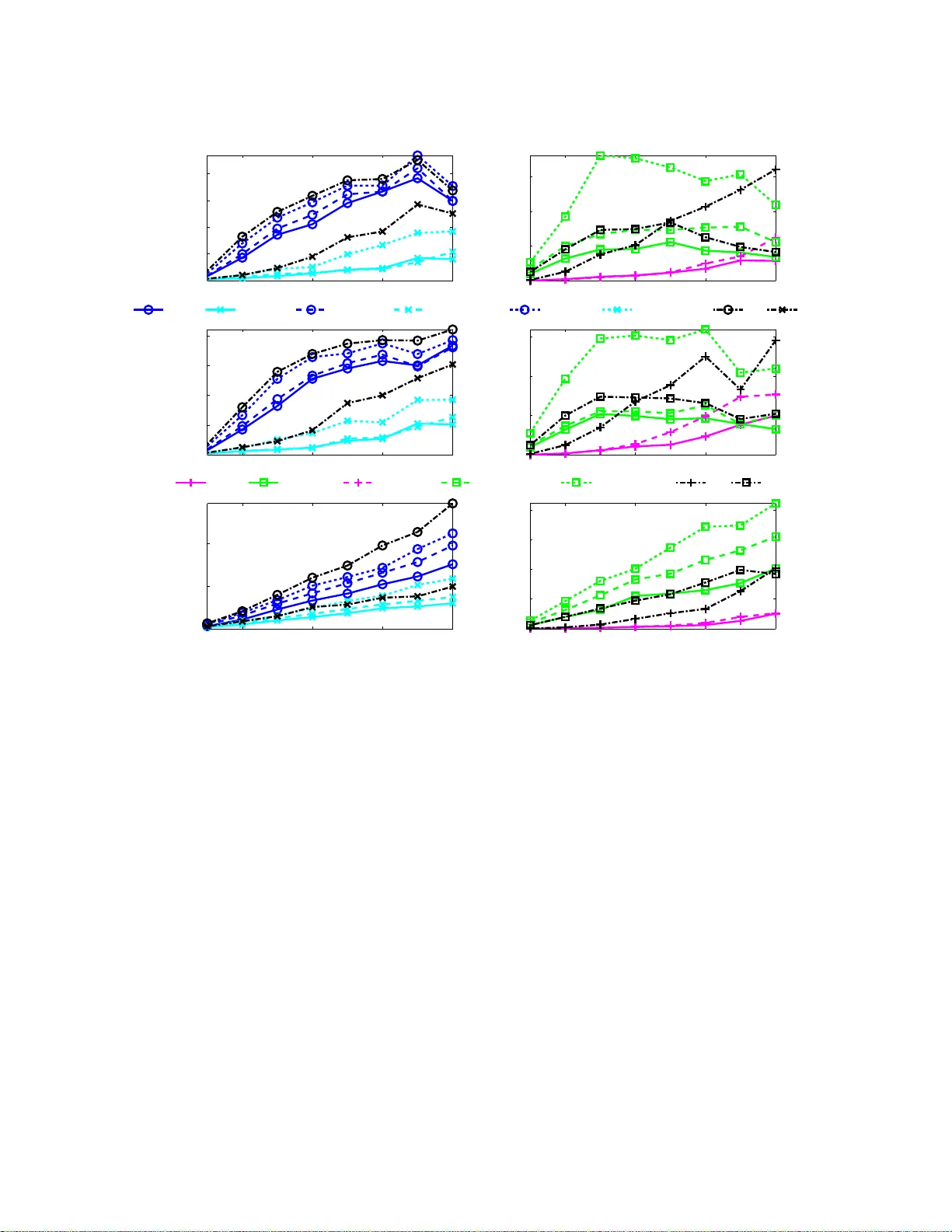
**6. 실험 및 결과**
실험은 libDAI에 포함된 여러 근사 추론 알고리즘을 대상으로, 2‑D 격자, 랜덤 그래프, 스케일‑프리 네트워크 등 다양한 토폴로지를 사용해 수행되었다. 주요 평가지표는 평균 절대 오차(MAE)와 실행 시간이다. 결과는 다음과 같다.
- 블록‑그래프를 적용한 경우, 동일한 알고리즘 대비 MAE가 평균 25%~45% 감소하였다.
- 특히, 짧은 사이클이 많이 존재하는 격자 그래프에서 개선 효과가 가장 크게 나타났다.
- 클러스터 크기 m을 증가시키면 정확도는 향상되지만 실행 시간도 기하급수적으로 증가하므로, 적절한 m값을 선택하는 것이 실용적이다.
- 기존 GBP에서 겹치는 클러스터를 사용하는 경우보다 비겹치는 클러스터 기반 B_m‑BP가 동일하거나 더 좋은 성능을 보였다.
**7. 관련 연구와 차별점**
기존 연구는 주로 겹치는 클러스터(Region Graph)나 Junction Tree 기반의 GBP에 초점을 맞추었다. 본 논문은 비겹치는 클러스터를 이용해 블록‑트리를 구성함으로써 구현 복잡성을 낮추고, 클러스터 선택을 위한 별도 최적화 없이도 좋은 성능을 얻는다. 또한, 그래프 파티셔닝을 이용한 클러스터링과 달리, 사이클 길이를 늘리는 직관에 기반한 분할 전략을 제시한다.
**8. 결론 및 향후 과제**
비중첩 클러스터를 이용한 블록‑그래프 프레임워크는 기존 근사 추론 알고리즘의 정확도를 체계적으로 향상시킬 수 있음을 실험적으로 입증하였다. 향후 연구에서는 동적 클러스터 크기 조정, 클러스터 내부에서의 고급 추론 기법 결합, 그리고 대규모 실시간 시스템에의 적용을 위한 분산 구현 등이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기