Information-sharing and aggregation models for interacting minds
We study mathematical models of the collaborative solving of a two-choice discrimination task. We estimate the difference between the shared performance for a group of n observers over a single person performance. Our paper is a theoretical extension…
Authors: Piotr Migda{l}, Micha{l} Denkiewicz, Joanna Rc{a}czaszek-Leonardi
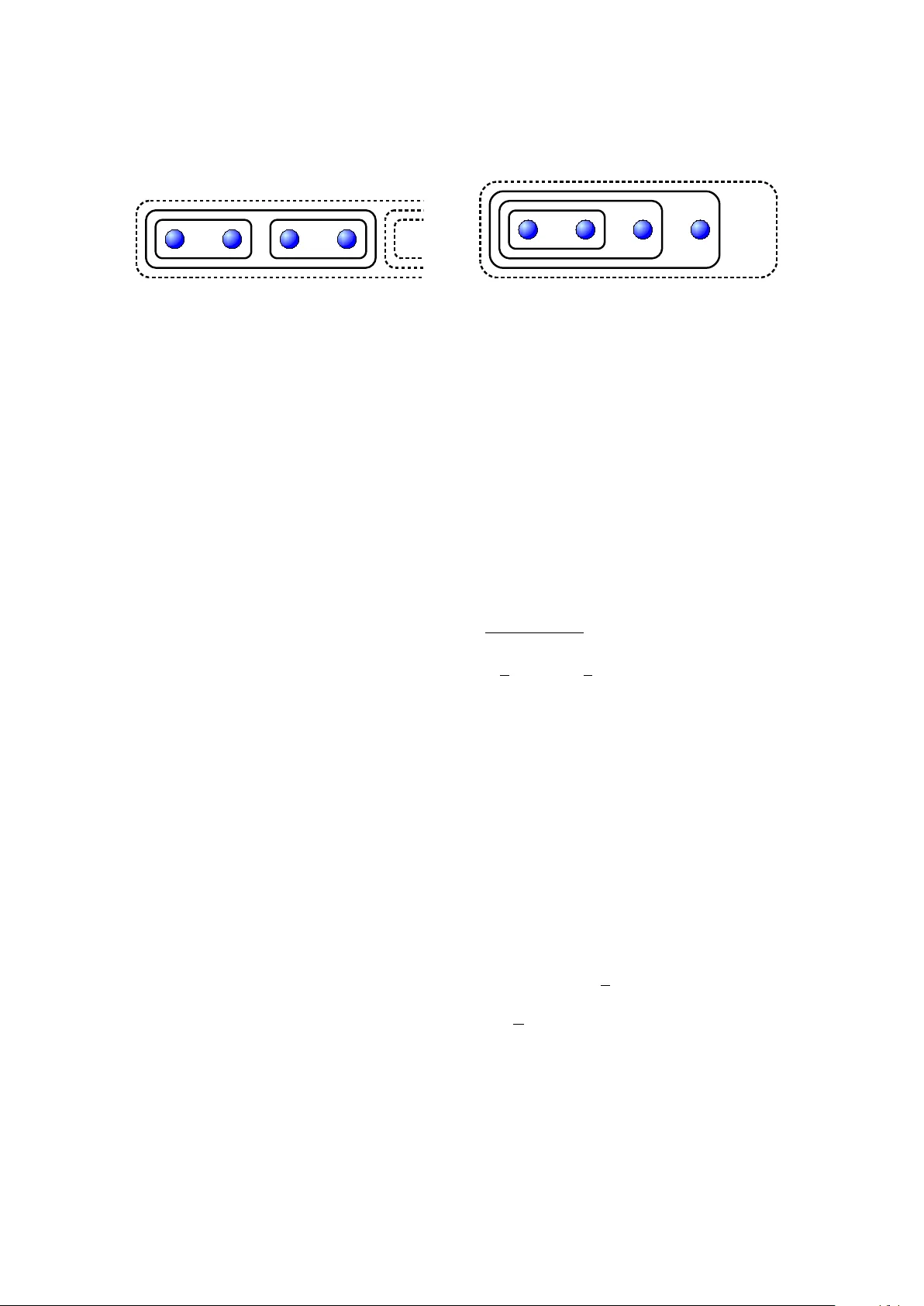
Information-sharing and aggregation mo dels for in teracting minds Piotr Migdał a,b , Joanna Rączaszek-Leonardi c , Mic hał Denkiewicz d , Dariusz Plew czynski e a Institute of The or etic al Physics, University of W arsaw, W arsaw, Poland b ICF O–Institut de Ciències F otòniques, 08860 Castel ldefels (Bar c elona), Sp ain c Institute of Psycholo gy, Polish A c ademy of Scienc es, W arsaw, Poland d Dep artment of Psycholo gy, University of W arsaw, W arsaw, Poland e Inter disciplinary Centr e for Mathematic al and Computational Mo del ling, University of W arsaw, Pawińskie go 5a, 02-106 W arsaw, Poland Abstract W e study mathematical mo dels of the collab orativ e solving of a t wo-c hoice discrimination task. W e estimate the difference b et ween the shared p erformance for a group of n observers o ver a single p erson p erformance. Our pap er is a theoretical extension of the recent work of Bahrami et al. (2010) from a dy ad (a pair) to a group of n in teracting minds. W e analyze sev eral mo dels of comm unication, decision-making and hierarc hical information-aggregation. The maximal slop e of psyc hometric function (closely related to the percentage of righ t answ ers vs. easiness of the task) is a conv enien t parameter characterizing p erformance. F or ev ery mo del w e inv estigated, the group p erformance turns out to b e a pro duct of tw o n umbers: a scaling factor dep ending of the group size and an a verage p erformance. The scaling factor is a p o w er function of the group size (with the exp onen t ranging from 0 to 1 ), whereas the av erage is arithmetic mean, quadratic mean, or maxim um of the individual slop es. Moreov er, v oting can b e almost as efficien t as more elab orate communication mo dels, giv en the participants hav e similar individual p erformances. Keywor ds: group decision making, t wo-alternativ e forced choice, decision aggregation, group information pro cessing, discriminative judgments, accuracy, discrimination difficult y, bias, information sharing, group size, tw o-c hoice decision, distributiv e cognitive systems, comm unication mo dels, cognitiv e pro cess mo deling 1. In tro duction An yone who has ever tak en part in group decision making or problem solving has most lik ely asked themselves at one p oin t or another whether the pro cess actually made an y sense. W ould it not b e b etter if the most comp eten t p erson in the group simply made the decision? In other w ords, it is an op en question whether a group can ev er outp erform its most capable Email addr esses: pmigdal@gmail.com (Piotr Migdał), darman@icm.edu.pl (Dariusz Plewczynski) URL: http://migdal.wikidot.com/en (Piotr Migdał), http://cognitivesystems.pl (Dariusz Plew czynski) Pr eprint submitte d to Journal of Mathematic al Psycholo gy, 10.1016/j.jmp.2013.01.002 August 26, 2018 mem b er. There ha v e b een man y studies that ha ve rep orted group decisions to b e less accurate (Corfman and Kahn, 1995). Some studies, ho w ever, hav e concluded that groups — ev en when they merely use simple ma jorit y v oting — can mak e b etter decisions than their individual mem b ers (Grofman, 1978; Kerr and Tindale, 2004; Hastie and Kameda, 2005). W e ask a more general question: ho w do es the group p erformance dep end up on the individual p erformances of its participan ts and the wa ys in which those participants comm unicate? This question is giv en new ligh t b y recen t trends in cognitive psychology , which after a half a century of fascination with isolated cognition in the individual, has finally admitted the individual interaction with the so cial environmen t. It is increasingly understo od that join t actions and join t cognition are not limited to situations of committee/voter decisions, but instead, they p erv ade everyda y life and require the constant co ordination and integration of cognitive and ph ysical abilities. This new approach, typically called distribute d c o gni- tion (Hutc hins and Lintern, 1995), or extende d c o gnition within the so cial domain (Clark, 2006), brings the fo cus of research to the mec hanisms of cognitiv e and physical co ordina- tion (Kirsh, 2006) that affect this in tegration. It also brings attention to the comparison of the p erformance of the group to the p erformance of the individual. F or some tasks that require differen t types of kno wledge and abilities from group participan ts, groups are likely to outp erform individuals (Hill, 1982). F or other tasks, such as simple discrimination tasks or estimations, a question arises if a group is indeed b etter than the b est of its mem b ers. If there are suc h situations, it is imp ortan t to know when they arise. Group decision making ob viously in volv es mem b ers interacting with eac h other. Casting a vote requires a minimum amount of communication for the individual (only to inform other group mem b ers about his or her choice). Ho wev er, other group decisions allow for extensiv e communication and negotiations of the decision. Our questions are: 1) which forms of communication are most likely to facilitate an improv ed outcome, and 2) what is actually b eing communicated in successf ul groups? Recent exp erimen ts by Bahrami, Olsen, Latham, Ro epstorff, Rees, and F rith (2010) ha v e shown that co op eration can b e b eneficial, ev en in simple task, and that this b enefit is best explained b y the participants comm unicating their relative confidences. In their study , dyads (pairs) p erformed a p erceptual tw o-c hoice discrimination task. On ev ery trial participan ts had to decide which of t wo consecutive stim uli (sets of Gab or patches) contained a patc h with higher contrast. First, decisions w ere collected from both p ersons; then, if the decisions were different, the participants were allo wed to communicate to reach a joint decision. The decision data obtained from each p erson w as used to fit a psyc hometric function, i.e., the probabilit y of that p erson giving a sp ecific answer, as a function of the difference of the contrast b et ween Gab or patc hes. These functions describe the person’s skill in the task. Similarly , a function describing the skill of the group as a whole can b e estimated from the group decisions. As was describ ed by Bahrami: "In exp eriments (...) psychometric functions wer e c onstructe d for e ach observer and for the dyad by plotting the pr op ortion of trials in which the o ddb al l was se en in the se c ond interval against the c ontr ast differ enc e at the o ddb al l lo c ation" (Bahrami et al. (2010), Supplementary Materials, p. 3). V arious assumptions about the nature of within-group in teractions during the join t 2 decision-making pro cess can be made. F rom these assumptions, we can deriv e theoreti- cal relationships b et w een the parameters of mem b ers’ functions and the parameters of the group function. These are the mo dels of decision making. The correctness of each join t decision mo del can then b e tested against empirical data. Bahrami et al. (2010) described and ev aluated four suc h models. One w as o wn, in whic h group mem b ers comm unicate their confidence in their individual c hoices. Another mo del stemmed from signal detection theory (Sorkin et al., 2001). If members know eac h other’s relativ e discriminatory ability (i.e., their psyc hometric functions), the group can mak e a statistically optimal c hoice. Th us, under certain conditions, we ha ve an upper b ound on group p erformance. The third mo del suggested that the dyad is only as go od as its b est member. Finally , the last mo del tested w as a control mo del inv olving random resp onse selection. The study concluded that, when similarly skilled p ersons meet, they can b oth b enefit from co operation. A mo del in whic h participants comm unicate their relative confidences b est explains this b enefit. W e extend the mo dels from Bahrami et al. (2010) to groups of n participants and compare their predictions. F urthermore, w e add a mo del in which a participan t either kno ws the correct answ er, or guesses. Imp ortan tly , in the case of larger groups, it may b e the case that only small subgroups of participan ts can comm unicate simultaneously . Th us, w e address this issue by considering hierarc hical sc hemes of decision aggregation, in which decisions are first made by subgroups, and then some of these subgroups in teract to reach a shared decision. The pap er is organized as follo ws. In Section 2, we presen t the Bahrami et al. (2010) approac h to integrating individual discrimination functions in pairs of participants. W e use it to assess p erformance in groups. In Section 3, we pro ceed to form ulating a series of mo dels of comm unication, which express the p erformance of a group of n p ersons as a function of their individual p erformances. In Section 4, w e inv estigate how each mo del w orks, assuming sev eral schemes of decision aggregation. Section 5 compares the in tro duced mo dels and pro vides insight in to further exp erimen tal and theoretical work. Section 6 concludes the pap er. 2. Mo del of discrimination Consider an exp erimen t in which a participant has to mak e simple discriminatory deci- sions of v arying difficulty . Eac h trial is assigned a parameter, c , that describ es the physical distance b et ween stim uli (e.g., in the Bahrami et al. exp erimen t c was the difference in con trast b et ween Gab or patches). Negativ e c describ es a situation in which the right choice is the first of the pair, whereas p ositiv e c describ es the opp osite situation. The absolute v alue of c reflects the difficulty of a giv en trial. The lo w er the v alue, the more difficult is the resulting trial. F rom now on, we refer to the parameter describing physical difference as stimulus c . In the case of Bahrami et al. exp erimen tal setup, it can b e interpreted as the t wo-in terv al stim ulus with the difference of contrasts equal to c . By knowing the choices of a certain decision-making agent (in our case either a single participan t or a group making the decision together) for a range of stimuli, w e can construct 3 a mathematical description of the agen t’s p erformance on the task. F or each agent, we can then determine his or her psychometric function: the probability of the agen t c ho osing the second answ er as a function of the stimulus, P ( c ) . An ideal resp onder would b e describ ed b y the Hea viside step function: P ( c ) = 0 for all negativ e stim uli, and P ( c ) = 1 for all p ositiv e stim uli (i.e., c ho osing the second in terv al if and only if c > 0 ). Because resp onders mak e errors, the actual decision rule and probabilit y are differen t. One wa y to describ e such a resp onse is deriv ed from signal detection theory (Sorkin et al., 2001). According to it, for a stim ulus c , a participant p erceiv es stimulus x , which is a normally distributed random v ariable cen tered around c + b and with v ariance σ , and decides basing on the sign of x . T w o mo dels describ ed in this pap er (W eighted Confidence Sharing and Direct Signal Sharing) use this mec hanism explicitly . The modifi ed realistic decision rule of an agent states that if the observed stim uli x is negativ e, an agent decides to select the first patc h (therefore in terpreting the difference in contrast as negative), in the case of p ositiv e v alue, the second option is selected. In particular, psyc hometric curves which are cumulativ e of the normal distribution: P ( c ) = H c + b σ , where (1) H ( x ) = 1 √ 2 π Z x −∞ exp − t 2 / 2 dt, (2) result in a go od fit for the exp erimen tal data (Bahrami et al., 2010). The parameter σ can b e in terpreted as the participan t’s uncertaint y ab out the decision. The parameter b is the bias (offset); it represen ts a tendency to choose a particular answ er, see Fig. 1. The P ( c ) function, defined as ab o ve, can b e view ed as a con volution of the step function (the correct answ er) and the Gaussian distribution (the discriminative error). - 3 - 2 - 1 1 2 3 c - stimulus 0.2 0.4 0.6 0.8 1.0 P H c L - probability of choosing the second option slope bias W Figure 1: Plot of the psychometric function, with shown slop e s and p ositiv e bias b . F or our purp oses, we assume that bias is m uch smaller than the c haracteristic width parameter, i.e., | b | σ . 4 Consequen tly , σ b ecomes the main determinant of the effectiveness of discrimination. It is con venien t to choose the maximal slop e of the psychometric function s = 1 √ 2 π σ , (3) as the primary measure of the resp onding agent’s effectiveness. No w, we can pro ceed to extending the Bahrami et al. (2010) mo dels. W e w ould lik e to kno w ho w the p erformance of a group of n p eople dep ends up on their individual cognitive p erformances. Therefore, w e need to solv e the explicit form ulas for the propagation of slop es and biases when com bining several resp onders within each of the differen t mo dels of comm unication: s model = s model ( s 1 , b 1 , . . . , s n , b n ) , (4) b model = b model ( s 1 , b 1 , . . . , s n , b n ) . (5) Eac h mo del is describ ed by the shared decision function P model = f [ P 1 , . . . , P n ] , (6) where f is a functional. F or all but tw o mo dels that w e in vestigate, P model ( c ) = f [ P 1 ( c ) , . . . , P n ( c )] , that is, the dep endence is p oin t wise (i.e., result for a giv en c requires only kno wing individual P i ( c ) for the same c ). W e can obtain the effectiv e slop e (4) and bias (5) using straigh tforw ard formulas that in volv e taking the deriv ativ e of the psychometric function with resp ect to the stim ulus: s model = P 0 model ( c ) | c = − b model ≈ P 0 model ( c ) | c =0 (7) b model = b for whic h P model ( − b ) = 1 2 ≈ P model (0) − 1 2 P 0 model ( c ) | c =0 , (8) where assuming (1) the approximation for the relativ e error for b oth s and b is of order O ( s 2 b 2 ) (or equiv alently , O ( b 2 σ 2 ) ), where O ( · ) stands for big O notation. The deriv ation is in App endix A. Note that if P model ( c ) is a cumulativ e Gaussian function (as in (1)), then the form ulas for slop e (3) and (7) are equiv alen t. How ever, it can b e used as a definition of the slop e and the bias in the general case of an arbitrary communication strategy P model ( c ) , ev en if (1) do es not hold. Bear in mind that for practical applications, we exp ect P model ( c ) to b e close enough to the cum ulative Gaussian function. Moreov er, when there are no biases, for all decision-making considered in this pap er, the maximal slop e is at c = 0 . A question arises ab out the relation b et w een the psyc hometric curve parameters and the exp ected rate of errors. T o assess the a v erage amount of incorrect answers we could exp ect from a resp onder, we introduced the following quantit y , W ( σ , b ) = Z 0 −∞ P ( c ) dc + Z ∞ 0 [1 − P ( c )] dc (9) = r 2 π σ exp − b 2 2 σ 2 + b 2 H b σ − 1 , (10) 5 where we integrated the error function (Abramowitz and Stegun, 1965). F or a uniform distribution and range of stimuli, ( − r, r ) for r ( σ + | b | ) , the rate of the incorrect resp onses is giv en b y W ( σ , b ) / (2 r ) . The a v erage num b er of wrong answers is alwa ys reduced when lo wering either width or bias, regardless of the other parameter’s v alue. This fact further justifies the choice of the slop e as the prop er effectiv eness measure. When there is no bias, (10) simplifies to W ( σ , 0) = 2 /s ; thus, the rate of the incorrect resp onses is 1 / ( r s ) . 3. Information-sharing mo dels In this section, we discuss different mo dels of information sharing for n participants. It is imp ortan t to underline that the mo dels incorp orate the pro cess of p erceiving (what the sub jects ma y kno w), the state of mind (what the sub jects know), and the communication and the decision-making pro cess (usually Bay es-optimal). W e briefly define the assumptions of each mo del and justify it in psychological terms. W e giv e results in terms of the effectiv e psyc hometric function, P model ( c ) , the effectiv e slop e, s model , and sometimes the effectiv e bias, b model (as for a few mo dels the bias is p o orly defined). Whenever calculations of P model ( c ) are not straigh tforward, we give some insight into the underlying mathematics. W e inv estigate the follo wing mo dels: • 3.1 Random Resp onder, • 3.2 V oting, • 3.3 Best Decides, • 3.4 W eighted Confidence Sharing, • 3.5 Direct Signal Sharing, • 3.6 T ruth Wins. 3.1. R andom R esp onder Mo del. The trial decision of a random group member is taken as the group decision. Motivation. Random Resp onder serv es as one of the reference mo dels, and it is not exp ected to b e fulfilled in most of realistic settings. Random factors determine the collective decision, i.e., comm unication is seen as ineffectiv e within framew ork of this model. Sometimes the decision is not based on any evidence and p eople may ha ve very misleading impressions of their own accuracy . Additionally , their decisions ma y dep end more up on a group mem b er’s c harisma or persuasive skills than his or her psychometric skills. In the w ork of Bahrami et al. (2010), this mo del is called ’Coin flip’. 6 R esults. P RR ( c ) = 1 n n X i =1 P i ( c ) (11) After the differen tiation, one obtains the slop e (7) and the bias (8): s RR ≈ s 1 + . . . + s n n (12) b RR ≈ s 1 b 1 + . . . + s n b n s 1 + . . . + s n (13) The relative error b oth for s RR and b RR is O ( s 2 1 b 2 1 ) + . . . + O ( s 2 n b 2 n ) . Note that P RR ( c ) is not normal (1). 3.2. V oting Mo del. Each participant mak es her or his own decision. The ma jorit y v ote determines the decision of the group. In a case of equal v otes for tw o outcomes, a coin is flipp ed. Motivation. P eople may ha ve no access to their accuracy (or they cannot comm unicate it reliably); th us, a go o d strategy is to take voting as the final consensus result. R esults. P V ot ( c ) = b n − 1 2 c X k =1 X ~ i [1 − P i 1 ( c )] · · · [1 − P i k ( c )] P i k +1 ( c ) · · · P i n ( c ) (14) + 1 2 X ~ i [1 − P i 1 ( c )] · · · h 1 − P i n/ 2 ( c ) i P i n/ 2+1 ( c ) · · · P i n ( c ) if n is ev en , where sum ov er ~ i denotes sum ov er ev ery p erm utation of participants. W e obtain (deriv ation in App endix B) s V ot ≈ s 1 + . . . + s n n × ( n 2 n n n/ 2 if n is ev en n 2 n − 1 ( n − 1) ( n − 1) / 2 if n is o dd (15) ≈ q 2 π × √ n × s 1 + . . . + s n n (16) b V ot ≈ s 1 b 1 + . . . + s n b n s 1 + . . . + s n (17) The P V ot ( c ) is not normal (1). The relative error b oth for s V ot and b V ot is O ( s 1 b 1 ) + . . . + O ( s n b n ) . Note that the addition of an o dd mem b er to a group do es not increase its a verage p erformance. The formula (16) is an asymptotic expression for large n , which utilizes the W allis form ula. F or n = 2 , the Random Responder and V oting models yield the same results. 7 3.3. Best De cides Mo del. The most accurate mem b er of the group makes the decision. This mo del is called Behavior and F e e db ack in Bahrami et al. (2010). In this mo del, we will fo cus on the case with no bias, b = 0 . Nonzero bias would mak e the result difficult to state in explicit form; see (10) for further explanation. Motivation. In some exp erimen tal settings, mem b ers of the group can determine, who is the most accurate (e.g., when feedbac k is present). Group members can then let that individual mak e the final decision. Studies b y Henry (1995) suggest that, at least in some types of tasks, participan ts can identify the most proficient member, so our assumption is plausible. As in the previous mo dels, there is no (effectiv e) communication b et w een the mem b ers of the group. R esults. P B D ( c ) = P mem b er with the highest s ( c ) (18) s B D = max( s 1 , . . . , s n ) (19) When biases are large, the group psyc hometric function is that of the most effectiv e par- ticipan t (i.e., one with the lo w est W ( σ i , b i ) (10)), P B D ( c ) = P i ( c ) . This strategy is most b eneficial for a group with very diverse individual p erformances. 3.4. W eighte d Confidenc e Sharing Mo del. Group mem b ers share their relativ e confidences z i = x i /σ i . The group decision dep ends on the sign of P n i =1 z i , i.e., for the negativ e they choose the first option and for the p ositiv e they c ho ose the second. This mo del requires eac h P i ( c ) to b e normal (1). Motivation. The v alue x i is the stimulus p erceiv ed by i -th participan t and has a distribution with densit y P 0 i ( c ) , as it is in Sorkin et al. (2001). W e assume the confidence to b e a con tinuous v ariable. The true stimulus c is, of course, common for all participan ts in a given trial. The relative confidence is equiv alent to a z -score, if the participan t is un biased (i.e., it is related to the probabilit y that the participant is righ t). Put differen tly , participan ts kno w their z -scores on a giv en trial but are unaw are of their o wn parameters s and b . This mo del w as first in tro duced by Bahrami et al. (2010). It is p ossible that, in an exp erimen tal trial, each participan t can estimate and effectively communicate their relativ e confidences, b y using a coarse real-w orld approximation of one’s z -score, e.g., ’I lean tow ards 1st’, or ’I am almost sure it is the 2nd’ ? . The study by Bahrami et al. (2010) suggests that this mo del most accurately describ es dyad p erformance. Giv en relative confidences ~ z = ( z 1 , . . . , z n ) , the group has to determine whether to choose the first or the second option. If there are only t wo participants with differen t opinions, the one with the stronger confidence (for a given trial) decides. This can b e written as follo ws: the group chooses the first option if z 1 + z 2 ≤ 0 , the second option otherwise, yielding an optimal strategy (Bahrami et al., 2010). In the general case of n participan ts, we use the 8 Ba yes optimal reasoning. W e calculate the probability that the stimulus is p ositiv e (and th us the second answer is correct) given the z -scores provided by each participan t: p ( c > 0 | ~ z ) = Z ∞ c =0 p ( c | ~ z ) dc = R ∞ 0 p ( ~ z | c ) p ( c ) dc R ∞ −∞ p ( ~ z | c ) p ( c ) dc , (20) where p ( c ) is the probability of a discrimination task with c . The probability of observing z i -score, giv en stimulus c , is P 0 i ( c − σ i z i ) . Thus p ( ~ z | c ) = P 0 1 ( c − x 1 ) · . . . · P 0 n ( c − x n ) . (21) Let us assume that the displa y ed stim ulus has a uniform distribution, i.e., that p ( c ) is constan t (not going in to mathematical nuances). T o define the decision function, we need to kno w when p ( c > 0 | ~ z ) ≥ 1 / 2 or, in other w ords, when the probability that the second answ er is correct is greater than 1 / 2 . As (21) is a Gaussian function of c , finding its maximum leads to the condition x 1 σ 2 1 + . . . + x n σ 2 n ≥ 0 , (22) or equiv alently , using the slop e parameter, s 1 z 1 + . . . + s n z n ≥ 0 . (23) Th us, when the condition holds, c ho osing the second option is the Ba y es optimal c hoice. Unfortunately , in this mo del w e only ha ve access to v alues of ~ z , not to individual p erfor- mances. T o obtain the precise answer, w e need to kno w the whole distribution of σ i (or s i ). Instead, w e can use the approximate condition for the choice of the second option, z 1 + . . . + z n ≥ 0 , (24) to obtain a low er b ound on the p erformance. The condition is exact for participants with equal performances (and should be close to the optimal if the v alues of σ i do not v ary m uch). This equation can b e seen as a t yp e of a weigh ted voting, where w eights dep end on sub jective confidences, but not on individual p erformances. Mem b ers do not kno w their own — or their peers’ — performance scores, so there is no justification for assigning more or less w eight to a particular mem b er throughout the exp erimen t. The only thing that matters is eac h member’s confidence in the present trial. R esults. T o calculate P W C S ( c ) , we need to compute, giv en stimulus c , the probability of obtaining set ~ z with a p ositiv e sum (24). Thus P W C S ( c ) = Z x 1 /σ 1 + ... + x n /σ n ≥ 0 exp − ( c + b 1 − x 1 ) 2 2 σ 2 1 + (25) − . . . − ( c + b n − x n ) 2 2 σ 2 n dx 1 · · · dx n (2 π ) n/ 2 σ 1 · · · σ n = H h √ 2 π s W C S ( c + b W C S ) i , (26) 9 where the in tegration is based up on the fact that a sum of Gaussian random v ariables z i is a Gaussian random v ariable (Piau, 2011). The resulting parameters are: s W C S = √ n × s 1 + . . . + s n n , (27) b W C S = s 1 b 1 + . . . + s n b n s 1 + . . . + s n . (28) Again, note that the abov e result for s W C S is the lo w er b oundary v alue for optimal Ba yesian reasoning, exact only for n = 2 (due to symmetry) and a group of participants with the same p erformance. By knowing the exact distribution of individual p erformances, w e can obtain a b etter (or at least the same) group p erformance. Then, instead of the summation of individual z -scores (24), one will get a more complicated form ula for the decision. 3.5. Dir e ct Signal Sharing Mo del. Group mem b ers share b oth their p erceiv ed stim uli x i and their σ i . The group de- cision dep ends on the sign of P n i =1 x i /σ 2 i . This mo del requires each P i ( c ) to b e normal (1). Motivation. As for the WCS, we assume that the v alue x i is the stim ulus p erceiv ed b y i -th participan t and has a distribution with the density P 0 i ( c ) , as it is in (Sorkin et al., 2001). The group p ossesses complete knowledge ab out the characteristics of i ts members and their p erceptions, so its effectiv eness is hindered only by the skill of the participants, not b y comm unication. This mo del constitutes the upp er b ound for group p erformance, pro vided that the stimuli are fully defined by their stimulus v alues (and p erceiv ed according to the discussed mo del). In the case of a more complex, non-p erceptiv e task, it is p ossible for a group to exceed this b ound (Hill, 1982). F or example, this could o ccur when participants’ skills complemen t each other. P eople know the strength of the stimuli but also their own sensitivit y . If the feedback is provided, we can plot x versus c to get σ . R esults. The final group decision follows the standard deriv ation of n classifiers collecting indep enden t results with normal distribution (e.g., Sorkin et al. (2001) and Bahrami et al. (2010)): P DS S ( c ) = 1 normalization Z c −∞ P 0 1 ( x ) · . . . · P 0 n ( x ) dx (29) s DS S = q s 2 1 + . . . + s 2 n = √ n × r s 2 1 + . . . + s 2 n n (30) b DS S = s 2 1 b 1 + . . . + s 2 n b n s 2 1 + . . . + s 2 n (31) Note that, regardless of the distribution of the individual p erformances, the group p erfor- mance outscores b oth Best Decides and W eigh ted Confidence Sharing. 10 3.6. T ruth Wins Mo del. W e assume that on eac h trial each member is in one of the tw o states: either they kno w the right answ er or they are aw are of their o wn ignorance. In the latter case, a random guess is made. It is sufficien t to ha ve a single group member p erceiv e the stimuli correctly to get the correct group answer. W e assume no bias, as there is no p ossible w a y to treat it consisten tly and it introduces false convictions. Motivation. F or so-called Eurek a problems, the signal-theoretic limit can b e exceeded (Hill, 1982). The k ey is that the answer to suc h a problem has the prop ert y of demonstrability: it allo ws a single mem b er who has the correct answ er to easily convince the rest of the group of its correctness (Laughlin et al., 1975). P eople know if they see the ’righ t’ stimuli (and all errors are due to guessing, not to false observ ations). This mo del has received m uc h atten tion in group decision theory , e.g., in Da vis (1973). It is appropriate in situations when the correctness of a solution can b e demonstrated. How ever, we do not exp ect this mo del to b e applicable to tasks similar to that of Bahrami et al. (2010). This mo del serv es as a con trol and an explicit example of a result b ey ond one provided b y the Direct Signal Sharing mo del. W e included it with the aim of generalizing the mo dels to differen t decision situations. R esults. The probability that the resp onder kno ws with certaint y the righ t answ er is R ( c ) = | 2 P ( c ) − 1 | . (32) That is, w e ha ve a rev ersed formula sa ying that, when a resp onder knows the answer with probabilit y R ( c ) , the resp onder answers correctly with probabilit y R ( c ) + (1 − R ( c )) / 2 (as there is the c hance to answ er correctly by a random guess). The probabilit y that at least one p erson knows the correct answer is R T W ( c ) = 1 − [1 − R 1 ( c )] · . . . · [1 − R n ( c )] . (33) Consequen tly , P T W ( c ) = sign ( c ) R T W ( c ) + 1 2 (34) s T W = n × s 1 + . . . + s n n , (35) where the slop e is a result of straightforw ard differen tiation (7). This mo del yields m uch b etter results than other mo dels; note, ho wev er, that the absence of false observ ations is a strong requiremen t. Other mo dels ha v e to operate without this assumption. Note that the P T W ( c ) is not normal. 4. Aggregation of information in hierarc hical sc hemes So far, w e hav e assumed that information from all participants is sim ultaneously col- lected and used in the group decision. One ma y argue that this is unrealistic for human 11 comm unication in groups of more than a few p ersons. W e, therefore, prop ose hierarc hical mo dels (sc hemes) in which only small subgroups can communicate at a particular time. Each of these subgroups reaches its o wn decision, in a manner describ ed b y one of the mo dels in tro duced in the previous section. Hence, the subgroup can be regarded as a decision- making agen t, describ ed b y a slop e and a bias. The subgroup can then communicate with other subgroups or individual members, which results in larger groups b eing created, un til all information is gathered and the final decision is made. The results of emplo ying a m ulti-level decision system can significan tly deviate from what sim ultaneous information collection predicts. F or instance, in a tw o-lev el v oting system, whic h has b een widely studied in the context of election results (Davis, 1973; Laughlin et al., 1975) the final outcome dep ends hea vily upon the distribution of votes in the subgroups, sometimes allowing minorit y groups to ov ercome the ma jorit y , sometimes exaggerating the p o w er of the ma jorit y . It is thus interesting to study the p ossible effects of such hierarc hical systems. W e prop ose the follo wing mo del for comm unication of n participants: 1. In the b eginning there are n agents. 2. Eac h turn only g (for our purp ose: 2 or 3 ) agen ts (groups or individuals) share their information according to a chosen mo del. These agen ts are then merged in to one agen t (defined b y s model ( s 1 , . . . , s g ) ). In other w ords, a group of p eople who shared information, is treated as a single agent in the next turn. Th ere are tw o free parameters: • The mo del used to combine members’ parameters into group parameters. • Ho w the groups are formed, i.e., the w ay to determine which agen ts should interact in giv en turn. Let us consider the follo wing wa ys in whic h groups can form (see Fig. 2 for the diagram of the t wo first schemes): • 4.1 Shallow hierarch y: Each turn g agen ts from the groups with the least n umber of participan ts interact. • 4.2 Deep hierarch y: Eac h turn g − 1 agents join to the group with largest num b er of participan ts (that is, there is only one group to which each turn g − 1 agents join). • 4.3 Random hierarc hy: Eac h turn g random agents in teract. Ab o v e, by participan ts we understand the total num b er of individuals that w ere merged into an agen t. F or some mo dels, the wa y in which groups are formed is irrelev an t for obvious reasons. This is the case for Random Resp onder, Best Decides, Direct Signal Sharing and T ruth Wins. The result is alwa ys the same and is equiv alent to the simplest situation without an y hierarch y . The mo dels, which are affected to some degree, are as follo ws: W eighted Confidence Sharing and V oting. 12 Shallo w Scheme Deep Sc heme Figure 2: Diagram of the in teraction ordering for aggregation schemes for g = 2 : Shallow Sc heme — eac h turn tw o agents from the least numerous groups interact, Deep Scheme — eac h turn a single participant joins the previously formed group. Note that, in principle, agen ts do not know their o wn slop es, so the order of in teractions cannot dep end up on the individual (or group) s i . How ev er, as b oth s W C S and s V ot dep end linearly on s i , av eraging o ver every p erm utation of participan ts yields a result that is pro- p ortional to the arithmetical mean of s i , or h s i . Consequen tly , to in vestigate the influence of the hierarc hical information-aggregation, it is sufficien t to treat each participan t as if his/her p erformance is equal to h s i . F or conv enience, we consider a more general mo del with the parameter (the amplification m ultiplier) dep ending on g (the group size) as follows: s a g ( s 1 , . . . , s g ) = a g s 1 + . . . + s g g . (36) This generalization describ es b oth W CS ( a 2 = √ 2 , a 3 = √ 3 , . . . ) and V oting ( a 3 = 3 / 2 , . . . ), and it allo ws us to give results in an elegant general form. 4.1. Shal low hier ar chy Our justification for the Shallow hierarch y is the following: people may lo cally find their partners and then make a collective decision. Then, iterativ ely , groups of the same (or similar) size mak e the collective decision. The analysis is simple when the n um b er of participan ts is a pow er of g , i.e., n = g k , where k is a natural n umber.Then, ev ery several elementary steps the n um b er of agents is reduced by the factor of g , and agen ts’ slop es are m ultiplied b y the factor a g . In the end, w e get s a g ,S hallow ,g = ( a g ) k h s i = n log g ( a g ) h s i . (37) In particular, for W eighted Confidence Sharing (i.e. a g = √ g ), w e reac h the saturation s W C S,S hallow ,g = √ n h s i . (38) Th us, the aggregation pro cess do es not introduce a decrease in the group p erformance when it is compared to collecting all information at once. The formula (38) holds only for n that is a p o w er of k . How ever, for differen t n s the formula works as a very go o d appro ximation. 13 See Fig. 3 for the numerical results. The relation (i.e., that for groups of size n = g k w e reac h the efficiency of mo del without aggregation or s a g ,S hallow ,g = s a g ,S hallow ) is true for ev ery mo del describ ed by (36) with a g = g α for an y α . In the V oting mo del we need to consider the aggregation in a group of at least three (i.e., g = 3 and a g = 3 / 2 ). Otherwise, it is equiv alent to the Random Resp onder mo del. F or n b eing the p o wer of three we get, s V ot,S hal low,g =3 = n log 3 3 / 2 h s i ≈ n 0 . 37 h s i , (39) whic h w orks as a go o d approximation also for the general o dd n . F or every ev en n , there is at least one pro cess with t wo parties, whic h significantly decreases the total p erformance (as v oting for tw o participants reduces to a coin flip). 4.2. A dding one or two at a time In this case, there is a single group to which single agen ts join one after another. The resulting slop e is as for the W eigh ted Confidence Sharing mo del: s W C S,D eep,g =2 = 2 − ( n − 1) / 2 h s i + n − 1 X i =1 2 − i/ 2 h s i = 1 + √ 2 − 2 1 − n/ 2 h s i (40) and for the V oting mo del for an o dd n and aggregation of three s V ot,D eep,g =3 = 2 ( n − 1) / 2 h s i + 2 ( n − 1) / 2 X i =1 2 − i h s i = 2 − 2 − ( n − 1) / 2 h s i (41) W e see that the Deep hierarc h y is very inefficient. The multiplier of h s i conv erges to a constan t. This leads to the conclusion that simultaneous aggregation (i.e., Shallo w hierarch y) is not only more natural but also m uch more efficient. T o obtain the asymptotic v alue of s a g ,Deep,g , w e can consider an equilibrium situation wherein g − 1 individuals join the group, whic h has already reached the limit s a g ,Deep,g = a g g − 1 g h s i + 1 g s a g ,Deep,g . (42) This leads to: s a g ,Deep,g = g − 1 g /a g − 1 h s i . (43) 4.3. R andom hier ar chy What happ ens b et ween the Shallow hierarch y and the Deep hierarch y? If the groups merge at rand om, is the final s closer to the most efficien t aggregation scheme, or to non- scaling (e.g., adding a few members at a time)? The answer, not surprisingly , lies in b et w een these t wo extremes. 14 W e parameterize time with t starting from 0 . Eac h turn g agents merge in to one of the slop e (36). The current num b er of agen ts is describ ed by n t = n 0 − ( g − 1) t . W e in v estigate ho w the distribution of slop es ρ t ( s ) ev olves with time, which reads ρ t +1 ( s ) − ρ t ( s ) = (44) − g ρ t ( s ) n t + Z ρ t ( s 1 ) n t · · · ρ t ( s g ) n t δ ( s model ( s 1 , · · · , s g ) − s ) ds 1 · · · ds g , where δ is the Dirac delta, i.e., a distribution such that R ∞ −∞ f ( x ) δ ( x − x 0 ) dx = f ( x 0 ) . The difference in distributions ρ t +1 ( s ) − ρ t ( s ) in volv es tw o pro cesses. The first expression means that we take g random agen ts. These agents interact and are remov ed from the distribution. The second expression means that, for ev ery p ossible group of g agen ts (with slop es s 1 , . . . , s n ), a new agen t is created with the slop e s model ( s 1 , . . . , s g ) . Note that w e use integrals, but sum ov er a finite set will give the same result. The parameter w e are most concerned with is the mean slop e, that is h s i t = n − 1 t Z sρ t ( s ) ds. (45) W e multiply (44) by s and integrate R · ds . In our case, (36), this giv es a relativ ely simple result: n t +1 h s i t +1 = n t h s i t − g h s i t + a g h s i t or h s i t = n 0 − ( g − 1) t + a g − 1 n 0 − ( g − 1) t h s i t − 1 . (46) T o obtain the final result, w e need to calculate h s i t max at the p oin t of time when only one agen t remains. W e consider t max = ( n 0 − 1) / ( g − 1) to b e an in teger (e.g., for g = 3 we need to consider an o dd num b er of p articipan ts, for g = 2 there are no restrictions). Then, remem b ering that h s i 0 = h s i and n 0 = n , w e get s a g ,Random,g = t max Y t =1 n 0 − ( g − 1) t + a g − 1 n 0 − ( g − 1) t h s i (47) = Γ 1 g − 1 Γ a g g − 1 Γ n 0 g − 1 + a g − 1 g − 1 Γ n 0 g − 1 h s i (48) ≈ Γ 1 g − 1 Γ a g g − 1 ( g − 1) ( a g − 1) / ( g − 1) × n ( a g − 1) / ( g − 1) × h s i (49) where Γ( x ) is the Euler gamma function, and we applied the Stirling appro ximation. F or g = 2 , we obtain the neat result s a g ,Random,g =2 ≈ 1 Γ( a 2 ) n a 2 − 1 h s i , (50) 15 in particular, for the W eighted Confidence Sharing mo del ( a 2 = √ 2 ) w e get s W C S,Random,g =2 ≈ 1 . 13 n 0 . 41 h s i , (51) whereas for the V oting mo del for g = 3 (and o dd num b er of participants) we get s V ot,R andom,g =3 ≈ 1 . 22 n 0 . 25 h s i . (52) In Fig. 3 , we present plots for W eigh ted Confidence Sharing in aggregation groups of t w o, and V oting in groups of three. W e use b oth analytical appro ximations and numerical results. æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì 10 20 30 40 50 60 n 2 3 4 5 6 7 8 multiplier æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ æ à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à à ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì ì 10 20 30 40 50 60 n 1 2 3 4 multiplier W eighted Confidence Sharing, g = 2 V oting, g = 3 Figure 3: Plot of n umerically obtained multipliers of h s i for mo dels with aggregation of information. W eigh ted Confidence Sharing with g = 2 for aggregation hierarc hies: Shallo w (circles), Deep (diamonds) and Random (squares). V oting with g = 3 , and only for odd num b er of participants, for aggregation hierarc hies: Shallo w (circles), Deep (diamonds) and Random (squares). The lines are the resp ectiv e analytical results from Sec. 4. The numerical results for the Random hierarc hy are taken from one shot, i.e., they are not a veraged. 5. Discussion on results and comparison of mo dels F or each in vestigated mo del, we arrived at the form ula for the slop e of the group as a function of individual slop es, s model ( s 1 , . . . , s n ) = multiplier model ( n ) × mean model ( s 1 , . . . , s n ) . (53) Explicit results can b e found in T ab. 1 and Fig. 4. Note that the form ula is a pro duct of t wo quantities — p erformance as a function of the group size (i.e., the m ultiplier), and the mean of the individual slop es (if the b etter-p erforming contribute more to the outcome). F or equally skilled participan ts, only the multiplier matters, whereas for a group of p eople with high v ariance in p erformance, the t yp e of mean is crucial. W e not only solv ed the problem for a particular list of mo dels, but we also constructed a general framework for the collab orativ e solving of a t wo-c hoice task, i.e., the group p er- formance can b e written as s model ( s 1 , . . . , s n ) = d × n α × s p 1 + . . . + s p n n 1 /p , (54) 16 where parameters d , α and p can b e fitted for any exp erimen tal data, even data not co vered b y the mo dels w e in vestigated. Note that for p = 1 we arrive at the arithmetic mean, for p = 2 w e arrive at the quadratic mean, and p → ∞ we arriv e at the maximum. F or the mo dels we in v estigated, (54) is either an exact solution (RR, WCS, BD, DSS, TH) or a go o d appro ximation (V oting, information aggregation sc hemes). If the result is exact, then d = 1 (to b e consistent with the case of n = 1 ). F or a giv en list of slopes ( s 1 , . . . , s n ) , it is p ossible to write relations with the performances (slop es) for different mo dels whic h read as follows: s RR ≤ s V ot < s W C S ≤ s DS S ≤ s T W . (55) An a v erage-p erforming participan t is exp ected to b enefit from participating in a join t task, unless the resp onder is c hosen at random (in which case there is neither a gain nor a loss). It is somewhat more difficult to compare the Best Decides mo del to the other mo dels, as it highly dep ends on the distribution of the participants’ skills. W e can write s RR < s B D < s DS S ≤ s T W . (56) Ho wev er, how do es the Best Decides mo del relate to the V oting and the W eigh ted Confidence Sharing mo dels? The answ er lies in the comparison of the most skilled participant with the a verage p erformance, i.e., max ( s ) / h s i . If this ratio is greater than ≈ 0 . 8 √ n , the Best Decides mo del outp erforms the V oting. If the ratio is greater that √ n , Best Decides outp erforms the W CS as well. F or example, when there is one exp ert (with s exp > 1 among s non − exp = 1 ) among the total num b er of n participants, then only when s exp > √ n + 1 it is b etter for a group to use the Best Decides strategy . Mo del s ( s 1 , s 2 ) s ( s 1 , s 2 , s 3 ) Mean Multiplier RR s 1 + s 2 2 s 1 + s 2 + s 3 3 arithmetic 1 V ot s 1 + s 2 2 s 1 + s 2 + s 3 2 arithmetic ≈ 0 . 8 √ n BD max( s 1 , s 2 ) max( s 1 , s 2 , s 3 ) maxim um 1 W CS s 1 + s 2 √ 2 s 1 + s 2 + s 3 √ 3 arithmetic √ n DSS p s 2 1 + s 2 2 p s 2 1 + s 2 2 + s 2 3 quadratic √ n TW s 1 + s 2 s 1 + s 2 + s 3 arithmetic n T able 1: Mo dels summary for the six considered mo dels of Sec.3. F or eac h model there is given explicit form ula for tw o and three members. In each mo del the s model has the general form m ultiplier × mean. F or sc hemes of aggregation (T ab. 2), we obtained t w o in teresting results. First, most of the models w e inv estigated are not affected b y the gradual aggregation of information. Second, for mo dels that are affected, the optimal solution is to aggregate information in the smallest p ossible groups, i.e., in g = 2 for W eigh ted Confidence Sharing and g = 3 for V oting. It is p ossible that participan ts’ strategies v ary from trial to trial. In such situations, the 17 æ æ æ æ æ æ æ æ æ æ à à à à à à à à à à ì ì ì ì ì ì ì ì ì ì ò ò ò ò ò ò 0 2 4 6 8 10 n 1 2 3 4 5 6 multilpier ò TW ì WCS DSS à Vot æ RR BD Figure 4: Plot summarizing multipliers for different mo dels. Mo del g Shallo w hierarch y Random hierarch y Deep hierarc hy V ot 3 n 0 . 37 1 . 22 n 0 . 25 2 . 00 V ot 4 n 0 . 16 1 . 15 n 0 . 08 1 . 36 V ot 5 n 0 . 35 1 . 38 n 0 . 19 2 . 15 W CS 2 n 0 . 5 1 . 13 n 0 . 41 2 . 41 W CS 3 n 0 . 5 1 . 25 n 0 . 37 2 . 73 W CS 4 n 0 . 5 1 . 37 n 0 . 33 3 . 00 W CS 5 n 0 . 5 1 . 48 n 0 . 31 3 . 23 T able 2: Summary of information-aggregation results (see Sec. 4) in groups of g agents for affected mo dels, i.e., V oting and W eigh ted Confidence Sharing. F or each model there are provided asymptotic multipliers for three different information-aggregation hierarc hies. In each mo del the s model has the form m ultiplier times arithmetic mean. Note that for V oting grouping in g = 4 is very ineffective (as, in fact, it effectively uses the opinions of three out of four participants). Also note that, asymptotically , the most effectiv e approach (i.e., the b est for very large groups) for the Shallow and Deep aggregation sc hemes is to gather information in the smallest p ossible groups of agents (i.e., in g = 3 for V oting and g = 2 for WCS). 18 outcome w ould b e a mixture of strategies (with w eights w model ), that is P ef f ( c ) = X models w model P model ( c ) , (57) s ef f = X models w model s model . (58) T o distinguish b et w een mo dels, the sole analysis of the group p erformance might not be enough, as (psyc hologically) different mo dels of problem-solving can yield the same p er- formance. One can test mo dified schemes that put additional constrain ts on participan ts’ in teractions to in vestigate communication directly . F or example, contact with other mem- b ers could b e limited to voice or text c hat, or no feedback ma y b e provided. In addition, participan ts might b e ask ed to express their confidence explicitly on a Likert scale. How- ev er, further exp erimen tal work should b e carried out to clarify if and when confidence is sub jectively accessible and can b e communicated explicitly , and when it can b e read from participan ts’ b eha viors. Preliminary results ( ? ) seem to suggest that the latter is common. Also the amount of feedback could range from full information ab out the stimulus to simple information ab out accuracy , to no feedbac k at all. As a reference, it may serv e to examine So cial Decision Sc heme Theory (Da vis, 1973), wherein the group decision is considered to b e a function of individual c hoices, regardless of skills, confidences or the difficulty of the task. In all the mo dels, in teraction is b eneficial for the ov erall p erformance, except for in the Random Resp onder mo del (where the p erformance is the same as the a veraged p erformance of each individual). It is p ossible that b ey ond a certain critical size, groups start to p erform w orse (Grofman, 1978). The mo dels w e consider do not predict suc h a collapse, as they are based on information sharing and do not incorp orate phenomena related to motiv ation and so cial or technical ability to work in groups. 6. Conclusion In the pap er, we examined mathematical mo dels for solving a t wo-c hoice discriminative task by a group of participan ts. W e were in terested in ho w group p erformance dep ended up on the p erformance of the individuals, their w ays of comm unication and their mo des of decision aggregation. As a measure of p erformance, w e used the slop e of the psychometric function (3), whic h indicates how p erformance c hanges with the difficult y of the task. The higher the slop e of s is, the b etter the p erformance of the individual (or the group). W e analyzed a num b er of p ossible mo dels of decision integration in a joint task. As w e mo ved from 2-p erson to n -p erson groups, w e also had to take in to accoun t patterns of in teraction among mem b ers. Obviously , the c hoice of the w ay in whic h aggregate decisions of group members are made is not alwa ys unconstrained. Some of the mo dels, it seems, can b e adopted in almost all group decision situations (such as the Random Resp onder mo del and the V oting mo del). Regardless of the prop erties of the stimuli, p eople can mak e their own decisions and vote. F or the Best Decides mo del, we need to assume that the group p ossess 19 information ab out the members’ p erformances (e.g., from the feedbac k). Other mo dels (i.e., the W eighted Confidence Sharing, the Direct Signal Sharing and the T ruth Wins mo dels) mak e direct assumptions ab out the problem structure or the information that can b e shared. Consequen tly , they can be considered only in particular tasks, in which a certain lev el of confidence in an individual’s own answer can b e reached. Our list of mo dels is b y no means exhaustiv e. W e need to b e aw are of the fact that the presented mo dels are v alid only for our sp ecific situation (collab orativ e decisions in a tw o-choice p erceptiv e task wherein difficulty can be smo othly adj usted). Other tasks ma y b e analyzed within the same paradigm, such as in te- grating information in an individual’s mind. Sev eral exp osures to the same stimulus by a single p erson, p erhaps using differen t senses or with differen t noise lev els, w ould b e another sub ject for further inv estigation. Suc h an approac h is presented in exp erimen ts on sensory in tegration, e.g., b y Ernst and Banks (2002), which serv e as one of the motiv ations for the Bahrami et al. (2010) mo dels. P erhaps collab orativ e decisions in other t wo-c hoice tasks (e.g., verbal or mathematical decisions) could also b e treated in a similar fashion. How ev er, for many other settings, more adv anced mo dels are needed, e.g., ones that tak e in to account more choices or the dynamic interaction b et w een solving a problem in an individual’s mind and communicating that decision to the other participants. Nevertheless, we b elieve that the first step should b e to exp erimentally verify the predicted results of this pap er (with an emphasis on the scaling of the p erformance), b efore pro ceeding to more adv anced theoretical mo dels. A c kno wledgements The w ork w as supported b y EC EuroUnderstanding grant DR UST to JRL, Spanish MINCIN pro ject FIS2008-00784 (TOQA T A) and ICF O PhD sc holarship to PM, and the P olish Ministry of Education and Science (grants: N301 159735, N518 409238) to DP . References Abramo witz, M., Stegun, I. A., 1965. Handb o ok of Mathematical F unctions: with F orm ulas, Graphs, and Mathematical T ables. Dov er Publication Bahrami, B., Olsen, K., Latham, P . E., Ro epstorff, A., Rees, G., F rith, C. D., Aug. 2010. Optimally In teracting Minds. Science 329 (5995), 1081–1085. 10.1126/science.1185718. Clark, A., Aug. 2006. Language, embo dimen t, and the cognitive niche. T rends in cognitive sciences 10 (8), 370–4. 10.1016/j.tics.2006.06.012. Corfman, K. P ., Kahn, B. E., Jan. 1995. The influence of member heterogeneity on dy ad judgmen t: Are t wo heads b etter than one? Mark eting Letters 6 (1), 23–32. 10.1007/bf00994037. Da vis, J. H., 1973. Group decision and so cial in teraction: A theory of social decision schemes. Psychological Review 80 (2), 97–125. 10.1037/h0033951. Ernst, M. O., Banks, M. S., Jan. 2002. Humans integrate visual and haptic information in a statistically optimal fashion. Nature 415 (6870), 429–33. 10.1038/415429a. Grofman, B., 1978. Judgmental competence of individuals and groups in a dichotomous c hoice situation: Is a ma jority of heads b etter than one? 10.1080/0022250x.1978.9989880. Hastie, R., Kameda, T., Apr. 2005. The robust b eaut y of ma jority rules in group decisions. Psychological review 112 (2), 494–508. 10.1037/0033-295x.112.2.494. 20 Henry , R., Ma y 1995. Improving Group Judgment A ccuracy: Information Sharing and Determin- ing the Best Member. Organizational Behavior and Human Decision Pro cesses 62 (2), 190–197. 10.1006/obhd.1995.1042. Hill, G. W., 1982. Group v ersus individual p erformance: Are N+1 heads b etter than one? Psychological Bulletin 91 (3), 517–539. 10.1037/0033-2909.91.3.517. Hutc hins, E., Lintern, G., 1995. Cognition in the Wild. V ol. 262082314. MIT press Cambridge, MA. Kerr, N. L., Tindale, R. S., Jan. 2004. Group p erformance and decision making. Annual review of psychology 55, 623–55. 10.1146/ann urev.psych.55.090902.142009. Kirsh, D., Jan. 2006. Distributed cognition: A metho dological note. Pragmatics & Cognition 14 (2), 249–262. 10.1075/p c.14.2.06kir Laughlin, P . R., Kerr, N. L., Davis, J. H., Halff, H. M., Marciniak, K. A., 1975. Group size, member ability , and so cial decision schemes on an intellectiv e task. Journal of Personalit y and So cial Psychology 31 (3), 522–535. 10.1037/h0076474. Piau, D., 2011. A simpler solution of the integral R x 1 + ... + x n ≥ a exp − π x 2 1 + . . . + x 2 n dx 1 · · · dx n . Mathe- matics - Stac k Exchange. http://math.stackexchange.com/q/61215 (v ersion: 2011-09-01) Sorkin, R. D., Hays, C. J., W est, R., 2001. Signal-detection analysis of group decision making. Psyc hological Review 108 (1), 183–203. 10.1037/0033-295x.108.1.183. App endix A. Appro ximations P ( c ) can b e expanded in T a ylor series of c around c = − b . P ( c ) = P [ − b + ( c + b )] (A.1) = P ( − b ) + ( c + b ) P 0 ( − b ) + ( c + b ) 2 2 P 00 ( − b ) + ( c + b ) 3 6 P 000 ( − b ) + . . . (A.2) where P ( i ) ( − b ) can b e found explicitly using (1), P ( i ) ( c ) = 1 σ i H ( i ) ( c + b σ ) . (A.3) In particular H (0) = 1 / 2 , H 0 (0) = 1 / √ 2 π , H 00 (0) = 0 , H 000 (0) = − 2 / √ 2 π . Consequen tly , P ( c ) = 1 2 + ( c + b ) √ 2 π σ + O ( c + b σ ) 3 , (A.4) that is, the appro ximation error of taking the linear approximation is of the order ( c + b ) 3 /σ 3 as the quadratic term v anishes. Plugging c = 0 we obtain P (0) = 1 2 + b √ 2 π σ + O ( b σ ) 3 (A.5) = 1 2 + sb + O [( sb ) 3 ] (A.6) and similarly , the deriv ativ e of (A.4) in 0 is P 0 ( c ) | c =0 = 1 √ 2 π σ + 1 √ 2 π σ O ( b σ ) 2 (A.7) = s 1 + O ( s 2 b 2 ) . (A.8) 21 The last equation giv es the approximate equation for slop e (7). Another expression P (0) − 1 / 2 P 0 ( c ) | c =0 = b + bO [( sb ) 2 ] 1 + O [( sb ) 2 ] = b 1 + O ( s 2 b 2 ) (A.9) yields in the appro ximate equation for bias (8). App endix B. V oting P V ot ( c ) = b n − 1 2 c X k =1 X ~ i [1 − P i 1 ( c )] · · · [1 − P i k ( c )] P i k +1 ( c ) · · · P i n ( c ) (B.1) + 1 2 X ~ i [1 − P i 1 ( c )] · · · h 1 − P i n/ 2 ( c ) i P i n/ 2+1 ( c ) · · · P i n ( c ) if n is ev en , After plugging the linearization (A.4) in the ab o ve, and using µ i = s i ( b i + c ) , each part has the form of 1 2 − µ i 1 + O ( µ 3 i 1 ) · · · 1 2 − µ i k + O ( µ 3 i k ) (B.2) × h 1 2 + µ i k +1 + O ( µ 3 i k +1 ) i · · · 1 2 + µ i n + O ( µ 3 i n ) (B.3) = 1 2 n − 1 2 n − 1 ( µ i 1 + . . . + µ i k ) + 1 2 n − 1 µ i k +1 + . . . + µ i n (B.4) + O ( µ 2 1 ) + . . . + O ( µ 2 n ) (B.5) After applying p erm utations to the main part (i.e., without the error estimation) w e get 1 2 n n k + 1 2 n − 1 n k [ − k + ( n − k )] µ 1 + . . . + µ n n (B.6) = 1 2 n n k + n 2 n − 1 − n − 1 k − 1 + n − 1 k µ 1 + . . . + µ n n , (B.7) whic h is easy to b e summed. The first comp onen t sums to 1 / 2 . In the second, binomial co efficien ts cancel pairwise, except for n − 1 0 − 1 = 0 and n − 1 b ( n − 1) / 2 c lea ving only n − 1 k for k = b ( n − 1) / 2 c . Consequen tly , when n is o dd, one gets P V ot,odd ( c ) = 1 2 + n 2 n − 1 n − 1 ( n − 1) / 2 µ 1 + . . . + µ n n + O ( µ 2 1 ) + . . . + O ( µ 2 n ) (B.8) and for ev en n P V ot,ev en ( c ) = 1 2 + n 2 n − 1 n − 1 ( n − 2) / 2 µ 1 + . . . + µ n n + O ( µ 2 1 ) + . . . + O ( µ 2 n ) . (B.9) After the differen tiation one obtains the slop e (7) and the bias (8). 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment