Matching Pursuits with Random Sequential Subdictionaries
Matching pursuits are a class of greedy algorithms commonly used in signal processing, for solving the sparse approximation problem. They rely on an atom selection step that requires the calculation of numerous projections, which can be computational…
Authors: Manuel Moussallam, Laurent Daudet, Ga"el Richard
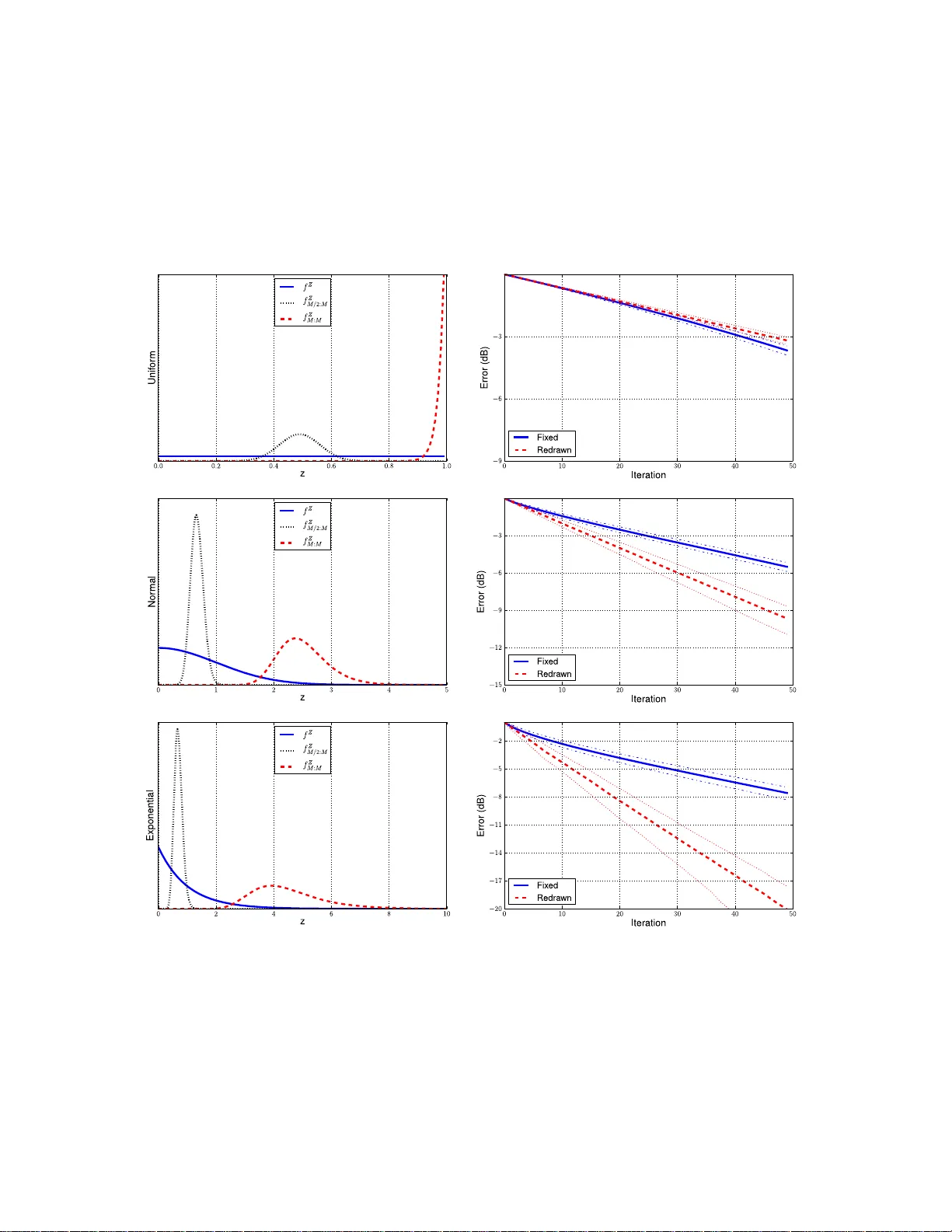
Matc hing Pursuit s with Random Sequential Sub dict ionar ies Manuel Moussallam 1 , Laurent Daudet 2 , 3 and Ga¨ el Richard 1 1 Institut T elecom - T elecom ParisT ech - CNRS/L TC I 37/ 39, rue Dar eau 75 014 Paris, F rance 2 Institut Langevin - ESPCI ParisT ech - Paris Diderot Universit y - UMR7587 1, r ue Jussieu 7 5238 P ARIS CEDEX 0 5 3 Institut Universitaire de F ra nce contact: manuel.moussallam@telecom-par istech.fr Abstract Matching pursuits a re a clas s o f gre edy a lgorithms co mmonly used in signal pr o cessing, for s o lving the spars e approximation pro blem. They rely on an atom selection step that requires the calcula tion o f numerous pro jections, which can b e co mputatio nally cos tly for lar ge dictiona ries a nd burdens their comp etitiveness in co ding applications. W e pr op ose using a non adaptive random sequenc e of sub dictionaries in the decomp osi- tion pro ces s , thus parsing a larg e dictionary in a probabilistic fas hio n with no a dditio na l pro jection cost no r parameter estimatio n. A theoretical mo deling based o n order statistics is provided, along with expe rimental evidence showing that the novel algorithm can b e efficien tly used on s parse approximation problems. An application to audio signal compres sion with multiscale time-fr equency dictionar ie s is present ed, along with a dis cussion of the co mplexity and practical implemen tations. k eywords Matching Pursuits ; Random Dictionaries; Sparse Approximation; Audio Signal Compress ion 1. In tro d uction The a bility to describ e a complex pro cess a s a combination of few simpler ones is often critical in en- gineering. Signal pro cessing is no exception to this par adigm, also known in this context as the spar s e representation problem. Y et rather s imple to ex po se, its combinatorial nature has led resea rchers to dev e lop so many bypassing strateg ie s that it ca n b e co ns idered a self- s ufficient to pic . Throughout these years of work, many additiona l benefits were found ar ising from the dimensio nality reduction. Firstly , sparsity allows faster pro cessing, a nd biologically inspired mo dels [37] sugg est that the mammalian brain takes a dv antage of it. Secondly , it helps reducing bo th storage and bro adcasting costs [34]. Finally , it ena bles semantic characterization, since few significant ob jects carr y most of the signals infor mation. The central problem in sparse approximation theory may be written as such: Given a signal f in a Hilbe r t space H and a finite-size dictionar y Φ = { φ γ } of M unit norm vectors ( ∀ γ ∈ [1 ..M ] , k φ γ k 2 = 1 ) in H , ca lle d atoms, find the smallest ex pansion o f f in Φ up to a reconstructio n erro r ǫ : min k α k 0 s.t. k f − M X γ =1 α γ φ γ k 2 ≤ ǫ (1) where k α k 0 is the num b er of non-zer o elements in the se q uence o f weigh ts { α γ } . E quiv alently , one se eks the subset o f indexes Γ m = { γ n } n =1 ..m of atoms of Φ a nd the co r resp onding m non ze ro weights { α γ n } solving: min m s.t. k f − f m k 2 ≤ ǫ (2) Pr eprint submitte d to Elsevier Octob er 24, 2018 where f m = P m n =1 α γ n φ γ n is called a m - term approximant of f . A corollar y problem is also defined, the sparse recov e ry problem, where one assumes that f has a spars e suppo rt Γ m in Φ ( m b eing m uch smaller than the space dimension) and tr ies to recover it (from noisy or fewer measurement than the signals dimens io n). In the sparse approximation problem, no suc h assumption is made and one just seeks to r etrieve the b est m - term approximant of f in the sense of minimizing the reconstruction error (or any ada pted divergence measur e). Many pr actical pr oblems b enefit from this mo deling, f rom denoising [1 4, 4] to fea ture e xtraction and signal compressio n [15, 34]. Unfortunately , problem (1) is NP- hard and an alternate stra tegy needs to be adopted. A first class of existing metho ds ar e based on a r elaxation o f the sparsit y constraint using the l 1 -norm instead o f the non- conv ex l 0 [42, 4], thus solv ing a quadra tic program. Alternatively , greedy alg orithms can pro duce (potentially sub o ptimal) solutions to problem (1) by iteratively selec ting atoms in Φ. Matching P ursuit (MP) [27] and its v a riants [3 0, 22, 6, 5, 3] ar e instances o f such greedy alg orithms. A c o mparative study of many exis ting alg orithms can b e found in [11]. MP-like algor ithms hav e simple underlying principles allowing intuitiv e understanding, and efficient implementations ca n be found [24, 26]. Such algorithms co nstruct an approximant f n after n iterations by alternating t wo s teps: Step 1 Select an a tom φ γ n ∈ Φ and app end it to the supp ort Γ n = Γ n − 1 S γ n Step 2 Update the a pproximation f n according ly . un til a stopping cr iterion is met or a p er fect decomp os ition is found (i.e f n = f ). This tw o-step g eneric description defines the cla ss of Gener al MP a lgorithms [20]. When designing the dictionary , it is imp orta nt that ato ms lo ca lly ressemble the signal tha t is to b e represented. This correla tion betw ee n the sig nal and the dictio na ry atoms ens ures that gree dy algorithms select ato ms that remove a lot of energy fro m the residual). F or so me classes of signals (e.g. audio), the v ariety of encountered wa veforms implies that a large n umber of atoms m us t b e considered. Even tually , one is interested in finding sparse expansions of signals in large dictio naries at reasona ble complexity . Metho ds addressing spar se recov er y pro blems hav e b enefited fro m rando m dictio nary design prop erties (e.g with MP-like algo rithms [4 3, 3]). Randomness in this context is used for spreading information that is lo calized (on a few non-z e ro co efficien ts in a lar g e dictionary) amo ng few er meas urement vectors. In the sparse approximation context tho ug h, the use for r andomness is less obvious. Much effort has bee n done on desig ning structured dictionar ies that exhibit go o d conv ergenc e pattern at r easonable costs [34, 6, 23]. Typical dictiona ries with limited size are based o n Time-F requency transforms such as window F ourier trans forms (also referr e d to as Gab or dictiona ries) [27, 19], Discrete Co sine [34], wa velets [37] or unions of b oth [6]. Such dictionaries ar e made o f atoms tha t are lo ca lized in the time-frequency plance, which gives them enough flexibility to repr esent complex non sta tionary signals . How ever the set o f considered lo calization reflects, in practice, a compromise. Considering a ll p ossible localiz ations is, in theor y , p ossible for discrete signals and dictionar ies, howev er it yields v ery large and r edundant dictionaries which rais es computational iss ues. The standard dictionary design [27] co nsiders a fixed subset of lo calizatio ns is arg uably a go o d option but it can ne ver b e o ptimal for all p os sible signals. Adapting the subset to the signal is then p os sible, but it intro duces additional complexity . Finally , one may consider us ing multiple r andom subsets, p erform multiple deco mpo sitions and av era ge them in a p o st-pro cess ing step [13]. In this pap er, an other optio n is considered: the use of randomly v a r ying sub dictiona ries at each itera tio n during a single decomp osition. The idea is to av o id the additional complexity of a dapting the dictionary to the signal, or of ha ving to p erfor m mult iple decomp ositio ns, while still improving on the fixed dictionary strategy . A parallel can b e tr a ced with quantization theory . Somehow, limiting dictionar y size amounts to dis- cretizing its atoms parameter s pace. This q uantization int ro duces noise in the deco mp o sition (i.e error due to dictionary-related mo del mismatch). Adaptive qua nt ization r educes the nois e and multiple quantization allow to av er age the nois e out. But the prop o sed technique is clo ser to the dithering technique [44 ] and more generally to th e sto chastic r esonance theory , w hich shows how a mo derate a mount of a dded noise can increase the b ehavior of many non linea r systems [16]. 2 Figure 1: Blo ck diagr am for Gener al MP algorithms. An input sig nal f is de c omp ose d onto a dictionary Φ by iter atively sele cting atoms φ γ n (Step 1) and up dating an appr oximant f n (Step 2). The pr o p osed metho d only r elies on a slight mo dification of step 1 and ca n therefore be applied to many pursuit algorithms. In this work, we fo cus on the approximation problem. Exp eriments on real audio data demonstrate the p otential be nefits in sig nal co mpr ession and pa rticularly in low-bit-rate a udio co ding. It should b e e mphasized tha t, as such, it is not well suited for spars e recovery problems such a s in the compressed sensing sc heme [9]. Indeed, sea rching in random subsets of Φ ma y burden the a lgorithm abilit y to retr ieve true t rue spa rse supp o rt of a s ignal in Φ. The r est of this pap er is organized as follows. Section 2 reca lls the standard Matching Pursuit algor ithm and some of it s v a riants. Then, w e introduce the prop os ed m o dification of Step 1 in Section 3 and exp ose some theoretical j ustifications based on a probabilistic mo deling of the decomp osition pro cess . A practica l application is pres ented in Section 4 as a pro of of concept with audio signals. Extended discussion o n v ar ious asp ects of the new metho d is pr ovided in Sec tion 5. 2. Matc hing Pursui t for Sparse Signal Represen tations 2.1. Matching Pu rsuit F r amework The Matc hing Pursuit (MP) algorithm [27] and its v a riants in the General MP fa mily [20] a ll sha r e the same underlying iterative tw o-step structure, as describ ed by Figur e 1. Sp ecific algorithms differ in the wa y they per form the atom selection criter ia C (Step 1), and the approximan t construction A (Step 2). Standar d MP a s originally defined in [27 ] is g iven by: C (Φ , R n f ) = arg max φ γ ∈ Φ |h R n f , φ γ i| (3) A ( f , Φ Γ n ) = n − 1 X i =0 h R i f , φ γ i i φ γ i (4) where R n f denotes the residual at iteration n (i.e R n f = f − f n ). O rthogo na l Matching Pursuit (OMP) [30] is based on the same sele c tion criteria, but the a pproximan t up date step ens ures orthogo na lity betw een the residual a nd the subspace spanned b y the alr eady selec ted a toms V Γ n = span { φ γ n } γ n ∈ Γ n A OM P ( f , Φ Γ n ) = P V Γ n f (5) where P V is the orthonor mal pro jector onto V . The algo r ithm stops when a predefined criterion is met, either an approximation threshold in the form of a S ignal-to-R esidual R atio (SRR): S RR ( n ) = 10 log k f n k 2 k f − f n k 2 (6) or a bit budge t (equiv alently a num ber of itera tions) in co ding applica tions. 3 Figure 2: Time F r e q uency grids define d by Φ a r ed undant mo nosc ale time- fr e quenc y dictionary, Φ I 1 and Φ I 2 , two subsets of Φ . Atoms fr om Φ I 2 ar e almost the same as Φ I 1 but with an additional time and/or fr equency offset. 2.2. We ak M P Often, the size of Φ prevents the us e of the criter ion C as defined in 3, esp ecially for infinite-siz e dictionaries. Instead, one ca n sa tisfy a w eak selec tion r ule C weak (Φ , R n f ) = φ γ weak such that: |h R n f , φ γ weak i| ≥ t n sup φ γ ∈ Φ |h R n f , φ γ i| (7) with 0 < t n ≤ 1. In practice, a weak selection step is implemented by limiting the num b er of a tomic pro jections in which the maximum is sear ched. This is equiv ale ntly seen as a subsampling of the la r ge dictionary Φ. T emlyak ov [41] prov ed the conv er gence when P t n n < ∞ and sta bilit y prop erties have been studied b y Gr ib o nv al et al in [20]. Let us denote Φ = { φ γ } a lar ge multiscale time-frequency dictionary with atom parameter γ living in S × U × Ξ a finite subset of R + × R 2 . S denotes the set of analysis sc a les, U is the s et of time index es a nd Ξ the set of frequency index e s (see for exa mple [34]). Co mputing C (Φ , R n − 1 f ) require s, in the gener al case, the co mputation of all atom pro jections h R n − 1 f , φ γ i which ca n b e prohibitive. A w eak s tr ategy cons ists in computing only a subset of these pro jections, thus using a co arse sub dictionary Φ I ⊂ Φ, which ca n b e s een as equiv alent to a subs a mpling of the pa r ameter space S × U × Ξ. F or instance, time index e s ca n b e limited to fra ctions of the a na lysis window size. Reducing the size of the dictionary is interesting for co ding purp oses. Actually , the sma ller the atom parameter s pace, the cheap e r the enco ding of ato m indexes. Figure 2 shows an example of suc h dictionary subsampling in a time-frequency plane. Each p oint r epresents the centroid of a time-frequency a tom φ γ , black circles cor r esp onds to a coarse subsampling of the parameter space and constitute the subdictionar y Φ I 1 ⊂ Φ. The f ull dictionary Φ fig ured b y the sma ll r ed c rosses , is 1 6 times bigger tha n Φ I 1 . How ever, the choice of subsampling has consequences on the deco mpo sition. Figure 2 pictur es an exa mple of a different coa rse subdictio na ry defined by a nother index subset Φ I 2 ⊂ Φ. F or mo st signals, the decomp o- sition w ill b e different when using Φ I 1 or Φ I 2 . Moreover, ther e is no easy w ay to guess which sub dictionar y would provide the fastest and/or most s ignificant decomp osition. Using one of these sub dictionaries instead of Φ implies that a v ailable atoms may be less s uited to lo cally fit the signals. MP would thus crea te e ne r gy in the time frequency plane where there is none in the signal, an artifact known as dark energy [3 8]. 2.3. Higher R esolution and L o c al ly-A daptive M atching Pu r s uits T o tackle this issue, high res olution metho ds have b een s tudied. First, a mo dification of the atom selection criterion has b e en proposed b y Jaggi et al [22] that not only takes energy in to account but also lo ca l fit to the signal. Other artifact preven ting metho ds have also been intro duced (e.g for pr e-echo [34] or dark energy [39]). A sec ond class of b y passing strategie s are lo cally-a daptive pursuits. An atom is first selected in the 4 coarse sub dictiona r y Φ I , then a lo cal o ptimization is p erformed to find a neigh b or ing ma ximum in Φ. Mallat et al prop os ed a Newton metho d [27], Go o dwin et al fo cused on phase tuning [17], Grib onv al tuned a chirp parameter [18] a nd Christense n et al a ddressed b o th phase and frequency [5, 40]. An equiv alent strategy is defined for ga mmachirps in [25]. Lo cally-adaptive methods in time- fr equency dictionaries implement a form of time and / or frequenc y rea ssignment of an a tom se le cted in a coa rse sub dictiona ry . These strategies yield repr esentations in the large dictio nary at a reduced cost. In many applications, the faster residuals energy decay compensates the slight computational overhead of the loca l optimization. In a previous work [28], we emphasize d the usefulness of lo cally-a daptive methods for shift-inv aria nt rep- resentation and s imilarity detectio n in the transfor m domain. Tho ugh, the resulting atoms a re from the large dictiona ry , i.e their indexes are more costly to enco de. Moreov er, these method requir e an additional parameter estimation step that may increase the overall complexity . 2.4. Statistics and MP Different appr oaches hav e b een propose d to enhance MP algorithms using statistics. F errando et al [13] were (to our knowledge) the first to prop os e to run multiple sub-optimal pursuits and retrie ve meaning ful atoms in a n a p osteriori averaging step. A somehow similar approa ch is introduced in [10] where the author s emphasize a lack of precis ion of their repr esentation due to the structure of the applied dictiona ry . T o avoid these decomp osition artifacts, they follow a Mon te-Carlo like method, where the set of atom parameter is randomly chosen befo r e each decomp osition follow ed by an av erag ing step. Elad et al [12] used the same par adigm fo r supp or t r ecov e r y , taking adv antage of man y subo ptimal representations instea d of a single one of higher pr ecision. Similar a pproaches ar e adopted within a Bay esian framework in [36, 45], although the subset selection is a b ypro duct of the choice of the prior. Their work is related to the branch of compressed sensing that uses pursuits a nd random measur ement matrices to r etrieve sparse suppo rts of v arious classes of high dimensional signals [43]. A recent work by Divek ar et al [7] prop o sed a form of proba bilis tic pursuit. Such work differs from ours in the sense that it is signal-ada ptive a nd tuned for the suppo r t r ecov er y problem. 3. Matc hing Pursui ts with Sequences of Sub dictionaries 3.1. Pr op ose d new algorithm This pap er pres ent s a mo dification of MP which consists in changing the subdic tio nary at ea ch iter a tion. Let us define a sequence I = { I n } n ∈ [0 ..m − 1] of length m . Ea ch I n is a se t of indexes of atoms from Φ . At iteration n , the algo rithm can only select an ato m in the subdictionary Φ I n ⊂ Φ. W e call such algor ithms Sequential Subdictio naries Matching Pursuits (SSMP). This method is illustrated by Fig ur e 3. When the sequence I is random, we call such algorithms Random Sequential Sub dictionaries (RSS) Pursuits. The propo sed modification can b e applied to an y algorithm from the Genera l MP family (RSS MP , RSS OMP , etc..). After m itera tions, the algo rithm outputs an approximant of the for m (8) f m = m − 1 X n =0 α n φ I n γ n (8) where φ I n γ n ∈ Φ I n . SSMP can b e seen as a W ea k General MP algor ithm as descr ib ed in [20]. Indeed, it amounts to reducing the atom selec tio n choice to a s ubs e t of Φ, whic h defines the we ak selec tio n rule (7). The orig inality of this work is the fact that we c hange the s ub dictio na ry a t each iter ation while it is usually fixed during the whole decomp osition. The sequence of subdictio na ries is known in adv ance and is thus signal indep endent. The s equence I might be built such that lim m →∞ S m − 1 n =0 Φ I n = Φ, althoug h in this case, the mo dified pursuit is not equiv alent to a pursuit using the large dictio nary Φ. How ever, it allows the sele c tion o f ato ms from Φ that were not in the initial sub dictionary Φ I 0 . 5 Figure 3: Blo ck diagr am of Se quential Sub dictionaries Pursuits (SSMP). St ep 1 is mo difie d so as to have the se ar ch t ake plac e in a differ ent sub dictionary at e ach ite r ation. The dictionary subsampling i s c ontr ol le d b y a fixe d pr e- defined sequenc e I . 3.2. A firs t example Let Φ be a Gabo r dictionary . Each atom in Φ is a Gab or atom that can b e pa rameterized b y a triplet ( s, u, ξ ) ∈ S × U × Ξ defining its scale, time and frequency lo calization res p e ctively . The co nt in uous-time version of s uch atom is given b y: φ s,u,ξ ( t ) = 1 √ s g t − u s e iξ ( t − u ) (9) where g can b e a Gaussia n or Hann window. A discrete Gab or dictionary is obtained by sa mpling the parameter space S × U × Ξ (and the window g ). Let N b e the signal dimension and K b e the num b er of Gab or scales ( s 1 , s 2 , .., s K ). F or each scale s k , u takes in teg er v alues be t ween 0 and N and ξ from 0 to s k / 2. The tota l size of Φ in this setup is M = P K k =1 s k N 2 atoms. Let f ∈ R N be a m -sparse signal in Φ, meaning that f is the s um o f m (randomly c hosen) components from the full dictionary Φ. W e are interested in minimizing the reco nstruction error ǫ = k f − f n k 2 k f k 2 given the size constraint n = m/ 2. Let Φ I 0 be a sub dictionary of Φ defined by selecting in each sc a le s k only a toms a t certain time lo- calizations. Subsampling the time ax is by half the window leng th is standard in audio pro ces sing (i.e. ∀ u ∃ p ∈ [0 , ⌊ 2 N /s k ⌋ − 1 ] , s .t. u = p.s k / 2). Φ I 0 can be seen as a subsampling of Φ. The size of Φ I 0 in this setup is down to K × N atoms. MP using Φ I 0 during the whole decomp osition is a sp ec ia l case of SSMP where all the subdictio naries are the same. W e la b e l this algorithm Coarse MP . Now let us define a pseudo-random sequence of subdictio na ries Φ I n that a re transla ted versions o f Φ I 0 . Each Φ I n has the s a me size than Φ I 0 but its a toms are parameterized as s uch: ∀ u ∃ p ∈ [0 , ⌊ 2 N /s k ⌋ − 1] , s.t. u = p.s k / 2 + τ n k where τ n k ∈ [ − s k / 4 , s k / 4] is a tr anslation pa rameter differe nt for e ach scale s k of ea ch sub dic tio nary Φ I n . Each Φ I n can also b e see n as a different subsa mpling of Φ. The s ize of each sub dictionar y Φ I n is th us a lso K × N . MP using the sequence of subdictiona ries Φ I n is labeled Random SSMP (RSS MP). Finally , a MP using the full dictionary Φ during the whole pro cess is lab eled F ull MP . W e compa re the reconstructio n erro r achiev ed with these three algor ithms (i.e Coar s e MP , RSS MP and F ull MP). Figure 4 gives corr esp onding results with the following setting: N = 10000 , m = 30 0, S = [32 , 12 8 , 512 ] and thus M = 84 0000 , averaged ov er 1000 runs. Althoug h RSS MP is constra ined at each iteration to choo se only within a limited subset of atoms, it exhibit an er ror decay close to the one of F ull MP . If f was exactly sparse in Φ I 0 , then keeping the fixed subdictio nary (Coarse MP) would provide a faster decay than using the random sequence (RSS MP). Ho wever in our setup, such case is unlik ely to happen. As stressed b y man y author s cited above, the choice o f a fixed subdictiona ry is often suboptimal with r e sp ect to a whole class of signa ls, as it may not hav e the basic in v a riants one may exp ect from a goo d repr esentation (for ins tance, the shift inv ar iance). A matter of concern is now to determine when RSS MP per forms b etter than Co arse MP in terms of approximation erro r decay . In the next subsection w e mak e use of order statistics to mo del the b ehavior of the tw o str ategies (i.e. MP with fixed coarse sub dictionar y and MP with v ar ying sub dictionar ies) dep ending on the initial distribution of pr o jections. 6 0 2 0 4 0 6 0 8 0 1 0 0 1 2 0 1 4 0 1 6 0 Iteration 3 .0 2 .5 2 .0 1 .5 1 .0 0 .5 0 . 0 Error (dB) Coarse MP RSS MP Full MP Figure 4: Evolution of normali zed appro ximation error ǫ w i th Match ing Pursuit using a fixed sub dictionary (Coa rse MP), a pseudo random sequence of subdictionaries (RSS MP) and the full original dictionary (F ull M P). Results av eraged ov er 1000 runs. 3.3. Or der Statistics W e need to in tr o duce a few too ls from the or der sta tistics theory . The in terested reader can refer for example to [29, 21] for mor e details. Let z 1 , z 2 , ..z n be n i.i.d samples dr awn from a contin uous r andom v ariable Z with probability dens ity f Z and a distribution function F Z . Let us denote Z 1: n , Z 2: n , .., Z n : n the o rder statistics. The random v a r iable Z i : n represents the i th smallest element of the n samples. The probability density of Z i : n is deno ted f Z i : n and is giv en by: f Z i : n ( z ) = n ! ( n − i )!( i − 1)! F Z ( z ) i − 1 f Z ( z )(1 − F Z ( z )) n − i (10) The densit y of extr emum v alues is easily derived from this equation, in par ticular the maximum v alue of the sequence has densit y: f Z n : n ( z ) = nF Z ( z ) n − 1 f Z ( z ) (11) The moments of the o r der sta tis tics are given by the formula: µ ( m ) i : n = E ( Z m i : n ) = Z ∞ −∞ z m f Z i : n ( z ) dz (12) And the v a riance is denoted σ 2 i : n . F or conv enience we will write the exp ectation µ i : n = µ (1) i : n . 3.3.1. Or der st atistics in an MP fr amework Given the greedy nature of MP , a statistical modeling of the series of pro jection ma x ima g ives meaningful insights ab out the overall conv er gence prop erties. Let f b e a signal in R N . At the first iter ation, the pro jection of the residual R 0 f = f ov e r a complete dictionary Φ of M unit normed atoms { φ i } i ∈ [1 ,M ] ( M > N ) is given by: ∀ i ∈ [1 ..M ] , α i = h R 0 f , φ i i (13) Let us denote z i = | α i | and consider them as M i.i.d samples drawn from a random v aria ble Z living in [0 , p k f k 2 ]. No te that s uch an assumption holds o nly if o ne considers that a toms in Φ are almost pairwise orthogo nals, i.e that Φ is quasi-incohe r ent. MP s elects the atom φ γ 0 = arg max z i whose weigh ts a bsolute v alue is giv en by the M th order statistics o f Z : Z M : M . | α γ 0 | = max φ γ ∈ Φ |h R 0 f , φ γ i| = Z M : M (14) 7 Standard MP co nstructs a residual by removing this atoms co ntribution and iter ating. Hence, weigh ts of selected a toms r emains independent and at iteration n the M − n -th order statistics of Z describ es the s elected weigh t: | α γ n | = max φ γ ∈ Φ |h R n f , φ γ i| = Z M − n : M (15) the energy co nserv ation in MP a llows to derive (16). k f k 2 = k R n f k 2 + n − 1 X i =0 | α γ i | 2 (16) Combining (16) and (15 ) and ta king the expe c ta tion, o ne gets (17) E ( k R n f k 2 ) = k f k 2 − n − 1 X i =0 µ (2) M − i : M (17) W e recog nize the seco nd order moment of µ (2) M − i : M = σ 2 M − i : M + µ 2 M − i : M . Similarly , from (1 6 ) we can derive the v ariance o f the estimato r: V a r ( k R n f k 2 ) = n − 1 X i =0 n − 1 X j =0 cov ( Z 2 M − i : M , Z 2 M − j : M ) (18) Given a distr ibution mo de l for Z , Equa tions (1 7) and (18) pr ovide mean and v ariance estimates of the residuals energy decay with a standa rd MP o n a q uasi-incoher ent dictionary Φ. 3.3.2. R e dr awing pr oje ction c o efficients: changing the dictio naries The idea at the core of the new algorithm descr ib ed in section 3 .1 is to draw a new s et o f pro jections at each iteration b y changing the dictionar y in a controlled manner. Let us no w assume that we know a sequence of co mplete quasi-incoher ent dictionaries { Φ i } i ∈ [0 ,n ] . Let us make the additional assumptions that the pro jection o f f has the same distribution in all these dictionaries. A t the first iteration, the pro cess is similar , so the atom φ γ 0 in Φ 0 is sele c ted as arg max φ γ ∈ Φ 0 | R 0 f , φ γ | with the sa me weigh t as (1 4). After s ubtracting the a tom we hav e a new re s idual R 1 f . The tric k is no w to search for the mo s t corr elated atom in Φ 1 . The a bsolute v alues of the corr esp onding inner pr o ducts define a new se t o f M i.i.d s amples z 1 i : ∀ i ∈ [1 ..M ] , z 1 i = | α i | = |h R 1 f , φ i i| (19) Let us assume that the z 1 i samples have the same distr ibution law than the z i , exc e pt that the sample space is now smaller b ec a use R 1 f has less energy than f . This means the new random v aria ble Z 1 is distributed like Z × k R 1 f k k f k . Let us denote Z 1 M : M the M -th order statistic for Z 1, its seco nd moment is: E ( Z 1 2 M : M ) = E ( Z 2 M : M ) . E ( k R 1 f k 2 k f k 2 ) + c ov ( Z 2 M : M , k R 1 f k 2 k f k 2 ) (20) and we know tha t k R 1 f k 2 = k f k 2 − Z 2 M : M hence: cov ( Z 2 M : M , k R 1 f k 2 ) = − cov ( Z 2 M : M , Z 2 M : M ) = ( µ (2) M : M ) 2 − µ (4) M : M (21) which leads to : E ( Z 1 2 M : M ) = µ (2) M : M . (1 − µ (2) M : M k f k 2 ) + 1 k f k 2 ( µ (2) M : M ) 2 − µ (4) M : M = µ (2) M : M − µ (4) M : M k f k 2 8 Since the new r esidual R 2 f has ener g y k R 2 f k 2 = k R 1 f k 2 − Z 1 2 M : M , taking the exp e c tation: E ( k R 2 f k 2 ) = k f k 2 − 2 µ (2) M : M + µ (4) M : M k f k 2 (22) and we se e higher moments of the M -th order statistic a pp ear in the residuals ener gy decay formula. A t the n -th itera tio n of this modified pursuit, we end up with a r ather s imple formula (23) where higher moments of the M -th order statistic of Z app ear. E ( k R n f k 2 ) = k f k 2 + n X i =1 ( − 1) j n i µ (2 i ) M : M k f k 2( i − 1) (23) Similarly , a v ariance estimator c a n b e derived that only depends on the moment s of the highest o rder sta tistic: V a r ( k R n f k 2 ) = n X i =1 n X j =1 ( − 1) j + i n i n j cov ( Z (2 i ) M : M , Z (2 j ) M : M ) k f k 2( i + j − 1) (24) 3.4. Comp arison with simple mo dels Let us now co mpare the be havior of the new r edrawn samples strategy to the one w he r e they are fixed. The relative error ǫ ( n ) = 10 log k R n f k 2 k f k 2 after n iterations is computed for bo th strateg ies. Knowing the proba bility density function (p df ) f Z , Equa tions (17) to (24) pr ovide close d- form mean and v aria nce estimate of ǫ ( n ) for both strategies . F o r example if Z ∼ U (0 , 1), its order s tatistics follo w a b eta distribution: Z k : M ∼ B eta ( k , M + 1 − k ) a nd all moments µ ( m ) M − k : M can be ea sily found. A graphical illustr ation of p o tential of the new strategy is given by Figure 5. F or three differen t distri- butions of Z , na mely uniform, normal (actually half nor mal since no negative v alues a re considered) and exp onential. The density function of tw o o rder statistics o f in terest (i.e the maximum f Z M : M , and the M / 2-th element f Z M / 2: M ) is plotted. These tw o elements combined pro vide an insight on how fast the exp ected v alue of se lected weigh t will decline us ing the fixed str ategy . Some c o mment s can be ma de: • In the uniform ca se: one migh t still exp ect to select relativ ely large co efficients (i.e go o d ato ms) after M / 2 itera tions with the s ta ndard strateg y . In this case, redrawing the samples (i.e changing the sub dic tio nary) app ears to be detrimen tal to the error decay rate. • F or no r mally and expo nentially distributed samples, the exp ected v alue of a co efficient selected in a fixed seq ue nc e dro ps more quickly tow ards small v a lue s (i.e there are r e latively fewer la rge v alues). Relative error profiles indicate that se lecting the ma ximum of redrawn samples can pr ov e beneficia l in terms o f minimizing the reconstruction er ror. It is promising for sparse approximation problems suc h as lossy compressio n. In practice, the uniform mo del is not well suited for sparse appr oximation problems. It basically indicates that the c hosen dictionary is po o rly co rrelated with the signal (e.g. white noise in Dirac dictionarie s ). Exp onential a nd norma l distributions, on the opp o site, a r e closer to pr actical situatio ns where the s ig nal is assumed spars e in the dictionar y , with additional measurement noise such as the one presented in section 3.2. In these ca ses, changing the subdic tio naries seems to be b eneficia l. Let us aga in stress that we ha ve only presented a mo del for erro r decays with tw o strategies and a se t of strong ass umptions . It is not a for mal pro of of a gua ranteed faster conv erg ence. How ever, it gives insigh t o n when the pr op osed new algorithm may be useful and when it ma y not, along with estimators of the decay rates when a statistical modeling of sig nal pro jections on subdictionarie s is av ailable. T o our knowledge, such mo deling w as not pro p o sed befor e for MP decomp o s itions. 9 Figure 5: Left : Pdf of Z and p dfs f or the maxim um and th e M / 2-th order statistic of Z for uniform, normal ( σ = 1) and exponent ial ( µ = 1) distri butions. Ri gh t: relativ e error decay (mean and v ariances) as a function of iteration n umber. M = 100 10 Figure 6: Bl ock diagram of encoding sc heme: each atom selected by the pursuit algorithm is transmi tted after quant izing its associated we ight . A simple en tropy co der then yields the bitstream 4. Matc hing Pursui t with Random Time F req uency Sub dictio naries for audio compression 4.1. Audio c ompr ession with union o f MDCT dictionari es Sparse decompositions using Matching Pursuit ha ve b ee n proven by Rav elli e t al [34] to be comp etitive for low bit-rate audio co mpr ession. In spite of Gab or dictionaries , they use the Mo dified Discrete Cosine T ransfor m (MDCT) [32] that is at the cor e of mos t tr ansform co ders (e.g. MPEG1 - Lay er I I I [1], MPEG 2/4 AA C). Let us recall the main adv antage o f RSSMP compared to Coarse MP: reconstruction error can be made smalle r with the same n umber of itera tions. If the random sequence of subdictionarie s is alrea dy known b y b o th co der a nd deco der then the co st o f enco ding each atom is the same in b oth case s . F or this pro of o f co ncept, a simplistic co ding scheme is used as presented in Figure 6. F or each atom in the approximan t, the index is t ransmitted alongside its quan tized amplitude (using a unif orm mid-tread quantizer). The cost of enco ding an atom index is log 2 ( M ) bits where M is the size of the dictionar y in which the ato m was chosen. A quantized appr oximation ˆ f n of f is obtained a fter n iterations with a characteristic S N R (same as S RR but computed on ˆ f n instead of f n ) and a sso ciated bit-rate. The sig nals are taken fro m the MPEG Sound Quality Asses ment Materia l (SQAM) dataset, their sa mpling frequency is r educed to 32000 Hz. Three cases are compared in this study: Coarse MP Matching Pursuit with a union o f MDCT basis with no additiona l parameter . The MDCT basis hav e sizes from 4 to 512 ms (8 dyadic scales from 2 7 to 2 14 samples) hop size is 5 0% in each scale. LoMP Lo c ally Optimized Matching Pursuit (Lo MP ) with a unio n of MDCT Ba s is. This is a lo cally- adaptive purs uit wher e an a tom is first selected in the coars e dictio nary . Then its time lo ca lization is optimized in a neig hbo urho o d to find the b est lo c a l atom in the full dictio nary . This purs uit is a slig htly sub o ptimal equiv alent of a Ma tchin g Purs uit using the full dictionary (F ull MP). It is nevertheless less computationally intensive. How ever, it requires the computation (and the tra nsmission) of a n additional parameter (the loc a l time shift) per atom (see [28] for mo re details). RSS MP MP with a r andom sequence of sub dictiona ries. Each sub dictio na ry is itself a union of MDCT basis, each bas is of sca le s k is randomly translated in time by a parameter τ i k ∈ [ − s k / 4 : s k / 4]. It is worth noticing that each scale is indep endently shifted. The sequence T = { τ i k } k =1 ..K,i =1 ..n is kno wn in adv ance at b oth enco der a nd deco der side, i.e. ther e is no need to t ransmit it. Step SSMP and J ump SSMP are t wo deterministic SSMP algorithms that are further described in Section 5. 4.2. Sp arsity r esult s Figure 7 shows the num ber of iteratio ns needed with the three des crib ed algo rithm (and tw o v ariants discussed in 5.1) to decomp ose short a udio signa ls from the MPE G SQAM da taset [2 ] (a glo ck enspiel, an orchestra, a male voice , a solo trump et and a singing voice), at 10 dB o f SRR. O ne can verify that RSS MP yields spa rser r epresentations (fewer a toms ato ms ar e needed to reach a given SRR) than Coar se MP . This statement remains v alid a t any given SRR level in this se tup. Exp eriments where run 10 0 times with the audio signal b eing randomly tr anslated in time at each r un. Figure 7 s hows that e mpirical v ariance r emains low, which gives us confidence in the fa c t that RSS MP will 11 glocs orchestra trumpet voicemale vega 0 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 2 5 0 0 Number of Iterations Coarse MP L o M P F u l l M P Random SSMP Jump SSMP Step SSMP Figure 7: Numb er o f iter ations nee de d to achieve 10 d B of SRR. Me ans and standar d deviation for various 4 se c onds leng t h audio signals fr om the MPEG SQA M dataset wit h MP on various fixe d and varying sequenc e s of sub dictionaries and r andom initial time offset. Step SSMP and Jump SSMP ar e two deterministic SSMP. give spa r ser represe ntations in most cases. So far w e hav e not found a natura l audio example con tra dicting this. 4.3. Compr ession r esu lts Figure 7 s hows that the lo cally-adaptive algorithm (LoMP) is b etter in ter ms o f spa rsity of the achiev ed representation than RSS MP . How ever, ea ch atom in these representations is mo re ex pe nsive to enco de. Actually , one must transmit a n additional lo ca l time shift par ameter. Wit h RSS MP no such parameter needs to b e transmitted. This gives RSS MP a decisive a dv antage ov er the t wo other algorithms for audio compressio n. As an example, let us examine the case of the last audio example lab eled ve ga . This is the first seco nds from Susan V ega ’s song T om’s Dinner. The three algo rithms are run with a union of 3 MDCT scales (a to ms hav e lengths of 4, 3 2 or 256 ms). Aga in these scor es hav e been av e r aged ov er 100 runs with the signal b eing randomly offset a t each run and sho wed v ery little empiric a l v ar iance. In order to reach e.g. 2 0 dB o f SRR (i.e befo r e w eight quantization): • Coarse MP selected 6886 ato ms. If each ha s a fixed index co ding cost of 18 bits and weight co ding cost of 16 bits, a total co st o f 23 1 kBits would b e neede d. • LoMP selected 3691 atoms. With sa me index and weigh t cost plus an additional time s hift parameter whose cost depends o n the leng th o f the selected a tom, the tota l cost w ould b e 1 49 kB its. • RSS MP selected 3759 a to ms (with empirica l sta ndard deviatio n of 1 6 atoms). E ach atom has the sa me fixed cost as in the C o arse MP ca se. T he av erage total size is thus 12 6 kBits. Using an entropy coder a s in Figure 6 do es not fundamentally change these results. Figur e 8 summarizes compressio n results with Co a rse MP , LoMP and RSS MP for v ario us audio signals fro m this dataset. Although these comparisons do no t use the most efficie nt quantization and co ding to ols, it is clear from this picture that the prop osed r andomization paradigm can be efficien tly used in audio compression with greedy a lgorithms. In this pro of of concept, the q uality mea sure adopted was the S N R . How ever, s uch algor ithms and dictionaries are k nown to int ro duce disturbing ringing artifacts and pre-echo. W e have no t exp e r ienced that the prop os ed algor ithm increa sed nor r educed these artifacts compared to the other pursuits. F urthermore, pre-echo con tro l and dar k ener gy manage ment tec hniques can be applied with this algorithm just as with any other. Audio ex amples are av aila ble online 1 . 12 0 1 0 2 0 3 0 4 0 5 0 6 0 Bitrate (kbps) 5 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 SNR (dB) glocs Coarse MP L o M P F u l l M P RSS MP 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 Bitrate (kbps) 5 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 SNR (dB) orchestra Coarse MP L o M P F u l l M P RSS MP 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 Bitrate (kbps) 5 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 SNR (dB) voicemale Coarse MP L o M P F u l l M P RSS MP 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 Bitrate (kbps) 5 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 SNR (dB) vega Coarse MP L o M P F u l l M P RSS MP Figure 8: SNR/Bitr ate curves for 6 s -lengt h si g nals fr om the MPEG SQAM dataset with multi-sc ale MDCT dictionaries ( 2 7 , 2 10 and 2 13 samples p er window). 13 5. Discussion Having presented the nov el algor ithm and an application to audio c o ding, fur ther ques tions are inves- tigated in this section. First a n exp erimental s tudy is conducted to illustrate why the seq uence of subdic- tionaries should be pseudo-r andomly genera ted. Then, the RSS scheme is applied to orthog onal pursuit a nd finally a co mplexity study is pr ovided. 5.1. R andom vs D eterministic In the above exp eriments we hav e cons tructed a seque nc e of rando mly v arying sub dictionar ies by desig ning a sequence of time shifts T = { τ i k } k =1 ..K,i =1 ..n by means of a pseudo-ra ndom g e nerator with a uniform distribution: ∀ ( k , i ) τ i k ∼ U ( − s k / 4 , s k / 4). There are other wa ys to construct such a sequence, so me o f which are deterministic. How ever, w e hav e found that this pseudo -random setup is in ter estingly the one that g ives the bes t per formances. T o illustrate this, let us recall the setup of Section 4 and co mpare the s parsity of representations achieved with sequences of sub dictiona ries built in the following manner: RANDOM: T is r andomly chosen: ∀ ( k , i ) τ i k ∼ U ( − s k / 4 , s k / 4) STEP: T is constr ucted with stepwise increasing seq uences : ∀ ( k , i ) τ i k = mod ( τ i − 1 k + 1 , s k / 2) and ∀ k , τ 0 k = 0 . This sequence yields dictionaries that are quite close from o ne iter ation to the next. JUMP: T is constructed w ith jum ps : ∀ ( k , i ) τ i k = mod ( τ i − 1 k + s k / 4 − 1 , s k / 2)and ∀ k , τ 0 k = 0 . This se- quence yields dictionaries that are very dissimilar from one iteration to the next, but a re quite clos e to dictionaries 2 iterations later. Figure 7 shows that among all cases, the random s trategy is the b est one in terms of s parsity . The worst strategy is STEP . This can be explained by the fact tha t, fro m one iteration to the next, the sub dic tio naries are well correla ted. Indeed a ll the analysis windows ar e shifted sim ulta neously b y the same (little) offset. The JUMP strategy is already better. Here the different analysis s c ales are shifted in differen t wa ys. Low correla tion b etw e e n successive s ubdictio naries app ear s to be an impo rtant fa c tor. Exp eriments w ere run 1 00 times a nd the hier archical pattern remain unch anged for higher SRR le vels. Many more deterministic strateg ies hav e b een tried, the random str ategy remains the most interesting one when no further as sumption ab o ut the sig nal is ma de. W e ex plain this phenomenon by noticing that pseudo random sequences ar e more likely to yield sub dictionar ies that are very uncorrela ted one to another not o nly o n a iteration-by-iteration basis but also for a la rge n umber of itera tions. 5.2. Ortho gonal purs uits Other SSMP family members can be created with a simple mo dificatio n of their ato m selection rule. In particular, one may want to apply this technique to Orthog onal Ma tchin g P ursuit. The resulting a lgorithm would then be ca lled RSS O MP . T o ev aluate RSS OMP , we hav e recr eated the to y exp eriment of [3] a nd use 1000 random dictionarie s of size 128 × 2 56 with atoms drawn uniformly from the unit sphere. Then, 1000 random signals are created using 64 element s from the dictiona ries with unit v aria nce zero mean Gaussian amplitudes. F or each signal and corres p o nding dictionary , the decomp o sition is p erfor med using MP and O MP with a fixed sub dictiona ry of size 128 × 64 (Coa rse MP and Coa rse OMP), a rando m sequence o f subdictionaries of size 128 × 64 (RSS MP and RSS OMP), and the co mplete dictionary (F ull MP and F ull OMP). Matlab/ Octav e c o de to reproduce this exp er iment is av ailable online. Averaged results are shown Figur e 9. Fixed sub dictionar y cas e s (Coa r se MP/O MP) show a saturated pattern ca used by incompleteness of the sub dictionary . Although working o n sub dictionar ies fo ur times smaller, pursuits on random seq uent ial sub dictiona ries exhibit a b ehavior close to pursuits on the complete 1 h ttp://www.tsi.telecom-paristec h.fr /aao/?p=531 14 0 20 40 60 80 100 120 −11 −10 −9 −8 −7 −6 −5 −4 −3 −2 −1 0 Number of iterations Error (dB) Coarse MP Coarse OMP RSS MP Full MP RSS OMP Full OMP Figure 9: Comp arison b etwe en algorithm MP (thin) and OMP (b old) with fixe d c o arse sub dict ionary Φ I 0 (dashe d dotte d blue), r andom se quential sub dictionaries Φ I n and ful l dictionary Φ (dashe d r e d). Input signal is a c ol le ction of N/ 2 ve c tors fr om Φ with normal weights. R esults avera ge d ove r 1000 runs. Her e N = 128 , M = 256 Step F ull MP Coarse MP F ull OMP Coarse OMP RSS MP RSS OMP Step 1 Pro jection O ( M N ) O ( LN ) O ( M N ) O ( L N ) O ( L N ) O ( LN ) Selection O ( M ) O ( L ) O ( M ) O ( L ) O ( L ) O ( L ) Step 2 Gram Ma trix 0 0 O ( i N ) O ( iN ) 0 O ( i N ) W eights 0 0 O ( i 2 ) O ( i 2 ) 0 O ( i 2 ) Residual O ( N ) O ( N ) O ( i N ) O ( iN ) O ( N ) O ( iN ) T otal O ( M N ) O ( LN ) O ( i 2 + M N ) O ( i 2 + L N ) O ( L N ) O ( i 2 + L N ) T able 1: Complexities of the differen t steps for v ar ious algorithm in the gen eral case (no update trick for pro jection). N is the signal dim ension. M is the n umber of atoms in Φ and L the num ber of a toms in subdictionaries. The iteration num b er i is alwa ys sm al ler than N . dictionary . Poten tial gains are e ven mor e visible with the OMP algor ithm, wher e the probabilistic parsing of t he large dictionary allo ws for a muc h better erro r decay rate than the fixed subdictionary case (Coarse OMP). 5.3. Computational C omplexities 5.3.1. Iter ation c omplexities in the gener al c ase Let f b e in R N and Φ be a redundant dictionary of M a toms also in R N . Let Φ I be a sub dictiona ry of Φ of L atoms. Complexities in the general cas e are given at iteratio n i by T a ble 1. When no up da te trick is us e d, Step 1 requires the pro jection of the N dimens io nal residual onto the dictionary follow e d b y the selection of the maximum index. Step 2 is r ather simple for s tandard MP , it o nly inv olves a n up date of the residual th rough a subtraction of the s elected atom. F or OMP though, a Gra m Matrix co mputation follow ed b y a n optimal w e ights ca lculation is needed to ensure or thogonality b etw een the residua l and the subspace spanned by all previously selected atoms . Co mplexities of this t wo a dditional steps incre a ses with the iter ation num b er a nd has led to the development of b y passing techniques tha t limit complexity using iterative QR factorizatio n trick [3]. Co mplexities in T able 1 are given according to these tr icks. 5.3.2. Up date trick s a nd short atoms Although RSS MP has the sa me complexit y in the genera l case as Coarse MP , there are practical lim- itations to its use. First, Mallat et al [2 7 ] pro p osed a simple up date trick that effectively ac celerates a decomp osition. Pro jection step is p erformed using pr evious pro jection v alues and the pre-computed inner pro ducts b etw een atoms o f the dictionar y . Changing the sub dictionary on a n itera tion-by-iteration bas is preven ts fr om us ing this trick. 15 Step F ull MP Coa rse MP RSS MP Step 1 Pro jection O ( β P log P ) O ( αP log P ) O ( αN log P ) Selection O ( β P ) O ( αP ) O ( αN ) Step 2 Gram Matrix 0 0 0 W eights 0 0 0 Residual O ( P ) O ( P ) O ( P ) T able 2: Complexities after iteration 1 of the different steps for v arious algorithm i n structured time- f requency dictionaries with fast transform and limited atomic support P << N . In this case, the local up date sp eed up trick ca n not b e applied to RSS MP . An even greater optimization is av a ila ble when using fas t transforms and more sp ecifically when o nly lo cal updates ar e possible. One of the main accelerating factor propose d fo r MP in the MPTK framew o rk [24] and for OMP in [2 6] is to limit the num b er o f pro jections that require an up date to match the support of t he selected ato m. Again, when c hanging dic tio naries at ea ch iter ation, this tric k can no longer b e used to a ccelerate Step 1 . Using fast transforms, the complexit y of the pro jectio n s tep a t first iteration reduces to O ( M log N ) for F ull MP [26]. Additionally if one uses shor t atoms o f size P << N , it fur ther re duce s to O ( M log P ). When lo cal upda te can be used instea d of full correlatio n, the pro jection step after iteration 1 has an ev en more reduced complexity of O ( αP log P ) in Φ I where α = L N is the redundancy factor a nd of β P log P in Φ where β = M N = α M P . Rega rdless of the dictiona ry , the r esidual only needs a lo cal up date around the chosen atom. T able 2 shows that in this context, the pro p o sed mo difica tion bec o mes less comp etitive with r esp ect to the standard alg orithm on fixed s ubdictio nary and can even be slow er than the full dictionar y case if L > P M L . How ever, it can still be co nsidered as a viable alternative since memory r equirements for full dictio na ry pro jections can g et pr ohibitive. In o rder to limit the computational burden, it is p ossible to change the subdictiona ry o nly once every several iterations . If the subdictionary Φ I i remains unc hang ed for J co nsecutive iterations , t hen the usual tricks for sp eeding up the pro jection can be applied. When Φ I i changes at itera tion i + J , a ll pro jections need b e r e computed. Although it can accelerate the algorithm, o ne may expec t a res ulting lo ss of quality . 5.3.3. Sp arsity/Complexity tr ade off Another w ay to tackle the complexity issue is by choo sing a n a ppropria te size for the subdictio naries. Since RSS MP yields muc h spar ser so lutions with dictionaries of the same size than Coar se MP , we can further reduce the size of the s ubdic tio naries in order to accelerate the co mputatio n while still hoping to get compact representations. Indeed, in the discussion ab ove, we ha ve only compared complexities p er iteration, but the to tal num ber of iter a tions is a lso impo r tant. T o illustrate this idea, we hav e used subsampled sub dictionar ies with a subsa mpling factor v arying fr om 1 (no subsa mpling) to 32. The subsa mpling is perfor med by limiting the fra me indexes in whic h we calculate the MDCT pro jections . It is imp ortant to notice that the sub dictiona ries are no long er redundant, and not ev en complete when the subsa mpling facto r is greater than 2. Fig ure 10 shows for t wo signals how the subsampling impacts the sparsity o f the representation (here e xpressed as a bit-rate calculated as in section 4) and the computational complexity rela tive to the r eference Coarse MP algorithm for whic h we ha ve implemen ted the lo cal upda te trick. Dictionaries used in this setup are multiscale MDCT with 8 differen t scales (from 4 to 51 2 ms), the exp eriment is run 100 times o n a dual core computer up to a SRR of 10 dB. Using ra ndom sub dictionaries 10 times smaller than the fixed one of Coar se MP , we can still hav e go o d compression ( cost 30 % less than the reference) with the computation b eing sligh tly faster. More in terestingly , this subsa mpling factor , a sso ciated with the RSS MP algor ithm, controls a spar- sity/complexit y tradeoff that allows m ultiple use ca ses depending on needs and resource s . 16 Figure 10: Il lustr ati on of the sp arsity/c omplexity tr ade off that c an b e achieve d by c ontr ol ling the size of the sub dictionaries in RSS MP. 6. Conclusion In this w ork, we pr op osed a modifica tion of g reedy algo r ithms of the MP family . Using a pseudo ra ndom sequence of s ubdictio naries instead of a fixed subdictiona ry can yield sparser appr oximations of sig nals. This sparsity ba sically comes at no additional c o ding co st if the rando m sequence is known in adv a nc e , th us giving our algor ithm a clear adv ant age for compres sion purpo ses as shown here for audio signals. O n the downside, the mo dification may incre a se complexity , but we hav e prop osed a tradeoff stra tegy that helps reducing computation times. The idea presented in this work ca n b e linked to ex isting techniques from o ther do mains, wher e r andomness is used to enhance signal pro c essing tasks. Dithering for quantization is o ne suc h tec hnique. Ano ther example is spre a d sp ectrum in communication [8], where a signa l is multiplied by a ra ndom seq uence b efore b eing transmitted o n a bandwidth that is m uch lar ger than the one of the orig inal conten t. Here, encryption is more imp or tant a g oal than co mpression. Ho wever, per forming RSS MP of a signal so mehow requir es the definition of a key (the pseudo- random sequence) that must b e k nown a t the reception side in o rder to deco de the repre s entation. Mo reov er, the repr esentation ma y also liv e in a muc h la rger space than the original co nten t. It is worth noticing for instance the work o f Puy et al [33] w he r e the a uthors a pply spread sp ectrum techniques to the compressed s ensing problem. Other exper iments should b e conducted for feature extra ction tas ks, since the go o d conv ergence prop er ties indicates that the selected comp onents car ry mea ningful informa tio n. F or instance, music index ing [35] and face pattern re cognition [31] use Matching Purs uits to derive the features that serve for their pro cessing. F urther work will have to inv estig ate whether RSS MP can impr ov e on the p erformance of o ther algorithms on s uch tasks. Ac kno wledgments W e ar e very grateful to the anonymous review er s for their detailed comments that helped improv e the quality of this pap er. W e also would like to thank Dr. Bob Sturm for the in terest he sho wed in our work a nd his relev a nt remarks a nd advice. Discussing with him w as both an opp o rtunity and a pleasure. This work was partly s uppo rted by the QUAERO prog r amme, funded by OSEO, F rench State Agency for innov a tion. 17 References [1] Coding of moving picture s and as so ciated audio for digital, storag e at speed up to about 1.5m bits/ s part 3: Audio is11192 -3, 199 2. [2] Repor t o n infor mal mp eg-4 extensio n 1 (bandwidth extension) verification tests. T echnical rep ort, ISO/IEC JTC1/SC2 9/WG11/N5571 , 2003. [3] T. Blumensa th and M.E . Davies. Gra dient pur suits. IEEE T r ans. on S ignal Pr o c essing , 56(6 ):2370 –2382 , 2008. [4] S. Chen, D. Donoho, a nd M. Saunders . A tomic deco mpo sition by bas is purs uit. SIAM Journal on Scientific C omputing , 20:33– 61, 199 8 . [5] M.G. Chris tens e n and S.H. Jensen. The cyclic matching pursuit and its application to audio mo deling and co ding. Pr o c. of Asilomar Co n f. on Signals, Systems and Computers. , 41:550 – 554, 2007. [6] L. Daudet. Sparse and str uctur ed decompositio ns of signals with the molecular matching pursuit. IEEE T r ans. on Audio Sp e e ch L anguage Pr o c essing , 14(5):180 8–18 26, 20 06. [7] A. Divek ar and O Ersoy . Pro babilistic matching pursuit for co mpressive sensing. T echnical r ep ort, Purdue Univ ersity , 201 0. [8] Rober t Dixon. Spr e ad Sp e ctru m Syst ems . Jo hn Wiley & Sons, 199 4. [9] D.L. Dono ho. Co mpressed sensing. IEEE T r ans. on Informatio n The ory , 5 2(4):128 9–13 0 6, 2006. [10] P .J. Durk a, D. Irc ha, a nd K.J. B linowsk a. Sto chastic time-frequency dictiona ries for ma tchin g pursuit. IEEE T r ans. on Signal Pr o c essing , 49 (3 ):507 – 510, 2001. [11] P . Dymar ski, N. Moreau, and G. Ric hard. Greedy s pa rse decompo sitions: A comparative study . EURASIP J ournal on A dvanc es i n Signal Pr o c essing , 1:34, 201 1 . [12] M. Elad and I. Y a vneh. A plurality of s parse r epresentations is b etter than the sparse st one alone. IEEE T r ans. on Information The ory , 55(10):4701–4 714, 2009. [13] S. E. F errando, E. J . Doolittle, A. J. Bernal, and L.J . Bernal. Probabilis tic matc hing purs uit with ga b or dictionaries. Elsevier Signal Pr o c essing , 80 :2099 –212 0 , 200 0 . [14] C´ edric F evotte, Bruno T orr´ esani, Lauren t Daudet, and S.J Gods ill. Denoising of musical audio using sparse linear regressio n and structur ed priors. IEEE T r ans. on Audio S p e e ch L anguage Pr o c essing , 16(1):174 –185 , 2008. [15] R.M. Figueras i V en tur a , P . V anderghey nst, and P . F r o ssard. Low-rate and flexible image co ding with redundant representations. IEEE T r ans. o n Ima ge Pr o c essing , 15(3):726 –739, 2006 . [16] L. Gammaitoni, P . H¨ anggi, P . Jung, and F. Marchesoni. Sto chastic res o nance. R eviews of Mo dern Physics , 70:2 2 3–28 7, 1 998. [17] M. M. Goo dwin a nd M. V etter li. Matching pursuit and atomic signa l models based on recur sive filter banks. IEEE T r ans. on Signal Pr o c essing , 47:1890–19 02, 1 9 99. [18] R. Grib onv a l. F ast matc hing pursuit with a multiscale dictionary of g aussian c hirps. IEEE T r ans. on Signal Pr o c essing , 4 9(5):994 – 1001, May 2001. [19] R. Gribo nv al, E. Bacry , S. Mallat, P . Depalle, a nd X. Ro de t. Analysis of sound signals with high resolution matching pursuit. International Symp osium on Time-F r e quency and Time-Sc ale Analysis. , pages 125 –128, 1996. 18 [20] R. Grib onv a l and P . V andergheynst. On the exp onential conv ergenc e of ma tching pursuits in quasi- incoherent dictionaries . IEEE T r ans. on Information The ory , 5 2(1):255 – 261, 2006 . [21] S. S Gupta, K. Nagel, and S. Panc hapakesan. On the or de r sta tis tics from equally c o rrelated norma l random v ariables. Biometrika , 60:403–41 3, 1972. [22] W. C. Jagg i, S.a nd Karl, S. Mallat, and A. S. Willsky . High resolution pur suit for feature extr action. Elsevier Applie d and Computational Harmonic A nalysis , 5:428 –449, 1998 . [23] P . Jost a nd P . V andergheynst. T ree-bas ed pursuit: Algorithm and pro p erties. IEEE T r ans. on Signal Pr o c essing , 54 (12):468 5–46 9 7, 20 0 6. [24] S. Krstulovic a nd R. Gribonv al. Mptk: matching pursuit made tractable. In Pr o c. of IEEE Int. Conf. Audio Sp e e ch and Signal Pr o c essing ( I CAS SP) , 2006 . [25] M. Lewicki and T. Sejnowski. Co ding time-v arying signals using spar se, shift-inv a riant representations. A dvanc es Neur al Inf. Pr o c ess. Syst. , 11:730 –736, 1999 . [26] B. Mailhe, R. Gr ibo nv al, F. Bimbot, and P . V a ndergheynst. A low complexity o rthogona l matching pursuit for sparse s ignal appr oximation with shift-inv aria nt dictionaries. Pr o c. of IEEE Int. Conf. Audio Sp e e ch and Signal Pr o c essing (ICASSP) , pages 3445–3 448, 2009. [27] S. Mallat and Z. Zhang. Ma tching pursuits with time-frequency dictionaries. IEEE T r ans. on Signal Pr o c essing , 41 (12):339 7–34 1 5, 19 9 3. [28] M. Moussallam, G. Richard, and L. Daudet. Audio signal repr e sentation for fac to risation in the spa r se domain. Pr o c. of IEEE In t. Conf. Audio Sp e e ch and Signal Pr o c essing (ICASSP) , pages 513 – 516, 2011. [29] H. N. Naga ra ja. Or de r sta tis tics from discrete distributions. S t atistics , 23:189 –216 , 19 92. [30] Y.C. Pati, R. Rezaiifar, and P .S. Krishna prasad. Orthogo nal matching pur suit: Recursive function approximation with applica tions to w avelet deco mpo sition. Pr o c. of Asilomar Conf. on Signals, Syst ems and Computers. , 2 7:40– 44, 1993. [31] P .J. Phillips. Ma tching pursuit filters applied to face identification. IEEE T r ans. on Image Pr o c essing , 7(8):1150 –116 4, aug 1998 . [32] J. P rincen and A. Br adley . Analysis/ synthesis filter bank design based on time domain alias ing cancel- lation. IEEE T r ansactions on A c oustics, Sp e e ch and Signal Pr o c essing , 3 4(5):1153 – 1 1 61, o ct 1986. [33] G. Puy , P . V andergheynst, R. Grib o nv al, and Y. Wiaux. Universal and efficient compress ed sensing by spread sp ectrum and application to realistic F ourier imaging techniques. T echnical r e po rt, 2011. [34] E . Rav elli, G. Richard, and L. Daudet. Union of MDCT bases for audio c o ding. IEEE T r ans. o n Audio Sp e e ch L anguage Pr o c essing , 16(8):13 61–1 372, 2 008. [35] E . Rav elli, G. Richard, and L. Daudet. Audio signal representations for indexing in the transfor m domain. IEEE T r ans. o n A udio Sp e e ch L anguage Pr o c essing , 18:43 4 – 446, 2010 . [36] P . Schn iter, L. C. Potter, and J . Ziniel. F ast bay es ian matching pursuit: model uncertaint y and parameter estimation for sparse linear mo dels. IEEE T r ans. on Signal Pr o c essing , pages 326 – 33 3, 2008. [37] E . Smith and M. S. Lewicki. Efficient auditory co ding. Nature , 43 9:978 –982 , 2005. [38] B. Sturm, J. Sh ynk, L. Daudet, a nd C Ro ads. Dark energy in sparse a tomic decomp ositions,. IEEE T r ans. on Audio Sp e e ch L anguage Pr o c essing , 16(3):671 –676 , 20 08. [39] B. L. Stur m and J. J. Sh ynk. Sparse approximation and the pursuit of meaningful sig nal mo dels with int erference adaptation. IEEE T r ans. on A u dio S p e e ch L anguage Pr o c essing , 1 8:461– 472, 2010 . 19 [40] B.L. Sturm a nd M.G. Christensen. Cyclic matching pursuits with multiscale time-frequency dictionar ies. Pr o c. of Asilomar C onf. on Signals, S ystems and Computers. , 4 4:581 –585 , nov. 20 10. [41] V.N. T emlyak ov. A c riterion for convergence o f weak greedy algor ithms. A dv. Comp. Math. , 1 7(3):269 – 280, 2 002. [42] R. Tibshirani. Regressio n shrink a ge and selection v ia the lasso . Journal of t he Roy al Statistic al So ciety, Series B , 58:267–28 8, 1 994. [43] J.A. T ropp a nd A.C. Gilber t. Sig nal r ecov er y from ra ndom measurements via orthog onal matching pursuit. IEEE T r ans. on Information The ory , 5 3(12):46 55–4 6 66, 2 0 07. [44] Ram Zamir a nd Meir F eder. On universal quantization by randomized uniform/lattice qua nt izers. IEEE T r ans. on Information The ory , 38(2):428–436 , 1992. [45] H. Zayyani, M. Babaie- Zadeh, and C. Jutten. Bayesian pursuit alg orithm for spar s e repres e ntation. Pr o c. of IEEE In t. C onf. A udio Sp e e ch and Signal Pr o c essing (ICAS S P) , pa g es 1549 –1 552, april 2009. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment