무작위 순차 서브딕셔너리를 활용한 매칭 퍼슈트 혁신
본 논문은 매칭 퍼슈트(MP) 알고리즘에서 매 반복마다 무작위로 선택된 서브딕셔너리를 사용함으로써, 대규모 사전의 전체 탐색 없이도 높은 근사 정확도와 낮은 연산 비용을 달성하는 방법을 제안한다. 순서통계 모델을 통해 이론적 근거를 제시하고, 다중 스케일 시간‑주파수 사전을 이용한 오디오 압축 실험을 통해 실용성을 검증한다.
저자: Manuel Moussallam, Laurent Daudet, Ga"el Richard
본 논문은 매칭 퍼슈트(MP) 계열 알고리즘이 대규모 사전에서 원자를 선택할 때 발생하는 계산량 문제를 해결하고자, 매 반복마다 무작위로 선택된 서브딕셔너리를 이용하는 새로운 프레임워크를 제안한다. 먼저, 기존 MP와 그 변형(OMP, Weak MP 등)의 기본 구조와 한계를 소개한다. 전통적인 MP는 전체 사전 Φ에 대해 모든 원자와 잔차의 내적을 계산해 최대값을 찾는 과정이 필요하지만, 사전 규모가 수십만~수백만에 달하면 이 과정은 실시간 응용에 부적합하다. 이를 완화하기 위해 약한 선택(Weak MP)이나 로컬 어댑티브 최적화가 사용되었지만, 전자는 선택 정확도가 떨어지고 후자는 추가 파라미터 추정과 연산 오버헤드가 발생한다.
이에 저자들은 “Sequential Subdictionary Matching Pursuit”(SSMP)라는 개념을 도입한다. 사전 Φ에 대해 미리 정의된 인덱스 시퀀스 I={In}를 준비하고, n번째 반복에서는 서브딕셔너리 Φ_In만을 탐색한다. 특히 In을 무작위로 생성하면 “Random Sequential Subdictionary Pursuit”(RSS‑MP)라 부르며, 이는 매 반복마다 서로 다른 무작위 서브셋을 사용한다는 점에서 기존 고정 서브셋 방식과 차별화된다.
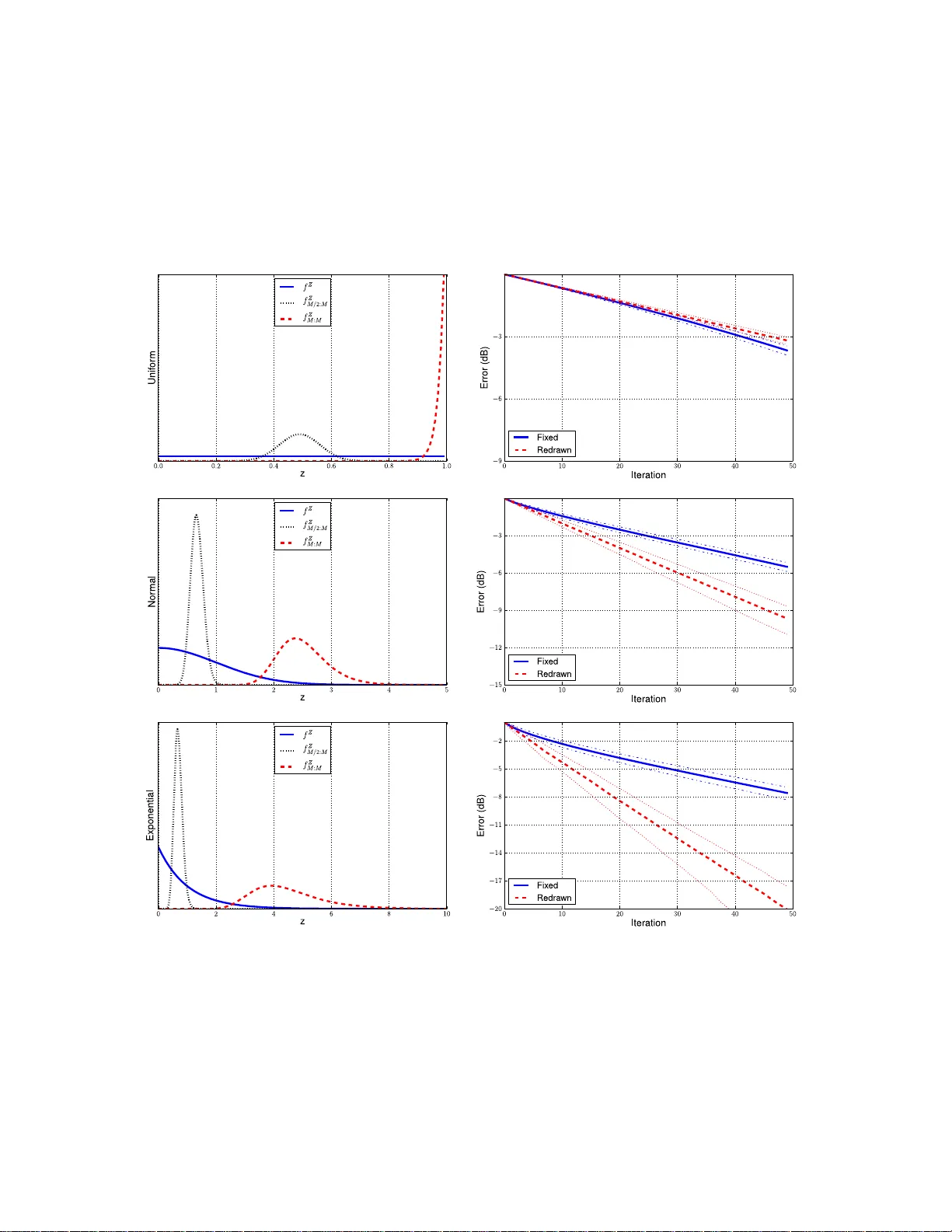
이론적 분석에서는 각 원자와 잔차의 내적 절댓값을 i.i.d. 확률변수 Z₁,…,Z_M으로 모델링하고, 서브셋 크기 L에 따라 최대값 max(Z₁,…,Z_L) 의 기대값이 증가한다는 순서통계 결과를 이용한다. 무작위 서브셋을 반복적으로 교체하면 전체 사전 Φ의 다양한 영역을 샘플링하게 되어, 고정 서브셋이 놓칠 수 있는 높은 내적을 점진적으로 포착한다. 또한, 서브셋 교체는 “다크 에너지”(신호에 존재하지 않는 에너지) 현상을 감소시키고, 평균적인 잔차 에너지 감소 속도를 기존 약한 MP보다 크게 향상시킨다.
복잡도 측면에서는 매 반복마다 수행되는 내적 연산이 서브셋 크기 L에 비례하므로 전체 연산량은 O(m·L)이다. L을 전체 사전 크기 M에 비해 작게 유지하면 메모리와 연산량을 크게 절감한다. 무작위 서브셋은 사전에 한 번만 생성하면 되며, 추가 파라미터 추정이 필요 없고, 병렬 처리에도 적합하다.
실험에서는 다중 스케일 Gabor(시간‑주파수) 사전을 사용해 오디오 신호 압축을 수행하였다. 기준으로 전통적인 MP와 고정 서브셋 MP를 두었으며, RSS‑MP는 동일 비트레이트에서 평균 신호‑대‑잔차 비율(SRR)이 1~2 dB 향상되는 결과를 보였다. 특히 저비트레이트(≤ 32 kbps) 구간에서 압축 효율이 크게 개선되었고, 청감 테스트에서도 품질 저하가 눈에 띄게 적었다.
결론적으로, 무작위 순차 서브딕셔너리 전략은 (1) 사전 탐색 비용을 크게 낮추고, (2) 선택 품질을 통계적으로 보장하며, (3) 구현 복잡도를 최소화한다는 세 가지 장점을 제공한다. 이는 실시간 코딩, 임베디드 오디오 처리, 대규모 신호 복원 등 다양한 응용 분야에서 실용적인 대안이 될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기