Structure Learning of Probabilistic Graphical Models: A Comprehensive Survey
Probabilistic graphical models combine the graph theory and probability theory to give a multivariate statistical modeling. They provide a unified description of uncertainty using probability and complexity using the graphical model. Especially, grap…
Authors: Yang Zhou
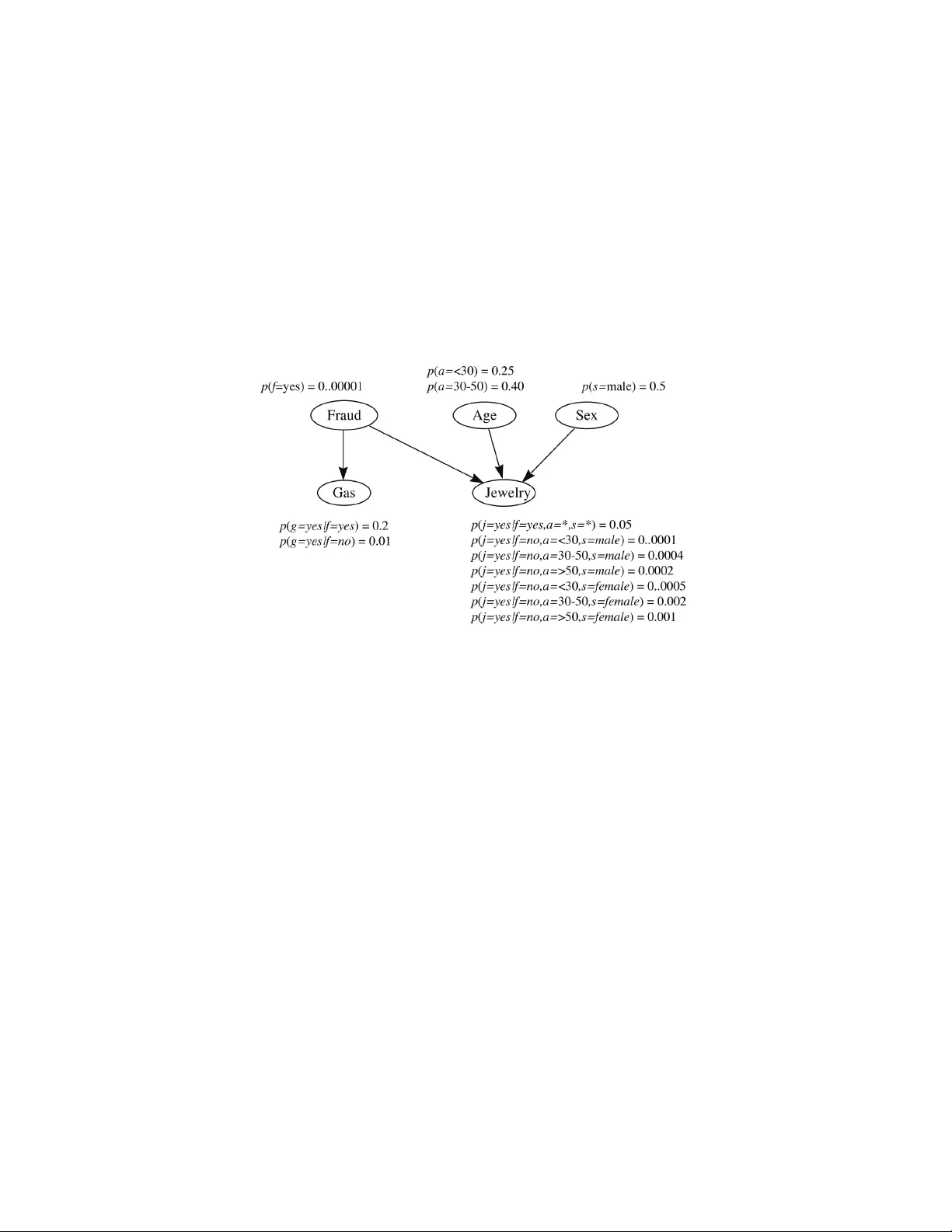
Structure Learning of Probabilistic Graphical Mo dels: A Comprehensiv e Surv ey Y ang Zhou Mic higan State Universit y No v 2007 Con ten ts 1 Graphical Models 3 1.1 In tro duction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.2 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.3 Undirected Graphical Mo dels . . . . . . . . . . . . . . . . . . . . 5 1.3.1 Mark ov Random Field . . . . . . . . . . . . . . . . . . . . 5 1.3.2 Gaussian Graphical Mo del . . . . . . . . . . . . . . . . . . 6 1.4 Directed Graphical Mo dels . . . . . . . . . . . . . . . . . . . . . 6 1.4.1 Conditional Probability Distribution . . . . . . . . . . . . 7 1.5 Other Graphical Mo dels . . . . . . . . . . . . . . . . . . . . . . . 9 1.6 Net work T op ology . . . . . . . . . . . . . . . . . . . . . . . . . . 10 1.7 Structure Learning of Grap hi cal Mo dels . . . . . . . . . . . . . . 11 2 Constrain t-based Algorithms 12 2.1 The S G S Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . 12 2.2 The PC Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 13 2.3 The G S Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 14 3 Score-based Algorithms 16 3.1 Score Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 3.1.1 The M D L Score . . . . . . . . . . . . . . . . . . . . . . . 17 3.1.2 The BD e Score . . . . . . . . . . . . . . . . . . . . . . . . 18 3.1.3 Ba yesian Information Criterion (BIC) . . . . . . . . . . . 19 3.2 Searc h for the Optimal Structure . . . . . . . . . . . . . . . . . . 21 3.2.1 Searc h ov er S tr u ct ur e Space . . . . . . . . . . . . . . . . . 21 3.2.2 Searc h ov er O r de r in g Space . . . . . . . . . . . . . . . . . 25 4 Regression-based Algorithms 27 4.1 Regression Mo del . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.2 Structure Learning through Regression . . . . . . . . . . . . . . . 30 4.2.1 Lik eliho o d Ob jectiv e . . . . . . . . . . . . . . . . . . . . . 30 4.2.2 Dep endency Ob jective . . . . . . . . . . . . . . . . . . . . 31 4.2.3 System-identification Ob jective . . . . . . . . . . . . . . . 33 4.2.4 Precision Matrix Ob jective . . . . . . . . . . . . . . . . . 34 4.2.5 MDL Ob jective . . . . . . . . . . . . . . . . . . . . . . . . 35 1 5 Hybrid Algorithms and Others 36 5.1 Hybrid Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . 36 5.2 Other Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 5.2.1 Clustering Approac hes . . . . . . . . . . . . . . . . . . . . 37 5.2.2 Bo olean Mo dels . . . . . . . . . . . . . . . . . . . . . . . . 37 5.2.3 Information Theoretic Based Ap pr oach . . . . . . . . . . 37 5.2.4 Matrix F actorization Based Approach . . . . . . . . . . . 37 2 Chapter 1 Graphical Mo dels 1.1 In tro duction Probabilistic graphical models com bin e the graph theory and probability theory to giv e a m ultiv ariate statistical modeling. They pro vide a unified description of uncertaint y using probability and complexity using the graphical mo del. Es- p ecially , gr aph ical mo dels pro vide the following several useful prop erties: • Graphical mo dels pro vide a simple and in tuitive interpretation of the structures of probabilistic mo dels. On the other hand, they can b e used to d es ign and motiv ate new mo d el s . • Graphical models pro vide additional insigh ts in to the prop erties of the mo del, including the conditional indep endence prop erties. • Complex computations whic h are required to p erform inferenc e and learn- ing in sophisticated models can be expressed in terms of graphical manip- ulations, in which the underlying mathematical expressions are carried along imp lic itl y . The graphical mo dels hav e b een applied to a large n umber of fields, includ- ing bioinformatics, social science, control theory , image pro cessing, marketing analysis, among others. How ever, structure learning for graphical mo dels r e- mains an op en c hallenge, since one must cop e with a com binatorial search o ver the space of all p ossible s tr u ct u r es . In this pap er, w e present a comprehens ive survey of the ex is ti ng structure learning algorithms. 1.2 Preliminaries W e will first d efi n e a set of notations which will be used throughout this pap er. W e represent a graph as G = h V , E i where V = { v i } is the set of no des in the graph and each no de corresp onds to a random v ariable x i ∈ X . E = { ( v i , v j ) : 3 i 6 = j } is the se t of edges. In a directed graph, if there is an edge E i,j from v i to v j , then v i is a parent of no de v j and v j is a child of no de v i . If there is no cycle in a directed graph, w e call it a Directed Acyclic Graph (D AG). The n umber of no des and n umber of edges in a graph are denoted by | V | and | E | resp ectively . π ( i ) is used to represent all the parents of no de v i in a graph. U = { x 1 , · · · , x n } denotes the finite set of discrete random v ariables where each v ariable x i ma y tak e on v alues from a finite domain. V al ( x i ) denotes the set of v alu es that v ariable x i ma y attain, and | x i | = | V al ( x i ) | denotes the cardinality of this set. In probabilistic graphical netw ork, the Mark ov blanket ∂ v i [P earl, 1988] of a no de v i is defined to b e the set of no des in which eac h has an edge to v i , i.e., all v j suc h that ( v i , v j ) ∈ E . The Marko v assumption states that in a probabilistic graphical netw ork , every set of no des in the netw ork is conditionally indep enden t of v i when conditioned on its Marko v blank et ∂ v i . F ormally , for dist inc t no d es v i and v k , P ( v i | ∂ v i ∩ v k ) = P ( v i | ∂ v i ) The Marko v blanket of a no de gives a lo calized probabilistic interpretation of the no de since it identifies all th e v ariables that shield off the no de from the rest of the netw ork, which means that the Mark ov blanket of a nod e is the only information necessary to predict the b eha vior of that no de. A DA G G is an I -M ap of a distribution P if all th e Marko v assumptions implied by G are satisfied b y P . Theorem 1.2.1. (F actorization Theorem) If G is an I-Map of P , then P ( x 1 , · · · , x n ) = Y i P ( x i | x π ( i ) ) According to this theorem, w e can represent P in a compact wa y when G is sparse such that the num b er of parameter needed is lin ear in the num b er of v ariables. This theorem is true in the reverse direction. The set X is d-separated from set Y given set Z if all paths from a no de in X to a no de in Y are blo c ked given Z . The graphical mo dels can e ss e ntially b e divided into tw o groups: directed graphical mo dels and undirected graphical mo dels. X 2 X 9 X 1 Figure 1.1: An Ising mo del with 9 no des. 4 1.3 Undirected Graphical Mo dels 1.3.1 Mark o v Random Field A Mark ov Random Field (MRF) is defined as a pair M = h G, Φ i . Here G = h V , E i represen ts an undirected graph, where V = { V i } is th e set of nodes, eac h of which corresp onds to a random v ariable in X ; E = { ( V i , V j ) : i 6 = j } represents the set of undirected edges. The existence of an edge { u, v } indicates the dep endency of the random v ariable u and v . Φ is a set of p oten tial functions (also called factors or clique p oten tials) asso ciated with the maximal cliques in the graph G . Eac h p oten tial function φ c ( · ) has the domain of some clique c in G , and is a mapping from p ossible joint assignments (to the elemen ts of c ) to non-negative real v alu es . A maximal clique of a graph is a fully connected sub-graph that can not b e further extended. W e use C to represen t the set of maximal cliques in the graph . φ c is the potential function for a maxi mal clique c ∈ C . The joint probability of a configuration x of the v ariables V can b e calculated as the normalized pro duct of the p oten tial function o ver all the maximal cliques in G : P ( x ) = Q c ∈C φ c ( x c ) P x ′ c Q c ∈C φ c ( x c ) where x c represents the curren t configuration of v ariables in the maximal clique c , x ′ c represents any p ossible configuration of v ariable in the maximal cli qu e c . In practice, a Marko v netw ork is often conv eniently expressed as a log-linear mo del, given by P ( x ) = exp P c ∈ C w c φ c ( x c ) P x ∈X exp P c ∈C w c φ c ( x c ) In the ab o v e equation, φ c are feature functions from some subset of X to real v alues, w c are weigh ts which are to be determined from training samples. A log- linear mo del can provide more compact representations for any distributions, esp ecially when the v ariables hav e large domains. This representation is also con venien t in analysis b ecause its negative log lik eliho od is con vex. Ho wev er, ev aluating the lik eliho od or gradient of the likelihoo d of a model requires in- ference in the mo del, which is generally computationally intractable due to the difficult y in calculating the partitioning function. The Ising mo del is a sp ecial case of Mark ov Random Field. It comes from statistical ph ysics, where eac h node represents the spin of a particle. In an Ising mo del, the graph i s a grid, so each edge is a clique . Eac h no de in th e Ising mo del takes binary v alues { 0 , 1 } . The p ar ameter s are θ i representing the external field on particle i , and θ ij representing the attraction b et ween particles 5 i and j . θ ij = 0 if i and j are n ot adjacent. The probability distribution is: p ( x | θ ) = exp X i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment