그래프 모델 구조 학습의 모든 것: 최신 알고리즘 총정리
본 논문은 확률 그래프 모델(Undirected & Directed)의 구조를 자동으로 추정하는 다양한 방법론을 체계적으로 정리한다. 제약 기반, 점수 기반, 회귀 기반, 하이브리드 및 기타 접근법을 구분하고, 각 알고리즘의 핵심 아이디어, 수학적 근거, 탐색 공간, 계산 복잡도 및 적용 사례를 비교한다. 또한 구조 학습이 직면한 조합적 난제와 최근 연구 동향을 조명한다.
저자: Yang Zhou
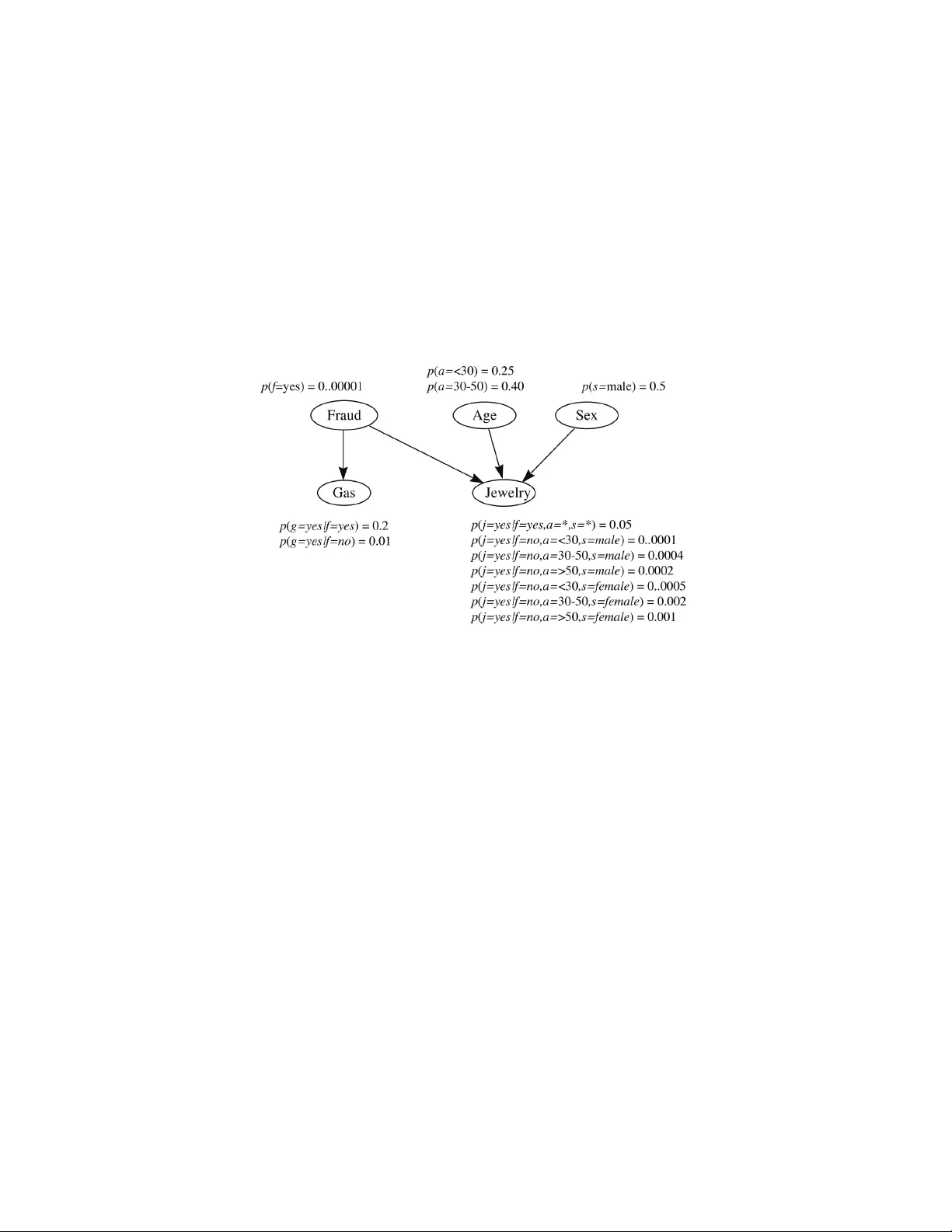
본 서베이 논문은 확률 그래프 모델(Probabilistic Graphical Models, PGM)의 구조 학습 문제를 포괄적으로 정리한다. 서론에서는 PGM이 확률론과 그래프 이론을 결합해 다변량 확률 분포를 직관적으로 표현하고, 조건부 독립성, 추론 복잡도 감소, 모델 설계 지원 등 다양한 장점을 제공한다는 점을 강조한다. 이어서 기본 용어와 표기법을 정의하고, 무향 그래프(MRF, Gaussian Graphical Model)와 유향 그래프(베이시안 네트워크) 등 주요 모델군을 상세히 설명한다. 특히 마코프 블랭킷, d‑separation, 팩터 그래프 등 핵심 개념을 수학적으로 정리하고, Ising 모델과 같은 특수 사례를 통해 실제 적용 맥락을 보여준다.
구조 학습을 크게 네 가지 접근법으로 구분한다.
1. **제약 기반(Constraint‑based) 알고리즘**
- **SGS (Skeleton Generation and Separation)**: 모든 변수 쌍에 대해 조건부 독립성 검정을 수행해 스켈레톤을 만든 뒤, v‑structures를 식별한다.
- **PC 알고리즘**: 변수 순서를 정하고, 낮은 차수의 조건부 독립성부터 검정해 탐색 비용을 감소시킨다.
- **GS 알고리즘**: 변수 집합을 점진적으로 확장·축소하며 인접성을 추정한다.
이들 방법은 독립성 검정 결과에 전적으로 의존하므로, 검정 오류가 구조 오류로 직접 연결된다. 또한, 고차원 데이터에서 검정 수가 급증해 계산량이 크게 늘어난다.
2. **점수 기반(Score‑based) 알고리즘**
- **점수 함수**: MDL(Minimum Description Length), BDe(Bayesian Dirichlet equivalent), BIC(Bayesian Information Criterion) 등을 소개하고, 각 점수가 모델 복잡도와 데이터 적합도를 어떻게 균형 잡는지 설명한다.
- **탐색 전략**: 전체 구조 공간 탐색(전역 최적화), 순서 공간 탐색(노드 순열 기반), 힐클라이밍, 탭우 탐색, MCMC 샘플링, 동적 프로그래밍 등 다양한 최적화 기법을 제시한다.
- **장·단점**: 점수 기반은 전역 최적을 찾을 가능성이 높지만, 점수 계산에 충분한 충분통계와 사전 분포가 필요하고, 탐색 과정이 여전히 지수적 복잡도를 가진다.
3. **회귀 기반(Regression‑based) 알고리즘**
- **선형 회귀와 Lasso**: 각 변수에 대해 다른 변수들을 설명 변수로 두고 L1 정규화를 적용해 스파스 인접성을 추정한다.
- **다양한 목적 함수**: Likelihood, Dependency, System‑identification, Precision matrix, MDL 등 여러 목표를 정의하고, 각각이 그래프 구조와 어떻게 연결되는지 분석한다.
- **특징**: 고차원·저표본 상황에서 효율적이며, 정밀 행렬 추정과 직접 연결돼 GGM에 특히 유용하지만, 비선형·비가우시안 관계를 포착하기 어렵다.
4. **하이브리드 및 기타 접근법**
- **하이브리드**: 제약 기반과 점수 기반을 결합해 초기 구조를 제약 기반으로 빠르게 얻고, 점수 기반으로 정교화한다.
- **클러스터링 기반**: 변수들을 클러스터링해 모듈 단위로 구조를 학습하고, 모듈 간 관계를 추정한다.
- **부울 네트워크**: SAT/SMT 솔버를 이용해 이산 변수의 논리적 제약을 만족하는 그래프를 찾는다.
- **정보 이론 기반**: 상호 정보, 최소 설명 길이 등을 이용해 변수 간 의존성을 직접 측정한다.
- **행렬 분해 기반**: NMF, PCA 등으로 잠재 요인을 추출하고, 요인 간 상관관계로 그래프를 구성한다.
각 장에서는 알고리즘 흐름도, 복잡도 분석, 주요 참고문헌을 표로 정리하고, 실제 적용 사례(유전자 발현 네트워크, 이미지 분할, 사회 네트워크 분석 등)를 통해 실용성을 입증한다.
마지막 장에서는 구조 학습이 본질적으로 NP‑hard 문제이며, 현재 연구가 다음과 같은 방향으로 진행되고 있음을 강조한다.
- **스케일러블 근사**: 샘플링 기반, 그래디언트 기반, 분산 컴퓨팅을 활용한 대규모 데이터 처리.
- **베이지안 비모수 방법**: Dirichlet Process, Indian Buffet Process 등으로 사전 가정을 완화하고, 무한 차원의 구조를 탐색.
- **강인성**: 노이즈와 결측치에 강인한 검정·점수 설계, 적응형 검정 순서.
- **도메인 특화**: 생물학적 네트워크의 모듈성, 사회 네트워크의 스몰월드·프리‑와이어 특성을 활용한 맞춤형 알고리즘.
결론적으로, 본 서베이는 구조 학습 분야의 전반적인 연구 흐름을 한눈에 파악하도록 돕고, 연구자들이 자신의 문제에 맞는 알고리즘을 선택하거나 새로운 방법을 설계하는 데 필요한 이론적·실험적 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기