Self-Avoiding Random Dynamics on Integer Complex Systems
This paper introduces a new specialized algorithm for equilibrium Monte Carlo sampling of binary-valued systems, which allows for large moves in the state space. This is achieved by constructing self-avoiding walks (SAWs) in the state space. As a con…
Authors: Firas Hamze, Ziyu Wang, N
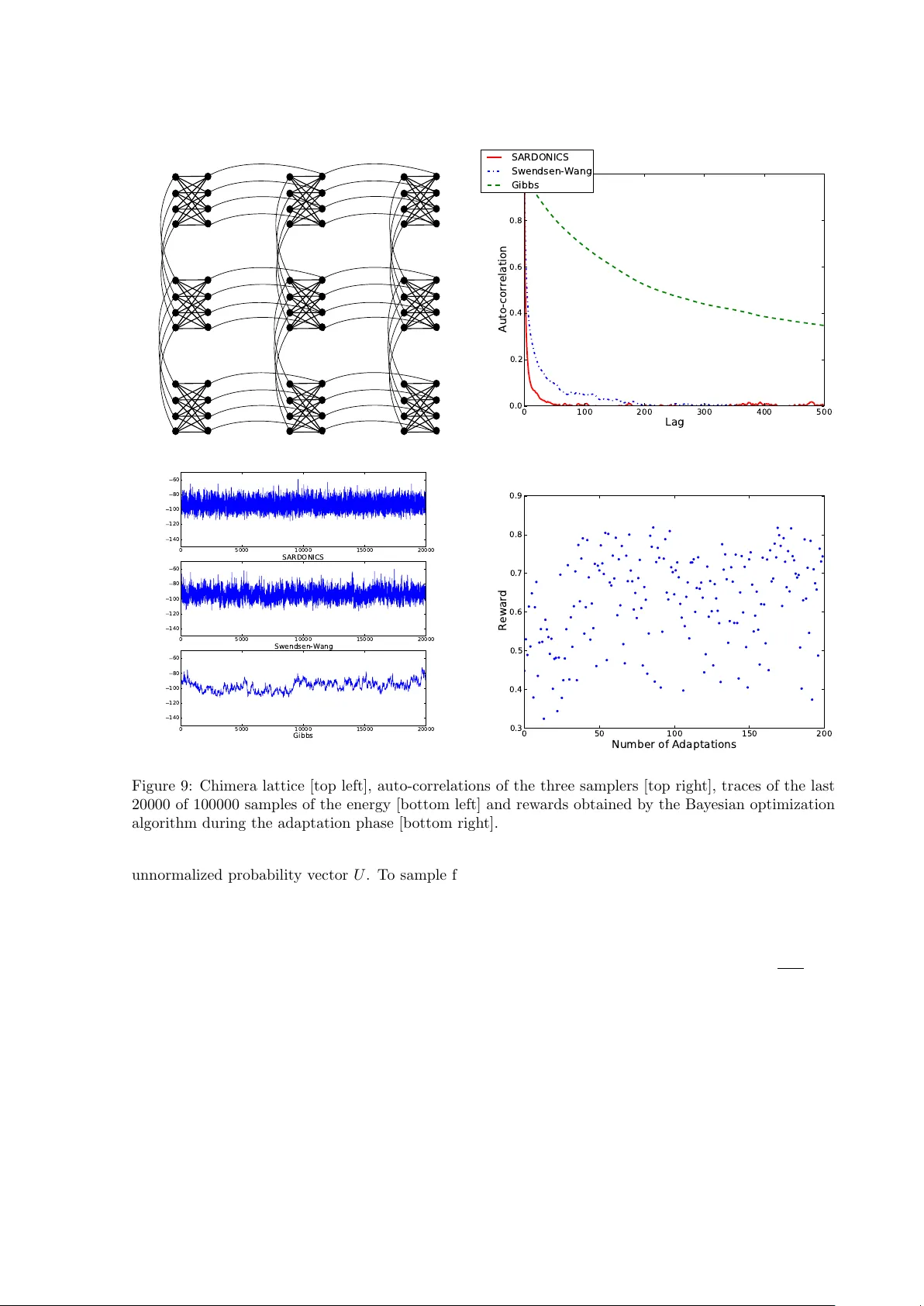
Self-Av oiding Random Dynamics on In teger Complex Systems Firas Hamze ∗ Ziyu W ang † Nando de Freit as ‡ Septem b er 17, 2018 Abstract This pap er in tro duces a new specialized algorithm for equilibrium Monte Carlo sampling of binary- v alued systems, whic h allows for large mov es in the state space. This is achiev ed b y constructing self-a voiding w alks (SA Ws) in the state space. As a consequence, many bits are flipp ed in a single MCMC step. W e name the algorithm SARDONICS, an acron ym for Self-Av oiding Random Dynamics on In teger Complex Systems. The algorithm has sev eral free parameters, but we sho w that Bay esian optimization can b e used to automatically tune them. SARDONICS p erforms remark ably well in a broad n um b er of sampling tasks: toroidal ferromagnetic and frustrated Ising mo dels, 3D Ising mo dels, restricted Boltzmann mac hines and chimera graphs arising in the design of quantum computers. 1 In tro duction Ising mo dels, also known as Boltzmann machines, are ubiquitous mo dels in physics, machine learning and spatial statistics [1, 6, 46, 32, 30]. They hav e recently lead to a revolution in unsup ervised learning kno wn as deep learning, see for example [27, 42, 48, 34, 40]. There is also a remark ably large num b er of other statistical inference problems, where one can apply Rao-Blackw ellization [23, 50, 35] to integrate out all contin uous v ariables and end up with a discrete distribution. Examples include topic mo deling and Dirichlet pro cesses [8], Bay esian v ariable selection [62], mixture mo dels [36] and multiple instance learning [33]. Th us, if w e had effective wa ys of sampling from discrete distributions, we would solve a great man y statistical problems. Moreov er, since inference in Ising mo dels can be reduced to max-SA T and coun ting-SA T problems [3, 65, 7], efficient Mon te Carlo inference algorithms for Ising mo dels would b e applicable to a v ast domain of computationally challenging problems, including constraint satisfaction and molecular simulation. Man y samplers ha ve b een introduced to mak e large mov es in con tinuous state spaces. Notable ex- amples are the Hamiltonian and Riemann Monte Carlo algorithms [12, 45, 17]. How ev er, there has b een little comparable effort when dealing with general discrete state spaces. One the most p opular algorithms in this domain is the Sw endsen-W ang algorithm [60]. This algorithm, as sho wn here, w orks w ell for sparse planar lattices, but not for densely connected graphical mo dels. F or the latter problems, acceptance rates to make large mo ves can b e very small. F or example, as pointed out in [44] Ising mo dels with Metropolis dynamics can require 10 15 trials to lea ve a metastable state at low temp eratures, and such a simulation w ould take 10 10 min utes. F or some of these mo dels, it is how ev er p ossible to compute the rejection probabilit y of the next mov e. This leads to more efficient algorithms that alwa ys accept the next mo ve [44, 25]. The problem with this is that at the next iteration the most fav orable mov e is often to go bac k to the previous state. That is, these samplers may often get trapp ed in cycles. T o ov ercome this problem, this pap er presents a sp ecialized algorithm for equilibrium Monte Carlo sampling of binary-v alued systems, which allows for large mov es in the state space. This is achiev ed b y constructing self-av oiding w alks (SA Ws) in the state space. As a consequence, many bits are flipp ed in a single MCMC step. W e prop osed a v ariant of this strategy for constrained binary distributions in [26]. The metho d presen ted here applies to unconstrained systems. It has many adv ancemen ts, but more free parameters ∗ D-wa v e Systems Inc.. Email: fhamze@dwa vesys.com † Universit y of British Columbia. Email: ziyuw@cs.ubc.ca ‡ Universit y of British Columbia. Email: nando@cs.ub c.ca 1 than our previous version, thus making the sampler hard to tune. F or this reason, we adopt a Bay esian optimization strategy [43, 9, 38] to automatically tune these free parameters, thereby allowing for the construction of parameter p olicies that trade-off exploration and exploitation effectively . Mon te Carlo algorithms for generating SA Ws for p olymer simulation originated with [52]. More recen tly , biased SA W processes were adopted as prop osal distributions for Metrop olis algorithms in [57], where the metho d was named c onfigur ational bias Monte Carlo . The crucial distinction b et ween these seminal w orks and ours is that those authors w ere concerned with simulation of physical systems that inheren tly posess the self-av oidance property , namely molecules in some state space. More sp ecifically , the ph ysics of such systems dictated that no comp onen t of a molecule ma y o ccup y the same spatial location as another; the algorithms they devised to ok this constraint into account. In contrast, we are treating a different problem, that of sampling from a binary state-space, where a priori, no suc h requirement exists. Our construction inv olv es the idea of imp osing self-a v oidance on sequences of generated states as a pro cess to instantiate a rapidly-mixing Marko v Chain on the binary state-space. It is therefore more related to the class of optimization algorithms known as T abu Search [18] than to classical p olymer SA W sim ulation metho ds. T o our kno wledge, though, a correct equilibrium Monte Carlo algorithm using the T abu-like idea of self-av oidance in state-space tra jectories has not y et b een prop osed. W e should also p oin t out that sequential Mon te Carlo (SMC) metho ds, such as Hot Coupling and annealed imp ortance sampling, ha ve b een prop osed to sample from Boltzmann mac hines [24, 54]. Since suc h samplers often use an MCMC k ernel as prop osal distribution, the MCMC sampler prop osed here could enhance those tec hniques. The same observ ation applies when considering other meta-MCMC strategies such as parallel temp ering [16, 13], m ulticanonical Monte Carlo [4, 20] and W ang-Landau [64] sampling. 2 Preliminaries Consider a binary-v alued system defined on the state space S , { 0 , 1 } M , i.e. consisting of M v ariables eac h of whic h can b e 0 or 1. The probability of a state x = [ x 1 , . . . x M ] is given by the Boltzmann distribution: π ( x ) = 1 Z ( β ) e − β E ( x ) (1) where β is an inverse temp er atur e. An instance of such a system is the ubiquitous Ising mo del of statistical ph ysics, also called a Boltzmann machine by the machine learning communit y . Our aim in this pap er is the generation of states distributed according to a Boltzmann distribution sp ecified by a particular energy function E ( x ). A standard procedure is to apply one of the lo c al Mark ov Chain Mon te Carlo (MCMC) methodologies suc h as the Metrop olis algorithm or the Gibbs (heat bath) sampler. As is w ell-known, these algorithms can suffer from issues of p oor equilibration (“mixing”) and trapping in lo cal minima at low temperatures. More sophisticated metho ds such as P arallel T emp ering [16] and the flat-histogram algorithms (e.g. m ulticanonical [4] or W ang-Landau [64] sampling) can often dramatically mitigate this problem, but they usually still rely on lo cal MCMC at some stage. The ideas presented in this paper relate to MCMC sampling using larger changes of state than those of local algorithms. They can be applied on their o wn or in conjunction with the previously-men tioned adv anced methods. In this paper, we fo cus on the p ossible adv antage of our algorithms ov er lo cal methods. Giv en a particular state x ∈ S , we denote by S n ( x ) the set of all states at Hamming distance n from x . F or example if M = 3 and x = [1 , 1 , 1], then S 0 ( x ) = { [1 , 1 , 1] } , S 1 ( x ) = { [0 , 1 , 1] , [1 , 0 , 1] , [1 , 1 , 0] } , etc. Clearly |S n ( x ) | = M n . W e define the set of bits in t wo states x , y that agree with each other: let P ( x , y ) = { i | x i = y i } . F or instance if x = [0 , 1 , 0 , 1] and y = [0 , 0 , 0 , 1], then P ( x , y ) = { 1 , 3 , 4 } . Clearly , P ( x , y ) = P ( y , x ) and P ( x , x ) = { 1 , 2 , . . . M } . Another useful definition is that of the flip op er ator , which simply inv erts bit i in a state, F ( x , i ) , ( x 1 , . . . , ¯ x i , . . . , x M ), and its extension that acts on a sequence of indices, i.e. F ( x , i 1 , i 2 , . . . , i k ) , F ( F ( . . . F ( x , i 1 ) , i 2 ) , . . . , i k ). F or illustration, we describe a simple Metrop olis algorithm in this framework. Consider a state x ∈ S ; a new state x 0 ∈ S 1 ( x ) is generated by flipping a random bit of x , i.e. x 0 = F ( x , i ) for i chosen uniformly 2 from { 1 , . . . , M } , and accepting the new state with probability: α = min(1 , e − β ( E ( x 0 ) − E ( x )) ) (2) If all the single-flip neighb ors of x , i.e. the states resulting from x via a single bit p erturbation, are of higher energy than E ( x ), the acceptance rate will b e small at low temperatures. 3 SARDONICS In con trast to the traditional single-flip MCMC algorithms, the elemen tary unit of our algorithm is a t yp e of mov e that allo ws for large changes of state and tends to propose them such that they are energetically fa vourable. W e b egin b y describing the mov e op erator and its incorp oration into the Mon te Carlo algorithm we call SARDONICS, an acronym for Self-Avoiding R andom Dynamics on Inte ger Complex Systems. This algorithm will then b e sho wn to satisfy the theoretical requirements that ensure correct asymptotic sampling. The mov e procedure aims to force exploration aw ay from the curren t state. In that sense it has a similar spirit to the T abu Se ar ch [18] optimization heuristic, but the aim of SARDONICS is equilibrium sampling, a problem more general than (and in many situations at least as c hallenging as) minimization. Supp ose that we hav e a state x 0 on S . It is p ossible to en vision taking a sp ecial type of biased self-avoiding walk (SA W) of length k in the state sp ac e , in other words a sequence of states such that no state recurs in the sequence. In this t yp e of SA W, states on sets {S 1 ( x 0 ) . . . S k ( x 0 ) } are visited consecutiv ely . T o generate this sequence of states ( u 1 , . . . , u k ), at step i of the pro cedure a bit is chosen to b e flipp ed from those that hav e not yet flipp ed relativ e to x 0 . Sp ecifically , an element σ i is selected from P ( x 0 , u i − 1 ), with u 0 , x 0 , to yield state u i = F ( u i − 1 , σ i ), or equiv alently , u i = F ( x 0 , σ 1 , . . . , σ i ). F rom u i − 1 ∈ S i − 1 ( x 0 ), the set of states on S i that can result from flipping a bit in P ( x 0 , u i − 1 ) are called the single-flip neighb ours of u i − 1 on S i ( x 0 ). The set of bits that can flip with nonzero probability are called the al lowable moves at each step. A diagrammatic depiction of the SA W is shown in Figure 1. The elements { σ i } are sampled in an ener gy-biase d manner as follo ws: f ( σ i = l | σ i − 1 , . . . , σ 1 , x 0 ) = e − γ E ( F ( u i − 1 ,l )) P j ∈P ( x 0 , u i − 1 ) e − γ E ( F ( u i − 1 ,j )) l ∈ P ( x 0 , u i − 1 ) and u i − 1 = F ( x 0 , σ 1 , . . . , σ i − 1 ) 0 otherwise (3) The larger the v alue that simulation parameter γ is assigned, the more likely the proposal f is to sample the low er-energy neighbors of u i − 1 . Conv ersely if it is zero, a neighbor on S i ( x 0 ) is selected completely at random. In principle, the v alue of γ will b e seen to b e arbitrary; indeed it can ev en b e different at eac h step of the SA W. W e wil hav e more to say ab out the c hoice of γ , as well as the related issue of the SA W lengths, in Section 4.2. The motiv ation b ehind using suc h an energy-biased scheme is that when prop osing large changes of configuration, it ma y generate final states that are “typical” of the system’s target distribution. T o make a big state-space step, one may imagine uniformly p erturbing a large n umber of bits, but this is likely to yield states of high energy , and an MCMC algorithm will b e extremely unlikely to accept the mov e at lo w temp eratures. A t this p oint it can b e seen wh y the term “self-av oiding” aptly describ es the processes. If we imagine the state-space to b e a high-dimensional lattice, with the individual states lying at the vertices and edges linking states that are single-flip neigh b ors, a self-av oiding walk on this graph is a sequence of states that induce a connected, acyclic subgraph of the lattice. In the mov e pro cedure we hav e describ ed, a state can never o ccur twice at an y stage within it and so the pro cess is ob viously self-av oiding. Note how ev er that the construction imp oses a stronger condition on the state sequence; once a tran- sition o ccurs from state x to state F ( x , i ), not only may state x not app ear again, but neither ma y any state y with y i = x i . It seems natural to ask why not to use a less constrained SA W pro cess, namely one that av oids returns to individual states and lik ely more familiar to those exp erienced in molecular and p olymer simulations, without eliminating an entire dimension at eac h step. In our exp erience, try- ing to construct such a SA W as a prop osal requires excessiv e computational memory and time to yield 3 x 0 = [1 1 1 0 0 ] u 1 u 2 u 3 = [1 0 1 1 1 ] S 1 ( x 0 ) S 2 ( x 0 ) S 3 ( x 0 Figure 1: A visual illustration of the mov e process for a SA W of length 3. The arro ws represent the allo wable mo ves from a state at that step; the red arrow shows the actual mov e taken in this example. With the system at state x 0 , the SA W b egins. Bit 4 of x 0 has been sampled for flipping according to Equation 3 to yield state u 1 = [11110]; the process is repeated until state u 3 on S 3 ( x 0 ) is reac hed. The sequence of states taken b y the SA W is σ = [4 , 2 , 5] . go od state-space trav ersal. A lo cal minim um “basin” of a combinatoric landscape can p otentially con tain a massiv e num ber of states, and a pro cess that mov es by explicitly av oiding particular states may b e do omed to w ander within and visit a substan tial p ortion of the basin prior to escaping. Let x 1 b e the final state reached b y the SA W, i.e. u k for a length k walk. By m ultiplying the SA W flipping probabilities, w e can straigh tforwardly obtain the probabilit y of mo ving from state x 0 to x 1 along the SA W σ , whic h we call f ( x 1 , σ | x 0 ): f ( x 1 , σ | x 0 ) , δ x 1 [ F ( x 0 , σ )] k Y i =1 f ( σ i | u i − 1 ) (4) The delta function simply enforces the fact that the final state x 1 m ust result from the sequence of flips in σ from x 0 . The set of { σ } suc h that f ( x 1 , σ | x 0 ) > 0 are termed the al lowable SA Ws b et w een x 0 and x 1 . Ideally , to implement a Metropolis-Hastings (MH) algorithm using the SA W prop osal, w e would lik e to ev aluate the mar ginal probability of prop osing x 1 from x 0 , which we call f ( x 1 | x 0 ), so that the mov e w ould b e accepted with the usual MH ratio: α m ( x 0 , x 1 ) , min 1 , π ( x 1 ) f ( x 0 | x 1 ) π ( x 0 ) f ( x 1 | x 0 ) (5) Unfortunately , for all but small v alues of the walk lengths k , marginalization of the proposal is in tractable due to the p oten tially massive n umber of allow able SA Ws b et ween the t wo states. T o assist in illustrating our solution to this, w e recall that a sufficient condition for a Mark ov transition k ernel K to hav e target π as its stationary distribution is detaile d b alanc e: π ( x 0 ) K ( x 1 | x 0 ) = π ( x 1 ) K ( x 0 | x 1 ) (6) One sp ecial case obtains if we used the marginalized prop osal f ( x 1 | x 0 ) follow ed b y the MH accept rule, K m ( x 1 | x 0 ) , f ( x 1 | x 0 ) α m ( x 0 , x 1 ) (7) As we cannot compute f ( x 1 | x 0 ), we shall use a kernel K ( x 1 , σ | x 0 ) defined on the joint sp ac e of SA Ws and states, and show that with some care, detailed balance (6) can still hold mar ginal ly . It will b e clear, 4 though that this do es not mean that the resultant marginal kernel K ( x 1 | x 0 ) is the same as that in (7) obtained using MH acceptance on the marginal pr op osal . Define the se quenc e r eversal op er ator R ( σ ) to simply return a sequence consisting of the elements of σ in reverse order; for example R ([2 , 3 , 1 , 4]) = [4 , 1 , 3 , 2]. One can straightforw ardly observe that eac h allo wable SA W σ from x 0 to x 1 can b e uniquely mapp ed to the allow able SA W R ( σ ) from x 1 to x 0 . F or example in Figure 1, the SA W R ( σ ) = [5 , 2 , 4] can b e seen to b e allow able from x 1 to x 0 . Next, we hav e the following somewhat more in volv ed concept, a v ariant of whic h we in tro duced in [26]: Definition 1. Consider a Markov kernel K ( x 1 , σ | x 0 ) whose supp ort set c oincides with that of (4). We say that pathwise detailed balance holds if π ( x 0 ) K ( x 1 , σ | x 0 ) = π ( x 1 ) K ( x 0 , R ( σ ) | x 1 ) for al l σ , x 0 , x 1 . It turns out that pathwise detailed balance is a str onger c ondition than marginal detailed balance. In other words, Prop osition 1. If the pr op erty in Definition 1 holds for a tr ansition kernel K of the typ e describ e d ther e, then π ( x 0 ) K ( x 1 | x 0 ) = π ( x 1 ) K ( x 0 | x 1 ) Pr o of. Supp ose, for given x 0 , x 1 , we summed b oth sides of the equation enforcing path wise detailed balance ov er all allow able SA Ws { σ 0 } from x 0 to x 1 , i.e. X σ 0 π ( x 0 ) K ( x 1 , σ 0 | x 0 ) = X σ 0 π ( x 1 ) K ( x 0 , R ( σ 0 ) | x 1 ) The left-hand summation marginalizes the kernel o v er allow able SA Ws and hence results in π ( x 0 ) K ( x 1 | x 0 ). The observ ation ab o v e that eac h allo wable SA W from x 0 to x 1 can be reversed to yield an allow able one from x 1 to x 0 implies that the right-hand side is simply a re-ordered summation ov er all allo wable SA Ws from x 1 to x 0 , and can thus be written as π ( x 1 ) K ( x 0 | x 1 ). W e are now ready to state the final form of the algorithm, which can b e seen to instantiate a Marko v c hain satisfying pathwise detailed balance. After prop osing ( x 1 , σ ) using the SA W pro cess, w e accept the mov e with the ratio: α ( x 0 , x 1 , σ ) , min 1 , π ( x 1 ) f ( x 0 , R ( σ ) | x 1 ) π ( x 0 ) f ( x 1 , σ | x 0 ) (8) The computational complexity of ev aluating this accept ratio is of the same order as that required to sample the prop osed SA Ws/state; the only additional op erations required are those needed to ev aluate the reverse prop osal app earing in the n umerator, which are completely analogous to those inv olved in calculating the forward proposal. Let us tak e a closer look at the marginal transition k ernel K ( x 1 | x 0 ). W e can factor the joint pr op osal in to: f ( x 1 , σ | x 0 ) = f ( x 1 | x 0 ) f ( σ | x 0 , x 1 ) Of course, if w e are assuming that f ( x 1 | x 0 ) is intractable to ev aluate, then the conditional f ( σ | x 0 , x 1 ) m ust b e so as well, but it is useful to consider. If we no w summed b oth sides of the joint probabilit y of mo ving from x 0 to x 1 o ver allo wable paths, w e would observ e: X σ 0 π ( x 0 ) K ( x 1 , σ 0 | x 0 ) = π ( x 0 ) f ( x 1 | x 0 ) X σ 0 f ( σ 0 | x 0 , x 1 ) α ( x 0 , x 1 , σ 0 ) The summation on the right-hand side is th us the c onditional exp e ctation of the accept rate giv en that w e are attempting to mo ve from x 0 to x 1 ; we call it α ( x 0 , x 1 ) , X σ 0 f ( σ 0 | x 0 , x 1 ) α ( x 0 , x 1 , σ 0 ) (9) and it defines an effe ctive ac c eptanc e r ate b etw een x 0 and x 1 under the sampling regime described since K ( x 1 | x 0 ) = f ( x 1 | x 0 ) α ( x 0 , x 1 ). It is not difficult to sho w that α ( x 0 , x 1 ) 6 = α m ( x 0 , x 1 ), i.e. the marginal accept rate for the join t prop osal is not the same as the one that results from using the marginalized prop osal. In fact we can mak e a stronger statement: 5 Prop osition 2. F or every p air of states ( x 0 , x 1 ) , α ( x 0 , x 1 ) ≤ α m ( x 0 , x 1 ) Pr o of. F or conciseness, denote 1 α m ( x 0 , x 1 ) = π ( x 0 ) f ( x 1 | x 0 ) π ( x 1 ) f ( x 0 | x 1 ) b y C . Define the sets A , { σ | f ( R ( σ ) | x 1 , x 0 ) f ( σ | x 0 , x 1 ) ≥ C } and ¯ A , { σ | f ( R ( σ ) | x 1 , x 0 ) f ( σ | x 0 , x 1 ) < C } . Then α ( x 0 , x 1 ) = X σ 0 f ( σ 0 | x 0 , x 1 ) min 1 , π ( x 1 ) f ( x 0 | x 1 ) f ( R ( σ 0 ) | x 1 , x 0 ) π ( x 0 ) f ( x 1 | x 0 ) f ( σ 0 | x 0 , x 1 ) = X σ 0 ∈A f ( σ 0 | x 0 , x 1 ) + π ( x 1 ) f ( x 0 | x 1 ) π ( x 0 ) f ( x 1 | x 0 ) X σ 0 ∈ ¯ A f ( R ( σ 0 ) | x 1 , x 0 ) = X σ 0 ∈A f ( σ 0 | x 0 , x 1 ) + 1 C X σ 0 ∈ ¯ A f ( R ( σ 0 ) | x 1 , x 0 ) But by definition, for σ ∈ A , f ( σ | x 0 , x 1 ) ≤ 1 C f ( R ( σ ) | x 1 , x 0 ). Therefore, α ( x 0 , x 1 ) ≤ 1 C X σ 0 ∈A f ( R ( σ 0 ) | x 1 , x 0 ) + 1 C X σ 0 ∈ ¯ A f ( R ( σ 0 ) | x 1 , x 0 ) = 1 C X σ 0 ∈A f ( R ( σ 0 ) | x 1 , x 0 ) + X σ 0 ∈ ¯ A f ( R ( σ 0 ) | x 1 , x 0 ) = 1 C = α m ( x 0 , x 1 ) There is another tec hnical consideration to address. The reader may hav e remarked that while detailed balance do es indeed hold for our algorithm, if the SA W length is constant at k > 1, then the resulting Mark ov c hain is no longer irr e ducible. In other w ords, not every x ∈ S is reachable with nonzero probabilit y regardless of the initial state. F or example if k = 2 and the initial state x 0 = [0 , 0 , 0 , 0 , 0 , 0], then the state x = [0 , 0 , 0 , 0 , 0 , 1] can nev er be visited. F ortunately , this is a rather easy issue to o vercome; one p ossible strategy is to randomly choose the SA W length prior to each step from a set that ensures that the whole state s pace can even tually b e visited. A trivial example of suc h a set is any collection of in tegers that include unity , i.e. such that single-flip mov es are allow ed. Another is a set that includes consecutiv e integers, i.e. { k 0 , k 0 + 1 } for any k 0 < M . This latter choice could allo w states separated by a single bit to o ccur in tw o steps; in the example ab ov e, if the set of lengths was { 3 , 4 } then we could hav e [0 , 0 , 0 , 0 , 0 , 0] → [0 , 0 , 1 , 1 , 1 , 1] → [0 , 0 , 0 , 0 , 0 , 1]. While this shows ho w to enforce theoretical correctness of the algorithm, in up coming sections we will discuss the issue of practical choice of the lengths in the set. The experimental section discusses the practical matter of efficiently sampling the SA W for systems with sparse connectivity , such as the 2D and 3D Ising mo dels. 3.1 Iterated SARDONICS The SARDONICS algorithm presen ted in Section 3 is sufficient to work effectiv ely on man y t yp es of system, for example Ising mo dels with ferromagnetic interactions. This section, ho wev er, will detail a more adv anced strategy for prop osing states that uses the state-space SA W of Section 3 as its basic mo ve. The ov erall idea is to extend the trial pro cess so that the search for a state to prop ose can contin ue from the state resulting from a c onc atenate d series of SA Ws from x 0 . The reader familiar with com binatorial optimization heuristics will note the philosophical resemblance to the class of algorithms termed iter ate d lo c al se ar ch [29], but will again b ear in mind that in the present work, w e are interested in equilibrium sampling as opp osed to optimization. W e begin b y noting that restriction to a single SA W is unnecessary . W e can readily consider in principle an arbitrary concatenation of SA Ws ( σ 1 , σ 2 , . . . , σ N ). A straigh tforward extension of the SA W 6 prop osal is then to select some num ber of iterations N (whic h need not b e the same from one mov e attempt to the next,) to generate x 1 from x 0 b y sampling from the concatenated proposal, defined to b e g ( x 1 , σ 1 , . . . , σ N | x 0 ) , f ( y 1 , σ 1 | x 0 ) f ( y 2 , σ 2 | y 1 ) . . . f ( y N , σ N | y N − 1 ) δ x 1 ( y N ) (10) and to accept the mov e with probability α ( x 0 , x 1 , σ 1 . . . , σ N ) = min 1 , π ( x 1 ) g ( x 0 , R ( σ N ) , . . . R ( σ 1 ) | x 1 ) π ( x 0 ) g ( x 1 , σ 1 , . . . , σ N | x 0 ) (11) In (10), the sup erscripted { y i } refer to the “intermediate” states on S generated by the flip sequences, and the functions f are the SA W prop osals discussed in Section 3. The prop osed state x 1 is iden tical to the final intermediate state y N ; to a void obscuring the notation with to o man y delta functions w e take it as implicit that the the prop osal ev aluates to zero for in termediate states that do not follow from the flip sequences { σ i } . W e refer to this as the iter ate d SARDONICS algorithm. Its p otential merit ov er taking a single SA W is that it may generate more distant states from x 0 that are fa v orable. Unfortunately , a priori there is no guaran tee that the final state x 1 will be more worth y of acceptance than the intermediate states visited in the pro cess; it is computationally wasteful to often prop ose long sequences of flips that end up rejected, esp ecially when p oten tially desirable s tates may hav e b een passed ov er. It is thus very imp ortan t to c ho ose the right v alue of N . F or this reason, w e will introduce Bay esian optimization techniques to adapt N and other parameters automatically in the following section. 3.2 Mixture of SA Ws A further addition we made to the basic algorithm was the generalization of the prop osal to a mixture of SA W pro cesses. Each segment of the iterated pro cedure introduced in Section 3.1 could in principle op erate at a different lev el of the biasing parameter γ . A p ossible strategy one can en vision is to o cca- sionally take a p air of SA Ws with the first at a small v alue of γ and the next at a large v alue. The first step encourages exploration a wa y from the curren t state, and the second a search for a new low-energy state. More specifically , for the t wo SA Ws ( σ 1 , σ 2 ), we can ha ve a proposal of the form: f ( x 1 , σ 1 , σ 2 | x 0 ) = f ( y 1 , σ 1 | x 0 , γ L ) f ( x 1 , σ 2 | y 1 , γ H ) where γ H and γ L are high and low in v erse temp erature biases resp ectiv ely . Unfortunately , such a method on its own will likely result in a high rejection rate; the numerator of the MH ratio enforcing detailed balance will b e: f ( x 0 , R ( σ 2 ) , R ( σ 1 ) | x 1 ) = f ( y 1 , R ( σ 2 ) | x 1 , γ L ) f ( x 0 , R ( σ 1 ) | y 1 , γ H ) The probability of taking the reverse sequences will likely b e v ery small compared to those of the forward sequences. In particular, the likelihoo d of descending at low-temperature biasing parameter along the sequence R ( σ 1 ), where σ 1 w as generated with the high-temp erature parameter, will b e lo w. Our simple approac h to dealing with this is to define the prop osal to b e a mixtur e of three t yp es of SA W pro cesses. The mixture weigh ts, P LL , P H L , P LH , with P LL + P LH + P H L = 1, define, respectively , the frequencies of choosing a prop osal unit consisting of a p air of SA Ws sampled with ( γ L , γ L ), ( γ H , γ L ), and ( γ L , γ H ). The first proposal type encourages local exploration; b oth SA Ws are biase d to wards low- energy states. The second one, as discussed, is desirable as it may help the sampler escap e from lo cal minima. The last one ma y seem somewhat strange; since it ends with sampling at γ H , it will tend to generate states with high energy whic h will consequently b e rejected. The purp ose of this prop osal, ho wev er, is to assist in the acceptance of the HL exploratory mov es due to its presence in the mixture prop osal. Thus, P LH is a parameter that must be carefully tuned. If it is to o large, it will generate to o man y mov es that will end up rejected due to their high energy; if too small, its p oten tial to help the HL mo ves b e accepted will b e diminished. The mixture parameters are thus ideal candidates to explore the effectiv eness of adaptiv e strategies to tune MCMC. 7 4 Adapting SARDORNICS with Ba y esian Optimization SARDONICS has sev eral free parameters: upp er and lo wer bounds on the SA W length ( k u and k l resp ec- tiv ely), γ H , γ L , P LL , P H L , P LH as explained in the previous section, and finally the num b er of concate- nated SA Ws N . W e group these free parameters under the sym b ol θ = { k u , k l , γ H , γ L , P LL , P H L , P LH , N } . Eac h θ defines a sto c hastic p olicy , where the SA W length k is chosen at random in the set [ k l , k u ] and where the SA W pro cesses are chosen according to the mixture probabilities P LL , P H L , P LH . T uning all these parameters by hand is an onerous task. F ortunately , this challenge can b e surmoun ted using adaptation. Sto c hastic approximation metho ds, at first sigh t, might app ear to b e go o d candidates for carrying out this adaptation. They hav e b ecome increasingly p opular in the subfield of adaptive MCMC [21, 2, 51, 63]. There are a few reasons, how ever, that force us to consider alternatives to sto c hastic appro ximation. In our discrete domain, there are no obvious optimal acceptance rates that could be used to construct the ob jective function for adaptation. Instead, w e c ho ose to optimize θ so as to minimize the area under the auto-correlation function up to a specific lag. This ob jective was previously adopted in [2, 38]. One migh t argue that is is a reasonable ob jective given that researc hers and practitioners often use it to diagnose the conv ergence of MCMC algorithms. Ho w ever, the computation of gradient estimates for this ob jective is v ery in volv ed and far from trivial [2]. This motiv ates the in tro duction of a gradient- free optimization sc heme known as Bay esian optimization [43, 9]. Bay esian optimization also has the adv antage that it trades-off exploration and exploitation of the ob jective function. In contrast, gradien t metho ds are designed to exploit lo cally and ma y , as a result, get trapped in unsatisfactory lo cal optima. The prop osed adaptive strategy consists of tw o phases: adaptation and sampling. In the adaptation phase Ba yesian optimization is used to construct a randomized p olicy . In the sampling phase, a mixture of MCMC kernels selected according to the learned randomized p olicy is used to explore the target distribution. Exp erts in adaptive MCMC would hav e realized that there is no theoretical need for this tw o- phase procedure. Indeed, if the samplers are uniformly ergodic, which is the case in our discrete setting, and adaptation v anishes asymptotically , then ergo dicit y can still b e established [51, 2]. How ev er, in our setting the complexit y of the adaptation scheme increases with time. Specifically , Ba yesian optimization, as we shall so on outline in detail, requires fitting a Gaussian pro cess to I points, where I is the n umber of iterations of the adaptation pro cedure. In the worst case, this computation is O ( I 3 ). There are tec hniques based on conjugate gradients, fast m ultip ole metho ds and lo w rank approximations to speed up this computation [15, 22]. Ho wev er, none of these ov ercome the issue of increasing storage and computational needs. So, for pragmatic reasons, w e restrict the num b er of adaptation steps. W e will discuss the consequence of this choice in the exp eriments and come back to this issue in the concluding remarks. The tw o phases of our adaptive strategy are discussed in more detail subsequently . 4.1 Adaptation Phase Our ob jective function for adaptive MCMC is the area under the auto-correlation function up to a sp ecific lag. This ob jective is intractable, but noisy observ ations of its v alue can b e obtained b y running the Mark ov chain for a few steps with a sp ecific choice of parameters θ i . Ba yesian optimization can be used to prop ose a new candidate θ i +1 b y approximating the unknown function using the entire history of noisy observ ations and a prior ov er this function. The prior distribution used in this pap er is a Gaussian pro cess. The noisy observ ations are used to obtain the predictiv e distribution of the Gaussian pro cess. An exp ected utility function derived in terms of the sufficient statistics of the predictive distribution is optimized to select the next parameter v alue θ i +1 . The ov erall pro cedure is sho wn in Algorithm 1. W e refer readers to [9] and [37] for in-depth reviews of Bay esian optimization. The unkno wn ob jective function h ( · ) is assumed to b e distributed according to a Gaussian pro cess with mean function m ( · ) and cov ariance function k ( · , · ): h ( · ) ∼ GP ( m ( · ) , k ( · , · )) . W e adopt a zero mean function m ( · ) = 0 and an anisotropic Gaussian cov ariance that is essen tially the 8 ALGORITHM 1: Adaptation phase of SARDONICS 1: for i = 1 , 2 , . . . , I do 2: Run SARDONICS for L steps with parameters θ i . 3: Use the dra wn samples to obtain a noisy evaluation of the ob jective function: z i = h ( θ i ) + . 4: Augment the observ ation set D 1: i = {D 1: i − 1 , ( θ i , z i ) } . 5: Update the GP’s sufficient statistics. 6: Find θ i +1 by optimizing an acquisition function: θ i +1 = arg max θ u ( θ |D 1: i ). 7: end for p opular automatic relev ance determination (ARD) k ernel [49]: k ( θ j , θ k ) = exp − 1 2 ( θ j − θ k ) T diag( ψ ) − 2 ( θ j − θ k ) where ψ ∈ R d is a vector of h yp er-parameters. The Gaussian pro cess is a surrogate mo del for the true ob jectiv e, which inv olves intractable exp ectations with respect to the in v arian t distribution and the MCMC transition kernels. W e assume that the noise in the measurements is Gaussian: z i = h ( θ i ) + , ∼ N (0 , σ 2 η ). It is p ossible to adopt other noise mo dels [11]. Our Gaussian pro cess emulator has hyper-parameters ψ and σ η . These hyper-parameters are typically computed by maximizing the likelihoo d [49]. In Ba yesian optimization, w e can use Latin h yp ercube designs to select an initial set of parameters and then proceed to maximize the likelihoo d of the h yp er-parameters iteratively [66, 55]. This is the approach follo wed in our exp erimen ts. Ho w ever, a go od alternativ e is to use either classical or Bay esian quadrature to in tegrate out the h yp er-parameters [47, 53]. Let z 1: i ∼ N (0 , K ) b e the i noisy observ ations of the ob jective function obtained from previous iterations. (Note that the Mark ov chain is run for L steps for each discrete iteration i . The extra index to indicate this fact has b een made implicit to improv e readability .) z 1: i and h i +1 are jointly m ultiv ariate Gaussian: z 1: i h i +1 = N 0 , K + σ 2 η I k T k k ( θ , θ ) , where K = k ( θ 1 , θ 1 ) . . . k ( θ 1 , θ i ) . . . . . . . . . k ( θ i , θ 1 ) . . . k ( θ i , θ i ) and k = [ k ( θ , θ 1 ) . . . k ( θ , θ i )] T . All the abov e assumptions about the form of the prior distribution and observ ation model are standard and less restrictive than they might app ear at first sight. The cen tral assumption is that the ob jective function is smooth. F or ob jective functions with discon tin uities, we need more sophisticated surrogate functions for the cost. W e refer readers to [19] and [9] for examples. The predictiv e distribution for any v alue θ follows from the Sherman-Morrison-W o odbury formula, where D 1: i = ( θ 1: i , z 1: i ): p ( h i +1 |D 1: i , θ ) = N ( µ i ( θ ) , σ 2 i ( θ )) µ i ( θ ) = k T ( K + σ 2 η I ) − 1 z 1: i σ 2 i ( θ ) = k ( θ , θ ) − k T ( K + σ 2 η I ) − 1 k The next query p oin t θ i +1 is chosen to maximize an acquisition function, u ( θ |D 1: i ), that trades- off exploration (where σ 2 i ( θ ) is large) and exploitation (where µ i ( θ ) is high). W e adopt the exp ected impro vemen t o ver the best candidate as this acquisition function [43, 56, 9]. This is a standard acquisition function for whic h asymptotic rates of conv ergence hav e b een pro ved [10]. Ho w ever, we p oin t out that there are a few other reasonable alternatives, such as Thompson sampling [41] and upp er confidence b ounds (UCB) on regret [59]. A comparison among these options as well as portfolio strategies to com bine them app eared recently in [28]. There are several go od w ays of optimizing the acquisition function, 9 including the metho d of DIvided RECT angles (DIRECT) of [14] and many v ersions of the pro jected Newton metho ds of [5]. W e found DIRECT to provide a v ery efficien t solution in our domain. Note that optimizing the acquisition function is m uch easier than optimizing the original ob jectiv e function. This is b ecause the acquisition functions can b e easily ev aluated and differen tiated. 4.2 Sampling Phase The Bay esian optimization phase results in a Gaussian pro cess on the I noisy observ ations of the perfor- mance criterion z 1: I , taken at the corresp onding locations in parameter space θ 1: I . This Gaussian process is used to construct a discrete stochastic p olicy p ( θ | z 1: I ) ov er the parameter space Θ . The Mark ov chain is run with parameter settings randomly dra wn from this p olicy at each step. One can synthesize the p olicy p ( θ | z 1: I ) in several w ays. The simplest is to use the mean of the GP to construct a distribution prop ortional to exp( µ ( θ )). This is the so-called Boltzmann p olicy . W e can sample M parameter candidates θ i according to this distribution. Our final sampler then consists of a mixture of M transition k ernels, where each k ernel is parameterized b y one of the θ i , i = 1 , . . . , M . The distribution of the samples generated in the sampling phase will approac h the target distribution π ( · ) as the num ber of iterations tends to ∞ provided the k ernels in this finite mixture are ergo dic. In high dimensions, one reasonable approach w ould b e to use a multi-start optimizer to find maxima of the unnormalized Boltzmann p olicy and then p erform lo cal exploration of the modes with a simple Metrop olis algorithm. This is a slight more sophisticated version of what is often referred to as the epsilon greedy p olicy . The strategies discussed thus far do not tak e in to accoun t the uncertain ty of the GP . A solution is to dra w M functions according to the GP and then find he optimizer θ i of each of these functions. This is the strategy follo wed in [41] for the case of contextual bandits. Although this strategy works well for lo w dimensions, it is not clear how it can b e easily scaled. 5 Exp erimen ts Our exp erimen ts compare SARDONICS to the p opular Gibbs, block-Gibbs and Sw endsen-W ang samplers. Sev eral types of binary-v alued systems, all b elonging to the general class of undirected graphical mo del called the Ising mo del , are used. The energy of a binary state s , where s i ∈ {− 1 , 1 } is given b y: E ( s ) = − X ( i,j ) J ij s i s j − X i h i s i (One can trivially map x i ∈ { 0 , 1 } to s i ∈ {− 1 , 1 } and vice-versa.) The interaction w eights J ij b et w een v ariables i and j are zero if they are top ologically disconnected; p ositiv e (also called “ferromagnetic”) if they tend to ha ve the same v alue; and negative (“an ti-ferromagnetic”) if they tend to hav e opp osite v alues. The presence of interactions of mixed sign can significantly complicate Monte Carlo simulation due to the proliferation of lo cal minimas in the energy landscap e. Interaction weigh ts of different sign pro duce unsatisfiable constrain ts and cause the system to b ecome “frustrated”. P arameters of SARDONICS ( θ ) k l k u γ L γ H P LL P H L P LH N Range { 1 , . . . , 70 } { 2 , . . . , 120 } [0 . 89 , 1 . 05] [0 . 9 , 1 . 15] [0 , 1] [0 , 1] [0 , 1] { 1 , . . . , 5 } T able 1: The ranges from which Bay esian Optimization c ho oses parameters for SARDONICS. The selec- tion mechanism ensures that k u ≥ k l and γ H ≥ γ L . The first set of exp erimen ts considers the b eha vior of Gibbs, SARDONICS and Swendsen-W ang on a ferromagnetic Ising mo del on a planar, regular grid of size 60 × 60. The model has connections b et ween the no des on one b oundary to the no des on the other boundary for each dimension. As a result of these 10 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 5000 10000 15000 20000 SARDONICS 5500 5000 4500 4000 0 5000 10000 15000 20000 Swendsen-Wang 5500 5000 4500 4000 0 5000 10000 15000 20000 Gibbs 5500 5000 4500 4000 0 50 100 150 200 Number of Adaptations 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Reward Figure 2: The 2D F erromagnetic model with perio dic (toroidal) b oundaries [top left], the auto-correlations of the samplers for T = 2 . 27 (critical temp erature) [top right], traces of ev ery 5 out of the 10 5 samples of the energy [b ottom left] and rewards obtained by the Bay esian optimization algorithm during the adaptation phase [b ottom righ t]. p eriodic boundaries, the mo del is a square toroidal grid. Hence, each no de has exactly four neigh b ors. In the first exp erimen t, the interaction w eights, J ij , are all 1 and the biases, h i , are all 0. W e test the three algorithms on this mo del at three different temp eratures: 1, 2 . 27 and 5. The v alue β = 1 / 2 . 27 corresp onds to the so-called critic al temp er atur e , where many interesting phenomena arise [46] but where sim ulation also becomes quite difficult. The experimental proto col for this and subsequent mo dels was the same: F or 10 indep endent trials, run the comp eting samplers for a certain num b er of iterations, storing the sequence of energies visited. Using e ac h trial’s energy sequence, compute the auto-c orr elation function (A CF). Comparison of the algorithms consisted of analyzing the energy ACF av eraged ov er the trials. Without going into detail, a more rapidly decreasing ACF is indicativ e of a faster-mixing Marko v chain; see for example [50]. F or all the mo dels, eac h sampler is run for 10 5 steps. F or SARDONICS, we use the first 2 × 10 4 iterations to adapt its hyper-parameters. F or fairness of comparison, we discard the first 2 × 10 4 samples from each sampler and compute the ACF on the remaining 8 × 10 4 samples. F or all our exp erimen ts, we use the ranges of parameters summarized in T able I to adapt SARDONICS. As shown in Figure 2, at the critical temp erature, Swendsen-W ang do es considerably b etter than its comp etitors. It is precisely for these types of lattice that Swendsen-W ang was designed to mix efficiently , through effectiv e clustering. This part of the result is therefore not surprising. How ev er, we must consider 11 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 5000 10000 15000 20000 SARDONICS 7500 7000 6500 6000 5500 0 5000 10000 15000 20000 Swendsen-Wang 7500 7000 6500 6000 5500 0 5000 10000 15000 20000 Gibbs 7500 7000 6500 6000 5500 0 5000 10000 15000 20000 SARDONICS 2200 2000 1800 1600 1400 1200 1000 0 5000 10000 15000 20000 Swendsen-Wang 2200 2000 1800 1600 1400 1200 1000 0 5000 10000 15000 20000 Gibbs 2200 2000 1800 1600 1400 1200 1000 Figure 3: Auto-correlations of the samplers, on the F erromagnetic 2D grid Ising mo del, for T = 1 [top left] and T = 5 [top righ t]. T races of every 5 out of the 10 5 samples of the energy at T = 1 [b ottom left] and T = 5 [b ottom righ t]. the p erformance of SARDONICS carefully . Although it do es muc h b etter than Gibbs, as exp ected, it under-p erforms in comparison to Swendsen-W ang. This seems to b e a consequence of the fact that the probabilit y distribution at this temp erature has man y peaks. SARDONICS, despite its large mov es, can get trapp ed in these peaks for man y iterations. At temp erature 5, when the distribution is flattened, the performance of SARDONICS is comparable to that of Swendsen-W ang as depicted in Figure 3. The same figure also sho ws the results for T = 1, where the target distribution is even more p eak ed. The goo d p erformance of SARDONICS for T = 1 migh t seem counterin tuitiv e considering the previous results for T = 2 . 27. An explanation is pro vided subsequently . A t temp eratures 1 and 2 . 27, adaptation is v ery hard. Before the sampler c on v erges, it is b eneficial for it to take large steps to achiev e low er auto-correlation. The adaptation mec hanism learns this and hence automatically chooses large SA W lengths. But after the sampler conv erges, large steps can take the sampler out of the high-probability region thus leading to low acceptance. If the sampler hits the p eak during adaptation then it learns to c ho ose small SA W lengths. This may also b e problematic if w e restart the sampler from a differen t state. This p oin ts out one of the dangers of ha ving finite adaptation sc hemes. A simple solution, in this particular case, is to c hange the bounds on the SA W lengths manually . This enables SARDONICS to ac hieve p erformance comparable to that of Swendsen W ang for these nearly 12 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 5000 10000 15000 20000 SARDONICS 5900 5850 5800 5750 5700 5650 5600 5550 5500 0 5000 10000 15000 20000 Swendsen-Wang 5900 5850 5800 5750 5700 5650 5600 5550 5500 0 5000 10000 15000 20000 Gibbs 5900 5850 5800 5750 5700 5650 5600 5550 5500 0 50 100 150 200 Number of Adaptations 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Reward Figure 4: F rustrated 2D grid Ising mo del with p erio dic b oundaries [top left], auto-correlations of the three samplers [top right], traces of the last 20000 of 100000 samples of the energy [b ottom left] and rew ards obtained b y the Bay esian optimization algorithm during the adaptation phase [b ottom righ t]. deterministic mo dels, as shown in Figure 3 for T = 1. How ever, ideally , infinite adaptation mechanisms migh t provide a more principled and general solution. In addition to studying the effect of temp erature changes on the p erformance of the algorithms, we also inv estigate their sensitivity with resp ect to the addition of unsatisfiable constrain ts. T o accomplish this, we set the in teraction weigh ts J ij and the biases h i uniformly at random on the set {− 1 , 1 } . W e set the temperature to T = 1 . 0. W e refer to this mo del as the frustrated 2D grid Ising mo del. As shown b y the auto-correlations and energy traces plotted in Figure 4, SARDONICS do es considerably b etter than its riv als. It is in teresting to note that Swendsen-W ang do es muc h w orse on this mo del as the unsatisfiable constraints hinder effective clustering. The figure also sho ws the reward obtained by the Ba yesian optimization scheme as a function of the num b er of adaptations. The adaptation algorithm traded-off exploration and exploitation effectively in this case. The third batc h of exp erimen ts compares the algorithms on an Ising mo del where the v ariables are top ologically structured as a 9 × 9 × 9 three-dimensional cub e, J ij are uniformly sampled from the set {− 1 , 1 } , and the h i are zero. β was set to 1 . 0, corresp onding to a lo wer temperature than the v alue of 0 . 9, at which it is known [39] that, roughly sp eaking, regions of the state space b ecome very difficult to visit from one another via traditional Mon te Carlo simulation. Figure 5 sho ws that for this more densely 13 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 5000 10000 15000 20000 SARDONICS 1350 1300 1250 1200 1150 0 5000 10000 15000 20000 Swendsen-Wang 1350 1300 1250 1200 1150 0 5000 10000 15000 20000 Gibbs 1350 1300 1250 1200 1150 0 50 100 150 200 Number of Adaptations 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Reward Figure 5: F rustrated 3D cub e Ising model with p eriodic b oundaries (for visualization simplicity , the b oundary edges are not shown) [top left], auto-correlations of the three samplers [top righ t], traces of the last 20000 of 100000 samples of the energy [b ottom left] and rewards obtained by the Bay esian optimization algorithm during the adaptation phase [bottom righ t]. connected mo del, the performance of Sw endsen-W ang deteriorates substan tially . How ever, SARDONICS still mixes reasonably well. While the three-dimensional-cub e spin-glass is a muc h harder problem than the 2D ferromagnet, it represen ts a worst case scenario. One w ould hop e that problems arising in practice will hav e structure in the p oten tials that w ould ease the problem of inference. F or this reason, the third experimental set consisted of runs on a restricted Boltzmann machine [58] with parameters trained from natural image patc hes via sto c hastic maxim um likelihoo d [61, 40]. RBMs are bipartite undirected probabilistic graphical mo dels. The v ariables on one side are often referred to as “visible units”, while the others are called “hidden units”. Eac h visible unit is connected to all hidden units. How ever there are no connections among the hidden units and among the visible units. Therefore, giv en the visible units, the hidden units are conditionally independent and vice-versa. Our mo del consisted of 784 visible and 500 hidden units. The mo del is illustrated in Figure 6. The pre-learned in teraction parameters capture local regularities of natural images [31]. Some of these parameters are depicted as images in Figure 8. The parameter β was set to one. The total num b er of v ariables and edges in the graph were th us 1284 and 392000 respectively . 14 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs Block Gibbs 0 5000 10000 15000 20000 SARDONICS 5800 5750 5700 5650 5600 5550 5500 0 5000 10000 15000 20000 Block Gibbs 5800 5750 5700 5650 5600 5550 5500 0 5000 10000 15000 20000 Gibbs 5800 5750 5700 5650 5600 5550 5500 0 50 100 150 200 Number of Adaptations 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Reward Figure 6: F rustrated 3D cub e Ising mo del with perio dic b oundaries [top left], auto-correlations of the three samplers [top right], traces of the last 20000 of 100000 samples of the energy [b ottom left] and rew ards obtained b y the Bay esian optimization algorithm during the adaptation phase [b ottom righ t]. Figures 6 and 7 sho w the results. Again SARDONICS mixes significan tly better than Sw endsen-W ang and the naiv e Gibbs sampler. Swendsen-W ang p erforms p o orly on this mo del. As shown in Figure 7, it mixes slowly and fails to con verge after 10 5 iterations. F or this bipartite model, it is p ossible to carry out blo ck-Gibbs sampling (the standard metho d of choice). Encouragingly , SARDONICS compares well against this p opular blo c k strategy . This is imp ortan t, because computational neuro-scien tists would lik e to add lateral connections among the hidden units, in which case blo c k-Gibbs would no longer apply unless the connections form a tree structure. SARDONICS th us promises to empow er computational neuro-scien tists to address more sophisticated mo dels of p erception. The catch is that at presen t SARDONICS takes considerably more time than blo c k-Gibbs sampling for these mo dels. W e discuss this issue in greater length in the following section. Finally , we consider a frustrated 128-bit chimera lattice that arises in the construction of quantum computers [7]. As depicted in Figure 9, SARDONICS once again outp erforms its competitors. 15 0 5000 10000 15000 20000 Iteration 3285 3280 3275 3270 3265 3260 3255 Energy Figure 7: T race of the last 20000 of 100000 samples of the energy for the Swendsen-W ang sampler. As w e can see, the sampler p erforms po orly on the RBM mo del. Figure 8: RBM parameters. Eac h image corresponds to the parameters connecting a sp ecific hidden unit to the entire set of visible units. 5.1 Computational considerations The bulk of the computational time of the SARDONICS algorithm is sp en t in generating states with the SA W prop osal. A t eac h step of the process, a component from a discrete probabilit y v ector, corresponding to the v ariable to flip, m ust b e sampled. Naively , the time needed to do so scales linearly with the length l of the vector. In graphical mo dels of sparse connectivity , how ever, it is p ossible ac hieve a dramatic computational sp eedup by storing the vector in a binary he ap . Sampling from a heap is of O (log l ), but for sp arsely c onne cte d mo dels, up dating the heap in response to a flip, whic h en tails replacing the energy c hanges that would result if the flipped v ariable’s neighb oring v ariables were themselves to flip, is also of logarithmic complexity . In con trast, for a densely connected model, the heap update would b e of O ( M log l ) where M is the maximum degree of the graph, while recomputing the probability vector in the naive metho d is O ( M ). The simple metho d is thus cheaper for dense mo dels. In our experiments, we implemen ted SARDONICS with the binary heap despite the fact that the RBM is a densely connected mo del. F or densely connected mo dels, one could easily parallelize the computation of generating states with the SA W prop osal. Suppose we ha ve n parallel pro cesses. Eac h pro cess P holds one section U p of the 16 0 100 200 300 400 500 Lag 0.0 0.2 0.4 0.6 0.8 1.0 Auto-correlation SARDONICS Swendsen-Wang Gibbs 0 5000 10000 15000 20000 SARDONICS 140 120 100 80 60 0 5000 10000 15000 20000 Swendsen-Wang 140 120 100 80 60 0 5000 10000 15000 20000 Gibbs 140 120 100 80 60 0 50 100 150 200 Number of Adaptations 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Reward Figure 9: Chimera lattice [top left], auto-correlations of the three samplers [top right], traces of the last 20000 of 100000 samples of the energy [b ottom left] and rewards obtained by the Ba yesian optimization algorithm during the adaptation phase [b ottom right]. unnormalized probability v ector U . T o sample from the discrete vector in parallel, eac h parallel pro cess can sample one v ariable v p to flip according to U p . Each process also calculates the sum of its section of the unnormalized probabilit y vector s p . Then the v ariable to flip is sampled from the set { v p : 1 ≤ p ≤ n } prop ortional to the discrete probability vector [ s 1 , s 2 , ..., s n ]. T o update U in response to a flip, we could use the naive metho d men tioned ab ov e. If we divide the U ev enly among pro cesses and assume equal pro cessor sp eed, sampling from and up dating the unnormalized probability vector would tak e O ( M + l n + n ) op erations. When n is small compared to M + l , we could achiev e near linear sp eed up. W e compare, in table I I, the amount of time it tak es to draw 10 5 samples using different samplers. In principle, it is unwise to compare the computational time of samplers when this comparison dep ends on sp ecific implementation details and architecture. The table simply provides rough estimates. The astute reader migh t b e thinking that we could run Gibbs for the same time as SARDONICS and exp ect similar p erformance. This is how ever not what happ ens. W e tested this hypothesis and found Gibbs to still underp erform. Moreov er, in some cases, Gibbs can get trapp ed as a result of being a small mov e sampler. The computational complexity of SARDONICS is affected b y the degree of the graph, whereas the complexit y of Swendsen-W ang increases with the num b er of edges in the graph. So for large sparsely- 17 Samplers Mo dels SARDONICS Sw endsen-W ang Gibbs Blo c k Gibbs F erromagnetic Ising Mo del 20 minutes 50 minutes tens of seconds N/A F rustrated 2D Ising Mo del 20 minutes 50 minutes tens of seconds N/A F rustrated 3D Ising Mo del 10 minutes a few minutes tens of seconds N/A RBM 10 hours a few hours 20 minutes a few minutes Chimera a few minutes tens of seconds tens of seconds N/A T able 2: Rough computation time for each sampler on differen t mo dels. All samplers are run on the same computer with 8 CPUs. The Sw endsen-W ang sampler is co ded in Matlab with the computationally in tensive part written in C. The SARDONICS sampler is co ded in Python also with its computationally in tensive part co ded in C. The Gibbs and block Gibbs samplers are co ded in Python. The Sw endsen-W ang and blo c k Gibbs samplers tak e adv antage of parallelism via parallel numerical linear algebra operations. The SARDONICS sampler and the Gibbs sampler, how ev er, run on a single CPU. The adaptation time of SARDONICS is also included. connected graphs, w e exp ect SARDONICS to ha ve a comp eting edge ov er Swendsen-W ang, as already demonstrated to some extent in the exp erimen ts. 6 Discussion The results indicate that the prop osed sampler mixes v ery w ell in a broad range of mo dels. How ev er, as already p oin ted out, we b eliev e that w e need to consider alternativ es to nonparametric m ethods in Bay esian optimization. P arametric metho ds would enable us to carry out infinite adaptation. This should solv e the problems pointed out in the discussion of the results on the ferromagnetic 2D Ising model. Another imp ortan t a ven ue of future work is to dev elop a multi-core implemen tation of SARDONICS as outlined in the previous section. Ac kno wledgmen ts The authors w ould like to thank Misha Denil and Helmut Katzgrab er. The Swendsen-W ang co de w as mo dified from a slow er v ersion kindly made a v ailable by Iain Murray . This researc h was supp orted by NSER C and a join t MIT ACS/D-W av e Systems grant. References [1] D. H. Ackl ey , G. Hin ton, and T.. Sejnowski. A learning algorithm for Boltzmann mac hines. Co gnitive Scienc e , 9:147–169, 1985. [2] Christophe Andrieu and Christian Rob ert. Controlled MCMC for optimal sampling. T echnical Rep ort 0125, Cahiers de Mathematiques du Ceremade, Universite P aris-Dauphine, 2001. [3] F Barahona. On the computational complexit y of Ising spin glass mo dels. Journal of Physics A: Mathematic al and Gener al , 15(10):3241, 1982. [4] Bernd A. Berg and Thomas Neuhaus. Multicanonical algorithms for first order phase transitions. Physics L etters B , 267(2):249 – 253, 1991. [5] Dimitri P . Bertsek as. Pro jected Newton metho ds for optimization problems with simple constraints. SIAM Journal on Contr ol and Optimization , 20(2):221–246, 1982. 18 [6] Julian Besag. Spatial interaction and the statistical analysis of lattice systems. J. R oy. Statist. So c., Ser. B , 36:192–236, 1974. [7] Zhengbing Bian, F abian Chudak, William G. Macready , and Geordie Rose. The Ising mo del: teaching an old problem new tricks. T echnical rep ort, D-W av e Systems, 2011. [8] David M. Blei, Andrew Y. Ng, and Michael I. Jordan. Laten t Dirichlet allo cation. J. Mach. L e arn. R es. , 3:993–1022, 2003. [9] Eric Bro c hu, Vlad M Cora, and Nando de F reitas. A tutorial on Ba yesian optimization of exp en- siv e cost functions. T echnical Rep ort TR-2009-023, Univ ersity of British Columbia, Department of Computer Science, 2009. [10] Adam D Bull. Con vergence rates of efficient global optimization algorithms. T echnical Rep ort arXiv:1101.3501v2, 2011. [11] P . J. Diggle, J. A. T awn, and R. A. Moy eed. Mo del-based geostatistics. Journal of the R oyal Statistic al So ciety. Series C (Applie d Statistics) , 47(3):299–350, 1998. [12] S Duane, A D Kennedy , B J Pendleton, and D Row eth. Hybrid Monte Carlo. Physics L etters B , 195(2):216–222, 1987. [13] David J. Earl and Mic hael W. Deem. P arallel temp ering: Theory, applications, and new persp ectives. Phys. Chem. Chem. Phys. , 7:3910–3916, 2005. [14] Daniel E Fink el. DIRECT Optimization Algorithm User Guide . Center for Researc h in Scien tific Computation, North Carolina State Universit y , 2003. [15] Nando De F reitas, Y ang W ang, Mary am Mahdaviani, and Dustin Lang. F ast Krylov metho ds for N-b ody learning. In Y. W eiss, B. Sch¨ olk opf, and J. Platt, editors, A dvanc es in Neur al Information Pr o c essing Systems , pages 251–258. MIT Press, 2005. [16] Charles J Geyer. Marko v Chain Monte Carlo maxim um lik eliho od. In Computer Scienc e and Statistics: 23r d Symp osium on the Interfac e , pages 156–163, 1991. [17] Mark Girolami and Ben Calderhead. Riemann manifold Langevin and Hamiltonian Mon te Carlo metho ds. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) , 73(2):123–214, 2011. [18] F. Glov er. T abu searc h – Part I. ORSA Journal on Computing , 1:190–206, 1989. [19] Rob ert B Gramacy , Herb ert K. H. Lee, and William MacReady . Parameter space exploration with gaussian pro cess trees. In Pr o c e e dings of the International Confer enc e on Machine L e arning , pages 353–360. Omnipress and ACM Digital Library , 2004. [20] J. Gub ernatis and N. Hatano. The multicanonical monte carlo metho d. Computing in Scienc e Engine ering , 2(2):95–102, 2000. [21] Heikki Haario, Eero Saksman, and Johanna T amminen. An adaptive Metropolis algorithm. Bernoul li , 7(2):223–242, 2001. [22] N. Halko, P . G. Martinsson, , and J. A. T ropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. Scienc e , 53(2):217–288, 2011. [23] Firas Hamze and Nando de F reitas. F rom fields to trees. In Unc ertainty in Artificial Intel ligenc e , pages 243–250, 2004. [24] Firas Hamze and Nando de F reitas. Hot Coupling: a particle approac h to inference and normalization on pairwise undirected graphs. A dvanc es in Neur al Information Pr o c essing Systems , 18:491–498, 2005. 19 [25] Firas Hamze and Nando de F reitas. Large-flip imp ortance sampling. In Unc ertainty in Artificial Intel ligenc e , pages 167–174, 2007. [26] Firas Hamze and Nando de F reitas. Intracluster mov es for constrained discrete-space MCMC. In Unc ertainty in Artificial Intel ligenc e , pages 236–243, 2010. [27] Geoffrey Hin ton and Ruslan Salakhutdino v. Reducing the dimensionality of data with neural net- w orks. Scienc e , 313(5786):504–507, 2006. [28] Matthew Hoffman, Eric Broch u, and Nando de F reitas. P ortfolio allo cation for Ba yesian optimization. In Unc ertainty in Artificial Intel ligenc e , pages 327–336, 2011. [29] Holger H. Ho os and Thomas Stutzle. Sto chastic L o c al Se ar ch: F oundations and Applic ations . Else- vier, Morgan Kaufmann, 2004. [30] J J Hopfield. Neurons with graded resp onse hav e collectiv e computational prop erties like those of t wo-state neurons. Pr o c e e dings of the National A c ademy of Scienc es , 81(10):3088–3092, 1984. [31] A. Hyv arinen, J. Hurri, and P .O. Hoy er. Natur al Image Statistics . [32] Ross Kindermann and J. Laurie Snell. Markov R andom Fields and their Applic ations . Amer. Math. So c., 1980. [33] Hendrik K ¨ uc k and Nando de F reitas. Learning ab out individuals from group statistics. In Unc ertainty in A rtificial Intel ligenc e , pages 332–339, 2005. [34] Honglak Lee, Roger Grosse, Ra jesh Ranganath, and Andrew Y. Ng. Con volutional deep b elief net- w orks for scalable unsupervised learning of hierarchical representations. In International Confer enc e on Machine L e arning , pages 609–616, 2009. [35] Jun S. Liu. Monte Carlo str ate gies in scientific c omputing . Springer, 2001. [36] Jun S. Liu, Junni L. Zhang, Michael J. P alum b o, and Charles E. Lawrence. Bay esian clustering with v ariable and transformation selections. Bayesian Statistics , 7:249–275, 2003. [37] Daniel Lizotte. Pr actic al Bayesian Optimization . PhD thesis, Universit y of Alb erta, Edmon ton, Alb erta, Canada, 2008. [38] Nimalan Mahendran, Ziyu W ang, Firas Hamze, and Nando de F reitas. Bay esian optimization for adaptiv e MCMC. T echnical Report arXiv:1110.6497v1, 2011. [39] E. Marinari, G. Parisi, and JJ Ruiz-Lorenzo. Numerical simulations of spin glass systems. Spin Glasses and R andom Fields , pages 59–98, 1997. [40] Benjamin Marlin, Kevin Swersky , Bo Chen, and Nando de F reitas. Inductive principles for restricted Boltzmann machine learning. In Artificial Intel ligenc e and Statistics , pages 509–516, 2010. [41] Benedict C May , Nathan Korda, Anthon y Lee, and David S Leslie. Optimistic Ba yesian sampling in contextual bandit problems. 2011. [42] Roland Memisevic and Geoffrey Hinton. Learning to represent spatial transformations with factored higher-order Boltzmann machines. Neur al Computation , 22:1473–1492, 2009. [43] Jonas Mo ˇ ckus. The Ba yesian approac h to global optimization. In System Mo deling and Optimization , v olume 38, pages 473–481. Springer Berlin / Heidelb erg, 1982. [44] J. D. Munoz, M. A. No votn y , and S. J. Mitchell. Rejection-free Monte Carlo algorithms for mo dels with contin uous degrees of freedom. Phys. R ev. E , 67, 2003. [45] Radford M Neal. MCMC using Hamiltonian dynamics. Handb o ok of Markov Chain Monte Carlo , 54:113–162, 2010. 20 [46] M. Newman and G. Bark ema. Monte Carlo Metho ds in Statistic al Physics . Oxford Universit y Press, 1999. [47] M.A. Osb orne, R. Garnett, and S. Rob erts. Active data selection for sensor netw orks with faults and changepoints. In IEEE International Confer enc e on A dvanc e d Information Networking and Applic ations , 2010. [48] Marc’Aurelio Ranzato, V olo dym yr Mnih, and Geoffrey Hin ton. Ho w to generate realistic images using gated MRF’s. In A dvanc es in Neur al Information Pr o c essing Systems , pages 2002–2010, 2010. [49] Carl Edward Rasm ussen and Christopher K I Williams. Gaussian Pr o c esses for Machine L e arning . MIT Press, Cambridge, Massac husetts, 2006. [50] Christian P . Rob ert and George Casella. Monte Carlo Statistic al Metho ds . Springer, 2nd edition, 2004. [51] Gareth O. Rob erts and Jeffrey S. Rosenthal. Examples of adaptive MCMC. Journal of Computational and Gr aphic al Statistics , 18(2):349–367, June 2009. [52] Marshall N. Rosenbluth and Arianna W. Rosenbluth. Monte Carlo calculation of the a verage exten- sion of molecular chains. J. Chem. Phys. , 23:356–359, 1955. [53] Hav ard Rue, Sara Martino, and Nicolas Chopin. Appro ximate Ba yesian inference for laten t Gaussian mo dels b y using integrated nested Laplace approximations. Journal Of The R oyal Statistic al So ciety Series B , 71(2):319–392, 2009. [54] Ruslan Salakhutdino v and Iain Murray . On the quantitativ e analysis of Deep Belief Netw orks. In International Confer enc e on Machine L e arning , pages 872–879, 2008. [55] T J Santner, B Williams, and W Notz. The Design and Analysis of Computer Exp eriments . Springer, 2003. [56] Matthias Sc honlau, William J. W elch, and Donald R. Jones. Global v ersus local searc h in constrained optimization of computer mo dels. L e ctur e Notes-Mono gr aph Series , 34:11–25, 1998. [57] J¨ orn I. Siepmann and Daan F renkel. Configurational bias Monte Carlo: a new sampling scheme for flexible c hains. Mole cular Physics: A n International Journal at the Interfac e Betwe en Chemistry and Physics , 75(1):59–70, 1992. [58] P . Smolensky . Information processing in dynamical systems: F oundations of harmony theory . Par al lel distribute d pr o c essing: Explor ations in the micr ostructur e of c o gnition, vol. 1: foundations , pages 194–281, 1986. [59] Niranjan Sriniv as, Andreas Krause, Sham M Kak ade, and Matthias Seeger. Gaussian pro cess opti- mization in the bandit setting: No regret and exp erimen tal design. In International Confer enc e on Machine L e arning , 2010. [60] Rob ert H. Swendsen and Jian-Sheng W ang. Nonuniv ersal critical dynamics in Monte Carlo sim ula- tions. Phys. R ev. L ett. , 58(2):86–88, 1987. [61] Kevin Swersky , Bo Chen, Ben Marlin, and Nando de F reitas. A tutorial on sto c hastic approximation algorithms for training restricted Boltzmann machines and deep b elief nets. In Information The ory and Applic ations Workshop , pages 1 –10, 2010. [62] S. S. Tham, A. Doucet, and R. Kotagiri. Sparse Ba yesian learning for regression and classification using Marko v chain Mon te Carlo. In International Confer enc e on Machine L e arning , pages 634–641, 2002. [63] Matti Vihola. Grapham: Graphical mo dels with adaptiv e random w alk Metrop olis algorithms. Computational Statistics an d Data Analysis , 54(1):49 – 54, 2010. 21 [64] F ugao W ang and D. P . Landau. Efficient, multiple-range random walk algorithm to calculate the densit y of states. Phys. R ev. L ett. , 86:2050–2053, 2001. [65] Dominic J. A. W elsh. Complexity: knots, c olourings and c ounting . Cam bridge Universit y Press, 1993. [66] Kenny Q. Y e. Orthogonal column Latin hypercub es and their application in computer exp erimen ts. Journal of the Americ an Statistic al Asso ciation , 93(444):1430–1439, 1998. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment