On a Class of Shrinkage Priors for Covariance Matrix Estimation
We propose a flexible class of models based on scale mixture of uniform distributions to construct shrinkage priors for covariance matrix estimation. This new class of priors enjoys a number of advantages over the traditional scale mixture of normal …
Authors: Hao Wang, Natesh S. Pillai
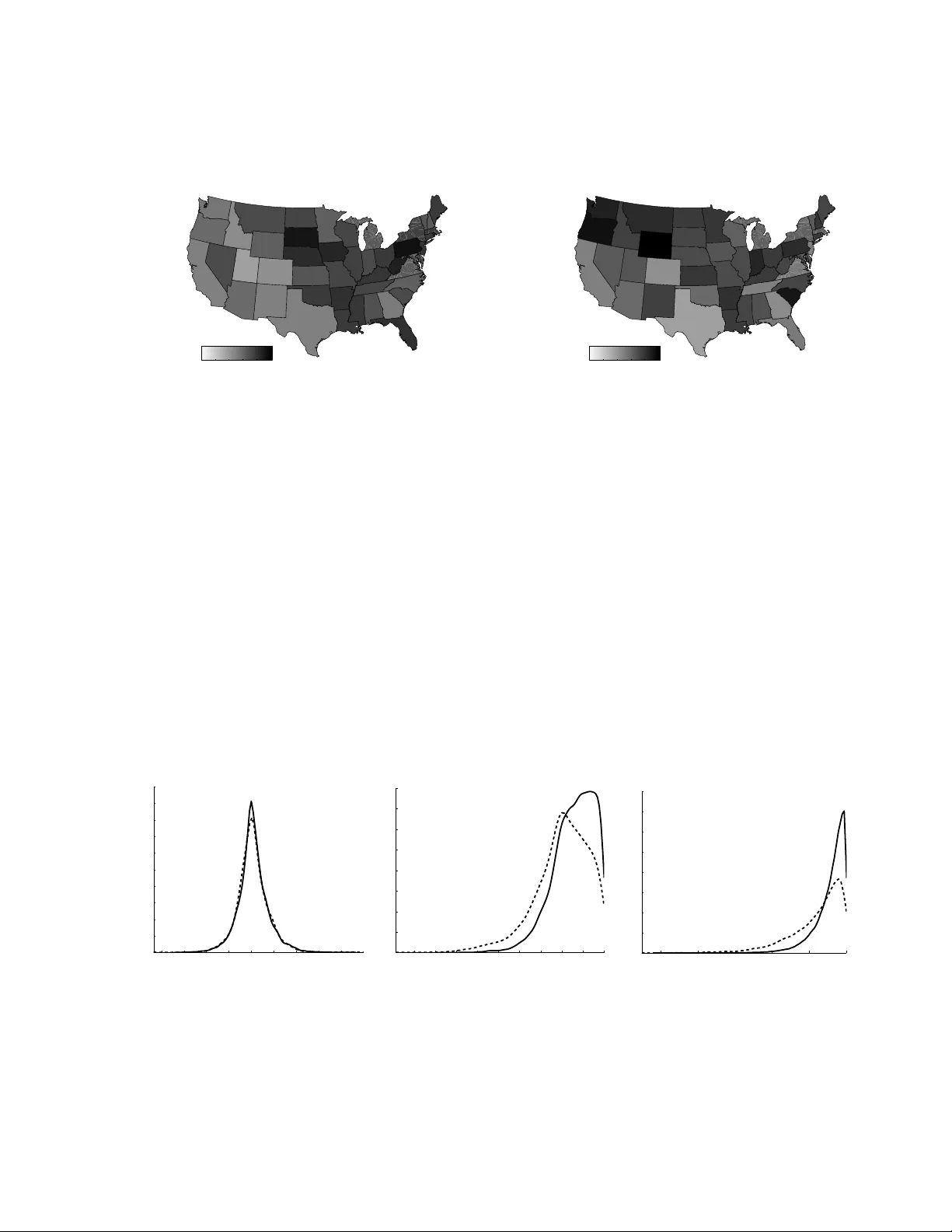
On a Class of Shrink age Priors for Co v ariance Matrix Estimation Hao W ang Dep artment of Statistics, University of South Car olina, Columbia, SC 29208, U.S.A. hao wang@sc.edu Natesh S. Pillai Dep artment of Statistics, Harvar d University, Cambridge, MA 02138, U.S.A. pillai@fas.harv ard.edu This v ersion: Octob er 1, 2018 Abstract W e prop ose a flexible class of mo dels based on scale mixture of uniform distri- butions to construct shrink age priors for cov ariance matrix estimation. This new class of priors enjo ys a n umber of adv antages o ver the traditional scale mixture of normal priors, including its simplicity and flexibilit y in characterizing the prior densit y . W e also exhibit a simple, easy to implemen t Gibbs sampler for p osterior sim ulation whic h leads to efficien t estimation in high dimensional p roblems. W e first discuss the theory and computational details of this new approac h and then extend the basic mo del to a new class of multiv ariate conditional autoregressiv e mo dels for analyzing m ultiv ariate areal data. The prop osed spatial model flexi- bly c haracterizes both the spatial and the outcome correlation structures at an app ealing computational cost. Examples consisting of b oth synthetic and real- w orld data sho w the utilit y of this new framework in terms of robust estimation as w ell as improv ed predictive p erformance. Key wor ds: Areal data; Co v ariance matrix; Data augmen tation Gibbs sampler; Multiv ari- ate conditional autoregressiv e mo del; Scale mixture of uniform; Shrink age; Sparsit y . 1 Intr oduction Estimation of the co v ariance matrix Σ of a m ultiv ariate random v ector y is ubiquitous in mo dern statistics and is particularly c hallenging when the dimension of the cov ariance matrix, p , is comparable or even larger than the sample size n . F or efficient inference, it is thus paramoun t to take adv antage of parsimonious structure often inherent in these high dimensional problems. Man y Bay esian approaches ha v e b een prop osed for co v ariance matrix estimation b y placing shrink age priors on v arious parameterizations of the co v ariance matrix Σ. Y ang & Berger ( 1994 ) proposed reference priors for Σ based on the sp ectral decomp osition of Σ. Barnard et al. ( 2000 ) and Liech t y et al. ( 2004 ) 1 considered shrink age priors in terms of the correlation matrix and standard deviations. Daniels & Kass ( 1999 , 2001 ) prop osed flexible hierarchical priors based on a n umber of parameterizations of Σ. All of these metho ds use non-conjugate priors and t ypically rely on Mark o v c hain algorithms whic h explore the state space lo cally suc h as Metrop olis- Hastings metho ds or asymptotic approximations for p osterior simulation and mo deling fitting and are restricted to lo w-dimensional problems. A large class of sparsity mo deling of the co v ariance matrix in volv es the iden tification of zeros of the inv erse Ω = Σ − 1 . This corresp onds to the Gaussian graphical mo dels in whic h zeros in the inv erse cov ariance matrix uniquely determine an undirected graph that represents the strict conditional indep endencies. The Gaussian graphical mo del approac h for co v ariance matrix estimation is attractive and has gained substan tiv e atten tion owing to the fact that its implied conditional dependence structure pro vides a natural platform for modeling dependence of random quan tities in areas suc h as biology , finance, environmen tal health and so cial sciences. The standard Bay esian approac h to inference in Gaussian graphical mo dels is the conjugate G -Wishart prior ( Ro v erato , 2002 ; Ata y-Ka yis & Massam , 2005 ), whic h places p ositive probabilit y mass at zero on zero elements of Ω. A zero constrained random matrix Ω has the G -Wishart distribution W G ( b, D ) if its densit y is p (Ω | G ) = C G ( b, D ) − 1 | Ω | ( b − 2) / 2 exp {− 1 2 tr( D Ω) } 1 { Ω ∈ M + ( G ) } , (1) where b > 2 is the degree of freedom parameter, D is a symmetric p ositive definite matrix, C G ( b, D ) is the normalizing constant, M + ( G ) is the cone of symmetric p ositive definite matrices with entries corresp onding to the missing edges of G constrained to b e equal to zero, and 1 {·} is the indicator function. Although G -Wishart prior has b een quite successfully used in man y applications, it has a few imp ortan t limitations. First, the G -Wishart prior is sometimes not v ery flexible because of its restrictive form. F or example, the parameters for the degrees of freedom are the same for all the elements of Ω. Second, unrestricted graphical mo del determination and cov ariance matrix estimation is computationally c hallenging. Recent adv ances for unrestricted graphical models ( Jones et al. , 2005 ; W ang & Carv alho , 2010 ; Mitsak akis et al. , 2010 ; Dobra et al. , 2011 ) all rely on the theoretical framew ork of A ta y-Kayis & Massam ( 2005 ) for sparse matrix completion which is very computationally in tensive. Indeed, for non-decomposable graphical models, we do not hav e a closed form expression for the normalizing constan t C G ( b, D ) and thus hav e to resort to tedious and often unstable Mon te Carlo in tegration to estimate it for b oth graphical mo del determination and co v ariance matrix estimation. An alternative metho d for Ba yesian graphical mo del determination and estimation is prop osed b y W ong et al. ( 2003 ). They placed point mass priors at zero on zero elemen ts of the partial correlation matrix and constan t priors for the non-zero elemen ts. Their metho dology applies to b oth decomp osable and non-decomp osable mo dels and is fitted b y a reversible jump Metrop olis-Hastings algorithm. How ev er, it is unclear ho w to incorp orate prior information ab out individual en tries of Σ in their framework as the 2 mathematical con venience of constan t priors is essential for their algorithm. Absolutely contin uous priors, or equiv alen tly , p enalt y functions, can also induce shrink age to zero of subsets of elements of Ω and represent an imp ortan t and flexible alternativ e to the p oint mass priors. In the classical formulation, there is a ric h liter- ature on metho ds for dev eloping shrink age estimators via differen t p enalt y functions including the graphical lasso mo dels ( Y uan & Lin , 2007 ; F riedman et al. , 2008 ; Roth- man et al. , 2008 ) and the graphical adaptiv e lasso mo dels ( F an et al. , 2009 ) among man y others. The recen t literature on Ba y esian methods has focused on the p osterior mo de estimation, with little atten tion on the k ey problem of efficien t inference on co- v ariance matrix based on full p osterior computation, with the only exception of W ang ( 2011 ) which gav e a fully Bay esian treatment of the graphical lasso mo dels. One likely reason is the difficulty in efficiently generating p osterior samples of cov ariance matrices under shrink age priors. A fully Bay esian inference is quite desirable b ecause it not only pro duces v alid standard errors and Bay es estimators based on decision-theoretic framew ork but, p erhaps more imp ortan tly , can b e applied in m ultiple classes of mul- tiv ariate mo dels that in v olve k ey components of unkno wn cov ariance matrices suc h as the m ultiv ariate conditional autoregressive mo dels developed in Section 5 . This paper prop oses a class of priors and the implied Ba yesian hierarc hical mo deling and computation for shrink age estimation of co v ariance matrices. A k ey but w ell kno wn observ ation is that any symmetric, unimo dal density ma y b e written as a scale mixture of uniform distributions. Our main strategy is to use this mixture represen tations to construct shrink age priors compared to the traditional methods for constructing shrink age priors using the scale mixture of normal distributions. As men tioned abov e, the scale mixture of uniform distribution is not new to Ba yesian inference. Early usage of this represen tation includes Bay esian robust and sensitiv e analysis ( Berger , 1985 ; Berger & Berliner , 1986 ) and robust regressions with heavy-tailed errors W alker et al. ( 1997 ). Ho wev er, our motiv ations are differen t; w e seek an approac h for constructing tractable shrink age priors that are b oth flexible and computationally efficient. W e argue that the class of scale mixture of uniform priors provide an app ealing framework for mo deling a wide class of shrink age estimation problems and also has the p oten tial to b e extended to a large class of high dimensional problems in v olving multiv ariate dep endencies. W e also highligh t that a salien t feature of our approac h is its computational simplicit y . W e construct a simple, easy to implement Gibbs sampler based on data augmen tation for obtaining p osterior draws for a large class of shrink age priors. T o the b est of our kno wledge, none of the existing Ba yesian algorithms for sparse p ermutation in v arian t co v ariance estimation can b e carried out solely based on a Gibbs sampler and they ha ve to rely on Metrop olis-Hastings metho ds. Since Gibbs samplers inv olv e global pro- p osal mo v es as compared to the lo cal proposals of Metropolis-Hastings metho ds, in high dimensions this makes a difference in b oth the efficiency of the sampler and the running time of the algorithm. Through sim ulation exp eriments, w e illustrate the ro- bust p erformance of the scale mixture of uniform priors for co v ariance matrix, as well as highlighting the strength and weakness of this approac h compared to those based on 3 p oin t mass priors. Through an extension to a class of multiv ariate conditional autore- gressiv e mo dels, w e further illustrate that the framew ork of scale mixture of uniforms naturally allows and encourages the in tegration of data and exp ert kno wledge in mo del fitting and assessmen t, and consequently improv es the prediction. The rest of the pap er is organized as follo ws. In Section 2 we outline our framework for constructing shrink age priors for cov ariance matrices using the scale mixture of uni- forms. In Section 3 we construct a Gibbs sampler based on a data augmen tation scheme for sampling from the p osterior distribution. In Section 4 w e conduct a simulation study and compare and con trast our models with existing metho ds. In Section 5 w e extend our mo del to build shrink age priors on multiv ariate conditional autoregressive mo dels. In Section 6 w e briefly discuss the application of our metho ds for shrink age estimation for regression mo dels. 2 Shrinka ge priors for precision ma trices 2.1 Precision matrix mo deling Let y = ( y (1) , y (2) , . . . , y ( p ) ) T b e a p -dimensional random v ector ha ving a m ultiv ari- ate normal distribution N (0 , Σ) with mean zero and cov ariance matrix Σ. Let Ω = ( ω ij ) p × p = Σ − 1 denote the precision matrix, i.e., the inv erse of the cov ariance matrix Σ. Giv en a set of indep enden t random samples Y = ( y 1 , . . . , y n ) p × n of y , w e wish to estimate the matrix Ω. W e consider the following prior distribution for the precision matrix: p (Ω | τ ) ∝ Y i ≤ j g ij ( ω ij − m ij τ ij ) 1 Ω ∈ M + , (2) where g ij ( · ) is a contin uous, unimo dal and symmetric probability density function with mo de zero on R , M + is the space of real v alued symmetric, p ositive definite p × p matrices, τ ij > 0 is a scale parameter controlling the strength of the shrink age and 1 A denotes the indicator function of the set A . Our primary motiv ation for constructing prior distributions of the form ( 2 ) is that, often in real applications the amount of prior information the mo deler can v ary across individual elemen ts of Ω. F or instance, one migh t incorp orate the information that the v ariance of certain entries of Ω are close to 0, or constrain some entries to be exactly 0. In this setting, shrinking different elemen ts of Ω at a different rate clearly provides a flexible framework for conducting Bay esian inference. In addition to obtaining a flexible class of prior distributions, by using a mixture representation for the density g ij , we can construct a simple, efficient and easy to implement Gibbs sampler to draw from the p osterior distribution of the precision matrix. 4 2.2 Scale mixture of uniform distributions Our main to ol is the follo wing theorem which says that all unimo dal, symmetric den- sities ma y b e expressed as scale mixture of uniform distributions. Theorem 1. Walker et al. ( 1997 ); F el ler ( 1971 ) Supp ose that θ is a r e al-value d r andom quantity with a c ontinuous, unimo dal and symmetric distribution with mo de zer o having density π ( θ ) ( −∞ < θ < ∞ ) . Supp ose π 0 ( θ ) exists for al l θ . Then π ( θ ) has the form: π ( θ ) = Z ∞ 0 1 2 t 1 {| θ | 0 con trols the deca y at the tails. The mixing densit y function h ( t ) giv en in ( 3 ) can b e though t of as the “scale” parameter. In this case we hav e h ( t ) ∝ t q exp( − t q /τ q ) , whic h corresp onds to the generalized gamma distribution. Tw o imp ortant sp ecial cases are the Gaussian distribution ( q = 2), and the double-exp onential distribution ( q = 1), which hav e b een studied extensively in the context of the Ba yesian lasso regression ( P ark & Casella , 2008 ; Hans , 2009 ) and the Ba y esian graphical lasso ( W ang , 2011 ). F or general q > 0, one ma y write the exp onential p ow er distribution as a scale mixture of Gaussian distributions ( Andrews & Mallo ws , 1974 ; W est , 1987 ). Ho w ever, a fully Ba yesian, computationally efficien t analysis is not av ailable based on Gaussian mixtures, esp ecially in the context of cov ariance estimation and graphical mo dels. A few approximate metho ds exist for doing inference using the exp onential pow er prior distribution suc h as the v ariational metho d prop osed by Armagan ( 2009 ). Our use of uniform mixture representation has the adv an tage of p osterior sim ulation via an efficient Gibbs sampler for any q > 0 as is sho wn in Section 2.3 and further exemplified in Sections 4 and 6 . Another natural candidate for shrink age priors is the Student- t distribution giv en b y π ( θ ) ∝ (1 + θ 2 /τ 2 ) − ( ν +1) / 2 , for which it is easy to sho w that h ( t ) ∝ t 2 (1 + t 2 /τ 2 ) − ( ν +3) / 2 . Hence, t 2 /τ 2 is an in verted b eta distribution IB (3 / 2 , ν / 2). Recall that the in verted b eta distribution IB ( a, b ) has the densit y given by p ( x ) ∝ x a − 1 (1 + x ) − a − b 1 x> 0 . The generalized double P areto distribution is giv en b y π ( θ ) ∝ (1 + | θ | /τ ) − (1+ α ) , whic h corresp onds to h ( t ) ∝ t (1 + t/τ ) − (2+ α ) ; i.e., the scale t/τ follows an inv erted b eta 5 distribution IB (2 , α ). Armagan et al. ( 2011 ) inv estigated the prop erties of this class of shrink age priors. The ab ov e discussed class of shrink age priors are w ell known and documented. In the follo wing w e give a new distribution whic h we call the “logarithmic” shrink age prior whic h seems to b e new in the context of shrink age priors. Consider the densit y given b y π ( θ ) ∝ log (1 + τ 2 /θ 2 ) . (4) It is easy to sho w that the corresp onding mixing distribution has the half-Cauc h y densit y , h ( t ) ∝ (1 + t 2 /τ 2 ) − 1 1 { t> 0 } . This prior has t wo desirable prop erties for shrink age estimation: an infinite spik e at zero and hea vy tails. These are precisely the desirable characteristics of a shrink age prior distribution as argued convincingly for the “horsesho e” prior in Carv alho et al. ( 2010 ). The horsesho e prior is constructed b y scale mixture of normals, namely , θ ∼ N (0 , σ 2 ) , σ ∼ C + (0 , 1) , where C + (0 , 1) is a standard half-Cauch y distribution on the p ositiv e reals with scale 1. The horsesho e prior do es not hav e a closed form density but satisfies the follo wing: K 2 log(1 + 4 /θ 2 ) < π ( θ ) < K log (1 + 2 /θ 2 ) , for a constant K > 0. Clearly , our new prior ( 4 ) has iden tical behavior at the original and the tails as that of the horsesho e prior distribution with the added adv an tage of ha ving an explicit density function unlike the horsesho e prior. 2.3 P osterior sampling Let y denote the observ ed data. The scale mixture of uniform represen tation pro vides a simple wa y of sampling from the p osterior distribution p ( θ | y ) ∝ f ( y | θ ) π ( θ ), where f ( y | θ ) is the lik eliho o d function and π ( θ ) is the shrink age prior densit y . The repre- sen tation ( 3 ) leads to the follo wing full conditional distributions of θ and t (conditional on y ) given by p ( θ | y , t ) ∝ f ( y | θ ) 1 | θ | | θ | , and the c orr esp onding (c onditional) cumulative distribution function is u = F ( t | y , θ ) = pr ( T < t | y , θ ) = π ( | θ | ) − π ( t ) π ( | θ | ) | θ | < t . (6) The adv an tage of the ab o ve theorem is that it giv es an explicit expression of the conditional cumulativ e distribution function in terms of the prior density π ( · ). This pro vides a simple wa y to sample from p ( t | y , θ ) using the inv erse cum ulative distribution function metho d whenever π ( · ) can b e easily inv erted. T able 1 summarizes the densit y functions of π ( θ ) and h ( t ), and the inv erse conditional cumulativ e distribution function F − 1 ( u | y , θ ) for sev eral shrink age priors introduced in Section 2.2 . W e note that the scale mixture of uniform distributions are already used for doing inference for regression mo dels using the Gibbs sampler outlined ab ov e, for instance see Qin et al. ( 1998 ). 3 Posterior comput a tion for precision ma trices 3.1 Gibbs sampling on giv en global shrink age parameter τ Recall that giv en a set of indep endent random samples Y = ( y 1 , . . . , y n ) p × n from a m ultiv ariate normal distribution N (0 , Ω − 1 ), we wish to estimate the matrix Ω using the prior distribution giv en by ( 2 ). Let T = { t ij } i ≥ j b e the v ector of latent scale parameters. F or simplicit y we first consider a simple case where g ij ( · ) = g ( · ) , m ij = 0 and τ ij = τ in this section, and then discuss the strategies for choosing τ in Section 3.2 . How ev er our algorithms can b e easily extended to the general case of unequal shrink age parameters τ ij . Theorem 1 suggests that the prior ( 2 ) can be represented as follows: p (Ω | τ ) = Z T p (Ω , T | τ )d T ∝ Z T Y i ≥ j 1 2 t ij 1 {| ω ij | <τ t ij } h ( t ij ) d T , 7 where p (Ω , T | τ ) ∝ Q i ≥ j 1 / (2 t ij ) 1 {| ω ij | <τ t ij } h ( t ij ) is the joint prior and h ( t ij ) ∝ − t ij g 0 ( t ij ). The joint p osterior distribution of (Ω , T ) is then: p (Ω , T | Y , τ ) ∝ | Ω | n/ 2 exp {− 1 2 tr( S Ω) } Y i ≥ j − 1 {| ω ij | <τ t ij } g 0 ( t ij ) , (7) where S = Y Y T . The most direct approach for sampling from ( 7 ) is to up date each ω ij one at a time giv en the data, T , and all of the entr ies in Ω except for ω ij in a wa y similar to those prop osed in W ong et al. ( 2003 ). Ho w ever, this direct approac h requires a separate Cholesky factorization for up dating each ω ij to find its allow able range and conditional distribution. It also relies on the Metrop olis-Hastings step to correct the sample. W e describ e an efficient Gibbs sampler for sampling (Ω , T ) from ( 7 ) that in volv es one step for sampling Ω and the other step for sampling T . Giv en T , the first step of our Gibbs sampler systematically scans the set of 2 × 2 sub-matrices { Ω e,e : e = ( i, j ) , 1 ≤ j < i ≤ p } to generate Ω. F or an y e = ( i, j ), let V = { 1 , . . . , p } b e the set of vertices and note that | Ω | = | A || Ω V \ e,V \ e | , where A , the Sch ur comp onen t of Ω V \ e,V \ e , is defined by A = Ω e,e − B with B = Ω e,V \ e (Ω V \ e,V \ e ) − 1 Ω V \ e,e . The full conditional density of Ω e,e from ( 7 ) is giv en by p (Ω e,e | − ) ∝ | A | n/ 2 exp {− 1 2 S e,e A } 1 { Ω e,e ∈T } , where T = {| ω ij | < τ t ij } ∩ {| ω ii | < τ t ii } ∩ {| ω j j | < τ t j j } . Th us, A is a truncated Wishart v ariate. T o sample A , we write A = 1 0 l 21 1 d 1 0 0 d 2 1 l 21 0 1 , S e,e = s 11 s 12 s 21 s 22 , with d 1 > 0 and d 2 > 0. The joint distribution of ( l 12 , d 1 , d 2 ) is then giv en by: p ( d 1 , d 2 , l 21 | − ) ∝ d n/ 2+1 1 d n/ 2 2 exp[ − 1 2 tr { s 11 d 1 + s 22 ( l 2 21 d 1 + d 2 ) + 2 s 21 d 1 l 21 } ] 1 Ω e,e ∈T , whic h implies that the univ ariate conditional distribution for the parameters d 1 and d 2 is a truncated gamma distribution, and a truncated normal distribution for l 21 . Details of the parameters of the truncated region and strategies for sampling are given in the App endix. Giv en Ω, the second step of our Gibbs sampler generates T in blo c k using the in verse cum ulative distribution function metho ds describ ed in equation ( 6 ). These t wo steps complete a Gibbs sampler for model fitting under a broad class of shrink age priors for Ω. One attractiv e feature of the ab o ve sampler is that it is also suitable for sampling Ω ∈ M + ( G ), that is, Ω is constrained b y an undirected graph G = ( V , E ) where V is 8 the set of vertices and E is a set of edges and ω ij = 0 if and only if ( i, j ) / ∈ E . The abilit y to sample Ω ∈ M + ( G ) is useful when substan tive prior information indicates a certain subset of elements in Ω are indeed zero. Section 5 provides such an example that in volv es a class of multiv ariate spatial mo dels. T o sample Ω ∈ M + ( G ), the only mo dification that is required is to replace the set of all 2 × 2 sub-matrices { Ω e,e : e = ( i, j ) , 1 ≤ j < i ≤ p } with the set { Ω e,e : e ∈ E } ∪ { Ω v : v ∈ V I } where V I is the set of isolated no des in G . 3.2 Cho osing the shrink age parameters W e start with the scenario when τ ij = τ and m ij = 0 for all i ≥ j . In this case we hav e p (Ω | τ ) = C − 1 τ Y i ≥ j g ( ω ij τ ) , where C τ is a normalizing term inv olving τ . This normalizing constant is a necessary quan tity for choosing h yp er parameters for τ . Since p (Ω | τ ) is a scale family , applying the substitution ˜ Ω = Ω /τ yields, C τ = Z Ω ∈ M + Y i ≥ j g ( ω ij τ )dΩ = τ p ( p +1) 2 Z ˜ Ω ∈ M + g ( ˜ ω ij )d ˜ Ω , (8) where the integral on the righ t hand side of the ab o ve equation do es not inv olv e τ b ecause { ˜ Ω : ˜ Ω ∈ M + } = { Ω : Ω ∈ M + } . Hence, under a hyperprior p ( τ ), the conditional p osterior distribution of τ is p ( τ | Y , Ω) ∝ τ − p ( p +1) / 2 Y i ≥ j g ( ω ij τ ) p ( τ ) . (9) No w the sampling scheme in Section 3.1 can b e extended to include a comp onent to sample τ at each iteration. No w s upp ose m ij = 0 and instead of having a single global shrink age parameter, we wish to con trol the rate at whic h the individuals elemen ts of Ω are shrunk tow ards 0 separately . A natural shrink age prior for this problem is p (Ω | τ ) = C − 1 τ Y i ≥ j g ij ( ω ij τ ) where g ij ma y all b e differen t. The idea is that by choosing a differen t density g ij for each edge, w e can incorp orate the prior information for the rate at which different en tries of Ω are shrunk tow ards 0. F or a hyper prior p ( τ ), using an identical calculation as in ( 8 ) and ( 9 ) w e deduce that the conditional p osterior of τ is then given b y p ( τ | Y , Ω) ∝ τ − p ( p +1) / 2 Y i ≥ j g ij ( ω ij τ ) p ( τ ) . (10) 9 Notice that the Gibbs sampler presented in Section 3.1 applies to this case as w ell; w e just need to use the cum ulative distribution function for the density g ij for sampling from the conditional distribution of t ij . Alternativ ely , one can also fix a density g and write p (Ω | τ ) = C − 1 τ Q i ≥ j g ( ω ij v ij τ ) for fixed p ositive constants v ij and then mak e inference ab out the common τ . W e conclude this section with the remark that our approach can b e adapted for hierarc hical mo dels. F or example, in Section 5 we consider a shrink age prior that shrinks Ω tow ards a given matrix M = ( m ij ) under the constrain t that Ω ∈ M + ( G ) for a giv en graph G : p (Ω) = C − 1 τ ,M Y ( i,j ) ∈ E g ( ω ij − m ij τ )1 Ω ∈ M + ( G ) , where E denotes the set of edges of the graph G and normalizing constan t C τ ,M = R Ω ∈ M + ( G ) Q ( i,j ) ∈ E g ( ω ij − m ij τ )dΩ is the normalizing constant. In this case C τ ,M is analyt- ically intractable as a function of τ . In the example of Section 5 , we fixed τ at a v alue that represents prior knowledge of the distribution of Ω to a v oid modeling τ . In some applications, it ma y b e desirable to add another lev el of hierarch y for mo deling τ so that w e can estimate it from data. Sev eral approaches hav e b een prop osed for dealing with the intractable normalizing constan t, see Liech t y et al. ( 2004 ), Liec h t y et al. ( 2009 ) and the references therein for one suc h approach. 4 Simula tion experiments T o assess the utilit y of the scale mixture of uniform priors, w e compared a range of priors in this family against three alternativ es: the frequentist graphical lasso metho d of F riedman et al. ( 2008 ), the Bay esian G -Wishart prior and the metho d of W ong et al. ( 2003 ). The latter t wo place p ositive prior mass on zeros. W e considered four cov ariance matrices from Rothman et al. ( 2008 ): Mo del 1. An AR (1) mo del with σ ij = 0 · 7 | i − j | . Mo del 2. A n AR (4) mo del with ω ii = 1, ω i,i − 1 = ω i − 1 ,i = 0 · 2, ω i,i − 2 = ω i − 2 ,i = ω i,i − 3 = ω i − 3 ,i = 0 · 2, ω i,i − 4 = ω i − 4 ,i = 0 · 1. Mo del 3. A sp arse mo del with Ω = B + δ I p wher e e ach off-diagonal entry in B is gen- er ate d indep endently and assigne d the value 0 · 5 with pr ob ability α = 0 · 1 and 0 otherwise. The diagonal elements B ii ar e set to b e 0, and δ is chosen so that the c ondition numb er of Ω is p . Her e the c ondition numb er is define d as max( λ ) / min( λ ) wher e max( λ ) , min( λ ) r esp e ctively denote the maximum and minimum eigenvalues of the matrix Ω . Mo del 4. A dense mo del with the same Ω as in mo del 3 exc ept for α = 0 · 5. F or each of the ab o ve four mo dels, we generated samples of size n = 30 , 100 and di- mension p = 30, yielding the prop ortion of non-zero elements to b e 6% , 25% , 10% , 50%, resp ectiv ely . W e compute the risk under tw o standard loss functions, Stein’s loss 10 function, L 1 ( ˆ Σ , Σ) = tr( ˆ ΣΣ − 1 ) − log( ˆ ΣΣ − 1 ) − p , and the squared-error loss function L 2 ( ˆ Σ , Σ) = tr( ˆ Σ − Σ) 2 . The corresp onding Ba yes estimators are ˆ Σ L 1 = { E(Ω | Y) } − 1 and ˆ Σ L 2 = E(Σ | Y), resp ectiv ely . W e used the p osterior sample mean using the Gibbs sampler for estimating the risk for the Bay esian metho ds and the maximum likelihoo d estimate for the graphical lasso metho d. When fitting graphical lasso mo dels, we used the 10-fold cross-v alidation to c ho ose the shrink age parameter. When fitting the G -Wishart priors, w e follow ed the con- v entional prior sp ecification Ω ∼ W G (3 , I p ) and used the rev ersible jump algorithm of Dobra et al. ( 2011 ) for mo del fitting. F or b oth the G -Wishart priors and the metho ds of W ong et al. ( 2003 ), we used the default graphical mo del space prior ( Carv alho & Scott , 2009 ) p ( G ) = { (1 + m ) m | G | } − 1 , where m = p ( p − 1) / 2 and | G | is the total num b er of edges in graph G . F or the scale mixtures of uniforms, w e considered the exp onential p ow er prior p (Ω | τ ) ∝ exp {− P i ≤ j | ω ij | q /τ q } with q ∈ { 0 · 2, 1 } , the generalized double-Pareto prior p (Ω | τ ) ∝ Q i ≤ j (1 + | ω ij | /τ ) − 1 − α and the new logarithmic prior p (Ω | τ ) ∝ Q i ≤ j log(1 + τ 2 /ω 2 ij ). F or the choice of the global shrink age parameters, we assumed the conjugate distribution τ − q ∼ Ga (1, 0 · 1) for the exp onen tial p o wer prior; α = 1 , 1 / (1 + τ ) ∼ U (0 , 1) for the generalized double P areto prior as suggested b y Armagan et al. ( 2011 ); and τ ∼ C + (0 , 1) for the logarithmic prior as was done for the horsesho e prior in Carv alho et al. ( 2010 ). Tw ent y datasets were generated for each case. The Bay esian pro cedures used 15000 iterations with the first 5000 as burn-ins. In all cases, the conv ergence w as rapid and the mixing w as goo d; the auto correlation of eac h elemen ts in Ω died out t ypically after 10 lags. As for the computational cost, the scale mixture of uniforms and the metho d of W ong et al. ( 2003 ) were significan tly faster than the G -Wishart metho d. F or example, for mo del 4, the G -Wishart to ok ab out 11 hours for one dataset under Matlab implemen tation on a six core 3 · 3 Ghz computer running Cen tOS 5 · 0 unix ; while the scale mixture of uniforms and the metho d of W ong et al. ( 2003 ) to ok only ab out 20 and 6 minutes resp ectively . The graphical lasso metho d is just used as a b enc hmark for calibrating the Ba yesian procedures. F or each dataset, all Ba yesian metho ds w ere compared to the graphical lasso method b y computing the relative loss; for example, for the L 1 loss, we computed the relative loss as L 1 ( ˆ Σ , Σ) − L 1 ( ˆ Σ glasso , Σ) , where ˆ Σ is any Ba yes estimator of Σ and Σ glasso is the graphical lasso estimator. Th us, a negative v alue indicates that the metho d p erforms b etter relative to the graphical lasso pro cedure and a smaller relativ e loss indicates a b etter relative p erformance of the metho d. T able 2 rep orts the sim ulation results. The tw o approach es based on p oint mass priors outp erform the con tin uous shrink age metho ds in sparser mo dels such as mo del 1, ho wev er, they are outp erformed in less sparse configurations suc h as mo del 2 and 4. One p ossible explanation is that the p oin t mass priors tend to fa v or sparse models b ecause it encourages sparsit y through a p ositive prior mass at zero. Finally , the exp onen tial p ow er with q =0 · 2, the generalized double P areto and the logarithmic 11 T able 2: Summary of the relativ e L 1 and L 2 losses for differen t mo dels and differen t metho ds. Medians are rep orted while standard errors are in parentheses. Model 1 Model 2 Model 3 Model 4 L 1 L 2 L 1 L 2 L 1 L 2 L 1 L 2 n=30 W G -4 · 4 (1 · 3) -5 · 9 (1 · 4) -0 · 3 (0 · 7) -12 · 7 (4 · 6) -0 · 9 (0 · 7) 1 · 4 (2 · 5) -2 · 3 (1 · 9) -0 · 0 (0 · 9) WCK -4 · 4 (1 · 0) -5 · 1 (2 · 3) -0 · 7 (0 · 6) -11 · 3 (3 · 8) -1 · 2 (0 · 6) 1 · 6 (1 · 5) -2 · 2 (1 · 0) 0 · 3 (0 · 5) EP q =1 -2 · 1 (1 · 1) 2 · 1 (1 · 0) -1 · 0 (0 · 8) -14 · 0 (4 · 7) -1 · 6 (0 · 7) -1 · 0 (2 · 2) -4 · 2 (1 · 2) -1 · 1 (0 · 5) EP q =0 · 2 -3 · 8 (1 · 1) -2 · 9 (2 · 1) -0 · 9 (0 · 8) -13 · 7 (4 · 9) -1 · 4 (0 · 7) -0 · 5 (2 · 5) -3 · 1 (1 · 1) -0 · 5 (1 · 3) GDP -3 · 8 (1 · 1) -3 · 2 (2 · 2) -1 · 3 (0 · 7) -13 · 2 (4 · 3) -1 · 4 (0 · 7) -0 · 4 (2 · 3) -2 · 5 (1 · 7) -0 · 4 (0 · 9) Log -3 · 7 (1 · 1) -2 · 3 (1 · 4) -0 · 6 (0 · 8) -13 · 3 (4 · 9) -1 · 3 (0 · 6) -0 · 2 (2 · 5) -3 · 2 (1 · 1) -0 · 8 (0 · 9) n=100 W G -1 · 7 (0 · 2) -3 · 9 (0 · 7) -0 · 3 (0 · 4) -0 · 4 (1 · 5) -0 · 8 (0 · 3) -1 · 5 (1 · 5) 0 · 4 (0 · 3) 0 · 7 (0 · 3) WCK -1 · 3 (0 · 2) -2 · 7 (0 · 6) -0 · 7 (0 · 3) -0 · 8 (1 · 1) -0 · 5 (0 · 2) 0 · 3 (1 · 4) 0 · 2 (0 · 3) 0 · 5 (0 · 3) EP q =1 -0 · 2 (0 · 2) 0 · 6 (0 · 3) -0 · 6 (0 · 3) 0 · 0 (0 · 8) -0 · 2 (0 · 3) 0 · 5 (0 · 5) -1 · 1 (0 · 3) -0 · 2 (0 · 1) EP q =0 · 2 -1 · 3 (0 · 2) -1 · 8 (0 · 3) -0 · 8 (0 · 3) -1 · 4 (1 · 2) -0 · 6 (0 · 2) -0 · 8 (0 · 7) -0 · 3 (0 · 3) 0 · 2 (0 · 2) GDP -1 · 4 (0 · 2) -2 · 1 (0 · 4) -0 · 8 (0 · 4) -1 · 3 (1 · 1) -0 · 6 (0 · 2) -0 · 6 (0 · 6) -1 · 0 (0 · 3) -0 · 1 (0 · 1) Log -1 · 4 (0 · 2) -1 · 9 (0 · 4) -0 · 8 (0 · 3) -1 · 3 (1 · 1) -0 · 6 (0 · 2) -0 · 6 (0 · 6) -0 · 6 (0 · 3) 0 · 0 (0 · 2) W G , G -Wishart; WCK, W ong et al. ( 2003 ); GDP , generalized double Pareto; EP , exp onential p ow er; Log: logarithmic. priors ha v e very similar p erformances – ranking among top mo dels in all cases. In summary , the exp erimen t illustrates that these three heavy-tailed priors in the scale mixture of uniform family are generally indeed go o d for high dimensional co v ariance matrix estimation. 5 Applica tion to mul tiv aria te conditional autoregressive models 5.1 Multiv ariate conditional autoregressiv e mo dels based on scale mixture of uniform priors Multiv ariate conditional autoregressive mo dels ( Banerjee et al. , 2004 ) constitute a di- v erse set of p ow erful to ols for modeling m ultiv ariate spatial random v ariables at areal unit level. Let W = ( w ij ) p r × p r b e the symmetric pro ximity matrix of p r areal units, w ij ∈ { 0 , 1 } , and w ii are customarily set to 0. Then W defines an undirect graph G r = ( V r , E r ) where an edge ( i, j ) ∈ E r if and only if w ij = 1. Let w i + = P j w ij , E W = diag( w 1+ , . . . , w p r + ) and M = ( m ij ) = E W − ρW . Let X = ( x 1 , . . . , x p r ) T denote a p r × p c random matrix where eac h x i is a p c -dimensional v ector corresp onding to re- gion i . F ollowing Gelfand & V ounatsou ( 2003 ), one p opular version of the multiv ariate conditional autoregressiv e mo dels sets the joint distribution of X as v ec ( X ) ∼ N { 0 , (Ω c ⊗ Ω r ) − 1 } , Ω r | ρ = E W − ρW, Ω c ∼ W ( b c , D c ) , (11) where Ω r is the p r × p r column co v ariance matrix, Ω c is the p c × p c ro w co v ariance matrix, ρ is the co efficient measuring spatial asso ciation and is constrained to b e b etw een the recipro cals of the minim um and maxim um eigenv alues of W to ensure that Ω r is nonsingular, and b c and D c resp ectiv ely denote the degree of freedom and lo cation parameters of a Wishart prior distribution for Ω c . The join t distribution in ( 11 ) implies the follo wing conditional distribution: x i | x − i , ρ, Ω c ∼ N ( X j ∈ ne( i ) ρ w − 1 i + x j , w − 1 i + Ω c ) , 12 where ne( i ) denotes the neigh b or of region i , that is, the set of p oints satisfying w ij = 1. Eviden tly , the t w o co v ariance structures (Ω r , Ω c ) are crucial in determining the effects of spatial smo othing. F or the matrix Ω c , direct application of shrink age priors can reduce estimation uncertain ties as compared to the conjugate Wishart prior in ( 11 ). F or Ω r , one common v alue of ρ for all x i ma y limit the flexibilit y of the mo del b ecause it assumes the same spatial asso ciation for all regions. The recent work of Dobra et al. ( 2011 ) uses the G -Wishart framew ork to provide alternativ e mo dels. Specifically , the authors recommend the follo wing extensions for mo deling (Ω r , Ω c ): Ω r | M ∼ W G r ( b r , M ) , M | ρ = E W − ρW, Ω c ∼ W G c ( b c , D c ) , (12) where the row graph G r is fixed and obtained from the proximit y matrix W , and the column graph G c is unkno wn. F or b oth models in ( 11 ) and ( 12 ), a prior for ρ w as c hosen to give higher probabilit y mass to v alues close to 1 to encourage sufficien t spatial dep endence. In particular, Dobra et al. ( 2011 ) put equal mass on the following 31 v alues: { 0, 0 · 05, 0 · 1, . . . , 0 · 8, 0 · 82, . . . , 0 · 90, 0 · 91, . . . , 0 · 99 } , . Notice that Ω r and Ω c are not uniquely identified since, for an y c > 0, Ω c ⊗ Ω r = ( c Ω c ) ⊗ (Ω r /c ) ( W ang & W est , 2009 ). W e address this b y fixing Ω r, 11 = 1. Using the theory and metho ds for cov ariance matrix dev elop ed in Section 3 , w e no w extend the m ultiv ariate conditional autoregressiv e mo dels ( 11 ) using the scale mixture of uniform distributions. W e consider the follo wing tw o extensions for mo deling Ω r ∈ M + ( G r ) and Ω c ∈ M + Ω r | ρ = E W − ρW , p (Ω c | τ ) ∝ Y i ≥ j g c ( ω c,ij /τ c ) , (13) and p (Ω r ) ∝ Y { ( i,j ) ∈ E r }∪{ i = j ∈ V r } g r ( | ω r,ij − m ij | /τ r ) 1 { ω r,ij < 0 } , p (Ω c | τ c ) ∝ Y i ≥ j g c ( ω c,ij /τ c ) . (14) The first extension ( 13 ) places shrink age priors on Ω c while leaving the mo del for Ω r unc hanged. The second extension ( 14 ) further shrinks Ω r to wards the matrix M = E W − ρW while allowing adaptiv e spatial smo othing b y not constraining Ω c to be con trolled by a common parameter ρ . One practical adv antage of the our mo del ( 14 ) o v er the mo del ( 12 ) of Dobra et al. ( 2011 ) is its flexibilit y in incorp orating prior kno wledge. F or example, the similarity of spatial neighbors implies that the off-diagonal elements of Ω r should b e constrained to b e negativ e ( Banerjee et al. , 2004 ). This p oint is not addressed by Dobra et al. ( 2011 ) as their metho d is only applicable when the free elements of Ω r are not truncated. In the scale mixture of uniform framework, this imp ortant constrain t is easily achiev ed by truncating eac h free off-diagonal element in Ω r to b e negative when sampling Ω r . The functional form of g r ( · ) and the shrink age parameter τ r can b e pre-sp ecified through careful prior elicitation as follo ws. Using the Gibbs sampler in Section 3.1 , we are able to sim ulate from the prior distribution of Ω r for fixed g r ( · ) and τ r . These prior dra ws 13 allo w us to choose g r ( · ) and τ r to represent plausible ranges of spatial asso ciations. T o sp ecify these ranges, one guideline can b e based on the mo del ( 11 ) for which Gelfand & V ounatsou ( 2003 ) recommended a prior for ρ that fa vors the upp er range of ρ ∈ (0 , 1). In ligh t of this recommendation, we prefer those g r and τ r that increasingly fa vor v alues of ω c,ij close to 1 for any ( i, j ) ∈ E r and ω c,ii close to w i + for i ∈ V r . Suc h choices of priors in tegrate prior information ab out spatial asso ciations and allow for v arying spatial smo othing parameters across differen t regions. 5.2 US cancer data Using our mo del, we analyze the same real data example studied by Dobra et al. ( 2011 ) concerning the application of m ultiv ariate spatial mo dels for studying the US cancer mortalit y rates. The data we analyzed consists of mortalit y coun ts for 10 types of tumors recorded for the 48 mainland states plus the District of Columbia for the y ear 2000. The data w ere collected b y the National Cen ter for Health Statistics. Moral- it y counts b elow 25 w ere treated as missing b ecause they are regarded as unreliable records in cancer surveillance comm unity . Let Y ij b e the num b er of deaths in state i = 1 , . . . , p r = 49 for tumor t yp e j = 1 , . . . , p c = 10 . F ollo wing Dobra et al. ( 2011 ), we considered P oisson multiv ariate loglinear mo dels with spatial random effects: Y ij | η ij ∼ P oi( η ij ) , log( η ij ) = log ( q i ) + µ j + X ij , where q i is the p opulation of state i , µ j is the intercept of tumor type j and X ij is the zero-mean spatial random effect associated with state i and tumor j and has the joint distribution v ec( X ) ∼ N { 0 , (Ω c ⊗ Ω r ) − 1 } . W e compared the out-of-sample predictiv e p erformance of mo del ( 13 ) and ( 14 ) against the mo del ( 11 ) of Gelfand & V ounatsou ( 2003 ) and mo del ( 12 ) of Dobra et al. ( 2011 ). F or ( 11 ) and ( 12 ), w e used the same h yp er-parameter settings as in Dobra et al. ( 2011 ). F or ( 13 ), w e set g c ( · ) to b e the logarithmic density in ( 4 ) and placed standard half-cauc hy prior on τ c in order to exp ect robust p erformance for shrink age estimation of Ω c as w as suggested by the sim ulation study in Section 4 . F or ( 14 ), w e let g r ( ω r,ij ) ∝ exp {−| ω r,ij − m ij | /τ r } 1 { ω r,ij < 0 } for i = j or ( i, j ) ∈ E r so that Ω r is centered around M = W − E W and the similarity of spatial neigh b ors is ensured. W e did not c ho ose hea vy-tailed distributions for g r ( · ) b ecause the sample size p c = 10 is relatively small for the dimension p r = 49 and a heavy-tailed prior can lead to a p osterior dis- tribution of ω r,ij to b e unrealistically small and ω r,ii to b e unrealistically large. W e considered τ r ∈ { 0 · 1, 1, 10 } to assess the prior sensitivity . Finally , w e mo deled g c ( · ) as in mo del ( 13 ). In order to assess the out-of-sample predictive p erformance, we replicated the 10- fold cross-v alidation exp eriment of Dobra et al. ( 2011 ). Sp ecifically , w e divided the nonmissing coun ts of Y in to 10 bins. F or each bin i , w e used the samples from the other 9 bins as observ ed data and imputed the samples from bin i as missing. T o compare differen t mo dels, w e then computed the predictive mean squared error and 14 mean v ariance as follo ws MSE = 1 |{ ( i, j ) : Y ij ≥ 25 }| X { ( i,j ): Y ij ≥ 25 } ( E ( Y ij ) − Y ij ) 2 , and V AR = 1 |{ ( i, j ) : Y ij ≥ 25 }| X { ( i,j ): Y ij ≥ 25 } V ar ( Y ij ) , where E ( Y ij ) and V ar ( Y ij ) are estimated using the p osterior sample mean and v ariance based on the output of the analysis of one of the 10 cross-v alidation datasets in whic h Y ij are treated as missing. All results were obtained using a Monte Carlo sample of size 80000 after an initial, discarded burn-in of 80000 iterations. Figure 1 shows the raw and predicted morality rate of colon cancer. T able 3 rep orts the predictive p erformance as measured by the mean squared error and mean v ariance. All methods with shrink age priors on Ω c impro ve the prediction ov er the standard metho d using the Wishart prior. Among the shrink age metho ds, the logarithmic prior outp erforms the G -Wishart prior. Allo wing Ω r to b e adaptive by setting τ r = 1 and 10 can further reduce the mean squared error while main taining the same predictive v ariance with the common ρ model. Ov erall, our results suggest that the mo dels ( 13 ) and ( 14 ) pro vide more accurate prediction and narro w er credible in terv als than the comp eting metho ds for this dataset. T o further study the prior sensitivit y to the choice of τ r , w e plotted the marginal prior and p osterior densities for the free off-diagonal element in Ω r using samples from the analysis of the first cross-v alidation dataset. Figure 2 displays the inference for one elemen t under τ r ∈ { 0 · 1, 1, 10 } . Clearly , the marginal p osterior distribution dep ends on the c hoice of τ r . This is not surprising b ecause the sample size is small compared to the dimension of Ω r . The case τ r = 1 and 10 seems to p erform w ell in this example b ecause the marginal p osterior distribution is influenced by the data. The case τ r =0 · 1 app ears to b e to o tight and thus is not largely influenced by the data. On the computing time, the Matlab implementation of mo del ( 14 ) to ok ab out 4 hours to complete the analysis of one of the ten cross-v alidation datasets, while mo del ( 12 ) of Dobra et al. ( 2011 ) took ab out 4 days. Additionally , Dobra et al. ( 2011 ) rep orted a run time of ab out 22 hours on a dual-core 2 · 8 Ghz computer under C++ implemen- tation for a similar dataset of size p r = 49 and p c = 11. As men tioned ab o v e, our mo dels based on the scale mixture of uniforms are not only more flexible but also more computationally efficien t. 6 Shrinka ge prior for linear regression models In this section we briefly in v estigate the prop erties of the shrink age prior constructed from scale mixture of uniforms for the linear regression mo dels. Recently , shrink age estimation for linear mo dels hav e received a lot of atten tion ( P ark & Casella , 2008 ; Griffin & Brown , 2010 ; Armagan et al. , 2011 ) all of which proceed via the scale mixture 15 (a) Ra w mortality rate (b) Predicted mortalit y rate 0.5 1 1.5 2 2.5 0.5 1 1.5 2 2.5 Figure 1: US cancer mortality map of colon cancer (p er 10000 habitants). (a) The ra w mortalit y rate, (b) The predicted mortality rate under mo del TDE+Log with τ r = 1. T able 3: Predictive mean squared error and v ariance in 10-fold cross-v alidation predic- tiv e p erformance in the cancer mortality example. GV DLR Common ρ +Log TDE+Log τ r =10 τ r =1 τ r =0 · 1 MSE 3126 2728 2340 2238 2187 2359 V AR 9177 6493 3814 3850 3810 3694 GV: the non-shrink age model ( 11 ) of Gelfand & V ounatsou ( 2003 ); DLR: mo del ( 12 ) of Dobra et al. ( 2011 ); Common ρ +Log: mo del ( 13 ) under common ρ for Ω r and logarithmic prior for Ω c ; TDE+Log: mo del ( 14 ) under truncated double-exp onential prior for Ω r with fixed but differen t τ r and logarithmic prior for Ω c . (a) τ r =0 · 1 (b) τ r =1 (c) τ r =10 −1.8 −1.6 −1.4 −1.2 −1 −0.8 −0.6 −0.4 −0.2 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 ω r,ij −4.5 −4 −3.5 −3 −2.5 −2 −1.5 −1 −0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 ω r,ij −25 −20 −15 −10 −5 0 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 ω r,ij Figure 2: Marginal prior (dashed lines) and p osterior (solid lines) densities of one free off-diagonal elemen t in Ω r from the analysis under mo del ( 14 ) with three different v alues of τ r : (a) τ r =0 · 1, (b) τ r =1, (c) τ r =10. 16 of normals. W alk er et al. ( 1997 ) and Qin et al. ( 1998 ) w ere among the first to use the scale mixture of uniform priors for regression mo dels. Ho wev er, they used this family only for mo deling the measurement errors and deriving the corresp onding Gibbs sampler. T o the b est of our knowledge, we are the first to inv estigate the scale mixture of uniforms as a class of shrink age priors for regression co efficients. When this pap er w as nearing completion w e were notified of a similar approac h in the v ery recen t work Polson & Scott ( 2011 ) in whic h the authors independently prop ose a similar construction based on mixtures of Bartlett-F ejer k ernels for the bridge regression and pro ceed via a result similar to Theorem 1 . Consider the follo wing version of a regularized Ba y esian linear mo del where the goal is to sample from the p osterior distribution p ( β | σ, τ , Y ) ∝ exp {− 1 2 σ 2 ( Y − X β ) T ( Y − X β ) } p Y j =1 g ( β j σ τ ) where g ( · ) is the shrink age prior and τ is the global shrink age parameter. Theorem 1 suggests w e can in tro duce laten t v ariable t = { t 1 , . . . , t p } suc h that the join t p osterior of ( β , t ) is given b y: p ( β , t | σ, τ , Y ) ∝ exp {− 1 2 σ 2 ( Y − X β ) T ( Y − X β ) } p Y j =1 {− g 0 ( t j ) 1 { σ τ t> | β j |} } The Gibbs samplers are then implemented b y (a) simulating β j from a truncated normal for eac h j , and (b) block simulating { t 1 , . . . , t p } from using the conditional cumulativ e distribution function in Theorem 2 . W e compare the p osterior mean estimators under the exp onential p ow er prior with q =0 · 2 and the logarithmic prior to the p osterior means corresp onding to several other existing priors. These t wo shrink age priors are in teresting because the exp onential p o wer prior is the Ba y esian analog of the bridge regression ( Park & Casella , 2008 ) and is c hallenging for fully p osterior analysis using the scale mixture of normals and relativ ely unexplored b efore, and the logarithmic prior is a new prior that resem bles the class of horsesho e priors that are sho wn to hav e some adv antages ov er man y existing approac hes ( Carv alho et al. , 2010 ). W e use the setting of simulation exp eriments considered in Armagan et al. ( 2011 ). Sp ecifically , w e generate n = 50 observ ations from y = x T β + , ∼ N (0 , 3 2 ), where β has one of the following five configurations: (i) β =(1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0) T , (ii) β (3,3,3,3,3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0) T , (iii) β =(1,1,1,1,1,0,0,0,0,0,1,1,1,1,1,0,0,0,0,0) T , (iv) β =(3,3,3,3,3,0,0,0,0,0,3,3,3,3,3,0,0,0,0,0) T , (v) β =(0 · 85, . . . , 0 · 85) T , and x = ( x 1 , . . . , x p ) T has one of the following tw o scenarios: (a) x j are indep endently and iden- tically distributed standard normals, (b) x is a multiv ariate normal with E ( x ) = 0 and co v ( x j , x j 0 ) = 0 · 5 | j − j 0 | . The v ariance is assumed to ha ve the Jeffrey’s prior p ( σ 2 ) ∝ 1 /σ 2 . The global shrink age parameter is assumed to hav e the conjugate τ − q ∼ Ga(1 , 1) for the exp onen tial p ow er prior with q =0 · 2, and τ ∼ C + (0 , 1) for the logarithmic prior. 17 T able 4: Summary of mo del errors for the simulation study in the regression analy- sis of Section 6 . Median mo del errors are rep orted; b o otstrap standard errors are in paren theses. (a) x j independent (b) x j correlated (i) (ii) (iii) (iv) (v) (i) (ii) (iii) (iv) (v) GDP a 2 · 7 (0 · 1) 2 · 2 (0 · 2) 4 · 0 (0 · 2) 3 · 8 (0 · 2) 5 · 7 (0 · 3) 2 · 1 (0 · 1) 2 · 1 (0 · 1) 3 · 2 (0 · 1) 4 · 2 (0 · 3) 4 · 4 (0 · 1) GDP b 2 · 8 (0 · 2) 2 · 1 (0 · 2) 4 · 6 (0 · 2) 3 · 8 (0 · 2) 7 · 0 (0 · 2) 1 · 9 (0 · 1) 2 · 0 (0 · 1) 3 · 3 (0 · 2) 4 · 2 (0 · 2) 4 · 7 (0 · 1) GDP c 2 · 6 (0 · 1) 2 · 4 (0 · 2) 4 · 4 (0 · 2) 4 · 0 (0 · 2) 6 · 5 (0 · 2) 1 · 9 (0 · 1) 2 · 2 (0 · 1) 3 · 1 (0 · 2) 4 · 3 (0 · 2) 4 · 3 (0 · 1) HS 2 · 7 (0 · 1) 2 · 1 (0 · 2) 4 · 8 (0 · 2) 3 · 8 (0 · 2) 7 · 3 (0 · 2) 2 · 0 (0 · 1) 2 · 0 (0 · 1) 3 · 3 (0 · 2) 4 · 3 (0 · 2) 4 · 6 (0 · 1) EP q =1 3 · 2 (0 · 1) 4 · 0 (0 · 3) 5 · 1 (0 · 3) 4 · 9 (0 · 3) 7 · 3 (0 · 5) 2 · 1 (0 · 1) 2 · 8 (0 · 2) 2 · 8 (0 · 1) 4 · 2 (0 · 3) 3 · 5 (0 · 2) EP q =0 · 2 2 · 5 (0 · 1) 2 · 0 (0 · 1) 4 · 7 (0 · 1) 3 · 9 (0 · 3) 7 · 3 (0 · 3) 2 · 0 (0 · 1) 2 · 1 (0 · 1) 3 · 2 (0 · 1) 3 · 9 (0 · 1) 5 · 4 (0 · 2) Log 2 · 5 (0 · 1) 2 · 5 (0 · 2) 4 · 5 (0 · 2) 4 · 5 (0 · 2) 6 · 4 (0 · 4) 2 · 0 (0 · 1) 2 · 4 (0 · 1) 3 · 0 (0 · 1) 4 · 3 (0 · 1) 4 · 6 (0 · 2) GDP a,b,c , three recommended Generalized double Pareto priors in Armagan et al. ( 2011 ); HS, horsesho e; EP , exponential power; Log, logarithmic. Mo del error is calculated using the Mahalanobis distance ( ˆ β − β ) T Σ X ( ˆ β − β ) where Σ X is the co v ariance matrix used to generate X . T able 4 rep orts the median mo del errors and the b o otstrap standard errors based on 100 datasets for each case. Results for cases other than the exp onential p o wer prior with q =0 · 2 and the logarithmic prior are based on the rep orted v alues of Armagan et al. ( 2011 ). Except for mo del (iii) and (v) in the correlated predictor scenario, the ex- p onen tial p o wer prior with q = 1 is outp erformed by other metho ds. The p erformances of the exp onen tial p o wer prior with q =0 · 2 and the logarithmic prior are comparable with those of the generalized P areto and the horsesho e priors. 7 Conclusion The scale mixture of uniform prior pro vides a unified framew ork for shrink age estima- tion of cov ariance matrices for a wide class of prior distributions. F urther researc h on the scale mixture of uniform distributions is of in terest in dev eloping theoretical insights as w ell as computational adv ances in shrink age prior estimation for Ba y esian analysis of co v ariance matrices and other related models. One obvious next step is to in v estigate the co v ariance selection models that encourage exact zeros on a subset of elemen ts of Ω under the scale mixture uniform priors. Suc h extensions can p otentially combine the flexibilit y of the scale mixture of uniform priors and the in terpretation of the graphs implied b y exact zero elemen ts. Another in teresting researc h direction is the generaliza- tion of the basic random sampling models to dynamic settings that allo w the co v ariance structure to b e time-v arying. Such mo dels are useful for analyzing high-dimensional time series data encoun tered in areas such as finance and en vironmen tal sciences. W e are current inv estigating these extensions and we exp ect the Gibbs sampler dev elop ed in Section 3.1 to pla y a key role in mo del fitting in these settings. 18 A cknowledgements The authors thank Ab el Ro driguez and James G. Scott for v ery useful con versations and references. NSP gratefully ackno wledges the NSF gran t DMS 1107070. Appendix Details of sampling algorithm in Section 3.1 The join t distribution of ( l 12 , d 1 , d 2 ) is: p ( d 1 , d 2 , l 21 | − ) ∝ d n/ 2+1 1 d n/ 2 2 exp[ − 1 2 tr { s 11 d 1 + s 22 ( l 2 21 d 1 + d 2 ) + 2 s 21 d 1 l 21 } ] 1 { Ω e,e ∈T } . Clearly , the full conditional distribution for d 1 , d 2 and l 21 are giv en by d 1 ∼ Ga { n/ 2 + 2 , ( s 11 + s 22 l 2 21 + 2 s 21 l 21 ) / 2 } 1 { Ω e,e ∈T } , d 2 ∼ Ga ( n/ 2 + 1 , s 22 / 2) 1 { Ω e,e ∈T } and l 21 ∼ N { s 21 /s 22 , 1 / ( s 22 d 1 ) } 1 { Ω e,e ∈T } , resp ectively . T o identify the truncated region T , recall Ω e,e = A + B , A = d 1 d 1 l 21 d 1 l 21 d 1 l 2 21 + d 2 , B = b 11 b 12 b 21 b 22 . The set T = {| ω ij | < t ij } ∩ {| ω ii | < t ii } ∩ {| ω j j | < t j j } can b e written as {| d 1 + b 11 | < t ii } ∩ {| d 1 l 21 + b 21 | < t ij } ∩ {| d 1 l 2 21 + d 2 + b 22 | < t j j } . (15) Giv en { B , t ii , t ij , t j j } , ( 15 ) gives straightforw ard expressions for the truncated region of eac h v ariable in ( d 1 , d 2 , l 21 ) conditional on the other t wo. Sampling a univ ariate truncated normal can b e carried out efficien tly using the metho d of Rob ert ( 1995 ), while sampling a truncated gamma is based on the inv erse cum ulative distribution function metho d. References Andrews, D. F. & Mallows, C. L. (1974). Scale mixtures of normal distributions. Journal of the R oyal Statistic al So ciety. Series B (Metho dolo gic al) 36 , pp. 99–102. Arma gan, A. (2009). V ariational bridge regression. Pr o c e e dings of the 12th Interna- tional Confe- r enc e on A rtificial Intel ligenc e and Statistics (AIST A TS) 5 . Arma gan, A. , Dunson, D. & Lee, J. (2011). Generalized double Pareto shrink age. A rXiv e-prints . A t a y-Ka yis, A. & Massam, H. (2005). The marginal lik eliho o d for decomp osable and non-decomp osable graphical Gaussian mo dels. Biometrika 92 , 317–35. 19 Banerjee, S. , Carlin, B. P. & Gelf and, A. E. (2004). Hier ar chic al Mo deling and analysis of Sp atial data . Bo ca Raton: Chapman & Hall. Barnard, J. , McCulloch, R. & Meng, X.-L. (2000). Mo deling cov ariance matri- ces in terms of standard deviations and correlations, with application to shrink age. Statistic a Sinic a 10 , 1281–1311. Ber ger, J. O. (1985). Statistic al de cision the ory and Bayesian analysis . New Y ork: Springer Series in Statistics, New Y ork: Springer, 2nd ed. Ber ger, J. O. & Berliner, L. M. (1986). Robust ba y es and empirical bay es analysis with -con taminated priors. The Annals of Statistics 14 , 461–486. Car v alho, C. M. , Polson, N. G. & Scott, J. G. (2010). The horsesho e estimator for sparse signals. Biometrika 97 , 465–480. Car v alho, C. M. & Scott, J. G. (2009). Ob jectiv e bay esian mo del selection in gaussian graphical mo dels. Biometrika 96 , 497–512. D aniels, M. J. & Kass, R. E. (1999). Nonconjugate ba yesian estimation of co v ari- ance matrices and its use in hierarchical mo dels. Journal of the A meric an Statistic al Asso ciation 94 , pp. 1254–1263. D aniels, M. J. & Kass, R. E. (2001). Shrink age estimators for cov ariance matrices. Biometrics 57 , 1173–1184. Dobra, A. , Lenkoski, A. & Rodriguez, A. (2011). Ba y esian inference for general gaussian graphical mo dels with application to multiv ariate lattice data. Journal of the A meric an Statistic al Asso ciation (to app e ar) . F an, J. , Feng, Y. & Wu, Y. (2009). Net w ork exploration via the adaptiv e lasso and scad p enalties. A nnals of Applie d Statistics 3 , 521–541. Feller, W. (1971). A n Intr o duction to Pr ob ability The ory and its Applic ations , v ol. I I. New Y ork: John Wiley & Sons, 2nd ed. Friedman, J. , Hastie, T. & Tibshirani, R. (2008). Sparse in v erse co v ariance estimation with the graphical lasso. Biostatistics 9 , 432–441. Gelf and, A. E. & V ouna tsou, P. (2003). Prop er m ultiv ariate conditional autore- gressiv e mo dels for spatial data analysis. Biostatistics 4 , 11–15. Griffin, J. E. & Br own, P. J. (2010). Inference with normal-gamma prior distri- butions in regression problems. Bayesian Analysis 5 , 171–188. Hans, C. (2009). Ba yesian lasso regression. Biometrika 96 , 835–845. 20 Jones, B. , Car v alho, C. , Dobra, A. , Hans, C. , Car ter, C. & West, M. (2005). Exp erimen ts in sto c hastic computation for high-dimensional graphical mo dels. Sta- tistic al Scienc e 20 , 388–400. Liechty, J. C. , Liechty, M. W. & M ¨ uler, P. (2004). Ba yesian correlation esti- mation. Biometrika 91 , 1–14. Liechty, M. W. , Liechty, J. C. & M ¨ uller, P. (2009). The Shadow Prior. Journal of Computational and Gr aphic al Statistics 18 , 368–383. Mitsakakis, N. , Massam, H. & Escobar, M. (2010). A Metrop olis-Hastings based metho d for sampling from G-Wishart distribution in Gaussian graphical mo dels. T ech. rep., Universit y of T oronto. P ark, T. & Casella, G. (2008). The Ba y esian Lasso. Journal of the Americ an Statistic al Asso ciation 103 , 681–686. Polson, N. G. & Scott, J. G. (2011). The Bay esian Bridge. ArXiv e-prints . Qin, Z. , W alker, S. & Damien, P. (1998). Uniform scale mixture mo dels with application to Bay esian inference. W orking pap ers series, Univ ersity of Mic higan Ross Sc ho ol of Business. R ober t, C. P. (1995). Simulation of truncated normal v ariables. Statistics and Computing 5 , 121–125. 10.1007/BF00143942. R othman, A. J. , Bickel, P. J. , Levina, E. & Zhu, J. (2008). Sparse p ermutation in v arian t co v ariance estimation. Ele ctr onic Journal of Statistics 2 , 494–515. R overa to, A. (2002). Hyp er-in verse Wishart distribution for non-decomp osable graphs and its application to Bay esian inference for Gaussian graphica l mo dels. Sc an- dinavian Journal of Statistics 29 , 391–411. W alker, S. , Damien, P. & Meyer, M. (1997). On scale mixtures of uniform distributions and the latent weigh ted least squares metho d. W orking pap ers series, Univ ersity of Mic higan Ross School of Business. W ang, H. (2011). The bay esian graphical lasso and efficient p osterior computation. W orking pap ers series, Univ ersity of South Carolina. W ang, H. & Car v alho, C. M. (2010). Sim ulation of hyper-inv erse wishart distribu- tions for non-decomp osable graphs. Ele ctr onic Journal of Statistics 4 , 1470–1475. W ang, H. & West, M. (2009). Bay esian analysis of matrix normal graphical mo dels. Biometrika 96 , 821–834. West, M. (1987). On scale mixtures of normal distributions. Biometrika 74 , pp. 646–648. 21 W ong, F. , Car ter, C. & K ohn, R. (2003). Efficient estimation of cov ariance selec- tion mo dels. Biometrika 90 , 809–30. Y ang, R. & Ber ger, J. O. (1994). Estimation of a cov ariance matrix using the reference prior. The Annals of Statistics 22 , pp. 1195–1211. Yuan, M. & Lin, Y. (2007). Mo del selection and estimation in the Gaussian graphical mo del. Biometrika 94 , 19–35. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment