Robustness of Anytime Bandit Policies
This paper studies the deviations of the regret in a stochastic multi-armed bandit problem. When the total number of plays n is known beforehand by the agent, Audibert et al. (2009) exhibit a policy such that with probability at least 1-1/n, the regr…
Authors: Antoine Salomon, Jean-Yves Audibert
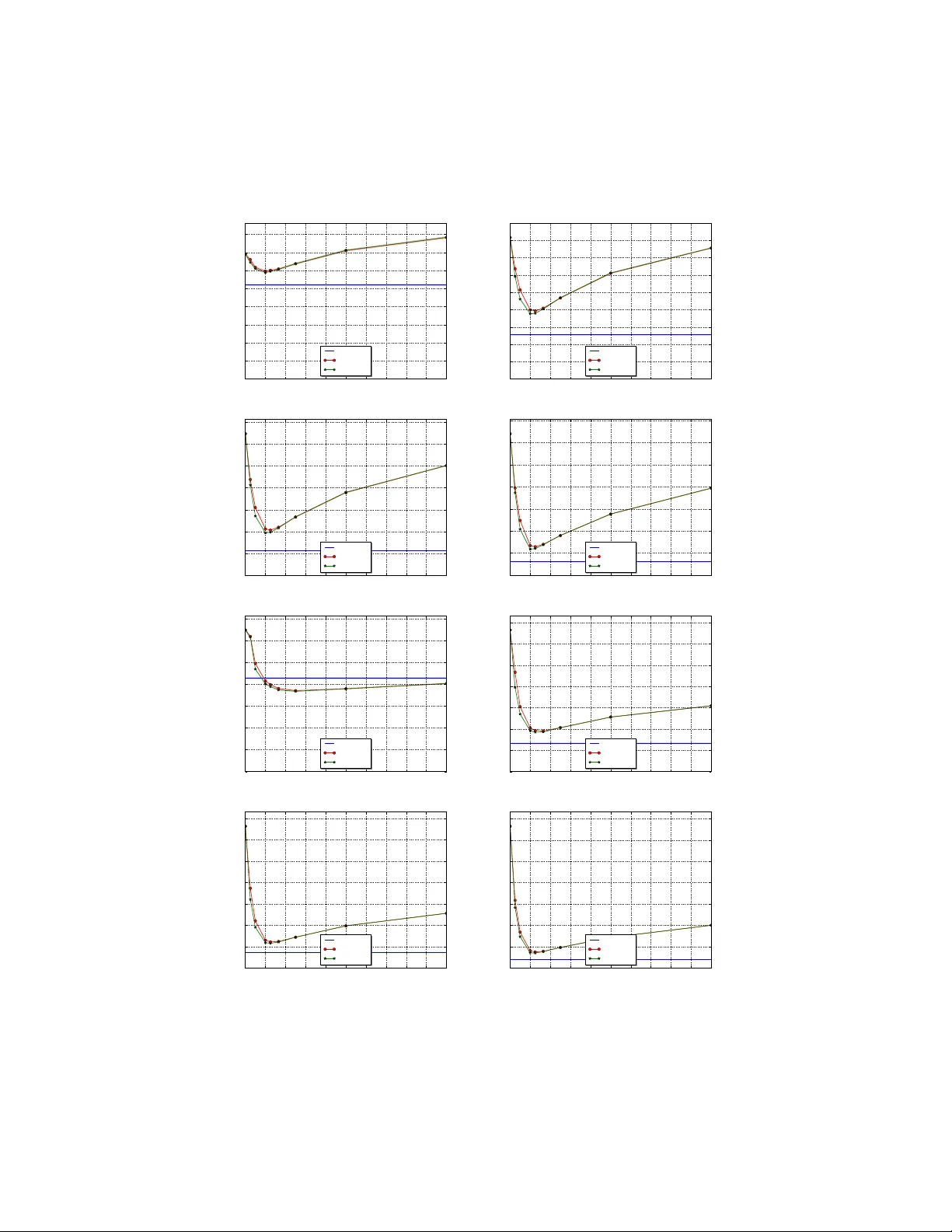
Robustness of an ytime bandit p olicies An toine Salomon a , Jean-Yv es Audibert a,b a Imagine, LIGM ´ Ec ole des Ponts ParisT e ch Universit´ e Paris Est b Sierr a, CNRS/ENS/INRIA, Paris, F r anc e Abstract This pap er studies the deviations of the regret in a stochastic m ulti-armed bandit problem. When the total n umber of pla ys n is known b eforehand by the agent, Audib ert et al. [2] exhibit a p olicy suc h that with probability at least 1 − 1 /n , the regret of the p olicy is of order log n . They hav e also shown that such a prop ert y is not shared by the p opular ucb1 p olicy of Auer et al. [3]. This work first answers an open question: it extends this negativ e result to any anytime p olicy . Another con tribution of this pap er is to design an ytime robust p olicies for specific multi-armed bandit problems in which some restrictions are put on the set of p ossible distributions of the different arms. W e also sho w that, for an y p olicy (i.e. when the num b er of plays is known), the regret is of order log n with probability at least 1 − 1 /n , so that the p olicy of Audib ert et al. has the b est p ossible deviation prop erties. Keywor ds: exploration-exploitation tradeoff, multi-armed sto c hastic bandit, regret deviations/risk 1. In tro duction Bandit problems illustrate the fundamental difficulty of sequen tial decision making in the face of uncertain ty: a decision mak er must c ho ose b etw een fol- lo wing what seems to b e the b est choice in view of the past (“exploitation”) or testing (“exploration”) some alternative, hoping to discov er a choice that b eats the current empirical b est c hoice. More precisely , in the sto c hastic multi-armed bandit problem, at each stage, an agent (or decision maker) c ho oses one action (or arm), and receives a reward from it. The agent aims at maximizing his rew ards. Since he does not know the pro cess generating the rewards, he does not know the b est arm, that is the one having the highest exp ected reward. He th us incurs a regret, that is the difference b et ween the cum ulative rew ard he w ould hav e got by alwa ys dra wing the b est arm and the cumulativ e rew ard he Email addr esses: salomona@imagine.enpc.fr (An toine Salomon), audibert@imagine.enpc.fr (Jean-Yv es Audibert) Pr eprint submitte d to Elsevier Novemb er 3, 2021 actually got. The name “bandit” comes from imagining a gambler in a casino pla ying with K slot mac hines, where at eac h round, the gam bler pulls the arm of an y of the machines and gets a pay off as a result. The multi-armed bandit problem is the simplest setting where one encoun- ters the exploration-exploitation dilemma. It has a wide range of applications including advertisemen t [4, 9], economics [5, 18], games [11] and optimization [15, 8, 14, 6]. It can b e a cen tral building blo c k of larger systems, like in ev olu- tionary programming [12] and reinforcemen t learning [23], in particular in large state space Marko vian Decision Problems [16]. Most of these applications re- quire that the p olicy of the forecaster works well for any time . F or instance, in tree search using bandit p olicies at each no de, the num b er of times the bandit p olicy will be applied at each node is not known beforehand (except for the ro ot no de in some cases), and the bandit policy should thus pro vide consistently lo w regret whatev er the total num b er of rounds is. Most previous w orks on the stochastic multi-armed bandit [21, 17, 1, 3, among others] focused on the exp ected regret, and show ed that after n rounds, the expected regret is of order log n . So far, the analysis of the upp er tail of the regret was only addressed in Audib ert et al. [2]. The tw o main results there ab out the deviations of the regret are the following. First, after n rounds, for large enough constan t C > 0, the probabilit y that the regret of ucb1 (and also its v ariant taking into account the empirical v ariance) exceeds C log n is upp er b ounded b y 1 / (log n ) C 0 for some constan t C 0 dep ending on the distributions of the arms and on C (but not on n ). Besides, for most bandit problems, this upp er bound is tight to the extent that the probability is also low er b ounded by a quan tity of the same form. Second, a new upp er confidence bound p olicy was prop osed: it requires to know the total num b er of rounds in adv ance and uses this knowledge to design a p olicy which essen tially explores in the first rounds and then exploits the information gathered in the exploration phase. Its regret has the adv an tage of being more concentrated to the exten t that with probability at least 1 − 1 /n , the regret is of order log n . The problem left open by [2] is whether it is p ossible to design an anytime robust p olicy , that is a p olicy such that for any n , with probabilit y at least 1 − 1 /n , the regret is of order log n . In this pap er, we answ er negativ ely to this question when the reward distributions of all arms are just assumed to b e uniformly bounded, sa y all rewards are in [0 , 1] for instance (Corollary 3.4). W e then study which kind of restrictions on the set of probabilities defining the bandit problem allo ws to answer p ositively . One of our p ositive results is the follo wing: if the agent knows the v alue of the exp ected rew ard of the best arm (but do es not kno w which arm is the best one), the agen t can use this information to design an an ytime robust policy (Theorem 4.3). W e also show that it is not p ossible to design a p olicy suc h that the regret is of order log n with a probability that w ould significantly greater than 1 − 1 /n , ev en if the agent knows the total num b er of rounds in adv ance (Corollary 5.2). The paper is organised as follows: in the first section, we formally describ e the problem we address and give the corresp onding definitions and prop erties. Next we present our main impossibility result. In the third section, we provide restrictions under which it is p ossible to design anytime robust p olicies. In the 2 fourth section, we study the robustness of p olicies that can use the kno wledge of the total n umber of rounds. Then w e pro vide experiments to compare our robust p olicy to the classical UCB algorithms. The last section is devoted to the proofs of our results. 2. Problem setup and definitions In the sto chastic multi-armed bandit problem with K ≥ 2 arms, at eac h time step t = 1 , 2 , . . . , an agent has to choose an arm I t in the set { 1 , . . . , K } and obtains a reward drawn from ν I t indep enden tly from the past (actions and observ ations). The environmen t is thus parameterized by a K -tuple of probabilit y distributions θ = ( ν 1 , . . . , ν K ). The agent aims at maximizing his rew ards. He do es not know θ but knows that it b elongs to some set Θ. W e assume for simplicit y that Θ ⊂ ¯ Θ, where ¯ Θ denotes the set of all K -tuple of probabilit y distributions on [0 , 1]. W e th us assume that the rew ards are in [0 , 1]. F or each arm k and all times t ≥ 1, let T k ( t ) = P t s =1 1 I s = k denote the num- b er of times arm k was pulled from round 1 to round t , and X k, 1 , X k, 2 , . . . , X k,T k ( t ) the sequence of asso ciated rewards. F or an environmen t parameterized by θ = ν 1 , . . . , ν K ), let P θ denote the distribution on the probability space suc h that for any k ∈ { 1 , . . . , K } , the random v ariables X k, 1 , X k, 2 , . . . are i.i.d. real- izations of ν k , and suc h that these K infinite sequence of random v ariables are indep enden t. Let E θ denote the asso ciated expectation. Let µ k = R xdν k ( x ) be the mean reward of arm k . Introduce µ ∗ = max k µ k and fix an arm k ∗ ∈ argmax k ∈{ 1 ,...,K } µ k , that is k ∗ has the best exp ected rew ard. The sub optimalit y of arm k is measured b y ∆ k = µ ∗ − µ k . The agent aims at minimizing its regret defined as the difference b et ween the cumulativ e rew ard he would ha v e got by alw ays drawing the best arm and the cumulativ e rew ard he actually got. At time n ≥ 1, its regret is thus ˆ R n = n X t =1 X k ∗ ,t − n X t =1 X I t ,T I t ( t ) . (1) The exp ectation of this regret has a simple expression in terms of the sub op- timalities of the arms and the exp ected sampling times of the arms at time n . Precisely , w e hav e E θ ˆ R n = nµ ∗ − n X t =1 E θ ( µ I t ) = nµ ∗ − E θ K X k =1 T k ( n ) µ k = µ ∗ K X k =1 E θ [ T k ( n )] − K X k =1 µ k E θ [ T k ( n )] = K X k =1 ∆ k E θ [ T k ( n )] . Other notions of regret exists in the literature: the quantit y P K k =1 ∆ k T k ( n ) is called the pseudo regret and ma y b e more practical to study , and the quan tity max k P n t =1 X k,t − P n t =1 X I t ,T I t ( t ) defines the regret in adverserial settings. Re- sults and ideas w e wan t to conv ey here are more suited to definition (1), and 3 taking another definition of the regret w ould only bring some more tec hnical in tricacies. Our main in terest is the study of the deviations of the regret ˆ R n , i.e. the v alue of P θ ( ˆ R n ≥ x ) when x is larger and of order of E θ ˆ R n . If a p olicy has small deviations, it means that the regret is small with high probability and in particular, if the p olicy is used on some real data, it is very likely to b e small on this sp ecific dataset. Naturally , small deviations imply small exp ected regret since w e ha v e E θ ˆ R n ≤ E θ max( ˆ R n , 0) = Z + ∞ 0 P θ ˆ R n ≥ x dx. T o a lesser extent it is also interesting to study the deviations of the sampling times T n ( k ), as this sho ws the abilit y of a p olicy to match the b est arm. More- o ver our analysis is mostly based on results on the deviations of the sampling times, which then enables to derive results on the regret. W e thus define b elow the notion of b eing f -upp er tailed for b oth quantities. Define R ∗ + = { x ∈ R : x > 0 } , and let ∆ = min k 6 = k ∗ ∆ k b e the gap b et w een the b est arm and second b est arm. Definition 1 ( f - T and f - R ) . Consider a mapping f : R → R ∗ + . A p olicy has f -upp er taile d sampling Times (in short, we wil l say that the p olicy is f - T ) if and only if ∃ C, ˜ C > 0 , ∀ θ ∈ Θ such that ∆ 6 = 0 , ∀ n ≥ 2 , ∀ k 6 = k ∗ , P θ T k ( n ) ≥ C log n ∆ 2 k ≤ ˜ C f ( n ) . A p olicy has f -upp er taile d R e gr et (in short, f - R ) if and only if ∃ C, ˜ C > 0 , ∀ θ ∈ Θ such that ∆ 6 = 0 , ∀ n ≥ 2 , P θ ˆ R n ≥ C log n ∆ ≤ ˜ C f ( n ) . W e will sometimes prefer to denote f ( n )- T (resp. f ( n )- R ) instead of f - T (resp. f - R ) for readability . Note also that, for sake of simplicity , we leav e aside the degenerated case of ∆ b eing null (i.e. when there are at least tw o optimal arms). In this definition, w e considered that the num b er K of arms is fixed, meaning that C and ˜ C may dep end on K . The thresholds considered on T k ( n ) and ˆ R n directly come from known tight upp er b ounds on the expectation of these quan tities for sev eral p olicies. T o illustrate this, let us recall the definition and prop erties of the p opular ucb1 p olicy . Let ˆ X k,s = 1 s P s t =1 X k,t b e the empirical mean of arm k after s pulls. In ucb1 , the agent plays eac h arm once, and then (from t ≥ K + 1), he plays I t ∈ argmax k ∈{ 1 ,...,K } ( ˆ X k,T k ( t − 1) + s 2 log t T k ( t − 1) ) . (2) 4 While the first term in the brack et ensures the exploitation of the knowledge gathered during steps 1 to t − 1, the second one ensures the exploration of the less sampled arms. F or this p olicy , Auer et al. [3] prov ed: ∀ n ≥ 3 , E [ T k ( n )] ≤ 12 log n ∆ 2 k and E θ ˆ R n ≤ 12 K X k =1 log n ∆ k ≤ 12 K log n ∆ . Lai and Robbins [17] sho wed that these results cannot b e improv ed up to numer- ical constants. Audib ert et al. [2] pro ved that ucb1 is log 3 - T and log 3 - R where log 3 is the function x 7→ [log( x )] 3 . Besides, they also study the case when 2 log t is replaced by ρ log t in (2) with ρ > 0, and prov ed that this mo dified ucb1 is log 2 ρ − 1 - T and log 2 ρ − 1 - R for ρ > 1 / 2, and that ρ = 1 2 is actually a critical v alue. Indeed, for ρ < 1 / 2 the p olicy do es not ev en hav e a logarithmic regret guaran tee in exp ectation. Another v arian t of ucb1 prop osed by Audib ert et al. is to replace 2 log t by 2 log n in (2) when w e w ant to hav e low and concentrated regret at a fixed giv en time n . W e refer to it as ucb-h as its implementation requires the knowledge of the horizon n of the game. The behaviour of ucb-h on the time in terv al [1 , n ] is significan tly different to the one of ucb1 , as ucb-h will explore m uch more at the b eginning of the interv al, and th us av oids exploiting the suboptimal arms on the early rounds. Audib ert et al. show ed that ucb-h is n - T and n - R (as it will be recalled in Theorem 3.5). As it will be confirmed b y our results, whether a p olicy knows in adv ance the horizon n or not matters a lot, that is why we in tro duce the following terms. Definition 2. A p olicy that uses the know le dge of the horizon n (e.g. ucb-h ) is a horizon p olicy. A p olicy that do es not use the know le dge of n (e.g. ucb1 ) is an anytime p olicy. W e now introduce the weak notion of f -upp er tailed as this notion will b e used to get our strongest imp ossibility results. Definition 3 ( f -w T and f -w R ) . Consider a mapping f : R → R ∗ + . A p olicy has we ak f -upp er taile d sampling Times (in short, we wil l say that the p olicy is f -w T ) if and only if ∀ θ ∈ Θ such that ∆ 6 = 0 , ∃ C, ˜ C > 0 , ∀ n ≥ 2 , ∀ k 6 = k ∗ , P θ T k ( n ) ≥ C log n ∆ 2 k ≤ ˜ C f ( n ) . A p olicy has we ak f -upp er taile d R e gr et (in short, f -w R ) if and only if ∀ θ ∈ Θ such that ∆ 6 = 0 , ∃ C , ˜ C > 0 , ∀ n ≥ 2 , P θ ˆ R n ≥ C log n ∆ ≤ ˜ C f ( n ) . The only difference b etw een f - T and f -w T (and b et ween f - R and f -w R ) is the interc hange of “ ∀ θ ” and “ ∃ C, ˜ C ”. Consequen tly , a p olicy that is f - T (resp ectiv ely f - R ) is f - T (respectively f -w R ). Let us detail the links b etw een the f - T , f - R , f -w T and f -w R . 5 Prop osition 2.1. Assume that ther e exists α, β > 0 such that f ( n ) ≤ αn β for any n ≥ 2 . We have f - T ⇒ f - R ⇒ f -w R ⇔ f -w T . The pro of of this prop osition is technical but rather straightforw ard. Note that we do not ha ve f - R ⇒ f - T , b ecause the agent ma y not regret having pulled a sub optimal arm if the latter has deliv ered go od rewards. Note also that f is required to b e at most p olynomial: if not some rare even ts suc h as unlik ely deviations of rew ards to wards their actual mean can not b e neglected, and none of the implications hold in general (except, of course, f - R ⇒ f -w R and f - T ⇒ f -w T ). 3. Imp ossibilit y result Here and in section 4 w e mostly deal with anytime p olicies, and the w ord p olicy (or algorithm) implicitly refers to an ytime p olicy . In the previous section, we hav e mentioned that for any ρ > 1 / 2, there is a v arian t of ucb1 (obtained by changing 2 log t into ρ log t in (2)) which is log 2 ρ − 1 - T . This means that, for any α > 0, there exists a log α - T p olicy , and a hence log α - R p olicy . The follo wing result sho ws that it is imp ossible to find an algorithm that would hav e better deviation prop erties than these ucb policies. F or man y usual settings (e.g., when Θ is the set ¯ Θ of all K -tuples of measures on [0 , 1]), with not so small probability , the agent gets stuck drawing a sub optimal arm he b elieves b est. Precisely , this situation arises when sim ultaneously: (a) an arm k deliv ers pay offs according to a same distribution ν k in tw o dis- tinct en vironmen ts θ and ˜ θ , (b) arm k is optimal in θ but sub optimal in ˜ θ , (c) in environmen t ˜ θ , other arms may b eha ve as in environmen t θ , i.e. with p ositiv e probability other arms deliver pa y offs that are likely in b oth en- vironmen ts. If the agen t susp ects that arm k deliv ers pay offs according to ν k , he do es not kno w if he has to pull arm k again (in case the environmen t is θ ) or to pull the optimal arm of ˜ θ . The other arms can help to p oin t out the difference betw een θ and ˜ θ , but then they hav e to b e c hosen often enough. This is in fact this kind of situation that has to b e taken into account when balancing a p olicy b et ween exploitation and exploration. Our main result is the formalization of the leads giv en ab o ve. In particular, w e give a rigorous description of conditions (a), (b) and (c). Let us first recall the following results, which are needed in the formalization of condition (c). One may lo ok at [22], p.121 for details (among others). Those who are not familiar with measure theory can skip to the non-formal explanation just after the results. 6 Theorem 3.1 (Leb esgue-Radon-Nik o dym theorem) . L et µ 1 and µ 2 b e σ -finite me asur es on a given me asur able sp ac e. Ther e exists a µ 2 -inte gr able function dµ 1 dµ 2 and a σ -finite me asur e m such that m and µ 2 ar e singular 1 and µ 1 = dµ 1 dµ 2 · µ 2 + m. The density dµ 1 dµ 2 is unique up to a µ 2 -ne gligible event. W e adopt the conv en tion that dµ 1 dµ 2 = + ∞ on the complementary of the supp ort of µ 2 . Lemma 3.2. We have • µ 1 dµ 1 dµ 2 = 0 = 0 . • µ 2 dµ 1 dµ 2 > 0 > 0 ⇔ µ 1 dµ 2 dµ 1 > 0 > 0 . Pr o of. The first p oint is a clear consequence of the decomp osition µ 1 = dµ 1 dµ 2 · µ 2 + m and of the conv ention men tioned ab o v e. F or the second p oin t, one can write b y uniqueness of the decomposition: µ 2 dµ 1 dµ 2 > 0 = 0 ⇔ dµ 1 dµ 2 = 0 µ 2 − a.s. ⇔ µ 1 = m ⇔ µ 1 and µ 2 are singular . And b y symmetry of the roles of µ 1 and µ 2 : µ 2 dµ 1 dµ 2 > 0 > 0 ⇔ µ 1 and µ 2 are not singular ⇔ µ 1 dµ 2 dµ 1 > 0 > 0 . Let us explain what these results hav e to do with condition (c). One may b e able to distinguish environmen t θ from ˜ θ if a certain arm ` delivers a pay off that is infinitely more likely in ˜ θ than in θ . This is for instance the case if X `,t is in the support of ˜ ν ` and not in the supp ort of ν ` , but our condition is more general. If the agent observes a pa y off x from arm ` , the quantit y dν ` d ˜ ν ` ( x ) represen ts ho w m uch the observ ation of x is more likely in en vironmen t θ than in ˜ θ . If ν k and ˜ ν k admit density functions (sa y , resp ectively , f and ˜ f ) with resp ect to a common measure, then dν ` d ˜ ν ` ( x ) = f ( x ) ˜ f ( x ) . Thus the agen t will almost nev er mak e a mistak e if he remov es θ from possible en vironments when dν ` d ˜ ν ` ( x ) = 0. This ma y happ en even if x is in both supp orts of ν ` and ˜ ν ` , for example if x is an atom of ˜ ν ` and not of ν ` (i.e. ˜ ν ` ( x ) > 0 and ν ` ( x )=0). On the contrary , if dν ` d ˜ ν ` ( x ) > 0 b oth environmen ts θ and ˜ θ are likely and arm ` ’s behaviour is b oth 1 Two measures m 1 and m 2 on a measurable space (Ω , F ) are singular if and only if there exists tw o disjoint measurable sets A 1 and A 2 such that A 1 ∪ A 2 = Ω, m 1 ( A 2 ) = 0 and m 2 ( A 1 ) = 0. 7 consisten t with θ and ˜ θ . No w let us state the imp ossibilit y result. Here and throughout the pap er w e find it more conv enient to denote f + ∞ g rather than the usual notation g = o ( f ), whic h has the following meaning: ∀ ε > 0 , ∃ N ≥ 0 , ∀ n ≥ N , g ( n ) ≤ εf ( n ) . Theorem 3.3. L et f : N → R ∗ + b e gr e ater than or der log α , that is for any α > 0 , f + ∞ log α . Assume that ther e exists θ , ˜ θ ∈ Θ , and k ∈ { 1 , . . . , K } such that: (a) ν k = ˜ ν k , (b) k is the index of the b est arm in θ but not in ˜ θ , (c) ∀ ` 6 = k , P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 > 0 . Then ther e is no f -w T anytime p olicy, and henc e no f - R anytime p olicy. Let us give some hints of the pro of (see Section 7 for details). The main idea is to consider a p olicy that would b e f -w T , and in particular that would “w ork well” in environmen t θ in the sense giv en by the definition of f -w T . The pro of exhibits a time N at which arm k , optimal in environmen t θ and th us often drawn with high P θ -probabilit y , is dra wn too man y times (more than the logarithmic threshold C log( N ) ∆ 2 k ) with not so small P ˜ θ -probabilit y , which shows the nonexistence of suc h a p olicy . More precisely , let n b e large enough and consider a time N of order log n and ab o ve the threshold. If the p olicy is f -w T , at time N , sampling times of sub optimal arms are of order log N at most, with P θ -probabilit y at least 1 − ˜ C /f ( N ). In this case, at time N , the draws are con- cen trated on arm k . So T k ( N ) is of order N , whic h is more than the threshold. This even t holds with high P θ -probabilit y . No w, from (a) and (c), we exhibit constan ts that are characteristic of the ability of arms ` 6 = k to “b ehav e as if in θ ”: for some 0 < a, η < 1, there is a subset ξ of this even t suc h that P θ ( ξ ) ≥ a T for T = P ` 6 = k T ` ( N ) and for which d P θ d P ˜ θ is low er b ounded by η T . The ev ent ξ on which the arm k is sampled N times at least has therefore a P ˜ θ -probabilit y of order ( η a ) T at least. This concludes this sk etch y pro of since T is of order log N , th us ( η a ) T is of order log log( η a ) n at least. Note that the conditions given in Theorem 3.3 are not very restrictive. The imp ossibilit y holds for very basic settings, and may hold even if the agent has great kno wledge of the p ossible environmen ts. F or instance, the setting K = 2 and Θ = B er 1 4 , δ 1 2 , B er 3 4 , δ 1 2 , where B er ( p ) denotes the Bernoulli distribution of parameter p and δ x the Dirac measure on x , satisfies the three conditions of the theorem. Nev ertheless, the main interest of the result regarding the previous literature is the follo wing corollary . 8 Corollary 3.4. If Θ is the whole set ¯ Θ of al l K -tuples of me asur es on [0 , 1] , then ther e is no f - R anytime p olicy, wher e f is any function such that f + ∞ log α for al l α > 0 . This corollary should b e read in conjunction with the following result for ucb-h whic h, for a given n , pla ys at time t ≥ K + 1, I t ∈ argmax k ∈{ 1 ,...,K } ( ˆ X k,T k ( t − 1) + s 2 log n T k ( t − 1) ) . Theorem 3.5. F or any β > 0 , ucb-h is n β - R . F or ρ > 1, Theorem 3.5 can easily b e extended to the p olicy ucb-h ( ρ ) which starts b y dra wing eac h arm once, and then at time t ≥ K + 1, plays I t ∈ argmax k ∈{ 1 ,...,K } ( ˆ X k,T k ( t − 1) + s ρ log n T k ( t − 1) ) . (3) Naturally , w e hav e n β n → + ∞ log α ( n ) for all α, β > 0 but this do es not con tradict our theorem, since ucb-h ( ρ ) is not an anytime p olicy . ucb-h will w ork fine if the horizon n is known in adv ance, but may perform p o orly at other rounds. Corollary 3.4 should also b e read in conjunction with the following result for the p olicy ucb1 ( ρ ) which starts b y drawing each arm once, and then at time t ≥ K + 1, plays I t ∈ argmax k ∈{ 1 ,...,K } ( ˆ X k,T k ( t − 1) + s ρ log t T k ( t − 1) ) . (4) Theorem 3.6. F or any ρ > 1 / 2 , ucb1 ( ρ ) is log 2 ρ − 1 - R . Th us, any improv emen ts of existing algorithms whic h would for instance in volv e estimations of v ariance (see [2]), of ∆ k , or of man y characteristics of the distributions cannot b eat the v arian ts of ucb1 regarding deviations. 4. P ositiv e results The intuition b ehind Theorem 3.3 suggests that, if one of the three condi- tions (a), (b), (c) do es not hold, a robust p olicy w ould consist in the follo wing: at eac h round and for each arm k , compute a distance betw een the empirical distribution of arm k and the set of distribution ν k that makes arm k optimal in a giv en environmen t θ . As this distance decreases with our b elief that k is the optimal arm, the policy consists in taking the k minimizing the distance. Th us, the agent ch o oses an arm that fits b etter a winning distribution ν k . He cannot get stuck pulling a sub optimal arm b ecause there are no environmen ts 9 ˜ θ with ν k = ˜ ν k in whic h k would be sub optimal. More precisely , if there exists suc h an environmen t ˜ θ , the agent is able to distinguish θ from ˜ θ : during the first rounds, he pulls ev ery arm and at least one of them will never b eha ve as if in θ if the current environmen t is ˜ θ . Thus, in ˜ θ , he is able to remov e θ from the set of p ossible environmen ts Θ (remember that Θ is a parameter of the problem whic h is kno wn b y the agent). Nev ertheless suc h a p olicy cannot w ork in general, notably b ecause of the three follo wing limitations: • If ˜ θ is the current environmen t and even if the agen t has identified θ as imp ossible (i.e. dν k d ˜ ν k ( X k, 1 ) = 0), there still could b e other environmen ts θ 0 that are arbitrary close to θ in whic h arm k is optimal and whic h the agen t is not able to distinguish from ˜ θ . This means that the agent may pull arm k to o often b ecause distribution ˜ ν k = ν k is to o close to a distribution ν 0 k that mak es arm k the optimal arm. • The ability to identify en vironments as imp ossible relies on the fact that the even t dν k d ˜ ν k ( X k, 1 ) > 0 is almost sure under P θ (see Lemma 3.2). If the set of all en vironments Θ is uncountable, such a criterion can lead to exclude the actual environmen t. F or instance, assume an agent has to distinguish a distribution among all Dirac measures δ x ( x ∈ [0 , 1]) and the uniform probability λ ov er [0 , 1]. Whatev er the pay off x observed by the agent, he will alwa ys exclude λ from the p ossible distributions, as x is alw ays infinitely more likely under δ x than under λ : ∀ x ∈ [0 , 1] , dλ dδ x ( x ) = 0 . • On the other hand, the agen t could legitimately consider an en vironment θ as unlikely if, for ε > 0 small enough, there exists ˜ θ such that dν k d ˜ ν k ( X k, 1 ) ≤ ε . Criterion (c) only considers as unlik ely an environmen t θ when there exists ˜ θ such that dν k d ˜ ν k ( X k, 1 ) = 0. Despite these limitations, we give in this section sufficient conditions on Θ for such a policy to b e robust. This is equiv alent to finding conditions on Θ under which the conv erse of Theorem 3.3 holds, i.e. under which the fact one of the conditions (a), (b) or (c) does not hold implies the existence of a robust p olicy . This can also b e expressed as finding which kind of kno wledge of the en vironment enables to design anytime robust p olicies. W e estimate distributions of eac h arm b y means of their empirical cumulativ e distribution functions, and distance b et ween t wo c.d.f. is measured by the norm k . k ∞ , defined by k f k ∞ = sup x ∈ [0 , 1] | f ( x ) | where f is any function [0 , 1] → R . The empirical c.d.f of arm k after having b een pulled t times is denoted ˆ F k,t . The wa y we c ho ose an arm at each round is based on confidence areas around ˆ F k,T k ( n − 1) . W e choose the greater confidence level ( gcl ) such that there is still 10 Pro ceed as follows: • Draw each arm once. • Remov e each θ ∈ Θ suc h that there exists ˜ θ ∈ Θ and ` ∈ { 1 , . . . , K } with dν ` d ˜ ν ` ( X `, 1 ) = 0. • Then at each round t , play an arm I t ∈ argmin k ∈{ 1 ,...,K } T k ( t − 1) inf θ ∈ Θ k ˆ F k,T k ( t − 1) − F ν k 2 ∞ . Figure 1: A c.d.f.-based algorithm: gcl . an arm k and a winning distribution ν k suc h that F ν k , the c.d.f. of ν k , is in the area of ˆ F k,T k ( n − 1) . W e then select the corresp onding arm k . By means of Massart’s inequality (1990), this leads to the c.d.f. based algorithm describ ed in Figure 1. Θ k denotes the set { θ ∈ Θ | k is the optimal arm in θ } , i.e. the set of en vironmen ts that mak es k the index of the optimal arm. 4.1. Θ is finite When Θ is finite the limitations presen ted ab o ve do not really matter, so that the conv erse of Theorem 3.3 is true and our algorithm is robust. Theorem 4.1. Assume that Θ is finite and that for al l θ = ( ν 1 , . . . , ν K ) , ˜ θ = ( ˜ ν 1 , . . . , ˜ ν K ) ∈ Θ , and al l k ∈ { 1 , . . . , K } , at le ast one of the fol lowing holds: • ν k 6 = ˜ ν k , • k is sub optimal in θ , or is optimal in ˜ θ . • ∃ ` 6 = k , P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 = 0 . Then gcl is n β - T (and henc e n β - R ) for al l β > 0 . 4.2. Bernoul li laws W e assume that any ν k ( k ∈ { 1 , . . . , K } , θ ∈ Θ) is a Bernoulli law, and denote by µ k its parameter. W e also assume that there exists γ ∈ (0 , 1) such that µ k ∈ [ γ , 1] for all k and all θ . 2 Moreo ver we may denote arbitrary environmen ts θ , ˜ θ by θ = ( µ 1 , . . . , µ K ) and ˜ θ = ( ˜ µ 1 , . . . , ˜ µ K ). In this case dν ` d ˜ ν ` (1) = µ l ˜ µ l > 0, so that for any θ , ˜ θ ∈ Θ and any l ∈ { 1 , . . . , K } one has P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 ≥ P ˜ θ ( X `, 1 = 1) = ˜ µ l > 0 . Therefore condition (c) of Theorem 3.3 holds, and the imp ossibility result only relies on conditions (a) and (b). Our algorithm can be made simpler: there is no 2 The result also holds if all parameters µ k are in a given interv al [0 , γ ], γ ∈ (0 , 1). 11 Pro ceed as follows: • Draw each arm once. • Then at each round t , play an arm I t ∈ argmin k ∈{ 1 ,...,K } T k ( t − 1) inf θ ∈ Θ k µ k − ˆ X k,T k ( t − 1) 2 . Figure 2: A c.d.f.-based algorithm in case of Bernoulli laws: gcl-b . need to try to exclude unlik ely environmen ts, and computing the empirical c.d.f. is equiv alen t to computing the empirical mean (see Figure 2). The theorem and its con verse are expressed as follows. W e will refer to our p olicy as gcl-b as it lo oks for the environmen t matc hing the observ ations at the Greatest Confidence Lev el, in the case of Bernoulli distributions. Theorem 4.2. F or any θ ∈ Θ and any k ∈ { 1 , . . . , K } , let us set d k = inf ˜ θ ∈ Θ k | µ k − ˜ µ k | . gcl-b is such that: ∀ β > 0 , ∃ C, ˜ C > 0 , ∀ θ ∈ Θ , ∀ n ≥ 1 , ∀ k ∈ { 1 , . . . , K } , P θ T k ( n ) ≥ C log n d 2 k ≤ ˜ C n β . L et f : N ∗ → R ∗ + b e gr e ater than or der log α : ∀ α > 0 , f + ∞ log α . If ther e exists k such that (a’) inf θ ∈ Θ \ Θ k d k = inf θ ∈ Θ k ˜ θ ∈ Θ \ Θ k | µ k − ˜ µ k | = 0 , then ther e is no anytime p olicy such that: ∃ C, ˜ C > 0 , ∀ θ ∈ Θ , ∀ n ≥ 2 , ∀ k 6 = k ∗ , P θ ( T k ( n ) ≥ C log n ) ≤ ˜ C f ( n ) . Note that we do not adopt the former definitions of robustness ( f - R and f - T ), b ecause the significan t term here is d k (and not ∆ k ) 3 , which represen ts the distance b etw een Θ k and Θ r Θ k . Indeed robustness lies on the ability to distinguish en vironments, and this ability is all the more stronger as the distance b et ween the parameters of these environmen ts is greater. Pro vided that the densit y dν d ˜ ν is uniformly bounded aw ay from zero, the theorem holds for any parametric model, with d k b eing defined with a norm on the space of 3 There is no need to leave aside the case of d k = 0: with the conv ention 1 0 = + ∞ , the corresponding even t has zero probability . 12 Pro ceed as follows: • Draw each arm once. • Then at each round t , play an arm I t ∈ argmin k ∈{ 1 ,...,K } T k ( t − 1) µ ∗ − ˆ X k,T k ( t − 1) 2 + . Figure 3: gcl ∗ : a v ariant of c.d.f.-based algorithm when µ ∗ is known. parameters (instead of | . | ). Note also that the second part of the theorem is a bit weak er than Theorem 3.3, because of the interc hange of “ ∀ θ ” and “ ∃ C, ˜ C ”. The reason for this is that condition (a) is replaced by a weak er assumption: ν k do es not equal ˜ ν k , but condition (a’) means that suc h ν k and ˜ ν k can be chosen arbitrarily close. 4.3. µ ∗ is known This section shows that the imp ossibility result also breaks down if µ ∗ is kno wn by the agent. This situation is formalized as µ ∗ b eing constan t ov er Θ. Conditions (a) and (b) of Theorem 3.3 do not hold: if a distribution ν k mak es arm k optimal in an environmen t θ , it is still optimal in any en vironment ˜ θ such that ˜ ν k = ν k . In this case, our algorithm can b e made simpler (see Figure 3). A t each round w e c ho ose the greatest confidence level such that at least one empirical mean ˆ X k,T k ( t − 1) has µ ∗ in its confidence interv al, and select the corresponding arm k . This is similar to the previous algorithm, deviations b eing ev aluated ac- cording to Hoeffding’s inequalit y instead of Massart’s one. There is one more refinemen t: the level confidence of arm k at time step t can b e defined as T k ( t − 1)( µ ∗ − ˆ X k,T k ( t − 1) ) 2 + (where, for any x ∈ R , x + denotes max(0 , x )) in- stead of T k ( t − 1)( µ ∗ − ˆ X k,T k ( t − 1) ) 2 . Indeed, there is no need to p enalize an arm for his empirical mean rew ard b eing too muc h greater than µ ∗ . W e will refer to this p olicy as gcl ∗ . Theorem 4.3. When µ ∗ is known, gcl ∗ is n β -T (and henc e n β -R) for al l β > 0 . gcl ∗ relies on the use of Ho effding’s inequality . It is now well-established that in general, the Ho effding inequality does not lead to the b est factor in fron t of the log n in the exp ected regret b ound. The minimax factor has b een iden tified in the works of Lai and Robbins [17], Burnetas and Katehakis [7] for sp ecific families of probability distributions. This result has b een strengthened in Honda and T akem ura [13] to deal with the whole set of probabilit y distribu- tions on [0 , 1]. Getting the b est factor in fron t of the log n term in the exp ected regret b ound appeared there to b e tigh tly linked with the use of Sanov’s in- equalit y . The recent work of Maillard et al. [19] builds on a non-asymptotic v ersion of Sano v’s inequality to get tight non-asymptotic b ounds for probability 13 distributions with finite supp ort. Garivier and Capp ´ e [10] adopts a different starting p oint: the Chernoff inequality . This inequality states that for i.i.d. random v ariables V , V 1 , . . . , V T , taking their v alues in [0 , 1], for an y τ < E V we ha ve P 1 T T X i =1 V i ≤ τ ≤ exp − T K ( τ , E V ) , (5) where K ( p, q ) denotes the Kullbac k-Leibler div ergence b etw een Bernoulli distri- butions of resp ectiv e parameter p and q . It is known to b e tight for Bernoulli random v ariables (as discussed e.g. in [10]). A Chernoff version of GCL* would consist in the following: I t ∈ argmin k ∈{ 1 ,...,K } T k ( t − 1) K min( ˆ X k,T k ( t − 1) , µ ∗ ) , µ ∗ . (6) A t the expense of a more refined analysis, it is easy to prov e that Theorem 4.3 still holds for this algorithm. Getting a small constant in fron t of the logarithmic term b eing an orthogonal discussion to the main topic of this pap er, w e do not detail further this p oin t. 5. Horizon p olicies W e no w study regret deviation prop erties of horizon p olicies. Again, w e pro ve that ucb p olicies are optimal. Indeed, deviations of ucb-h are of order 1 /n α (for all α > 0) and our result shows that this cannot b e impro ved in general. This second imp ossibility result holds for many settings, that is the one for whic h there exists θ , ˜ θ ∈ Θ suc h that: (b) an arm k is optimal in θ but not in ˜ θ , (c’) in en vironmen t ˜ θ , all arms ma y behav e as if in θ . Indeed, dra ws ha ve to be concentrated on arm k in environmen t θ . In partic- ular, with large P θ -probabilit y , the num b er of dra ws of arm k (and only of arm k ) exceed the logarithmic threshold C log n ∆ 2 at step N = l K C log n ∆ 2 m . Suc h an ev ent only affects a small (logarithmic) num b er of pulls, so that in environmen t ˜ θ arms ma y easily behav e as in θ , and arm k is pulled too often with not so small P ˜ θ -probabilit y . More precisely , this ev ent happ ens with at least P θ -probabilit y 1 − ( K − 1) ˜ C f ( n ) for a f -wT p olicy . Because arms under environmen t ˜ θ are able to b eha v e as in θ , there exist constants 0 < a, η < 1 and a subset ξ of this even t suc h that P θ ( ξ ) ≥ a N and for which d P θ d P ˜ θ is lo w er bounded by η N . The even t ξ has then P ˜ θ -probabilit y of order ( η a ) N at least. As N is of order log n , the probabilit y of arm k b eing pulled to o often in ˜ θ is therefore at least of order 1 /n to the p ow er of a constant. Hence the following result. Theorem 5.1. L et f : N → R ∗ + b e gr e ater than or der n α , that is for any α > 0 , f ( n ) n → + ∞ n α . Assume that ther e exists θ , ˜ θ ∈ Θ , and k ∈ { 1 , . . . , K } such that: 14 (b) k is the index of the b est arm in θ but not in ˜ θ , (c’) ∀ ` ∈ { 1 , ..., K } , P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 > 0 . Then ther e is no f -w T horizon p olicy, and henc e no f - T horizon p olicy. Note that the conditions under which the imp ossibility holds are far less restrictiv e than in Theorem 3.3. Indeed, conditions (b) and (c’) are equiv alent to: (a”) P ˜ θ dν k d ˜ ν k ( X `, 1 ) > 0 > 0 , (b) k is the index of the b est arm in θ but not in ˜ θ , (c) ∀ ` 6 = k , P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 > 0. These are the same conditions as in Theorem 3.3, except for the first one, (a”), whic h is weak er than condition (a). As a consequence, corollary 3.4 can also b e written in the con text of horizon p olicies. Corollary 5.2. If Θ is the whole set ¯ Θ of al l K -tuples of me asur es on [0 , 1] , then ther e is no f - T horizon p olicy, wher e f is any function such that f ( n ) n → + ∞ n α for al l α > 0 . Moreo ver, the imp ossibilit y also holds for many basic settings, such as the ones describ ed in section 4.2. This shows that gcl-b is not only b etter in terms of deviations than ucb an ytime algorithms, but it is also optimal and, despite b eing an anytime p olicy , it is at least as go o d as any horizon p olicy . In fact, in most settings suitable for a gcl algorithm, gcl is optimal and is as go od as ucb-h without using the kno wledge of the horizon n . Nev ertheless, the imp ossibility is not strong enough to av oid the existence of f - R horizon p olicies, with f ( n ) n → + ∞ n α and any α > 0. Prop osition 2.1 do es not enable to deduce the non-existence of f - R p olicy from the non- existence of f -w T policy because it needs f to b e less than a function of the form αn β . W e b eliev e that, in general, the imp ossibilit y still holds for f - R horizon p olicies, but the corresp onding conditions will not b e easy to write and the analysis will not be as clear as our previous results. Basically , the impossibility w ould require the existence of a pair of en vironments θ , ˜ θ such that • an arm k is optimal in θ but not in ˜ θ , • in environmen t ˜ θ , all arms ma y b ehav e as if in θ in such a w ay that b est arm in ˜ θ w ould hav e actually giv en greater rewards than the other arms if it had b een pulled more often. Finally , as in section 4 one can wonder if there exists a conv erse to our result. Again, suc h an analysis would b e tougher to p erform and we only giv e some basic hints. 15 If Θ is suc h that for any θ, ˜ θ ∈ Θ either (b) or (c’) do es not hold, then one could actually perform very well. In this degenerated case, only one pull of each arm ma y make it p ossible to distinguish tricky pairs of environmen ts θ , ˜ θ , and thus to learn the best arm k ∗ . The agent then k eeps on pulling arm k ∗ , and its regret is almost surely less than K at any time step. The tricky part is that, as the distinction relies on the fact that the even t dν k d ˜ ν k ( X k, 1 ) > 0 is almost sure under P θ (see Lemma 3.2), this ma y not work if Θ is uncountable. 6. Exp erimen ts Our goal is to compare anytime ucb p olicies, more precisely ucb1 ( ρ ) for ρ ≥ 0 defined by (4), to the low-deviation p olicies ucb-h ( ρ ) for ρ ≥ 0, defined b y (3), and gcl ∗ in tro duced in Section 4 (see Figure 3). Most bandit p olicies con tain a parameter allowing to tune the exploration-exploitation trade-off. T o do a fair c omparison with an ytime ucb p olicies, w e consider the full range of p ossible exploration parameters. W e estimate the distribution of the regret of a p olicy b y running 100000 sim- ulations. In particular, this implies that the confidence interv al for the exp ected regret of a policy is smaller than the size of the mark ers for n = 100, and smaller than the linewidth for n ≥ 500. The reward distribution of the arms are here either the uniform (Unif ), or the Bernoulli (Ber) or the Dirac distributions. 6.1. T uning the explor ation p ar ameter in ucb p olicies for low exp e cte d r e gr et In ucb p olicies, the exploration parameter can b e interpreted as the confi- dence level at which a deviation inequality is applied (neglecting union b ounds issues). F or instance, the p opular ucb1 uses an exploration term p (2 log t ) /T k ( t ) = p log( t 4 ) / (2 T k ( t )) corresp onding to a 1 /t 4 confidence lev el in view of Ho effd- ing’s inequality . Sev eral studies [17, 1, 7, 2, 13] hav e shown that the critical confidence level is 1 /t . In particular, [2] hav e considered the p olicy ucb1 ( ρ ) ha ving the exploration term p ( ρ log t ) /T k ( t ), and shown that this p olicy hav e p olynomial regrets as so on as ρ < 1 / 2 (and ha v e logarithmic regret for ρ > 1 / 2). Precisely , for ρ < 1 / 2, the regret of the p olicy can b e low er b ounded b y n γ with 0 < γ < 1 which is all the smaller as ρ is close to 1 / 2. The first exp eriments, rep orted in Figures 4 and 5, show that for n ≤ 10 8 , taking ρ in [0 . 2 , 0 . 5) generally leads to better p erformance than taking the crit- ical ρ = 0 . 5. There is not really a contradiction with the previous results as for such ρ , the exponent γ is so small than there is no great difference b et ween log n and n γ . F or n ≤ 10 8 , the p olynomial regret will app ear for smaller v alues of ρ (i.e. ρ ≈ 0 . 1 in our experiments). The numerical simulations exhibit t wo different t yp es of bandit problems: in simple bandit problems (which contain the case where the optimal arm is a Dirac distribution, or the case when the smallest reward that the optimal arm can giv e is greater than the largest rew ard than the other arms can give), the p erformance of UCB policies is all the b etter as the exploration is reduced, that is the expected regret is an increasing function of the exploration parameter. In 16 difficult bandit problems (which con tain in particular the case when the smaller rew ard that the optimal arm is smaller than the mean of the second best arm), there is a real trade-off b etw een exploration and exploitation: the exp ected regret of ucb1 ( ρ ) decreases with ρ for small ρ and then increases. Both types of problems are illustrated in Figure 5. 6.2. The gain of knowing the horizon There is consisten tly a sligh t gain in using ucb-h ( ρ ) instead of ucb1 ( ρ ) both in terms of exp ected regret (see Figures 4 and 5) and in terms of deviations (see Figures 6 to 13 in pages 20 to 22). The latter figures also show the follo wing. If the agent’s target is not to minimize its exp ected regret, but to minimize a quan tile function at a given confidence lev el, increasing the exploration parameter ρ (for instance taking ρ = 0 . 5 instead of ρ = 0 . 2) can lead to a large improv emen t in difficult bandit problems, but also a large decrement simple bandit problems. Besides, for large v alues of ρ or for simple bandit problems, ucb1 ( ρ ) and ucb-h ( ρ ) b eha ve similarly and thus, there is not muc h gain in using ucb-h p olicies instead of ucb1 policies. 6.3. The gain of knowing the me an r ewar d of the optimal arm When the mean reward µ ∗ of the optimal arm is kno wn, there is a strong gain in using this information to design the p olicy . In all our exp eriments comparing the exp ected regret of p olicies, summarized in Figures 4 and 5, the parameter-free and anytime p olicy gcl ∗ p erforms a lot b etter than ucb1 ( ρ ) and ucb-h ( ρ ), even for the best ρ , except in one simulation (for n = 100, and K = 2 arms: a Bernoulli distribution of parameter 0 . 6 and a Dirac distribution at 0 . 5). In terms of thinness of the tail distribution of the regret, gcl ∗ outp erforms all p olicies in simple bandit problems, while in difficult bandit problems, it generally outp erforms ucb1 (0 . 2) and ucb-h (0 . 2) and p erforms similarly to ucb1 (0 . 5) and ucb-h (0 . 5) (see Figures 6 to 13 in pages 20 to 22). The gain of kno wing µ ∗ is more important than the gain of knowing the horizon. It is not clear to us that w e can ha ve a significant gain in knowing b oth µ ∗ and the horizon n compared to just kno wing µ ∗ . 7. Pro ofs 7.1. Pr o of of Pr op osition 2.1 f - T ⇒ f - R : When a p olicy is f - T , by a union bound, the ev ent ξ 1 = ∃ k ∈ { 1 , . . . , K } , T k ( n ) ≥ C log n ∆ 2 k o ccurs with probabilit y at most K ˜ C f ( n ) . Introduce S k,s = P s t =1 ( X k,t − µ k ) . Since w e ha ve n X t =1 X I t ,T I t ( t ) = K X k =1 S k,T k ( n ) + K X k =1 T k ( n ) µ k , 17 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 Expected regret Comparison of policies for n = 100 and K = 2 arms: Ber(0.6) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 2 4 6 8 10 12 14 16 Expected regret Comparison of policies for n = 500 and K = 2 arms: Ber(0.6) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 5 10 15 20 25 30 35 Expected regret Comparison of policies for n = 1000 and K = 2 arms: Ber(0.6) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 10 20 30 40 50 60 70 Expected regret Comparison of policies for n = 2000 and K = 2 arms: Ber(0.6) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 1 2 3 4 5 6 7 Expected regret Comparison of policies for n = 100 and K = 2 arms: Ber(0.6) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 5 10 15 20 25 30 35 Expected regret Comparison of policies for n = 500 and K = 2 arms: Ber(0.6) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 10 20 30 40 50 60 70 Expected regret Comparison of policies for n = 1000 and K = 2 arms: Ber(0.6) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 20 40 60 80 100 120 140 Expected regret Comparison of policies for n = 2000 and K = 2 arms: Ber(0.6) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) Figure 4: Exp ected regret of ucb1 ( ρ ), ucb-h ( ρ ) and gcl ∗ for v arious bandit settings (1/2). 18 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 5 10 15 20 25 Expected regret Comparison of policies for n = 1000 and K = 2 arms: Dirac(0.6) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 5 10 15 20 25 Expected regret Comparison of policies for n = 1000 and K = 2 arms: Unif([0.5,0.7]) and Unif([0.4,0.6]) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 1 2 3 4 5 6 Expected regret Comparison of policies for n = 100 and K = 3 arms: Ber(0.6), Ber(0.5) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 5 10 15 20 25 30 35 40 45 50 Expected regret Comparison of policies for n = 1000 and K = 3 arms: Ber(0.6), Ber(0.5) and Ber(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 1 2 3 4 5 6 7 Expected regret Comparison of policies for n = 100 and K = 3 arms: Ber(0.6), Ber(0.5) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 10 20 30 40 50 60 70 Expected regret Comparison of policies for n = 1000 and K = 3 arms: Ber(0.6), Ber(0.5) and Dirac(0.5) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 2 4 6 8 10 12 14 16 Expected regret Comparison of policies for n = 100 and K = 5 arms: Ber(0.7), Ber(0.6), Ber(0.5), Ber(0.4) and Ber(0.3) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 1 . 8 2 . 0 Exploration parameter ρ 0 10 20 30 40 50 60 70 80 Expected regret Comparison of policies for n = 1000 and K = 5 arms: Ber(0.7), Ber(0.6), Ber(0.5), Ber(0.4) and Ber(0.3) GC L ∗ UC B 1 ( ρ ) UC B - H ( ρ ) Figure 5: Exp ected regret of ucb1 ( ρ ), ucb-h ( ρ ) and gcl ∗ for v arious bandit settings (2/2) 19 − 30 − 20 − 10 0 10 20 30 40 Regret level r 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 30 − 20 − 10 0 10 20 30 40 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 10 15 20 25 30 35 40 Regret level r 0 . 00 0 . 02 0 . 04 0 . 06 0 . 08 0 . 10 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 6: Comparison of p olicies for n = 100 and K = 2 arms: Ber(0.6) and Ber(0.5). Left: smoothed probability mass function. Center and right: tail distribution of the regret. − 50 0 50 100 150 200 Regret level r 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 50 0 50 100 150 200 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 20 40 60 80 100 120 140 160 180 200 Regret level r 0 . 00 0 . 01 0 . 02 0 . 03 0 . 04 0 . 05 0 . 06 0 . 07 0 . 08 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 7: Comparison of p olicies for n = 1000 and K = 2 arms: Ber(0.6) and Ber(0.5). Left: smoothed probability mass function. Center and right: tail distribution of the regret. − 15 − 10 − 5 0 5 10 15 20 25 30 Regret level r 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 15 − 10 − 5 0 5 10 15 20 25 30 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 10 15 20 25 30 Regret level r 0 . 00 0 . 02 0 . 04 0 . 06 0 . 08 0 . 10 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 8: Comparison of p olicies for n = 100 and K = 2 arms: Ber(0.6) and Dirac(0.5). Left: smoothed probability mass function. Center and right: tail distribution of the regret. − 20 0 20 40 60 80 100 120 140 160 Regret level r 0 . 00 0 . 05 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 20 0 20 40 60 80 100 120 140 160 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 40 60 80 100 120 140 160 Regret level r 0 . 00 0 . 01 0 . 02 0 . 03 0 . 04 0 . 05 0 . 06 0 . 07 0 . 08 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 9: Comparison of p olicies for n = 1000 and K = 2 arms: Ber(0.6) and Dirac(0.5). Left: smoothed probability mass function. Center and right: tail distribution of the regret. 20 − 5 0 5 10 15 20 25 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( r − 1 ≤ ˆ R n ≤ r + 1) GC L ∗ UC B 1 ( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1 ( 0 . 5 ) UC B - H ( 0 . 5 ) − 5 0 5 10 15 20 25 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1 ( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1 ( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 10: Comparison of p olicies for n = 1000 and K = 2 arms: Dirac(0.6) and Ber(0.5). Left: smo othed probability mass function. Right: tail distribution of the regret. In this simple bandit problem, ucb1 and ucb-h curves are almost iden tical. − 5 0 5 10 15 20 25 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( r − 1 ≤ ˆ R n ≤ r + 1) GC L ∗ UC B 1 ( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1 ( 0 . 5 ) UC B - H ( 0 . 5 ) − 5 0 5 10 15 20 25 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1 ( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1 ( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 11: Comparison of p olicies for n = 1000 and K = 2 arms: Unif([0.5,0.7]) and Unif([0.4,0.6]). Left: smoothed probability distribution function. Right: tail distribution of the regret. In this simple bandit problem, ucb1 and ucb-h curves are almost identical. − 50 0 50 100 150 200 Regret level r 0 . 00 0 . 05 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 50 0 50 100 150 200 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 40 60 80 100 120 140 160 180 200 Regret level r 0 . 00 0 . 02 0 . 04 0 . 06 0 . 08 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 12: Comparison of p olicies for n = 1000 and K = 3 arms: Ber(0.6), Ber(0.5) and Ber(0.5). Left: smo othed probability mass function. Center and right: tail distribution of the regret. 21 − 50 0 50 100 150 200 250 Regret level r 0 . 00 0 . 05 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 I P( r − 2 ≤ ˆ R n ≤ r + 2) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) − 50 0 50 100 150 200 250 Regret level r 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) 50 100 150 200 250 Regret level r 0 . 00 0 . 01 0 . 02 0 . 03 0 . 04 0 . 05 0 . 06 I P( ˆ R n > r ) GC L ∗ UC B 1( 0 . 2 ) UC B - H ( 0 . 2 ) UC B 1( 0 . 5 ) UC B - H ( 0 . 5 ) Figure 13: Comparison of p olicies for n = 1000 and K = 5 arms: Ber(0.7), Ber(0.6), Ber(0.5), Ber(0.4) and Ber(0.3). Left: smoothed probabilit y mass function. Center and righ t: tail distribution of the regret. w e ha ve ˆ R n = S k ∗ ,n − S k ∗ ,T k ∗ ( n ) − X k 6 = k ∗ S k,T k ( n ) + X k 6 = k ∗ ∆ k T k ( n ) . (7) Let T = P k 6 = k ∗ T k ( n ) = n − T k ∗ ( n ) , t ∗ = P k 6 = k ∗ C log n ∆ 2 k , and W = max 0 ≤ s ≤ t ∗ ( S k ∗ ,n − S k ∗ ,n − s ). Since S k ∗ ,n − S k ∗ ,T k ∗ ( n ) ≤ W on the complement ξ c 1 of ξ 1 , w e ha v e ˆ R n ≤ n 1 ξ 1 + W − X k 6 = k ∗ S k,T k ( n ) + X k 6 = k ∗ ∆ k T k ( n ) . (8) Consider the even ts ξ 2 = ( W > X k 6 = k ∗ r C β 2 log n ∆ k ) , ξ 3 ,k = ( max 1 ≤ s ≤ C log n ∆ 2 k ( − S k,s ) > r C β 2 log n ∆ k ) , and ξ = ξ 1 ∪ ξ 2 ∪ k 6 = k ∗ ξ 3 ,k . F rom Ho effding’s maximal inequality , we hav e P θ ( ξ 2 ) ≤ exp − 2 P k 6 = k ∗ p C β / 2 log n ∆ k 2 P k 6 = k ∗ ( C log n ) / ∆ 2 k ! ≤ exp − β log n = 1 n β ≤ α f ( n ) . W e also use Ho effding’s maximal inequality to control P θ ( ξ 3 ,k ): P θ ( ξ 3 ,k ) ≤ exp − 2 p C β / 2 log n ∆ k 2 ( C log n ) / ∆ 2 k ! = 1 n β ≤ α f ( n ) . 22 By gathering the previous results using a union b ound, we ha ve P ( ξ ) ≤ 2 α + ˜ C f ( n ) . Besides on the complement of ξ , by using (8), w e ha v e ˆ R n < X k 6 = k ∗ r C β 2 log n ∆ k + X k 6 = k ∗ r C β 2 log n ∆ k + X k 6 = k ∗ C log n ∆ k . W e ha ve thus prov ed that ∀ θ ∈ Θ , ∀ n ≥ 1 , P θ ˆ R n ≥ ( C + p 2 C β ) log n ∆ ≤ ˜ C + 2 α f ( n ) , hence the p olicy is f - R . f -w T ⇒ f -w R : it is exactly the same pro of as for f - T ⇒ f - R since the core of the argument is indep enden t of the p osition of “ ∀ θ ” with resp ect to “ ∃ C , ˜ C ”. f -w R ⇒ f -w T : let us prov e the contrapositive. So we assume ∃ θ ∈ Θ suc h that ∆ 6 = 0 , ∀ C 0 , ˜ C 0 > 0 , ∃ n ≥ 1 , ∃ k 6 = k ∗ , P θ T k ( n ) ≥ C 0 log n ∆ 2 k > ˜ C 0 f ( n ) . (9) It is enough to pro ve that for this θ , we hav e ∀ C > 9 K/ ∆ , ∀ ˜ C > α, ∃ n ≥ 1 , P θ ˆ R n ≥ C log n ∆ > ˜ C f ( n ) . T o achiev e this, w e consider C 0 = ( β +2) C / ∆ and ˜ C 0 = max 2 ˜ C , max m ≤ K f ( m ) in (9) and let k 0 6 = k ∗ b e such that the ev en t ξ 0 = T k 0 ( n ) ≥ C 0 log n ∆ 2 k 0 holds with probability greater than ˜ C 0 /f ( n ) = 2 ˜ C /f ( n ). F rom (9) and using ˜ C 0 ≥ max m ≤ K f ( m ), we necessarily hav e n ≥ K . Le t L = log f ( n ) ˜ C nK and ξ 00 = ( ∀ k 6 = k ∗ , ∀ s ∈ { 1 , . . . , n } , | S k,s | ≤ r sL 2 ) \ ( ∀ s ∈ { 1 , . . . , n } , | S k ∗ ,n − S k ∗ ,n − s | ≤ r sL 2 ) . By Ho effding’s inequality and a union bound, this even t holds with probability at least 1 − ˜ C /f ( n ). As a consequence, we ha v e P ( ξ 0 ∩ ξ 00 ) > ˜ C /f ( n ). W e now pro ve that on the even t ξ 0 ∩ ξ 00 , w e ha v e ˆ R n ≥ C log n ∆ . First note that for any a > 0 the function s 7→ as − √ 2 sL is decreasing on 0 , L 2 a 2 and increasing on L 2 a 2 , + ∞ , and that T k 0 ( n ) ≥ C 0 log n ∆ 2 k 0 ≥ C L ∆ 2 k 0 , 23 since f ( n ) ˜ C nK ≤ αn β α n 2 = n β +2 ≤ n C 0 /C . Then, by using (7) and T k ∗ ( n ) = n − P k 6 = k ∗ T k ( n ), w e ha v e ˆ R n ≥ −| S k ∗ ,n − S k ∗ ,T k ∗ ( n ) | − X k 6 = k ∗ | S k,T k ( n ) | + X k 6 = k ∗ ∆ k T k ( n ) ≥ − s L P k 6 = k ∗ T k ( n ) 2 − X k 6 = k ∗ r LT k ( n ) 2 + X k 6 = k ∗ ∆ k T k ( n ) ≥ X k 6 = k ∗ ∆ k T k ( n ) − p 2 T k ( n ) L ! ≥ ∆ k 0 T k 0 ( n ) 2 + ∆ k 0 T k 0 ( n ) 2 − p 2 LT k 0 ( n ) + X k 6 = k ∗ ,k 6 = k 0 min s ≥ 1 ∆ k s − √ 2 Ls ! ≥ C 0 log n 2∆ k 0 + C 2 − √ 2 C L ∆ k 0 − X k 6 = k ∗ ,k 6 = k 0 L 2∆ k ≥ C 0 log n 2∆ k 0 + C 6 L ∆ k 0 − K L 2∆ ≥ C 0 log n 2∆ k 0 ≥ C log n ∆ , whic h ends the pro of of the contrapositive. 7.2. Pr o of of The or em 3.3 Let us first notice that we can remov e the ∆ 2 k denominator in the the def- inition of f -w T without loss of generalit y . This w ould not be possible for the f - T definition o wing to the different p osition of “ ∀ θ ” with resp ect to “ ∃ C , ˜ C ”. Th us, a policy is f -w T if and only if ∀ θ ∈ Θ suc h that ∆ 6 = 0 , ∃ C, ˜ C > 0 , ∀ n ≥ 2 , ∀ k 6 = k ∗ , P θ ( T k ( n ) ≥ C log n ) ≤ ˜ C f ( n ) . Let us assume that the policy has the f -upp er tailed property in θ , i.e., there exists C, ˜ C > 0 ∀ N ≥ 2 , ∀ ` 6 = k , P θ T ` ( N ) ≥ C log N ≤ ˜ C f ( N ) . (10) Let us sho w that this implies that the p olicy cannot hav e also the f -upp er tailed prop ert y in ˜ θ . T o pro ve the latter, it is enough to show that for any C 0 , ˜ C 0 > 0 ∃ n ≥ 2 , P ˜ θ T k ( n ) ≥ C 0 log n > ˜ C 0 f ( n ) . (11) since k is sub optimal in en vironment ˜ θ . Note that proving (11) for C 0 = C is sufficient. Indeed if (11) holds for C 0 = C , it a fortiori holds for C 0 < C . Besides, when C 0 > C , (10) holds for C replaced by C 0 , and w e are th us brough t 24 bac k to the situation when C = C 0 . So w e only need to lo wer b ound P ˜ θ T k ( n ) ≥ C log n . F rom Lemma 3.2, P ˜ θ dν ` d ˜ ν ` ( X `, 1 ) > 0 > 0 is equiv alent to P θ d ˜ ν ` dν ` ( X `, 1 ) > 0 > 0. By indep endence of X 1 , 1 , . . . , X K, 1 under P θ , condition (c) in the theorem ma y be written as P θ Y ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) > 0 ! > 0 . Since n Q ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) > 0 o = ∪ m ≥ 2 n Q ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) ≥ 1 m o , this readily im- plies that ∃ η ∈ (0 , 1) , P θ Y ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) ≥ η ! > 0 . Let a = P θ Q ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) ≥ η . Let us tak e n large enough suc h that N = b 4 C log n c satisfies N < n , C log N < N 2 K and f ( n ) η t a t − ( K − 1) ˜ C f ( N ) > ˜ C 0 for t = b C log N c . F or any ˜ C 0 , suc h a n do es exist since f + ∞ log α for an y α > 0. The idea is that if until round N , arms ` 6 = k hav e a b eha viour that is t ypical of θ , then the arm k (whic h is sub optimal in ˜ θ ) ma y be pulled ab out C log n times at round N . Precisely , w e prov e that ∀ ` 6 = k , P θ T ` ( N ) ≥ C log N ≤ ˜ C f ( N ) implies P ˜ θ T k ( n ) ≥ C 0 log n > ˜ C 0 f ( n ) . Let us denote A t = ∩ s =1 ...t n Q ` 6 = k d ˜ ν ` dν ` ( X `,s ) ≥ η o . By indep endence and by definition of a , w e ha ve P θ ( A t ) = a t . W e also ha ve P ˜ θ T k ( n ) ≥ C log n ≥ P ˜ θ T k ( N ) ≥ N 2 ≥ P ˜ θ \ ` 6 = k T ` ( N ) ≤ N 2 K ! ≥ P ˜ θ \ ` 6 = k T ` ( N ) < C log N ! ≥ P ˜ θ A t ∩ ( \ ` 6 = k T ` ( N ) < C log N )! . In tro duce B N = T ` 6 = k T ` ( N ) < C log N , and the function q such that 1 A t ∩ B N = q ( X `,s ) ` 6 = k, s =1 ..t , ( X k,s ) s =1 ..N . Since ˜ ν k = ν k , b y definition of A t and by standard prop erties of density functions 25 d ˜ ν ` dν ` , w e ha v e P ˜ θ A t ∩ ( \ ` 6 = k { T ` ( N ) < C log N } )! = Z q ( x `,s ) ` 6 = k, s =1 ..t , ( x k,s ) s =1 ..N Y ` 6 = k s = 1 ..t d ˜ ν ` ( x `,s ) Y s =1 ..N d ˜ ν k ( x k,s ) ≥ η t Z q ( x `,s ) ` 6 = k, s =1 ..t , ( x k,s ) s =1 ..N Y ` 6 = k s = 1 ..t dν ` ( x `,s ) Y s =1 ..N dν k ( x k,s ) = η t P θ A t ∩ ( \ ` 6 = k { T ` ( N ) < C log N } )! ≥ η t a t − ( K − 1) ˜ C f ( N ) > ˜ C 0 f ( n ) , where the one before last step relies on a union bound with (10) and P θ ( A t ) = a t , and the last inequalit y uses the definition of n . W e ha ve thus pro v ed that (11) holds, and thus the p olicy cannot hav e the f -upp er tailed prop erty sim ultane- ously in environmen t θ and ˜ θ . 7.3. Pr o of of The or em 4.1 Let θ b e in Θ. Consider the ev ent ξ = ∀ k ∈ { 1 , . . . , K } , T ∈ { 1 , . . . , n } , T k ˆ F k,T − F ν k k 2 ∞ < β + 1 2 log n . F rom Massart’s inequality (see [20]) applied nK times corresp onding to the differen t times and arms and a union b ound to com bine the inequalities, we ha ve P θ ( ξ ) ≥ 1 − nK (2 e − ( β +1) log n ) = 1 − 2 K n β . W e sho w that on the ev en t ξ , inequalities T k ( n ) ≤ 2( β +1) log n δ 2 k + 1 hold for an y k 6 = k ∗ , where δ k = min ˜ θ ∈ Θ k k F ν k − F ˜ ν k k ∞ . Note that δ k > 0: if not, it would mean that k is sub optimal in θ and optimal in an other environmen t ˜ θ , with ν k = ˜ ν k . In this case, by hypothesis there exists ` 6 = k such that d ˜ ν ` dν ` ( X `, 1 ) = 0 P θ -a.s. Th us ˜ θ is almost surely remo v ed during the first rounds of the p olicy and, as Θ is finite, all of these problematic ˜ θ are remov ed almost surely . Note also that θ cannot be remo v ed: it is readily seen that P θ dν ` d ˜ ν ` ( X `, 1 ) > 0 = 1 for all ˜ θ ∈ Θ and, still b ecause Θ is finite, it is almost sure that dν ` d ˜ ν ` ( X `, 1 ) > 0 for all ˜ θ ∈ Θ. A last consequence of the finiteness of Θ is that terms δ k are 26 uniformly bounded aw a y from zero o v er Θ, and so are the terms ∆ k , so that the inequalities we are going to prov e eas ily lead to the conclusion of the pro of. Assume by contradiction that there exists k 6 = k ∗ suc h that T k ( n ) > 2( β +1) log n δ 2 k + 1. Then there exists t ≤ n suc h that I t = k and T k ( t − 1) > 2( β +1) log n δ 2 k . As arm k is c hosen at round t , we hav e: T k ∗ ( t − 1) inf ˜ θ ∈ Θ k ∗ k ˆ F k ∗ ,T ∗ k ( t − 1) − F ˜ ν k ∗ k 2 ∞ ≥ T k ( t − 1) inf ˜ θ ∈ Θ k k ˆ F k,T k ( t − 1) − F ˜ ν k k 2 ∞ On the one hand, w e ha ve: β + 1 2 log n > T k ∗ ( t − 1) inf ˜ θ ∈ Θ k ∗ k ˆ F k ∗ ,T ∗ k ( t − 1) − F ˜ ν k ∗ k 2 ∞ , and on the other hand p T k ( t − 1) inf ˜ θ ∈ Θ k k ˆ F k,T k ( t − 1) − F ˜ ν k k ∞ ≥ p T k ( t − 1) δ k − k ˆ F k,T k ( t − 1) − F ν k k ∞ ≥ p T k ( t − 1) δ k − s ( β + 1) log n 2 T k ( t − 1) ! = p T k ( t − 1) δ k − r β + 1 2 log n. By com bining the former inequalities, w e get: r β + 1 2 log n > p T k ( t − 1) δ k − r β + 1 2 log n and T k ( t − 1) < 2( β + 1) log n δ 2 k , whic h is the contradiction exp ected. 7.4. Pr o of of The or em 4.2 The pro of of the first part of the theorem is the same as the previous section 7.3, except that one has to substitute δ k b y d k and that the d k ( k 6 = k ∗ ) are not necessarily non negativ e. Indeed, the distance k ˆ F k,T − F ν k k ∞ equals | ˆ X k,T − µ k | in the context of Bernoulli la ws. The proof of the second part is similar to the one of Theorem 3.3: we assume b y con tradiction that there exists a policy such that ∃ C, ˜ C > 0 , ∀ θ ∈ Θ , ∀ n ≥ 2 , ∀ k 6 = k ∗ , P θ ( T k ( n ) ≥ C log n ) ≤ ˜ C f ( n ) . 27 The main difference is that we cannot fix θ, ˜ θ such that θ ∈ Θ k , ˜ θ ∈ Θ r Θ k and µ k = ˜ µ k . The hypothesis only allows us to take µ k and ˜ µ k arbitrarily close. This means that w e are allow ed to consider t wo sequences ( θ n ) n ≥ 1 and ( ˜ θ n ) n ≥ 1 suc h that, for all n ≥ 1 (with obvious notations): • θ n ∈ Θ k , ˜ θ n ∈ Θ r Θ k , • ˜ µ n k ≥ 2 − 1 N µ n k , • 1 − ˜ µ n k ≥ 2 − 1 N (1 − µ n k ) , where N = b 4 C log n c . On the other hand, the hypothesis readily implies that ∀ θ , ˜ θ ∈ Θ , ∀ ` ∈ { 1 , · · · , K } , d ˜ ν ` dν ` (1) = ˜ µ l µ l ≥ γ and P θ Y ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) ≥ γ K − 1 ≥ P θ \ ` 6 = k d ˜ ν ` dν ` ( X `, 1 ) ≥ γ = Y ` 6 = k P θ d ˜ ν ` dν ` ( X `, 1 ) ≥ γ ≥ Y ` 6 = k P θ ( X `, 1 = 1) = Y ` 6 = k µ l ≥ γ K − 1 . Let us denote a = γ K − 1 and A t = T t s =1 n Q ` 6 = k d ˜ ν ` dν ` ( X `,s ) ≥ a o . By indep en- dence, w e ha v e P θ ( A t ) = a t . T o find a contradiction, w e set t = b C log N c and we adapt the reasoning of the former pro of. If n is chosen large enough, one has N < n and C log N < N 2 K , and then: P ˜ θ n ( T k ( n ) ≥ C log n ) ≥ P ˜ θ n T k ( N ) ≥ N 2 ≥ P ˜ θ n \ ` 6 = k T ` ( N ) ≤ N 2 K ≥ P ˜ θ n \ ` 6 = k { T ` ( N ) < C log N } . ≥ P ˜ θ n A t ∩ \ ` 6 = k { T ` ( N ) < C log N } . Let us denote B N = T ` 6 = k { T ` ( N ) < C log N } . B N is measurable w.r.t. X k, 1 , . . . , X k,N and X `, 1 , . . . , X `,t ( ` 6 = k ), and A t is measurable w.r.t. X `, 1 , . . . , X `,t ( ` 6 = k ), 28 so that we can write 1 A t ∩ B N = c t,N (( X `,s ) ` 6 = k, s =1 ..t , ( X k,s ) s =1 ..N ) . By properties of ˜ ν n k and ν n k and b y definition of A t w e ha ve P ˜ θ n A t ∩ \ ` 6 = k { T ` ( N ) < C log N } = Z c t,N (( x `,s ) ` 6 = k, s =1 ..t , ( x k,s ) s =1 ..N ) Y ` 6 = k s = 1 ..t d ˜ ν n ` ( x `,s ) Y s =1 ..N d ˜ ν n k ( x k,s ) ≥ Z c t,N (( x `,s ) ` 6 = k, s =1 ..t , ( x k,s ) s =1 ..N ) a t Y ` 6 = k s = 1 ..t dν n ` ( x `,s ) Y s =1 ..N 2 − 1 N dν n k ( x k,s ) = a t 2 P θ n A t ∩ \ ` 6 = k { T ` ( N ) < C log N } ≥ a t 2 a t − ( K − 1) ˜ C f ( N ) ! . By straightforw ard calculations, one can then show that f ( n ) P ˜ θ n ( T k ( n ) ≥ C log n ) − − − − − → N → + ∞ + ∞ , whic h is the contradiction exp ected. 7.5. Pr o of of The or em 4.3 The pro of is similar the one of Theorem 4.1, except that we use Ho effding’s inequalit y rather than Massart’s one. Consider the even t ξ = ∀ k ∈ { 1 , . . . , K } , s ∈ { 1 , . . . , n } , s ( ˆ X k,s − µ k ) 2 < β + 1 2 log n . F rom Hoeffding’s inequality applied 2 nK times corresp onding to the differen t times and arms and a union b ound to combine the inequalities, we hav e P ( ξ ) ≥ 1 − 2 nK e − ( β +1) log n = 1 − 2 K n β . W e will pro ve b y contradiction that on the even t ξ , w e hav e T k ( n ) ≤ 1 + 2( β +1) log n ∆ 2 k for all k 6 = k ∗ . F or this, consider k 6 = k ∗ suc h that T k ( n ) > 2( β +1) log n ∆ 2 k + 1 . Then there exists t ≤ n suc h that I t = k and T k ( t − 1) > 2( β +1) log n ∆ 2 k . Since the arm k is c hosen at time t , it means that T k ( t − 1) µ ∗ − ˆ X k,T k ( t − 1) 2 + ≤ T k ∗ ( t − 1) µ ∗ − ˆ X k ∗ ,T k ∗ ( t − 1) 2 + . (12) Let us split the proof into tw o cases. First case: ˆ X k,T k ( t − 1) ≥ µ ∗ . Then ˆ X k,T k ( t − 1) − µ k ≥ ∆ k and T k ( t − 1) ˆ X k,T k ( t − 1) − µ k 2 ≥ T k ( t − 1)∆ 2 k . The 29 con tradiction readily comes from the definition of ξ . Second case: ˆ X k,T k ( t − 1) < µ ∗ . F rom inequalit y (12) one has ˆ X k ∗ ,T k ∗ ( t − 1) < µ ∗ , and (12) can be written as: T k ( t − 1) ˆ X k,T k ( t − 1) − µ ∗ 2 ≤ T k ∗ ( t − 1) ˆ X k ∗ ,T k ∗ ( t − 1) − µ ∗ 2 . On the one hand, w e ha ve: β + 1 2 log n > T k ∗ ( t − 1) ˆ X k ∗ ,T k ∗ ( t − 1) − µ ∗ 2 , and on the other hand p T k ( t − 1) ˆ X k,T k ( t − 1) − µ ∗ ≥ p T k ( t − 1) ∆ k − ˆ X k,T k ( t − 1) − µ k ≥ p T k ( t − 1) ∆ k − s ( β + 1) log n 2 T k ( t − 1) ! = p T k ( t − 1)∆ k − r β + 1 2 log n. The former inequalities leads to r β + 1 2 log n > p T k ( t − 1)∆ k − r β + 1 2 log n ⇒ T k ( t − 1) < 2( β + 1) log n ∆ 2 k . Th us there is a contradiction, meaning that there is no k such that T k ( n ) > 2( β +1) log n ∆ 2 k + 1 . 7.6. Pr o of of The or em 5.1 W e assume by con tradiction that there exists a f -w T p olicy . As in the pro of of Theorem 3.3, on can remov e the ∆ 2 k denominator, so that we hav e: ∃ C, ˜ C > 0 , ∀ n ≥ 2 , ∀ ` 6 = k , P θ T ` ( n ) ≥ C log n ≤ ˜ C f ( n ) . Let us sho w that this implies that the p olicy cannot hav e also the f -upp er tailed prop ert y in ˜ θ . T o pro ve the latter, it is enough to show that for any C 0 , ˜ C 0 > 0 ∃ n ≥ 2 , P ˜ θ T k ( n ) ≥ C 0 log n > ˜ C 0 f ( n ) , (13) since k is sub optimal in environmen t ˜ θ . Similarly to the pro of of theorem 3.3, proving (13) for C 0 = C is sufficient. Moreo ver, there exists η ∈ (0 , 1) suc h that the ev ent A = n Q K ` =1 d ˜ ν ` dν ` ( X `, 1 ) ≥ η o 30 has probabilit y a > 0 under P θ . W e denote A t = ∩ s =1 ...t n Q K ` =1 d ˜ ν ` dν ` ( X `,s ) ≥ η o , and b y independence we hav e P θ ( A t ) = a t . Let us set N = d K C log n e , choose n large enough so that n > N , and denote Y a r.v. that equals the index of an arm among those that hav e b een pulled the most after time step N , e.g. Y = min argmax l ∈{ 1 ,...,K } T l ( N ) . Obviously , such an arm has b een pulled at least C log n at step N (i.e. T Y ( N ) ≥ C log n a.s.), so that one has: P ˜ θ ( T k ( n ) ≥ C log n ) ≥ P ˜ θ ( T k ( N ) ≥ C log n ) ≥ P ˜ θ ( Y = k ) ≥ P ˜ θ ( A N ∩ { Y = k } ) . In tro duce the function q such that 1 A N ∩{ Y = k } = q ( X `,s ) 1 ≤ ` ≤ K, s =1 ..N . One has: P ˜ θ ( A N ∩ { Y = k } ) = Z q ( x `,s ) 1 ≤ ` ≤ K, s =1 ..N , ( x k,s ) s =1 ..N Y 1 ≤ ` ≤ K s = 1 ..N d ˜ ν ` ( x `,s ) ≥ η N Z q ( x `,s ) 1 ≤ ` ≤ K, s =1 ..N , ( x k,s ) s =1 ..N Y 1 ≤ ` ≤ K s = 1 ..N dν ` ( x `,s ) = η N P θ ( A N ∩ { Y = k } ) ≥ η N ( P θ ( A N ) − P θ ( Y 6 = k )) ≥ η N a N − η N P θ ( ∃ l 6 = k , T l ( N ) ≥ C log n ) ≥ η N a N − η N P θ ( ∃ l 6 = k , T l ( n ) ≥ C log n ) ≥ ( η a ) N − η N ( K − 1) ˜ C f ( n ) . As N is of order log n , it is then readily seen that f ( n ) P ˜ θ ( T k ( n ) ≥ C log n ) − − − − − → n → + ∞ + ∞ , hence the result. References [1] R. Agraw al. Sample mean based index p olicies with o(log n) regret for the multi-armed bandit problem. A dvanc es in Applie d Mathematics , 27: 1054–1078, 1995. [2] J.-Y. Audib ert, R. Munos, and C. Szep esv´ ari. Exploration-exploitation tradeoff using v ariance estimates in m ulti-armed bandits. The or etic al Com- puter Scienc e , 410(19):1876–1902, 2009. [3] P . Auer, N. Cesa-Bianchi, and P . Fisc her. Finite-time analysis of the mul- tiarmed bandit problem. Mach. L e arn. , 47(2-3):235–256, 2002. 31 [4] M. Babaioff, Y. Sharma, and A. Slivkins. Characterizing truthful multi- armed bandit mec hanisms: extended abstract. In Pr o c e e dings of the tenth A CM c onfer enc e on Ele ctr onic c ommer c e , pages 79–88. ACM, 2009. [5] D. Bergemann and J. V alimaki. Bandit problems. 2008. In The New P algrav e Dictionary of Economics, 2nd ed. Macmillan Press. [6] S. Bub eck, R. Munos, G. Stoltz, and C. Szep esv ari. Online optimization in X-armed bandits. In A dvanc es in Neur al Information Pr o c essing Systems 21 , pages 201–208. 2009. [7] A.N. Burnetas and M.N. Katehakis. Optimal adaptive p olicies for sequen- tial allo cation problems. A dvanc es in Applie d Mathematics , 17(2):122–142, 1996. [8] P .A. Co quelin and R. Munos. Bandit algorithms for tree searc h. In Unc er- tainty in Artificial Intel ligenc e , 2007. [9] N.R. Dev an ur and S.M. Kak ade. The price of truthfulness for pay-per- clic k auctions. In Pr o c e e dings of the tenth ACM c onfer enc e on Ele ctr onic c ommer c e , pages 99–106. A CM, 2009. [10] A. Garivier and O. Capp ´ e. The kl-ucb algorithm for b ounded stochastic bandits and b ey ond. Arxiv pr eprint arXiv:1102.2490 , 2011. [11] S. Gelly and Y. W ang. Exploration exploitation in go: UCT for Monte- Carlo go. In Online tr ading b etwe en explor ation and exploitation Workshop, Twentieth Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS 2006) , 2006. [12] J.H. Holland. A daptation in natur al and artificial systems . MIT press Cam bridge, MA, 1992. [13] J. Honda and A. T akem ura. An asymptotically optimal bandit algorithm for b ounded supp ort mo dels. In Pr o c e e dings of the Twenty-Thir d Annual Confer enc e on L e arning The ory (COL T) , 2010. [14] R. Kleinberg, A. Slivkins, and E. Upfal. Multi-armed bandits in metric spaces. In Pr o c e e dings of the 40th annual ACM symp osium on The ory of c omputing , pages 681–690, 2008. [15] R. D. Kleinberg. Nearly tigh t b ounds for the contin uum-armed bandit problem. In A dvanc es in Neur al Information Pr o c essing Systems 17 , pages 697–704. 2005. [16] L. Ko csis and Cs. Szep esv´ ari. Bandit based Monte-Carlo planning. In Pr o c e e dings of the 17th Eur op e an Confer enc e on Machine L e arning (ECML- 2006) , pages 282–293, 2006. [17] T. L. Lai and H. Robbins. Asymptotically efficient adaptive allo cation rules. A dvanc es in Applie d Mathematics , 6:4–22, 1985. 32 [18] D. Lamberton, G. Pag ` es, and P . T arr` es. When can the tw o-armed bandit algorithm b e trusted? A nnals of Applie d Pr ob ability , 14(3):1424–1454, 2004. [19] O.A. Maillard, R. Munos, and G. Stoltz. A finite-time analysis of m ulti- armed bandits problems with kullback-leibler divergences. A rxiv pr eprint arXiv:1105.5820 , 2011. [20] P . Massart. The tight constant in the Dvoretzky-Kiefer-W olfo witz inequal- it y . The Annals of Pr ob ability , 18(3):1269–1283, 1990. [21] H. Robbins. Some asp ects of the sequential design of exp eriments. Bul letin of the Americ an Mathematics So ciety , 58:527–535, 1952. [22] W. Rudin. R e al and c omplex analysis (3r d) . New Y ork: McGraw-Hill Inc, 1986. [23] R. S. Sutton and A. G. Barto. R einfor c ement L e arning: A n Intr o duction . MIT Press, 1998. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment