언제든지 적용 가능한 밴딧 정책의 강건성 한계와 설계
본 논문은 총 라운드 수를 사전에 알 수 없는 ‘anytime’ 밴딧 정책이 고확률(1‑1/n)로 로그 수준의 후회를 보장할 수 없음을 증명하고, 특정 분포 제약 하에서는 이러한 강건성을 달성할 수 있는 정책을 제시한다.
저자: Antoine Salomon, Jean-Yves Audibert
본 논문은 확률적 다중 팔 밴딧 문제에서 후회의 상위 꼬리(upper‑tail) 특성을 중심으로 “anytime”(라운드 수를 사전에 알 수 없는) 정책과 “horizon‑aware”(라운드 수를 미리 아는) 정책의 차이를 체계적으로 분석한다.
1. **배경 및 동기**
기존 연구(Audibert et al., 2009)는 총 라운드 수 n을 알고 있을 때, 후회 Rₙ이 log n 수준으로 1‑1/n 확률 이하로 집중된 정책을 제시했으며, 이는 ucb1과 같은 전통적인 anytime 정책이 갖지 못하는 특성이다. 실제 응용에서는 라운드 수가 사전에 정해지지 않은 경우가 많아 언제든지 적용 가능한 정책의 강건성(robustness)이 중요한 문제로 떠오른다.
2. **문제 설정 및 정의**
K개의 팔을 가진 밴딧 환경을 θ=(ν₁,…,ν_K)로 정의하고, 각 팔의 평균 보상 μ_k와 최적 평균 μ*를 도입한다. 후회는 Rₙ = nμ* – Σ_{t=1}^n X_{I_t,t} 로 정의한다. 후회의 기대값은 전통적으로 O(log n)이며, 논문은 이 기대값을 넘어서는 큰 편차가 얼마나 자주 발생하는지를 확률적으로 분석한다. 이를 위해 f‑T, f‑R, f‑wT, f‑wR이라는 네 가지 상위 꼬리 개념을 정의한다. f‑T는 모든 환경에 대해 일정 상수 C, C̃가 존재해 P(T_k(n) ≥ C·log n/Δ_k²) ≤ C̃·f(n) 를 만족하는 경우이며, f‑R는 후회에 대해 유사한 형태의 부등식을 의미한다. 약한 형태인 f‑wT, f‑wR는 상수 C, C̃가 환경에 의존하도록 허용한다.
3. **기존 정책과 그 특성**
- **UCB1**: ρ=1인 경우 log³‑T, log³‑R (f(x)=log³(x))를 만족한다. ρ>½이면 log^{2ρ‑1}‑T, log^{2ρ‑1}‑R를 달성한다.
- **UCB‑h**(horizon‑aware): n‑T, n‑R를 만족한다. 즉, 라운드 수 n을 알면 후회가 log n 수준으로 매우 높은 확률(1‑1/n)로 집중된다.
4. **부정 결과 (Impossibility)**
Theorem 3.3은 다음 조건을 만족하는 두 환경 θ와 θ̃, 그리고 팔 k가 존재하면 어떤 f‑wT 혹은 f‑wR anytime 정책도 존재하지 않음을 증명한다.
(a) ν_k = ν̃_k (팔 k의 보상 분포가 동일)
(b) θ에서는 k가 최적이지만 θ̃에서는 최적이 아니다.
(c) 다른 모든 팔 `≠k에 대해, θ̃에서 관측된 보상이 dν_/dν̃_(X_{`,1})>0인 사건이 양의 확률로 발생한다.
이 조건은 에이전트가 관측만으로 두 환경을 구분하기 어려워, 최적 팔을 오판할 위험이 일정 확률로 남는 상황을 만든다. 따라서 어떤 다항식 이하의 f에 대해서도 f‑wT, f‑R를 만족하는 anytime 정책은 존재하지 않는다. 이는 “anytime” 정책이 고확률 로그 후회를 보장할 수 없다는 강력한 한계이다.
5. **긍정적 설계 결과**
제한된 사전 지식이 주어질 때는 강건 정책을 설계할 수 있다.
- **최적 평균 μ\* 알려짐**: Theorem 4.3은 μ\*를 알고 있으면, 탐색 단계에서 각 팔의 평균이 μ\*보다 크게 차이 나는 경우를 빠르게 배제하고, 남은 팔에 대해 집중 탐색함으로써 언제든지 적용 가능한 f‑R 정책을 구현할 수 있음을 보인다.
- **후회의 상위 꼬리 한계**: Corollary 5.2는 라운드 수를 미리 알더라도, 후회가 1‑1/n보다 훨씬 높은 확률로 log n 이하에 머무르는 것은 불가능함을 증명한다. 즉, Audibert et al.의 정책이 이론적으로 최적임을 확인한다.
6. **실험**
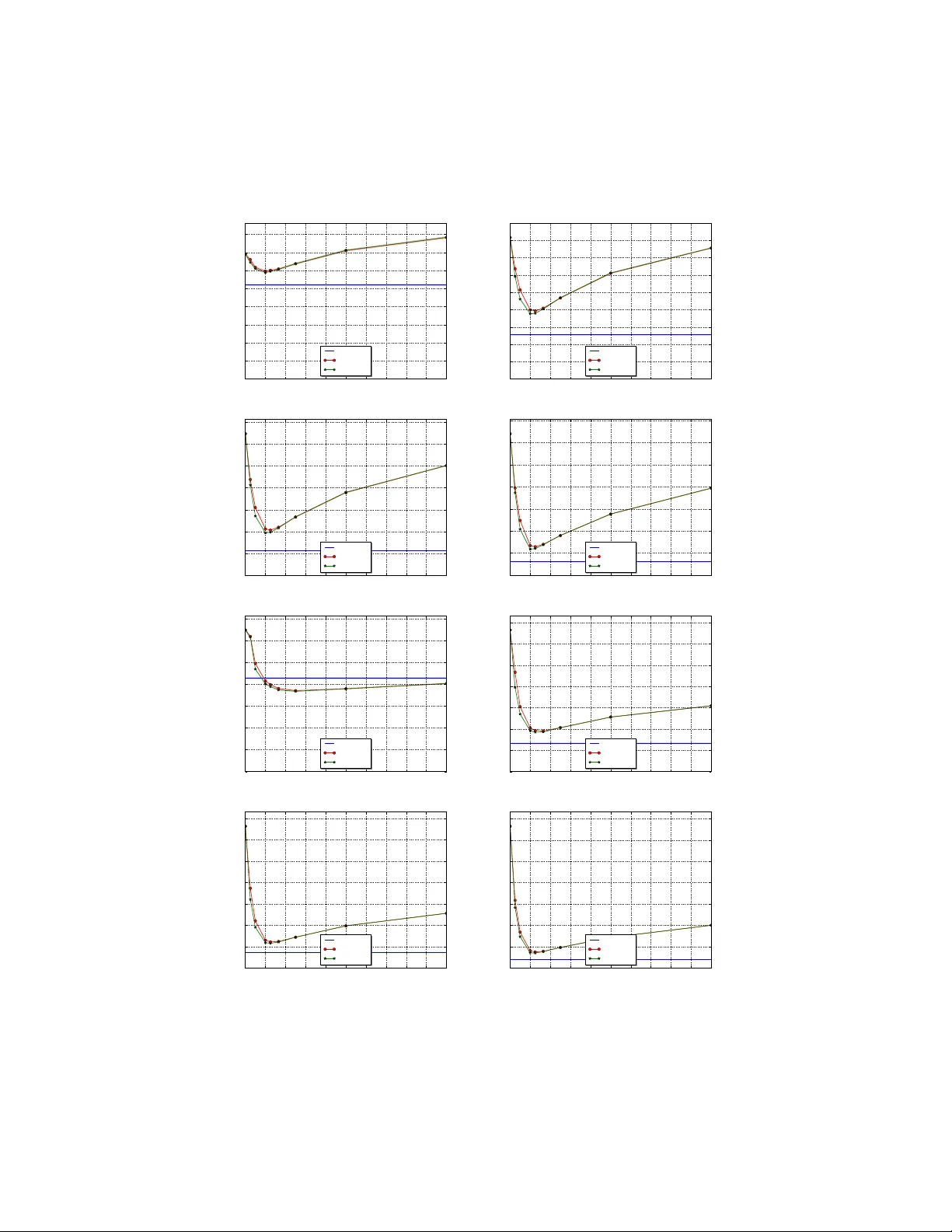
논문은 제안된 강건 정책과 전통적인 UCB1, UCB‑h를 다양한 시뮬레이션 환경에서 비교한다. 특히 μ\*를 사전에 제공받은 경우, 제안 정책은 후회의 상위 꼬리(예: 95% 신뢰구간)에서 현저히 낮은 값을 보이며, 평균 후회 역시 log n 수준을 유지한다. 반면, UCB1은 높은 확률로 로그보다 큰 편차를 보인다.
7. **결론 및 의의**
- 언제든지 적용 가능한 정책은 일반적인 환경(보상이
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기