Diagonal Based Feature Extraction for Handwritten Alphabets Recognition System using Neural Network
An off-line handwritten alphabetical character recognition system using multilayer feed forward neural network is described in the paper. A new method, called, diagonal based feature extraction is introduced for extracting the features of the handwri…
Authors: J. Pradeep, E. Srinivasan, S. Himavathi
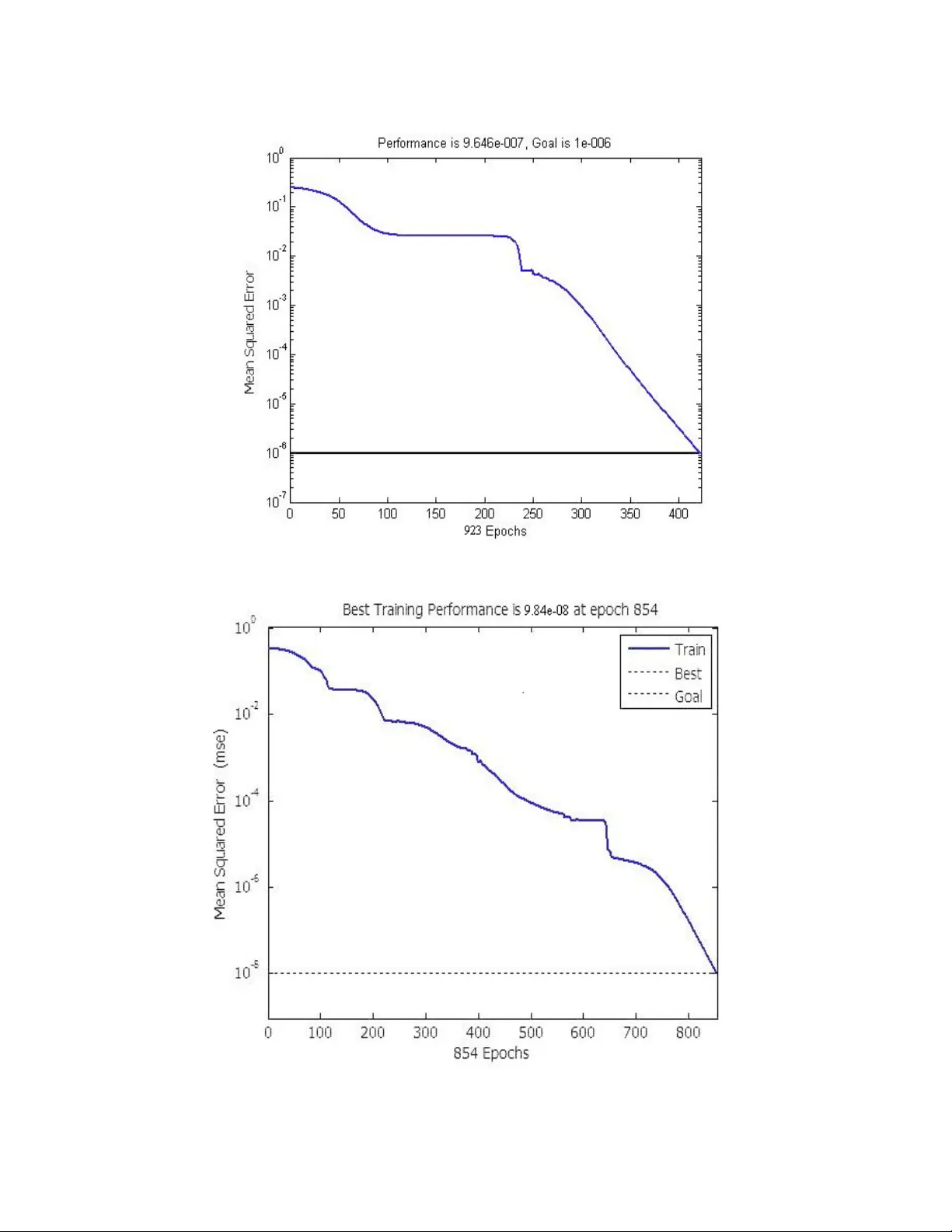
International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 DOI : 10.512 1/ijcsit.201 1.3103 27 D IAGONAL BA SED F EATURE E XTRACTION FOR HANDWRITTEN A LPHABE TS R ECOGNI TION S YSTEM US ING N EURA L N ETWO RK J.Pr adeep 1 , E.Srinivasan 2 and S.H imavathi 3 1,2 Department of EC E , Pondiche rry College Engineeri ng, Pondicherry, India. jayabala .pradeep@pec .edu, esrini vasan@pec.ed u 3 Department of EEE, P ondich erry College Eng inee ring , Pondic herry , India. himavath i@pec.edu A BSTRACT An off-line handwritten alphabetical character recognitio n system using multilayer feed forward n eural network is descri bed i n t he paper. A new method, called, di agonal based feature extrac tion i s introduced for extracti ng the features of the handwritten al phabets. Fifty dat a se ts, e ach containing 2 6 al phabets written by v arious people, a re used for tr aining the neural netw ork and 570 different h andwritten alphabetica l characters are use d for testin g. The proposed recog n ition syste m pe rforms quite well yielding higher levels of recognition accuracy compared to the systems employi ng the conventional horizont al and vertical methods of feature extraction. This system will be suita ble for co nvert in g handwritte n documents into structural text form and recognizing handwritten names . K EYWORDS Handwri tten character recogni tion, Image proce ssing, Feature extraction, feed fo rward neural net works. 1. I NTRODUC TION Handwriting recognition h as been one of the m o s t fascinati ng and challenging research areas in field of image processing a nd pattern recognition in the rece nt years [1] [2]. It contributes immensely to the advancement o f an au tomation proce ss a nd can improve t he interface between man and m a chine in numerous applications. Severa l research wo rks have been focusing on new techniques and methods that wou l d reduce the processing time while providi ng hi gh er recognition accuracy [3]. In general, handwriting recognition is class ified int o two type s as off-line and on-line handwriting re cognition methods. In the off-line recognition, the writing is usually ca ptured optically by a sc anner and the completed writing is available as an image. But , in the on-line system t he t wo dimensional coordinates of successive points are r epresented as a function of time a nd the order of strokes made by the writ er are also available. The on-line methods h ave been shown to be superior to their off-line counterpa rts in r ecog nizing handwritten characters due to t he temporal information available with the former [4] [5]. However, in t he off-line systems, the neural networks have been successfully used to yield comparably high recognition accuracy levels . Several applications including mail sorting, bank processing, document readin g and postal addr e ss recognition require o ff- line handwriting r ec ognition systems. As a result, the off-line handwriting recognition continues to be an active area for r e search towards exploring the newer techniques that would improve recognition accuracy [6] [7]. The first important step in any handwritten recognition system is pre-processing fol lowed b y segmentation a nd feature extraction. Pre- processing in cludes the steps that are r equired t o sha pe the i nput image into a form suitabl e f or segmentation [8 ]. In t he segmenta tio n, the input image is segmented into individual characters and t he n, each character is r es ized i nto m x n pi x els towards the training network. International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 28 The Selection of appropriate feature extraction method i s prob a bly the single most important factor in achieving high recognition performance. Several methods of feature extrac tion for character recognition h a ve be en report e d in the literature [9]. The widely used feature extraction methods are Template m atching, De formable templates, Unitary Image transforms, Graph description, Projection Hi s tograms, Contour profiles, Zoning, Geometric mom ent invariants, Zernike Moments, Spl ine curve approximation, Fourier descriptors, Gradient feature and G a bor features. An arti ficial neural Network as the b a ckend is u sed for performing classification and recognition tasks. In the o ff-line r ec ognition system, the neural n etworks have emerged as the fast and reliable tools for classification towards achieving hi gh recognition acc urac y [10]. Classification techniques have been a ppli e d to handwritten charac ter re cognition since the 1990s. These methods include statistical methods based on Bayes decision rul e , Artifi c ial Neural N etworks (ANNs), Kernel M ethods including Support Vector Machines ( SVM) and multiple classifier combination [11], [12 ]. U. Pal et al , have proposed a modifi e d quadratic classifier based scheme t o recognize the o ff- line handwritten numerals of six popular Indian scripts [7]. Multilayer perceptron has been u sed for recognizing Handwritten English characters [13] .The features are extracted from Bou ndary tr a cing and their Fourier Des cripto rs . Character is identified by analysing its shape and comparing its fea t ures th at distinguish each character. Al so an analysis has been carried out to determine the number of hidden layer nodes to achieve high performance of back propagati on network. A recog nit ion accu racy of 94% has been reported for handwritten English characters with less training time. Dinesh et al [14] have us ed horizontal/vertical strokes, and end poin ts as the potential features for recognition and reported a r e cognition accuracy of 90.50% for handwr i tten Kannada num e rals. However, this method uses the thinning process which results in the loss of features. U. Pal et al [15] have proposed zoning and dir ec tional chain code fe a tures and considered a feature vector of length 100 fo r handwritten numeral recognition a nd have r e ported a hi gh level of recognition accuracy. However, the f e ature extraction process is complex and ti me consuming. In t his paper, a diagonal feature extraction scheme for the r ecog nizing off-line handwritt en characters is propose d. In the feature extraction process, res ized individual c haracter of size 90x 60 pixels is further divided into 54 equal zones, e ach of size 10x10 pixels. The fe atures are extracted from the pixels of each zone b y moving along their diagonals. This procedure is repeated for all the zones leading to extracti on of 54 features for each character. These extracted features are used to train a fe e d forward back pr opaga tion neural network em ployed for performing class ification and recognition t as ks. Extensive simulation studies show tha t the recognition system using diagonal features p rovides good recognition acc uracy while requiring less time for training. The paper i s or ganized as follows. In section II, t he proposed recognition system is p resented. The feature extraction procedure adopted in the system is detailed in th e section III. Section IV describes the classification and recognition using feed f orward back pr opagation neural network. Section V pre se nts th e e xpe rimental results and comparative analysis. In sectio n VI, the pro posed re cog niti on system in Graphical User Interface is presented and fi na lly, the paper is concluded in section VII . International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 29 2. T HE P ROPOSED R ECOG NIT IO N S YSTEM In this section, the proposed recognition sys tem is described. A t y pical handwriting recognition system consists of pre-processing , segmentation, feature extraction, classifica tion and recognition, and p ost processing stages. The schematic diagram of the pr opos ed recognitio n system is shown in F ig.1 2.1. I m age Acquisition In Image acquisiti on, the recognition system acquires a scanned image as an i nput image. The image s hould have a specific for mat such as JPEG, BMT etc. This image is acquir ed through a scanner, digital camera or any other suitable digital input device . 2.2. Pre -processing The pre-processing is a s e ries of operations performed on t he scanned in put image. It essentially enhances the image rendering it suitable for segmentation. The various tasks performed on the image in pre-processing sta g e are shown in Fig.2. B inarization process converts a gray scale image into a binary i mage us in g global thresholding technique. Detec tio n of edges in th e binarized i mage using sobel technique, dilation the image and filling the ho les present i n it are the op e rations p e rf orme d in the last two st a ges t o produce the pre-processed i mage suitable fo r segmentation [16]. Fig ure 1. Schematic di agram of the proposed recognition sy ste m International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 30 Figure 2. Pre-process ing of handwritten character 2.3. Seg m entation In the segmentation stage, an image of sequence of ch aracters is decomposed into sub-images of individual character. In t he prop ose d system, t he pre- proce ssed in put image i s s egme nted into isolated characters by assigning a number to each character using a labelling process. This labelling pr ov ides inf o rmation about number of characters in the image. Each i ndividual character is uniformly resize d into 90X60 pixels for class ification and recognition stage. 3. P ROPOSED F EATURE E XTRACTION M ETHOD In th is stage, the features o f the characters that are crucial for classifying th em at recognition stage are extracted. This is an important stage as i ts effective functioning improves the recognition rate and r educes t he misclassification [17]. D iag onal feature extraction scheme for recognizing off-line handwritten characters is proposed in this work . Every character image of size 90x 60 pixels is di vide d int o 54 equal zon e s, each o f si ze 10x10 pixels ( Fig .3(c)). The features are extracted from each zone pixels by moving along t he d iagona ls of its respective 10X10 pixels. E ach zone has19 diagonal l ine s and the foreground pixels p resent long each diagonal li ne is summed to get a single sub-feature, thus 19 sub-features are obtained from t he each zone. These 19 sub-features values are averaged to f orm a single feature value and placed in the corresponding zone ( F ig.3 (b)). This procedure i s sequentially repeated for t he all the zones. Th ere could be some zones whose diagonals are empty of fo regrou nd pixels. The feature values corresp ondi ng to these zo nes are zero. Finally, 54 f e atures are extracted for each character. In additi on , 9 and 6 features ar e obtained by averaging t he values p laced in zones rowwise and columnwise, respectively . A s re sult, every character is represented by 69, that is, 54 +15 features. International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 31 Figure 3 . Procedure for extracting feature from the cha racters 4. C LASSIFICATIO N AND R ECOGNITION The classification stage is the decision making part of a recognition system and it uses the features extracted in the previous stage. A feed forward back propagation neural network having two hidden layers with architecture of 54-100-100-38 is used t o perform the classification. The hidden lay ers u se log sigmoid activation f u nction, and the out put laye r is a competitive l a yer, as one of the characters i s to be i dent ified. The feature vector is denoted as X where X = ( f 1 , f 2 ,…, f d ) where f de notes f eatures an d d is the number of zones into wh ich eac h cha racter is di vide d. The n umber of i nput neurons is determined by len gth of t he f eatu re vector d. The total nu mbe rs of characters n determines the numb er of neurons in the output lay er. The numbe r of neurons i n the hid den layers is o btained by tri al and error . The most compac t network is chosen and presented . The network training parameters are : Input nodes : 54/69 Hidden nodes : 100 each Output nodes :38 (26 alphabets, 10 numera ls and 2 special symbols) Training algorithm : Gradient descent with momentum training and adaptive learning Perfor m function :Mean Square Error Training goal achieved : 0.000001 Training epochs :1000000 Training momentum constant: 0.9. International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 32 Figure 4. Three layer neur al ne twork for character recognition The architecture of th e network with two layers is i llustrated in fig. 4. The outp ut of th i layer is given by ) ( log 1 i i i i b a w sig a + = − (1) where, ] 3 , 2 , 1 [ = i and Ρ = 0 a i w = Weight vec tor of th i layer i a = Output of th i layer i b = Bias vec tor for th i layer 5. R ESULTS AN D D ISCUSSION The recognition system ha s be e n impl e mented using Matlab7.1.The sc anned im age is taken as dataset/ i nput and fee d forward architecture is used. The structure of neural n etw ork includes an input layer wi th 54/69 in pu ts, two hidden layers each with 100 neurons and an output l a yer wit h 26 neurons. The gradient descent back propagation method with mome ntum and adaptive learning rate and lo g- sigmoid transfer functions is used fo r neural network training. Neural network has been t ra ined using known dataset. A recognition system using two different feature International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 33 lengths is built. The number of input nodes is chosen b a sed on the number of features. A fter training the network, the recognition sys tem was t e sted using several unkn own dataset and the results obtained are presente d in this section. Two approaches wit h t hr ee di fferent ways of feature extraction are u se d f or characte r recognition in the proposed system. The three dif fe rent ways of f e ature e xtraction are horizontal direction, vertical direction a nd diagonal direction . In th e f irst approach, the feature vector size is chosen as 54, i.e. with out rowwise and columnwise features. The res ults o btaine d u sing thr ee dif fe rent types of featur e extraction are summarized in Table. I. The criteria f or choosing the type of feature extraction a re: ( i) the speed of convergence, i.e. number o f epochs required to achieve t he tr a ining goal and ( ii) tr a ining stability. H owe ver, the most important parameter of i nterest is th e accuracy of the recognition system. The results p resented in Table 1 show that the diagonal feat ure extraction yields good recognition acc uracy co mpare d to the ot hers types of feature extraction. Fig.5.shows the Er ror (MSE) vs. Training Epochs performance function of the network with 5 4 features obtained though diagonal extraction. The desired pe rformance goal has been achieved in 923 epochs . In t he second approach, the feature vector size i s chosen as 6 9 including the rowwise and columnwise f e atures. The r esults obtained for the second approac h is also presented in T a ble. II and i t shows t hat the diagonal feature extraction pr ov ides hi g her recognition accuracy, compared to the others types of feature extraction. Fig.6. shows the E rror (MSE) vs. Tr a inin g Epochs performance of the network with 69 f e atures obt a ined t hough diagonal extraction. It can be noted that it requires 854 ep ochs to reduce the mean square error to the de sired level. TABLE . I COMPARISON OF RECOGNITION RATE RESULTS OBTAINED USING DIFFERENT ORIENTATI ONS WITH 54 FEATURES Networks 1 2 3 Feature Extraction type Vertical Horizontal Diagonal Number of nodes in input layer 54 54 54 Number of nodes in 1st hidden layer 100 100 100 Number of nodes in 2st hidden layer 100 100 100 Number of nodes in output layer 26 26 26 Recognition rate percentage 92.69 93.68 97.80 International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 34 Figure 5 . The va riation of MSE with training Epochs for 54 features Figure 6. The varia tion of MSE with training Epochs for 69 features International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 35 6. I MPLEME NTATION ON G RAPHICAL U SER I NTERFAC E A user-friendly f ront end interface as shown in Fig.7 and Fig.8 has been implemented for the proposed handwritten character recognition s ystem u sing menu b ased GU I (G raphica l User Interface). The int e rface system presents the user with two menus - first me nu wit h five processing stages (Fig.7) and the se cond menu to choose the type feature extraction (Fig.8). Figure 7. Recognition Syst em using Menu Based Graphical User Interface The menu ba se d GUI enab les t he user to perform pre-processing, select th e type of feature extraction, perform t he feature extraction using the chosen method and train the network. After TABLE.II COMPARISON OF RECOGNITION RATE RESULTS OBTAINED USING DIFFERENT ORIENTATIONS WITH 69 FEATURES Networks 1 2 3 Feature Extraction type Vertical Horizontal Diagonal Number of nodes in input layer 69 69 59 Number of nodes in 1st hidden layer 100 100 100 Number of nodes in 2st hidden layer 100 100 100 Number of nodes in output layer 26 26 26 Recognition rate percentage 92.69 94.73 98.54 International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 36 the network is trained, the r ecognition of t he test image can be i nitiated by clicking the recognition bar on the i nt erface. The test image is chosen using the facili ty provided for selecting the test images. Upon t he completion of recognition process, the recognized image appears on t he not e pad. The same pro cedure can be u se d to recogniz e any number o f test images. Finally the exit bar is used t o quit from the charac ter r e cognition system after recognizing all t he test images. The GUI frees the user from th e difficulties of worki ng f rom the command line interface. Figure 8 . Feature Extraction O ptions in Menu Based Graphical User Int erface 7. C ONCLUSION A simple off-line h a ndwritten English alphabet characters recognition system using a n ew type of feature extraction, namely, diagonal feature extraction is proposed. Two approaches usin g 54 features and 6 9 features are chosen to build the Neural Network recog nition system. To compare the recognition efficiency of the pro pose d diagonal method of f ea ture extraction, the neural network recognition s ystem is trained using the horizontal and vertical featur e extraction methods. Six different recognition n etworks are built. Experimenta l results re veals that 6 9 features g ives better recognition accuracy than 54 features fo r all the types of fea ture ex tracti on. From the test results i t is identified t ha t the di a gonal method of f e ature extraction yields the highest r ecognition acc uracy of 97.8 % for 54 features and 98.5 % fo r 6 9 features. The diagona l method of feature extraction is verifi ed u sing a number of test images. The propo se d off -line hand written character recognition system with better-qua lit y re cognition rates will be eminently suitable f or serval applications including p osta l/parcel addres s recognition, bank proecssing, document reading and co nv e rsion of any handwritten docume nt int o structural tex t form. R EFERENCES [1] S. Mori, C.Y. Suen and K. Kamamoto, “ Historical revie w of OCR research and development,” Proc . of IE EE , v ol. 80, pp. 1029-1058, July 1992. [2] S. Impedovo, L. Ottaviano and S. Occhinegro, “Optical ch aracter recognition”, International Journal Patter n Recognition and Artificial Intelligence , Vol. 5(1 -2), pp. 1-24, 1991. [3] V.K. Go v indan and A.P. Shi va prasad, “Ch arac t e r Recogniti on – A review,” Pattern Recognition, v ol. 23, no. 7, pp. 671- 683, 1 990 International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 37 [4] R. Plamondon and S. N . Srihari, “ On- line and off- line handwritten character recognition: A c omprehensive s urvey,” IEEE. Tr ansactions on Patte rn Analysis and Machine Intelligence, v ol. 22, no . 1, pp. 63-84, 2000. [5] N. Arica and F. Yarman-Vural, “An O verview of Character Recognition Focused on Off-line Handwriting”, I EEE Transactions on Systems, Man, and Cybernetics , Part C: Applications and Reviews , 2001, 31(2), pp. 216 - 233. [6] U. B ha ttacharya, and B. B . Chaudhuri, “Handwritten nu me ral database s o f Indian scripts and multistage recognition of mixed numerals,” I EEE Transaction on Pattern analysis and machine intelligence , vol.31, No.3, pp.444-457, 2009. [7] U. Pal, T. Wakabayashi and F. Kimura, “Handwritten nume ral recognition of six popular scripts,” Ninth International conference on Document Analysis and Recognition ICDAR 07, Vol.2, pp.749-753, 2007. [8] R.G. Casey and E. L ecolinet, “A Su rvey of Me thod s and Strategies in Character Segmentation,” IEEE Transactions on Pattern Analysis a nd Machine Intelligence, Vol. 18, No.7, July 1996, pp. 690-706. [9] Anil.K.Jain and Torfinn Taxt, “Feature extraction methods for character recognition-A Survey,” Pattern Recognition, vo l. 29, no. 4, pp. 641-662, 1996. [10] R.G. Casey and E. Le colinet, “A Survey of Methods and Strategies in Character Segmentation,” IEEE Transactions on Pattern Analysis a nd Machine Intelligence, Vol. 18, No.7, July 1996, pp. 690-706. [11] C. L. Liu, H. Fujisawa, “Classifi c ation and L earning for Charac ter Recognition: Comparison of Methods an d Remaining Problems”, Int. Workshop on Neural N etworks and Learning in Document Analys is and Recognition , Seoul, 2005. [12] F. Bortolozzi, A. S. Brito, Luiz S. Oliveira and M. Morita, “ Rec ent Advances in Handwritten R e cognition”, Do c ument Analys i s , Umapada P al, Swapan K. Parui, Bidyut B. Chaudhuri, pp 1-30. [13] Anita Pal & Dayashankar Singh, “Handwritten English Character Recogniti on Using Neural,” N etwork In ternational J ournal of Computer Science & Communication. v ol. 1, No. 2, July-December 2010, pp. 141-144. [14] Dinesh Acharya U, N V Subba Reddy and Krishnamurthy, “Isolated handwritten Kannada numeral recognition using structural feature and K-means cluster,” IISN-2007, pp-125 -129. [15] N. Sharma, U. P a l, F. Kimura, "Recognition o f Handwritten Kannada Numerals", 9th International Confere n c e on Information Technology (ICIT'06) , ICIT, pp. 133-136. [16] Rafael C. Gonz alez, Richard E. woods and Steven L.Eddins, Digital Image Processing using MATLAB, Pearson Education, Dorling Kinde rsley, South Asia, 2004. [17] S.V. Rajashe k a raradhya, and P.VanajaRanja n, “Efficient zone based feature extraction algorithm for handwritten numeral recognition of f o ur popular south-Indian scripts,” International J ournal of Computer Science & Informa tion Technol ogy ( IJCSIT), V ol 3, No 1, Feb 2011 38 Journal of Theoretical and Appli ed Information Technology , JATIT vol.4, no.12, pp.1171-1181, 2008. Authors J.Pradeep received his B.Tech degree i n Electronics and Communication Eng ineering fro m Barathiyar col lege of Engineering and Technogy affiliated to Pondi c herry University in the year 2005. He obtained hi s M.Tech de g ree in Electronics and Communication Engineering from Podicherry Engineering Coll ege in the year 2009. He is currently a Ph.D candida te in the Department o f Electronics and Communication Engineering in Podicherry Engineering College. He has published two papers in International Journal. He i s a life member of ISTE. His areas o f interest are Wireless Commun ica tion, Image proceesing and Neural ne t works. E.Srinivasan obt ained his B.E. degree in Electrical and E lec tronics Engineering from P. S.G. College of Technology, Co imbatore, India, in the year 1984. He recei ve d his M.E. d eg ree in I nstrumentation Technology in the year 19 87 from Madras Inst itute of Technology, Chennai, India. He w as awarded wi th Ph.D. degree by the An na University, Chennai, India in the year 2003 for his rese arch contributions in Nonlinear Signal Processing. Currentl y , he i s serving as Professor and Head of the Department of Electronics and Communica tion Engineering, Pondicherry Engineering Coll eg e, Pondicherry, Indi a . He has publi s hed 30 research papers in national/international jo u rnals/conferences. He is a reviewer of the AMSE j ournal of Signal Processing. His research interests include nonlinear signal processing and p attern recognition and their applications. S.Himavathi completed he r BE degree i n Electrical and Electronics Engineering from Colleg e of Engineering, Guindy, Chenna i, India, in the year 1984. She obtained her M.E. degree in Instrumentati on Technolog y in the year 1987 from Madras Insti tute o f Tec hnology, Chennai, India. She completed her Ph.D. degree in t he area of Fuzzy modelin g in t he year 2 003 from Anna U nive rsity, Chennai, India. She is a Professor and Head of the Department of Electrical and Elect ronics Engineering, Pondicherry Engineering C ollege . Sh e has around 50 publications to her credit. She is a re v iewer of t he AMSE journ al of Mode ling, IEEE Industrial Electronics Society and Asian N eural Networ ks Society. Her research interests are Fuzzy systems, Neural Networks, Hybri d systems and their applications.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment