대각선 기반 특징 추출을 이용한 손글씨 알파벳 인식 시스템
** 본 논문은 90×60 픽셀 크기로 정규화된 영문 알파벳 이미지를 10×10 픽셀 54개의 구역으로 나눈 뒤, 각 구역의 대각선 픽셀 합을 평균하여 54개의 기본 특징과 행·열 평균 15개의 부가 특징을 추출한다. 추출된 69차원 특징 벡터를 입력으로 하여 2개의 은닉층(각 100노드)과 26개의 출력노드를 갖는 다층 퍼셉트론을 학습시킨다. 실험 결과, 대각선 특징은 기존의 수평·수직 특징보다 인식 정확도가 97.8% (54특징)와 98…
저자: J. Pradeep, E. Srinivasan, S. Himavathi
**
본 논문은 오프라인 손글씨 영문 알파벳 인식을 위한 새로운 특징 추출 기법과 이를 활용한 신경망 분류 시스템을 제안한다. 전체 시스템은 이미지 획득, 전처리, 세분화, 특징 추출, 분류·인식, 후처리의 전형적인 흐름을 따른다. 이미지 획득 단계에서는 스캐너나 디지털 카메라를 통해 JPEG·BMP 등 표준 포맷의 스캔 이미지를 입력받는다. 전처리 단계에서는 전역 임계값을 이용한 이진화, Sobel 엣지 검출, 팽창·구멍 메우기 등을 수행해 노이즈를 제거하고 문자 경계를 명확히 만든다. 세분화 단계에서는 라벨링 기법으로 개별 문자 영역을 추출하고, 각 문자를 90×60 픽셀로 정규화한다.
특징 추출 단계가 논문의 핵심이다. 정규화된 문자 이미지를 10×10 픽셀 크기의 54개 구역으로 나눈 뒤, 각 구역 내부의 19개 대각선 라인에 존재하는 전경 픽셀 수를 합산한다. 이 합을 19개의 대각선 라인 수로 나누어 평균값을 구하고, 이를 해당 구역의 특징값으로 저장한다. 이렇게 하면 구역마다 하나의 특징값이 생성되어 54개의 기본 특징이 된다. 추가적으로, 구역을 행별·열별로 묶어 각각 평균을 구해 9개의 행 평균 특징과 6개의 열 평균 특징을 만든다. 최종적으로 54+15=69개의 특징 벡터가 각 문자에 할당된다. 이 방법은 수평·수직 투영 방식이 놓치기 쉬운 대각선 방향의 구조적 정보를 효과적으로 포착한다는 장점을 가진다.
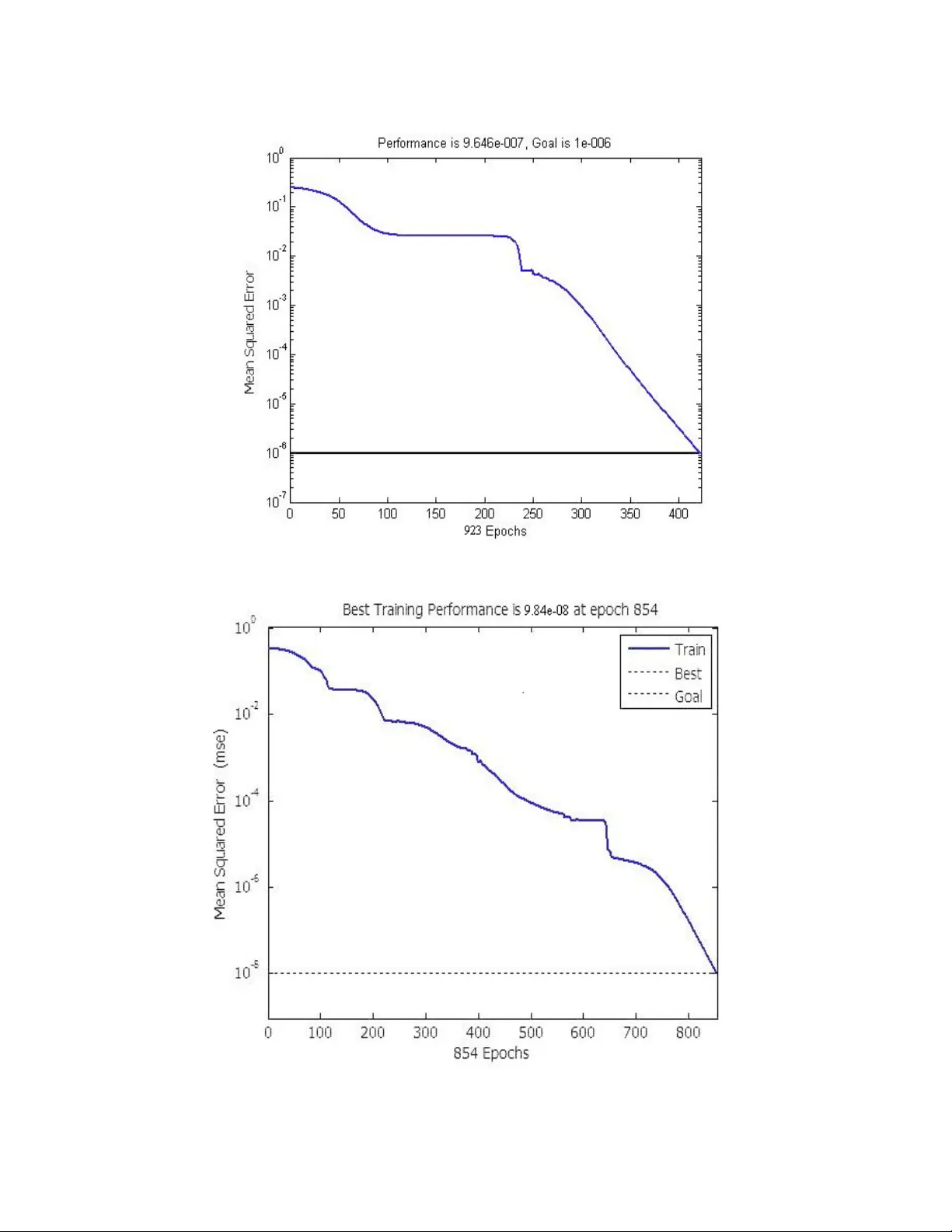
분류·인식 단계에서는 피드포워드 역전파 신경망을 사용한다. 입력층 노드 수는 특징 차원(54 또는 69)에 따라 결정되며, 두 개의 은닉층 각각 100개의 시그모이드 활성화 뉴런을 배치한다. 출력층은 26개의 알파벳 클래스를 위한 경쟁형 레이어로 구성된다. 학습 알고리즘은 모멘텀(0.9)과 적응 학습률을 결합한 경사 하강법을 적용하고, 손실 함수는 평균 제곱 오차(MSE)이다. 목표 MSE는 1e‑6이며, 최대 에포크는 1,000,000으로 설정했지만 실제 수렴은 923(54특징)와 854(69특징) 에포크 내에 이루어졌다.
실험은 50개의 훈련 세트(각 세트에 26자, 다양한 필체)와 570개의 테스트 샘플을 사용해 수행되었다. 세 가지 특징 추출 방식(수직, 수평, 대각선)을 각각 54·69 차원으로 적용해 6개의 신경망을 구축하고, 인식 정확도를 비교했다. 결과는 다음과 같다. 54특징 기준에서 수직 92.69%, 수평 93.68%, 대각선 97.80%의 정확도를 보였으며, 69특징 기준에서는 수직 92.69%, 수평 94.73%, 대각선 98.54%를 기록했다. 대각선 기반 특징이 가장 높은 정확도와 빠른 학습 수렴을 달성했으며, 행·열 평균을 추가한 69특징이 전반적으로 성능을 향상시켰다.
시스템 구현에는 MATLAB 7.1을 사용했으며, 사용자 친화적인 GUI를 제공해 전처리·특징 선택·학습·인식 과정을 메뉴 기반으로 제어할 수 있다. GUI는 사용자가 이미지 파일을 선택하고, 원하는 특징 추출 방식을 지정한 뒤, 인식 결과를 메모장 형태로 출력하도록 설계되었다.
결론적으로, 대각선 기반 특징 추출은 기존 수평·수직 방식에 비해 문자 형태의 복합적인 구조를 더 잘 반영하여 인식 정확도를 크게 높인다. 제안된 시스템은 98%에 육박하는 높은 정확도로 우편·은행·문서 자동화 등 실무 적용 가능성을 시사한다. 다만, 현재 실험은 영문 알파벳에 한정되어 있으며, 필체 다양성 및 잡음에 대한 강건성 검증이 부족하다. 향후 연구에서는 다국어·다스크립트 데이터, CNN·RNN 등 딥러닝 기반 자동 특징 학습과의 비교, 그리고 실시간 온·오프라인 혼합 시스템 구축 등을 통해 제안 방법의 일반화와 확장성을 검증할 필요가 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기