A measure of statistical complexity based on predictive information
We introduce an information theoretic measure of statistical structure, called 'binding information', for sets of random variables, and compare it with several previously proposed measures including excess entropy, Bialek et al.'s predictive informat…
Authors: Samer A. Abdallah, Mark D. Plumbley
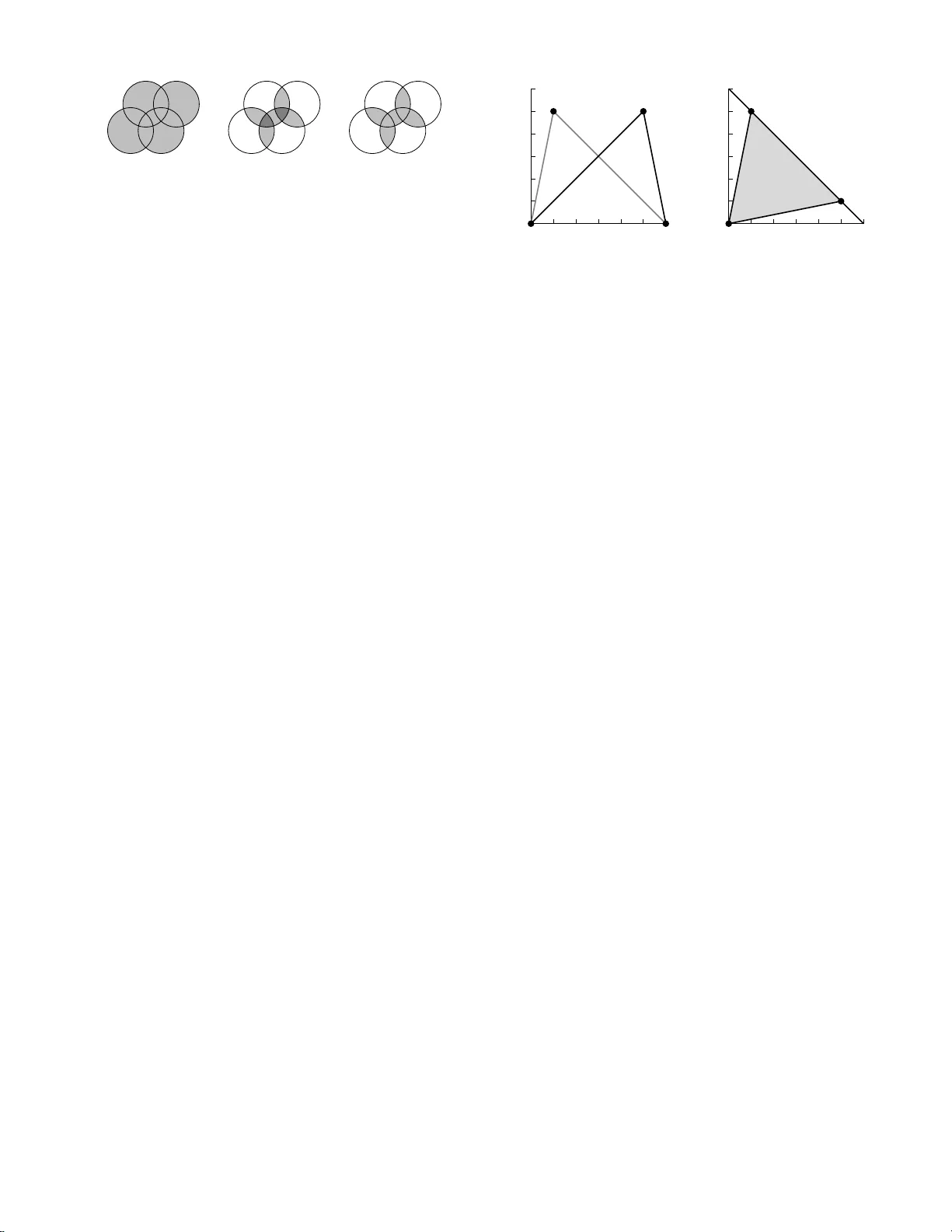
A measure of statistical complexit y based on predictiv e information Samer A. Abdalla h and Mark D. Plum bley Que en Mar y University of L ondon (Dated: Octob er 25, 2018) W e introduce an information t heoretic measure of statistical structure, called ‘binding in forma- tion’, for sets of random v ariables, and compare it with several previously prop osed measures in- cluding excess entrop y , Bialek et al. ’s predictive informatio n, and the multi-informati on. W e derive some of the prop erties of the binding information, particularly in relation to th e multi-information, and show that, for fin ite sets of binary random v ariables, the pro cesses which maximises bindin g information are the ‘parit y’ processes. Finally we discuss some of the implications this has for th e use of the b inding information as a meas ure of complexit y . I. INTRO DUCTION The concepts o f ‘structure’, ‘pa ttern’ and ‘co mplexit y’ are relev a n t in many fields of inquir y: ph ysics, bio logy , cognitive sciences, mac hine learning, the arts and so on; but are v ag ue enough to resist b eing qua nt ified in a single definitive manner. One a pproach, which we ado pt here, is to attempt to characterise them in sta tis tica l terms, for distributions over configurations o f some system, using the tools of information theory [1]. In this letter, w e pr o po se a measure o f statistica l struc- ture based on the concept o f pr e dictive information r ate (PIR) [2], which mea sures an asp ect of tempor al depen- dency not captured by previo usly prop ose d mea sures. W e review a n um ber of these earlier prop osa ls and the PIR, and then define the binding information a s the ex- tensive counterpart of the PIR applicable to arbitra ry countable s ets of random v a riables. After descr ibing some of its prop erties, we identify some finite disc rete pro cesses that ma ximise the binding informatio n. In the following, if X is a ra ndo m pro cess indexed by a set A , and B ⊆ A , then X B denotes the comp o und random v ariable (random ‘vector’) formed b y taking X α for each α ∈ B . The set of integers fro m M to N inclusive will b e written M ..N , and \ will deno te the set difference op erator, so, fo r example, X 1 .. 3 \{ 2 } ≡ ( X 1 , X 3 ). II. BACK GROUND Suppo se that ( . . . , X − 1 , X 0 , X 1 , . . . ) is a bi-infinite sta- tionary sequence of random v ar iables, and tha t ∀ t ∈ Z , the random v ariable X t takes v alues in a discrete set X . Let µ b e the a sso ciated shift-in v ar iant probability mea - sure. Stationa rity implies that the probability distribu- tion ass o ciated with any c o nt iguous blo ck o f N v a riables ( X t +1 , . . . , X t + N ) is indep endent of t , and therefore w e can define a shift-inv ariant blo ck entropy function: H ( N ) , H ( X 1 , . . . , X N ) = X x ∈X N − p N µ ( x ) log p N µ ( x ) , (1) where p N µ : X N → [0 , 1 ] is the unique probability mass function for any N consecutive v ariables in the seque nce , p N µ ( x ) , P r( X 1 = x 1 ∧ . . . ∧ X N = x N ). The entr opy r ate h µ has tw o equiv alen t definitions in terms of the blo ck entropy function [1, Ch. 4]: h µ , lim N →∞ H ( N ) N = lim N →∞ H ( N ) − H ( N − 1) . (2) The blo ck en tropy function ca n also b e used to express the mutual infor mation betw een t wo cont iguous segments of the sequence of length N and M resp ectively: I ( X − N .. − 1 ; X 0 ..M − 1 ) = H ( N ) + H ( M ) − H ( N + M ) . (3) If we let b oth block lengths N and M tend to infinity , we obtain what has been ca lled the exc ess entr opy [3] or the effe ctive me asur e c omplexity [4 ]. It is the amount of in- formation abo ut the infinite future tha t ca n b e obtained, on a v erage , b y observing the infinite past: E = lim N →∞ 2 H ( N ) − H ( 2 N ) . (4) Bialek et al. [5] defined the pr e dictive information I pred ( N ) as the mutual infor mation b etw een a blo ck of length N and the infinite future following it: I pred ( N ) , lim M →∞ H ( N ) + H ( M ) − H ( N + M ) . (5) They show ed that even if I pred ( N ) div erges as N tends to infinit y , the manner of its divergence reveals something ab out the lear nability of the underlying r a ndom pro cess. Bialek et al. also emphasised that I pred ( N ) is the sub- extensive comp onent o f the entropy: if N h µ is the pur ely extensive ( i.e. , linear in N ) comp onent of the ent ropy , then I pred ( N ) is the differe nce betw een the blo ck entropy H ( N ) a nd its extensive component: H ( N ) = N h µ + I pred ( N ) . (6) The multi-information [6] is defined for any collection of N ra ndom v ariables ( X 1 , . . . , X N ) as I ( X 1 ..N ) , − H ( X 1 ..N ) + X i ∈ 1 ..N H ( X i ) . (7) F or N = 2 , the multi-information reduces to the m utual information I ( X 1 ; X 2 ), while for N > 2, I ( X 1: N ) co nt in- ues to b e a mea sure of dep endence, b e ing zero if and only 2 finite past infinite future PI X − N : − 1 X 0 , . . . (a) predictive information I pred ( N ) infinite past infinite future E . . . , X − 1 X 0 , . . . (b) excess entropy E r µ b µ ρ µ X 0 infinite future infinite past . . . , X − 1 X 1 , . . . (c) predictive information rate b µ FIG. 1. V enn diagram representation [1, Ch. 2] of sev- eral information measures for stationary random pro cesses. Eac h circle or ov al represen ts a random v ariable or sequence of random v ariables relative to time t = 0. Overla pp ed areas correspond to vari ous m utual informations. In (c), the circle represents the ‘p resen t’. Its total area is H ( X 0 ) = H (1) = ρ µ + r µ + b µ , where ρ µ is the multi-information rate, r µ is the residual entrop y rate, and b µ is the predictiv e information rate. The entrop y rate is h µ = r µ + b µ . if the v a r iables are s tatistically indep endent. In the ther- mo dynamic limit, the intensiv e multi-information r ate ( cf. Dubno v’s information r ate [7]) can be defined as ρ µ , lim N →∞ I ( X 1 ..N ) − I ( X 1 ..N − 1 ) . (8) It can easily b e shown that ρ µ = I pred (1) = H (1) − h µ . Erb a nd Ay [8] studied this quan tit y (they call it I ) and show ed that, in the pre s ent terminology , I ( X 1 ..N ) + I pred ( N ) = N ρ µ . (9) Comparing this with ( 6 ), we see that I pred ( N ) is a lso the sub-extensive comp onent of the multi-information. Thu s, all of the measures co nsidered so far, being linear ly depe ndent in v arious w a ys, are close ly related. Another class of measures, including Gr assb erger ’s true me asur e c omplexity [4] and Crutchfield et al. ’s sta- tistic al c omplexity C µ [9, 10], is base d on the prop erties of sto chastic automata that mo del the pro ces s under c o n- sideration. These hav e some interesting prop erties but are beyond the scop e of this letter. In [2], we introduce d the pr e dictive information r ate (PIR), which is the av erag e information in one observ a- tion a bo ut the infinite future given the infinite past. If ← X t = ( . . . , X t − 2 , X t − 1 ) denotes the v a r iables b efor e time t , and → X t = ( X t +1 , X t +2 , . . . ) denotes those a fter t , the PIR is defined as a conditional mutual infor mation: I t , I ( X t ; → X t | ← X t ) = H ( → X t | ← X t ) − H ( → X t | X t , ← X t ) . (10 ) Equation ( 10 ) can b e read as the av erage reduction in uncertaint y a bo ut the future o n lea rning X t , given the past. Due to the symmetry of the mutual infor mation, it can a lso b e written as I t = H ( X t | ← X t ) − H ( X t | → X t , ← X t ). H ( X t | ← X t ) is the en tropy r ate h µ , but H ( X t | → X t , ← X t ) is a quantit y that do es not app ear to b e have b een considered by other authors yet. It is the conditiona l entropy of one v ar iable given al l the o thers in the sequenc e , future as well as past. W e call this the r esidual entr opy r ate r µ , and define it as a limit: r µ , lim N →∞ H ( X − N ..N ) − H ( X − N .. − 1 , X 1 ..N ) . (11) The second term, H ( X − N .. − 1 , X 1 ..N ), is the joint entropy of tw o non-adjacent blo cks with a gap b e tw een them, and canno t b e expr essed as a function of block entropies alone. If we let b µ denote the shift-inv ariant PIR, then b µ = h µ − r µ (see Fig. II ). Many of the measures r eviewed ab ov e were intended as mea sures of ‘complexity’, a q uality that is so mewhat op en to interpretation [11, 12]. It is generally a greed, how ev er, that complexity should b e low for systems that a r e deterministic or easy to compute or predict— ‘ordered’—a nd low for systems that a co mpletely random and unpredictable—‘disordere d’. The PIR s atisfies these conditions without b eing ‘over-univ ersal’ in the sense of Crutchfield et al. [12, 1 3]: it is not simply a function of ent ropy or en tropy rate that fails to distinguis h be t ween the different streng ths of tempora l dependency tha t c a n be exhibited by sys tems at a given level of entrop y . In our analysis of Marko v chains [2], we found that pro cesse s which max imis e the PIR do not maximise the multi- information rate ρ µ (or the exces s entropy , which is the same in this case ), but do hav e a certain kind o f pa rtial predictability that requir es the obs erver con tin ually to pay a tten tion to the most r ecent observ ations in order to make optimal pr edictions. And so, while Crutchfield et al. ma ke a compelling case for the exces s entrop y E and their statistical complexity C µ as measur es of complex- it y , th ere is still r o om to sug gest that the PIR captures a different and non trivia l asp ect of tempo ral dependency structure not prev iously examined. II I. BINDING INFOR MA TION If the PIR ra te is accumulated ov er success ive time steps, a q uantit y which we call the binding information is obtained. T o pro ceed, w e first reformulate the infinite sequence PIR ( 10 ) so that it b ecomes applicable to a finite s equence of r andom v ariables ( X 1 , . . . , X N ): I t ( X 1 ..N ) = I ( X t ; X ( t +1) ..N | X 1 .. ( t − 1) ) , (12) Note that this is no longer shift-inv a riant and may de- pend on t . The binding infor mation, then, is the sum B ( X 1 ..N ) = X t ∈ 1 ..N I t ( X 1 ..N ) . (13) 3 (a) H ( X 1 .. 4 ) (b) I ( X 1 .. 4 ) (c) B ( X 1 .. 4 ) FIG. 2. Illustration of binding information as compared with multi-info rmation for a set of four rand om v ariables. In each case, the quantit y is represented by t he total amount of blac k ink, as it were, in the shaded parts of the diagram. Whereas the multi-information counts the m ultiply-ov erlapped areas multiple times, the bind ing information counts eac h over- lapp ed areas just on ce. Expanding this in terms of entropies and conditiona l en- tropies and ca ncelling terms yields B ( X 1 ..N ) = H ( X 1 ..N ) − X t ∈ 1 ..N H ( X t | X 1 ..N \{ t } ) . (14) Like the m ulti-information, it measures dep endencies betw een random v a riables, but in a differ ent w ay (see fig. II I ). Tho ugh the binding information was derived by accumulating the PIR sequentially , the result is p er m u- tation inv ariant, sugg e sting tha t the co ncept migh t b e applicable to ar bitrary sets of r andom v ar iables regar d- less of their top olo g y . Accor dingly , we define the binding information as f ollows: Definition 1. If { X α | α ∈ A} is set of r andom vari ables indexe d by a c ountable set A , the binding information is B ( X A ) , H ( X A ) − X α ∈A H ( X α | X A\{ α } ) . (15) Since the binding information can b e expressed as a sum of (conditional) m utual informations b etw een se ts of random v ariables ( 13 ), it is (a) non-neg ative and (b) inv a r iant to inv ertible p oint wise transforma tions of the v ar iables; that is, if Y A is a set of random v ariables suc h that, ∀ α ∈ A , Y α = f α ( X α ) for some inv ertible functions f α , then B ( Y A ) = B ( X A ). The binding information is zer o fo r sets o f independent random v a riables—the case of complete ‘disor der’—and zero when a ll v aria bles ha ve zer o en tropy , taking known v alues and re presenting a certain kind of ‘order’. How- ever, it is also p ossible to obtain low binding information for r andom systems which ar e nonetheless very order ed in a certain w ay . If each v ariable X α is some function of X α ′ for a ll α ′ 6 = α , then the state o f the en tire system can b e read off from any one of its co mpo nent v a riables. In this case, it is ea s y to show that B ( X A ) = H ( X A ) = H ( X α ) for an y α ∈ A , which, a s we will see, is relatively low compared with what is poss ible as so on as N b ecomes appreciably lar ge. Thus, binding information is lo w for bo th highly ‘o rdered’ and hig hly ‘disorder ed’ systems, but in this case , ‘hig hly order ed’ do es not simply mea n deterministic or known a priori : it means the whole is predictable from the smallest of its parts. 1 N N H (bits) I (bits) B (bits) I < ( N − 1) H I < N − H B < H B < ( N − 1)( N − H ) a b c d 1 1 N N B (bits) I (bits) I + B < N I < ( N − 1) B B < ( N − 1) I b c a d FIG. 3. Constraints on multi-information I ( X 1 ..N ) and bind- ing informati on B ( X 1 ..N ) f or a system of N = 6 binary ran- dom v ariables. The la b elled points represent iden tifiable dis- tributions ov er the 2 N states th at this system can o ccupy: ( a) known state , the system is deterministically in one configura- tion; (b) giant bit , one of the P 6 B processes; ( c) p arity , the parity pro cesses P 6 2 , 0 or P 6 2 , 1 ; (d) indep endent , the system of indep endent unbiased random bits. IV. BOUNDS ON BINDING AND MUL T I-INF ORMA TION In this sectio n we confine our attention to sets of dis- crete random v a riables taking v alue s in a common al- phab et co ntaining K symbols. In this case, it is quite straightforward to derive upper b ounds, as functions of the joint en tropy , on both the m ulti-information and the binding infor mation, a nd also upp e r b o unds on multi- information and binding information a s functions of each other. In [14], we pr ov e the following results: Theorem 1. If { X α | α ∈ A} is a set of N = |A| r andom variables al l taking values in a discr ete set of c ar dinality K , then the fol lowing c onstra ints al l hold: I ( X A ) ≤ N log K − H ( X A ) (16) I ( X A ) ≤ ( N − 1) H ( X A ) (17) B ( X A ) ≤ H ( X A ) (18) B ( X A ) ≤ ( N − 1)( N log K − H ( X A )) . (19) Also , B ( X A ) and I ( X A ) ar e mutual ly c onstr aine d: I ( X A ) + B ( X A ) ≤ N log K . (20) These bounds restr ict I ( X A ) and B ( X A ) to tw o tr ia n- gular re gions of the plane when plotted against the join t ent ropy H ( X A ) and are illustrated for N = 6 , K = 2 in fig. IV . Two more linear b ounds were suggested by em- pirical computations of binding info r mation and m ulti- information: I ( X A ) ≤ ( N − 1) B ( X A ) (21) and B ( X A ) ≤ ( N − 1) I ( X A ) . (22) W e hav e not fo und a gener al pro of of these inequalities for all N , but we have constructed a numerical a lgorithm [1 4] that is able to find pro o fs f or given v alues of N up to 3 7, at which p oint insufficient numerical pr ecision b ecomes the limiting f actor. 4 V. MAXIMISING BINDING INFORMA T ION Is the absolute maximum of B ( X 1 ..N ) = ( N − 1) log K implied by Theo rem 1 is attainable, and by what k inds of pro cesses? In [14] we prov e the following: Theorem 2. If { X 1 , . . . , X N } is a set of discr ete r andom variables e ach taking values in 0 .. ( K − 1) , then B ( X 1 ..N ) is maximise d at ( N − 1) log 2 K bits by the K ‘mo dulo- K pr o c esses’ P N K,m for m ∈ 0 .. ( K − 1) , under which the pr ob abili ty of a c onfigur ation x ∈ (0 ..K − 1) N is P N K,m ( x ) = ( K 1 − N if P N i =1 x i mo d K = m, 0 otherwise. (23) When K = 2 (binary random v ar iables) the maximal binding information of N − 1 bits is reached by the tw o ‘parity’ pro cesses: P N 2 , 0 is the ‘even’ pr o cess, whic h dis- tributes uniform probability o v er all configurations with even par ity; P N 2 , 0 is the ‘odd’ pro cess, which distr ibutes uniform probabilities over the complement ary s et. The m ulti-information of the parity pro cesses is 1 bit. By contrast, the binary pro cesses which maximis e the multi- information at N − 1 bits are the ‘giant bit’ pro cesses: the indices 1 ..N are partitioned int o tw o sets B a nd its complement B = 1 ..N \ B , and probabilities assigned to configuratio ns x ∈ { 0 , 1 } N as follo ws: P N B ( x ) = 1 2 : if ∀ i ∈ 1 ..N . x i = I ( i ∈ B ) , 1 2 : if ∀ i ∈ 1 ..N . x i = I ( i ∈ B ) , 0 : otherwis e , (24) where I ( · ) is 1 if its argument is true and 0 otherwise. The binding information of these pro cesses is 1 bit. Thus we s e e that the pro cesses whic h maximise the binding information and the mult i-information a re quite different in c haracter. VI. DISCUSSION A ND CONCLUSIONS As noted in § I , Bia lek et al. arg ue that the predic- tive information I pred ( N ), b eing the sub-extensive com- po nent of the entropy , is the unique measure of c omplex- it y that satisfies certain rea sonable desider ata, including transformatio n in v ar iance for contin uo us-v a lue d v ariables [5, § 5 .3]. While lack of space precludes a full discus- sion, w e note that tr a nsformation inv aria nc e do es not , as Bialek et al. sta te [5, p. 245 0], demand sub-extensivity: binding information is transformatio n inv ariant, since it is a sum of conditional m utual informatio ns, and yet it c an hav e an extensive compo nent , since its intensive counterpart, the PIR, ca n have a well-defined v alue, e.g. , in stationary Mark ov chains [2]. Measures of statis tica l dep endency a r e disc ussed by Studen` y a nd V ejnarov` a, [6, § 4], who form ulate a ‘lev el- sp ecific’ mea sure that ca ptures the dep endency visible when fixe d size subsets of v ariables are examined in iso- lation. Studen` y and V ejnarov` a [6, p. 277] use the parity pro cess as an example of a random process in whic h the depe ndence is o nly visible at the highest level, that is, amongst a ll N v a riables; if fewer than N v a riables a r e ex- amined, they a pp ea r to be indep endent . They note that such pr o cesses were called ‘pseudo-indep endent’ by Xi- ang et al. [15], who conc luded that sta ndard a lgorithms for Bayesian netw ork construction fail when applied to them. It is in triguing, then, that these a re singled out as ‘mo st complex’ according to the binding information criterion. T o summar ise, we hav e in tro duced binding information as a measure of statistical structure that can b e applied to any coun table set o f random v ariables regar dless of any topolo gical o rganisa tio n of the v ariables. Binding information is maximised in finite discr e te v alued sys - tems by the ‘mo dulo pr o cess’. F urther results on binding information, a nd inv estigations of binding information in some specific random proce sses a re presen ted in [14]. [1] T. M. Co ver and J. A. Thomas, El ements of Information The ory (John Wiley and Sons, New Y ork, 1991). [2] S. A. Ab dallah and M. D. Plumbley , Connection Science 21 , 89 (2009). [3] J. Crutchfield and N. P ac k ard, Ph ysica D : Nonlinear Phe- nomena 7 , 201 (1983). [4] P . Grassb erger, I nternational Journal of Theoretica l Physics 25 , 9 07 (1986). [5] W. Bia lek, I. Nemenman, and N. Tish b y , Neural Com- putation 13 , 2409 (2001 ). [6] M. Studen ` y and J. V ejnarov` a, in L e arning in Gr aphic al Mo dels , ed ited by M. I. Jordan (MIT Press, 1998) pp . 261–297 . [7] S. D ubnov, Signal Processing Letters, IEEE 11 , 698 (2004). [8] I. Erb and N. Ay , Journal of Statistical Physics 115 , 949 (2004). [9] J. P . Crutchfield and K. Y oung, Physica l R eview Letters 63 , 105 (1989) . [10] J. P . Crutc hfield and D. P . F eldman, Physical Review E 55 , 1239R (1997 ). [11] C. H. Bennett, in Complexity, Entr opy, and the Physics of Inf ormation , edited by W. H. Zurek (Addison-W esley , 1990) p p. 137–148 . [12] D. P . F eldman and J. P . Crutchfield, Physics Letters A 238 , 244 (199 8). [13] J. P . Crutchfield, D. P . F eldman, and C. R. Sh alizi, Physica l R eview E 62 , 2996 (2000 ) . [14] S. A. Ab dallah and M. D. Plum bley , Pr e dictive Inf orma- tion, Multi-information and Binding Inf ormation , T ech. Rep. C4DM-TR-10-10 (Queen Mary Universit y of Lon- don, 2010). [15] Y. Xiang, S. W on g, and N . Cercone, in Pr o c. 12th Conf. on Unc ertainty in Artificial I ntel li genc e (1996) pp. 564– 571.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment