Variable selection and updating in model-based discriminant analysis for high dimensional data with food authenticity applications
Food authenticity studies are concerned with determining if food samples have been correctly labeled or not. Discriminant analysis methods are an integral part of the methodology for food authentication. Motivated by food authenticity applications, a…
Authors: Thomas Brendan Murphy, Nema Dean, Adrian E. Raftery
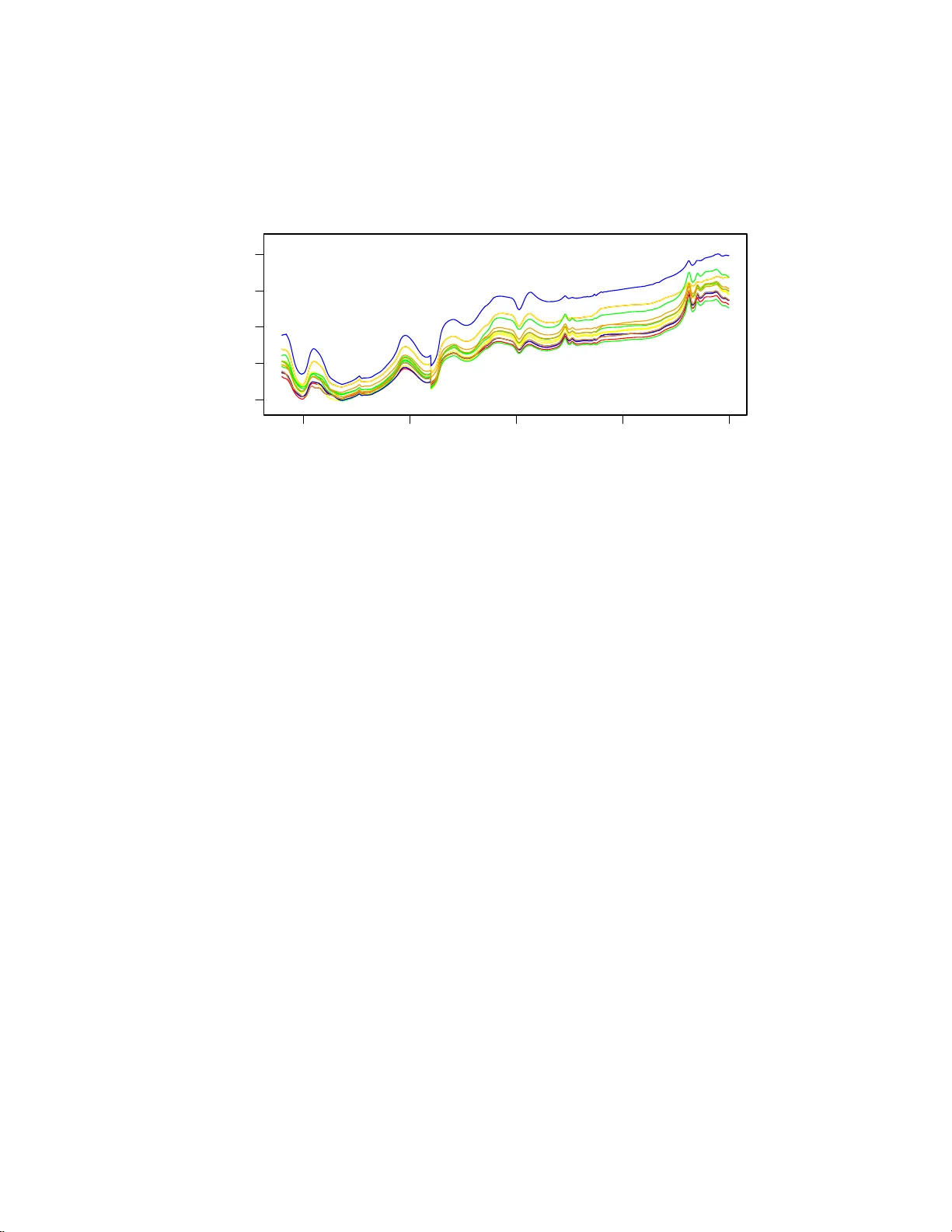
The Annals of Applie d Statistics 2010, V ol. 4, No. 1, 396–421 DOI: 10.1214 /09-A OAS279 c Institute of Mathematical Statistics , 2 010 V ARIABLE SELEC TION AND UPD A TING IN MODEL-BASED DISCRIMINANT ANAL YSIS F OR HIGH DIMENSIONAL D A T A WITH F OOD AUTHENTICITY APPLICA TIONS By Thomas Brend an Murphy 1 , 3 , Nema Dean 3 and Adrian E . Rafter y 2 , 3 University Col le ge Dublin, University of Glasgow and University of Washington, Se attle F o od authenticit y studies are concerned with determining if foo d samples h a ve b een correctly labeled or not. Discriminan t analysis metho d s are an in tegral part of the metho dology for foo d authenti- cation. Motiv ated by foo d authenticit y applicatio ns, a mo del-b ased discriminan t analysis metho d that includes v ariable selectio n is pre- sented. The discriminan t analysis mo del is fitted in a semi-sup ervised manner u sing b oth lab eled and unlab eled data. The metho d is shown to giv e excellent class ification p erformance on several high-dimensional multicl ass fo od authenticit y data sets with more va riables than ob- serv ations. The va riables selected by the proposed metho d pro vide information ab out whic h v ariables are meaningful for classification purp oses. A headlong search strategy for var iable selection is shown to b e efficient in terms of computation and achiev es excellent classifi- cation p erformance. I n applications to several foo d authenticit y d ata sets, our prop osed meth o d outperformed default implemen tations of Random F orests, AdaBoost, transductive SVMs and Bay esian Multi- nomial Regression by substantia l margins. 1. Introd uction. F o o d s that are exp ensiv e are sub ject to potentia l fraud where rogue suppliers ma y attempt to pro vide a c heap er in authen tic alterna- tiv e in place of the more exp ensive authen tic fo o d. F o o d auth en ticit y studies are c oncerned with assessin g t he v eracit y of the lab eling o f foo d samples. Received Ap ril 2009; revised Au gust 2009. 1 Supp orted in p art by the S cience F oun d ation of Ireland Basic Research Grant 04/BR/M00 57 and Research F rontier s Programme Grant 2007/RFP/MA TF281. 2 Supp orted in part by NICHD Gran t R01 H D 054511 and NS F Grant A TM 0724721. 3 Supp orted in part by NIH Grant 8 R01 EB002 137-02. Key wor ds and phr ases. F oo d authen t icit y studies, headlong searc h, model-based dis- criminan t analysis, normal mixture models, semi-sup ervised learning, up dating classifica- tion rules, vari able selection. This is an electronic reprint of the orig inal ar ticle published by the Institute of Ma thema tical Statistics in The Annals of Applie d Statistics , 2010, V ol. 4, No. 1, 396 –421 . This reprint differs from the orig inal in pagination and t yp ogra phic detail. 1 2 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y Discriminan t a n alysis metho d s are of prime im p ortance in fo o d authentic - it y studies where samp les whose authen ticit y is b eing assessed are classified using a d iscriminant analysis method and the lab eling and classification are compared. S amp les determined to ha v e p otentia lly inaccurate lab eling can b e sent for fu rther testing to determine if fraudulent lab eling h as b een used. Mo del-based d iscriminan t analysis [Bensmail and Celeux ( 1996 ), F raley and Raftery ( 2002 )] pro vides a framew ork for discriminant analysis based on parsimonious normal m ixture models. This app roac h to discriminan t analy- sis has b een sh o wn to b e effectiv e in pr actice and, b eing based on a statistical mo del, it allo ws for uncertain t y to b e treated appropriately . In man y applications, only a sub set of the v ariables in a d iscr im in an t analysis con tain an y group m emb ership information and including v ariables whic h ha ve n o group information increases the complexit y of the analysis, p oten tially degrading the classification p erformance. Therefore, there is a need for including v ariable selectio n as part of an y discriminant an alysis pro cedur e. Additionally , if a subset of v ariables is f ou n d to b e imp ortan t for classification pur p oses, then it suggests the p oten tial for collect ing a smaller su bset of v ariables usin g in exp ensive metho d s rather than the f ull high dim en sional data. V ariable selection can b e completed as a p repro cessing step prior to d is- criminan t analysis (a filtering app roac h) or as part of the analysis p ro cedure (a w rapp er approac h). Completing v ariable selection prior to the discrimi- nan t analysis can lead to v ariables that ha v e w eak individual classification p erformance b eing omitted from the subsequ en t analysis. Ho wev er, such v ariables could b e imp ortan t for classification pu r p oses when join tly con- sidered with others. Hence, p erforming v ariable selectio n as p art of the d is- criminan t analysis pro cedure is preferred. Com b ining v ariable selec tion and linear or quadr atic discriminant analy- sis has b een co nsidered previously in th e literature; see McLac hlan [( 1992 ), Chapter 12] for a review. Man y of these metho ds are b ased on measuring the Mahalanobis d istance b et wee n groups b efore and after the inclusion of a v ariable into the d iscriminan t analysis mo del. In the mac h ine learning liter- ature, Koha v i and John ( 1997 ) dev elop ed a wr app er appr oac h for com b in ing v ariable selectio n in sup ervi se d lea rning, of whic h discriminan t analysis is a sp ecial case. V ariable selection is of p articular imp ortance in situations where there are more v ariables than observ ations av ailable, th at is, large p , sm all n ( n ≪ p ) problems [W est ( 2003 )]. These situations arise with in creasing frequency in statistical applicatio ns, including genetics, proteomics, image p ro cessing and fo o d scie nce. Th e t wo fo o d science applicatio ns considered in Section 2 in volv e data sets with many more v ariables than observ ations. In this pap er a v ersion of mo del-based d iscr im in an t analysis is develo p ed b y adapting the mo d el-based clustering with v ariable selection m etho d of V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 3 Raftery and Dean ( 2006 ). This metho d of discrim in an t analysis builds a discriminant rule in a stepwise manner b y considering the inclusion of extra v ariables in to the mod el and also considerin g remo ving existing v ariables from the mod el based on their imp ortance. T he s tepwise selectio n pr o cedure is iterated un til conv ergence. A brief r eview of m o del-based clusterin g an d discr im in an t analysis is giv en in Section 3 . The un derlying mo del for mod el-based clustering with v ariable selection is reviewed in Section 3.1 and this mo d el is extended to mo del- based d iscriminant analysis w ith v ariable selection in Section 3.2 . In S ec- tion 3.3 the fitting of the discriminant analysis model is extended to in - corp orate semi-sup ervised u p dating using b oth the lab eled and unlab eled observ ations [Dean, Mur phy and Do w n ey ( 2006 )] in order to impr o ve the classification p erformance. Searc h strategie s for selecting the v ariables for inclusion a nd exclusion are discus s ed in S ection 3.4 . A h eadlong searc h strateg y is prop osed that com bines go o d classification p erformance an d computational effici ency . The prop osed metho d ology is applied to the high dimens ional d ata sets in Sec- tion 4 and the metho dology and results are discussed in Section 5 . 2. D ata. 2.1. F o o d authenticity and ne ar infr ar e d sp e ctr osc opy. An authentic fo o d is one th at is wh at it claims to b e. Im p ortant asp ects of fo o d d escription include its pro cess history , geographic origin, sp ecies/v ariety and pur ity . F o o d pro ducers, regulators, r etailers and consumers n eed to b e assured of the auth en ticit y of fo o d pro ducts. F o o d au th en ticit y studies are concerned with esta blishing whether fo o ds are auth entic or not. Many analytical c hemistry tec hniqu es are used in fo o d authen ticit y stu dies, in clud ing gas c hromatograph y , mass sp ectroscop y and vibrational sp ectroscopic tec hniques (Raman, ultra violet, m id-infrared, near-infrared and visible). All of these tec h niques ha v e b een sho w n to b e ca- pable of discriminating b et we en certain sets of similar biological materials. Do wney ( 1996 ) and Reid, O’Donnell a nd Do wney ( 2006 ) pro vide r eviews of foo d authen ticit y studies with an emphasis on sp ectroscopic metho ds. Near in frared (NIR) sp ectroscop y pr o vides a quic k and efficien t metho d of collect ing data for use in f o o d authenticit y studies [Do wney ( 1996 )]. It is particularly useful b ecause it requires v ery little sample preparation and is nondestructive to the samples b eing tested. W e consider t wo fo o d authen ticit y data sets which consist of com b ined visible and near-infrared sp ectroscopic measuremen ts fr om fo o d samples of differen t typ es. The aim o f the fo o d authen ticit y study is to cla s s ify the fo o d samples in to known group s . Th e t w o s tudies are outlined in detail in Sections 2.2 and 2.3 : 4 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y 500 1000 1500 2000 2500 0.8 1.0 1.2 1.4 1.6 W avelength (nm) log(1/R) Fig. 1. The ne ar-infr ar e d sp e ctr a r e c or de d for thr e e examples of e ach me at sp e cies in the study. The disc ontinuity at 1100 nm is due to a sensor cha nge at that value. The samples ar e c olor e d as Be ef = r e d, L amb = gr e en, Pork = blue, T urkey = or ange, Chicken = yel l ow. • Classifying m eats in to sp ecies (Beef, Chic ken, Lamb, P ork, T ur k ey). • Classifying olive oils in to geographic origin (C r ete, Pe lop onese, other). In b oth stud ies, com bin ed visible and near infrared sp ectra we re collected in reflectance m o de usin g an NIRSystems 6500 in strument ov er the w a v e- length range 400–2498 n m at 2 nm int erv als. The visible p ortion of the sp ectrum is the range 40 0–80 0 n m and the near-infrared region is the range 800–2 498 n m. Hence, the v alues collected for eac h fo o d sample consist of 1050 reflectance v alues tak en at 2 nm in terv als (see , for example, Figure 1 ). F or the meat samples, t wen t y five separate scans we re collecte d d uring a single passage of th e sp ectrophotometer and av eraged, after whic h th e mean sp ectrum of a reference ceramic tile (16 scans) w as recorded and subtracted from the mean sp ectrum. A s imilar pro cess w as used for the oliv e oil data, but few er scans were used . F ull details of the sp ectral data collection p r o cess are giv en in McElhinney , Do wney and F earn ( 1999 ) and Do wney , McIn t yre and Da vies ( 2003 ). The reflectance v alues in the visible and near-infrared r egion are p ro duced b y vibrations in the chemica l b onds in the substance b eing analyzed. The data are highly correlated d ue to the pr esence of a large n u m b er of o ver- lapping broad p eaks in this region of the electromagnetic sp ectrum and the presence of com binations and ov ertones. As a result, ev en though the data are v er y highly correlated, the reflectance v alues at adjacen t w a ve lengths can ha ve d ifferen t sources and reflectance v alues at v er y different wa vel engths can ha ve the same source. S o, the information enco ded in eac h sp ectrum is recorded in a complex manner and spread o ver a range of lo cations. O s- b orne, F earn and Hindle ( 1993 ) pro vid e an extensive review of th e c h emical V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 5 and tec hnological asp ects of near-infr ared sp ectroscop y and its application. F ur ther information on the com bin ed sp ectra and their structure is gi v en in Section 4 where the results of the analysis of the data are giv en . Because of the co mplex nature of the com bined sp ectroscopic data, there is int erest in determining if a small subset of reflectance v alues con tain as m u c h information for authen tication purp oses as the w hole sp ectrum do es. If a small num b er of v ariables conta in sufficient inf ormation for authen ticatio n purp oses, then this indicates the p ossibilit y of develo p ing p ortable sen sors for foo d auth enticit y stu dies that are more r apid and ha v e a lo we r cost than recording the com b ined visible and near-infr ared sp ectrum. In fact, p ortable sensors hav e b een devel op ed on a commercial basis f or the authen ticatio n of S cottish w h iskys [Connolly ( 2006 )] using u ltra violet sp ectroscopic tec h- nology . Hence, there are motiv ations f or in corp orating feature selection in the classificati on metho ds used on th ese data from the application and the mo deling viewp oin ts. The problem of feature selection is esp ecially difficult b ecause the n umb er of p ossible subsets of w a vele ngths that could b e selecte d in this problem is 2 1050 . S o, efficient s earch strategies n eed to b e used so that a go o d set of features can b e selected without s earching o ver all p ossible su bsets. 2.2. Homo genize d me at data. McElhinney , Downey and F earn ( 1999 ) constructed a collection of com bined visible and near-infrared sp ectra from 231 homogenized meat s amples in o rder to assess the effe ctiv eness of visible and near-infrared sp ectroscop y as a tool for determining the co rrect sp ecies of the samples. The samples collected for this study consist of 55 Chick en, 55 T u rk ey , 55 P ork, 32 Beef and 34 Lam b samples. The samples w ere collected o ve r an extended p er io d of time and from a num b er of sources in order to ensure a representa tive sample of meats. F or eac h sample, a sp ectrum consisting of 1050 r eflectance measuremen ts w as recorded (as outlined in S ection 2.1 ). A plot of all of the sp ectra is shown in Figure 1 . W e can see that there is a discrimination b et ween the red meats (b eef and lam b) and the white meats (c h ic ken, turk ey and p ork) o ver some of the visible region (400 –800 nm), bu t discrimination within meat co lors is less clear. 2.3. Gr e ek olive oils data. Do w ney , McIn tyre and Da vies ( 2003 ) recorded near-infrared sp ectra f r om a total of 65 extra virgin oliv e oil samples that w ere collected from three differen t regions in Greece (18 Cr ete, 2 8 P elo- p onese, 19 other). Eac h data v alue consists of 1050 reflectance v alues o ve r the visib le and near-infrared range. The aim of their stud y wa s to assess the effectiv eness of near-infr ared s p ectroscop y in determining the geog r aphical origin (see Figure 2 ) of the oils. 6 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y 3. Mo d el-based clustering and discriminan t analysis. Mo del-based clus- tering [Banfield and Raftery ( 1993 ), F raley and Raftery ( 1998 , 2002 ), McLac h- lan and P eel ( 2000 )] u s es mixture mo d els as a framew ork for cluster analysis. The underlying mod el in m o del-based clustering is a n ormal mixture model with G comp onen ts, that is, f ( x ) = G X g =1 τ g f ( x | µ g , Σ g ) , where f ( ·| µ g , Σ g ) is a m ultiv ariate normal densit y with mean µ g and co v ari- ance Σ g . A cen tral idea in mo del-based clustering is the use of constrain ts on the group cov ariance matrices Σ g ; these constraints use the eigen v alue de- comp osition of the co v ariance matrices to imp ose shap e restrictions on the groups. The decomp osition is of the form Σ g = λ g D g A g D T g , where λ g is the largest eigen v alue, D g is an orthonormal m atrix of eigen v ectors, and A g is a diagonal matrix of scaled eigen v alues. In terpretations f or the p arameters in th e co v ariance decomp osition are as follo ws: λ g = v olume; A g = shap e; D g = orien tation. These parameters can b e constrained in v arious w a ys to b e equal or v ariable across groups. Additionally , the shap e and orien tation matrices can b e set equal to the identit y matrix. Bensmail and Celeux ( 1996 ) dev elop ed mo del-based discriminant analysis metho ds using the same co v ariance d ecomp osition. An extension of mo d el- based discriminant anal ysis that allo ws for up dating of the classificatio n rule using th e unlab eled data w as deve lop ed b y Dean, Murphy and Do wn ey Fig. 2. R e gions of Gr e e c e wher e the olive oi l samples wer e c ol l e cte d. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 7 ( 2006 ) and will b e describ ed in more detail in Section 3.3 . Mo del-based clustering and discriminan t analysis can b e imp lemen ted in the statistic s pac k age R [R Dev elopmen t Core T eam ( 2007 )] u sing th e mclu st pac k age [ F raley and Rafte ry ( 19 99 , 2003 , 2007 )]. 3.1. Mo del-b ase d clustering with variable sele ction. W e argue that v ari- able selection needs to b e part of th e discriminant analysis pro cedur e, b e- cause completing v ariable selectio n pr ior to discrimin an t analysis ma y lose imp ortant group ing information. This argumen t is supp orted b y the r esult of Chang ( 1983 ), w h o sho wed that th e principal comp onents corresp ondin g to the larger eigen v alues do not necessarily con tain inform ation ab out group structure. Th is suggests that the commonly us ed filter approac h of select- ing the first few principal comp onent s to exp lain a minim u m p ercen tage of v ariation can b e sub optimal. A similar argum ent can b e made that select- ing discriminating v ariables without r eference to the grouping v ariable ma y miss imp ortan t v ariables. I n addition, some v ariables ma y cont ain strong group inform ation w h en used in com bin ation with other v ariables, b ut not on their o w n . Another critique of completing a v ariable (or f eature) selec- tion step b efore sup ervised learning (filtering) is giv en b y Koha vi and John ( 1997 ), S ection 2.4. Raftery and Dean ( 2006 ) dev elop ed a step wise v ariable selectio n wrapp er for mo d el-based clustering. With their m etho d, v ariables are selected in a step wise manner. T heir metho d in volv es the stages: • A v ariable is p rop osed for add ition to th e set of selected clustering v ari- ables. T he Ba yesia n Information C r iterion (BIC) is u sed to compare a mo del in which the v ariable conta ins extra information ab out the clus- tering b eyond the information in the already selected v ariables v ers us a mo del where the v ariable do esn’t cont ain additional information ab out the clustering b ey ond th e information in the already selected v ariables. The v ariable w ith the greate st p ositiv e BIC difference is added to the mo del. If the pr op osed v ariable has a negativ e BIC difference, th en n o v ariable is added. • BIC is used to consider whether a v ariable should b e remo ved from the mo del; This step is the rev erse of the v ariable addition step. If all of the selected v ariables con tain clustering information, then n one is r emo ve d from the set of selec ted clustering v ariables. This p ro cess is iterate d unti l no further v ariables are added or r emo ve d. This approac h, that com b in es v ariable selection and cluster analysis, av oids the problems of completing v ariable selection indep en d en tly of the clustering. While the s tep wise v ariable selection wrapp er p rop osed in Raftery and Dean ( 2006 ) and other wrapp er approac hes can give excellen t clusterin g resu lts, there is a considerable computational bur den with wr app er ap p roac hes when 8 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y compared to filtering approac hes; this is b ecause the mo del needs to b e fitted eac h time a v ariable is add ed or remo v ed from the set of selec ted clus terin g v ariables. 3.2. Mo del-b ase d discriminant analysis with variable sele ction. W e adapt the ideas of Raftery and Dean ( 2006 ) to pro duce a discriminant analysis tec h- nique that includes a step wise v ariable select ion wrapp er. This discriminan t analysis metho d uses a step wise v ariable selection pro cedur e to fi n d a subset of v ariables that giv es go o d classificatio n results. Eac h stage of the algorithm in v olv es t w o steps: • Determine if a v ariable (not already selecte d) would con trib ute to th e dis- criminan t analysis mo del. In order to do this, a m o del comparison using BIC is used to compare a discriminan t analysis mo del where the v ariable con tains group inform ation b eyo n d the information in the already selected v ariables versus a mod el where the v ariable do es not con tain group infor- mation b ey ond the information in the already selected v ariables. V ariables where the BIC d ifference is p ositiv e are candidates for addition to the set of selected v ariables; th e pro cedur e for searc hing for v ariables to add to the m o del is giv en in Section 3.4 . • Determine if an y selected v ariables should b e remo v ed from the d iscrimi- nan t analysis mod el. This s tep is the rev erse of the v ariable addition step. V ariables w here the BIC mo del comparison s uggests that the v ariable d o es not con tain group information are candidates for remo ving from the set of selected v ariables; the pr o cedure for searc h ing for v ariables to r emov e from the mo del is outlined in Section 3.4 . Let ( x 1 , x 2 , . . . , x n ) b e the observed data v alues and let ( l 1 , l 2 , . . . , l n ) b e the group ind icator v ariables for these observ ations where l ig = 1 if observ a- tion i b elongs to group g and l ig = 0 otherwise. Supp ose that the observ ation x i is partitioned in to three parts: x ( c ) i are the v ariables already chose n; x ( p ) i is the v ariable b eing p rop osed; x ( o ) i are the remainin g v ariables. The d ecision on whether to includ e or exclud e a prop osed v ariable is based on the comparison of tw o mo dels: • Grouping: p ( x i | l i ) = p ( x ( c ) i , x ( p ) i , x ( o ) i | l i ) = p ( x ( o ) i | x ( p ) i , x ( c ) i ) p ( x ( p ) i , x ( c ) i | l i ). • No Grouping: p ( x i | l i ) = p ( x ( c ) i , x ( p ) i , x ( o ) i | l i ) = p ( x ( o ) i | x ( p ) i , x ( c ) i ) p ( x ( p ) i | x ( c ) i ) × p ( x ( c ) i | l i ). Figure 3 s ho ws the difference b etw een the “Grouping” and “No Groupin g” mo dels for x i . If th e Group ing mo del holds, x ( p ) i pro v id es information ab out whic h group the data v alue b elongs to b ey on d that pro vided b y x ( c ) i , while if the No Groupin g mo del h olds, x ( p ) i pro v id es no extra information. The Group ing and No Grouping mo d els are sp ecified as follo ws: V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 9 T able 1 Constr aine d c ovarianc e str uctur es i n mo del-b ase d clustering as implemente d in th e mclust p ackage for R Mod el ID V olume Shap e Orientation Co v ariance ( Σ g ) EI I Equal Equal spherical NA λI VI I V ariable Equal spherical NA λ g I EEI Equal Equal Axis aligned λA VEI V ariable Equal Axis aligned λ g A EVI Equal V ariable Axis aligned λA g VVI V ariable V ariable Axis aligned λ g A g EEE Equal Equal Equal λDA D T EEV E qual Equal V ariable λD g AD T g VEV V ariable Equal V ariable λ g D g AD T g VVV V ariable V ariable V ariable λ g D g A g D T g • Grouping: W e let p ( x ( p ) i , x ( c ) i | l i ) b e a n ormal density with p arsimonious co v ariance structure as describ ed in T able 1 . Th at is, ( x ( p ) i , x ( c ) i ) | ( l ig = 1) ∼ N ( µ ( p,c ) g , Σ ( p,c ) g ) , l i ∼ Multinomial(1 , τ ) , where τ = ( τ 1 , τ 2 , . . . , τ G ). • No Group ing: W e let p ( x ( c ) i | l i ) b e a normal dens it y with p ars imonious co v ariance structure. In addition, p ( x ( p ) i | x ( c ) i ) is assumed to hav e a linear Fig. 3. A gr aphic al mo del r epr esentation of the Gr ouping and the No Gr ouping mo dels. 10 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y regression m o del stru cture. That is, x ( c ) i | ( l ig = 1) ∼ N ( µ ( c ) g , Σ ( c ) g ) , l i ∼ Multinomial(1 , τ ) , x ( p ) i | x ( c ) i ∼ N ( α + β T x ( c ) i , σ 2 ) , where τ = ( τ 1 , τ 2 , . . . , τ G ). The same m o del structur e is assum ed for p ( x ( o ) i | x ( c ) i , x ( p ) i ) in the Grouping mo del as in the No Groupin g mo del. Therefore, this part of the mo del do es not in fluence the c hoice to include x ( p ) i in the mo del or not. The decision as to w hether the Grouping or No Gr ou p ing mo del is ap- propriate is made u sing the BIC appr o ximation of the log Ba y es factor. The logarithm of the Ba y es factor is log(Ba yes F actor) = log p ( x i |M G ) p ( x i |M N G ) , (3.1) where M G is th e Grouping mod el, M N G is th e No Grouping mo del and p ( x i |M k ) = Z p ( x i | θ k , M k ) p ( θ k |M k ) dθ k is the integrat ed lik eliho o d of mod el M k . W e use the BIC appro ximation of the integrate d lik eliho o d in the form BIC = 2 × log maximized lik eliho o d − d log ( n ) , where d is the num b er of parameters in the m o del and n is the sample size [Sc hw arz ( 1978 )]. F ollo w ing Raftery and Dean ( 200 6 ), the log Ba y es factor ( 3.1 ) can b e r ed uced to log(Ba yes F actor) = log p ( x ( p ) i , x ( c ) i |M G ) p ( x ( p ) i | x ( c ) i , M N G ) p ( x ( c ) i |M N G ) (3.2) ≈ 1 2 [BIC(Grouping) − BIC(No Grouping)] , whic h only in v olves ( x ( c ) i , x ( p ) i ) and not x ( o ) i . V ariables with a p ositiv e differ- ence in BIC(Grouping) − BIC (No Groupin g) are candid ates for b eing added to the mo del. A t eac h v ariable addition stage, the BIC of the grou p ing mod el is calcu- lated usin g eac h of the ten co v ariance structures giv en in T able 1 and the mo del with the highest BIC is selected for the Grouping mo del for mo del comparison purp oses. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 11 A t eac h stage, w e also c hec k if an already chose n v ariable should b e r e- mo ved from the mo d el. This decision is made on th e basis of the BIC dif- ference in a similar wa y to previously . In this case, x ( p ) i tak es the role of the v ariable to b e dropp ed, x ( c ) i tak es the role of the remaining chosen v ariables and x ( o ) i are the other v ariables. The v ariables with a p ositiv e difference in BIC(Grouping) − BIC(No Grouping) are cand idates for r emov al from the mo del; in th is case, the BIC for the no group ing mo dels are computed for all co v ariance structures from T able 1 and the mo del with the highest BIC is s elected as the No Grouping mo del. 3.3. Discriminant analysis with u p dating. In standard d iscriminan t anal- ysis, the unlab eled data are not u sed in the mo del fitting pro cedure. Ho w- ev er, these data con tain inform ation that is p oten tially imp ortant, esp ecially when v ery few lab eled data v alues are a v ailable. W e can mo d el b oth the la- b eled and u nlab eled d ata as coming from the same mo del, but where the unlab eled data is missing the lab eling v ariable, this leads to a mixture mo del for the unlab eled data. Hence, the unlab eled data can then b e us ed to help fit a mo d el to the data. This idea has b een in vestig ated by man y authors, including Ganesalingam and McLac h lan ( 1978 ) and O’Neill ( 197 8 ) and more recen tly b y Dean, Murphy and Do wn ey ( 2006 ), Chap elle, Sc h ¨ olk opf and Zien ( 2006 ), T oher, Do wn ey and Murphy ( 2007 ) and Liang, Mukh erjee and W est ( 2007 ). Let ( x 1 , l 1 ) , ( x 2 , l 2 ) , . . . , ( x N , l N ) be the la b eled data and y 1 , y 2 , . . . , y M b e th e u nlab eled data. W e let z = ( z 1 , z 2 , . . . , z M ) b e the unobserv ed (miss- ing) lab els f or the u nlab eled data. In this framew ork, th e Grouping and No Grouping mo dels for the observed data are of the form: • Grouping: W e let p ( x ( p ) i , x ( c ) i | l i ) b e a n ormal density with p arsimonious co v ariance structure as describ ed in T able 1 , namely , ( x ( p ) i , x ( c ) i ) | ( l ig = 1) ∼ N ( µ ( p,c ) g , Σ ( p,c ) g ) , l i ∼ Multinomial(1 , τ ) . Also, p ( y ( p ) j , y ( c ) j ) is a mixture of n ormals with parsimonious co v ariance structures, n amely , ( y ( p ) j , y ( c ) j ) ∼ G X g =1 τ g N ( µ ( p,c ) g , Σ ( p,c ) g ) . • No Group ing: W e let p ( x ( c ) i | l i ) b e a normal dens it y with p ars imonious co v ariance structure, n amely , x ( c ) i | ( l ig = 1) ∼ N ( µ ( c ) g , Σ ( c ) g ) , l i ∼ Multinomial(1 , τ ) . 12 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y W e also let p ( y ( c ) j ) b e a m ixture of norm al d ensities with pars imonious co v ariance structure, n amely , y ( c ) j ∼ G X g =1 τ g N ( µ ( c ) g , Σ ( c ) g ) . In addition, w e assume a linear regression mo del for p ( x ( p ) i | x ( c ) i ) and p ( y ( p ) j | y ( c ) j ), namely , x ( p ) i | x ( c ) i ∼ N ( α + β T x ( c ) i , σ 2 ) and y ( p ) j | y ( c ) j ∼ N ( α + β T y ( c ) j , σ 2 ) . In b oth m o dels, we assu me an identic al m o del structure for p ( x ( o ) i | x ( c ) i , x ( p ) i ) and p ( y ( o ) j | y ( c ) j , y ( p ) j ), and this doesn’t affect the c hoice to include a v ariable in the mo del or not. This mo d el can b e fitted usin g the EM algorithm [Dempster, Laird and Rubin ( 1977 )] b y introdu cing the missing lab els z in to the mo del. The cal- culations inv olv ed in fitting the mo d el including the lab eled and unlab eled data follo w those outlined in Dean, Mu r phy and Do wney ( 2006 ). T h e max- im u m likelihoo d estimates for the regression part of th e mo d el corresp ond to least squares estimates of the regression parameters. The final estimates of the p osterior pr obabilit y of group mem b erships pr o- duced by the EM al gorithm are u sed to classify the un lab eled observ ations. Th us, eac h obser v ation j is classified into the group g that maximizes ˆ z j g o ve r g , w here ˆ z j g = ˆ τ g p ( y ( c ) j | ˆ µ ( c ) g , ˆ Σ ( c ) g ) P G g ′ =1 ˆ τ g ′ p ( y ( c ) j | ˆ µ ( c ) g ′ , ˆ Σ ( c ) g ′ ) , y ( c ) j is the set of c hosen v ariables, and { ( ˆ τ g , ˆ µ ( c ) g , ˆ Σ ( c ) g ) : g = 1 , 2 , . . . , G } are the maximum lik eliho o d estimates f or the un kno wn mo del parameters for this set of c hosen v ariables. 3.3.1. Example. An illus trativ e example of the BIC ca lculations when the prop osed algo rithm is applied to the meat sp ectroscopy data is sho wn in Figures 4 – 6 ; half the data of eac h t yp e were randomly s elected as training data in this example. The v ariable selection algorithm b egins by selecting 626 nm as the w av e- length with the greatest d ifference b etw een the Grouping and No Gr ou p ing mo dels (Figure 4 ) and the E co v ariance structure w as c hosen. I t is worth V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 13 Fig. 4. A plot of the BI C differ enc e for e ach wavelength. The wavelength with the gr e atest BIC differ enc e is 626 nm. noting that w av elengths close to 626 nm still hav e strong evidence of group- ing ev en though the sp ectra are smo othly v aryin g. This phenomenon is due to the fact th at the sp ectrum consists of a n u m b er of o v erlapping p eaks an d the r eflectances at adjacen t locations can ha ve different sources. As a result, extra grou p ing information can b e a v ailable at wa vel engths that are v ery close. Subsequ ently , the 814 n m wa velengt h is added to the mo del (Figure 5 ) and the EEV cov ariance structure was c hosen. A t the third stage, the 774 nm Fig. 5. A plot of the BIC differ enc e f or e ach waveleng th given that wavelength 626 nm is al r e ady ac c epte d. The wavelength with the gr e atest BIC differ enc e is 814 nm. Note that wavelengths close to 626 nm stil l have p ositive BIC differ enc e values. 14 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y Fig. 6. A plot of the BIC differ enc e for e ach wavelengt h given that the first two wave- lengths chosen (626 nm and 814 nm) ar e alr e ady ac c epte d. The wavelength with the gr e atest BIC differ enc e is 774 nm. T able 2 A f ul l example of the variable sele ction pr o c e dur e use d to classify the me at samples i nto five t yp es. The up dating pr o c e dur e was use d in this ex ample Iteration Prop osal BIC diff. Decision Prop osal BIC d iff. Decis ion 1 Ad d 626 nm 425 . 4 Accepted 2 Ad d 814 nm 274 . 1 Accepted 3 Ad d 774 nm 427 . 4 Accepted Remov e 774 nm − 427 . 4 Rejected 4 Ad d 664 nm 142 . 6 Accepted Remov e 626 nm − 120 . 1 Rejected 5 Ad d 680 nm 220 . 1 Accepted Remov e 774 nm − 78 . 8 Rejected 6 Ad d 864 nm 165 . 2 Accepted Remov e 774 nm − 91 . 7 Rejected 7 Ad d 602 nm 118 . 9 Accepted Remov e 774 nm − 26 . 3 Rejected 8 Ad d 794 nm 118 . 3 Accepted Remov e 774 nm − 86 . 2 Rejected 9 Ad d 702 nm 178 . 6 Accepted Remov e 774 nm − 127 . 5 Rejected 10 Add 1996 n m 127 . 5 Accepted Remov e 1996 nm − 127 . 5 Rejected 11 A dd 644 nm 76 . 6 Accepted Remov e 644 n m − 76 . 6 Rejected 12 Add 2316 n m 24 . 1 Accepted Remov e 2316 n m − 24 . 1 Rejected 13 Add 2310 n m 103 . 2 Accepted Remov e 702 nm − 26 . 1 Rejected 14 Add 1936 n m 10 . 8 Accepted Remov e 702 n m 4 . 4 Accepted 15 A dd 704 nm − 3 . 7 Rejected Remov e 1936 nm − 41 . 3 Rejected w av elength is select ed (Figure 6 ) and the VEV co v ariance stru cture wa s cho- sen. The pro cedure con tinues un til thirteen wa velengt hs are selected (details of the iterat ions are giv en in T able 2 ) and the VEV co v ariance stru cture is c hosen at all subsequent stag es. In terestingly , m an y of the c hosen w av elengths are in the visible range (400– 800 n m) of the sp ectrum, indicating that color is im p ortant when sep- V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 15 arating th e meat samples. The closest t wo wa velengths that w ere selected w ere 2310 nm and 2316 nm and a num b er of w av elengths that w er e selected are appro ximately 20 nm apart. In sum mary , the selected w av elengths are spread out mainly in the visible region, bu t some wa v elengths w ere selected in the near-infrared regio n . 3.4. He ad long mo del se ar ch str ate gy. The v ariable selection algorithm demonstrated in Section 3.3.1 is a greedy searc h strategy . A t the v ariable ad- dition stages of the algorithm, the v ariable w ith the greate st BIC d ifference is ad d ed and at v ariable remo v al stages, the v ariable w ith the greatest BIC difference is remo ved. The pro cess of fin ding the v ariable with the greatest BIC difference in v olve s calculating the BIC d ifference for all v ariables un - der consideration; for the sp ectroscopic data th ere are typica lly just u nder 1050 v ariables u nder consideration at th e v ariable addition stages. Hence, this searc h strateg y is compu tationally demanding; this feature is shared b y other w rapp er v ariable selectio n m etho ds to o. A less computationally exp ensive alternativ e is to us e a headlong s earc h strategy [Badsb erg ( 1992 )]. Th e v ariable added or remo ved in the headlong searc h strate gy need n ot b e the b est in terms of having th e greatest BIC dif- ference; it merely needs to b e the first v ariable considered whose difference is greater than s ome pr e-sp ecified v alue (here min . evidenc e ). W e found that min . evidenc e = 0 ga v e go o d results for the applications in this pap er. T he headlong strategy h as close connections to the “first-improv emen t” mo ves used in local searc h alg orithms [e.g., Ho os and St¨ utzle ( 2005 ), Chapter 2.1 ]. This means that instead of add ing the v ariable with the greatest evidence for Grouping ve rsus No Group ing, the first v ariable found to ha v e a cer- tain amount of evidence for Group ing v ersus No Groupin g w ould b e added. A t the v ariable addition stages of the algorithm, the remaining v ariables are examined in tur n fr om an ordered list. The initial ord er of the list is based on the v ariables’ original BIC differences at the univ ariate addition stage; this ordering w as used in a similar con text in Y eung, Bumgarner and Raftery ( 2005 ). W e exp eriment ed with the initial ordering and also tr ied using increasing w a ve length and decreasing wa velength. T he classification p erformance w as not sensitiv e to the initial orderin g, but the selected v ari- ables d id dep end on the ordering. In th e con text of increasing and decreasing w av elength, there w as a bias to w ard selec ting lo w and high w a vele ngths, re- sp ectiv ely . Here is a summary of the algorithm: 1. S elect the first v ariable th at is added to b e the one that has the most evidence for Group ing ve rsus No Groupin g in terms of greatest BIC dif- ference (the same as the first step of the greedy search algorithm). Create a list of the remaining v ariables in decreasing ord er of BIC differences. 16 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y 2. S elect the second v ariable that is added to b e the fir s t v ariable in the list of remainin g v ariables with BIC difference for Gr ou p ing ve r sus No Grouping, including the first v ariable selected, greater than min . evidenc e . An y v ariable c hec ked and not used at this stage is p laced at the end of the list of r emaining v ariables. 3. S elect the next v ariable th at is added to b e the first v ariable in the list of remaining v ariables with BIC difference for Grouping v ersus No Group- ing, including the previous v ariables s elected, greater than min . evidenc e . If no v ariable has BIC difference greater than min . evidenc e , then no v ari- able is added at this stage. An y v ariable c hec ked and not used at this stage is p laced, in turn, at the end of the list of remaining v ariables. 4. C hec k in turn eac h v ariable curren tly selected (in rev erse order of in- clusion) for evidence of No Grouping (v ersu s Grou p ing), including the other selected v ariables, and remo ve the fir st v ariable with BIC difference greater th an min . evidenc e . If no v ariable h as BIC difference greater than min . evidenc e , then n o v ariable is remo ved at this stage. The r emo ve d v ariable is p laced at the end of the list of other remaining v ariables. 5. I terate steps 3 and 4 un til t wo consecutiv e steps ha v e b een r ejected, th en stop. 4. Resu lts. The prop osed method ology wa s applied to th e t wo fo o d au- then ticit y data sets outlined in Secti on 2.1 . In eac h case, the d ata were sp lit so that 50% of the d ata w ere used as lab eled data and 50% as u nlab eled. The metho dology w as applied to 50 random splits of lab eled and un lab eled data and the mean and standard d eviation of the classification rate we re computed. The results we re compared to previously rep orted p er f ormance results for these data and sev eral widely used alternativ e tec hniqu es: Random F orests [Breiman ( 2001 )], AdaBo ost [F reund and Sc hapire ( 1997 )], Ba y esian Multi- nomial Regression [Madigan et al. ( 2005 )], and T ransductive Supp ort V ector Mac hines [V apn ik ( 1995 ), J oac hims ( 199 9 ), Collober t et al. ( 200 6 )]. W e used the default settings in the R [R Dev elopmen t Core T eam ( 2007 )] implemen tations of Random F orests ( ra ndomFore st version 4.5-30 ) [Lia w and Wiener ( 2002 )] and Ad aBoost ( adabag v ersion 1.1) [Cort ´ es, Mart ´ ınez and Rubio ( 2007 )]. The use of v arious parameter settings was explored, but the results d id not v ary to a large e xten t with r esp ect to the c h oice of parameter v alues. F or Ba yesian Multinomial Regression we used cross v alidation to c ho ose b et we en the c hoice of prior v ariance v alues { 10 p : p = − 4 , − 3 , − 2 , − 1 , 0 , 1 , 2 , 3 , 4 } as suggested in Genkin, Lewis and Madigan ( 2005 ). F or the T r ansductiv e SVM analysis we us ed the Univ erSVM soft w are version 1.1 [Sinz and Roffilli ( 2007 )] with a linear kernel and parameters ( c, s, z ) = (100 , − 0 . 3 , 0 . 1); other p arameter v alues w ere considered, but the v alues re- p orted yielded the b est classifications. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 17 T able 3 Classific ation p erformanc e on the Me ats data for the variable sele ction algorithm with up dating and f or pr evious analyses of these data. Me an classific ation p erformanc e for the 50 r andom splits of the data ar e r ep orte d with standar d deviations in p ar entheses Metho d Misclassification rate V ariable selection and up dating 6 . 1% (3 . 5) V ariable selection ( greedy ) and up d ating 5 . 1% (1 . 9) V ariable selection only 9 . 3% (3 . 6) Dean, Murphy an d Do wney ( 20 06 ) 5 . 6% (2 . 0) McElhinney , Downey and F earn ( 1999 ) 7 . 3%–13 . 9% T ransductive S VMs 42 . 6% (5 . 7) Random F orests 20 . 1% (3 . 8) AdaBoost.M1 20 . 3% (4 . 8) Ba yesian Multinomial Regress ion 34 . 2% (5 . 8) 4.1. Me ats dat a. The results ac h iev ed on the homogenized meat data (Section 2.2 ) are rep orted in T able 3 . These resu lts sho w that the v ari- able selection and up dating metho d giv es comparable or b etter p erf ormance than previous analyses of these d ata; a n imp ro ved cla s sification rate h as b een ac h iev ed relativ e to those ac h iev ed b y McElhinney , Do wney and F earn ( 1999 ) who used factorial discriminant analysis (FD A), k -nearest neighbors ( k NN), discriminant partial least squ ares regression (PLS) and soft inde- p endent mo deling o f class analogy (SI MCA). F urthermore, a comparable classification p erformance has b een ac h iev ed r elativ e to Dean, Murp h y and Do wney ( 2006 ) who u sed mod el-based d iscriminan t analysis with up d ating on a reduced form of the data d er ived from wa v elet thresh oldin g. The v ari- able selection and up dating pro cedure ga ve su b stan tially b etter p er f ormance than other comp eting m etho ds f or classificatio n . An examination of th e misclassification table (T able 4 ) for the v ariable se- lection and u p d ating metho d shows that man y of the miscla ssifications w ere due to the difficulty in separating the c hick en and turkey groups. Interest- ingly , no m isclassifications were made b et ween the red and w hite meats. The c hosen w a v elengths show us w h ic h parts of the sp ectrum are of im- p ortance when classifying samples into different sp ecies. W e recorded the c hosen w a velengths for eac h of the 50 sets of r esults and these are sh o wn in Figure 7 . W e can see that a large prop ortion (51%) of th e chosen w av elengths are in the visible regi on (400–80 0 nm), but some regions in the near-infr ared sp ectrum are also c h osen. Liu and Chen [( 2000 ), T able 1] assign man y of the sp ectral features in the visible p art of the sp ectrum to differen t forms of m yogl obin suc h as deo x y my oglobin (430, 440, 445 nm), o xym yoglo b in (545, 560, 575, 585 nm), metm yoglo b in (485, 495, 500, 505 nm) and sulfmy o- globin (635 nm). Su lfm yoglo b in is a pr o duct of th e reaction of my oglobin 18 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y Fig. 7. Wavelength s chosen in the five me at classific ation pr oblem for the variable sele c- tion and up dating metho d. The height of the b ars shows how many times the wavelength was chos en in 50 r andom splits of the data. with H 2 S generated by bacteria, and Arnalds et al. ( 2004 ) found the region of the s p ectrum close to 635 nm to b e imp ortan t when s ep arating the red and white meat samples. The p eak at 1100 n m is the w a v elength where the sensor c hanges in the near-infrared sp ectrometer and the p eak at 1068 nm can b e attributed to thir d o v ertones of C-H stretc h m o de and C-H combi- nation b ond s from meat constituen ts other than oxym y oglobin [Liu, Ch en and Ozaki ( 200 0 )]. Th e near infrared regio n consisting of w a v elengths near 1510 nm h as b een attributed to p r otein, and a cluster of c hosen wa velengt hs is clo s e to this regio n. In all cases, b et wee n 13 and 19 wa velengt hs were c hosen for classification purp oses. T able 4 Av er age classific ation r esults for the differ ent me at typ es for the variable sele ction and up dating classific ation metho d Predicted T ruth Beef Lam b Po r k T urkey Chick en Beef 98 . 6 1 . 4 0.0 0 . 0 0 . 0 Lam b 1 . 4 98 . 6 0.0 0 . 0 0 . 0 P ork 0 . 0 0 . 0 99.2 0 . 5 0 . 3 T urkey 0 . 0 0 . 0 0.0 88 . 2 11 . 8 Chic ken 0 . 0 0 . 0 0.0 11 . 1 88 . 9 V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 19 T able 5 Classific ation p erformanc e on the Me ats data for the variable sele ction algorithm with up dating and for pr evious analyses of these data after c ombining the chicken and turke y into a p oultry gr oup. Me an classific ation p erformanc e for the 50 r andom splits of th e dat a ar e r ep orte d with standar d deviations in p ar entheses Metho d Misclassification rate V ariable selection and up dating 0 . 8% (1 . 3) V ariable selection ( greedy ) and up d ating 0 . 7% (0 . 7) V ariable selection only 1 . 8% (3 . 2) Dean, Murphy an d Do wney ( 2006 ) 1 . 0% (0 . 9) McElhinney , Downey and F earn ( 1999 ) 2 . 6%–4 . 3% T ransductive S VMs 20 . 9% (8 . 0) Random F orests 10 . 5% (3 . 3) AdaBoost.M1 14 . 7% (3 . 7) Ba yesian Multinomial Regress ion 17 . 2% (4 . 9) F ollo win g McElhinney , Do wney and F earn ( 1999 ) and Dean, Murph y and Do wney ( 2006 ), w e com bin ed the c hick en and turk ey groups in to a p oultry group to d etermine ho w we ll w e can cla ssify the homogenized meat samp les in to f our t yp es. The classificatio n results are r ep orted in T ab le 5 and th e mis- classifications from the v ariable selection metho d with up dating are sho w n in T able 6 . There is a significan t impro v ement in classification p erformance from all of the metho d s. Ag ain, the white and red meats are separated with zero error. The w av elengths chosen for the four group classification problem (Fig- ure 8 ) still ha v e a su b stan tial prop ortion c hosen from the visible p art of the sp ectrum (52%). In this application, b et ween 13 and 21 w a ve lengths were c hosen for classification purp oses. The VEV cov ariance structure w as c hosen in al most eve ry run as the final mo del for b oth the f our and fiv e group meat classification problems. T able 6 Av er age classific ation r esults for the differ ent me at typ es after c ombining the chicken and turkey i nto a p oultry gr oup. T he r esults shown ar e for the variable sele ction and up dating metho d Predicted T ruth Beef Lam b Po r k Po u ltry Beef 98 . 2 1 . 8 0.0 0 . 0 Lam b 2 . 7 97 . 3 0.0 0 . 0 P ork 0 . 0 0 . 0 99.1 0 . 9 P oultry 0 . 0 0 . 0 0.0 100 . 0 20 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y Fig. 8. W avelengths chosen i n the four me at classific ation pr oblem for the variable se- le ction and up dating metho d. 4.2. Gr e ek olive oil data. The metho ds we re app lied to the Greek oliv e oil data (Section 2.3 ), with 50% of th e data b eing treated as trainin g data and 50% as test data. Fift y random splits of training an d test data w ere used. The misclassification rates ac hieved on these data are rep orted in T able 7 . V ariable selecti on and up d ating pro vides one of the b est classificatio n rates for these data. Do wney , McIn tyre and Davie s ( 2003 ) did rep ort a b etter mis- classification rate (6.1%) using factorial discriminant analysis (FD A), but the c hoice of a subset of wa vele ngths, d ata p repro cessing metho d and clas- sification metho d (from partial le ast squares, facto rial discriminant analysis and k -nearest neigh b ors) was made with reference to the test data classifi- cation p erformance. In con tr ast, our mo del select ion w as done without any reference to the test data classification p erformance. A cross tabulation of the classifications with the true origin of the oliv e oils (T able 8 ) rev eals the difficult y in classifying the oils. In con trast to the meat classificatio n p r oblem, the c hosen w av elengths for this p roblem (Figure 9 ) are concen trated in the near-infrared r egion (800– 2498 nm), b ut some w av elengths in the visible region are also selected. The most commonly chosen wa velength is 2080 n m, wh ic h has b een attributed to an O-H stretc h ing/O-H b end com b ination [Osb orne et al. ( 1984 )]. W a ve- lengths near 2310, 2346 and 2386 nm are due to C-H str etching vibrations and other vibrational mod es. I n particular, wa v elengths in the 231 0 nm r e- gion hav e previously b een assigned to fat cont en t. In all cases, b et ween 6 and 29 w a vele ngths w ere selected, with a mean of 15 w a v elengths b eing c hosen. The EEE co v ariance structure w as c hosen for every fin al mo d el for the oliv e oil cla ssification problem. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 21 4.3. Sensitivity to sp e ctr al r esolution. In order to determine the sensitiv- it y of the selected w av elengths to the resolution of the sp ectrometer used in this study , we inv estigated th e effect of r ed ucing the n u m b er of reflectance v alues b y computing the mean reflectance v alue ov er sets of adjacen t w av e- lengths and using th ese as inputs in to the v ariable selec tion mo del. The results of this analysis are outlined for the olive oil authen tication problem, and similar results were found for the meat sp ecies authentici t y stu dy . W e found that the classification error of the oliv e oil samp les increases sligh tly as so on as an y adjacen t w a vel engths are aggregated (T able 9 ). Ho w - ev er, once the w av elengths are ag gregated, the classifica tion err or remained steady for agg regating b et w een 2 and 30 adjacen t w a v elengths. Thereafter, there wa s a s erious deterioration in the classification p erformance w hen more than 30 adjacen t wa vel engths were aggrega ted. This suggests th at a consid er- T able 7 Classific ation p erformanc e on the Olive Oil data for the variable sele ction algorithm with up dating and f or pr evious analyses of these data. Me an classific ation p erformanc e for the 50 r andom splits of th e data ar e r ep orte d with st andar d deviations in p ar entheses. F or the variable sele ction only r esults, the maximum numb er of sele cte d wavelengths was r estricte d to b e six t o avoid de gener acies Metho d Misclassification rate V ariable selection and up dating 6 . 9% (5 . 4) V ariable selection ( greedy ) and up d ating 16 . 6% (11 . 3) V ariable selection only 17 . 9% (10 . 9) Dean, Murphy an d Do wney ( 2006 ) 11 . 9% (6 . 3) Dow n ey , McInt y re and Davies ( 2003 ) 6 . 1%–19 . 0% T ransductive S VMs 12 . 4% (7 . 5) Random F orests 19 . 3% (6 . 5) AdaBoost.M1 34 . 1% (9 . 3) Ba yesian Multinomial Regress ion 57 . 0% (1 . 2) T able 8 Av er age classific ation r esults for the olive oil gr oups. The r esults shown ar e for the variable sele ction and up dating metho d Predicted T ruth Crete Peleponese Other Crete 90 . 0 8 . 7 1 . 3 P eleponese 1 . 0 92 . 9 6 . 1 Other 0 . 0 3 . 8 96 . 2 22 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y T able 9 The chang e in cl assific ation p erformanc e for the variable sele ction and up dating metho d as the numb er of adjac ent wavelengths b eing aggr e gate d i ncr e ases Aggregation lev el Classification error 1 6 . 9% 2 9 . 7% 3 7 . 6% 5 7 . 9% 10 9 . 9% 15 8 . 5% 30 9 . 1% 50 13 . 2% 70 28 . 7% able amount of th e group information is main tained at ev en lo w resolutions, but th at there is more information in the ra w d ata themselv es. The sp ectral regions select ed w hen analyzing the data in aggrega ted form w ere found to b e s table. In b oth app licatio ns, the sele cted regi ons w ere v ery similar for the aggregated data, b ut few er v ariables tended to b e selected b ecause of the agg regation pro cess. Fig u re 10 s h o ws the chosen wa v elengths when the ra w sp ectra, t wo adjacen t wa velengt hs and three adjacen t wa ve- lengths are aggregat ed and then analyzed for the oliv e oil classificat ion prob- lem. This sh o ws that the selection p ro cedure c h o oses very sp ecific sp ectral regions on b oth the ra w and aggregated scale. Fig. 9. Wavelengths chose n in the olive oil classific ation pr oblem using the variable se- le ction and up dating met ho d. The height of the b ars shows how many times the wavelength was chos en in 50 r andom splits of the data. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 23 Fig. 10. The chose n wavelength s when the r aw olive oil sp e ctr a ar e analyze d and when adjac ent wavelengths ar e aggr e gate d. 5. D iscussion. The discriminant analysis metho d p resen ted in this pa- p er ga v e m uch b etter results th an those given by p opular statistical and mac hine learning tec hniques suc h as Random F orests [Breima n ( 2001 )], Ad- aBoost [F r eund and Sc hapire ( 1997 )] and Ba y esian Multinomial Regression [Genkin, Lewis and Madigan ( 2005 ), Madigan et al. ( 20 05 )] and T ransduc- tiv e SVMs [V apnik ( 1995 ), Joac h ims ( 1999 )] for the high-d im en sional fo o d authen ticit y d ata sets analysed here. T h is impro vemen t is further enhanced b y the add ition of the up dating pr o cedure for including the unlab eled data in the estimation metho d. Th e results sho w th at the headlong searc h metho d for v ariable selectio n is an efficie n t metho d for selecting w a velengt hs. In addition to the improv emen t in classification results in the example data sets give n, th e num b er of v ariables needed for classification w as sub- stan tially reduced from 1050 to less than thirt y . Th e v ariable s election resu lts in the f o o d authentic ity applicat ion su ggest the p ossibilit y of dev eloping au- then ticit y sens ors th at only us e reflectance v alues ov er a carefully selected subset of the near-infrared and visible sp ectral range. T he regions of the sp ectrum select ed b y the metho d can b e inte rpreted in terms of the under- lying chemical prop erties of the fo o ds under analysis. W e ha v e compared ou r metho d with four established leading classification metho ds from statistics and mac hine learning for which standard soft w are implemen tations are av ailable. One of these, AdaBo ost, was identified by Leo Breiman as “the b est off-the-shelf classifier in the w orld ” [Hastie, Tibshir ani and F riedman ( 2001 )]. It is p ossible that the large imp ro vemen t in p erfor- mance of our metho d relati v e to the established methods w e ha v e compared it with is due to the fact that our data h a ve man y v ariables of whic h only a 24 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y v ery small prop ortion (1%–3 % ) are usefu l. Th e v ariables that are not useful ma y in tro duce a great d eal of noise and degrade p erformance, and s o other metho ds that do not reduce the n u m b er of v ariables ma y suffer fr om this. Although the method s w ere dev elop ed for the fo o d authen ticit y applica- tion outlined herein, the metho d could b e applied in con texts such as the analysis of gene exp ression data and do cument classificatio n. The results of the v ariable selection pr o cedure could m ean a su bstan tial sa vings in terms of time for data coll ection and space for futur e d ata storage. A range of recen t app roac hes to v ariable s electio n in a classificati on con- text include the D ALAS S approac h of T r endafilo v and Jolliffe ( 2007 ), v ari- able s electio n for k ernel Fisher d iscriminan t analysis [Lou w and S teep ( 2006 )] and the stepwise stopping ru le approac h of Mu nita, Barroso and Oliv eira ( 2006 ). A num b er of different searc h algorithms (prop osed as alternativ es to bac kward/forw ard /stepwise searc h) wrapp ed around different discr im i- nan t functions are compared by Pa c heco et al. ( 2006 ), and genetic search algorithms wrapp ed around Fisher discriminan t analysis are considered by Chiang and P ell ( 2004 ). Another example of v ariable selectio n metho ds in the con text of classification using sp ectroscopic data is giv en b y In dahl and Naes ( 2004 ). In terms of other approac h es to v ariable s electio n, a go o d review of re- cen t wo rk on the problem of v ariable or feature selection in classification wa s giv en b y Guyon and Elisseeff ( 2003 ) fr om a mac h ine learning p ers p ectiv e. A go o d r eview of method s in volving Sup p ort V ector Mac hines (SVMs) (along with a prop osed criterion for exh austiv e v ariable selection) is give n b y Mary- Huard, Robin and Daudin ( 2007 ). An extension allo win g v ariable selection for the m u lticlass problem u sing SVMs is given by W ang and Xiatong ( 2007 ). An alte rnativ e approac h for com bining pairwise classifiers, b ased on Hastie and Tibshirani ( 1998 ), is giv en b y Szepannek and W eihs ( 200 6 ). Greensh tein ( 2006 ) lo oks at theoretical asp ects of the n ≪ p classification and v ariable selection p r oblem in terms of emp ir ical risk minimization su b ject to l 1 con- strain ts. Finally , an alternative to single subset v ariable selection through Ba y esian Mod el Av eraging [Madigan and Raftery ( 1994 )] is give n b y Dash and Co op er ( 2004 ). Ac kn owledgmen ts. W e w ould lik e to thank the Editor, Asso ciate Editor and Referees w hose suggestio ns greatly impro ved this pap er. W e w ould also lik e to thank Gerard Do wney for pro vidin g the fo o d authenticit y d ata and for help with interpreting the results of the analysis. SUPPLEMENT AR Y MA TERIAL Supp lemen t: Data (DOI: 10.1214 /09-A OAS279SUPP ; .zip). Th is zipfile [Murphy , Dean and Raftery ( 2009 )] conta in s the data sets u sed in this p ap er. The original data source information and conditions for the use of the d ata are outlined in th is file. V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 25 REFERENCES Arnalds , T., McEl hinney , J., Fea rn , T. and Do wney , G. (2004). A hierarchical dis- criminan t analysis for sp ecies identification in raw meat by visible and near infrared sp ectroscopy . Journal of Ne ar Infr ar e d Sp e ctr osc opy 12 183–188. Badsberg , J. H. (1992). Mo del search in contingency t ables by CoCo. I n Computational Statistics (Y. Do dge and J. Whittak er, eds.) 1 25 1–256. Physica, Heidelb erg. Banfield , J. D. and Rafter y , A. E. ( 1993). Mo del-based Gaussian and non-Gaussian clustering. Biometrics 49 803–821. MR1243494 Bensmail , H. and Celeu x , G. (1996). Regularized Gaussian discriminant analysis through eigen val ue decomp osition. J. Amer. Statist. Asso c. 91 17 43–1748 . MR1439118 Breiman , L. (2001). Random F orests. Mach. L e arn. 45 5–32. Chang , W.-C. (1983). On using principal comp onents b efore separating a mixture of tw o multiv ariate normal distributions. J. R oy. Stat ist. So c. Ser. C. 32 267–275. MR0770316 Chapelle , O., S ch ¨ olk opf , B. and Zien , A. (2006). Semi-Sup ervise d L e arning . MI T Press, Cam b rid ge. Av ailable at http://www .kyb.tueb ingen.mpg .de/ssl- b ook . Chiang , L. H. and Pell , R . J. ( 2004). Genetic algorithms combined wi th discriminan t analysis for key v ariable identification. J. Pr o c ess Contr ol 14 143–155. Collober t , R., Sinz , F., Weston , J. and Bottou , L. (2006). Large scale transductive SVMs. J. Mach. L e arn. R es. 7 16 87–1712 . MR227442 1 Connoll y , C. (2006). Sp ectroscopic and Analytical Develo pments Ltd fingerprints brand spirits with u ltra violet sp ectrophotometry . Sensor R eview 26 94–97. Cor t ´ es , E. A., Mar t ´ ınez , M. G. and Rubio , N. G. (2007). adabag : Applies adabo ost.M1 and bagging. R pac k age version 1.1. Dash , D. and Cooper , G. F. (2004). Mo del av eraging for prediction with d iscrete Bay esian netw orks. J. Mach. L e arn. R es. 5 11 77–1203 . MR2248014 Dean , N., Murphy , T. B. and Dow ney , G. (2006). Using unlab elled data to up date classification rules with applications in foo d authentici ty studies. J. R oy. Statist. So c. Ser. C 55 1–14. MR2224157 Dempster , A. P ., Laird , N. M. and Rubin , D. B. (1977). Maximum likelihoo d from incomplete data v ia the EM algorithm (with discussion). J. Ro y. Stat i st. So c. Ser. B 39 1–38. MR0501537 Do wne y , G. (1996). Authentication of fo o d and food ingredien ts by near infrare d sp ec- troscop y . Journal of Ne ar Infr ar e d Sp e ctr osc opy 4 47–61. Do wne y , G., McIntyre , P . and Da vies , A. N. (2003). Geographical classification of ext ra virgin olive oils from the eastern Mediterranean by chemometric analysis of visible and near infrared sp ectroscopic data. Applie d Sp e ctr osc opy 57 158– 163. Fraley , C. and Rafter y , A. E. (1998). Ho w many clusters? Whic h clustering metho d? Answers v ia model-based cluster anal ysis. Computer Journal 41 57 8–588. Fraley , C. and Rafter y , A. E. (1999). MCLUS T: Soft wa re for mo del-based clustering. J. Classific ation 16 297–306. Fraley , C. and Rafter y , A. E. (2002). Model-based clustering, discriminant analysis, and density estimation. J. A mer. Statist. Asso c. 97 611–6 31. MR1951635 Fraley , C. and Ra fter y , A. E. (2003). Enhanced mo del-based clustering, density es- timation and discriminant analysis softw are: MCLUST. J. Classific ation 20 263–296. MR2019797 Fraley , C. and Rafter y , A. E. (2007). mclust : Mo del-based clustering/normal mixture mod eling. R pac k age version 3.1-1. Freund , Y. and Schapire , R. E. (1997). A decision-theoretic generalization of on-line learning and an application t o b o osting. J. Comp. System Sci. 55 119–139. MR1473055 26 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y Ganesalingam , S. and McLachl an , G. J. (1978). The efficiency of a linear discriminant function based on u nclassified initial samples. Biometrika 65 658–662. MR0521834 Genkin , A., Lewis , D. D. and Madigan , D. (2005). BMR: Bay esian multinomial regres- sion softw are. Avai lable at http://www .stat.rut gers.edu/ ~ madigan/BM R/ . Greenshtei n , E. (2006). Best subset selection, p ersistence in high- dimensional statistical learning and optimization u n der l 1 constrain t. Ann. Statist. 34 2367–2 386. MR2291503 Guyon , I. and Elissee f f , A. (2003). An in tro duction to v ariable and feature selection. J. Mach. L e arn. R es. 3 1157 –1182. Hastie , T. and Tibshira ni , R. (19 98). Classification by p airwise coupling. A nn. Statist . 26 451–471. MR1626055 Hastie , T., Tibshirani , R. and Friedman , J. H. (2001). The Elements of Statistic al L e arning . S pringer, New Y ork. MR1851606 Hoos , H. H . and St ¨ utzle , T. (2005). Sto chastic L o c al Se ar ch: F oundations and Applic a- tions . Morgan K aufmann, San F rancisco. Indahl , U. and Na e s , T. (2004). A vari able selection strategy for sup ervised classification with contin uous spectroscopic d ata. Jou rnal of Chemomet rics 18 53–61. Jo achims , T. (1999). T ransductive infere nce fo r text classification using supp ort vector mac hines. In ICML’99: Pr o c e e dings of the Sixte enth International Conf er enc e on Ma- chine L e arning 200–209 . Mor gan Kaufmann, San F rancisco. Ko h a vi , R. and John , G. (1997). W rapp ers for feature selection. Art i ficial Intel ligenc e 91 273–324 . Liang , F., Mukherjee , S. and West , M. (2007). The use of unlab eled data in predictive mod eling. Stat ist. Sci. 22 189–205. MR2408958 Lia w , A. and Wi ener , M. (2002). Classification and regression by randomForest . R News 2 18–22. Liu , Y. and Ch e n , Y. R. (2000). Tw o-dimensional correla tion spectroscopy stud y of vis- ible and near-infrared sp ectral va riations of chic ken meats in cold storage. Applie d Sp e ctr osc opy 54 1458–14 70. Liu , Y., Chen , Y. R. and Ozaki , Y. (2000). Two-dimensional visible/near infrared corre- lation sp ectroscopy study of thermal treatment of chic ken meat. Journal of A gricultur al and F o o d Chemistry 48 901–90 8. Louw , N. and S teep , S . J. (2006). V ariable selection in kernel Fisher discriminan t analysis by means of recursiv e fea ture elimination. Comput. Statist. Data A nal. 51 2043–20 55. MR2307560 Madigan , D. and R after y , A. E. (1994). Mo del selection and accounting for mo del uncertaint y in graphical mo dels using Occam’s windo w. J. Amer. Statist. Asso c. 89 1535–15 46. Madigan , D., G enkin , A., Lewis , D. D. and Fradkin , D. ( 2005). Ba yesian multinomial logistic regression for author identification. In Bayesian Infer enc e and Maximum En- tr opy M etho ds i n Sci enc e and Engine ering ( K. H. Knuth, A. E. Abbas, R. D. Morris and J. P . Ca stle, eds.). AIP Conf. Pr o c. 803 509–51 6. Institute of Physics, Lond on. Mar y-Huard , T., Robin , S. and D audin , J.-J. (2007). A p enalized criterion for v ariable selection in classification. J. Multivariate A nal. 98 695–705. MR2322124 McElhinney , J., Downey , G. and Fearn , T. (1999). Chemometric processing of visi- ble and near infrared reflectance sp ectra for sp ecies iden tification in selected raw ho- mogenised meats. Jour nal of Ne ar Infr ar e d Sp e ctr osc opy 7 145–154. McLachl an , G. J. (1992). Discriminant Analys is and Statistic al Pattern R e c o gnition . Wiley , New Y ork. MR1190469 McLachl an , G. J. and Peel , D. (2000). Finite Mixtur e Mo dels . Wiley , New Y ork. MR1789474 V ARI ABLE SELECTION AND UPDA TING IN DISCRIMI N ANT ANAL Y SIS 27 Munit a , C. S., Barroso , L. P . and Oliveira , P . M. S. (2006). Stopping rule for v ariable selection using step wise discriminan t an alysis. Journal of R adio analytic al and Nucle ar Chemistry 269 335–338. Murphy , T. B., Dean , N. and Rafter y , A. E. (2009). Supplement to “V ariable selection and u p dating in mo del-based discriminant analysis for h igh dimensional data with foo d authenticit y applications.” DOI: 10.1214 /09-A OAS279SUPP . O’Neill , T. J. (1978). N ormal d iscrimination with unclassified observ ations. J. Amer. Statist. Asso c. 73 821–82 6. MR0521330 Osborne , B. G., Fearn , T. and Hindle , P . H. (1993). Pr actic al NIR Sp e ctr osc opy With Applic ations in F o o d and Bever age Analysis . Longman Scien tific & T echnical, Harlow , UK. Osborne , B. G., Fearn , T., Miller , A. R. and Douglas , S. (1984). A pplication of n ear infrared reflectance sp ectroscopy to the comp ositional an alysis of biscuits and biscuit doughs. Journal of the Scienc e of F o o d and A gricultur e 35 99 –105. P a ch e co , J., Casado , S., N ´ u ˜ nez , L. and G ´ omez , O. (2006). Analysis of new vari able selection metho ds for discriminant analysis. C omput. Statist. Data Anal. 51 1463–1478. MR2307519 R Development Core Team (2007). R: A L anguage and Envir onment for Statistic al Computing . R F oundation for Statistical Co mputing. Vienna, Austria. Rafter y , A. E. and De an , N. (2006). V ariable selection for mo del-based clustering. J. Amer . Statist. Asso c. 101 168– 178. MR2268036 Reid , L. M., O’Donnell , C. P . and Do wne y , G. (2006). R ecent tec hn ological adv ances in the determination of food authenticit y . T r ends in F o o d Scienc e and T e chnolo gy 17 344–353 . Schw arz , G. (1978). Estimating the dimension of a mo del. Ann. Statist. 6 461–464 . MR0468014 Sinz , F. and Roffilli , M. (2007). U niverSVM soft ware. V ersion 1.1. Ava ilable at http://mlo ss.org/so ftware/view/19/ . Szep annek , G. and Weihs , C. (2006). V ariable selection for discrimination of more t h an tw o classes where data are sparse. In F r om D ata and Information Analysis to Know le dge Engine ering (M. Sp iliopoulou, R. Kru se, C. Borgelt, A. Nurnb erger and W. Gaul, eds.) 700–707 . Springer, Berlin. Toher , D ., Do wney , G. and Murphy , T. B. (2007). A comparison of model-based and regression cla ssification techniques applied to near infrared sp ectroscopic data in fo od authentication studies. Chemometrics and Intel ligent L ab or atory Systems 89 102–115. Trendafilo v , N. T. and Jolliffe , I. T. (2007). DALASS: V ariable selection in discrim- inant analysis via the LAS S O. C omput. Statist. Data Anal. 51 3718–3 736. MR2364486 V apni k , V . (1995). The Natur e of Statistic al L e arning The ory , 2nd ed. S pringer, New Y ork. MR1367965 W ang , L. and Xia tong , S. (2007). On L 1 -norm multiclass supp ort vector machines: Method ology and theory . J. A m er. Statist. Asso c. 10 2 583–594. MR2370855 West , M. (2003). Ba yesian factor regression models in th e “large p , sma ll n ” paradigm. In Bayesian Statistics 7 723–7 32. Oxford Univ. Press, Oxford. MR2003537 Yeung , K. Y., Bumga rn er , R . and Rafter y , A. E. (2005). Bay esian mod el av erag- ing: Dev elopment of an impro ved multi-class, gene selection and classi fication to ol for microarra y data. Bioinformatics 21 2394–240 2. 28 T. B. MURPH Y, N. DEAN AND A. E. RAFTER Y T. B. Murphy School of Ma thema tical Sciences University College Dublin Belfield, Dublin 4 Ireland E-mail: brendan.m urph y@ucd.ie N. Dean Dep ar tment of St a tistics University of Glasgow Glasgow, G 12 8QQ United Kingdom E-mail: nema@stats.gla.ac.uk A. E. Rafter y Dep ar tment of St a tistics University of W ashing ton, Sea ttle Box 3 54320 Sea ttle, W ashing ton 98195-43 2 0 USA E-mail: raftery@stat.w ashington.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment