Towards a stable definition of Kolmogorov-Chaitin complexity
Although information content is invariant up to an additive constant, the range of possible additive constants applicable to programming languages is so large that in practice it plays a major role in the actual evaluation of K(s), the Kolmogorov-Cha…
Authors: Jean-Paul Delahaye, Hector Zenil
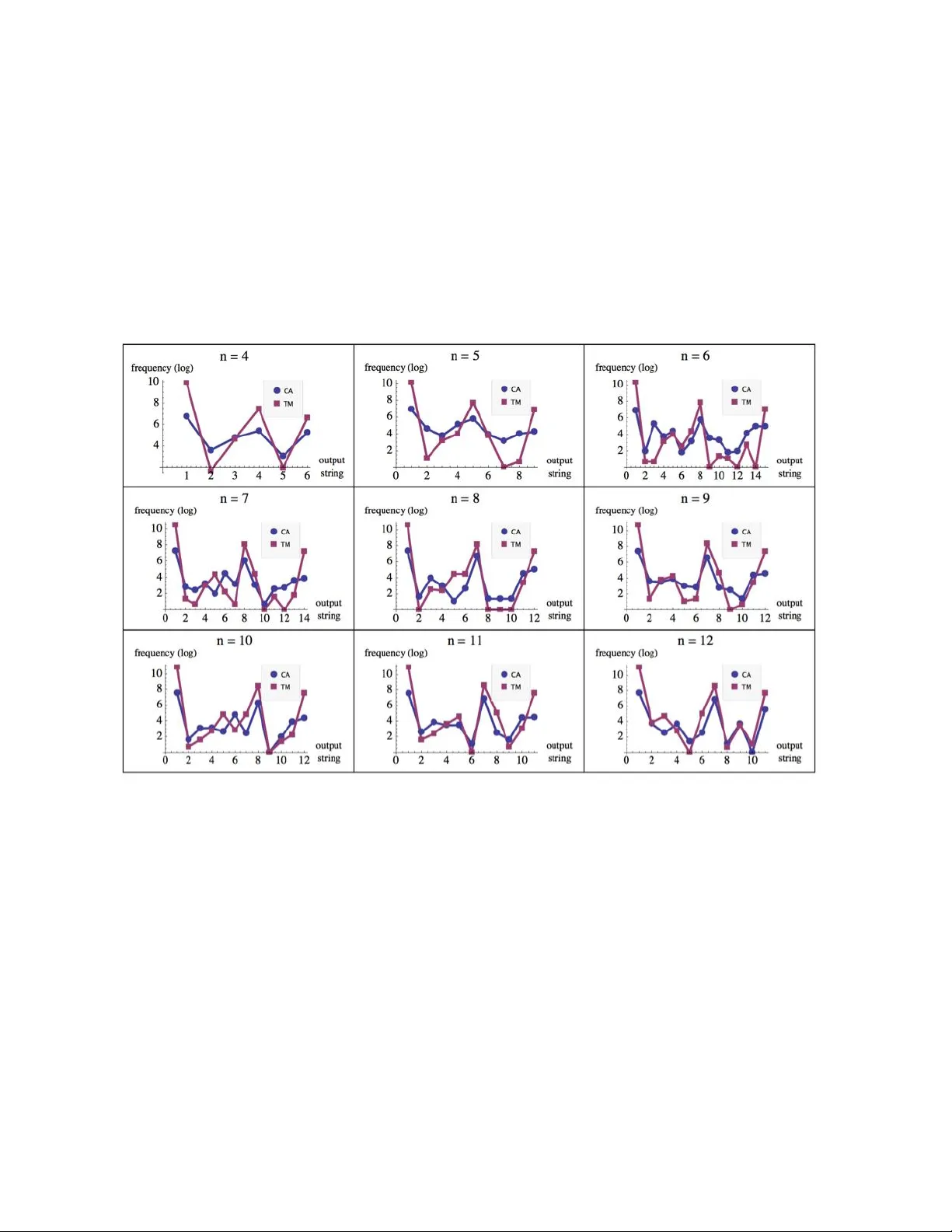
Fundamenta Informaticae XXI (2008) 1–15 1 IOS Pr ess T owards a stable definition of K olmogor ov-Chaitin complexity Jean-P aul Delahaye Laboratoir e d’Informatique F ondamentale de Lille (CNRS) jean-paul.delahaye@lifl.fr Hector Zenil ∗ Laboratoir e d’Informatique F ondamentale de Lille (CNRS) Institut d’Histoir e et de Philosophie des Sciences et des T echniques, (CNRS, ENS, Universit ´ e P aris 1) Carne gie Mellon University hector .zenil@lifl.fr , hector .zenil-chavez@malix.univ-paris1.fr , hectorz@andr ew .cmu.edu Abstract. Although information content is in v ariant up to an additiv e constant, the range of pos- sible additi ve constants applicable to programming languages is so large that in practice it plays a major role in the actual e v aluation of K ( s ) , the K olmogorov-Chaitin complexity of a string s . Some attempts ha ve been made to arri ve at a framew ork stable enough for a concrete definition of K , in- dependent of any constant under a programming language, by appealing to the naturalness of the language in question. The aim of this paper is to present an approach to overcome the problem by looking at a set of models of computation con v erging in output probability distribution such that that naturalness can be inferred, thereby providing a frame work for a stable definition of K under the set of con ver gent models of computation. Keyw ords: algorithmic information theory , program-size complexity . 1. Intr oduction W e will use the term model of computation to refer both to a T uring-complete programming language and to a specific de vice such a univ ersal T uring machine. ∗ Some of the ideas contained in this paper were de veloped during the stay of H. Zenil’ s tenure as a visiting scholar at Carne gie Mellon Univ ersity . He wishes to thank Jeremy A vigad for his support and Ke vin Kelly for his v aluable comments and suggestions. 2 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity The term natural for a T uring machine or a programming language has been used within sev eral contexts and with a wide range of meanings. Many of these meanings are related to the expressi ve se- mantic frame work of a model of computation. Others refer to how well a model fits with an algorithm implementation. Previous attempts have been made to arriv e at a model of computation stable enough to define the Kolmogoro v-Chaitin complexity of a string independent of the choice of programming lan- guage. These attempts have used, for instance, lambda calculus and combinatory logic[9, 13] appealing to their naturalness . W e provide further tools for determining whether approaches such as these are natural to produce the same relati ve K olmogorov-Chaitin measures. Our approach is an attempt to make precise such appeals to the term natur al related to the K olmogorov-Chaitin complexity , and to provide a frame work for a stable definition of K independent enough of additive constants. Definition The Kolmogoro v-Chaitin complexity K u ( s ) of a string s with respect to a univ ersal T uring machine U is defined as the binary length of the shortest program p that produces as output the string s . K u ( s ) = { min ( | p | ) , U ( p ) = s } A major drawback of K is that it is uncomputable[1] because of the undecidability of the halting problem. Hence the only way to approach K is by compressibility methods. A major criticism brought forward against K (for example in[7]) is its high dependence of the choice of programming language. 2. Dependability on additiv e constants The following theorem tells us that the definition of Kolmogoro v-Chaitin complexity makes sense e ven when it is dependent upon the programming language: Theorem (invariance) If L 1 and L 2 are two T uring machines and K L 1 ( s ) and K L 2 ( s ) the K ol- mogorov - Chaitin complexity of a binary string s when L 1 or L 2 are used respecti vely , then there e xists a constant C L 1 ,L 2 such that for all binary string s : | K L 1 ( s ) − K L 2 ( s ) | < C L 1 ,L 2 In other terms, there is a program p 1 for the uni versal machine L 1 that allows L 1 to simulate L 2 . This p 1 is usually called an interpreter or compiler in L 1 for L 2 . Let p 2 be the shortest program producing some string s according to L 2 . Then the result of chaining together the programs p 1 and p 2 generates s in L 1 . Chaining p L 2 onto p 1 adds only constant length to p 2 , so there exists a constant C that bounds the difference in length of the shortest program in L 1 from the length of the shortest program in L 2 that generates the arbitrary string s . Ho wev er , the constants in volved can be arbitrarily lar ge so that one can e ven af fect the relati ve order relation of K under two different universal T uring machines such that if s 1 and s 2 are two different strings and K ( s 1 ) < K ( s 2 ) one can construct an alternativ e univ ersal machine that not only changes the v alues for K ( s 1 ) and K ( s 2 ) b ut re verses the relation order to K ( s 1 ) > K ( s 2 ) . One of the first conclusions drawn from algorithmic information theory is that at least one among the 2 n binary strings of length n will not be compressible at all. That is because there are only 2 n − 1 binary programs shorter than 2 n . In general, if one wants to come up with an ultimate compressor one JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 3 can compress the length of ev ery string by c bits with 2 n − c length descriptions. It is a straightforward conclusion that no compressing language can arbitrarily compress all strings at once. The strings a language can compress depend on the language used, since any string (even a random-looking one) can in some way be encoded to shorten its description within the language in question e ven if a string compressible under other languages turns out to be incompressible under the new one. So one can always come up with another language capable of effecti vely compressing any gi ven string. In other terms, the v alue of K ( s ) for a fix ed s can be arbitrarily made up by constructing a suitable programming language for it. Howe ver , one would wish to a void such artificial constructions by finding distinguished programming languages which are natural in some technical sense–rather than tailor-made to fav or any particular string– while also preserving the relative v alues of K for all (or most) 2 n binary strings of length n within an y programming language sharing the same order-preserving property . As suggested in [7], suppose that in a programming language L 1 , the shortest program p that gener- ates a random-looking string s is almost as long as s itself. One can specify a new programming language L 2 whose uni versal machine U 2 is just like the univ ersal machine U 1 for L 1 except that, when presented with a very short program p 2 , U 2 simulates U 1 on the long program p , generating s. In other words, the complexity of p can be ”b uried” inside of U 2 so that it does not sho w up in the U 2 program p 2 that generates s . This arbitrariness makes it hard to find a stable definition of Kolmogoro v-Chaitin complex- ity unless a theory of natural programming languages is provided which is unlike the usual definition in terms of an arbitrary , Turing-complete programming language. For instance, one can conceiv e of a univ ersal machine that produces certain strings very often or very seldom, despite being able to produce any conceiv able string giv en its univ ersality . Let’ s say that a uni versal T uring machine is tailor-made to produce much fe wer (0) n strings than any other string in s ∈ { 0 , 1 } n . By follo wing the relation of K olmogorov-Chaitin complexity to the universal distribution[11, 8] m ( s ) = 1 / 2 K ( s )+ O (1) one would conclude that for the said tailor-made construction the string (0) n is of greater K olmogorov-Chaitin complexity than an y other , which may seem counterintuitive. This is the kind of artificial constructions one would prefer to av oid, particularly if there is a set of programming languages for which their output distributions con ver ge, such that between two natural programming languages the additi ve constant remains small enough to make K in v ariant under the encoding from one language to the other , thus yielding stable values of K . The issue of dependence on additive constants often comes up when K is ev aluated using a particular programming language or univ ersal Turing machine. One will always find that the additi ve constant is large enough to produce very dif ferent values. This is e ven worst for short strings, shorter for instance compared to the program implementation size. One way to overcome the problem of the calculation of K for short strings was suggested in [2, 3]. It in volv ed building from scratch a prior empirical distribution of the frequency of the outputs according to a formalism of uni versal computation. In these e xperiments, some of the models of computation explored seemed to con ver ge, up to a certain degree, leading to propose a natural definition of K for short strings. That was possible because the additive constant up to which the output probability distributions con ver ge has a lesser impact on the calculation of K , particularly for those at the top of the classification (thus the most frequent and stable strings). This would make it possible to establish a stable definition and calculation of K for a set of models of computation identified as natural for which K ( s ) relati ve orders are preserv ed e ven for lar ger strings. Our attempt differs from pre vious attempts in that the programs generated by different models may produce the same relati ve K despite the programming language or the uni versal T uring machine being necessarily compact in terms of size. This is what one would expect for a stable definition of K to work 4 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity with e ven if there were still some additi ve constants in volv ed. 3. T owards a stable definition of K The experiment described in detail in [2] proceeded by analyzing the outputs of two different models of computation: deterministic T uring machines ( T M ) and one-dimensional cellular automata ( C A ). Some follo wed methods and techniques for enumerating, generating and performing exhausti ve searches are suggested in further detail in [14]. The T uring machine ( T M ) model, represents the basic frame work underlying many concepts in computer science, including the definition of Kolmogoro v-Chaitin com- plexity , while cellular automaton, has been largely studied as a particular interesting model also capable of universal computation. The descriptions for both T M and C A followed standard formalisms com- monly used in the literature. The T uring machine description consisted of a list of rules (a finite program) capable of manipulating a linear list of cells, called the tape , using an access pointer called the head . The directions of the tape are designated right and left . The finite program can be in any one of a finite set of states Q numbered from 1 to n with 1 the state at which the machine starts its computation. There is a distinguished n + 1 state called the halting state at which the machine halts. Each tape cell can contain a 0 or 1 (there is no special blank character). Time is discrete and the time instants (steps) are ordered from 0 , 1 , . . . with 0 the time at which the machine starts its computation. At any time, the head is positioned ov er a particular cell. At time 0 the head is situated on a distinguished cell on the tape called the start cell, and the finite program starts in the state 1. At time 0 all cells contain the same symbol, either 0 or 1. A rule can be written in a 5 -tuple notation as follo ws { s i , k i , s i +1 , k i +1 , d } , where s i is the scanned symbol under the head, k i the state at time t , s i +1 the symbol to write at time t + 1 , k i +1 and d the head mov ement either to the right or to the left at time t + 1 . As usual a T uring machine can perform the follo wing operations: 1. write an element from A = { 0 , 1 } . 2. shift the head one cell left or right. 3. change the state of the finite program out of Q . And when the machine is running it executes the above operations at the rate of one operation per step. At the end of a computation the T uring machine has produced an output described by the contiguous cells in the tape ov er which the head went through. An analogous standard description of a one-dimensional cellular automata was followed. A one- dimensional cellular automaton is a collection of cells on a grid that e volv es through a number of discrete time steps according to a set of rules based on the states of neighboring cells that are applied in parallel to each row over time. In a binary cellular automaton, each cell can take only one among two possible v alues (0 or 1). When the cellular automaton starts its computation, it applies the rules at row 0. A neighborhood of m cells means that the rule takes into consideration the value of the cell itself, m cells to the right and m cells to the left in order to determine the v alue of the next cell at ro w n + 1 . For the T uring machines the experiments were performed ov er the set of 2-state 2-symbol T uring machines, henceforth denoted as T M (2 , 2) . There are 4096 different T uring machines according to the description gi ven abo ve and the deri ved formula (2 sk ) sk from the traditional 5 -tuplet rule description of a T uring machine. It was then let all the machines run for t steps each and proceeded to feed each with an empty tape with 0 and once again with an empty tape filled with 1. It was proceeded in the same fashion for cellular automata with nearest-neighbor taking a single 1 on a background of 0 s and a single start cell 0 on a background of 1 s, henceforth denoted by C A (1) . There are 2 × 2 × 2 = 2 3 = 8 possible binary states for the three cells neighboring a gi ven cell, there are a total of 2 8 = 256 elementary cellular automata or E C A . JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 5 Figure 1. The experiments can be summarized by looking at the abov e diagram comparing two output probability distributions for strings of length n = 3 , after t = n × 10 = 30 steps. Matching strings are linked by a line. As one can observe, in spite of certain crossings, T M (2 , 2) and C A (1) seem to be strongly correlated and both group the output strings by reversion and complementation symmetries. By taking the six groups–marked with brackets–both probability distributions mak e a perfect match. In [2] we pro vide another example for strings length n = 4 . Let s ( T M ( i ) , m ) and s ( C A ( j ) , m ) be the two sets of output strings produced by the i -th Turing machine and the j -th cellular automaton respectiv ely , after m steps according to an enumeration for T uring machines and cellular automata, a probability distribution was built as follo ws: the sample space associated with the experiment is S = { s | s ∈ { 0 , 1 } n } since both s ( T M ( i ) , m ) and s ( C A ( j ) , m ) are sets of binary strings. Let’ s call S the set of outputs either from s ( T M ( n ) , m ) or s ( C A ( n ) , m ) . For each s ∈ S the space of the random variable X ∈ S is { 0 , 1 } n . For a discrete variable X , the probability P r ( X = s ) means the probability f ( x ) of the random variable X to produce the substring s . Let D ( X ) = { s t , f ( s t ) } such that for all s i ∈ S , f ( s t ) > f ( s t +1 ) . f ( x ) is the probability of s to be produced. In other words, D ( X ) is the set of tuples of a string follo wed by the probability of that that string to be produced by a T uring machine or a cellular automata after m = 10 n steps. 3.1. Output probability distrib ution D(X) D ( X ) is a discrete probability distribution since Σ u P r ( X = s ) = 1 , as u runs through the set of all possible values of X , for a set of finite number of possible binary strings, and the sum of all of them is exactly 1. D ( X ) simply denoted as D from no w on was calculated in [2] for two sets of T uring machines and cellular automata with small state and symbol v alues up to certain string length n . In each case D was found to be stable under sev eral variations such as number of steps and sample sizes, allowing to define a stable distrib ution D for each, denoted from now on as D T M for the distribu- tion of T uring machines and D C A for the distribution from cellular automata. 6 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 3.2. Equivalence of complexity classes The application of a widely used theorem in group theory may provide further stability , getting rid of crossings due to exchanged strings, with dif ferent strings probably having the same K olmogorov- Chaitin complexity but biasing the rank comparisons. Desirably , one would have to group and weight the frequency of the strings with the same expected complexity in order to measure the rank correlation without any additional bias. Consider, for instance, two typical distributions D 1 and D 2 for which the calculated frequenc y ha ve placed the strings (0) n and (1) n at the top of D 1 and D 2 respecti vely . If the ranking distance of both distributions is then calculated, one might get a biased measurement due to the exchange of (0) n with (1) n despite the fact that both should ha ve, in principle, the same Kolmogoro v- Chaitin complexity . Therefore, we want to find out how to group these strings such that after comparison they do not af fect the rank comparison. The P ´ olya-Burnside enumeration theorem[10] makes possible to count the number of discrete com- binatorial objects of a given type as a function of their symmetrical cases was used. W e have found that experimentally symmetries that are supposed to preserv e the K olmogorov-Chaitin comple xity of a string are rev ersion ( r e ) , complementation ( co ) and the compositions from them ( cosy ( s ) and sy co ( s ) ). In all the distrib utions b uilt from the experiments so far we hav e found that strings always tend to group them- selves in contiguous groups with their complemented and reversed v ersions. That is also a consequence of the setting up of the experiments since each T uring machine ran from an empty tape filled with zeros first and then again with an empty tape filled with ones in order to av oid any antisymmetry bias. Each cellular automata ran starting with a 0 in a background of ones and once again with a 1 in a background of zeros as well for the same reason. Definition (complexity class) Let D be the probability distribution produced by a computa- tion. A complexity class C in D is the set of strings { s 1 , s 2 ,. . . , s i } such that K ( s 1 ) = K ( s 2 ) = . . . = K ( s i ) . The above clearly induces a partition since S n i =1 C i = D and T n i =1 C i = ∅ for n the number of strings in D . In other words, all strings in D are in one and only one complexity class. W e will denote D r the reduced distrib ution of D . Evidently the number of elements in D is greater than or equal to D r . The P ´ olya-Burnside enumeration theorem will help us arrive at D r . There are 2 n dif ferent binary strings of length n and 4 possible transformations to take into consideration: 1. id , the identity symmetry , id ( s ) = s . 2. sy , the re version symmetry gi ven by: If s = d 1 d 2 , . . . d n , sy ( s ) = d n d 2 , . . . d 1 . 3. co , the complementation symmetry gi ven by co ( s ) = mod ( d i + 1 , 2) . Let T denote the set of all possible transformations under composition of the above. The classes of complexity can then be obtained by applying the Burnside theorem according to the follo wing formula: (2 n + 2 n/ 2 + 2 n/ 2 ) / 4 , for n odd (2 n + 2 ( n +1) / 2 ) / 4 otherwise. JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 7 This is obtained by calculating the number of in v ariant binary strings under T . For the transformation id there are 2 n in variant strings. For sy there are 2 n/ 2 if n is e ven, 2 ( n +1) / 2 if n is odd, the number of in variant strings under co is zero and the number of in v ariant strings under sy co is 2 n/ 2 if n is e ven, or zero if it is odd. Let’ s use B ( D ) to denote the application of the Burnside theorem to a distribution D . As a consequence of applying B ( D ) , grouping and adding up the frequencies of the strings, once has to divide the frequency results by 2 or 4 (depending on the number of strings grouped for each class) according to the follo wing formula: f r ( s ) / | S ( sy ( s ) , co ( s ) , sy co ( s )) | where f r represents the frequency of the string s and the denominator the cardinality of the union set of the equi valent strings under T . For example, the string s 1 = 0000 for n = 4 is grouped with the string s 2 = 1111 because they both hav e the same algorithmic complexity: C 0000 = { 0000 , 1111 } . The inde x of each class C i is the first string in the class according to arithmetical order . Thus the class { 0000, 1111 } is represented by C 0000 . Another example of a class with tw o member strings is the one represented by 0011 from the class C 0011 = { 0011 , 1100 } . By contrast, the string 0010 has other three strings of length 4 in the same class: C 0010 = { 0100 , 0010 , 1101 , 1011 } . Other class with four members is the one represented by 0001 , the other three strings being C 0001 = { 0001 , 0111 , 1000 , 1110 } because for any s i ∈ C 0001 with i < n the number of strings in C 0001 , T ( s i ) = s j , i.e. by applying a transformation T one can transform an y string from any other in C 0001 . It is clear that B induces a total order in D r from D under the transformations T preserving K because if s 1 , s 2 and s 3 are strings in { 0 , 1 } n : K ( s 1 ) ≤ K ( s 2 ) and K ( s 2 ) ≤ K ( s 1 ) then K ( s 1 ) = K ( b ) so s 1 , s 2 are in the same complexity class C s 1 ,s 2 (antisymmetry); If K ( s 1 ) ≤ K ( s 2 ) and K ( s 2 ) ≤ K ( c ) then K ( s 1 ) ≤ K ( s 3 ) (transiti vity) and either K ( s 1 ) ≤ K ( s 2 ) or K ( s 2 ) ≤ K ( s 1 ) (totality). Hereafter the r in D r will simply be denoted by D , it being understood that it refers to D r after applying B ( D ) . 3.3. Rank order correlation T o figure out the degree of correlation between the probability frequency[5], we followed a statistical method for rank comparisons. Spearman’ s rank correlation coef ficient is a non-parametric measure of correlation, i.e. it makes no assumptions about the frequenc y distribution of the variables. Spearman’ s rank correlation coefficient is equiv alent to the Pearson correlation on ranks. The Spearman coefficient has to do with measuring correspondence between two rankings for assessing the significance of this correspondence. The Spearman Rank Correlation Coefficient is: ρ = 1 − (6Σ d 2 i ) /n ( n 2 − 1) where d i is the dif ference between each rank of corresponding values of x and y , and n the number of pairs of v alues. The Spearman coef ficient is in the interval [ − 1 , 1] where: • If the agreement between the two rankings is perfect (i.e., the two rankings are the same) the coef ficient has value 1. 8 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity • If the disagreement between the two rankings is perfect (i.e., one ranking is the reverse of the other) the coef ficient has value -1. • For all other arrangements the value lies between -1 and 1, and increasing v alues (for the same number of elements) imply increasing agreement between the rankings. • If the rankings are completely independent, the coef ficient has value 0. 3.3.1. Lev el of significance The approach to testing whether an observed value of ρ is significantly dif ferent from zero is to calculate the probability that it would be greater than or equal to the observed ρ , gi ven the null hypothesis (that they are correlated by chance), by using a permutation test in order to conclude that the obtained value of ρ is unlikely to occur by chance. The lev el of significance is determined by a permutation test[6], checking all permutations of ranks in the sample and counting the fraction for which the ρ is more e xtreme than the ρ found from the data. As the number of permutations grows proportional to N ! , this is not practical e ven for small numbers. An asymptotically equiv alent permutation test can be created when there are too many possible orderings of the data. For less than 9 elements we proceeded by a permutation test. For more than 9 elements the significance was calculated by Monte Carlo sampling, which takes a small (relati ve to the total number of permutations) random sample of the possible orderings, in our case the sample size was 10000 , big enough to guarantee the results gi ven the number of elements. The significance con vention is that below . 5 , the correlation might be the product of chance and then it has to be rejected. If it is 0 . 05 , then there is enough confidence that the correlation has not occurred by chance and therefore it is said that the correlation is significant. If it is 0 . 01 or belo w , then the correlation is said to be highly significant and very unlikely to be the product of chance since it would occur by chance less than 1 time in a hundred. The significance tables generated and followed for the calculation of the significance of the Spearman correlation coef ficients can be consulted in the following URL: http://www .mathrix.org/experimentalAIT/spearmantables 3.4. Con vergence in distrib utions W e want to find out if the probability distrib utions b uilt from single and dif ferent models of computation con verge. Definition (convergence in order) A sequence of distributions D 1 , D 2 , . . . con ver ges to D N , if for all string s i ∈ D n , or d ( s i ) ∈ D n → or d ( s i ) ∈ D N ( s ) , when n tends to infinity . In other words, D n con verges to an order when n tends to infinity . Definition (convergence in values) A sequence of distributions D 1 , D 2 , . . . conv erges to D N if, for all string s i ∈ D n , f ( s i ) ∈ D n → f ( s i ) ∈ D N ( s ) , when n tends to infinity . Definition (order-preserving): A T uring machine N is Kolmogoro v-Chaitin complexity monotone, or K olmogorov-Chaitin complexity order -preserving if, giv en the output probability distri- JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 9 Figure 2. The above sequence of plots sho w the ev olution of the probability distributions for both 2-state T uring machines and one-dimensional elementary cellular automata, arranging the strings (x axis) in arithmetical order to compare the frequency value (y axis) of equal output strings produced by each T M (2 , 2) and C A (1) . n is the length of the strings to compare with, but also determines how far a machine runs in number of t = 10 × n steps and how man y machines are sampled determined by: a = n × 341 for T M (2 , 2) and a = n × 21 for C A (1) with a the size of the sample so that 12 × 341 = 4092 and a = 12 × 21 = 252 give the closest whole numbers to the total number of machines in T M (2 , 2) and C A (1) respecti vely . n is in other words what let us define the progression of the sequence to look for the con ver gence in distrib ution. Our claim is that when n tends to infinity the distributions con ver ge either in order or in values to a limit distrib ution, as we will formulate in section 3.4. 10 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity bution D 1 of N , if K D N ( s 1 ) ≤ K D N ( s 2 ) then K D 2 ( s 1 ) ≤ K D 2 ( s 2 ) . Definition (quasi order preserving) A T uring machine N is c -K olmogorov-Chaitin com- plexity monotone, or c -K olmogorov-Chaitin complexity order- preserving if, for most strings, N is K olmogorov-Chaitin complexity monotone, or Kolmogoro v-Chaitin complexity order-preserving. A T uring machine N is . 01 -K olmogorov-Chaitin complexity order -preserving is K olmogorov-Chaitin com- plexity order -preserving. In order to determine the degree of order-preserving we hav e introduced the term c that will be determined by the correlation significance between two gi ven output probability distrib utions D 1 and D 2 . In other words, one can still define a monotony measure ev en if only a significant first segment of the distributions conv erge. This is important because by algorithmic probability we know that random- looking strings will be–and because of their random nature hav e to be–very unstable exchanging places at the bottom of the distributions. But we may nevertheless want to know whether a distribution con- ver ges for most of the strings. Whether or not a probability distribution D con ver ges to D N , one might still want to check if two dif ferent models of computation con ver ge between them: Definition (relative Kolmogorov-Chaitin monotony) Let be M and N two T uring ma- chine. M and N are relativ ely c -K olmogorov-Chaitin complexity monotone if gi ven their probability distributions D 1 and D 2 respecti vely and K D 2 ( s 1 ) ≤ K D 2 ( s 2 ) then K D 1 ( s 1 ) ≤ K D 1 ( s 2 ) in D 1 for all f ( s 1 ) , f ( s 2 ) > c . Definition (distribution length): Gi ven a model M , the length of its output probability distribution D denoted by | D | is the length of the largest string s ∈ D . Main result T M (2 , 2) and C A (1) are relativ e Kolmogoro v-Chaitin complexity quasi monotone up to | D | = 12 . The following table shows the Spearman rank correlation coef ficients for D T M (2 , 2) with D C A (1) from string lengths 2 to 12: JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 11 Figure 3. The probability of the null hypothesis (that between D T M (2 , 2) and D C A (1) the correlation is the product of chance) decreases very soon remaining very low , while the significance increases systematically from n = 2 to 12 . Number Spearman Significance of elements coefficient v alue 2 1 50 3 1 33 . 33 6 0 . 94 0 . 01 9 0 . 78 0 . 01 15 0 . 44 0 . 01 14 0 . 66 0 . 01 12 0 . 67 0 . 01 12 0 . 78 0 . 01 12 0 . 80 0 . 02 11 0 . 79 0 . 01 11 0 . 80 0 . 01 Significance values are not expected to score well at the beginning due to the lack of elements to determine if other than the product of chance produced the order . For 2 elements in each rank order there are only 2 ways to arrange each rank, and even if they make a perfect match as they do, the significance cannot be higher than 50 percent because there is still half chance to have had produced that particular order . It is also the case for 3 elements, ev en when the ranks made a perfect match as well. But starting at 6 one can start looking to an actual significance value, and up to 12 in the sequence below one can witness a notorious increase up to stabilize the value at 0 . 01 which is, for all them, highly significant. Just one case was just significant rather than highly significant according to the threshold con vention. The fact that each of the values of the sequence are either significant or highly significant makes the entire sequence con ver gence even more significant. D T M (2 , 2) and D C A (1) are therefore statistically highly correlated and they are relati ve 0.01-Kolmogoro v-Chaitin complexity quasi monotone up to | D | = 12 in almost all values. Therefore T M (2 , 2) and C A (1) are relativ e K olmogorov-Chaitin complexity monotone. 12 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity It also turned out that the Pearson correlation coefficients were all highly significant between the actual probability v alues between D T M (2 , 2) and D C (1) , with the follo wing values: Number Pearson of elements coefficient 2 1 3 0 . 624662 6 0 . 979218 9 0 . 972992 15 0 . 95721 14 0 . 975683 12 0 . 920039 12 0 . 942916 12 0 . 982229 11 0 . 916871 11 0 . 944149 The abo ve results are important because the y not only sho w that T M (2 , 2) and C A (1) are K olmogorov- Chaitin monotone up to | D | = 12 b ut because they constitute the basis and e vidence for the formulation of the conjectures in section 3.5: 3.5. Conjectures of con ver gence Let or d denote the ranking order of a distribution D and pr the actual probability values of D for each string s ∈ D , then: Conjecture 1 If pr ( D T M ( n )) = { f ( s 1 ) , f ( s 2 ) , . . . , f ( s u ) } , then for all s i , f s i → f ( L s i ) when n → ∞ with { f ( L s 1 ) , f ( L s 2 ) , . . . , f ( L s n ) , . . . } the limit frequencies. In other words, the sequence of probability values f ( D T M (1)) , f ( D T M (2)) , . . . , f ( D T M ( n )) , . . . con ver ges when n tends to infinity . Let’ s call this limit distribution pr hereafter . Conjecture 2 The sequence ord ( D T M (1)) , or d ( D T M (2)) , . . . , or d ( D T M ( n )) con ver ges when n tends to infinity . Notice that the conjecture 2 is weaker than the conjecture 1 since conjecture 2 could be true ev en if conjecture 1 is false. Both conjectures 1 and 2 imply there exists a k ∈ { 1 , 2 , . . . , n } such that for all i > k , T M ( i ) is K olmogorov-Chaitin complexity order -preserving. Like wise for cellular automata: JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 13 Conjecture 3 The sequence pr ( D C A (1)) , pr ( D C A (2) , . . . , pr ( D C A ( u )) con ver ges to pr ( D C A ( n )) when n tends to infinity . Conjecture 4 The sequence or d ( D C A (1)) , or d ( D C A (2)) , . . . , or d ( D C A ( n )) con ver ges when n tends to infinity . Notice that the conjecture 2 is weaker than the conjecture 1 since conjecture 2 could be true ev en if conjecture 1 is false. Both conjectures 1 and 2 imply there exists a k ∈ { 1 , 2 , . . . , n } such that for all i > k , C A ( i ) is K olmogorov-Chaitin complexity order -preserving. Like wise for T uring machines, conjecture 3 implies conjecture 4, b ut conjecture 4 could be true e ven if conjecture 3 is false. Conjecture 5 pr ( D C A ( n )) = pr ( D T ( n )) . Conjecture 6 ord ( D C A ( n )) = or d ( D T ( n )) . In other w ords, the limit distrib utions for both C A and T M con ver ge to the same limit distributions. Conjecture 5 implies conjecture 6, but conjecture 6 could be true e ven if conjecture 5 is false. Both pr and or d define D N , from no w on the natural probability distrib ution. W e now can propose our definition of a natural model of computation: Definition (naturalness in distribution) M is a natural model of computation if it is c - K olmogorov-Chaitin monotone or c -K olmogorov-Chaitin order -preserving for c = . 01 . In other words, any model of computation preserving the relativ e order of the natural distribution D N is natural in terms of Kolmogoro v-Chaitin complexity under our definition. So one can no w technically say that a tailor -made T uring machine producing a dif ferent enough output distrib ution is not natural ac- cording to the prior D N . One can now also define (a) a degree of natural ness according to the ranking coef ficient and number of order-preserving strings as suggested before and (b) a K olmogorov-Chaitin order-preserving test such that one can be able to say whether a programming language or T uring ma- chine is natural by designing an experiment and running the test. For (a) it suf fices to follow the ideas in this paper . For (b) one can follow the experiments described partially here supplemented with further details av ailable in [3] in order to produce a probability distribution that could be compared to the nat- ural probability distribution to determine whether or not con vergence occurs. The use of these natural distributions as prior probability distributions are one of the possible applications. The following URL provides the full tables: http://www .mathrix.org/experimentalAIT/naturaldistrib ution Further details, including the original programs, are av ailable online in the experimental Algorithmic Information Theory web page: http://www .mathrix.org/e xperimentalAIT/ Further experiments are in the process of being performed, both for bigger classes of the same models of computation and for other models of computation, including some that clearly are not K olmogorov- 14 JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity Figure 4. Frequency (log) distributions for T M (2 , 2) and C A (1) , for n = 12 . In this plot no string arrangement was made, unlike figure 2. The rate of grow seems to follo w a power law . Chaitin order-preserving. More experiments will be performed covering different parameterizations, such as distributions for non-empty initial configurations, possible rates of con ver gence and radius of con vergence, as well as the actual relation between the mathematical expected values of the theoreti- cal definitions of K ( s ) and m ( s ) (the so called universal distribution[9]), as first suggested in [2, 3]. W e are aware of the possible expected differences between probability distributions produced by self- nondelimiting vs. self-delimiting programs[4], such as in the case discussed within this paper , where the halting state of the T uring machines was partially dismissed while the halting of the cellular automata was randomly chosen to produce the desired length of strings for comparison with the TM distrib utions. A further in vestigation suggests the possibility that there are interesting qualitative differences in the probability distributions the y produce. These can be also be studied using this approach. If these conjectures are true, as suggested by our experiments, this procedure is a feasible and ef- fecti ve approach to both m ( s ) and k ( s ) . Moreov er , as suggested in[2], it is a way to approach the K olmogorov-Chaitin complexity of short strings. Furthermore, statistical approaches might in general be good approaches to the K olmogorov-Chaitin complexity of strings of any length, as long as the sample is large enough for getting a reasonable significance. Refer ences [1] C.S. Calude, Information and Randomness: An Algorithmic P erspective (T exts in Theor etical Computer Sci- ence. An EA TCS Series) , Springer; 2nd. edition, 2002. [2] J.P . Delahaye, H. Zenil, On the K olmogorov-Chaitin comple xity for short sequences, in Cristian Calude (eds) Complexity and Randomness: F r om Leibniz to Chaitin . W orld Scientific, 2007. [3] J.P . Delahaye, H. Zenil, On the Kolmo gor ov-Chaitin complexity for short sequences (long version) . arXiv:0704.1043v3 [cs.CC], 2007. JP . Delahaye, H. Zenil / T owards a stable definition of K olmogor ov-Chaitin complexity 15 [4] G.J. Chaitin, Algorithmic Information Theory , Cambridge Uni versity Press, 1987. [5] W . Snedecor , WG. Cochran, Statistical Methods , Io wa State Uni versity Press; 8 edition, 1989. [6] P .I. Good, P ermutation, P arametric and Bootstrap T ests of Hypotheses , 3rd ed., Springer , 2005. [7] K. Kelly , Ockhams Razor , T ruth, and Information, in J. van Behthem and P . Adriaans, (eds) Handbook of the Philosophy of Information , to appear . [8] A.K. Zvonkin, L. A. Le vin. The Complexity of finite objects and the Algorithmic Concepts of Information and Randomness, UMN = Russian Math. Surve ys , 25(6):83-124, 1970. [9] M. Li and P . V it ´ anyi, An Intr oduction to K olmogor ov-Chaitin Complexity and Its Applications , Springer , 1997. [10] H, Redfield, The Theory of Group-Reduced Distributions, American J ournal of Mathematics , V ol. 49, No. 3 (Jul., 1927), pp. 433-455, 1997. [11] R. Solomonoff, The Discov ery of Algorithmic Probability , J ournal of Computer and System Sciences , V ol. 55, No. 1, pp. 73-88, August 1997. [12] R. Solomonof f, A Pr eliminary Report on a General Theory of Inductive Inference , (Re vision of Report V - 131), Zator Co., Cambridge, Mass., Feb . 4, 1960 [13] J. T romp, Binary Lambda Calculus and Combinatory Logic, Kolmo gor ov Complexity and Applications . M. Hutter , W . Merkle and P .M.B. V itanyi (eds.), Dagstuhl Seminar Proceedings, Internationales Begegnungs und Forschungszentrum fuer Informatik (IBFI), Schloss Dagstuhl, German y , 2006. [14] S. W olfram, A New Kind of Science , W olfram Media, Champaign, IL., 2002.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment