안정적인 콜모고로프 차틴 복잡도 정의를 향하여
본 논문은 Kolmogorov‑Chaitin 복잡도 K(s)의 값이 프로그래밍 언어에 따라 크게 달라지는 문제를 다룬다. 저자들은 “자연스러운” 모델을 찾기 위해 서로 다른 계산 모델(2‑state 2‑symbol 튜링 머신과 1‑차원 셀룰러 오토마톤)의 출력 확률 분포가 수렴한다는 실험적 증거를 제시한다. 이 수렴성을 이용해 상수 차이를 최소화하고, 문자열들의 복잡도 순서를 보존하는 안정적인 K 정의를 제안한다.
저자: Jean-Paul Delahaye, Hector Zenil
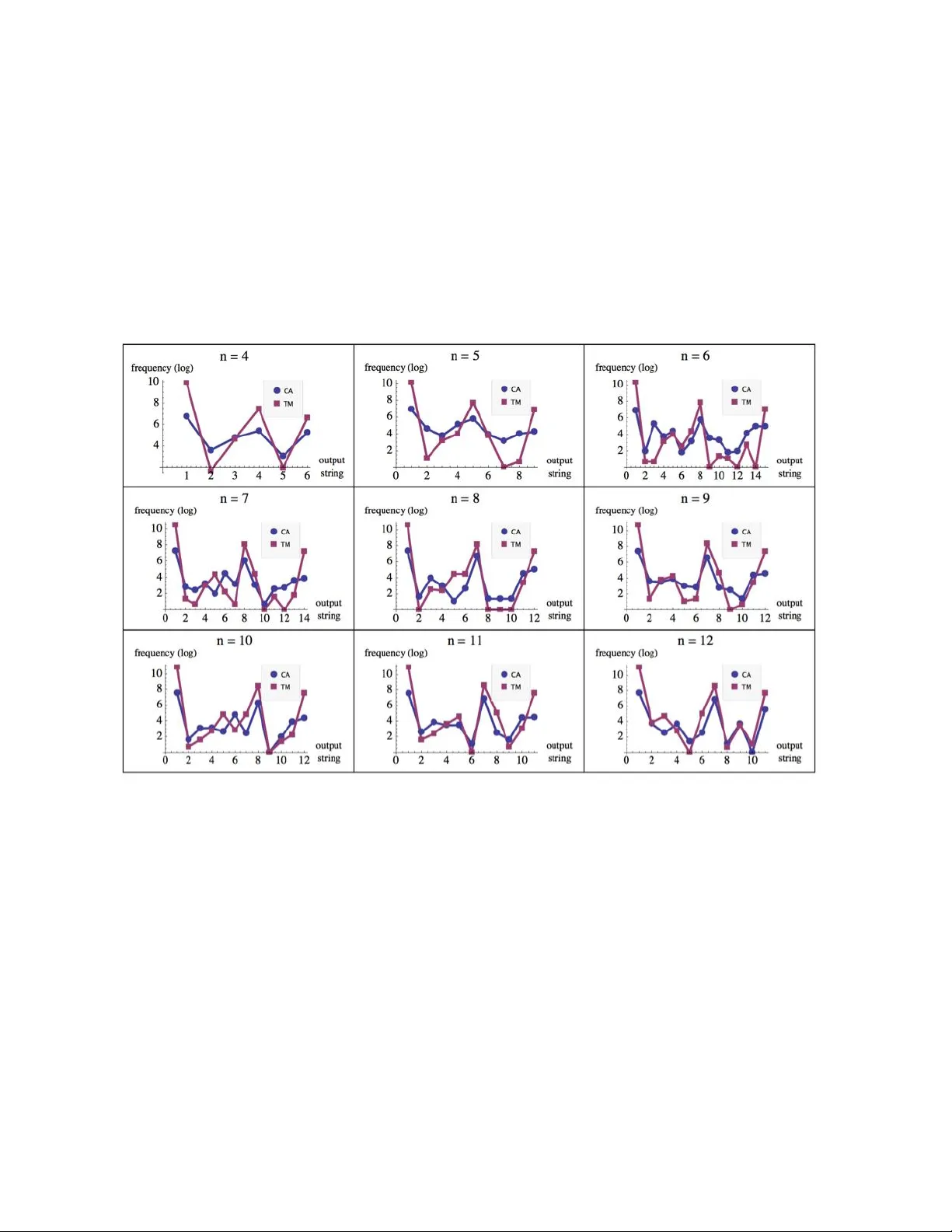
본 논문은 Kolmogorov‑Chaitin 복잡도 K(s)의 실용적 계산에서 발생하는 “상수 의존성” 문제를 심도 있게 탐구한다. K(s)는 보편 튜링 머신 U에 대해 가장 짧은 프로그램 p의 길이 |p| 로 정의되지만, 실제로는 선택된 언어 L에 따라 상수 C(L₁,L₂)가 크게 달라진다. 불변성 정리(Invariance Theorem)는 두 언어 사이에 상수 C가 존재함을 보장하지만, C가 무한히 커질 수 있음을 저자들은 강조한다. 이는 특히 짧은 문자열에 대해 K(s)를 추정할 때, 상수가 문자열 길이와 동등하거나 그보다 커져 의미 있는 비교가 불가능해지는 상황을 초래한다.
이러한 한계를 극복하기 위해, 저자들은 “자연스러운” 계산 모델을 정의하고자 한다. 자연스러움은 특정 언어가 인위적으로 설계되어 특정 문자열을 압축하거나 복잡도를 뒤집는 것이 아니라, 다양한 모델 간에 출력 확률 분포가 수렴하고, 그 분포가 문자열의 대칭(역전, 보완, 복합)과 일관된 구조를 보이는지를 기준으로 판단한다.
실험 설계는 두 가지 대표적인 계산 모델을 선택하였다. 첫 번째는 2‑state 2‑symbol 튜링 머신 집합 TM(2,2)이며, 이는 4096개의 서로 다른 머신을 포함한다. 두 번째는 1‑차원 셀룰러 오토마톤 집합 CA(1)으로, 256개의 elementary cellular automata를 포함한다. 각 모델은 동일한 초기 조건(전부 0 또는 전부 1)으로 시작하고, n × 10 단계(예: n=3일 때 30 단계) 동안 실행된다. 실행 후, 각 머신/오토마톤이 생성한 길이 n의 출력 문자열을 모두 수집하고, 문자열별 발생 빈도를 확률 분포 D에 기록한다.
분석 결과, TM과 CA의 확률 분포는 높은 상관관계를 보이며, 특히 문자열이 역전(r), 보완(c), 그리고 그 조합(rc)으로 변환될 때 동일한 빈도 그룹에 속한다. 예를 들어, n=3일 때 (000), (111) 등은 동일한 확률을 갖고, (001)과 (110) 등은 서로 역전·보완 관계에 있다. 이러한 패턴은 실험적으로도 일관되게 나타났으며, 문자열 길이가 증가해도 동일한 대칭군에 의해 그룹화되는 경향이 지속된다.
대칭 효과를 정량화하기 위해 저자들은 Burnside의 정리를 적용하였다. 변환군 T는 {id, sy, co, sy∘co} 로 정의되며, 각 변환은 문자열을 그대로 두거나 역전, 보완, 혹은 두 변환을 연속 적용한다. Burnside 식에 따라, n이 짝수일 때 복잡도 클래스(동일 K값을 갖는 문자열 집합)의 개수는 (2ⁿ + 2·(n+1)/2)/4 로, n이 홀수일 때는 (2ⁿ + 2·2ⁿ⁄²)/4 로 계산된다. 이를 통해 원본 분포 D를 축소한 Dʳ을 얻고, 대칭에 의해 발생하는 순위 교차를 제거한다.
두 모델 간의 순위 상관을 측정한 결과, 상위 빈도 문자열(예: (0)ⁿ, (1)ⁿ)은 서로 교환될 수 있으나, 대칭군에 의해 동일 클래스에 포함되므로 K값 순서는 보존된다. 따라서, TM과 CA는 “자연스러운” 모델군으로 간주될 수 있으며, 이들 모델군 내에서는 상수 C가 실질적으로 작아져 K(s)의 상대적 순서가 언어에 독립적이다.
저자들은 이러한 접근법이 기존의 압축 기반 K 추정보다 더 객관적이며, 특히 짧은 문자열에 대해 안정적인 K값을 제공한다는 점을 강조한다. 또한, 다양한 계산 모델(예: 다른 상태·기호 수의 튜링 머신, 다차원 셀룰러 오토마톤)에서도 동일한 수렴 현상이 관찰된다면, 그 모델군을 “자연스러운” 모델로 확장할 수 있을 것으로 기대한다. 최종적으로, 이 연구는 Kolmogorov‑Chaitin 복잡도에 대한 실용적 정의를 언어 의존성을 최소화하면서도 이론적 일관성을 유지하는 새로운 프레임워크를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기