On-line Learning of an Unlearnable True Teacher through Mobile Ensemble Teachers
On-line learning of a hierarchical learning model is studied by a method from statistical mechanics. In our model a student of a simple perceptron learns from not a true teacher directly, but ensemble teachers who learn from the true teacher with a p…
Authors: Takeshi Hirama, Koji Hukushima
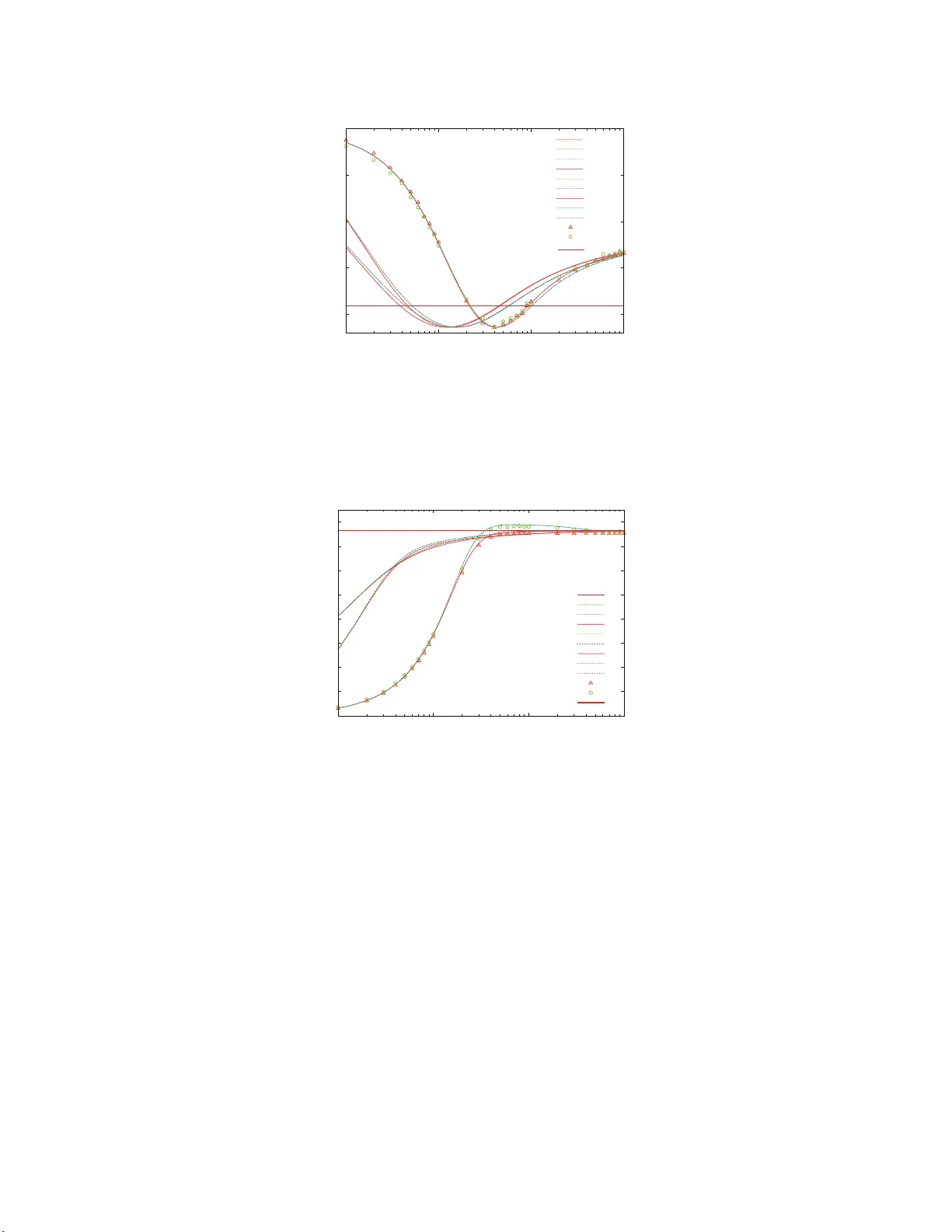
T yp eset with jpsj2.cls < v er.1 .2.2b > Full P aper On-line Learning of an Unlearnable T rue T eac her through Mobile Ensem ble T eac hers T ak eshi Hirama and Ko ji Hukus hima Dep artment o f Basic Sci enc e, Unive rsity of T okyo, 3-8-1 Komab a, Me gur o-ku, T okyo 153-8902 , J ap an (Received Marc h 1, 2022) On-line learning of a hierar chical learning mo del is studied b y a metho d from sta tistical mechanics. In our model a s tuden t o f a simple perceptro n lear ns from not a true teacher directly , but ensemble tea c her s who learn from the true teacher with a p erceptro n learning rule. Since the true teacher and the ensemble teachers ar e expressed a s non-monotonic per- ceptron and s imple ones, resp ectiv e ly , the ensemble teachers go a r ound the unlearnable tr ue teacher with the dis ta nce b etw een them fixed in an a symptotic s teady state. The general- ization p erformance of the student is shown to exceed that of the ensemble tea c her s in a transient state, as was shown in similar ensem ble- teac her s mo dels. F urther, it is found that moving the ensem ble teac her s even in the steady state, in co ntrast to the fixed ensemble teachers, is efficient for the perfo r mance of the studen t. KEYWORDS: online learning, ensem ble teachers, gen eralization error , statistical mech anics 1. In tro duction Learning is an inference problem of inhered rules from a gi ven set of examples whic h consist of in p ut data and corresp onding ou tp ut data generated b y th e ru les. In practice, the examples are often supp lied in exh austibly and then the learning m u st pro ceed by u sing eac h example just once. Such lea rning is called on-line learning. 1–3) On the con trary , the learning in whic h all the examples are present ed rep eatedly at an ytime is called off-line or b atc h learnin g. The on-line learning as w ell as the off-line one has b een extensiv ely studied b y using statistica l-mec hanical metho ds so far and man y extensions of the on-line learning sc heme ha ve b een made in order to impro ve a generalization p erformance. 1, 3) Recen tly , Miy osh i and Ok ada 4) and Ur ak ami, Miy oshi and O k ada 5) analyzed t he generalizat ion p erformance of a student sup ervised by a mo ving teac her that goes around a fi xed true teac her in a fr amework of the on-line learning using the statistical mec hanical metho d. In their mo del, the studen t is not directly giv en the outp uts by th e true teac her. The movi ng teac h er learns from the true teac her and provides its output to th e stu den t. In this sen se, the mo del is a kin d of hierarc h ical learning. In ref. 5, th e true teac her is a non-monotonic p erceptron, wh ile the moving teac her and the s tuden t are simple p erceptron using p erceptron learning, wh ic h could not infer the true tea cher completely in principle. The theoretical b oun d of the generali zation error of a simple p erceptron learner h as b een obtained. 6) In that case, the mo ving teac her go es around 1/18 J. Phys. So c. Jpn. Full P aper the true teac her with a fixed distance b et ween th em. In terestingly , it turned out that when the student ’s learnin g rate is relat iv ely s m all, the student’ s generalizatio n error can temp orally b ecome smaller than that of the mo vin g teac h er, even if the stu d en t only us es the examples from the movi ng teac her. Subsequ ently , Miyoshi and Ok ada 7) and Utsumi, Miy oshi and Ok ada 8) analyzed the gen- eralizatio n p erformance of an extended m o del of the on-line learning with m ultiple teac hers, whic h would b e called ensem ble-teac hers learning mod el. Th is mo d el is also r egarded as an extension of the ensemble learning 9, 10) b ecause the ensem b le teac hers and the student in the ensem b le-teac hers mo del can b e interpreted as the en s em ble students and their int egrating mec hanism, resp ectiv ely . I n p articular, ref. 8 discussed the mo del in wh ic h the true teac her, the ens em ble teac hers and the student are all simple p erceptrons. In this mo del the tru e teac her and the ensem b le teac hers are fixed. Th e student adopts the Hebbian learning or the p erceptron learnin g as a learning r ule and us es examples f rom the en s em ble teac hers in turn or randomly . As a result, it w as clarified that the Hebbian learning and the p erceptron learning sh o w qualitativ ely d ifferent b eha vior from eac h other. In th e Hebbian learning, the generalizat ion error monotonically d ecreases during the learning pro cess and its asymp totic v alue is indep endent of the learning rate. The asymptotic v alue is redu ced as the n u m b er of the ensemble teac hers increases since th e ensemble teac hers hav e more v ariet y in their rep- resen tations. On the other hand, in the p erceptron learning, the generalization error sho ws non-monotonic b ehavi or and exhibits a minim um at a certain s tep in the learning. The min- im um v alue of the generalization err or decreases as th e learning rate d ecrease s and th e total n u m b er of the teac h ers increases. In ref. 5 and r ef. 8, it w as sho wn that the generalization error of a stud en t could b e smaller than that of a mo ving teac her or fixed ensem ble teac hers. A comparison b et we en the generalizat ion p erformance with a fixed teac her and that with a mobile teac her, ho wev er, has not b een m ade directly . F urthermore, in the on-line learning with the ensem b le tea c hers it is not trivial that either the mobilit y or the multiplicit y of the ensemble teac hers is effectiv e for the learnin g p erformance of the student. In this p ap er , we study the on-line learnin g for the ensem ble teac hers which can mo ve aroun d a true tea c her. W e discus s a mo del in whic h the fixed true teac h er is n on-monotonic p erceptron and the ensemble mo ving teac h ers and the stud ent are a simple p erceptron. Th is is a generalized ve rsion of the mo del stud ied in ref. 5. Adopting the p erceptron learning as a learning rule for the ensemble teac hers, they go arou n d th e true teac her with constant ord er parameters in th e steady state . Then we analyze the generaliza tion p erformance of the stud en t whic h learns from the mobile ensem ble teac hers using the Hebb ian and the p erceptron rules. W e also study the mo del with the ensem b le teac h er s fixed in their s teady state. It is th us clarified that the mo ve m en t of the ensem b le teac hers , in comparison with th e fixed en sem ble case, significantly improv es the 2/18 J. Phys. So c. Jpn. Full P aper generalizat ion p erformance of the s tuden t as a transient state in the learning pro cess. The pap er is organized as follo w s: In sec. 2, we introdu ce the m od el with th e ensem b le mo ving teac her s going around the un learnable true teac h er. In sec. 3, b ased on th e statistical- mec hanical idea, we theoretically deriv e the ordin al d ifferen tial equ atio n s of ord er parameters and an explicit form ula of th e generalizatio n err or of our mo del in terms of the ord er p arame- ters. In sec. 4, we sho w the theoretical an d n u merical results of the generalization p erformance of the studen t with the Hebbian and p erceptron ru les. The last section is devot ed to our con- clusion. In the app endixes, the deriv atio n s of the d ifferential equations d iscu ssed in sec. 3 are present ed in detail. 2. Mo del In this pap er, we consider a true teac her, K ens em ble mo ving teac hers and a s tuden t, whose connection w eigh ts are expr essed as N dimensional v ectors, A , B k and J , resp ectiv ely , with k = 1 , 2 , · · · , K . F or simp licit y , eac h component A i of A with i = 1 , · · · , N is assu med to b e dr a wn from N (0 , 1) ind ep en den tly and fixed, where N ( m, σ 2 ) d enotes th e Gaussian distribution with m and σ 2 b eing a mean an d v ariance, resp ectiv ely . As an in itial condition of the learning p ro cess, eac h of the comp onents B 0 k i and J 0 i of B 0 k , J 0 are also assumed to b e d ra wn f rom N (0 , 1) ind ep enden tly . In put x is also the N -dimen sional v ector and the comp onen t x i follo ws from N (0 , 1 / N ) indep endently . T h us, we ha v e h A i i = B 0 k i = J 0 i = h x i i = 0 , (2.1) ( A i ) 2 = D B 0 k i 2 E = D J 0 i 2 E = 1 , (2.2) and ( x i ) 2 = 1 N , (2.3) where h· · · i denotes an a ve rage o ve r the Gaussian distribu tion. In the statistical m ec hanics of the learning, 1, 2) w e are interested in asymptotic b eha vior of A , B and J in a thermo dynamics limit N → ∞ . Then, one finds that the norms of the v ectors are k A k = √ N , k B 0 k k = √ N , k J 0 k = √ N , k x k = 1 . (2.4) The norms, k B k k and k J k , of the ensem b le mo vin g teac hers and the stud en t c h ange durin g the learning pro cess from their initial v alues. The normalized length of these v ectors is in tr o du ced as l B k = k B k k / k B 0 k k for the ensemble teac hers and l J = k J k / k J 0 k for the stud ent. In the thermo dynamic limit, the direction cosines b et ween th ese vec tors are a relev an t extensive quan tity , denoted for A and B k , A and J , B k and B k ′ , and B k and J r esp ectiv ely as R B k = A · B k k A kk B k k , R J = A · J k A kk J k , (2.5) 3/18 J. Phys. So c. Jpn. Full P aper q k k ′ = B k · B ′ k k B k kk B ′ k k , R B k J = B k · J k B k kk J k . (2.6) In the p r esen t study , w e assume that the true teac her is a non-mon otonic p erceptron and the ensem b le mo ving teac hers and the stud en t are a simple p erceptron. T h e outp u t f or a giv en input x of the true teac her is defined by a non-monotonic fu nction o = sgn (( A · x − a ) A · x ( A · x + a )) (2.7) with a fixed th reshold a , while those of th e ensem ble mo v in g tea c hers and the student are simply giv en b y sgn( B k · x ) and sgn( J · x ), resp ective ly . Here, sgn( · ) is the sign function defined as sgn( s ) = ( +1 , s ≥ 0 , − 1 , s < 0 . (2.8) A measure of dissimilarit y b et wee n the true teac her and the ensemble teac hers or th e student is defined by using their outp u ts as ǫ B k ≡ Θ ( − o · sgn ( B k · x )) (2.9) for k th ensemble teac her and ǫ J ≡ Θ ( − o · sgn ( J · x )) (2.10) for the student, where Θ( · ) is the step fu nction defined as Θ( s ) = ( +1 , s ≥ 0 , 0 , s < 0 . (2.11) One of th e main p urp oses of the statistical learning theory is to obtain theoretically th e generalizat ion errors ǫ g B k and ǫ g J , whic h are defined as the av erage of the errors, ǫ B k and ǫ J o ve r the wh ole set of p ossible in p uts x . Since the in p ut x app ears in Eq. (2.9) and Eq. (2.10) as in ner pro du cts A · · · x , B k · x and J · x , the a v erage o ver Gaussian v ector x could b e reduced to an a ve r age ov er correlated Gaussian v ariables. Wh en one defines a set of v ariables, v , v B k and u as v = A · x , (2.12) v B k l B k = B k · x , (2.13) ul J = J · x , (2.14) they ob ey the multiple Gaussian distribu tion P ( v , { v B k } , u ) = 1 (2 π ) ( K +2) / 2 | Σ | 1 / 2 exp − ( v , { v B k } , u )Σ − 1 ( v , { v B k } , u ) T 2 , (2.15) 4/18 J. Phys. So c. Jpn. Full P aper with zero means an d the co v ariance matrix Σ Σ = 1 R B 1 R B 2 · · · R B K R J R B 1 1 q 1 , 2 · · · q 1 ,K R B 1 J R B 2 q 2 , 1 1 . . . . . . . . . . . . . . . . . . . . . q K − 1 ,K R B K − 1 J R B K q K, 1 · · · q K,K − 1 1 R B K J R J R B 1 J · · · R B K − 1 J R B K J 1 . (2.16) Ev aluating the correlated Gaussian in tegrations, the generalization errors ǫ g B k and ǫ g J are obtained as ǫ g B k = 2 Z − a −∞ + Z a 0 D v H − R B k v q 1 − R 2 B k , (2.17) and ǫ g J = 2 Z − a −∞ + Z a 0 D v H − R J v q 1 − R 2 J , (2.18) where D s is th e Gauss ian measure defin ed as D s ≡ ds √ 2 π exp − s 2 2 , (2.19) and H ( · ) is the err or function defi n ed as H ( s ) ≡ Z ∞ s D x. (2.20) It should b e n oted that the dyn amical effect of the generalization err ors app ears only through R B k and R J . This implies that the generalization errors h av e a fu ndamen tal minimum as a function of R B k and R J , ir resp ectiv e of the m atte r if the v alues of R B k and R J whic h give th e minim u m v alue of the generalization error app ear in a particular chosen learning r u le of the student and the ensemble teac hers. An efficien t learning rule might realize the f u ndamen tal minim u m for a giv en learning mo del. Let us defin ed th e u p date r ule in the on-line learning. Th e ensem ble mo ving teac hers B k are up dated fr om the curr en t state B m ′ k using an input x and outp ut of the tr u e teac her A for the inpu t x m ′ , ind ep en den tly as B m ′ +1 k = B m ′ k + f m ′ k ( x m ′ , B m ′ k , o m ′ ) x m ′ , (2.21) where f m ′ is an up date function of the ensem ble m o ving teac hers and m ′ denotes the time step of the ensem ble mo ving teac hers. In particular, we choose the p erceptron learning for the up date function f k , wh ich is giv en by f m ′ k = η B Θ − v m ′ B k o m ′ o m ′ . (2.22) Here, η B is the learning rate of the ens emble moving teac hers. I n our an alysis, the learning rate 5/18 J. Phys. So c. Jpn. Full P aper η B is in dep enden t of the teac h ers and is fix ed dur ing the learning p ro cess. Af ter a s ufficien t long learning pro cess u s ing the p erceptron ru le, the en sem ble movi ng teac h ers reac h steady state with R B k , l B k and q k k ′ fixed. In the pr esen t study , we focus our atten tion to dynamical effect of th e ensem ble teac hers for th e learning p erform ance of the stud en t. In order to separate off a tran s ien t effect of the en s em ble teac hers, the student learns from th e ensemble teac hers in the s teady state. T he stud en t J is up dated usin g an inpu t x and an output of one of the K ensem b le moving teac hers B k c hosen randomly . T he explicit recursion formula for J m with m b eing the time s tep of the student is give n b y J m +1 = J m + g m k ( x m , J m , s gn( v B k l B k )) x m , (2.23) where g m k is an up date fu nction of the student and k is a un iform random int eger c hosen from 1 to K . Note that the ensem b le mo ving teac hers are also up dated using th e same input. W e particularly discuss t w o different learning rules for the stud en t, whic h are the Hebbian learning g m k = η sgn v m B k l m B k , (2.24) and the p erceptron learning g m k = η Θ − v m B k u m sgn v m B k l m B k . (2.25) The learning rate of the student η is also constan t du r ing the learnin g pro cess. 3. Order-parameter theory As shown in the previous section, the generalization errors of the ensemble teac h er s and the stud ent are expressed in terms of the p arameter R B k and R J and evolv e only trough a few parameters associated with the learning of B k and J in the ther m od ynamic limit. It has b een sho wn th at a class of the on-line learning can b e charact erized by a few extensiv e parameters, called order parameter. In th is section, follo w ing ref. 3, a set of ordinal d ifferen tial equ atio n s of the order parameters are obtained in our mo del by taking the therm od ynamic limit. The learning pro cess of the ensemble m o ving teac hers are d escrib ed by the thr ee order parameter R B k , l k and q k k ′ , whic h are assu med to b e self-a veraging. It is su fficien t to consider the ev olution of R B k and l k in order to d escrib e the dyn amics of th e ensem b le teac hers, b ut that of the o verla p q k k ′ b et wee n t wo different teac hers is necessary for the stud en t dynamics as seen later. F rom the up date rules of the ensem ble teac hers in eq. (2.21), one find s a closed form u la of the ordinal d ifferen tial equations of the ord er p arameters as, dl B dt ′ = η B √ 2 π R B 2 exp − a 2 2 − 1 − 1 + 1 2 l B 2 η 2 B Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B , (3.1) 6/18 J. Phys. So c. Jpn. Full P aper dR B dt ′ = − R B l B dl B dt ′ + 1 l B η B √ 2 π 2 exp − a 2 2 − R B − 1 , (3.2) dq dt ′ = − q l B dl B dt ′ − q l B dl B dt ′ + 2 l B η B √ 2 π R B 2 exp − a 2 2 − 1 − q + 1 l 2 B 2 η 2 B Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D xH ( z ) , (3.3) where z ≡ − ( q − R 2 B ) x + R B q 1 − R 2 B v q (1 − q )(1 + q − 2 R 2 B ) , (3.4) and t ′ denotes con tinuous time. W e omit the subscript k from the order p arameters, b ecause the differen tial equations including their initial conditions h av e a p ermutatio n symmetry for the subscrip t k . Deriv ation of the differential equation is give n in the app end ix A. F rom these equation one easily obtain the steady solutions of R B , l B and of q as follo w s : R B = 2 exp − a 2 2 − 1 , (3.5) l B = √ 2 π η B 1 − R 2 B Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B , (3.6) q = R 2 B + (1 − R 2 B ) Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D xH ( z ) Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B . (3.7) Note that R B , q an d l B /η B dep end only on the th reshold a of th e true teac her. In our study , the ensem ble teac h er s are assumed to tak e the steady s tate b efore the studen t b egins to learn in order to mak e the dyn amical effec t of the ensem ble teac hers clear. T herefore these solutions of R B , l B and q are used as an initial condition of the learning dyn amics of the student discu ssed b elo w. The learning d ynamics of the student is also describ ed by a set of ordin al differential equa- tions of a few order parameters, which is deriv ed f rom the up date functions f or the Hebbian rule (2.24) and the p erceptron one (2.25). W e refer to the app endix B for the deriv ation of the dynamical equations. A straigh tforw ard calculation for the Hebbian r ule leads to dl dt = η r 2 π R B + η 2 l ! , (3.8) dR J dt = − R J l dl dt + η l r 2 π R B , (3.9) 7/18 J. Phys. So c. Jpn. Full P aper dR B J dt = − R B J 1 l dl dt + 1 l B dl B dt + η B l B √ 2 π R J 2 e − a 2 2 − 1 − R B J + η lK r 2 π q − 2 η η B K l B l ( K − 1) Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x { 2 H ( z ) − 1 } + Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B . (3.10) Corresp onding differen tial equations for the p erceptron rule are giv en as dl dt = η R B J − 1 √ 2 π + η π tan − 1 q 1 − R 2 B J R B J , (3.11) dR J dt = − R J l dl dt + η l √ 2 π ( R B − R J ) , (3.12) dR B J dt = − R B J 1 l dl dt + 1 l B dl B dt + η B l B √ 2 π R J 2 e − a 2 2 − 1 − R B J + η q lK √ 2 π q K − R B J + 2 η η B K l B l ( K − 1) Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x − Z ∞ z D y H ( − z 1 ) + Z z −∞ D y H ( z 1 ) + Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x { 2 H ( z 2 ) − 1 } (3.13) Solving these differential equations for the studen t and the ensemble teac hers, w e can obtain the generalizatio n errors ǫ g J and R J as a f unction of time step. 4. Results and Discussion In this sectio n we p resen t dyn amical b eha vior of the order parameter R J and the general- ization error ǫ g J obtained b y solving n umerically the set of the differen tial equations obtained in the previous section. In order to s tudy “dynamical” effect of the ens emble teac hers, w e compare results of tw o different cases; one with the teac hers fixed to a steady state and the other with the teac hers k ept to learn in the steady state sh aring the same inputs with the student . In this study , w e c ho ose the threshold v alue a = 0 . 5 of th e non-monotonic p erceptron for the true teac her, yielding l B /η B ≃ 0 . 93, R B ≃ 0 . 76 and q ≃ 0 . 91 in the steady s tate for the ensem ble teac hers. W e also p erform d ir ect s im ulations of the giv en up date rules for the fi nite-size p erceptrons. In the simulatio n s w e use the dimension of v ectors N = 10 4 and p erform 10 5 tra jectories of the learning pro cess for taking the a ve rage o v er the random inputs. As s h o wn in fi gures b elo w, although a limited case with η = 0 . 1 is on ly sho wn for a v oiding cro wded plots, th e results of R J and ǫ g J obtained by the simulatio n s for all the parameter 8/18 J. Phys. So c. Jpn. Full P aper studied agree with the theoretical ones by the order-parameter differen tial equations, This confirms that the assu mption of the self-a veragi ng is appropriate in our mo del. Figure 1 shows time dep endence of R J for th e Hebbian learning when the ensemble teac hers stop to learn and tak e a s teady-state ve ctor. The transient p rocess of R J dep ends on the learning rate η of the student and the n u m b er K of the ensemble teac hers. The v alue of R J gets larger w ith increasing the num b er K and th e learning rate η , meaning th at the stud en t comes close to the true teac her. As the time t go es on, it appr oac hes monotonically a steady v alue, whic h incr eases as K increases. Inte r estingly , the steady v alue of R J exceeds the v alue of R B when the num b er K of the ensem ble teac hers is greater than 1. This is similar to that sho wn in ref. 8. Figure 2, on the other hand , sh o ws the corresp ond in g time dep endence of R J when the ensem ble teac hers contin ue to learn in their steady state. While at the ve r y b eginning of the learning pro cess the v alue of R J sho ws monotonic time dev elopment similar to the case that the ensemble teac hers are fixed , it is larger than that with the fixed teac hers after a certain time and even tually app roac hes unit y , whic h is ind ep enden t of the learnin g rate, ev en if the num b er K is one. It should b e noted that the v alue of R B is common in t w o cases of Figs. 1 and 2. This im p lies that th e num b er K of the ensemble teac hers is not efficien t for the learnin g of the s tu den t, b ut their con tinuous learning ev en with a fixed similarity to the true teac her is significan tly imp ortan t. Figure 3 sho ws dynamical b eha vior of the generaliza tion error of the student for the Hebbian learning, which monotonically d ecreases and even tually conv erges to th e steady v alue when the en s em ble teac hers are fi x ed . Th e steady v alue of ǫ g J only dep ends on th e num b er K and not th e learning rate η . As K in creases, the v alue decreases and furtherm ore it can b e smaller than th at of the generalizatio n err or ǫ g B of the ensem b le teac hers when K is larger than one, r eflecting the b eha vior of R J . This m eans that the p erformance of the student b ecomes b etter than the ensemble teac hers wh en K ≥ 2. The obtained v alue of ǫ g J , ho wev er, d oes not reac h th e fu ndamen tal minimum v alue of th e generalization error in this case ev en when K increases to infinit y . In Fig. 4 the dynamical b eha vior of ǫ g J is sh o wn in the case where the ensem b le teac hers are m o ving. In con trast to the case of the fixed ensemble teac hers, ǫ g J sho ws non-monotonic b ehavi or in the learning pro cess and the steady v alue of indep en d en t of b oth K and η wh ile it is qu ite larger than ǫ g B . The minim um v alue of ǫ g J reac hes the fund amen tal minim u m v alue at a certain time step, d ep ending on the learning rate η . In a sense, the mobile ensem b le teac hers is a b etter on-line learning mo del, w hile the b est p erformance o ccurs only at a transient state unfortun ately . Let u s turn to the p erceptron learnin g of the stu den t. W e sh o w the time devel op men t of R J for the fixed and m o ving ens emble teac hers in Figs. 5 and 6, resp ectiv ely . Th e steady v alues of R J coincide with R B b oth for the t wo cases and it is ind ep enden t of K and η . F u rther non-monotonic b eha vior is f ound for small η and large K and then the v alue of R J 9/18 J. Phys. So c. Jpn. Full P aper tak es a maximum v alue at a certain time step, which exceeds R B certainly as a transien t state. Mo ving the ensem ble teac h er s enhances significan tly the maxim u m v alue, meanin g that the student is closer to the true teac her. In particular, for small v alue of η the maximum v alue of R J for the unique moving teac h er is larger than th at for the K = ∞ fixed ensem b le teac hers. F u gues 7 and 8 sho w the corresp onding d y n amical b eha vior of the generalization errors ǫ g J of the p erceptron-learning student with the fi x ed and mobile ensem b le teac h ers, r esp ectiv ely . As exp ected from the b eha vior of R J in Figs. 5 and 6, the steady v alue of ǫ g J for all the case is the same as that of the en s em ble teac hers. Ho w eve r, an essen tial difference is found in transient b ehavio r of ǫ g J . Although th e minimum v alue d oes not necessarily ac hieve the fundamental minimum v alue of ǫ g J in the case of the fixed ens em ble teac h ers, it do es f or small v alue of η in the mo ving ensemble teac hers with a finite time int erv al as s ho wn in Fig. 8. This means again that mo vin g the ensem ble teac hers pla ys an imp ortan t role for the learning p erformance of the stud en t. 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1 10 100 100 0 t R J η = 0 . 1 η = 1.0 . η = 10.0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 R B Fig. 1. Time dep endence of the direction co sine R J betw een the student J w ith the Hebbian learning and the true teacher A with a = 0 . 5 in the ca s e that the K ensemble teachers are fixed to b e a steady state vector. Curves repr esen t numerical solution of the or der -parameter differential equations with K = 1 , 50 a nd ∞ and η = 0 . 1 , 1 and 1 0. The straight line is the direction cos ine R B betw een the fixed ensemble teachers and the true teacher. Symbols represe nt cor respo nding results obta ined b y the direct sim ulation with system size N = 10 4 and η = 0 . 1. 5. Conclusion W e ha ve analyzed the generalizatio n p erformance of a s tuden t sup ervised b y ensemble mo ving teac hers in the framework of on-line learning. In this pap er w e adopted a non- monotonic p erceptron as a true teac her and a simple p erceptron as the ensem b le moving teac hers an d th e studen t. W e h a v e treated the Hebb ian learnin g and the p erceptron learning 10/18 J. Phys. So c. Jpn. Full P aper 0 0. 2 0. 4 0. 6 0. 8 1 1 10 100 100 0 t R J η = 0 . 1 η = 10.0 η = 1.0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 R B Fig. 2. Time dep endence of the direction co sine R J betw een the student J w ith the Hebbian learning and the true teacher A with a = 0 . 5 in the c a se that the ensemble teach ers contin ue to lear n in their steady state. The s ym b ols and the lines are the same as tho se in Fig. 1. 0. 3 0.3 5 0. 4 0.4 5 0. 5 1 10 100 100 0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 t η = 0 . 1 η =1.0 . η = 10.0 ǭ I $ ǭ I , Fig. 3. Time dep endence of the generalizatio n erro r of the s tuden t ǫ J betw een the student J with the Hebbian learning and the true teacher A with a = 0 . 5 in the case of the fixed ensemble teachers. The symbols and lines a re the s ame as those in Fig. 1 . as a learning r ule for the s tu den t and h a v e calculated the generalizati on err or of the stud en t with some ord er parameters analytically or numerically . In this stud y , we particularly fo cus on the effect of mobile ensemble teac hers on the learning p erform ance of the student. There- fore, it is assumed that the ensem ble teac hers lea r n only from the true teac h er by using the p erceptron learning and reac h a steady s tate b efore the student b egins to learn. This is helpful for separating a transien t learning effect of the ensemble teac hers from an intrinsic effect. In the Hebb ian learnin g, it h as b een pro ven that th e n u m b er K of the ensemble teac h ers is not efficien t, bu t their contin uous learning in their steady state is signifi cantly imp ortan t f or the student to come close to the tru e teac her. I n the case th at the ensemble teac hers con tin u e to learn, the v alue of R J ev entual ly approac hes unity , w hic h is indep en d en t of th e learning 11/18 J. Phys. So c. Jpn. Full P aper 0. 3 0.35 0. 4 0.45 0. 5 1 10 100 1000 t ǭ I , Theory K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 ǭ I $ η = 0 . 1 η = 1.0 η =10.0 Fig. 4. Time dep endence o f the generaliza tion error of the student ǫ J betw een the student J with the Hebbian learning a nd the tr ue teacher A with a = 0 . 5 in the cas e of the mobile ensem ble teachers. The symbols of the lines a nd plots ar e the sa me as in Fig. 1. 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 1 10 100 100 0 t R J η = 0 . 1 η = 10.0 η = 1.0 . Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 R B Fig. 5. Time dep endence of the direction c o sine R J betw een the student J with the p erceptron learning and the true teacher A with a = 0 . 5 in the case of the fixed ensemble teachers. The symbols of the lines and plots ar e the same as in Fig. 1. rate, eve n if the num b er K is one. Although the stud en t w ith R J = 1 do es not alw a y s m ean a b est learning p erformance in the Hebbian learning, the minimum v alue of ǫ g J reac hes the fundamental minimum v alue as a transient state, regardless of the num b er K . This is sh arp con trast to th e case of th e fixed ensem ble teac hers, in whic h the fu ndamen tal minimum v alue of ǫ g J nev er o ccurs. The time step at whic h ǫ g J has a minim u m v alue decreases with increasing the learning rate η , b ut its precise step has not b een predicted theoretic ally at the pr esen t momen t. In the p erceptron learning, in cont r ast to the Hebbian learning, no s ignifi can t d ifference has b een found in the s tea dy states. The steady v alues of R J and ǫ g J coincide with those of R B and ǫ g B in b oth of th e fi xed and mobile ens em ble teac hers. Ho we v er, the effect of the 12/18 J. Phys. So c. Jpn. Full P aper 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1 1 10 100 100 0 t R J η = 0 . 1 η = 1.0 η = 10.0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= Fig. 6. Time dep endence of the direction c o sine R J betw een the student J with the p erceptron learning and the true teacher A with a = 0 . 5 in the case of the mobile ensemble teachers. The symbols of the lines and plots ar e the same as in Fig. 1. 0. 3 0.3 5 0. 4 0.4 5 0. 5 1 10 100 100 0 t ǭ I , η = 0 . 1 η = 1.0 η = 10.0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 ǭ I $ Fig. 7. Time dep endence o f the generaliza tion error of the student ǫ J betw een the student J with the perce ptr on le arning a nd the true teacher A with a = 0 . 5 in the case tha t the fixed ensemble teachers. The symbols of the lines a nd plots ar e the sa me as in Fig. 1. mo ve men t of the ensemble teac hers app ears in the transien t state in the learning pro cess, where, in p articular for th e s m all v alue of the learning rate η , th e m axim um v alue of R J exceeds the v alue of R B and th en the minimum v alue of ǫ g J reac hes the fun damen tal minimum v alue ev en if th e n u m b er K is one. In the case of the fixed ensemble teac hers, while the former is found only f or th e large K and small η , the latter is hardly seen for an y parameter observed. It would b e in teresting to see that th e result of the mobile ensemble teac hers weakly dep ends on the num b er of the ensem ble teac hers. F ur ther, the minim um v alue of ǫ g J for the K = 1 mobile en sem ble teac her is smaller than that for K = ∞ fi xed ensemble teac hers. Our stu d y suggests that the mov emen t of the ensem b le teac hers, rather than the n u mb er K , is imp ortan t for the student learning in our m od el. 13/18 J. Phys. So c. Jpn. Full P aper 0. 3 0.3 5 0. 4 0.4 5 0. 5 1 10 100 100 0 t ǭ I , η = 0 . 1 η = 1.0 . η = 10.0 Theor y K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 K= п , η = 0 . 1 K= 1 , η = 1 . 0 K= 50 , η = 1 . 0 K= , η = 1 . 0 K= 1 , η = 10 . 0 K= 50 , η = 10 . 0 K= , η = 10 . 0 п п Sim ulation K= 1 , η = 0 . 1 K= 50 , η = 0 . 1 ǭ I $ Fig. 8. Time dep endence o f the generaliza tion error of the student ǫ J betw een the student J with the p e rceptron learning and the true teacher A with a = 0 . 5 in the cas e of the mobile ensemble teachers. The symbols of the lines a nd plots ar e the sa me as in Fig. 1. One of the dr a wbac ks of the present mo del is that the minim um of ǫ g J is giv en as the transien t state in the learning pro cess and that n o alg orithm is found to s top the learning at the transien t state. W e p oint out that the p erceptron learning shows a finite time interv al of the transient state whic h giv es the minim u m of ǫ g J as sh o wn in Fig. 8. This m igh t b e con ve nien t in comparison to the Hebbian learning, bu t the explicit constru ction of the stopp ing algorithm, including a pr actical w a y , still remains to b e solv ed in fur ther work. Ac kno w ledgmen ts W e are grateful to S. Miy oshi for a critical reading of this man uscrip t and fru itful discus - sions. T his w ork w as sup p orted by the Gran t-in-Aid for Scientific Researc h on the Priorit y Area “Deep ening and Expansion of S tatisti cal Mec hanical Informatics” (No. 180700 4) by Ministry of Edu cat ion, Cultu r e, Sp orts, Science and T ec hnology . App endix A: Deriv ation of the learning dynamics for the ensem ble teac hers In this app endix, w e deriv e a set of th e ordin al differential equations (3.1), (3.2) and (3.3) of the order parameters for the ensem ble moving teac hers in our m od el. F rom the up date ru les of the ensemble teac hers of eq. (2.21), a standard calculus 3) leads to the follo wing ordinal differen tial equations in terms of the a v erage ov er th e correlat ed Gaussian v ariables, dl B k dt ′ = h f k v B k i + h f 2 k i 2 l B k , (A · 1) dR B k dt ′ = − R B k l B k dl B k dt ′ + h f k v i l B k , (A · 2) dq k k ′ dt ′ = − q k k ′ l B k dl B k dt ′ − q k k ′ l B k ′ dl B k ′ dt ′ 14/18 J. Phys. So c. Jpn. Full P aper + h f k ′ v B k i l B k ′ + h f k v B k ′ i l B k + h f k f k ′ i l B k ′ l B k , (A · 3) where the con tinuous time t ′ is defin ed b y the thermo dynamic limit of m ′ / N w ith m ′ b eing the time step of the ensemble teac h ers in eq. (2.21 ). The brack et h· · · i denotes th e a verag e with resp ect to the m ultiple Gaussian d istribution giv en in eq. (2.15). Since eac h comp onent of A and B 0 k are generate d indep end en tly from the Gaussian distribution, A and B 0 k with an y k are orthogonal to eac h other in the thermo dyn amic limit. Then, the initial cond itions of the differential equations for R B k and q k k ′ are giv en by R 0 B k = 0 , q 0 k k ′ = 0 , (A · 4) One easily fi nds that from eqs. (A · 1)-(A · 3 ) and (A · 4) that the order parameters R B k , l B k and q k k ′ are in v arian t un der a p erm utation of the index k of the ensem ble teac hers. Because of the symmetry , we omit the subscrip ts k from the order parameters. W e can calculate sample a ve r age s in eqs. (A · 1)-(A · 3) and obtain h f k v B k i = η B √ 2 π R B 2 exp − a 2 2 − 1 − 1 , ( A · 5) h f 2 k i =2 η 2 B Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B , (A · 6) h f k v i = η B √ 2 π 2 exp − a 2 2 − R B − 1 , (A · 7 ) h f k ′ v B k i = h f k v B k ′ i = η B √ 2 π R B 2 exp − a 2 2 − 1 − q , (A · 8) h f k f k ′ i =2 η 2 B Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D xH ( z ) , (A · 9) where z ≡ − ( q − R 2 B ) x + R B q 1 − R 2 B v q (1 − q )(1 + q − 2 R 2 B ) . ( A · 10) Substituting them into eqs. (A · 1), (A · 2) an d (A · 3), the d ifferential equations (3.1), (3.2) and (3.3) are derive d. App endix B: Deriv ation of the learning dynamics for the studen t As in the app endix A, a set of th e differentia l equ atio n s for the student dynamics is derived in this app endix. F r om the up date rule (2.23) of the stud en t, the stand ard calculus again leads to the follo wing equations: dl dt = 1 K K X k =1 h g k u i + h g 2 k i 2 l , (B · 1) 15/18 J. Phys. So c. Jpn. Full P aper dR J dt = − R J l dl dt + 1 K K X k =1 h g k v i l , (B · 2) dR B k J dt = − R B k J l dl dt − R B k J l B k dl B k dt + 1 K K X k ′ =1 h f k u i l B k + h g k ′ v B k i l + h f k g k ′ i l B k l , (B · 3) where t denotes a con tinuous time d efined by t = m/ N . As an initial condition of eqs. (B · 2) and (B · 3), we tak e R 0 J = 0 , R 0 B k J = 0 , (B · 4) since A , B 0 k and J 0 are orthogo nal to eac h other in the thermo dynamic limit. It is sho wn from eqs. (B · 4) and (B · 3) that the order parameter R B k J do es not dep end on the ind ex k . Then, one can omit the sub script k fr om the ord er p arameter w ithout loss of the generalit y . By substituting the tw o up date fun ctio ns g of the Hebbian and the p erceptron lea r ning re- sp ectiv ely , one calculat es the Gaussian a v erages in eqs. (B · 1)-(B · 3) in the case of the Hebbian learning as h g k u i = η r 2 π R B J , (B · 5) h g 2 k i = η 2 , (B · 6) h g k v i = η r 2 π R B , (B · 7) h f k u i = η B √ 2 π R J 2 exp − a 2 2 − 1 − R B J , (B · 8) h g k ′ v B k i = η r 2 π q δ k ,k ′ , (B · 9) h f k g k ′ i = − 2 η η B Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x { 2 H ( z ) − 1 } , (B · 10) h f k g k i = − 2 η η B Z − a −∞ + Z a 0 D v H − R B v q 1 − R 2 B , (B · 11) and in the case of the p erceptron learning as h g k u i = η √ 2 π ( R B J − 1) , (B · 12) h g 2 k i = η 2 π tan − 1 q 1 − R 2 B J R B J , (B · 13) h g k v i = η √ 2 π ( R B − R J ) , (B · 14) 16/18 J. Phys. So c. Jpn. Full P aper h f k u i = η B √ 2 π R J 2 exp − a 2 2 − 1 − R B J , (B · 15) h g k ′ v B k i = η √ 2 π ( q δ k ,k ′ − R B J ) , (B · 16) h f k g k ′ i = 2 η η B Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x − Z ∞ z D y H ( − z 1 ) + Z z −∞ D y H ( z 1 ) , (B · 17) h f k g k i = 2 η η B Z − a −∞ + Z a 0 D v Z ∞ − R B v √ 1 − R 2 B D x { 2 H ( z 2 ) − 1 } . (B · 18) Here, z 1 and z 2 are defin ed as z 1 ≡ − ( R B J − R B R J ) √ 1 − q y + q 1 + q − 2 R 2 B x + R J q (1 − R 2 B )(1 + q − 2 R 2 B ) v q (1 − R 2 B ) (1 + q )(1 − R 2 J ) − 2( R 2 B − 2 R B R J R B J + R 2 B J ) (B · 19) and z 2 ≡ − ( R B J − R B R J ) x + R J q 1 − R 2 B v q 1 − R 2 J − R 2 B − R 2 B J + 2 R B R J R B J , (B · 20) and δ k ,k ′ is the Kr onec k er delta d efined b y δ k ,k ′ = ( +1 , k = k ′ , 0 , k 6 = k ′ . (B · 21) Inserting (B · 5)-(B · 11) and (B · 12) -(B · 18 ) in to (B · 1)-(B · 3 ) giv es th e dyn amical equ ations (3.8)- (3.10) for the Hebbian rule and those (3.11)-(3 .13) for th e p erceptron one, resp ectiv ely . 17/18 J. Phys. So c. Jpn. Full P aper References 1) D.Saad, (ed.): On-line Learning in Neural Netw or ks (Cambridge Univ ers it y Press, Cam bridg e, 1998). 2) A.Engel and C.V a n den Bro eck: Statistical Mechanics of Lear ning (Cambridge Univ er sit y Press, Cambridge, 2 0 01). 3) H.Nishimori: Statistica l Physics of Spin Glass e s and Informa tio n Pro cessing: An Introduction (Oxford University P ress, Oxford, 200 1). 4) S.Miyoshi and M.Ok ada: J. P h ys. So c. Jpn. 75 (2006) 02400 3. 5) M.Urak ami, S.Miy os hi and M.Ok ada : J. Phys. So c. Jpn. 76 (2007) 04 4003. 6) J.Inoue , H.Nishimori and Y.Kabashima: J. Ph y s A 30 (1997) 3795 . 7) S.Miyoshi and M.Ok ada: J. P h ys. So c. Jpn. 75 (2006) 04400 2. 8) H.Utsumi, S.Miyoshi a nd M.Ok ada: J. Phys. So c. J pn. 76 (20 07) 11400 1 . 9) R. Urbanczik: Phys. Rev. E 62 (2000 ) 1448. 10) S. Miyoshi, K . Hara a nd M. Ok ada: Ph ys. Rev. E 71 (200 5 ) 03 6116. 18/18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment