An Enhanced Static Data Compression Scheme Of Bengali Short Message
This paper concerns a modified approach of compressing Short Bengali Text Message for small devices. The prime objective of this research technique is to establish a low complexity compression scheme suitable for small devices having small memory and…
Authors: Abu Shamim Mohammad Arif, Asif Mahamud, Rashedul Islam
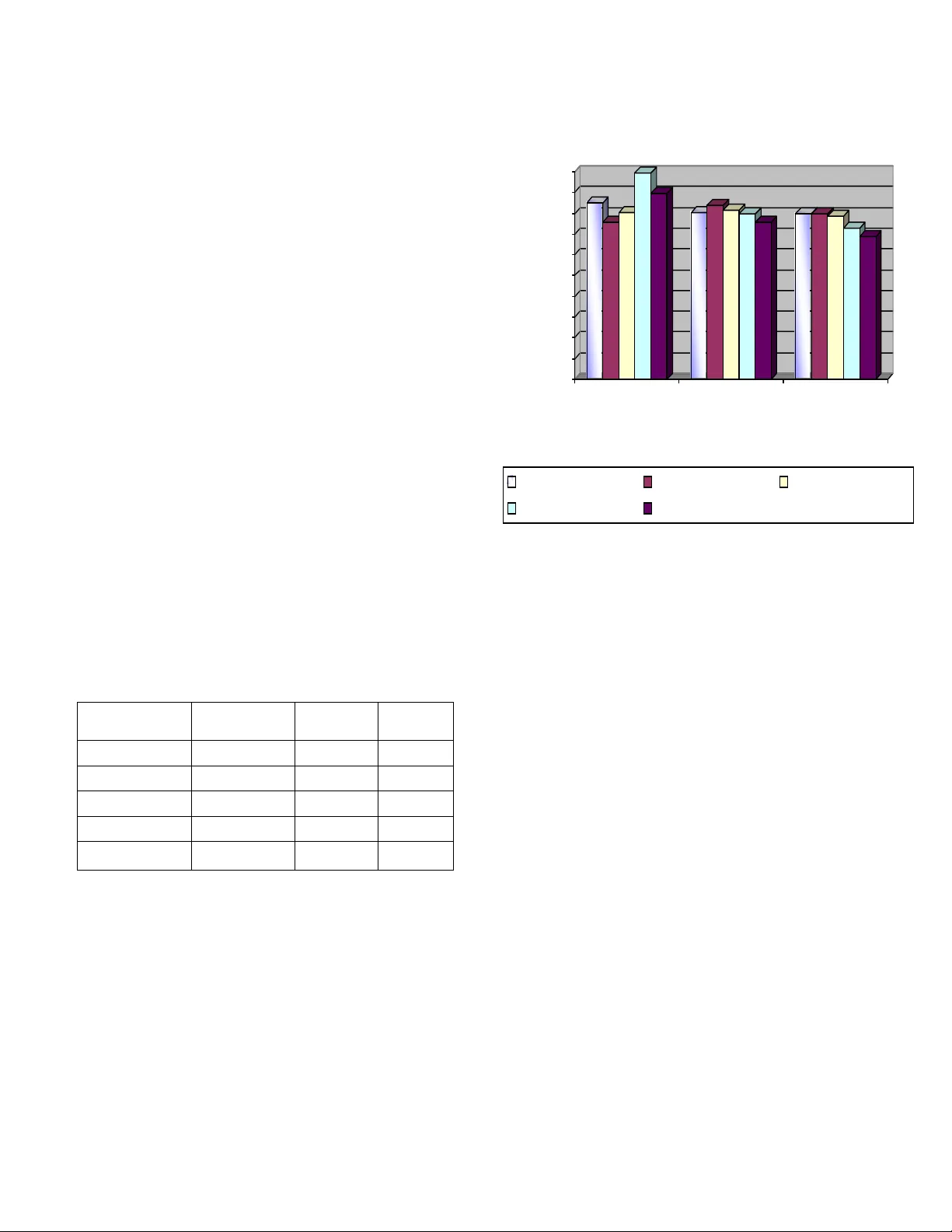
AN ENHANCED STATIC DATA COMPRESSION SCHEME OF BENGALI SHORT MESSAGE Abu Shamim Mohammad Arif Assistant Professor, Computer Scie nce & Enginee ring Discipline, Khulna University, Khulna, Ba ngladesh E-mail: shamimarif@yahoo.com Asif Mahamud Computer Scie nce & Enginee ring Discipline, Khulna University, Khulna, Ba ngladesh. E-mail: asif.cse04@gmail.com Rashedul Islam Computer Scie nce & Enginee ring Discipline, Khulna University, Khulna, Ba ngladesh. E-mail: rashedrst@yahoo.com Abstract —This paper concerns a modifie d approach of compressing Short Ben gali Text Message for small d evices. The prime objective of this resea rch technique is to establish a low- complexity compression sc heme su itable for small devices having small memory an d relatively lower p rocessing speed . The basic aim is not to compress text of any size up to its maximum level without having any constraint on space and time; ra ther than the main target is to comp ress shor t messages up to an optimal level which needs minimum space , consume less time and the processor requiremen t is lower. We have impl emented Character Masking, Dictionary Matching, Associative r ule of data mining and Hyphenation algorithm for syllable based co mpression in hierarchical ste ps to achieve lo w complexity lo ssless compress ion of text message for any mobile devices. The scheme to ch oose the diagrams are performed on the basis of extensive statistical model and the static Huffman codi ng is done through the same context. I. I NTRODUCTION We are now at the age of science. Now a day, Science brings everythi ng to the door of us. Scie nce makes life easy with its ma ny renowned and unrenowne d achieveme nts. Small devices are one of such achiev ements. In case of ou r personal computer there is much space to store various types of data. We never worried about how much s pace the data or messages take into the me mory to store that data. But in c ase of small de vice we have to consider the memo ry space required to store the respective data or text m essages. Compression of the te xt message is the number one techni que in this case. Compression is an art of re ducing the size of a file by removing red undancy in its st ructure. Data Com pression offers an attractive approach of reducing communication cost s by using available ban dwidth effectively . Data Compression technique can be divi ded into two m ain categories nam ely for Lossless Data Compression and Lossy Data Com pression. If the recovery of data is exact then the compression algori thms are called Lossless. This type of lossless compression algorithms are used for all kinds of text, scientific and statistical databases, m edical and biological images and so on. The main usage of Lossy Data Compression is in normal image compression and in m ultimedia compression. Our aim is to develop a Lossless Com pression technique for com pressing short message for sm all devices. It is necessary to clearly me ntion here t hat compression fo r small devices m ay not be the ult imate and maxim um compression. It is because of the case that in order to ensure compression in the m aximum level we definitely need t o use and implement algorithm s sacrificing space and time. But these two are the basic limitati ons for any kind of mobil e devices especially cellular phones. Thus we are to be concerned on such techniques suitab le to compress data in the most smart and efficient way from the point of view of low sp ace and relatively slower perform ance facility and which is not require higher processor configurat ion. The basic objective of th e thesis is to implement a compression technique suitable for small devices to facilitat e to store text messages by compressing it up to a certain level. More precisely saying- Firstly, to achieve a technique whic h is simple and bett er to store data in a sm all device. Secondly, to keep required com pression space minimum in order to cope with memory of sm all devices. Thirdly, to have the compression time optimal and sustainable. II. LITERATURE SURVEY A. Definitions Data Compres sion In computer science and inform ation theory, data compression oft en referred to as source codin g is the process of encoding inform ation using fewer bit s (or other inform ation- bearing units) than an un-encoded re presentation wo uld use through use of s pecific encoding schem es. One popular instance of compression that ma ny computer users are familiar with is the ZIP file format, which, as well as providing compression, acts as an achiever, storing many files in a single output file. As is the case with a ny form of com munication, compressed data comm unication only work s when both the sender and receiver of the informat ion understand the e ncoding scheme. For exam ple, this text makes sense only if the receiver understands that it is in tended to be interp reted as characters (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 97 representing the English language. Similarly, compressed data can only be understoo d if the decoding m ethod is known by the receiver. Some compression algorith m s exploit this property in order to encrypt data during the com pression process so that decompression can only be achieved by an authorized p arty (eg. through the use of a pass word). [9] Compression is useful because it helps reduce the consumption o f expensive resources, such as di sk space or transmissi on bandwidth. On the downside, com pressed data must be uncom pressed to be viewed (or he ard), and this extra processing may be detrimental to some applications. Fo r instance, a compression scheme for text requires mechanism for the text to be decompressed fast e nough to be viewed a s it's being decompressed an d may even requir e extra temporary space to decompress the text. The design of data compression schemes therefore involve trade- offs between vari ous factors, including the d egree of compression, the amount of distort ion introduced (if usi ng a lossy com pression scheme), and the computati onal resources required to com press and uncom press the data. Short Message A message in its m ost general meaning is an ob ject of communicati on. It is something w hich provides inform ation; it can also be this information itself [9]. Therefore, its meaning is dependent up on the context in which it is used; the ter m may apply to both the information and its form. A com muniqué is a brief report or statement released by a public agency. [9] Short Text Message Text Messaging, also cal led SMS (Short Message Servi ce) allows short text messages to be received and displayed on the phone. 2-Way Text Me ssaging, also called MO-SMS (Mobil e- Originated Short Message Service,) allows messages to be sent from the phone as well .[9] Text messaging impli es sending short messages generall y no more than a couple of hundred characters in length. The term is usually app lied to messaging that takes place between two or more mobil e devices Existing Methods and Systems for Lossless Data Compression Though a number of research es have been performed regarding data compression, in the specific field of SMS Compression the num ber of available research works is not huge. The remark able subject is that all the compression technique is for other l anguages b ut not for B engali. The techniques are mainly for Eng lis h, Chinese, and Arabic etc. Bengali dif fers from t hese languages f or its distinct symbol and conjunct letters. So , we have to gather knowled ge from the other la nguage compress ion technique and then had t o go for our respective com pression. The following two sections give a glim pse of the most recent research de velopments on SMS Compression issue. Efficient Data Compression Scheme using Dynamic Huffman Co de Applied on Arabic Language [1] This met hod is proposed by Sameh et al . In add ition to the categorization of data compression schemes with respect to message and code word lengt hs, these methods are classified as either static or dynamic. A st atic method is one in which the mapping from the set of messages to t he set of code-wo rds is fixed bef ore transmi ssion begins, s o that a given m essage is represented by the sam e codeword every time it appears in the message ensemble. The classic static defined-word sche me is Huffman c oding. In Huffman coding, the a ssignment o f code- words to source messages is based on the probabilities with which the source m essages appear in the message ensemble. Messages which appear more frequently are represe nted by short code-words; messages with smaller probabilities map to longer code-words. Th ese probabilities are determined before transmission begins. A c ode is dynam ic if the mappi ng from the set of messages to t he set of code-wor ds changes over time. For exam ple, dynamic Huffman coding involves computing an appro ximation to the probabilities of occurrence "on the fly", as the ensemble is being transmitted. The assignment of code-words to messages is based on t he values of the relative frequenci es of occu rrence at each point in time. A message x may be represented by a short cod eword early in the transmission because it occurs frequently at the beginning of the ensemble, even though its p robability of occu rrence over the total ensemble is low. Later, when the more probable messages begi n to occur w ith higher frequency, t he short codeword will be mapped to one of the higher prob ability messages and x will be mapped to a longer cod eword. There are two m ethods to represe nt data befo re transm ission: Fixed Length Code and Variabl e length C ode. The Huffm an coding algori thm produces an o ptimal variable le ngth prefix code for a given alphabet in w hich frequencies are pre assigned to each letter in the alphabet. Symbols that occur more fre quently ha ve shorter Code words than symbol s that occur l ess freque ntly. The two symbols that occur least frequently will have the same codeword length . Entropy is a m easure of the inform ation content of data. The entropy of the data will specify th e amount of lossless data compression c an be achieved . However, finding the e ntropy of data sets is non trivial. We ha ve to notice that there is no unique Huf fman code because Assi gning 0 and 1 t o the branches is arbitrary an d if ther e ar e more nodes with th e same probability, it doesn’t matter how they are connected The av erage mes sage leng th as a measure of efficiency of the code has been adop ted in this work. The average search length of t he massage is the summation of the multiplication of the len gth of code-word and its probability of occurrence. Also the compression ratio as a measure of efficiency has been used. Comp. Ratio = Compressed file size / source file size * 100 % The task of c ompression con sists of two com ponents, an encoding algorithm that takes a message and generates a “compressed” representation (hopefully with fewer bits) and a decoding algorith m that reconstructs the original message or some approximation of it from the co mpressed representation. Genetic Algorithms in Syllable-Based Text Compression [2] This met hod is proposed by Tomas Kuthan an d Jan Lansky . To perform syllable-based com pression, a proced ure is needed (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 98 for decomposition into syllables. They call an algo rithm hyphenation a lgorithm if, whenever giv en a word of a language, it returns it’s deco mposition into syllables. According to the definition of syllable every two different hyphenation of the same word always contain the same number of syllables. The re can be an algorithm that works as a hyphenation algorithm for every lan guage. Then it is called universal hyphenation algorithm. Otherwise it is called specific hyphenation al gorithm. They descr ibe four universal hyphenation algorithms: universal left P U L , universal right P U R , universal middle-left P U M L and universal mi ddle-right P U M R . The first phase of all these algorithms is the same. Firstly, they decom pose the given t ext into words and for eac h word mark its consonants and vowels. Then all the maxi mal subsequences of vowel are dete rm ined. These blocks form the ground of the syllables. All the con sonants before the first block belon g to the first syl lable and those behi nd the last block will belong to the last syllable. This algorithm differs in the way they redistribute the inner groups of c onsonants be tween the two a djusting vowel blocks. P U L puts all the consonants to the preceding block and P U R puts them all to the subseque nt block. P U M L and P U M R try to redistribute t he consonant bl ock equally. If t heir number is odd P U M L pushes the bi gger parity to the left, while P U M R to the right. The only exception is, when P U M L deals with a one- element group of con sonants. It puts the only consonan t to the right to avoid creation of n ot so comm on syllables beginni ng with a vowel. Hyphenatin g priesthood correct hyphena tion priest-hoo d universal le ft P U L priesth-ood universal right P U R prie-sthood universal m iddle-left P U M L priest-hoo d universal m iddle-right P U M R pries-thood Effectiveness of these algorith ms is then m easured. In general, P U L was the worst one; it had lowest number of correct hyphen ations and produ ced largest sets of uni que syllables. The main reason for this is that it generates a lot of vowel-start ed syllables, whic h are not very comm on. P U R was better but the m ost successful we re both ’middle’ versions. English docum ents were best hyphenate d by P U M R , while with Czech texts P U M L was slightly better. Lossless Compression of Short English Text Message for JAVA Enable Mob ile Devices [3] This me thod is propose d by Rafiqul et al. publi shed in preceedings of 11th Internat ional Conference on Com puter and Information Tec hnology (IC CIT 2008), in December, 2008, Dhaka, Bang ladesh. The Total compression pro cess is divided into three steps name ly for C haracter Masking, Substring Substitution or Dictionary Matching or Partial Coding, Bi t Mapping or Enc oding (Using Fixe d Modified Huffman Codi ng). The very firs t step of planned SMS Compressio n is Character Masking. Character Masking is a process in which the character(s) code(s) a re change d or re-defi ned on the basis of any specifi c criteria. I n concerned tas k it is plan ned to use character ma sking for reduci ng th e storage overhead for blank spaces. Firstly the spaces are expected t o be searched out and then encoded by a prede fined code-wor d. This code word should be unique for the overall co mpression. For multiple consecutive blank spaces the sam e technique ma y be employed. The modi fied message is t hen passed to wards the next compress ion step for dictiona ry Matching or Par tial Coding. In the second st ep they employ Dicti onary Matching or Partial Coding. In this phase th e string referre d from the first step is passed through a parti al coding which e ncodes the masked character s (perfo rmed pr eviously in the firs t step) on the basis of the following char acter. The character following masked character mergers the masked space by encoding it. Thus all the spaces are m erged and as a result it may be certainly reduce a m entionable amount of characters. Aft er this task we pass the modified string of message through a dictio nary mat chi ng sche me wher e the mes sage is search ed for matching s ome pre-de fined m ost-commonly used words or substrings or punctuations to reduce the to tal number of characters. The message is then forwarded to Step 3 where the actual coding i s perform ed. In the final ste p of coding t hey have used s tatic Huffm an Coding Styl e. But here the m odification is ma de that in spite of calculating on-stage codes th ey use predefined codes in order to reduce the sp ace and time complexity. The codes for dictionary entries are also predefined. The to tal message is thus encoded by a c omparativel y small num ber of bits and hence they get a compresse d outcome. Compression of a Chinese Te xt [4] This met hod is propose d by Phil Vines, Justi n Zobel. In this met hod, the byte oriented ve rsion of PPM (Par tial Predictive Matching) is not pr ed icting characters, but rather halves of character. It is re asonable to suppose that modifying PPM to deal with 16 bit characters should enab le the model to more accurately capture the st ructure of the language and hence provide better com pression .They have i dentified several chang es that need to be made to the PPM implementation describ ed above to allow effective 16 -bit coding of Chinese. First, the halving limit needs to be modified the nu mber of 16-bit ch aracters that can be occur in a context in much greater tha n of 4-bit ch aracter s. So a large probability space is required . Second, in conjunction with this change the increm ent should also be increa sed to force more frequent halving and prevent the m odel from stagnating. T heir experiments suggest that a halv ing limit of 1024 and an increment of 16 are appr opriate. Third , the me thod described above for estimating escap e probabilities may not be appropriate since so many characters are novel. Fourth, model order must be chosen. Most implements encode bytes, but this is an arbitrary choice and an y unit can be used within the constraints of memory size and model order. For En glish context s and symbols are quickly re peated, so that, after only a few kilobytes of t ext, good com pression is achi eved and context s of as little as three characters can give excellent co mpression. (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 99 As byte-orient ed PPM is a general met hod that gives g ood results not only for Engli sh text but f or a wide variet y of data types, an obvious option is to apply it directly to Chinese tex t. Higher order m odels take a lone r time to accum ulate contexts with probabilities that accurately reflect t he distribution. So that, when memory is limited, the models spends most of its time in the learning phase, where it emits large number of escape codes and i s unable to m ake . Thus they obse rve poorer compression because such co ntexts do not reappear sufficiently often before t he model need s to be flu shed and rebuild over 800. Reloading the model with immediate prior text after each flush is unlikely to helpfu l; since the problem is that there is not sufficient me mory to hold the model that make accurate prediction. It follows that increa sing the amount of memory available for st oring conte xts could be expected to im prove compressio n performance. H owever, assuming o nly moderate volumes of memory are available, managing eve n a character-based m odel can be pr oblematic; they believe t hat because of t he number of distinct symbols , use of a word-based model i s unlikely to be valuable. The implem entation of PPM describe d above uses a simple memory m anagement strat egy; all inform ation is discar ded when the available space is cons umed. III. PROPOSED SYSTEM Our prime concern of thesis is to implement a lossles s compression of sh ort Bengali text for low-powered de vices in a low complexity scheme. The idea behind t his is there are still many compression t echniques for languages l ike English, Arabic and other language an d m any people are still involving to improve t he compression ratio of m essages of the respective language. Som e of them are also published i n various conferences and jo urnals. Although Be ngali short message technique is achieved coupl e of years ago but there is not still any compression techniq ue suitable for Bengali languages. Bengali text com pression differs fro m English text compression from mainly two point s of views. Firstl y, the compression techniques i nvolving pseudo-c oding of uppercase (or lowercase) letters are not applicable for Ben gali text. Secondly, in case of Be ngali, we may em ploy specific mechanism of coding depe ndent vowel signs t o remove redundancy, w hich is absent f or the case of Engli sh. In Bengali , we have 91 disti nct symbol units i ncluding independ ent vowels, constant s, dependent vowel signs, two part independent vowel si gns, additional consta nts, various signs, additional signs and Be ngali numerals etc. A detai l of Bengali symbols available in. Moreover, in Bengali we have a large involvement of conjuncts which also focuses a scope of redundancy rem oval. Though English has g ot a fixed encoding base l ong ago, still now in practical ap plication, Beng ali has adapted unique encoding schem e. The use of Bengal i Unicode has n ot yet got a massive use. This is really a gr eat limitation for research in Bengali. Bengali text compression also suffers from the same problem. A. Compression Process In this pape r, we prop ose a new dic tionary base d compression techni que for Bengali text compressi on. To facilitate efficient searching and low complex coding of the source text, we employ term probabilit y of occurring characters and group of charac ters in a message wi th indexing the dictionary entries. The total compression scheme is divided i nto two sta ges: Stage 1: Building th e knowledge-base. Stage 2: Appl y proposed t ext ranking approach for compression the source text. Stage 1: Bui lding the know ledge-base The test-bed is formed from the standard Bengali tex t collections fr om various so urces. We consider a collection of texts of various categories and t hemes (like news, docum ents, papers, essays, poems and adverti sing docum ents) as the test bed. By reading the respective freque ncy statistics we select our respecti ve knowled gebase entries a nd divide the freque ncy into a fo ur level archit ecture. Assi gning mi nimum lengt h code-words to the selected compone nts is the mai n objective of the statistics gathering phase. It is remarkable that, though a few collections of domain speci fic text collection are available, still now no soph isticated Bengali text compression evaluation test-bed is availab le. As data compression and especially dicti onary based text compression great ly involves the structure , wording an d context of text s, a collection involving different types of t ext is a must fo r evaluating the compression. In construc ting the dictionary, we use the test- text-bed of 109 f iles varying from 4kb to 1800kb. The Variable Lengt h Coding (VLC ) algorithm [1] is used to produce an optim al variable length prefix code fo r a given alphabet. Noteworthy that, in the previous step of knowledgebase form ation, frequencies is already pre-assigned to each letter in the alphabe t. Symbols that occur m ore frequently ha ve shorter Code-wor ds than symbols that occur less frequently. The two symbols that o ccur least frequently will have the sa me codeword length . Entropy is a measure of the information cont ent of data. The entropy of the data will specify the amount of l ossless data compression can be achieved. However, fi nding the entropy of data set s is non trivial. We have to n otice that there is no u nique Huffman code because Assigning 0 and 1 to the branc hes is arbitrary and if there are more nodes with the same probability, it do esn’t matter how they are connected. The average message length as a measure of efficiency of the code has been adop ted in this work. Avg L = L1 * P (1) + L2 * P (2) + ….. + Li * P (i) Avg L = ∑ Li * P (i) Also the compression ratio as a m easure of efficiency has been used. Compression Ratio = Compressed file size / source file size * 100 % The task of com pression consist s of two com ponents, an encoding algorithm that takes a message and generates a “compressed” representation (hopefully with fewer bits) an d a decoding algorithm that reconstru cts the original message (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 100 or some appr oximation of it from the com pressed representation. Stage 2: Apply pr oposed text ranking approac h for compression the source text Text ranking i s an elementary schem e which is used to a ssign weights or index of texts or terms (especially word toke ns) on the basis of any suitable scheme or c riteria. Thi s scheme of indexing o r ranking is ideall y frequency of occurrence of the texts or even probability of occu rrence of the texts or component s. In our m ethod, we gra b the source t ext and ta ke the Unicode value of the corresponding dat a. Our method of compression proces s differs mai nly from others i n this point. Still now no one has the method of taking the most successive match. But we have the way to take the most successive match. We will start with maxim um level and proceed thr ough the hie rarchi cal levels to find successful match. It is to remark that in the last level there is only letters and their Unic ode value. So, if a word does not m atch in any level it has to match in this level. To perform compression, we need a procedure for decomposition into syllables. We will call an algorithm hyphenation algorithm [2] if, whenever given a word of a language, it return s it’s decomposition into syllables. It is called universal hyphenation algorithm. By this algorithm we can ge nerate the successful match for a string or sentence what othe r method ha ven’t done . We call this algorithm as specific hyphenation algorithm. We will use four universal hyph enation algorithms: universal le ft P U L , universal rig ht P U R , universal m iddle-left P U M L and universal m iddle-right P U M R . The first phase of all these algorithms is the same. Firstly, we decompose the given text into words a nd for each wo rd mark its letter and symbol. Then we determine all th e maxima l subsequences of vowel. T hese blocks form the ground of the syllables. All th e consonants befo re the first block belo ng to the first sy llable and those behind the last block will belong to the last syllable. After takin g the most successi ve matching the n encode with the code-words obtained in the Step 1 for each matching elements. And lastly the resultant data will be transmitted. B. Decompression Process The total decom pression process can be divided into t he following three steps: Step 1: Grab the bit representat ion of the message Step 2: Identify the charact er representation Step 3: Display the dec oded message. As all the letters and symbols are to be coded in such a fashion that by looking ahead sev eral symbols (Typically the maximum length of the code ) we can distinguish each character (with attribute of Human Coding). In step 1 the bit represen tation of the modified message is performed. It is simpl y analyzing the bit maps. The second step involves recogn ition of each separate bit- patterns and i ndication of t he characters or sym bols indicat ed by each bit pattern. This recogn ition is pe rformed on the basis of the inform ation from fixed encodi ng table used at the t ime of encodi ng. The final step involves simply repr esenting i.e. display of the characters recognize d through decoding the received encoded m essage. IV. EXPERIMENT RESULT The proposed m odel of short text Compress ion for Bengali language provides much more efficiency than othe r SMS compression models. This propose d model is also expected to have lower complexity than that of t he remaining m odels. The steps provi ded are not previo usly impl emented in sam e model. The basic aspect of the model is, in this model we plan to use less than eight bit codeword for each character in ave rage using static coding in place of eight bits and hence we may easily reduce total nu mber of bits required in general to represent or transmit the message. The modification is required and to some extent essential because for low complexity devices is not any in telligent approach to calculate the codes for each character sacrificing tim e and space requirements. That is why it may be a good approach to predefine the code s for each charact er having less bit length in total to compress the message. Th e fixed codes will be determined from the heuristic values based on the dictionary we normally use. The ultimate aim is to use less number of bits to reduce the load of characters. We intend to apply th e dictionary matching or multi-grams method to enhance the optimality of com pression. Multi- grams m ethod is used in order to re place a num ber of used sub-string or even strings fr om the input message. Specific code words are de fined for t hose words or s ubstrings or strings. It is because t he case that if we can replace any pa rt of the message by a single characters t hen we can defini tely reduce the total number of character gradually. It is necessary to mention here that the co-o rdination of multi-grams or dictionary method wi th modifi ed Huffman coding ma y ensure the maxim um 3 to 5 p ossible com pression. In orde r to enha nce the perform ance of compres sion the di ctionary m atching or multi-grams will play a vital role in compression ratio becau se the propose thesis is based on successful a nd ultimate optimal compression of Bengali text at the level best for wireless mobile devices with small memory and lower performance speed. As we are usin g Huffman co ding for len gth seven whereas each characte r requires eight bits to be represented. Thus for n cha racters we will be a ble to com press n bits using fixed Huffman coding. In the nex t step we will be able to save the memory requirem ents for blank spaces using c haracter masking. For example, for any Bengali shor t message of length 200 characters it is usual to predict that we may have at least 25 spaces. If we ca n el iminate those blank spaces by masking with its consecutive char acter thro ugh ch aracter masking, then we may reduce those 25 characters from the original message. It is necessary to mention here that the dictionary matching or multi-grams method is completely (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 101 dependent on the probability distribu tion of input message and we are to be m uch more careful on c hoosing the dictionary entries for Bengali text. The implementation of the compression scheme is performe d using JAVA 2 Micro Edition with the simulation using Java-2 SE 1.5. Th e cellular phone s adapting the proposed C ompression too l must be JAVA powered. T he implementation will include bo th encoding and decoding mechanism. A. Discussions on Results The perform ance evaluatio n is perform ed on the basi s of the various corpuses. As the pr im e aspect of our proposed Compression Scheme is not to compress huge amount of t ext rather to compress texts with limited size affordab le by 36 the mobile devi ces i.e. embedded syst ems, we took bloc ks of texts less than one thousand charac ters chosen randomly from those files ignorin g binary files and other Cor pus files and performed the efficiency e valuation. The most rece nt study i nvolving c ompression o f text data are- 1. “Arabic Text Stegano graphy using multiple diacritics” by Adnan A bdul-Aziz Gut ub, Yousef Sal em Elarian, Sam eh Mohammad Awai deh, Aleem Khalid Alvi. [ 1] 2. “Lossless Com pression of Short English Text Message for JAVA e nables mobi le devices” by “Md. Rafi qul Islam, S . A. Ahsan Rajon, Anond o Poddar. [2] We denote the ab ove two methods as DCM-1 and DCM-2 respectively. The simulation was performed in a 2.0 GHz Personal Computer wit h 128 MB of RAM in threading e nable platform . The result for diffe rent size of blocks of text is as follows- Source DCM-1 DCM-2 Proposed Techniqu e Prothom Alo 4.24 4.01 3.98 Vorer Kagoj 3.78 4.19 3.98 Amader somoy 4.02 4.08 3.93 Ekushe-khul.poem 4. 98 3.98 3.65 Ekushe- khul.Article 4.48 3.79 3.44 0 0. 5 1 1. 5 2 2. 5 3 3. 5 4 4. 5 5 COM PRESSI ON RATI O DCM- 1 DCM- 2 PROPOS ED SCHEM E S CO M PR ESSI O N RA TI O CO M PA RI SO N PROT HOM A LO V ORER KA GOJ A MA DER SO MO Y Ekushe - khul . PO EM Ekushe - khul . A rtic l e V. CONCLUSION The prime objective of th is undergraduate research is to develop a more co nvenient low complex ity compression technique for sm all devices. As the environment is completely different from the usual one (PCs with huge m emory and amazingly greater perform ance sp eed) and the challenge is to cope with the low memory an d relatively less pro cessing speed of the cellular phon es, the ultimate obj ective is to devise a way to compress text messages in a s mart fashion to ensure op timal rate and efficiency for the mobile phones which ma y not be the best approach for other l arge-scale computing devices. That is why, in com parison to other ordinary data com pression schemes the prop osed is of low comple xity and less time consuming. REFERENCES [1] Sam eh Ghwanmeh,Riyad Al-Shalabi and Ghassan Kanaan “Efficient Data Compression Scheme using Dy namic Huffman code Applied on Arabic Language” Journal of Com puter Science,2006 [2] T omas Kuthan and Jan Lansky “Genetic algorithms in sy llable based text compression” Dateso 2007. [3] M d. Rafiqul Islam, S.A.Ahsan Rajon, Anondo Poddar “Lossless Compression of Short English T ext Message for JAVA enable mobile devices” Published in Proceedings of 11t h International Conference on Computer and Information Technol ogy (ICCIT 2008) 25-27 December, 2008, Khulna, Bangladesh. [4] Phil Vines,Justin Zobel, “Compres sion of Chinese Text” Journal title: software practice and experience,1998. [5] www.maxim umcompression.com Data Compression Theory and Algorithms Retrieved/visited on August 10, 2009. (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 102 [6] Khair Md. Yeasir Arafat Majumder, Md. Zahurul Islam, and Majuz mder Khan, “Analysis of and Observati ons from a Bangla News Corpus”, Proceedings of 9th International Conference on Computer and Information technology ICCIT 2006, pp. 520-525, 2006. [7] N. S. Dash, “Corpus Linguistic s and Language Technology”, 2005. [8] L eonid Peshkin, “Structure Inducti on By Lossless Graph Compression”. 2007 Data compression Conference (DCC’07). [9] www.datacompression.com Theory of Data Compression (IJCSIS) International Journal of Computer Science and Information Security Vol. 4, No. 1 & 2, 2009 ISSN 1947 5500 103
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment