벵골어 단문 메시지 향상된 정적 데이터 압축 기법
본 논문은 메모리와 처리 속도가 제한된 소형 기기(예: 휴대폰)를 위한 벵골어 단문 메시지(SMS)의 효율적인 무손실 압축 기법을 제안합니다. 문자 마스킹, 사전 매칭, 데이터 마이닝 연관 규칙, 음절 기반 하이픈 알고리즘을 계층적으로 결합하고, 통계 모델 기반의 정적 허프만 코딩을 적용하여 낮은 복잡도와 최적의 압축률을 달성하는 것이 목표입니다.
저자: Abu Shamim Mohammad Arif, Asif Mahamud, Rashedul Islam
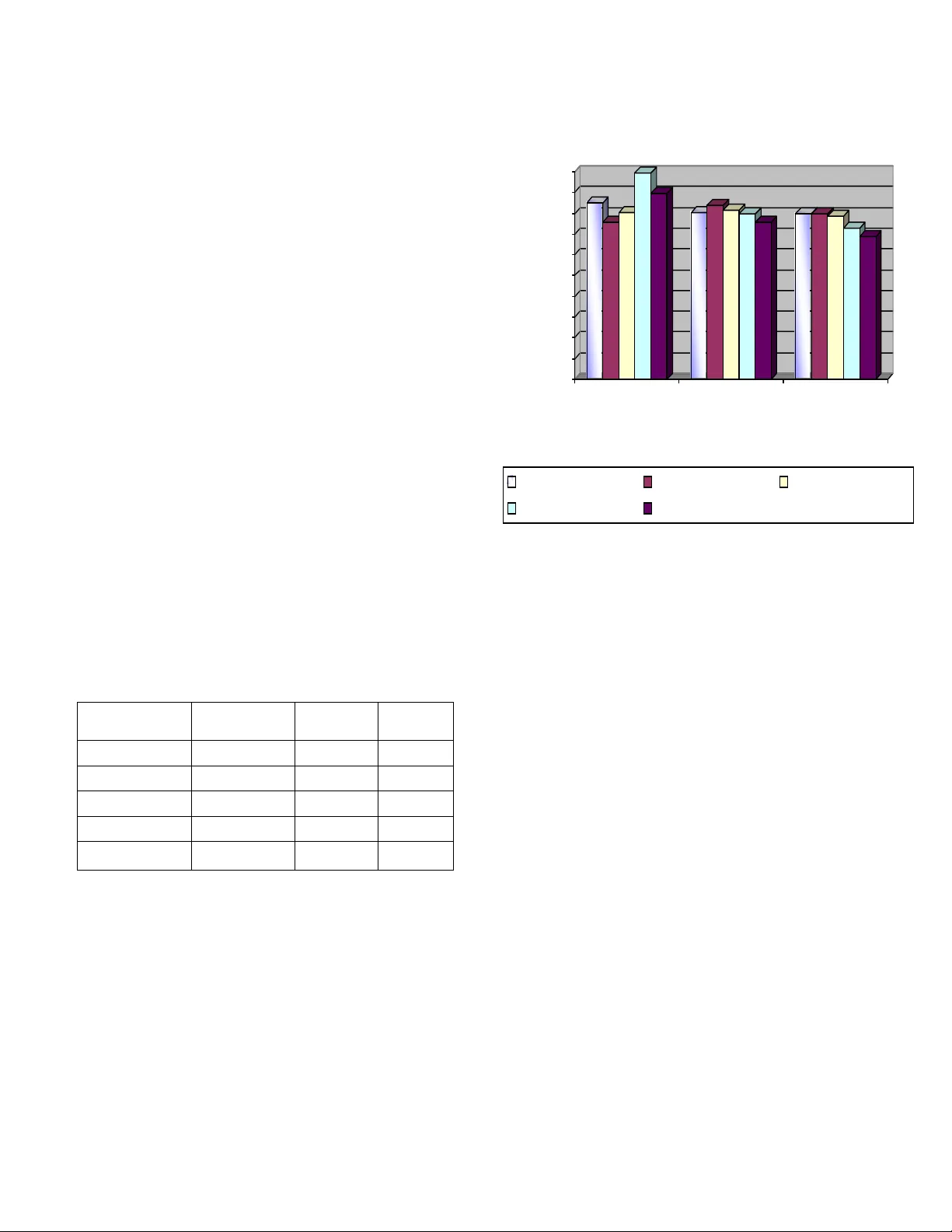
이 논문은 벵골어 단문 메시지(SMS)를 소형 모바일 기기에서 효율적으로 저장 및 전송하기 위한 새로운 무손실 압축 체계를 제안하고 그 구현 방법을 상세히 설명합니다.
서론에서는 모바일 기기의 제한된 메모리 공간과 상대적으로 낮은 처리 속도라는 환경적 제약을 강조하며, 이러한 조건下에서도 동작 가능한 "저복잡도(Low-Complexity)" 압축 기법의 필요성을 제기합니다. 기존의 고성능 압축 알고리즘들은 공간과 시간을 많이 요구하므로 모바일 환경에는 부적합하며, 본 연구의 목표는 최대 압축이 아닌, 자원 제약 내에서의 "최적 압축"을 달성하는 것임을 명시합니다.
문헌 조사 섹션에서는 데이터 압축, 단문 메시지의 기본 정의를 제공하고, 관련 선행 연구들을 검토합니다. 아랍어 텍스트 압축을 위한 동적 허프만 코딩, 음절 분해를 이용한 텍스트 압축에 유전자 알고리즘을 적용한 연구, 자바 기반 모바일 기기를 위한 영어 SMS 압축 기법(문자 마스킹, 사전 매칭, 고정 허프만 코딩 사용), 그리고 중국어 텍스트 압축을 위한 PPM(Partial Predictive Matching) 변형 기법 등을 소개하며, 이들 연구가 주로 영어나 다른 언어에 집중되어 있고 벵골어의 고유한 문자 체계(결합 문자 등)를 고려한 연구가 부족함을 지적합니다. 이는 본 연구의 차별성과 동기를 부여합니다.
제안 시스템 섹션에서는 본 논문의 핵심 방법론을 계층적 단계로 설명합니다. 총 네 가지 주요 기술이 순차적으로 적용됩니다: 1) **문자 마스킹**: 빈칸과 같은 특정 문자를 인코딩하여 기본적인 공간을 절약합니다. 2) **사전 매칭**: 미리 구축된 정적 사전을 사용하여 빈번히 나타나는 벵골어 단어나 구를 짧은 코드로 치환합니다. 3) **연관 규칙 마이닝**: 데이터 마이닝 기법을 차용하여, 텍스트에서 함께 자주 발생하는 문자 쌍(다이어그램)을 발견하고 이를 하나의 단위로 압축합니다. 사용할 다이어그램 집합은 벵골어 텍스트 코퍼스에 대한 통계적 분석을 통해 선정됩니다. 4) **음절 기반 하이픈 알고리즘**: 단어를 음절 단위로 분해하여, 언어의 구조적 중복성을 추가로 활용합니다. 마지막으로, 위 모든 단계를 거쳐 생성된 새로운 심볼 집합(원본 문자, 사전 코드, 다이어그램 코드, 음절 코드 등)에 대해 **정적 허프만 코딩**을 최종적으로 적용합니다. 허프만 코드 테이블 역시 동일한 통계 모델을 기반으로 사전에 생성되어, 압축/해제 시 추가적인 계산 부담을 없앱니다.
이러한 다단계 접근법은 각 단계가 비교적 단순한 연산으로 구성되어 전체 시스템의 복잡도를 낮추도록 설계되었습니다. 정적 사전과 정적 허프만 코드를 사용함으로써 실행 시간 오버헤드와 메모리 사용량을 최소화하는 동시에, 문자, 단어, 문자 조합, 음절이라는 여러 수준에서 중복성을 제거하여 종합적인 압축 효율을 꾀합니다. 논문은 벵골어의 복잡한 문자 체계를 효과적으로 처리할 수 있는 실용적인 솔루션을 제시함으로써, 관련 분야 연구의 공백을 메우고 모바일 컴퓨팅 환경에 기여하고자 합니다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기