Using Association Rules for Better Treatment of Missing Values
The quality of training data for knowledge discovery in databases (KDD) and data mining depends upon many factors, but handling missing values is considered to be a crucial factor in overall data quality. Today real world datasets contains missing va…
Authors: Shariq Bashir, Saad Razzaq, Umer Maqbool
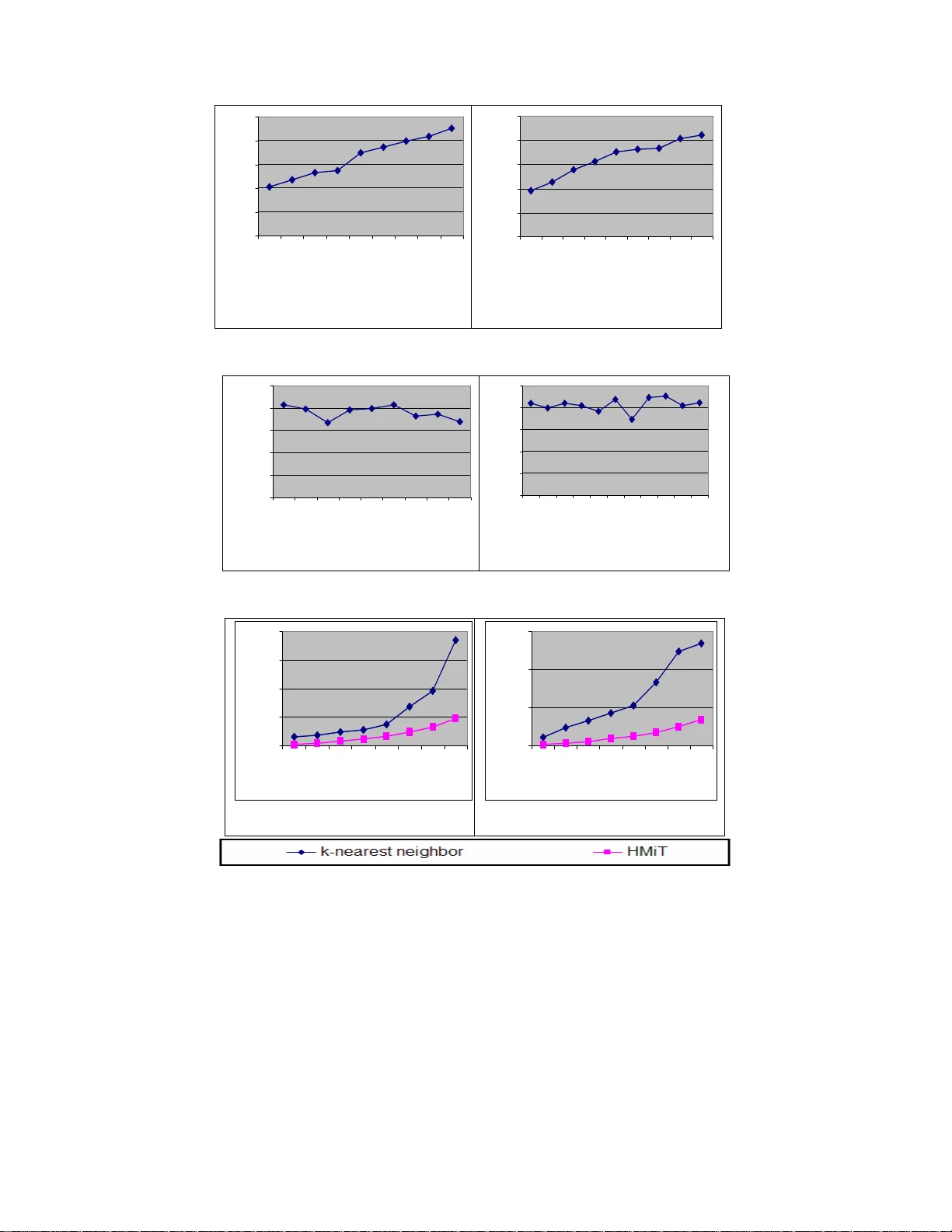
Using Association Rules for Bett er Treatment of Missing Values SHARIQ BASHIR, SAAD RAZZAQ, UMER MAQBOOL, SONYA TAHIR, A. RAUF BAIG Department of Computer Science (Machine Intelligence Group) National University of Computer and Emerging Sciences A.K.Brohi Road, H-11/4, Islamabad. Pakistan shariq.bashir@nu.edu.pk, rauf.baig@ nu.edu.pk Abstract: - The quality of training data for knowledge discove ry in databases (KDD) and data mining depends upon many factors, but handling missing values is consid ered to be a crucial factor in ov erall data quality. Today real world datasets contains missing values due to hu man, operational error, hardware malfunctioning and many other factors. The quality of knowledge extr acted, learning and deci sion problems depend directly upon the quality of training data. By consideri ng the im portance of handling missing values i n KDD and data mining tasks, in this paper we propose a novel H ybr id M issing values I mputation T echnique (HMiT) using associat ion r ules minin g and hy br id combi natio n of k- nearest neighbor approach. To check the eff ectiveness of our HMiT missing values i mputation technique, we also perform detail experimental re sults on real world datasets. Our results suggest that the HMiT technique is not only better in term of accuracy but it also take les s processing time as compared to current best missing values imputation techniq ue based on k-nearest neighbor approach, which shows t he effectiveness of our mis sing va lues imputation technique. Key-Words: - Quality of training data, missing values imput ation , association rules min ing, k-nearest neighbor, data mining 1 Introduction The goal of knowledge discovery in databases (KDD) and data mining algorithms is to form genera lizat ions , fr om a se t of t raini ng ob ser vation s, and to construct learning models such that the classification accuracy on previously unobser ved observati ons are maximize d. For all ki nds of learning algorith ms, the maxi mum accur acy is usually determined by two important factors: (a) the quality of the training data, and (b) the inductive bias of the lear ning algorit hm. The quality of traini ng data depends upon many factors [1], but handling missing values i s considered to be a crucial factor in overall data quality. For many real-world applicati ons of KDD and data mining, even whe n there ar e huge a mounts of data, the subset of cases with comp lete data may be relatively small. Trai ning as well as testing samples have missing values. Missing data may be due to different reas ons such as refu sal to responds, faulty data collection instrument s, data entry problems and data transmission problems. Missing data is a problem that continues to plague data analysis methods. Even as an alysis metho ds gain sophistication, we continue to encounter missing values in f ields, especi ally in data bases with a lar ge number of fields. The absence of information is rarely beneficial. All things being equal, more data is almost always better . Therefore, we should think carefully about how we hand le the thorny issue of missing data. Due to the frequent oc currence of missing values in training observations, i mputation or prediction of t he missing data has alwa ys remain ed at the center of attention of KDD and data mini ng resea rch community [13]. Imputation is a term that denotes the procedur e to replace the missin g values by considering the relationships present in th e observations. One main advantage of imputing missing valu es during preprocessing step is that, t he missing data treat ment is independent of the learning algorithm. In [6, 7] imputing missing values using prediction mod el is proposed. To impute mis sing values of attribute X , first of all a prediction model is constructed by considering the attribute X as a class label and other attributes as input t o prediction model. Once a prediction mo del is constructed, then it is utilized for predicting missing values of attribute X . The mai n advantag es of imputi ng missing val ues usin g this approach ar e that, this method is very useful when strong attribute relationship exists in the training data, and secondly it is a very fast and e fficient meth od as compared t o k-nearest neighbor approach. T he imputation processing time depends only on the construction of prediction model, on ce a prediction model is constructed, then the missing values are imputed in a constant time. On the other hand, the main drawback s of this ap proach are that, if there is no relationship exists among one or m ore attributes in the dataset and the attributes with missing data, then the prediction model will not be suitable to estimate the missing value. The seco nd drawback of thi s approach is that, the pred icted values are usually more accurate than the true values. In [6] and [7] another i mportant imputation technique based on k-nearest n eighbor is used to imput e missi ng va lues for bo th disc rete an d continuous value attribute s. It uses majority voting for categorical attr ibutes and mea n value for continuous value attributes. The main advantage of this technique it that, it does no t require any predictive model for missing values imputation of an attribute. The major draw backs of this approach ar e the choice of using exact distance function, considering all attributes wh en a ttempt ing to re trieve the similar type of examples, and searching through all the dataset for finding the same type of instances, require a large processing ti me for missing values imputation in preproces sing step. To overcome the limitations of missing values imputation using prediction model and decrease the processing time of missing values treatm ent in prepro cessing s tep, w e propo se a n ew mis sing values imputation technique ( HM iT ) using association rules mining [2, 3, 9] and hybrid combination of k-nearest nei ghbor approach [6, 7]. Association rule mining is one of the m ajor techniques of data mining and it is perhaps the most common form of local-pattern discovery in unsupervised learning systems. Before t his, different forms of associatio n rules have been successfully applied in the cl assification [9, 1 2], sequential patterns [4] and fault-tolerant patterns [14]. In [9, 12] different extensi ve experimental results on real world datasets show that classificati on using association rule mining is more accurate than neural network, Bayesian classification and decision tress. In HMiT , the m iss ing v alues are imput ed us ing association rules by comparing the known attribute values of missing observat ions and the an tecedent part of a ssoci ation rules. In the case, whe n there is no rule present or fire d (i.e . no attributes relationship exists in the training data) against the missing value of an observation, then the missing value is i mputed using k-nearest neighbor approach. Our experimental res ults suggest that our imputation technique not only increases the accur acy of missing values imputation, b ut it also sufficiently decrease the processing time of p reprocessing step . 2 Hybrid Missing Values Imputation Technique (HMiT) Let I = {i 1 … i n } be the set of n dis tinct items. Let TDB represents the trai ning dataset, where each record t has a unique identifier i n the TDB , and contains set of items such that t items ⊂ I . An association rule is an expressi on A -> B , where A and B are items A ⊂ I , B ⊂ I , and A ∩ B = φ . Here, A is called antecedent of rule and B is called consequent of rule. The main technique of HMiT is divided into two phases- (a) fi rstly the missing val ues are i mpute on the basis of association rules by compari ng the antecedent pa rt of ru les with th e known attribu tes values of missing value observation, (b) For the case, when there is no association rule exist or fired against any missing value (i.e. no relations exist between the attributes of ot her observations with the attributes of missing value), then the missing values are imputed using the i mputation technique based on k-nearest neighbor approach [6, 7]. The main reason why we are using k- nearest a pproac h as a hy brid combination is that, it is considered to be more robust agai nst noise or in the case whe n the relationship between observat ions of data set i s very small [7]. Figure 1 shows the framewor k of missing values imputation using our hybrid imputatio n framework. At the start of imputation process a set of strong (with good support and confidence) association rules are created on the basis of given train ing dataset with s upp ort an d con fide nce thr esho ld. O nce associatio n rules are cr eated, the HMiT utilizes them for miss ing valu es imputatio n. For each obs ervation X with missing values, association rules are fired by comparing the known attributes val ues of X with the antecedent part of association rules one by one. If the know attributes values of X are the sub set of any associatio n rule R , then R is add ed in the fire d set F . Once all association rules are checked against the missi ng val ue of X , then the set F is considered fo r imputation. If the set F is non em pty, then m edian and mod of the cons equent part of t he rules in set F is used for missing value imputati on in case of numeric and discr ete attributes. For the case, when Fig. 1. The fr ame work of ou r HMiT miss ing val ues i mput atio n tech nique. Fig. 2. Pseudo code of HMiT missing values imputation technique Scan the dataset Create Association Rules on given support and confiden ce thresh olds For each observation of Training data with Missing value Impute missing values using Association Rules If in the case when no relationship exists, impute values usin g k-nearest neighbor approach Hybr idI mput atio n (S uppo rt min_sup , Confidence min_co nf ) 1. Generate freque nt itemset ( FI ) on gi ven min_sup . 2. Generate associat ion rules ( AR ) using FI on gi ven min_conf . 3. for each training observation X , which contain s at lea st on att ribute v alue missing. 4. for each rule R in association rules set ( AR ). 5. compa re t he anteced ent p art of R with the known attribu te values of X . 6. if antecedent part of R ⊆ X {known att ribute val ues}. 7. add R to fired set F 8. if F ≠ φ 9. if the missing value of X is discrete then use Mod in set F to impute missing value. 10. if the mi ssing valu e of X is continuous t hen take Me dian in set F to impute mi ssing value . 11. else 12. impute missing value us ing k-nearest neighbor approach. 0 20 40 60 80 100 10 20 30 40 50 60 70 Missing Valu es % Accur acy Support = 2% Confi dence = 60% Car Evaluation data set 0 20 40 60 80 100 10 20 30 40 50 60 70 M issin g valu es % Acc u ra c y Support = 2% Confidence = 60% CRX dataset Fig. 3. Effect of ra ndo m missi ng va lues on mi ssin g valu es imp utati on acc uracy the set F is empty, then the missing value of X is imputed using k-neare st neighbor approach. The pseudo code of our HMiT is de scri bed in Fig ure 2. Lines from 1 to 2 create the association rules on the basis of given support and confidence threshold . Lines from 4 to 7 first compare th e antecedent part of all association rules with the known attributes values of missing value observ ation X . If the known attributes values of X are subset of any rule R , then R is added in the set F . If the set F is non empty , then the missing values are i mpute on the basis of conseq uent p art of fir ed a ssociati on rul es in L ine 9 and 10, othe rwise the missing values are impute usin g k-n ear est n eigh bor appr oac h in L ine 12. 3 Experime ntal Results To evaluate the performance of HMiT we perform our experimental results on benchmark dat asets available at [15]. The brief introduction of each dataset is described in Tab le 1. To validate the effectiveness of HMiT , we add rando m missing values in e ach of our exp eri ment al data set . Fo r performan ce reas ons, we us e Ramp [5] algorithm for frequent itemset mining and association rules generation. All the code of HMiT is written in Visual C++ 6.0, and the expe riment s are perf or med o n 1.8 GHz machine with main me mory of size 256 MB, running Windows XP 2005. Table 1. Details of our experimental datasets Datasets Instances Total Attributes Classes Car Evaluation 1728 6 4 CRX 690 16 2 3.1 Effect of Percent age of Missing Values on Missing Values Imputation A ccuracy The effec t of perc enta ge of mis sin g values o n imputation accuracy is shown in Figure 3 wit h HMiT and k-nearest neighbor a pproach. The results in Figure 3 are showi ng that as the level of pe rcentage of missing valu es increases the accuracy of predicting missing v alues decreases. We obtain the Figure 3 results by fixing the support and confidence thresholds as 40 and 60% respectively and nearest neighbor size as 10. The reason behind why use nearest neigh bor size = 10, is descried i n [1]. From the results it is clear, that our HM iT genera tes goo d results as compar ed to k-nearest neighbor approach on all levels. 3.2 Effect of Confidence Threshold on Missing Values on Missing Values Imputation Accuracy The effect of confidence th reshold on mi ssing values imputation accuracy is shown in the Figure 4. We obtai n the F igur e 4 res ults by fi xing t he supp ort threshold as 40 and insert random mi ssing values with 20%, while the confidence th reshold was varied from 20% to 100 %. For clear under standing, we exclude th e accuracy effect of k- nearest nei ghbor from Figure 4 results. By lo oking the results, it is clear that as the confid ence threshol d increases the accuracy of predicting correctly missing also increases. For hig her level of conf idence only strong rules are gen erated and th ey more accurately predict the missing values, bu t in case of less confidence more weak or exceptional rules are generated which results in very less accuracy. From our experiments 0 20 40 60 80 100 20 30 40 50 60 70 80 90 100 Co nf id en ce% Ac c ur a c y Missing Values = 20% Supp ort = 2% Car Evaluati on dataset 0 20 40 60 80 100 20 30 40 50 60 70 80 90 100 Confidence % Accur acy Missing Valu es = 20 % Suppo rt = 2% CRX dataset Fig. 4. Effect of confidence threshold on missing values im putation accuracy Fig. 5. Effect of support threshold on mis sing values imputation accuracy 0 50 100 150 200 5 1 02 03 04 05 06 07 0 Miss ing Value s % T i m e ( secs) Support = 2% Confidence = 60% Car Eval uation da taset 0 50 100 150 5 1 02 03 04 05 06 07 0 Mi ss ing Value s % T i m e ( secs) Support = 2% Confidence = 60% CRX dataset Fig. 6. Performance analysis of HMiT and k-nearest neighbor with different missing values level we suggest that confidence thres hold between 60% to 70% generates good results. 3.3 Effect of Support Threshold on Miss ing Values on Missing Values Imputation Accuracy The effect of support threshold on missing values imput ation accur acy is show n in the F igur e 5. We obtai n the Figu re 5 r es ults b y f ixing the c onfid enc e threshold as 60% and insert rando m missing values with 20%. Again for clear understanding, we exclude th e accuracy effect of k- nearest nei ghbor from Figure 5 results. From the results it is clear that as the support threshold decreases more mis sing values are predicted with association rules, this is because more ass ociation rules are generated. But on the other hand a s the support threshold increases less rules are generated and less number of missing values are p redicted with assoc iation rules. 0 20 40 60 80 100 40 45 50 55 60 65 70 75 80 Support Acc ur acy Missing Values = 20% Confidence = 60% Car Evaluati on dataset 0 20 40 60 80 100 40 45 50 55 60 65 70 75 80 85 90 Suppor t A ccuracy Missing Value s = 20% Confidence = 60% CRX dataset 3.4 Performance Analysis of HMiT and k- nearest neighbor approach The results of Figure 6 are showing that HMiT perfor ms be tter i n ter m of processing time as compared to k-nearest neighbor approach. 4 Conclusion Missing value imputation is a complex problem in KDD and data minin g tasks. In this pa per we present a novel approac h HMiT for m is sing va lues imputation based on association rule mining and hybrid combination of k-nearest neighbor approach. To analyze the effectiven ess of HMiT we perform detail experiments results on benchmark datasets. Our results suggest that missing valu es imputation using our technique has good potential in term of accuracy and is also a good tech nique in term of processing time. References: [1] E. Acuna and C. Rodriguez, “Th e treatment of missing values and its effect in the classifier accuracy”, Clus terin g and Dat a Mining Application, Springer-Verl ag Berlin- Heidelberg , pp.639-64 8 2004. [2] R. Agrawal, T. Im ielinski, and A. Swami, “Mining Association Rules between Sets of Items in Larg e Databases”, In Proc. of ACMSIGMOD Int’l Co nf. Management of Data , pp. 207-216, M ay 1993. [3] R. Agrawal and R. Srikant, “Fast Algorithm s for Mining Associ ation Rules”, In Proc. of Int’l Conf. Very Large Data Bases, pp. 487-499 , Sept. 1994. [4] R. Agrawal and R. Srikant, “Mining Sequential Patterns”, In Pr oc. of Int ’l C onf. Data Eng. , pp. 3-14, Mar. 1995. [5] S. Bashir and A. R. Baig, “Ram p: High Performance Frequent Ite m set Mining with Efficient Bit-vector Projection Technique”, In Proc. of 10 th Pacific Asia Conference on Knowledg e and Data Discovery (PAKDD2006), Singapore, 2006. [6] G. Batista and M. Monard, “Experimental comparis on of K -Nearest Nei ghbor an d mean or mode Imputation methods with the internal strategies used by C4.5 and CN2 to treat missing data”, Tech. Report, ICMC- USP, Feb 2003. [7] G. Batista and M. Monard, “K -Nearest Neighbour as Imputation Method: Experimental Results”, Tech. Report 186 ICMC-USP, 2002. [8] I.Duntsch and G. Gediga, “Maximu m consistency of incomplete data via n on- invasive imputation”, Arti ficial intelligence Review, vol. 19 , pp.93-107.2003. [9] H. Hu and J. Li, “Using Association Rules to Make Rule-based Cla s sifiers Robust”, In Proc. of 16 th Australasian Databas e Conference ( ADC), 2005. [10] J. Han and M. Ka mber, “Data Mining Concepts and Techniques”, 2002. [11] W.Z Liu, A.P white, S. G Thompson and M.A Bramer, “Techniques for dealing with missing v alues in classif ication”, Lecture Notes in Computer Science , pp.1280, 1997. [12] B. Liu, W. Hsu and Y. Ma, “Integrating classification and associat ion rule mini ng”, In Proc. KDD’ 98 , New York, NY, Aug. 1998. [13] M. Magnani, “Techniques for dealing with miss ing data in Kn owledge di scovery tas ks”, 40127 Bologna –ITALY . [14] J. Pei, A.K.H. Tung and J. Han, “ Fault- Tolerant Frequent Patter Mining, Problems and Challen ges”, In Proc. of ACM-SIGMOD Int. Workshop on Research Issues and Data Mining and Knowledge Discovery (DMKD’01) , 200 1. [15] UCI Repository of machine learnin g, www.ics.uci.edu.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment