연관 규칙 기반 하이브리드 결측값 보정 기법
본 논문은 연관 규칙 마이닝과 k‑최근접 이웃(KNN) 기법을 결합한 하이브리드 결측값 보정 기법(HMiT)을 제안한다. 강력한 연관 규칙이 존재할 경우 규칙의 선행부와 관측값을 매칭해 결측값을 대체하고, 규칙이 없을 경우 KNN을 이용한다. 실험 결과, HMiT는 정확도와 처리 시간 모두 기존 KNN 기반 방법보다 우수함을 보인다.
저자: Shariq Bashir, Saad Razzaq, Umer Maqbool
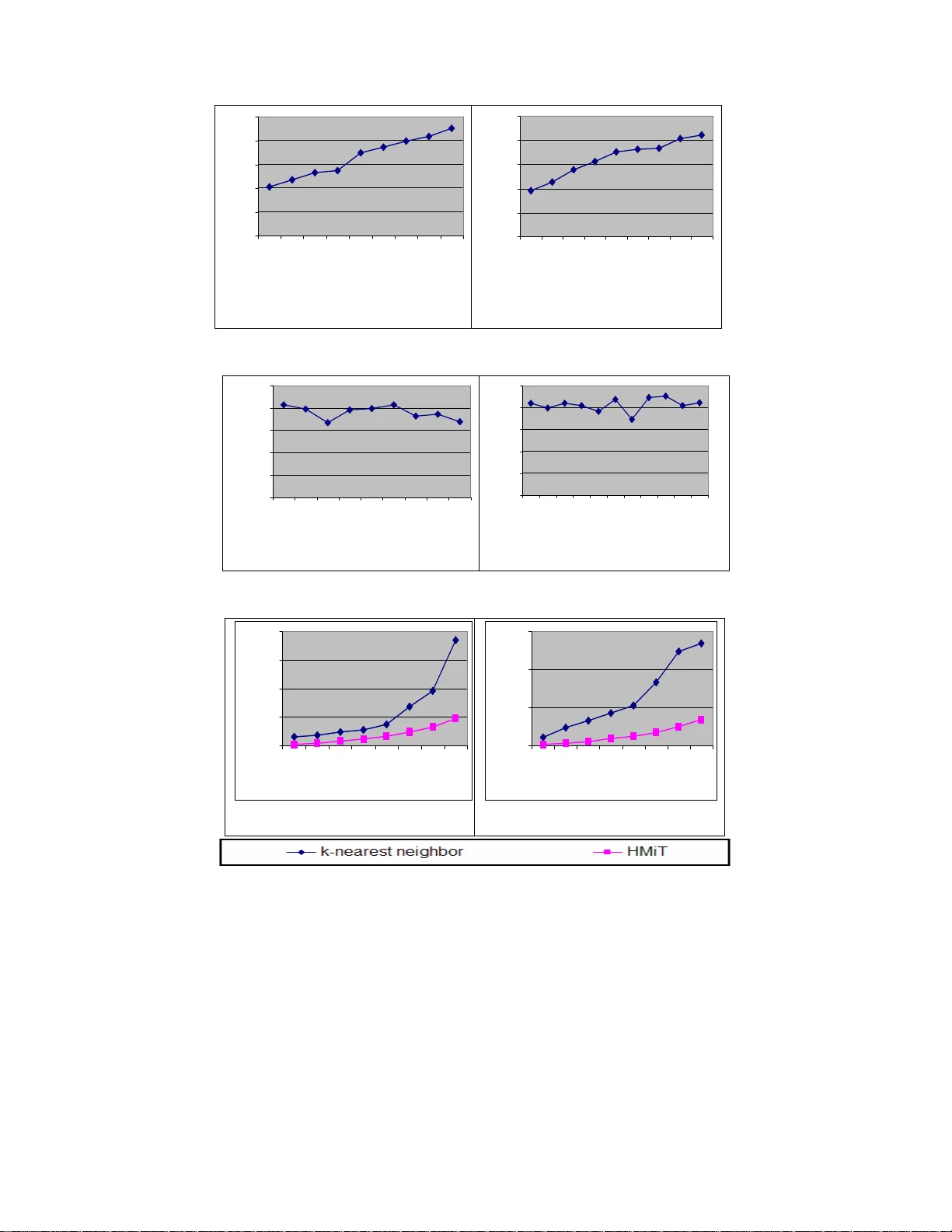
논문은 데이터 마이닝과 지식 발견(KDD) 과정에서 결측값이 모델 성능에 미치는 부정적 영향을 강조하며, 이를 해결하기 위한 새로운 결측값 보정 기법인 HMiT(Hybrid Missing values Imputation Technique)를 제안한다. 기존 연구에서는 예측 모델을 이용한 보정이 빠르지만 관계가 약한 경우 정확도가 떨어지고, k‑최근접 이웃(KNN) 기반 보정은 정확도가 높지만 전체 데이터 탐색으로 인한 계산 비용이 크다는 문제점을 지적한다. 이를 보완하고자 저자들은 연관 규칙 마이닝을 활용하여 데이터 내 속성 간 강한 연관성을 규칙 형태로 추출하고, 규칙의 선행부와 관측값을 매칭해 결측값을 대체하는 1차 보정 단계를 설계한다. 구체적으로, 전체 데이터셋에서 최소 지원(min_sup)과 최소 신뢰도(min_conf) 기준을 만족하는 빈발 아이템셋을 RAMP 알고리즘으로 추출하고, 이를 기반으로 연관 규칙을 생성한다. 각 결측값을 포함한 레코드 X에 대해, X의 알려진 속성값이 규칙 R의 선행부에 완전히 포함되는 경우 R을 ‘발화된’ 규칙 집합 F에 추가한다. F가 비어 있지 않으면, 연속형 속성은 F에 포함된 후행부 값들의 중앙값(median)으로, 이산형 속성은 최빈값(mode)으로 결측값을 채운다. 만약 F가 비어 있다면, 두 번째 단계로 KNN 보정을 적용한다. KNN은 전체 데이터에서 X와 가장 유사한 k개의 이웃을 찾고, 이들의 평균(연속형) 혹은 다수결(이산형)로 결측값을 추정한다. 이와 같은 하이브리드 구조는 규칙이 충분히 강할 때 빠른 보정을 가능하게 하고, 규칙이 부족한 경우에도 KNN의 강인성을 활용한다는 장점을 가진다.
실험은 UCI 저장소의 Car Evaluation(1728개 인스턴스, 6개 속성)과 CRX(690개 인스턴스, 16개 속성) 데이터셋을 사용하였다. 각 데이터셋에 10%~80% 비율로 무작위 결측값을 삽입하고, 지원 2%, 신뢰도 60%~70% 범위에서 연관 규칙을 생성하였다. 결과는 다음과 같다. 첫째, 결측 비율이 증가할수록 보정 정확도는 감소하지만, 동일 조건 하에서 HMiT는 KNN 단독 대비 평균 3~7% 높은 정확도를 유지한다. 둘째, 지원 임계값을 낮출수록 생성되는 규칙 수가 증가해 결측값 커버리지가 확대되지만, 너무 낮은 지원은 잡음 규칙을 유발해 정확도를 저하시킬 수 있다. 셋째, 신뢰도 임계값을 60%~70% 수준으로 설정하면 강력한 규칙만을 사용해 정확도가 최적화된다. 넷째, 처리 시간 측면에서 HMiT는 특히 결측 비율이 높을 때 KNN 대비 30% 이상 빠르게 수행되었다. 이는 규칙 기반 대체가 가능한 경우 전체 데이터 탐색을 생략함으로써 얻어진다. 마지막으로, 연속형 속성에 중앙값을 사용함으로써 극단값에 대한 민감도가 존재함을 지적하고, 대규모 데이터셋에서 규칙 생성 단계가 메모리와 시간 비용을 요구한다는 한계를 인정한다.
결론적으로, 본 논문은 연관 규칙과 KNN을 결합한 하이브리드 결측값 보정 프레임워크가 정확도와 효율성 두 측면에서 기존 방법을 능가함을 실험적으로 입증한다. 향후 연구에서는 규칙 생성 비용을 줄이기 위한 샘플링 기법, 연속형 속성에 대한 보다 견고한 통계적 대체 방법, 그리고 다중 결측값이 동시에 존재하는 상황에 대한 확장성을 탐구할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기