Robust Recovery of Signals From a Structured Union of Subspaces
Traditional sampling theories consider the problem of reconstructing an unknown signal $x$ from a series of samples. A prevalent assumption which often guarantees recovery from the given measurements is that $x$ lies in a known subspace. Recently, th…
Authors: Yonina C. Eldar, Moshe Mishali
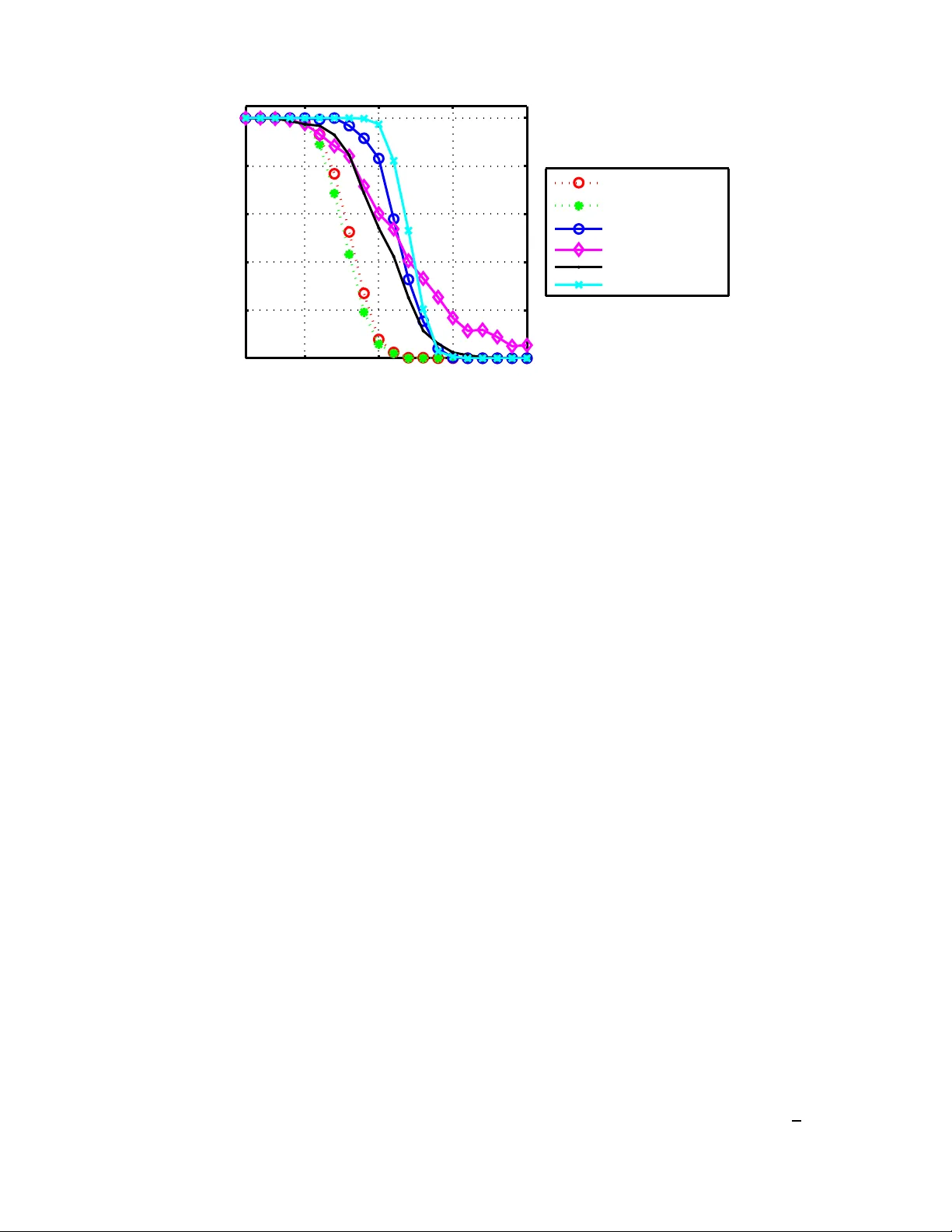
1 Rob ust Reco v ery of Signals From a Structured Union of Subs paces Y onina C. Eldar , Senior Member , IEEE and Moshe M ishali, St udent Member , IEEE Abstract T radition al sampling theories co nsider the problem of reconstructing an u nknown sign al x from a series of samples. A prev alent assumption wh ich often guarantees recovery from the given measurements is that x lies in a known subspace. Recently , there has been gr owing interest in n onlinear but structu red signal mo dels, in which x lies in a union of subspaces. In this paper we develop a g eneral framework for robust and efficient recovery of such signals from a giv en set of samp les. Mo re specifically , we treat the case in which x lies in a sum of k subspaces, chosen fro m a larger set of m po ssibilities. The samples are mo delled as inner pr oducts with an arbitrar y set of sampling functio ns. T o derive an efficient an d ro bust recovery algorith m, we show that our pr oblem can be formu lated as that of r ecovering a b lock-spar se vector wh ose non -zero elemen ts appear in fixed block s. W e then propo se a mixed ℓ 2 /ℓ 1 progr am for block sparse recovery . Our main result is an equiv alence con dition under wh ich the proposed conve x algo rithm is guara nteed to recover the original signal. Th is result relies on th e notion o f b lock restricted isometry pro perty ( RIP), which is a g eneralization of the standar d RIP used extensiv ely in the context of compressed sensing. Based o n RIP we a lso prove stability of our app roach in the presen ce of noise and modelling errors. A special case of o ur f ramework is tha t o f rec overing multiple m easurement vecto rs (MMV) that shar e a joint sparsity pattern. Adap ting o ur r esults to this co ntext leads to new MMV recovery metho ds as w ell as equ i valence condition s under which the en tire set can be d etermined efficiently . I . I N T R O D U C T I O N Sampling theory h as a rich his tory dating back to Cauchy . Undo ubtedly , the sampling theorem tha t had the mos t impact o n signal processing and communications is that as sociated with Whittak er , Kotel ´ nikov , and Shannon [1], [2]. Their famous result is that a band limited fun ction x ( t ) can be recovered from its un iform samples as long as the s ampling rate exceed s the Nyquist rate, c orresponding to twice the highest frequency of the signal [3]. More recently , this basic theo rem has be en extende d to include more general class es of signal spaces. In p articular , it Department of El ectrical Engineering, T echn ion—Israel Institute of T echn ology , Haifa 3200 0, Israel. Phone: +972-4-8293256 , fax: +972- 4-829575 7, E-mail : { yonina@ee,mos hiko@techunix } .technion.ac.il. This work was supported in part by the Israel Science Foundation under Grant no. 1081/07 and by the European Commission in the framework of the F P7 N etwork of Excellence in Wireless COMmunications NEWCOM++ (con tract no. 216715). 2 can b e shown that under mild technica l conditions, a signal x lying in a g i ven s ubspac e ca n be recovered exactly from its linear gen eralized samples using a series of filtering op erations [4]–[7]. Recently , the re has bee n growing interest in n onlinear signal mode ls in which the unknown x do es not nec essarily lie in a subsp ace. In order to ens ure rec overy from the samples, some u nderlying structure is needed. A general model that cap tures many interesting case s is that in which x lies in a union of s ubspac es. In this setting, x res ides in o ne of a se t of gi ven sub spaces V i , howe ver , a priori it is no t known in whic h one . A s pecial cas e of this framew ork is the problem underlying the field of compress ed se nsing (CS), in wh ich the goal is to recover a length N vector x from n < N linea r measuremen ts, whe re x has n o more than k non -zero elemen ts in some bas is [8], [9]. Many algo rithms h av e been proposed in the literature in order to recover x in a s table a nd efficient manner [9]–[12]. A v ariety of c onditions have been developed to ensu re tha t these methods recover x exactly . One of the main tools in this con text is the res tricted isometry property (RIP) [9], [13 ], [14]. In particular , it can be shown that if the mea surement matrix sa tisfies the RIP then x can be recovered by solving an ℓ 1 minimization a lgorithm. Another sp ecial case of a u nion of subspace s is the s etting in which the unknown signal x = x ( t ) has a multiband structure, so that its Fourier transform co nsists of a limited number of bands at unknown loca tions [15], [16]. By formulating this problem within the frame work of CS, explicit sub-Nyquist sampling and reco nstruction sc hemes were developed in [15], [16] that ens ure perfect-recovery at the minimal pos sible rate. This setup was recently generalized in [17 ], [18] to dea l with sampling and reco nstruction of signals that lie in a fi nite union of sh ift- in variant su bspace s. By comb ining ideas from standard sa mpling theory with CS results [19], explicit low-rate sampling and recovery methods we re de veloped for such signal sets. Another example of a union of subspace s is the se t of finite rate of innov ation signa ls [20], [21], that are modelled as a weighted s um o f shifts of a given generating function, whe re the shifts a re un known. In this pa per , ou r goal is to develop a unified framework for efficient recovery of sign als that lie in a structured union o f sub spaces . Our emphasis is on c omputationally efficient methods that a re s table in the presen ce o f noise and mod elling errors. In contrast to our pre vious work [15]–[18], here we consider union s of fi nite-dimensional subspa ces. Spe cifically , we restrict our attention to the c ase in which x resides in a sum of k s ubspac es, c hosen from a g i ven s et of m su bspace s A j , 1 ≤ j ≤ m . However , which s ubspac es c omprise the sum is unknown. This setting is a sp ecial ca se of the more gen eral union mod el considered in [22], [23]. Con ditions und er which u nique and stable s ampling are poss ible were developed in [22], [23]. Howe ver , no concre te algorithm was provided to recover such a signal from a given set of samp les in a s table and ef ficient manner . Here we propos e a c on vex optimization algorithm that will often rec over the true underlying x , an d develop explicit conditions unde r which perfect recovery is gua ranteed. F urthermore, we prove that our method is stable an d robust in the sens e tha t the reconstruction error is bo unded in the presen ce o f no ise and mismodelling, namely wh en x does not lie exactly in 3 the union. Our results rely on a ge neralization of the RIP whic h fits the u nion se tting we treat he re. Our first contrib ution is s howing that the problem of recovering x in a structured union of sub spaces c an b e cast a s a sparse rec overy problem, in which it is des ired to recover a s parse vector c that ha s a particular s parsity pattern: the non -zero values ap pear in fixed blocks. W e refer to such a model as block sp arsity . Clearly any b lock- sparse vector is also sparse in the standard sense. Ho wever , by exploiting the block structure of the s parsity pattern, recovery ma y be possible un der more gen eral conditions. Next, we dev elop a concrete a lgorithm to rec over a block-sp arse vec tor from g i ven me asurements, which is base d on minimizing a mixed ℓ 2 /ℓ 1 norm. This problem can be cas t as a conv ex se cond order co ne program (SOCP), an d solved e f ficiently u sing standard software packag es. A mixed norm ap proach for block-sp arse recovery was a lso considered in [24], [25]. By ana lyzing the measureme nt operator’ s null s pace, it was shown that a symptotically , as the signal len gth grows to infinity , a nd unde r ideal cond itions (no noise or mo deling errors), p erfect recovery is possible with high p robability . Howe ver , no robust equiv alence results were estab lished between the output of the algorithm and the true b lock-sparse vector for a giv en finite-length measu rement vector , or in the pres ence of noise and mismo delling. Generalizing the c oncept o f RIP to our setting, we introduce the bloc k RIP , which is a less stringent requirement. W e then p rove tha t if the measurement ma trix sa tisfies the block RIP , then ou r p roposed conv ex algorithm will recover the u nderlying block spa rse signal. Furthermore, un der block RIP , o ur algorithm is stable in the p resence of noise and mismod elling errors. Using ideas similar to [12], [26 ] we then p rove that random matrices satisfy the block RIP with ov erwhelming probability . Moreov er , the probability to satisfy the block RIP is su bstantially lar ger tha n that of s atisfying the stand ard RIP . These results e stablish that a s ignal x that lies in a fin ite structured union can be recovered ef ficiently and s tably with overwhelming probability if a certain me asurement ma trix is constructed from a random ensemb le. An interesting special case of the b lock-sparse mode l is the multiple mea surement vector (MMV) p roblem, in which we ha ve a s et of u nknown vectors that share a joint s parsity p attern. MMV rec overy algorithms were studied in [19], [27]–[30]. Equiv alence results based on mutua l coherence for a mixed ℓ p /ℓ 1 program were deriv ed in [28]. These resu lts turn ou t to be the same as that obtaine d from a single meas urement problem. This is in c ontrast to the fact that in practice, MMV methods tend to outperform algorithms that trea t eac h of the vectors sep arately . In order to develop mea ningful equ i valence res ults, we cas t the MMV problem as one of b lock-sparse recovery . Ou r mixed ℓ 2 /ℓ 1 method translates into minimizing the sum of the ℓ 2 row- norms o f the unkn own ma trix represen ting the MMV set. Our general results lead to RIP-bas ed e quiv a lence c onditions for this algorithm. Furthermore, our framew ork sugge sts a d if ferent type of sampling method for MMV problems which tends to increase the recovery rate. The equiv a lence con dition we obtain in this case is stronger than the single mea surement setting. As we sho w , 4 this me thod lead s to supe rior rec overy rate when c ompared with other popular MMV algo rithms. The remainder of the paper is o r ganize d as follo ws. In Se ction II we des cribe the gene ral problem of sampling from a u nion of su bspace s. Th e relationship betwe en our problem a nd that of block-sparse recovery is developed in Section III. In Section IV we explore stability and uniquen ess issues which leads to the definition o f bloc k RIP . W e also presen t a non-con vex optimization algorithm with combina torial complexity whos e s olution is the true unknown x . A con vex relax ation of this algorithm is proposed in Section V. W e the n deri ve equiv a lence con ditions based on b lock RIP . The c oncept of bloc k RIP is further use d to establish robustness and stability of ou r algorithm in the pres ence of no ise and mo delling errors. This a pproach is s pecialized to MMV sa mpling in Section VI. Fina lly , in Se ction VII we prove that random ensemb les tend to sa tisfy the block RIP with high probability . Throughou t the paper , we denote vectors in an arbitrary Hilbert spac e H by lower c ase letters e.g., x , and s ets of vectors in H b y calligraphic letters, e.g., S . V ectors in R N are written as boldface lowercase letters e.g., x , a nd matrices as boldface up percase letters e.g., A . The ide ntity ma trix of appropriate dimen sion is written as I or I d when the dimens ion is no t clear from the context, and A T is the transpos e of the matrix A . T he i th element of a vector x is de noted b y x ( i ) . Linear transformations from R n to H are written as uppe r ca se letters A : R n → H . The adjoint of A is written as A ∗ . T he standard Euclidean norm is denoted k x k 2 = √ x T x and k x k 1 = P i | x ( i ) | is the ℓ 1 norm of x . The Kronec ker p roduct between matrices A an d B is denoted A ⊗ B . The following variables are us ed in the seq uel: n is the number of s amples, N is the leng th of the input signa l x when it is a vector , k is the sp arsity or block spa rsity (to be d efined later on) of a vector c , and m is the numb er of subs paces . For e ase of notation we as sume througho ut tha t all s calars are define d over the field of rea l numb ers; howev er , the results are also valid over the co mplex domain with ap propriate modifica tions. I I . U N I O N O F S U B S PAC E S A. Subspa ce S ampling T raditional sampling theory deals with the problem of recoveri ng an unknown signal x ∈ H from a set of n samples y i = f i ( x ) w here f i ( x ) is some function of x . The s ignal x can be a function o f time x = x ( t ) , or c an represent a finite-length vector x = x . T he mos t common type of samp ling is linear sampling in which y i = h s i , x i , 1 ≤ i ≤ n, (1) for a set of functions s i ∈ H [4], [31]–[37]. Here h x, y i de notes the stand ard inner produ ct on H . For example, if H = L 2 is the s pace of real fin ite-energy s ignals then h x, y i = Z ∞ −∞ x ( t ) y ( t ) dt. (2) 5 When H = R N for so me N , h x , y i = N X i =1 x ( i ) y ( i ) . (3) Nonlinear sa mpling is treated in [38]. Howev er , h ere our focus will be on the linear case . When H = R N the un known x = x as we ll as the sa mpling func tions s i = s i are vectors in R N . Therefore, the samples can b e written co n veniently in matrix form as y = S T x , where S is the matrix with columns s i . In the more genera l case in which H = L 2 or any other abstract Hilbert sp ace, we can use the set transformation n otation in order to con veniently represen t the s amples. A set transformation S : R n → H corresponding to sampling vectors { s i ∈ H , 1 ≤ i ≤ n } is d efined by S c = n X i =1 c ( i ) s i (4) for all c ∈ R n . From the defi nition of the adjoint, if c = S ∗ x , then c ( i ) = h s i , x i . Note tha t when H = R N , S = S and S ∗ = S T . Using this notation, we ca n always express the sa mples as y = S ∗ x, (5) where S is a set transformation for a rbitrary H , a nd an approp riate matrix whe n H = R N . Our g oal is to recover x from the s amples y ∈ R n . If the vectors s i do no t spa n the entire s pace H , then the re are many po ssible signals x consistent with y . More specific ally , if we define by S the samp ling spa ce spanned by the vectors s i , then clea rly S ∗ v = 0 for a ny v ∈ S ⊥ . Therefore, if S ⊥ is not the tri vial spac e then adding s uch a vector v to a ny solution x of (5) will result in the sa me sa mples y . Ho wever , b y exploiting prior knowledge on x , in many cas es un iqueness can b e guaran teed. A prior very often as sumed is that x lies in a gi ven subsp ace A of H [4]–[7]. If A an d S have the sa me fin ite dimen sion, and S ⊥ and A intersec t only at the 0 vector , the n x can be pe rfectly recovered from the sa mples y [6], [7], [39]. B. Union of S ubspac es When su bspace information is av ailable, p erfect recons truction can often be guaran teed. Furthermore, rec overy can be implemented by a s imple linear transformation of the given samples (5). Howev er , there are many p ractical scena rios in w hich we are gi ven prior information about x that is not neces sarily in the from of a subspac e. One such cas e studied in detail in [39] is that in which x is kn own to be smooth. Here we focus our attention on the setting where x lies in a un ion of subs paces U = [ i V i (6) where each V i is a su bspace . Thus, x b elongs to one of the V i , b ut we do not know a priori to which one [22], [23]. Note that the set U is no lon ger a su bspace . Ind eed, if V i is, for examp le, a o ne-dimensiona l space spa nned by the 6 vector v i , then U co ntains vectors o f the form α v i for some i but d oes not include their linear combinations. Our goal is to rec over a vector x lying in a union o f sub space s, from a g i ven se t of sample s. In p rinciple, if we knew which sub space x be longed to, then reconstruction can be obtained us ing standard sampling results. However , here the problem is more in volved because conceptually we firs t need to identify the correct subs pace an d only then can we recover the signal within the spa ce. Previous work on sampling over a union focused on in vertibility and stability resu lts [22], [23]. In contrast, here, our main interest is in d ev eloping concrete recovery algorithms that a re prov ably robust. T o achiev e this goal, we limit our attention to a subclass of (6) for wh ich stable recovery a lgorithms can be developed and a nalyzed. Specifica lly , we treat the ca se in which each V i has the add itional structure V i = M | j | = k A j , (7) where {A j , 1 ≤ j ≤ m } a re a given se t of disjoint subs paces, and | j | = k den otes a sum over k indices. Thus, each subspa ce V i correspond s to a dif ferent c hoice of k sub space s A j that comprise the sum. W e ass ume throu ghout the paper that m and the dimens ions d i = dim( A i ) of the sub spaces A i are finite. Given n sa mples y = S ∗ x (8) and the knowledge that x lies in exac tly o ne of the su bspace s V i , we would like to recover the u nknown signal x . In this se tting, there are m k possible su bspace s co mprising the union. An alternative interpretation of our mo del is as follows. Given an o bservation vector y , we seek a sign al x for which y = S ∗ x a nd in addition x c an be written as x = k X i =1 x i , (9) where e ach x i lies in A j for some ind ex j . A spe cial case is the stand ard CS p roblem in which x = x is a vec tor of leng th N , that ha s a spa rse represen tation in a g i ven ba sis defi ned by an in vertible matrix W . Th us, x = Wc wh ere c is a spa rse vector tha t has at mos t k nonzero e lements. Th is fits our framew ork by c hoosing A i as the s pace spa nned by the i th c olumn of W . In this setting m = N , and there are N k subspa ces co mprising the union. Another exa mple is the bloc k sparsity model [24], [40 ] in which x is divided into equal-length bloc ks of size d , and a t most k blocks can be non zero. Such a vector can be desc ribed in our s etting with H = R N by cho osing A i to be the spac e spanne d by the correspond ing i columns of the identity matrix. He re m = N /d and there are N/d k subspa ces in the union. A final example is the MMV problem [19], [27]–[30] in which our goal is to recover a matrix X from 7 measureme nts Y = MX , for a given sampling ma trix M . Th e matrix X is as sumed to have at most k non- zero rows. Thu s, not only is eac h c olumn x i k -sparse, but in addition the non-zero elements of x i share a joint sparsity pa ttern. This problem ca n be transformed into that o f recovering a k -block sparse signal by stacking the rows of X and Y , leading to the relationship v ec( Y T ) = ( M ⊗ I ) ve c( X T ) . (10) The s tructure of X leads to a vector ve c ( X T ) that is k -block spa rse. C. Pr o blem F ormulation and Main Results Gi ven k and the s ubspac es A i , we would like to addres s the following que stions: 1) What are the conditions on the sa mpling vectors s i , 1 ≤ i ≤ n in order to guaran tee that the sampling is in vertible a nd sta ble? 2) How c an we recover the un ique x (regardless of c omputational c omplexity)? 3) How c an we recover the un ique x in an ef ficien t and s table man ner? The first q uestion was add ressed in [22], [23] in the more ge neral context o f unions o f spa ces (without requiring a particular structure such as (7)). Howev er , no concrete methods were propo sed in order to recover x . Here we provide efficient co n vex algorithms that rec over x in a s table way for a rbitrary k under appropriate cond itions on the sampling functions s i and the spa ces A i . Our resu lts are based on an e quiv a lence betwee n the union of subspaces prob lem assuming (7) a nd that of recovering block-spa rse vectors. This allows us to recover x from the gi ven s amples by first treating the problem of recovering a block k -sparse vector c from a g i ven set of measurements. Th is relationship is established in the n ext section. In the remind er of the pape r we therefore focus on the block k -spa rse model and develop our results in that context. In particular , we introduce a b lock R IP condition that ensures uniqueness a nd s tability of our sa mpling problem. W e then sugg est an efficient c on vex optimization problem which approximates an unknown block-sparse vector c . Ba sed on block RIP we prov e that c can be recovered exac tly in a stable way using the proposed optimization prog ram. Fu rthermore, in the p resence o f noise and mode ling e rrors, our algorithm ca n approximate the bes t block- k sparse s olution. I I I . C O N N E C T I O N W I T H B L O C K S P A R S I T Y Consider the model of a s ignal x in the union of k out of m subspa ces A i , with d i = dim( A i ) as in (6) a nd (7). T o write x explicit ly , we choose a basis for e ach A i . Denoting by A i : R d i → H the se t transformation 8 correspond ing to a basis for A i , a ny s uch x can be written a s x = X | i | = k A i c i , (11) where c i ∈ R d i are the rep resentation co efficients in A i , a nd | i | = k denotes a sum ov er a se t of k indices. The choice of indices depe nd on the s ignal x and are un known in advance. T o develop the equi valence with b lock sparsity , it is useful to introdu ce some further n otation. First, we define A : R N → H a s the set transformation that is a result of co ncatena ting the diff erent A i , with N = m X i =1 d i . (12) Next, we de fine the i th sub-block c [ i ] of a length- N vector c over I = { d 1 , . . . , d m } . The i th sub-block is of length d i , a nd the blocks a re formed se quentially so that c T = [ c 1 . . . c d 1 | {z } c [1] . . . c N − d m +1 . . . c N | {z } c [ m ] ] T . (13) W e ca n then define A by A c = m X i =1 A i c [ i ] . (14) When H = R N for some N , A i = A i is a matrix and A = A is the ma trix obtained by column-wise concatenating A i . If for a given x the j th su bspace A j does no t app ear in the s um (7), or e quiv a lently in (11), then c [ j ] = 0 . Any x in the union (6 ), (7) can be repres ented in terms o f k of the base s A i . Therefore, we ca n write x = A c where there are at most k non -zero blocks c [ i ] . Con sequen tly , o ur union model is equiv alent to the model in which x is represe nted by a sparse vector c in a n ap propriate bas is. Howe ver , the spars ity pattern h ere ha s a unique form which we will exploit in our conditions a nd algorithms: the non-ze ro e lements a ppear in blocks. Definition 1: A vector c ∈ R N is c alled block k -sparse over I = { d 1 , . . . , d m } if c [ i ] is n onzero for at most k indices i whe re N = P i d i . An examp le of a block-sparse vec tor with k = 2 is depicted in Fig. 1. When d i = 1 for each i , block sp arsity c T = d 1 = 3 d 4 = 6 d 2 = 4 d 5 = 1 d 2 = 2 Fig. 1. A block-sparse vector c ov er I = { d 1 , . . . , d 5 } . The gray areas represent 10 non-zero entries which occup y two blocks. reduces to the con ventional definition of a s parse vector . De noting k c k 0 , I = m X i =1 I ( k c [ i ] k 2 > 0) , (15) 9 where I ( k c [ i ] k 2 > 0) is an indicator function that obtains the v alue 1 if k c [ i ] k 2 > 0 and 0 otherwise, a block k -sparse vector c can b e defi ned by k c k 0 , I ≤ k . Evidently , there is a o ne-to-one corresponden ce be tween a vector x in the union, and a b lock-sparse vector c . The me asurements (5) can also be repres ented explicitly in terms of c a s y = S ∗ x = S ∗ A c = Dc , (16) where D is the n × N ma trix d efined by D = S ∗ A. (17) W e can therefore phras e our problem in terms of D and c a s that of re covering a block - k s parse vec tor c over I from the meas urements (16). Note that the c hoice of basis A i for each subsp ace does not affect our model. Indee d, choos ing alternati ve bases will lead to x = A Wc where W is a block diagonal matrix with block s o f size d i . De fining ˜ c = Wc , the block sparsity pa ttern of ˜ c is equ al to that o f c . Since ou r problem is equiv alent to that of recoveri ng a block spars e vector over I from linea r meas urements y = Dc , in the reminder of the pa per we focus our a ttention on this problem. I V . U N I Q U E N E S S A N D S T A B I L I T Y In this s ection we study the uniquenes s and stab ility of our s ampling method. Thes e properties are intimately related to the RIP , which we g eneralize here to the block-sparse setting. The first question we ad dress is that of unique ness, na mely c onditions under whic h a bloc k-sparse vec tor c is uniquely determined by the measureme nt vector y = Dc . Pr o position 1: There is a unique block- k sparse vec tor c consistent with the mea surements y = Dc if and only if Dc 6 = 0 for every c 6 = 0 that is block 2 k -spa rse. Pr o of: The p roof follows from [22, Propo sition 4]. W e next addre ss the issue of stability . A sa mpling operator is stable for a set T if and o nly if there exists constants α > 0 , β < ∞ such tha t α k x 1 − x 2 k 2 H ≤ k S ∗ x 1 − S ∗ x 2 k 2 2 ≤ β k x 1 − x 2 k 2 H , (18) for every x 1 , x 2 in T . The ratio κ = β /α provides a measure for stability of the sampling operator . The operator is maximally stable wh en κ = 1 . In our s etting, S ∗ is rep laced by D , and the set T contains bloc k- k sparse vectors. The follo wing propos ition follows immediately from (18) by noting that giv en two bloc k- k s parse vectors c 1 , c 2 their difference c 1 − c 2 is b lock- 2 k s parse. 10 Pr o position 2: The measu rement matrix D is stable for ev ery bloc k k -sparse vector c if and only if there exists C 1 > 0 and C 2 < ∞ s uch tha t C 1 k v k 2 2 ≤ k Dv k 2 2 ≤ C 2 k v k 2 2 , (19) for every v that is block 2 k -sp arse. It is ea sy to see that if D s atisfies (19) then Dc 6 = 0 for all block 2 k -sparse vec tors c . Therefore, this condition implies b oth in vertibili ty and stability . A. Block RIP Property (19) is related to the RIP used in several previous works in CS [9], [13], [14]. A matrix D of size n × N is sa id to have the RIP if there exists a constant δ k ∈ [0 , 1) su ch that for ev ery k -spa rse c ∈ R N , (1 − δ k ) k c k 2 2 ≤ k Dc k 2 2 ≤ (1 + δ k ) k c k 2 2 . (20) Extending this property to block-spa rse vectors leads to the following defin ition: Definition 2: Let D : R N → R n be a giv en matrix. Then D has the block RIP over I = { d 1 , . . . , d m } with parameter δ k |I if for every c ∈ R N that is bloc k k -spa rse over I we have that (1 − δ k |I ) k c k 2 2 ≤ k Dc k 2 2 ≤ (1 + δ k |I ) k c k 2 2 . (21) By abuse of notation, we us e δ k for the bloc k-RIP cons tant δ k |I when it is clear from the context that we refer to blocks. Bloc k-RIP is a sp ecial case of the A -res tricted isometry defined in [23]. F rom P roposition 1 it follows that if D sa tisfies the RIP (21) with δ 2 k < 1 , then the re is a unique block-spa rse vector c con sistent with (16). Note that a block k -sparse vector over I is M -sparse in the con ven tional se nse wh ere M is the sum of the k lar gest values in I , since it has at mos t M n onzero elements. If we require D to satisfy RIP for all M -sparse vectors, then (21) must h old for a ll 2 M -sparse vectors c . Since we only require the RIP for bloc k sparse sign als, (21) only has to be satisfied for a certain subs et o f 2 M -spa rse signals , na mely those tha t have block s parsity . As a result, the block-RIP c onstant δ k |I is typically sma ller tha n δ M (where M depends o n k ; for blocks with equal size d , M = k d ). T o empha size the advantage of block RIP over standa rd RIP , c onsider the following matrix, s eparated into three blocks of two c olumns ea ch: D = − 1 1 0 0 0 1 0 2 − 1 0 0 3 0 3 0 − 1 0 1 0 1 0 0 − 1 1 · B , (22) 11 where B is a diago nal matrix tha t res ults in unit-norm columns of D , i.e., B = diag (1 , 15 , 1 , 1 , 1 , 12) − 1 / 2 . In this example m = 3 and I = { d 1 = 2 , d 2 = 2 , d 3 = 2 } . Suppos e tha t c is b lock-1 sparse , which correspon ds to at most two non-zero values. Brute-force calcu lations show that the s mallest value of δ 2 satisfying the standard RIP (20 ) is δ 2 = 0 . 866 . On the other hand, the b lock-RIP (21 ) corresp onding to the case in which the two non-zero elements are restricted to occur in one block is satisfied with δ 1 |I = 0 . 289 . Increasing the number o f non-zero elemen ts to k = 4 , we ca n verify that the standard RIP (20) does not ho ld for any δ 4 ∈ [0 , 1) . Indeed, in this example there exist two 4 -sparse vectors that resu lt in the same measureme nts. In contrast, δ 2 |I = 0 . 966 satisfies the lower bound in (21) wh en res tricting the 4 non-zero v alues to two blocks. Conseque ntly , the measu rements y = Dc uniquely specify a single block-spa rse c . In the next sec tion, we will se e that the ability to recover c in a comp utationally efficient way depend s on the c onstant δ 2 k | I in the block RIP (21). The s maller the v alue of δ 2 k | I , the fe wer sa mples are needed in order to guarantee stable recovery . Both standard and block RIP co nstants δ k , δ k |I are by definition increasing with k . Therefore, it was sugge sted in [12] to no rmalize each of the c olumns of D to 1, s o as to start with δ 1 = 0 . In the same spirit, w e rec ommend cho osing the bas es for A i such that D = S ∗ A ha s unit-norm co lumns, correspo nding to δ 1 | I = 0 . B. Recovery Method W e have se en tha t if D satisfies the RIP (21) with δ 2 k < 1 , then there is a unique bloc k-sparse vector c consisten t with (16). The q uestion is how to fi nd c in practice. B elow we present an algorithm that will in principle find the unique c from the sa mples y . Unfortunately , tho ugh, it has expone ntial complexity . In the next section we s how that u nder a stronger condition on δ 2 k we can recover c in a stable and efficient ma nner . Our firs t claim is that c ca n be uniquely recovered by solving the optimization problem min c k c k 0 , I s . t . y = Dc . (23) T o show that (23) will ind eed recover the true value of c , su ppose that the re exists a c ′ such that Dc ′ = y and k c ′ k 0 , I ≤ k c k 0 , I ≤ k . Since both c , c ′ are consisten t with the measu rements, 0 = D ( c − c ′ ) = Dd , (24) where k d k 0 , I ≤ 2 k so tha t d is a bloc k 2 k -sp arse vector . Since D satisfies (21 ) with δ 2 k < 1 , we must have that d = 0 or c = c ′ . In principle (23) can be solved by search ing over all possible se ts of k b locks whether there exists a c tha t is 12 consisten t with the meas urements. The in vertibility condition (21) e nsures that the re is o nly one s uch c . Howev er , clearly this approa ch is not efficient. V . C O N V E X R E C OV E RY A L G O R I T H M A. Noise-F ree Re covery W e now develop an efficient co n vex optimization problem instea d of (23) to approximate c . As we s how , if D satisfies (21) with a small e nough value of δ 2 k , then the method w e p ropose will recover c exactly . Our approach is to minimize the sum of the energy of the blocks c [ i ] . T o write d own the problem explicitly , we define the mixed ℓ 2 /ℓ 1 norm over the index set I = { d 1 , . . . , d m } as k c k 2 , I = m X i =1 k c [ i ] k 2 . (25) The a lgorithm we sug gest is then min c k c k 2 , I s . t . y = Dc . (26) Problem (26) c an be written a s an SOCP by d efining t i = k c [ i ] k 2 . T hen (26) is equiv alent to min c ,t i m X i =1 t i s . t . y = Dc t i ≥ k c [ i ] k 2 , 1 ≤ i ≤ m t i ≥ 0 , 1 ≤ i ≤ m, (27) which ca n be solved using standa rd s oftware pac kages. The n ext theorem es tablishes that the solution to (26) is the true c as long as δ 2 k is small enoug h. Theorem 1: Let y = Dc 0 be meas urements o f a block k -sparse vector c 0 . If D satisfies the block RIP (21) with δ 2 k < √ 2 − 1 then 1) there is a unique block- k sparse vector c c onsistent with y ; 2) the SOCP (27) has a u nique s olution; 3) the solution to the SOCP is e qual to c 0 . Before proving the theorem we note that it provides a gain over s tandard CS res ults. Specifically , it is shown in [14] that if c is k -sparse a nd the mea surement matrix D s atisfies the stan dard RIP with δ 2 k < √ 2 − 1 , then c ca n 13 be rec overed exactly from the measureme nts y = Dc v ia the linear program: min c k c k 1 s . t . y = Dc . (28) Since any block k -sparse vector is also M -spa rse w ith M equal to the su m of the k lar gest values of d i , we c an find c 0 of Theorem 1 by solving (28) if δ 2 M is small enoug h. Howev er , this standa rd CS a pproach does not exploit the fact that the non-zero values appe ar in blocks , and not in arbitrary loc ations within the vector c 0 . On the o ther hand, the SOCP (27) explicitly takes the block structure of c 0 into acc ount. Therefore, the condition of Theorem 1 is not as stringent as that obtained by using equiv alence res ults with respect to (28). Ind eed, the block RIP (21) bounds the norm of k Dc k over block sparse vectors c , while the stan dard RIP conside rs all poss ible cho ices of c , also thos e tha t are not 2 k -block sparse . Th erefore, the value o f δ 2 k in (21) can be lower than that o btained from (20) with k = 2 M , as we illustrated by an example in Section III. Th is advantage will also be se en in the co ntext of a c oncrete example at the e nd of the sec tion. Our proof below is rooted in tha t of [14]. However , some essential mod ifications are ne cessa ry in order to adapt the results to the b lock-sparse case. The se dif feren ces are a res ult of the fact that our algorithm relies on the mixed ℓ 2 /ℓ 1 norm rathe r than the ℓ 1 norm a lone. This adds another la yer o f comp lication to the proof, an d therefore w e expand the deriv ations in more de tail than in [14]. Pr o of: W e fi rst note that δ 2 k < 1 gu arantees uniquene ss of c 0 from Propos ition 1. T o prove parts 2) and 3) we s how that any solution to (26) h as to be eq ual to c 0 . T o this en d let c ′ = c 0 + h be a solution of (26). The true value c 0 is non-zero over at most k b locks. W e denote b y I 0 the block indices for which c 0 is nonzero, a nd by h I 0 the restriction of h to these b locks. Next we de compose h as h = ℓ − 1 X i =0 h I i , (29) where h I i is the restriction of h to the s et I i which consists of k blocks , chosen such that the norm of h I c 0 over I 1 is largest, the norm over I 2 is s econd largest and s o on. Our goa l is to show that h = 0 . W e prove this b y noting that k h k 2 = k h I 0 ∪I 1 + h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 ∪I 1 k 2 + k h ( I 0 ∪I 1 ) c k 2 . (30) In the first pa rt of the proo f we show t hat k h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 ∪I 1 k 2 . In the s econd part we establish that k h I 0 ∪I 1 k 2 = 0 , which completes the proof. P art I: k h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 ∪I 1 k 2 14 W e begin by noting tha t k h ( I 0 ∪I 1 ) c k 2 = ℓ − 1 X i =2 h I i 2 ≤ ℓ − 1 X i =2 k h I i k 2 . (31) Therefore, it is sufficient to b ound k h I i k 2 for i ≥ 2 . Now , k h I i k 2 ≤ k 1 / 2 k h I i k ∞ , I ≤ k − 1 / 2 k h I i − 1 k 2 , I , (32) where w e defined k a k ∞ , I = max i k a [ i ] k 2 . The first inequality follo ws from the fact that for any b lock k -s parse c , k c k 2 2 = X | i | = k k c [ i ] k 2 2 ≤ k k c k 2 ∞ , I . (33) The se cond inequa lity in (32) is a res ult of the fact that the norm of each block in h I i is by definition smaller or equal to the norm of e ach b lock in h I i − 1 . Since there are at most k nonzero blocks, k k h I i k ∞ , I ≤ k h I i − 1 k 2 , I . Substituting (32) into (31), k h ( I 0 ∪I 1 ) c k 2 ≤ k − 1 / 2 ℓ − 2 X i =1 k h I i k 2 , I ≤ k − 1 / 2 ℓ − 1 X i =1 k h I i k 2 , I = k − 1 / 2 k h I c 0 k 2 , I , (34) where the equality is a res ult of the f act that k c 1 + c 2 k 2 , I = k c 1 k 2 , I + k c 2 k 2 , I if c 1 and c 2 are non-zero on disjoint blocks. T o develop a bound on k h I c 0 k 2 , I note that s ince c ′ is a so lution to (26), k c 0 k 2 , I ≥ k c ′ k 2 , I . Using the fact tha t c ′ = c 0 + h I 0 + h I c 0 and c 0 is s upported on I 0 we have k c 0 k 2 , I ≥ k c 0 + h I 0 k 2 , I + k h I c 0 k 2 , I ≥ k c 0 k 2 , I − k h I 0 k 2 , I + k h I c 0 k 2 , I , (35) from which we conc lude that k h I c 0 k 2 , I ≤ k h I 0 k 2 , I ≤ k 1 / 2 k h I 0 k 2 . (36) The las t ineq uality follows from ap plying Cau chy-Schwarz to any bloc k k -spa rse vector c : k c k 2 , I = X | i | = k k c [ i ] k 2 · 1 ≤ k 1 / 2 k c k 2 . (37) Substituting (36) into (34): k h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 k 2 ≤ k h I 0 ∪I 1 k 2 , (38 ) which co mpletes the first part o f the proof. P art II: k h I 0 ∪I 1 k 2 = 0 W e next show that h I 0 ∪I 1 must be eq ual to 0 . In this part we in voke the RIP . 15 Since Dc 0 = Dc ′ = y , we h av e Dh = 0 . Using the fact that h = h I 0 ∪I 1 + P i ≥ 2 h I i , k Dh I 0 ∪I 1 k 2 2 = − ℓ − 1 X i =2 h D ( h I 0 + h I 1 ) , Dh I i i . (39) From the parallelogram identity and the bloc k-RIP it can be sh own that |h Dc 1 , Dc 2 i| ≤ δ 2 k k c 1 k 2 k c 2 k 2 , (40) for any two bloc k k -sparse vectors with disjoint supp ort. The proo f is similar to [14, Lemma 2 .1] for the stan dard RIP . Therefore, |h Dh I 0 , Dh I i i| ≤ δ 2 k k h I 0 k 2 k h I i k 2 , (41) and s imilarly for h Dh I 1 , Dh I i i . Su bstituting into (39), k Dh I 0 ∪I 1 k 2 2 = ℓ − 1 X i =2 h D ( h I 0 + h I 1 ) , Dh I i i ≤ ℓ − 1 X i =2 ( |h Dh I 0 , Dh I i i| + |h Dh I 1 , Dh I i i| ) ≤ δ 2 k ( k h I 0 k 2 + k h I 1 k 2 ) ℓ − 1 X i =2 k h I i k 2 . (42) From the Cauc hy-Schwarz ine quality , any length-2 vector a s atisfies a (1) + a (2) ≤ √ 2 k a k 2 . T herefore, k h I 0 k 2 + k h I 1 k 2 ≤ √ 2 q k h I 0 k 2 2 + k h I 1 k 2 2 = √ 2 k h I 0 ∪I 1 k 2 , (43) where the last equality is a result of the f act that h I 0 and h I 1 have disjoint sup port. Sub stituting into (42) a nd using (32 ), (34) and (36), k Dh I 0 ∪I 1 k 2 2 ( 32 ) , ( 34 ) ≤ √ 2 k − 1 / 2 δ 2 k k h I 0 ∪I 1 k 2 k h I c 0 k 2 , I ( 36 ) ≤ √ 2 δ 2 k k h I 0 ∪I 1 k 2 k h I 0 k 2 ≤ √ 2 δ 2 k k h I 0 ∪I 1 k 2 2 , (44) where the las t inequality follows from k h I 0 k 2 ≤ k h I 0 ∪I 1 k 2 . Co mbining (44) with the RIP (21) we have (1 − δ 2 k ) k h I 0 ∪I 1 k 2 2 ≤ k Dh I 0 ∪I 1 k 2 2 ≤ √ 2 δ 2 k k h I 0 ∪I 1 k 2 2 . (45) Since δ 2 k < √ 2 − 1 , (45) can hold on ly if k h I 0 ∪I 1 k 2 = 0 , which c ompletes the proof. W e conclude this subsec tion by pointing out more explicitly the dif ferenc es between the p roof of Theorem 1 and that of [14 ]. The main d if ference begins in (32); in our formulation e ach o f the s ubvectors h I i may have a dif ferent 16 number of non-zero elements, while the equiv alent e quation in [14] (Eq. (10)) relies on the fact that the maximal number o f non -zero elemen ts in ea ch of the subvectors is the same . This requires the use of several mixed-norms in our se tting. The rest of the proo f follows the spirit of [14 ] where in s ome of the inequalities conv entional norms are us ed, while in others the ada ptation to our s etting ne cessitates mixed norms. B. Robust Recovery W e now treat the situation in wh ich the obs ervati ons are noisy , an d the vector c 0 is n ot exac tly bloc k- k sparse. Specifica lly , supp ose that the me asurements (16) are corrupted b y boun ded noise so that y = Dc + z , (46) where k z k 2 ≤ ǫ . In order to recover c we us e the modified SOCP: min c k c k 2 , I s . t . k y − Dc k 2 ≤ ǫ. (47) In addition, given a c ∈ R N , we denote by c k the bes t a pproximation of c by a vector with k non-zero blocks, so that c k minimizes k c − d k 2 , I over a ll block k -spa rse vectors d . T heorem 2 shows tha t ev en when c is no t block k -sparse and the meas urements are noisy , the best b lock- k approximation ca n be we ll a pproximated using (47). Theorem 2: Let y = Dc 0 + z be noisy measurements of a vector c 0 . Let c k denote the best b lock k -spa rse approximation of c 0 , suc h that c k is block k -sparse a nd minimizes k c 0 − d k 2 , I over all bloc k k -spars e vectors d , and let c ′ be a so lution to (47). If D satisfie s the bloc k RIP (21) with δ 2 k < √ 2 − 1 then k c 0 − c ′ k 2 ≤ 2(1 − δ 2 k ) 1 − (1 + √ 2) δ 2 k k − 1 / 2 k c 0 − c k k 2 , I + 4 √ 1 + δ 2 k 1 − (1 + √ 2) δ 2 k ǫ. (48) Before proving the the orem, note that the first term in (48) is a result of the f act that c 0 is no t exactly k -bloc k sparse. Th e se cond express ion qua ntifies the rec overy error due to the nois e. Pr o of: The proof is very similar to that of The orem 1 with a fe w d if ferences wh ich we indic ate. Th ese cha nges follo w the proof of [14, Theorem 1.3], with app ropriate modifications to ad dress the mixed no rm. Denote by c ′ = c 0 + h the s olution to (47). Due to the noise and the fact that c 0 is not bloc k k -s parse, we will no lon ger o btain h = 0 . Howe ver , we will show that k h k 2 is b ounded. T o this end , we begin a s in the proof of The orem 1 by us ing (30). In the fi rst part of the proof we show that k h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 ∪I 1 k 2 + 2 e 0 where e 0 = k − 1 / 2 k c 0 − c I 0 k 2 , I and c I 0 is the restriction of c 0 onto the k b locks correspo nding to the largest ℓ 2 norm. Note that c I 0 = c k . In the seco nd part, we develop a bou nd on k h I 0 ∪I 1 k 2 . P art I: Bo und on k h ( I 0 ∪I 1 ) c k 2 17 W e b egin by deco mposing h as in the p roof of T heorem 1. The ineq ualities until (35 ) hold here as w ell. Instead of (35) we have k c 0 k 2 , I ≥ k c I 0 + h I 0 k 2 , I + k c I c 0 + h I c 0 k 2 , I ≥ k c I 0 k 2 , I − k h I 0 k 2 , I + k h I c 0 k 2 , I − k c I c 0 k 2 , I . (49) Therefore, k h I c 0 k 2 , I ≤ 2 k c I c 0 k 2 , I + k h I 0 k 2 , I , (50) where we u sed the fact that k c 0 k 2 , I − k c I 0 k 2 , I = k c I c 0 k 2 , I . Combining (34), (37) and (50) we have k h ( I 0 ∪I 1 ) c k 2 ≤ k h I 0 k 2 + 2 e 0 ≤ k h I 0 ∪I 1 k 2 + 2 e 0 , (51) where e 0 = k − 1 / 2 k c 0 − c I 0 k 2 , I . P art II: Bound on k h I 0 ∪I 1 k 2 Using the fact that h = h I 0 ∪I 1 + P i ≥ 2 h I i we have k Dh I 0 ∪I 1 k 2 2 = h Dh I 0 ∪I 1 , Dh i − ℓ − 1 X i =2 h D ( h I 0 + h I 1 ) , Dh I i i . (52) From (21 ), |h Dh I 0 ∪I 1 , Dh i| ≤ k Dh I 0 ∪I 1 k 2 k Dh k 2 ≤ p 1 + δ 2 k k h I 0 ∪I 1 k 2 k Dh k 2 . (53) Since b oth c ′ and c 0 are feas ible k Dh k 2 = k D ( c 0 − c ′ ) k 2 ≤ k Dc 0 − y k 2 + k Dc ′ − y k 2 ≤ 2 ǫ, (54) and (53 ) bec omes |h Dh I 0 ∪I 1 , Dh i| ≤ 2 ǫ p 1 + δ 2 k k h I 0 ∪I 1 k 2 . (55) Substituting into (52), k Dh I 0 ∪I 1 k 2 2 ≤ |h Dh I 0 ∪I 1 , Dh i| + ℓ − 1 X i =2 |h D ( h I 0 + h I 1 ) , Dh I i i| ≤ 2 ǫ p 1 + δ 2 k k h I 0 ∪I 1 k 2 + ℓ − 1 X i =2 |h D ( h I 0 + h I 1 ) , Dh I i i| . (56) Combining with (42) and (44), k Dh I 0 ∪I 1 k 2 2 ≤ 2 ǫ p 1 + δ 2 k + √ 2 δ 2 k k − 1 / 2 k h I c 0 k 2 , I k h I 0 ∪I 1 k 2 . (57) 18 Using (37) and (50) we have the upper bo und k Dh I 0 ∪I 1 k 2 2 ≤ 2 ǫ p 1 + δ 2 k + √ 2 δ 2 k ( k h I 0 k + 2 e 0 ) k h I 0 ∪I 1 k 2 . (58) On the other han d, the RIP res ults in the lower bound k Dh I 0 ∪I 1 k 2 2 ≥ (1 − δ 2 k ) k h I 0 ∪I 1 k 2 2 . (59) From (58 ) and (59), (1 − δ 2 k ) k h I 0 ∪I 1 k 2 ≤ 2 ǫ p 1 + δ 2 k + √ 2 δ 2 k ( k h I 0 ∪I 1 k + 2 e 0 ) , (60) or k h I 0 ∪I 1 k 2 ≤ 2 √ 1 + δ 2 k 1 − (1 + √ 2) δ 2 k ǫ + 2 √ 2 δ 2 k 1 − (1 + √ 2) δ 2 k e 0 . (61) The c ondition δ 2 k < √ 2 − 1 ens ures that the denominator in (61) is p ositi ve. Sub stituting (61) res ults in k h k 2 ≤ k h I 0 ∪I 1 k 2 + k h ( I 0 ∪I 1 ) c k 2 ≤ 2 k h I 0 ∪I 1 k 2 + 2 e 0 , ( 62) which co mpletes the proof of the theorem. T o s ummarize this se ction we have see n that as long as D sa tisfies the bloc k-RIP (21 ) with a suitable constant, any block - k spa rse vector can be pe rfectly recovered from its sa mples y = Dc using the con vex SOCP (26). Th is algorithm is stable in the s ense that by slightly modifying it as in (47) it can tolerate n oise in a way that ensu res that the n orm of the recovery error is boun ded by the no ise lev el. Furthermore, if c is not block k -sparse, then its best block -sparse approximation can be app roached by solving the SOCP . These results are su mmarized in T a ble I. In the table , δ 2 k refers to the bloc k RIP constan t. T ABLE I C O M PA R I S O N O F A L G O R I T H M S F O R S I G N A L R E C OV E R Y F R O M y = D c 0 + z Algorithm (26) Algorithm (47) c 0 block k -sparse arbitrary Noise z none ( z = 0 ) bounded k z k 2 ≤ ǫ Condition on D δ 2 k ≤ √ 2 − 1 δ 2 k ≤ √ 2 − 1 Recovery c ′ c ′ = c 0 k c 0 − c ′ k 2 small; se e (48) C. Advantage of Block Sp arsity The standard sparsity model c onsidered in CS ass umes that x has at most k non-zero elements, h owe ver it d oes not impose any further structure. In particular , the no n-zero compon ents can a ppear anywhere in the vector . There are many practical s cenarios in which the non-zero values are aligned to blocks, meaning they appe ar in regions, 19 and are not arbitrarily s pread throughout the vector . One example in the structured union of subs paces model we treat in this pape r . Other examples are considered in [25]. Prior work on recovery of block-sparse vectors [24] a ssumed consecu ti ve blocks of the s ame size. It was sown t hat in this ca se, when n, N go to infinity , the algorithm (26) will recover the true block-sparse vector with overwhelming probability . The ir a nalysis is ba sed on ch aracterization of the n ull sp ace o f D . In co ntrast, o ur ap proach relies o n RIP which allo ws the d eri vation o f unique ness a nd equ i valence con ditions for fin ite dimensions and no t only in the as ymptotic regime. In ad dition, Theo rem 2 co nsiders the c ase of mismod elling and noisy obs ervations wh ile in [24] on ly the ideal n oise-free setting is treated. T o demonstrate the advantage of our algorithm over stan dard ba sis pu rsuit (28), conside r the matrix D of (22) . In Section V, the stan dard and b lock RIP co nstants of D were calculated and it was shown that bloc k RIP c onstants are smaller . This su ggests that there are input vectors x for which the mixed ℓ 2 /ℓ 1 method of (26) will b e able to rec over them exactly from me asurements y = Dc while s tandard ℓ 1 minimization will fail. T o illustrate this b ehavior , let x = [0 , 0 , 1 , − 1 , − 1 , 0 . 1] T be a 4 -sparse vector , in which the non-zero eleme nts are known to a ppear in blocks of length 2 . The prior kn owledge that x is 4 -sparse is no t sufficient to determine x from y . In co ntrast, there is a unique block-sparse vector cons istent wit h y . Furthermore, our algorithm which is a relaxed version of (23), finds the correct x wh ile stan dard ℓ 1 minimization fails in this ca se; its output is ˆ x = [ − 0 . 0289 , 0 , 0 . 9134 , − 1 . 0289 , − 1 . 0289 , 0] . W e further compare the recovery pe rformance of ℓ 1 minimization (28) a nd our algorithm (26) for an extens i ve set of random signals. In the experiment, we draw a ma trix D of size 25 × 50 from the Gau ssian ense mble. The input vec tor x is also ran domly g enerated as a b lock-sparse vector with block s of len gth 5 . W e draw 1 ≤ k ≤ 25 non-zero en tries from a zero-mean unit variance n ormal distribution and divide them into b locks which are chose n uniformly a t rand om within x . Ea ch of the algorithms is ex ecuted ba sed on the measu rements y = Dx . In Fig. 2 we plot the fraction of suc cessful recons tructions for eac h k over 500 experiments. The resu lts illustrate the ad vantage of inco rporating the block-sparsity structure into the optimization program. An interesting feature of the graph is that when using the block-spa rse rec overy approa ch, the performanc e is roughly constan t over the bloc k-length ( 5 in this example). This explains the performanc e advantage over stan dard sparse rec overy . V I . A P P L I C A T I O N T O M M V M O D E L S W e now spe cialize o ur algo rithm a nd eq uiv alen ce results to the MMV problem. This leads to two contributions which we discuss in this sec tion: Th e first is an equi valence result based on RIP for a mixed-norm MMV algorithm. The sec ond is a new mea surement strategy in MMV proble ms that leads to improved performance over con ventional MMV methods , both in simulations and as meas ured by the RIP-base d equiv a lence condition. In contrast to previous equiv alence results, for this strategy we show that even if we c hoose the worst poss ible X , improved pe rformance over the single measureme nt s etting c an be guaran teed. 20 5 10 15 20 25 0 0.2 0.4 0.6 0.8 1 k Empirical Recovery Rate D 25 X 50 Basis pursuit Our algorithm Fig. 2. Recov ery rate of block-sparse signals using standard ℓ 1 minimization (basis pursuit) and the mix ed ℓ 2 /ℓ 1 algorithm. A. Equivalenc e Results As we have se en in Se ction II, a sp ecial case of b lock s parsity is the MMV mod el, in wh ich we a re given a ma trix of measureme nts Y = MX where X is an unknown L × d matrix tha t has at mos t k non-zero rows. Denoting by c = v ec ( X T ) , y = ve c( Y T ) , D = M T ⊗ I d we can express the vector of measureme nts y as y = Dc where c is a block s parse vec tor with conse cutiv e blocks of length d . Therefore, the resu lts of T heorems 1 and 2 can b e spe cified to this problem. Recovery algorithms for MMV u sing co n vex optimization prog rams were studied in [28 ], [30] a nd several greedy algorithms were p roposed in [27 ], [29]. Spe cifically , in [27]–[30] the au thors study a c lass of optimization programs, which we refer to as M-BP: M-BP( ℓ q ): min L X i =1 k X i k p q s . t . Y = MX , (63) where X i is the i th row of X . The cho ice p = 1 , q = ∞ was cons idered in [30], while [28] treated the cas e of p = 1 a nd arbitrary q . Using p ≤ 1 a nd q = 2 was sugg ested in [27], [41], leading to the iterati ve algorithm M-FOCUSS. For p = 1 , q = 2 , the program (63) has a global minimum which M-FOCUSS is p roven to find. A nice comparison between these me thods can be found in [30]. Equiv alence for MMV algorithms base d on RIP analysis does not a ppear in pre vious papers. The mos t detailed the oretical analysis c an be found in [28] which establishes equiv a lence resu lts based on mutual coherenc e. Th e res ults imply e quiv a lence for (63) with p = 1 unde r conditions equal to those obtained for the single measurement case. No te that R IP analysis typically leads to tighter equiv alence boun ds tha n mu tual cohe rence analysis. In our re cent work [19], we sugges ted an alternative approa ch to solving MMV problems by merging the d measureme nt co lumns with ra ndom coef ficients and in such a way trans forming the multiple measurement problem 21 into a sing le measureme nt coun terpart. As proved in [19], this technique preserves the non -zero loc ation set with probability one thus reduc ing c omputational complexity . Moreover , we showed that this method ca n be use d to boost the empirical recovery rate by repea ting the ran dom merging several times. Using the b lock-sparsity approac h we can alternati vely cas t any MMV model as a sing le measureme nt vector problem by deterministically transforming the multiple measurement vectors i nto the single vector model v ec( Y T ) = ( M ⊗ I d ) v ec( X T ) , where c = vec( X T ) is block- k s parse with c onsecu ti ve blocks of length d . In co ntrast to [19] this does not reduce the numbe r of unk nowns so that the compu tational comp lexity of the resulting algorithm is on the s ame orde r a s p re vious approache s, and a lso do es not offer the oppo rtunity for boosting. Howe ver , as we see in the next subs ection, with an appropriate choice of measureme nt matrix this ap proach results in improved recovery c apabilities. Since we can ca st the MMV problem a s o ne of block-sparse recovery , we ma y a pply our equi valence resu lts of The orem 1 to this setting lead ing to RIP-based equi valence. T o this e nd we first no te that applying the SOCP (26) to the effecti ve measurement vector y is the same as solving (63) with p = 1 , q = 2 . Thu s the eq ui valence conditions we de velop below relate to this program. Next, if z = Dc where c is a block 2 k -sparse vector an d D = M ⊗ I d , then taking the s tructure of D into acco unt, Z = MX whe re X is a size L × d matrix whose i th row is e qual to c [ i ] , and similarly for Z . The block spa rsity o f c implies that X h as at most 2 k non-ze ro ro ws. The s quared ℓ 2 norm k z k 2 2 is e qual to the squared ℓ 2 norm o f the rows of Z w hich ca n be written as k z k 2 2 = k Z k 2 F = T r( Z T Z ) , (64) where k Z k F denotes the Frob enius norm. Since k c k 2 2 = k X k 2 F the RIP c ondition bec omes (1 − δ 2 k ) T r( X T X ) ≤ T r( X T M T MX ) ≤ (1 + δ 2 k ) T r( X T X ) , (65) for any L × d matrix X with a t most 2 k non-zero rows. W e now show that (65) is e quiv a lent to the standa rd RIP condition (1 − δ 2 k ) k x k 2 2 ≤ k Mx k 2 2 ≤ (1 + δ 2 k ) k x k 2 2 , (66) for any length L vector x that is 2 k -s parse. T o se e this, suppos e first that (65) is s atisfied for e very ma trix X with at most 2 k non-zero rows an d let x b e an a rbitrary 2 k -spa rse vector . If we define X to be the matrix wh ose co lumns are a ll e qual to x , then X will have at mos t 2 k non-zero rows an d therefore satisfies (65). Since the columns of X are all equal, T r( X T X ) = d k x k 2 2 and T r( X T M T MX ) = d k M x k 2 2 so that (66) holds. Con versely , suppose that (66) is sa tisfied for all 2 k -sparse vec tors x a nd let X be a n arbitrary matrix with at most 2 k non-zero rows. Denoting by x j the columns of X , each x j is 2 k -sparse and therefore sa tisfies (66). Summing over all values j 22 results in (65). T o su mmarize, if M satisfies the c on ven tional RIP condition (66), the n the algorithm (63) with p = 1 , q = 2 will recover the true unknown X . This requirement red uces to that we would obtain if we tri ed to recover each column of X sep arately , using the s tandard ℓ 1 approach (28). As we a lready noted, previous e quiv a lence results for MMV algorithms also s hare this feature. A lthough this condition gua rantees that proce ssing the vectors jointly does n ot harm the recovery ability , in p ractice exploiting the joint sparsity pattern of X via (63) leads to improved results. Unfortunately , this beh avior is not ca ptured by any of the known equiv alenc e cond itions. This is due to the special s tructure of D = M ⊗ I . Since e ach meas urement vector y i is affected only by the correspond ing vec tor x i , it is clear that in the worst-case we ca n choos e x i = x for some vector x . In this case, all the y i s a re eq ual so that adding mea surement vectors will no t improve our recovery ability . Consequ ently , worst-case analys is based on the stan dard mea surement mode l for MMV problems c annot lea d to improved performance over the s ingle measureme nt c ase. B. Impr oved MMV Re covery W e have seen that the pe ssimistic e quiv a lence results for MMV algorithms is a c onsequ ence of the fact that in the w orst-case s cenario in which x i = x , using a separable meas urement s trategy will render all observation vectors equal. In this s ubsection we introduce a n alternativ e me asurement techn ique for MMV problems that ca n lead to improved worst-case behavior , a s meas ured by RIP , over the single chan nel case. One way to improve the analytical results is to co nsider an average case analysis instead of a worst-case app roach. In [42] we show that if the unk nown vectors x i are generated randomly , then the performance improves with increasing numb er of meas urement vectors. The ad vantage s tems from the fact that the situation of equal vectors has z ero probab ility and the refore does not aff ect the average pe rformance. Here we take a dif ferent rou te which does not in volve randomness in the unknown vectors, and leads to improved res ults e ven in the w orst-case (name ly without req uiring an average a nalysis). T o enha nce the performance of MMV recovery , we note that when we a llo w for an arbitrary (unstructured) D , the RIP condition of The orem 1 is weaker than the standard RIP requirement for recovering k -s parse vectors. Th is sugges ts that we can improve the performance of MMV method s by con verting the problem into a general block sparsity problem, a nd then s ampling with an arbitrary unstructured matrix D rather than the choice D = M T ⊗ I d . The tradeoff introduced is increase d computational comp lexity since each measu rement is base d on all inp ut vectors. The theoretical c onditions will now be loose r , since bloc k-RIP is weaker than stand ard RIP . Furthermore, in practice , this approac h o ften improves the performance over se parable MMV measureme nt tech niques as we illustrate in the follo wing example. In the example, we compa re the performance of several MMV algo rithms for recovering X in the model Y = 23 5 10 15 20 0 0.2 0.4 0.6 0.8 1 k Empirical Recovery Rate M−BP(l 1 ) M−BP(l ∞ ) M−BP(l 2 ) M−FOCUSS p=0.8 ReMBo (BP) Our algorithm Fig. 3. Recov ery rate for different number k of non-zero rows in X . Each point on the graph represents an averag e recovery rate over 500 simulations. MX , with our method based on block sparsity in which the measurements y are obtained via y = Dc whe re c = v ec( X T ) an d D is a dens e matrix. C hoosing D as a block diag onal matrix with blocks equal to M results in the sta ndard MMV mea surement mode l. The e f fectiv e matrices D ha ve the same size in the case in which it is block diagonal a nd whe n it is dens e. T o compare the performance of (26) with a dense D to that of (63) with a bloc k diagonal D , we compute the e mpirical recovery rate of the metho ds in the same way performed in [19]. The matrices M and D are drawn randomly from a Gaussian ensemble. In our example, we choo se ℓ = 20 , L = 30 , d = 5 where ℓ is the number of rows in Y . The matri x X is ge nerated ran domly by first selecting the k no n-zero rows un iformly at random, an d the n drawing the elements in thes e rows from a n ormal distributi on. T he empirical rec overy rates using the methods of (63) for different c hoices o f q and p , ReMBO [19] and our algorithm (26) with dens e D are depicted in F ig. 3. When the index p is o mitted it is equal to 1 . Evidently , our algorithm p erforms better than mo st popular optimization techniques for MMV sys tems. W e stress that the performance a dvantage is due to the joint measureme nt p rocess rather than a new recovery algorithm. V I I . R A N D O M M A T R I C E S Theorems 1 and 2 estab lish that a sufficiently small block RIP co nstant δ 2 k | I ensures exa ct recovery of the coefficient vector c . W e no w prove that random matrices are lik ely to satisfy this requirement. Specific ally , we show that the probab ility that δ k |I exceeds a certain thresho ld d ecays exponen tially in the length o f c . Our app roach relies on results of [12], [26] developed for standard RIP , howe ver , exploiting the block s tructure of c leads to a much faster deca y rate. Pr o position 3: Supp ose D is an n × N matrix from the Gaus sian e nsemble, na mely [ D ] ik ∼ N (0 , 1 n ) . Let δ k |I be the smallest value s atisfying the b lock RIP (21) ov er I = { d 1 = d, . . . , d m = d } , a ssuming N = md for some 24 integer m . Then, for every ǫ > 0 the bloc k RIP consta nt δ k |I obeys (for n, N large en ough, and fixed d ) Prob q 1 + δ k |I > 1 + (1 + ǫ ) f ( r ) ≤ 2 e − N H ( r ) ǫ · e − m ( d − 1) H ( r ) . (67) Here, the ratio r = k d/ N is fixed, f ( r ) = q N n √ r + p 2 H ( r ) , and H ( q ) = − q log q − (1 − q ) log (1 − q ) is the entropy function defined for 0 < q < 1 . The ass umption that d i = d simplifies the calculations in the proof. Following the proof, we sh ortly ad dress the more d if ficult c ase in which the block s have varying len gths. W e note that Propos ition 3 reduces to the result of [12] when d = 1 . Howe ver , since f ( r ) is independ ent of d , it follows that for d > 1 and fixed problem dimen sions n, N , r , block-RIP c onstants a re smaller than the s tandard RIP constan t. The second expon ent in the right-hand side of (67) is respons ible for this behavior . Pr o of: Let λ = (1 + ǫ ) f ( r ) and defin e ¯ σ = max | T | = k , d σ max ( D T ) , σ = min | T | = k , d σ min ( D T ) , (68) where σ max ( D T ) , σ min ( D T ) , are the largest and the smallest sing ular v alues of D T , respec ti vely . W e use | T | = k , d to denote a column subse t of D c onsisting of k blocks of length d . For bre vity we omit subs cripts and denote δ = δ k |I . T he ineq ualities in the definition o f block -RIP (21) imply that 1 + δ ≥ ¯ σ 2 (69) 1 − δ ≤ σ 2 . (70) Since δ is the smallest n umber sa tisfying thes e inequalities w e h av e that 1 + δ = max( ¯ σ 2 , 2 − σ 2 ) . Th erefore, Prob √ 1 + δ > 1 + λ = Prob p max( ¯ σ 2 , 2 − σ 2 ) > 1 + λ (71) ≤ Prob( ¯ σ > 1 + λ ) + Pr ob( p 2 − σ 2 > 1 + λ ) . (72) Noting that σ ≥ 1 − λ implies p 2 − σ 2 ≤ 1 + λ we co nclude that Prob √ 1 + δ > 1 + λ ≤ Prob( ¯ σ > 1 + λ ) + Pr ob( σ < 1 − λ ) . (73) W e now bou nd each term in the right-hand-side of (73) using a resu lt of D avidson and Szarek [43] regarding the conce ntration of the extreme sing ular values o f a Gauss ian matrix. It was p roved in [43 ] that an m × n matrix X with n ≥ m s atisfies Prob( σ max ( X ) > 1 + p m/n + t ) ≤ e − nt 2 / 2 (74) Prob( σ min ( X ) < 1 − p m/n − t ) ≤ e − nt 2 / 2 . (75) 25 Applying a union bound leads to Prob ¯ σ > 1 + r k d n + t ! ≤ X | T | = k , d Prob σ max ( D T ) > 1 + r k d n + t ! (76) ≤ X | T | = k , d e − nt 2 / 2 (77) = m k e − nt 2 / 2 . (78) Using the we ll-kno wn b ound on the binomial coe f ficient (for sufficiently large m ) m k ≤ e mH ( k/m ) , (79) we co nclude that Prob ¯ σ > 1 + r k d n + t ! ≤ e mH ( k/m ) e − nt 2 / 2 . (80) T o u tilize this resu lt in (73) we rearrange 1 + λ = 1 + (1 + ǫ ) f ( r ) (81) = 1 + (1 + ǫ ) r k d n + r 2 N n H ( r ) ! (82) ≥ 1 + r k d n + r (1 + ǫ ) 2 N n H ( r ) (83) and o btain that Prob ( ¯ σ > 1 + λ ) ≤ Prob ¯ σ > 1 + r k d n + r (1 + ǫ ) 2 N n H ( r ) ! . (84 ) Using (80) leads to Prob ( ¯ σ > 1 + λ ) ≤ e mH ( k/m ) e − n (1+ ǫ )2 N H ( r ) 2 n (85) = e N H ( r ) − m ( d − 1) H ( r ) − (1+ ǫ ) N H ( r ) (86) ≤ e − N H ( r ) ǫ e − m ( d − 1) H ( r ) . (87) Similar a r guments are u sed to bo und the s econd term in (73), c ompleting the proof. The p roof of Proposition 3 c an be adapted to the case in which d i are no t equ al. In this case , the notation | T | = k , d is replaced by | T | = k |I and has the follo wing meaning: T indicates a co lumn s ubset of D cons isting of k blocks from I . Since I c ontains variable-length blocks, | T | is not con stant a nd depend s o n the particular column subset. Conseq uently , in o rder to app ly the u nion bou nds in (76) we nee d to co nsider the worst-case scen ario correspond ing to the maximal block length in I . Prop osition 3 thus holds for d = max( d i ) . Ho wever , it is clear 26 0 1 2 3 4 5 x 10 −3 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 r ρ (r) d=1 d=5 d=20 n/N=1/2 n/N=2/3 n/N=3/4 Fig. 4. The upper bound on δ k |I as a function of the sparsity ratio r , for three sampling rates n/ N , and three block structures d = 1 , 5 , 20 . The horizontal threshold is fixed on ρ ∗ = √ 2 − 1 representing the threshold for equiv alence deriv ed in Theorem 1. that the resulting probability boun d will not be as stringent as in the ca se of equal d i = d , especially when the ratio max ( d i ) / min( d i ) is large. Proposition 3 holds as is for matrices D from the Be rnoulli ens emble, namely [ D ] ik = ± 1 √ n with equ al probability . In fact, the proposition is true for any ensemble for which the concen tration of extreme singular values h olds. The following corollary e mphasizes the a symptotic behavior of bloc k-RIP constants per given number of s amples. Cor ollary 3: Cons ider the setting o f Propo sition 3, and de fine g ( r ) = q N n √ r + p 2 H ( r ) d − 1 . T hen, Prob q 1 + δ k |I > 1 + (1 + ǫ ) g ( r ) ≤ 2 e − mH ( r ) ǫ . (88) Pr o of: Let λ = (1 + ǫ ) g ( r ) . The result then follows by replacing (81 )-(83) with 1 + λ ≥ 1 + r k d n + r (1 + ǫ ) 2 N nd H ( r ) , (89) which lea ds to Prob( ¯ σ > 1 + λ ) ≤ e − mH ( r ) ǫ . T o evaluate the asymp totic behavior o f block -RIP we note tha t for every ǫ > 0 the right-hand s ide of (88) goes to z ero when N = md → ∞ . Cons equently , for fixed d δ k |I < ρ ( r ) △ = − 1 + [1 + g ( r )] 2 , (90) with overwhelming probability . In Fig. 4 we compute ρ ( r ) for several problem dimensions and c ompare it with standard RIP wh ich is obtained when d = 1 . Evidently , as the no n-zero entries are forced to block structure, a wider ran ge of spa rsity ratios r sa tisfy the condition o f The orem 1. 27 0 2 4 6 8 10 12 0 0.2 0.4 0.6 0.8 1 Total number of non−zeros δ k |I D 12 X 24 Block size 1 2 3 4 6 8 12 (a) 0 5 10 15 0 0.2 0.4 0.6 0.8 1 Total number of non−zeros δ k |I D 16 X 24 Block size 1 2 3 4 6 8 12 (b) 0 5 10 15 0 0.2 0.4 0.6 0.8 1 Total number of non−zeros δ k |I D 18 X 24 Block size 1 2 3 4 6 8 12 (c) Fig. 5. T he standard and block-RIP con stants δ k |I for t hree different dimensions n, N . Each graph represent an av erage ove r 10 instances of random matrix D . Each instance of D is scaled by a factor such that (18) is satisfied with α + β = 2 . Although Fig. 4 shows advantage f or b lock-RIP , the abso lute sparsity ratios predicted by the theory are p essimistic as also noted in [12 ], [26 ] in the case o f d = 1 . T o o f fer a more optimistic vie wpoint, the R IP and block-RIP constants were c omputed b rute-force for several ins tances of D f rom the Gaussian en semble. Fig. 5 plots the results and qualitati vely affirms that block-RIP cons tants are more “likely” to be smaller than their s tandard RIP counterparts, even when the dimension s n, N are relativ ely small. An important qu estion is h ow many samples are need ed roughly in order to gu arantee stable recovery . This question is address ed in the follo wing prop osition, which quotes a result from [44] b ased on the proofs of [45]; we rephra se the result to ma tch our notation. Pr o position 4 ( [ 44, The or em 3.3]): Con sider the setting of Propos ition 3, namely a random Gauss ian ma trix D of s ize n × N and b lock sp arse s ignals over I = { d 1 = d, . . . , d m = d } , where N = md for some integer m . Le t t > 0 and 0 < δ < 1 be cons tant numbers. If n ≥ 36 7 δ ln(2 L ) + k d ln 12 δ + t , (91) where L = m k , then D satisfies the block -RIP (21) with restricted isometry cons tant δ k |I = δ , with probability at least 1 − e − t . As obs erved in [44], the first term in (91) has the domina nt impa ct on the required numbe r of measureme nts in an as ymptotic se nse. Spec ifically , for block sparse s ignals ( m/k ) k ≤ L = m k ≤ ( e m/k ) k . (92) Thus, for a g i ven fraction of nonze ros r = k d/ N , roughly n ≈ k log( m/k ) = − k log( r ) measuremen ts a re needed. For c omparison, to sa tisfy the s tandard RIP a larger number n ≈ − k d log ( r ) is required. Note that Corollary 4 p uts the emphasis o n the req uired problem dimens ions to satisfy a giv en RIP level. In c ontrast, Propos ition 3 provides a tail bou nd on the expe cted iso metry co nstant for given problem dimensions. 28 V I I I . C O N C L U S I O N In this pa per , we studied the problem of rec overing an unknown signal x in an arbitrary Hilbert s pace H , from a g i ven set of n samples which a re mod elled a s inne r produ cts o f x with sampling functions s i , 1 ≤ i ≤ n . The signal x is kno wn to lie in a union of su bspace s, so that x ∈ V i where ea ch of the sub spaces V i is a su m of k subspa ces A i chosen from an ensemble of m possibilities. Thus, the re are m k possible su bspace s in which x c an lie, a nd a -priori we do not k now which s ubspac e is the true on e. While p revious treatments o f this model conside red in vertibility c onditions, h ere we provide conc rete recovery a lgorithms for a s ignal over a s tructured u nion. W e began by sh owing that recovering x can be reduce d to a s parsity problem in which the goal is to recover a bloc k-sparse vector c from mea surements y = Dc wh ere the non-zero values in c are groupe d into blocks. The meas urement matrix D is equal to S ∗ A where S ∗ is the sa mpling operator a nd A is a set transformation correspond ing to a bas is for the sum o f all A i . T o determine c we su ggested a mixed ℓ 2 /ℓ 1 con vex optimization program that takes on the form of an SOCP . Re lying o n the no tion of block-RIP , we de veloped s ufficient cond itions under which c can b e perfectly rec overed using the proposed algorithm. W e also proved that under the sa me conditions, the unknown c can be stably approximated in the presen ce of no ise. Furthermore, if c is not exactly block-sparse , then its be st block-sparse app roximation can be a pproache d us ing the prop osed method. W e then showed that whe n D is ch osen at random, the rec overy con ditions are satisfied with high probab ility . Specializing the res ults to MMV systems , we propos ed a new method for sampling in MMV p roblems. In this approach each measurement vector depend s on all the u nknown vectors. As we showed, this can lead to better recovery rate. Furthermore, we e stablished eq uiv alen ce results for a class of MMV algorithms based o n RIP . Throughou t the paper , we assumed a finite union of subspaces as well as finite dimension of the underlying space s. An interesting future direction to explore is the extension of the ideas d ev eloped h erein to the more challenging problem of rec overing x in a possibly infi nite union of subs paces , which are not necessa rily finite-dimens ional. Although at first sight t his seems lik e a dif ficult problem as our algorithms are inheren tly finite-dimensional, recovery methods for s parse signals in infin ite dimensions h av e been addres sed in some of our previous work [15 ]–[19]. In particular , we have s hown that a signal lying in a un ion of shift-in variant subspace s can be recovered efficiently from certain s ets of s ampling functions. In our future work, we intend to combine the se results with those in the current paper in order to d ev elop a more general theory for recovery from a union of subspa ces. A recent p reprint [46] that was posted o nline a fter the su bmission o f this pap er p roposes a ne w framework ca lled model-based compres si ve se nsing (MCS). The MCS approach assumes a vector signal model in which only certain predefine d sp arsity patterns may appear . In general, obtaining efficient recovery algorithms in such sce narios is dif ficult, un less further structure is impose d on the spa rsity patterns . Th erefore, the authors c onsider two types of sparse vectors: block sparsity as tr eated he re, and a wav elet tree model. For these s ettings, they gene ralize two 29 known greed y algorithms: CoSaMP [47] and iterati ve hard thresholding (IHT) [44 ]. These results emphasize our claim that the oretical questions of unique ness and stable represe ntation c an be studied for arbitrary unions as in [23]. However tractable rec overy algorithms inherently require some structure, as the o ne co nsidered here. The union model developed in this paper is broader than the block -sparse setting treated in [46] in the sense that it allo ws to model linear depe ndencies betwee n the nonzero v alues rather than only between their locations, by appropriate choice of subsp aces in (6), (7). In addition, we aim at optimization-based recovery algorithms (26),(47) which require s electing the objec ti ve in order to promote the model properties. Fina lly , we emph asize that our results are non asy mptotic and also e nsure stable recovery in the presen ce of noise and signal mismodeling. R E F E R E N C E S [1] C. E. Shannon, “Communication s in the presence of noise, ” Pr oc. IRE , vol. 37, pp. 10–21, Jan 1949 . [2] A. J. Jerri, “The S hannon sampling t heorem–Its various extensions and applications: A tutorial rev iew , ” Proc. of the IEEE , vol. 65, no. 11, pp. 156 5–1596, Nov . 1977. [3] H. Nyquist, “Certain topics in telegraph transmission theory , ” EE Tr ans. , vol. 47, pp. 617 –644, Jan. 1928. [4] M. Unser , “Sampling—50 years after S hannon, ” IEEE P r oc. , v ol. 88, pp. 569–5 87, Apr . 2000 . [5] P . P . V aidyanathan, “Generalizations of the sampling theorem: Sev en decades after Nyquist, ” IEEE T rans. C ir cuit Syst. I , vol. 48, no. 9, pp. 109 4–1109, Sep. 20 01. [6] Y . C. Eldar and T . Michaeli, “Beyond bandlimited sampling: Nonlinearities, smoothness and sparsity , ” to app ear in IE EE Signal Proc. Maga zine . [7] Y . C. Eldar and T . G. Dvorkind, “ A minimum squared-error framew ork for generalized sampling, ” IEEE T rans. Signal Pr ocessing , vol. 54, no. 6, pp. 2155–2167, Jun. 2006. [8] D. L. Donoho, “Compressed sensing, ” IEEE Tr ans. on Inf. Theory , v ol. 52, no. 4, pp. 128 9–1306, Apr 2006 . [9] E. J. Cand ` es, J. Romberg, and T . T ao, “Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information, ” IEEE T rans. Inf. Theory , vol. 52, no . 2, pp . 489–509, F eb . 2006. [10] S. S. Chen, D. L. Donoho, and M. A. Saunders, “Atomic Decomposition by Basis Pursuit, ” SIAM J. Scientific Computing , vol. 20, pp . 33–61, 199 9. [11] S. G. Mallat and Z. Zhang, “Matching pursuits with t ime-frequenc y dictionaries, ” IEEE T ransactions on Signal Process ing , vol. 41, no. 12, pp. 339 7–3415, 1993. [12] E. Cand ` es and T . T ao, “Decoding by linear programming, ” IEEE T rans. Inf. Theory , vol. 51, no. 12, pp. 4203–4215, Dec. 2005. [13] E. J. Cand ` es , J. Romberg, and T . T ao, “Stable signal reco very from incomplete and inaccurate measurements, ” Comm. Pur e and Appl. Math. , vol. 59, no. 8, pp. 1207 –1223, Mar . 2006. [14] E. Cand ` es , “The restricted isometry property and its i mplications for compressed sensing , ” C. R . Acad. Sci. P aris, Ser . I , vol. 346, pp. 589–59 2, 2008. [15] M. Mishali and Y . C. Eldar , “Bl ind multiband signal reconstruction: Compressed sensing for analog signals, ” IEE E T rans. Signal Pr ocess. , vol. 57, pp. 993– 1009, Mar . 2009. [16] ——, “From theory to practice: Sub-Nyquist sampling of sparse wideband analog signals, ” arXiv 0902.4291; submitted to IEEE Selcted T opics on Signal Pr ocess. , 2009. [17] Y . C. E ldar , “Compressed sensing of ana log signals in shit-in v ariant spaces, ” to app ear in IEEE T rans. on Signa l Pr oc. [18] ——, “Uncertainty relations for analog signals, ” submitted to IEEE Tr ans. on Information T heory , 2008. [19] M. Mishali and Y . C. El dar , “Reduce and boost: Recovering arbitrary sets of jointly sparse vectors, ” IE EE T rans. Signal P r ocess. , vol. 56, no. 10, pp. 4692–4702 , Oct. 20 08. [20] M. V . V etterli, P . Marziliano, and T . Blu, “S ampling signals with finite rate of innov ati on, ” IEEE T rans. Signal Proce ssing , vol. 50, pp. 1417–1 428, June 2002. [21] P . Dragotti, M. V etterli, and T . Blu, “Sampling moments and reconstructing signals of finite rate of innov ation: Shann on meets St rang- Fix, ” IEEE T rans. Sig. Proc. , vol. 55, no. 5, pp. 1741– 1757, May 200 7. [22] Y . M. Lu and M. N. Do, “ A theory for sampling signals from a union of subspaces, ” IEEE T rans. Signal P r ocess. , vol. 56, no. 6, pp. 2334–2 345, 2008. [23] T . Blumensath and M. E. Da vies, “Sampling theorems for signals from t he union of finite-dimension al linear subspaces, ” IEEE T rans. Inf. Theory , to appear . [24] M. Stojnic, F . Parvaresh, and B . Hassibi, “On the reconstruction of block-sparse signals with an optimal number of measurements, ” arxiv 08 04.0041 , Mar . 200 8. [25] F . Parv aresh, H. V ikalo, S . Misra, and B. Hassibi, “Recovering S parse Signals Using Sparse Measurement Matrices in Compressed DN A Microarrays, ” Selected T opics in Signal Pr ocessing, IEEE J ournal of , vol. 2, no. 3, pp. 275–285, June 2008 . [26] E. Cand ` es and T . T ao, “Near optimal signal recovery from random projections: Univ ersal encoding strategies?” IEEE T rans. Inf. Theory , vol. 52, no. 12, pp. 5406–5425 , Dec. 2006. 30 [27] S. F . Cotter , B. D. Rao, K. E ngan, and K. Kreutz-Delgado, “Sparse solutions to linear i n verse problems with multiple measurement vectors, ” IEEE Tr ans. Signal Pr ocess. , vol. 53, no. 7, pp. 24 77–2488, July 20 05. [28] J. Chen and X. Huo, “Theoretical results on sparse representations of multiple-measurement vectors, ” IEE E T rans. Signal Pr ocess. , vol. 54, no. 12, pp. 4634–4643 , Dec. 2006. [29] J. A. Trop p, “Algorithms for simultaneous sparse approximation. Part I: Greedy pursuit, ” Signal Pr ocess. ( Special Issue on Sparse Appr oximations in Signa l and Ima ge Processing ) , vol. 86, pp. 572–588, Apr . 200 6. [30] ——, “ Algorithms for simultaneous sparse approximation. Part II: Conv ex relaxation, ” Signal Pr ocess. (Special Issue on Sparse Appr oximations in Signa l and Ima ge Processing ) , vol. 86, pp. 589–602, Apr . 200 6. [31] S. G. Mallat, “ A t heory of multiresolution signal decomposition: The wav elet representation, ” IEEE T rans. P attern Anal. Mach. Intell. , vol. 11, pp. 674–693, 198 9. [32] I. Djokovic and P . P . V aidyanathan, “Generalized sampling theorems i n multiresolution subspaces, ” IEEE T rans. Signal Proce ssing , vol. 45, pp. 583–599, Mar . 1997. [33] Y . C. E ldar and T . W erther , “General framew ork for consistent sampling in Hil bert spaces, ” I nternational Jo urnal of W avelets, Multir esolution, and Information Pr ocessing , v ol. 3, no. 3, pp. 347–3 59, Sep. 2005. [34] O. Christansen and Y . C. E ldar , “Oblique dual frames and shift-in variant spaces, ” Applied and Computational Harmonic Analysis , vol. 17, no. 1, 200 4. [35] Y . C. E ldar , “Sampling and reconstruction i n arbitrary spaces and oblique dual frame v ectors, ” J . F ourier Analys. Appl. , vol. 1, no. 9, pp. 77– 96, Jan. 20 03. [36] ——, “Sampling without input constraints: Consistent reconstruction in arbitrary spaces, ” in Sampling, W avelets and T omogr aphy , A. I. Zayed and J. J. Benedetto, Eds. Boston, MA: Birkh ¨ auser , 2004, pp. 33–60. [37] Y . C. Eldar and O. Christansen, “Characterization of oblique dual frame pairs, ” J. A pplied Signal Pr ocessing , pp. 1–11, 2006, article ID 92674. [38] T . G. Dvorkind, Y . C . Eldar , and E . Matusiak, “Nonlinear and non-ideal sampling: Theory and methods, ” IE EE T rans. Signal Pro cessing , to appear . [39] T . Michaeli and Y . C. Eldar, Con vex Optimization in Signal Pr ocessing and Communications . Cambridge Univ . Press, 2009, ch. Optimization T echniques in Modern Sampling Theory . [40] Y . C. Eldar and H. B ¨ olcsk ei, “Compressed sensing for block-sparse signals: Uncertainty r elations, cohe rence, and efficient reco very , ” 2009, in preparation. [41] D. Malioutov , M. Cetin, and A. S. W illsky , “ A sparse signal reconstruction perspectiv e for source localization with sensor arrays, ” IEEE Tr ans. Signal Pr ocess. , vol. 53, no. 8, pp. 3010– 3022, Aug. 200 5. [42] Y . C. E ldar and H. R auhut, “ A verage case analysis of multichannel sparse recov ery using conv ex relaxation, ” submitted to IEEE Tr ans. on I nform. Theory . [43] S. J. Szarek, “Condition numbers of random matrices, ” J . Comple xity , vo l. 7, no. 2, pp. 131–14 9, 1991. [44] T . Blumensath and M. E. Davies, “Iterative hard thresho lding for compressed sensing, ” arxiv 0805.05 10 , July 2008 . [45] R. Baraniuk, M. Daven port, R. DeV ore, and M. W akin, “A simple proof of t he restricted isometry property for random matrices, ” Constructive A ppr oximation , vol. 28, no. 3, pp. 253–263, 2008 . [46] R. Baraniuk , V . Cev her , M. Duarte, and C. Hegde, “Model-based compressi ve sensing, ” Pr eprint , 2008 . [47] D. Needell and J. A. Trop p, “Cosamp: Iterativ e signal recovery from incomplete and inaccurate samples, ” Applied and Computational Harmonic A nalysis , vol. 26, no. 3, pp. 301 – 321, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment