Using statistical smoothing to date medieval manuscripts
We discuss the use of multivariate kernel smoothing methods to date manuscripts dating from the 11th to the 15th centuries, in the English county of Essex. The dataset consists of some 3300 dated and 5000 undated manuscripts, and the former are used …
Authors: Andrey Feuerverger, Peter Hall, Gelila Tilahun
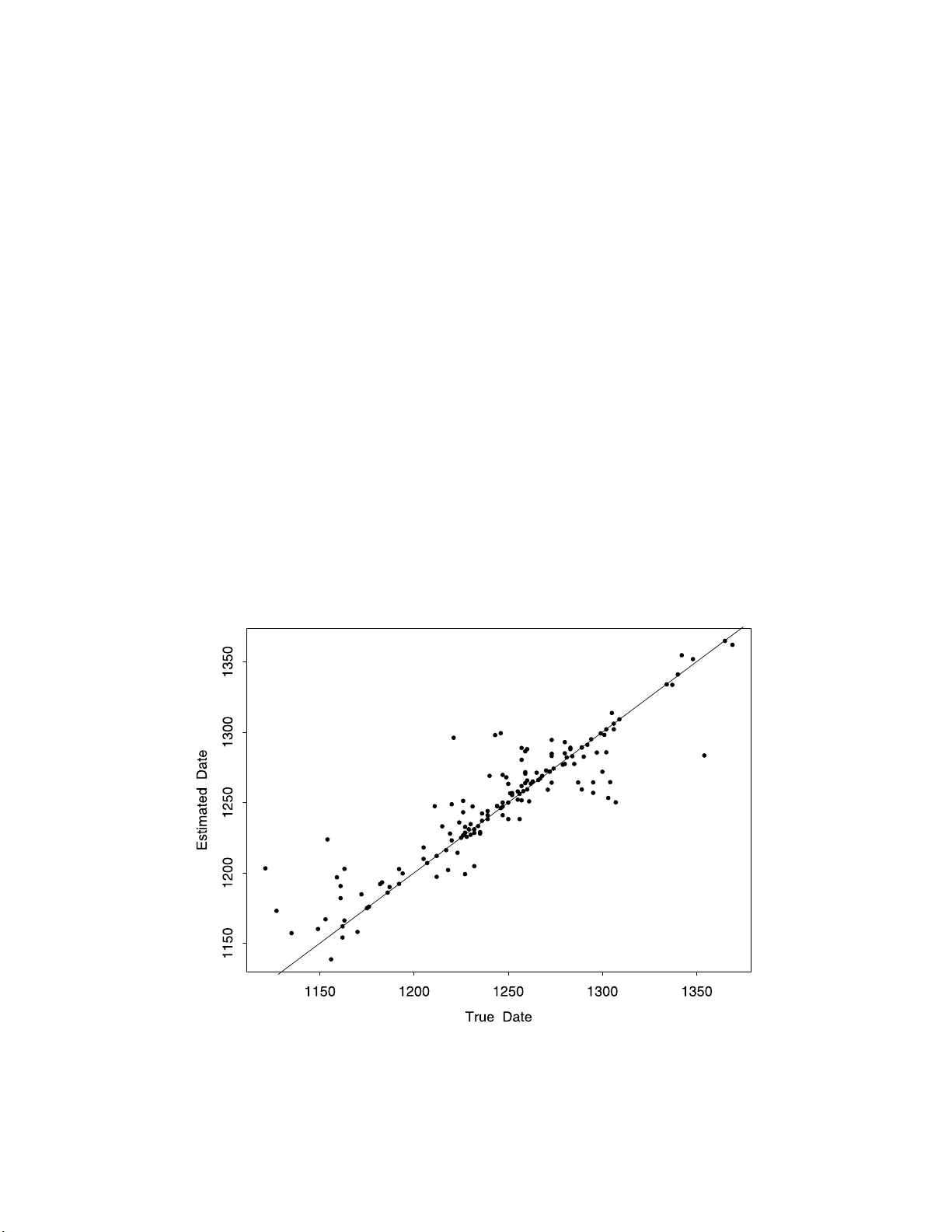
IMS Collectio ns Beyond P arametri cs in In terdisciplinary Research : F estsch rift in Honor of Professor Pranab K. Sen V ol. 1 (20 08) 321–331 c Institute of Mathematical Statistics , 2008 DOI: 10.1214/ 193940307 000000248 Using statistical smo othing to date mediev al man us cripts ∗ Andrey F euerv erger 1 , P eter Hall 2 , Gelila Tilah un 3 and Micha el Gerv ers 4 University of T or onto, Univ ersity of Melb ourne, University of T or onto and University of T or onto Abstract: W e discuss the use of multiv ariate kernel smo othing methods to date manusc ripts dating from the 11th to the 15th cent uries, in the English coun t y of Essex. The dataset consists of some 3300 dated and 5000 undated man uscripts, and the former are used as a training sample for imputing dates for the latter. It is assumed that tw o manuscripts that are “close”, in a sense that may be defined by a vec tor of measures of distance f or documents, wi ll ha v e close d ates. Using this approac h, statistical ideas are used to assess “sim- ilarity”, by smo othing among distance measures, and th us to estimate dates for the 5000 undated man uscripts b y reference to the dated ones. 1. In troductio n The problem of searching for, and comparing, documents on the world wide web has motiv a ted the dev elopmen t of t echniques for mea suring the “rela tio nships” among do c uments. These metho ds include appro aches based on fo rmal measures of distance (see e.g . the collections o f pap er s edited by Ber ry [ 1 , 2 ] and Djeraba [ 6 ]), as well a s more statistical tec hniques (see e.g. Cutting et al. [ 5 ]). A brief review of the litera ture, in a sta tistica l context, ha s b e e n g iven by F euer verger et al. [ 7 ]. The present article builds on the latter paper , by giving relatively detailed accounts of the application of kernel-smo othing methods to the da ting, o r ca lendaring as it is often called, of mediev al manuscripts. These manuscripts ar e charters written b etw een the 11th and the 1 5th centuries. They re la te to prop erty holdings o r transfers in the count y of Esse x , England. Many were taken fr om ent ries in the Hospital ler Cartulary of 1442 and are essent ially land deeds inv o lving the Order of the Hospital of St John o f Jerusalem (Gerv ers [ 11 ]). The Order, which works internationally today in hea lthcare, originated in the 11th century as a monastic brotherho o d caring for pilgrims in the Holy Land. The dated ma nuscripts ar e part of a database assembled at the Univ ersity of T or onto in ∗ Supported in part b y the Natural Sciences and Engineering Research Council of Canada. 1 Departmen t of Stat istics, Universit y of T oronto, 100 St. George Street, T oronto , Onta rio, Canada M5S 3G3, e-mai l : andrey@u tstat.tor onto.edu 2 Departmen t of Mathematics and Statistics, University of Melb ourne, Melb ourne, VIC 3010, Australia, e-mail : p.hall@m s.unimelb .edu.au 3 Departmen t of Stat istics, Universit y of T oronto, 100 St. George Street, T oronto , Onta rio, Canada M5S 3G3, e-mai l : gelila@u tstat.tor onto.edu 4 Departmen t of Hi story ETC., Universit y of T oront o, 100 St. G eorge Street, T oronto , O ntario, Canada M5S 3G3, e-mai l : 102063.2 152@compu serve.com AMS 2000 subje ct classific ations: Primar y 62G99, 62P99; s econdary 62-07, 62H20. Keywor ds and phr ases: bandwidth, calendaring, dating, deeds, document, k ernel, resemblance distance, shi ngle. 321 322 A. F euerver ger et al. connection with the DEEDS (Do cuments of Esse x England Data Set) pro ject, and are discussed by Gervers [ 10 , 12 , 13 ]. In this pap er we interpret the dates of unda ted do cuments a s missing com- po nent s of ra ndom data vectors of indeterminate length, and impute them using nonparametric, kernel-based regressio n in which the explanator y v ariables are inter- do cumen t distances. Sections 2, 3, 4 and 5 resp ectively discuss measures o f distance, methodo logy for smo othing empirical distances, applications of these techniques to manuscript data, and theo r y relating to Section 3. 2. Shingles, resemblanc es and distances Mathematical formalisatio n of a manuscript pro ceeds as follows. Remov e all punc- tuation from the manuscript. The do cument that remains is a sequence of n , s ay , words, with repetitions counted as different w ords. W rite this sequence as M = ( w 1 , . . . , w n ). A consecutive sequence of k words, i.e. S = ( w t +1 , w t +2 , . . . , w t + k ) where 0 ≤ t ≤ n − k , is called a shingle of or der k . Let S k ( M ) = { S k 1 , . . . , S k,N ( k ) } , where 1 ≤ N ( k ) ≤ n − k + 1, deno te the set of distinct shingles of or der k obta ina ble from the ma n uscript M . If M i and M j are t w o m anuscripts then the mathematical intersection of S k ( M i ) and S k ( M j ) is the set o f differen t shingles of order k that are contained in b oth manuscripts. B r o der et al. [ 3 ] and Bro der [ 4 ] in tro duced the notion of the k th or der r esemblanc e distanc e , d k ( i, j ), b etw een M i and M j . It is the prop o r tion o f shingles , out of the set of all k th order shingles in M i and M j , that are not contained in bo th M i and M j . It can b e defined mathematically as d k ( i, j ) = 1 − kS k ( M i ) ∩ S k ( M j ) k kS k ( M i ) ∪ S k ( M j ) k , where k S k denotes the n um ber of element s of a finite set S . W e shall denote b y res k ( i, j ) = 1 − d k ( i, j ) the k th o rder resemblance. 3. Smo othing step W e work with r -vectors o f res em blance distances . In particular , the k th compo nent of the vector descr ibing the distance b etw ee n M i and M j is d k ( i, j ), for 1 ≤ k ≤ r . Thu s, it is assumed that resemb lance distances, of orders up to the r th, capture the principa l ways in which manuscripts differ. Ther e may , howev er , b e sig nificant information from other, order e d v a riables s uch as do cument length or the simple fre - quencies of certa in key w ords. These could also b e incorp or a ted in to o ur smo othing algorithm, by ma king obvious changes to the metho dology discussed below. Cate- gorical v ariables such a s do cument “type”, for example whether the do cument is a marriag e contract o r a land deed (in the c o nt ext of Latin manuscripts discussed in Section 4), are a rguably b est included by smo o thing w ithin the resp ective type. If manuscript M i is undated, and manu scripts M j , for j ∈ J , have res pec- tiv e known dates t j , then the kernel weigh t a pplied to M j , based on its nearness to M i , is a ( i, j ) = a ( i, j | h 1 , . . . , h r ) = r Y k =1 K { d k ( i, j ) /h k } , Dating me dieval manuscripts 323 where K denotes a nonneg ative, nonincreasing function defined on the po sitive half-line, and h 1 , . . . , h r are bandwidths. Our estimator, ˆ t i of the date t i of M i is ˆ t i = arg min X j ∈J ( t j − t ) 2 a ( i, j ) = X j ∈J t j a ( i, j ) X j ∈J a ( i, j ) . (3 . 1) Theoretical prop er ties of this estimator will b e discusse d in Section 5. There is precedent in the field of manuscript dating for using robust methods. In this context one could minimise the loss function P j ∈J Ψ( t j − t ) a ( i, j ), where Ψ is a p ositive, symmetric, “ c up shap ed” function with its unique minimum at the origin and increa sing no fa s ter than linear ly in its tails. This leads to the estimator t = ˆ t i that solves X j ∈J ψ ( t j − t ) a ( i, j ) = 0 , where ψ = Ψ ′ . T aking Ψ( u ) ≡ | u | we obtain the lo cal median. See H¨ ardle and Gasser [ 14 ] for discuss io n of ro bust nonparametric metho ds in a univ a riate setting. T o choose ba ndwidths, define ˆ t j ′ = ˆ t j ′ ( h 1 , . . . , h r ) ≡ a r g min t X j ∈J , j 6 = j ′ ( t j − t ) 2 a ( j ′ , j | h 1 , . . . , h r ) , ( ˆ h 1 , . . . , ˆ h r ) = arg min ( h 1 ,...,h r ) X j ′ ∈K t j ′ − ˆ t j ′ ( h 1 , . . . , h r ) 2 , where K is the union, ov er 1 ≤ k ≤ r , of the s et of a ll j ∈ J suc h that d k ( i, j ) is among the m larg est v a lues o f that quantit y . Her e m would give an appro priately small fraction of the to ta l n umber of dated manuscripts. Our empirical choice of the bandwidth vector is ( ˆ h 1 , . . . , ˆ h r ). This metho d is a for m of predictive cro s s- v alidation. See F euer verger et al. [ 7 ] for discussion of re finements. 4. Application to Latin man uscript data 4.1. The dataset, and appr o aches to c alendari ng A t the time of writing this pap er, the s e t of dated manuscripts consisted of 3 353 charters written in the 11th, 12th, 13th, 14th a nd 1 5th centu ries. In addition there were some 500 0 undated manuscripts. An exa mple o f a dated manuscript is giv en in the App endix. The term “ dated” ab ov e is use d in an informal s e ns e, and do es not imply that a dated manuscript alwa ys had an exa ct da te wr itten upon it. Indeed, the ma jor - it y of dated manuscripts are calendar ed by internal evidence, and inaccuracies are sometimes present. Gervers [ 12 ] details the nature a nd po ten tial size of these errors ; discrepancies of the order of several generations are p oss ible. Witness names are one source of internal evidence, but iden tical witness names app ea r on manuscripts that could not po ssibly hav e b een witnessed by the sa me per son, and sometimes o n manuscripts dated 1 00 years or more a part. See, for example, Rees ([ 15 ], p. xvii). F urthermore, witness names can b e truncated, making them hard to identify reli- ably; o r the names ma y b e omitted altogether. Handwriting evidence can also b e used for dating, but it to o has dr awbac ks (e.g. Stenton [ 17 ], p. xxxii). In cases where reliable int ernal dating is not p ossible, use can be made of the fact that the lang uage, form and co nten t of mediev al manuscripts is constantly changing 324 A. F euerver ger et al. with time (e.g. Sten ton [ 17 ]). This “ dating b y formulae” approach, as it is sometimes called, is o utlined by Gervers [ 12 , 13 ] in co nnection with the DEEDS manuscripts pro ject. See also Fiallos [ 8 , 9 ], who descr ibes so me a lgorithms for dating. Both Fiallos and Gervers r efer to a “shingle” a s a “word pattern” o r “s tr ing”; the term “shingle” w as intro duced b y B ro der [ 4 ]. The tec hniques discussed by Gerv ers are substantially more interactive, and more demanding of ex per t historical knowledge, than automated-statistical approa ch es such as those suggested in the pr esent pa per . While this ma y enhance accura c y in s o me ca ses, it makes the metho dology difficult to transfer to other applications. 4.2. D ata analysis Figure 1 shows a histogr am giving the distributions of dates for the full dataset, of size 33 5 3. T he da tes range from 1089 to 14 66, and are seen to b e more concentrated tow a r ds central v alues. By means of random sampling these do cuments were divided in to three disjoint groups. The fir st gro up, consisting of 3034 do cuments, served as a training set; the seco nd, of 167 do cuments, was used for v alidation; and the third, of 152 do cuments, was set as ide to serv e as a test set. The decisio n to set aside a v alidatio n subset, ra ther than us e leave-one-out v alidation, was made to reduce computational lab o ur . B elow we r e p o r t results obtained using resemblance distance; see Section 2 for a definition. Througho ut we employ ed the exp onential kernel, K ( x ) = e − x . W e exp erimented with shingles of sizes one, t wo and three, as well as with a ll combinations of these sizes. With ev ery such com bination we v a ried the v a lue of m , in troduced in Sec tio n 3 a nd defined as the num b er of “clo sest” charters to be included in the w eighted es timation pro cedure, ov er the range m = 5 , 10 , 20 and 50. Optimisation ov er h was done by searching ov er a fine grid. The “shingling ” of charters into lists of unique sequences of co nsecutive words, the matc hing of shingles among charters, the computation of distances b et ween them, and the estimation of dates, were car r ied out emplo ying C and sta ndard UNIX commands. Using shingle sizes grea ter than three was ruled out, to limit the a mount of computation required and also in light of the findings rep orted b elow. In this s ection, so as to describ e the effects o f different s hingle sizes, we shall present r esults in the Fig 1 . Histo gra m of the dates for the c omplete dataset. Dating me dieval manuscripts 325 setting of univ ar iate smo o thing ov er resemblance distances. That is, we to ok r = 1 in the setting of Section 3, a lthough that single co mpo nent w as any o ne of d 1 ( i, j ), d 2 ( i, j ) and d 3 ( i, j ); the particular v alue will be ma de clear in discussion. T aking r = 3 pro duces results which hav e prop erties resembling an “av erage” of those discussed b elow. T o conv ey a broa d impression of statistical pro per ties of the data we men tion that the total num ber of resemblance v alues amo ng the v alidation and training manuscripts was 167 × 3034 = 506 , 6 78. The mean v alues were 0.083 , 0.014 and 0.0042 for shingles o f size k = 1, 2 and 3, res pec tively . The pairwise correlations betw een the 506,678 resem blance v alues, for resem blances ba sed on shingle siz e s k = 1 , 2 and 3, were 0.93 b et ween shing le sizes 2 and 3, 0.8 8 betw een shingle sizes 1 and 2, and 0.76 betw een shingle s izes 1 a nd 3. Res em blance v alues can occ asionally be quite large; they exceeded 0.5 a total of 14, 7 and 4 times among the r e s emb lances based on shingle sizes 1, 2 and 3 , resp ectively . Note to o that the mean year of the training do cuments was 1 245.8. If this v alue w ere used as the date estimate for each do cumen t in the v alidation set, the mean absolute erro r would b e 36.6 years. F or shingles o f size k = 1, and using r esemblance distance, the optimal v alue of ( m, h ) was fo und to b e approximately (10 , 9 . 0 × 10 − 3 ). (The small v a lues fo r bandwidth, here and b elow, re flec t small v a lues of re s emb lance.) These choices resulted in an av erage absolute difference b etw een true and estimated dates for charters, within the v alidatio n set, of 13.1 y ears. When o nly the closest m = 5 charters were used the av er a ge erro r only increased slightly , to 13.2 years, while m = 20 and m = 50 resulted in a verage absolute errors o f 13.2 a nd 13.3 years, resp ectively , when each w as used in conjunction with its corresp onding o ptimal bandwidth. As c a n be seen, the results are quite ro bust aga inst choice of m . Note, how ever, that for a particular v a lue of m , and for a given charter in the v alidation set, it ca n o ccasionally happ en that there are fewer than m charters (in the training set) that hav e nonzero resemblance to it. When that o ccurred, only those charters having nonzero resemblances were included in the estimation pro cedure. In this sense the effective v alue o f m could o cca sionally b e s maller than its nomina l v alue, particularly when m was la rge. The r esults are also ro bust a gainst v arying h . F or example, in the o ptimal case, m = 10, the av e r age error s tay ed b elow 13 .2 years provided h remained in the range (6 . 9 × 10 − 3 , 1 . 1 × 1 0 − 2 ). In these instances, as in other results cited b elow, the mea n absolute error functions were inv ar iably well behav ed as h and m v a ried, and had clear ly defined (if somewhat broad) minima. No insta nces o f separated m ultiple minima were discov ered during our e x per iment ation. Figure 2 shows a gr ey-scale “image” plot of shingle- size k = 2 resemblances betw een the 1 67 v alidation manu scripts (on the vertical a xis) and the training manuscripts (on the horizontal a xis). In pr o ducing this plot, the man uscripts on each ax is were first order ed fro m earlies t date to latest, and res e mblance v alues exceeding 0.3 were s et equal to 0.3, while v a lues b elow 0.1 were set equal to zer o. The training manuscripts were then gr oup ed, w ith five consecutive manuscripts in each of 60 6 groups, a nd the resem blance v alues were averaged for ea ch v alidation manuscript within ea ch tr aining gr oup. These v alues were then norma lized so that the maxim um v alue for each v a lidation man uscript w as equal to one. Finally , re- sulting v alues at or b elow 0.8 were set equal to “white,” while the v alue 1.0 was s et equal to “black;” a linear gr ey scale was used betw een these v alues. The roughly di- agonal character of this display mir rors the tendency for do cuments to hav e higher resemblance v a lues with other do cuments of c omparable dates. The wide scatter 326 A. F euerver ger et al. Fig 2 . Gr ey-sc ale plot of shingle-size 2 r esemblanc es b et we en the validation and tr aining manuscripts. evident in the display also serves to emphasize the inherent difficulty o f the problem. F or shingle s of size k = 2, and using the res em blance measur e , the optimal v alue of ( m, h ) was (5 , 6 . 7 × 1 0 − 3 ), giving a mean a bsolute error of 11.1 years. The mean abso lute er ror stay ed b elow 11.2 years provided h r emained in the rang e (5 . 1 × 10 − 3 , 9 . 5 × 10 − 3 ). When m increased to 10 or to 5 0 the b est mean abso lute error increased to 11.6 or 11.7 y ears, resp ectively . O nce aga in, results are seen to be robust aga inst choice o f m . Analogously , for shingles of size k = 3 the optimal v alue of ( m, h ) was (10 , 2 . 0 × 10 − 3 ), g iving a mean absolute er ror of 1 2.1 years. F or m = 5 and m = 50 the er ror was 12.4 and 12.2 years, resp ectively . W e also ex per iment ed with using resemblance measur e s for pairs of shingle sizes, employing biv ar iate kernels that w ere pro ducts of univ ariate kernels. W e found that whenever shingle size k = 2 was included in a pair the optimisation attempted to eliminate the effect of the other shingle size (1 or 3 ) by a ssigning to it a relatively high (or even infinite) ba ndwidth. In consequence the results w ere virtually ident ical to those achiev ed using shingle size 2 a lone: the minim um error achiev ed using shingle sizes 1 and 2 simultaneously was 11 .2 years, and was achiev ed with m = 5, while for shingle s izes 2 a nd 3 together it was 11.1 years and also o ccurre d with m = 5 . By way of contrast, for shingle sizes 1 and 3 tog e ther the optimal e r ror w as 11.8 years and was attained with ( m, h 1 , h 3 ) = (10 , 0 . 0024 , 0 . 05), where h j denotes the bandwidth applied to shingle size j . (Note that when more than one shingle size is used, the effective v alue of m typically is somewhat increa sed, since the union is taken of the m clo sest do cuments for ea ch shingle size.) The r esult for using a ll three shingle size s (1, 2 and 3) simultaneously was simi- Dating me dieval manuscripts 327 lar to tha t when using shing le size 2 alone, or using pairs of shingle sizes including size 2: minimu m mean absolute err o r was achiev ed with m = 5, a nd was 11.2 y ears. Considering this and the previo us r esults, it is seen that the b est a mo ng the pr o ce- dures discusse d so far is to use only the resemblance distance based o n shingles of size 2, taking ( m, h ) = (5 , 6 . 7 × 10 − 3 ). Finally , to obtain independent verification of the claimed error rate, this pro cedure w as a pplied to the 152 do cuments in the test set; the mea n absolute err or w as found to be 12 .2 years. The apparent difference betw een the er ror rates for the v alidation and test subsets is consistent with the bias due to having selected the b est of several pro cedures, with the somewhat sma ll sample sizes of these subsets, and with the fa c t that (due to ra ndo m sa mpling) the manuscripts in these subsets had slightly different distributions of dates a nd word- counts. Figure 3 shows the true da tes for manu scripts in the test set, together with their estimated dates. (The zero error line is also superimp os e d.) V ery s light bias effects are discernible at the edges due to the fact that for such manuscripts closest matches canno t exist at more extreme da tes. It is also seen tha t manuscripts near the central date ranges ar e estimated slightly mor e accur ately , in part owing to the av ailability of many mor e training man uscripts in the cent ral date ra nges (though there is also some c o unt erv ailing influence, since the presence of more do cuments at a ce r tain date slightly biases the s e lec tion o f clo s est fitting manuscripts to that date). The size of a do cument b eing dated was also found to hav e a mo dest influ- ence on how accurately it could b e dated. V ery larg e do cument s app ear to have been dated somewhat more accurately than others, but v ery small documents w ere not, in genera l, dated inaccurately; indeed, the claimed mean absolute error rate app ears to b e quite g enerally applicable overall. (V ersio ns of Figure 3 in w hich dot Fig 3 . T rue and estimate d dates f or manuscripts i n the test set with the zer o err or line sup erim- p ose d. 328 A. F euerver ger et al. sizes v arie d to reflect manuscript size did no t prov e to b e infor mative.) Finally , we mention that similar detailed numerical studies were also conducted for o ther definitions o f distance discussed by F euerverger et al. [ 7 ]. In each of these cases, the results obtained w ere br oadly similar to those for resemblance distance, with shingles of size 2 alo ne aga in being the apparent ly optimal c hoice on whic h to base the estimation pro cedure s . F or these distances, the optimal mean abso lute errors obtained all turned out to b e slightl y larger than that ac hieved using the resemblance distance. 5. Theoretical prop erties of k ernel imputation Let M 0 be a particular undated man uscript, written at a time t 0 , a nd let ( M 0 , M ) denote the v alue o f the pair ( M i , M j ) when M i = M 0 and M j = M is a ran- domly chosen, dated manuscript. W r ite ∆ ℓ for the cor r esp onding v alue o f d ℓ ( i, j ). Although the nu mbers of words in bo th a man uscript a nd a dicti onary are finite, they ar e p o tentially so lar ge that v alues o f d ℓ ( i, j ) are virtua lly distributed in the contin uum. Therefore it is appropria te to mo del the joint distribution of the date T of a manuscript M , and the distances ∆ ℓ , b y that of a vector ( T , ∆ 1 , . . . , ∆ r ) distributed in the co nt inuu m within the r egion (0 , ∞ ) × [0 , 1] r . In this setting our k ernel method for estimating the unknown da te t 0 is con- sistent if the following t wo a s sumptions are s atisfied: (a) the mean v alue of T , ev aluated when the distances ∆ 1 , . . . , ∆ r are in arbitra rily s mall neighbourho o ds of 0, co n verges to t 0 as those neighbour ho o ds shrink to 0; a nd (b) the mea n square of T , ev aluated in the same cont ext, r emains b ounded. The first of these conditions is one of “asymptotic un biasedness” of the da te of a random man uscript M , as the distances b etw ee n M a nd the fixed manuscript M 0 conv e r ge to 0. The second condition is a co mmon a ssumption of finite v ariance. Resp e c tively , these tw o conditions may b e stated for ma lly as E { T I (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) } P (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) → t 0 (5 . 1) as δ 1 , . . . , δ r → 0, and E { T 2 I (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) } P (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) (5 . 2) remains b ounded as δ 1 , . . . , δ r → 0. Ass ume in addition that for each c > 1, lim sup δ 1 ,...,δ r → 0 P (∆ 1 ≤ c δ 1 , . . . , c ∆ r ≤ δ r ) P (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) < ∞ ; that the kernel K is b ounded, contin uous , compactly supp or ted a nd nonincreasing on the p ositive real line; that K ( x 0 ) > 0 for s ome x 0 ≥ 0; that the dated manuscripts {M j , j ∈ J } are indep e ndent a nd identically distributed as M ; that the num ber N ( J ) of elemen ts of J is allow ed to increase to infinity; and that at the same time as N ( J ) increases, the bandwidths h 1 , . . . , h r decrease to 0, but so slowly that N ( J ) P (∆ 1 ≤ h 1 , . . . , ∆ r ≤ h r ) → ∞ . (5 . 3) Let C denote the set of all c o nditions stated in this par agra ph. Theorem 5.1. If C holds then the estimator ˆ t i define d at (2 . 1) c onver ges in pr ob- ability to the true date of the undate d manu script M 0 . Dating me dieval manuscripts 329 Under mo re refined conditions, prop erties o f bias a nd v ariance may b e derived. In particular it may b e shown that v ariance is gener ally of order { N ( J ) h 1 . . . h r } − 1 and bias of order max( h 2 1 , . . . , h 2 r ), and that the estimator is asymptotically Nor- mally distributed. T o der ive the theor em, note that for each ǫ > 0, any k ernel K that satisfies conditions C may b e sandwic hed b et ween tw o kernels K 1 and K 2 , with the pro p- erties: (a) K 1 ≤ K ≤ K 2 , (b) K 2 ( x ) − K 1 ( x ) ≤ ǫ for all x , and (c) K 1 and K 2 are each expressible as finite, p ositive linear combinations of functions of the form L ( x ) = I (0 < x ≤ c ), wher e c > 0. W e first derive the theor em in the case K = L . Define A = P j ∈J t j a ( i, j ), B = P j ∈J a ( i, j ), δ ℓ = c h ℓ , δ = ( δ 1 , . . . , δ r ) and π ( δ ) = P (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ). Then by (5.1) and (5.2) w e hav e in the case K = L , E ( A ) = N ( J ) E { T I (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) } = { t 0 + o (1) } N ( J ) π ( δ ) , v ar( A ) ≤ N ( J ) E T 2 I (∆ 1 ≤ δ 1 , . . . , ∆ r ≤ δ r ) = O { N ( J ) π ( δ ) } , E ( B ) = N ( J ) π ( δ ) and v ar( B ) ≤ N ( J ) π ( δ ). It follows from these r esults and (5.3) that A/ { N ( J ) π ( δ ) } → t 0 and B / { N ( J ) π ( δ ) } → 1, b oth convergences b eing in probability . Therefor e A/B → t 0 in probability , a s had to b e shown. Finally we treat a more genera l kernel satisfying c onditions C. Using the prop- erties no ted t wo pa r agra phs ab ov e we may deduce from the results for K = L in the previous par agra ph that for each ǫ > 0, E ( B ) { t 0 − ǫ + o (1) } ≤ E ( A ) ≤ E ( B ) { t 0 + ǫ + o (1) } , v ar( A ) + v a r( B ) = O { E ( B ) } , E ( B ) ≍ N ( J ) P (∆ 1 ≤ h 1 , . . . , ∆ r ≤ h r ) . Again these res ults imply the desired prop erty A/B → t 0 . App endix A: T ypical dated man uscript from database Doc umen t 006402 14, as it app ears in the databa se, is given b elow. The manu- script’s date, 12 37 AD, is part of its header. All punctuation mar ks hav e b een remov ed, a nd num b ers (in Roman numerals) are given b etw een exclamation mark s. Each num b er is replaced by s imply “ #” be fo r e shingling, so different nu mbers a re not distinguished. How ev er, s hingling distinguishes capitalised fro m non-capitalised words; for exa mple, “ regis” is regar ded as different from “ Regis”. 00640214 1237 Hae c est finalis co nc or dia f act a in curia domini r e gis apud Westmonasterium a die S Johannis Baptistae i n !xv! dies anno r e gni r e gis He nrici filii r e gis Johannis !xxi! c or am R ob erto de L exinton Wil lelmo de Eb or ac o A da filio Wil lelmi Wil lelmo de Culewurth justit iariis et aliis domini r e gis fidelibus tunc ibi pr aesentibus inter Jo- hannem Baio c quaer entem et R ob ertum Sarum episc opum et ca pitulum defor c i antes p er R adulfum de Haghe p ositum lo c o ipsorum ad lucr andum vel p erd endum de advo- c atione e ccl esiae de Waye Bayouse unde assisa ultimae pr aesentationis summonita fuit inter e os in e adem curia scilic et q uo d pr ae dictus T r e c o gnovit advo c ationem pr ae dict ae e c clesiae cum p ertinentiis esse jus ipsorum e pisc opi et c apituli et e ccle- siae suae Sarum ut il lam quam idem episc opus et c apitulum Sarum hab ent de dono Al ani de Baio cis p atris pr ae dicti Johannis cujus haer es ipse e st e t idem episc opus et c apitulum pr ae dictum co nc esserunt pr o se ob suc c essoribus suis eidem Johanni ut eidem e c clesiae quotiescunque t ota vita ipsius e am vac ar e c ontigerit p ossit idone am 330 A. F euerver ger et al. p ersonam pr aesentar e ita quo d quicunque pr o temp or e fuerit p ersona ejusdem e c- clesiae ad pr aesentationem ipsius Joha nnis r e ddet singulis annis pr ae dictis episc op o et c apitulo sex mar c as ar gent i de pr ae dicta e c clesia apud Sarum nomine p ensionis scilic et ad festum S Michaelis !xx ! solidos ad Natale D omini !xx! solidos ad Pascha !xx! solidos ad nativitatem b e ati Joha nnis Bap tistae !xx! solidos et p ost de c essum ipsius Johannis advo c atio pr ae dictae e c clesiae cum p ert inentiis r emanebit pr ae dictis episc op o et c apitulo Sarum et e orum suc c essoribus q uieta de haer e dibus ipsius Johan- nis in p erp et uum Et pr aeter e a idem episc opus et c apitulum pr ae dictum c onc esserunt pr o se et suc c essoribus suis quo d ipsi de c aeter o invenient unum c ap el lanum divina c elebr antem singulis diebus anni in c ap el la b e ati Johann is sita infr a p ar o chiam de Waye pr o anima pr ae dicti Johannis et pr o animabus haer e dum suorum et ante c es- sorum suorum et pr o cunctis fidelibus in p erp etuum et idem episc opus et c apitulum pr ae dict um et suc c essor es sui invenient ornamenta libr os et luminaria sufficientia in e adem c ap el la in p erp etuum References [1] Berr y, M. W. (2001). Computational Information R etrieval . SIAM, Philadel- phia. MR18618 11 [2] Berr y, M. W. (2003 ). Survey of T ext Mining: Clustering, Classific ation, and R etrieval. Spr ing er, New Y ork. [3] Broder, A. Z. , Glassman, S. C., Manasse, M. S. and Zweig, G. (19 97). Synt actic clustering of the web. SRC T echnical Note No. 19 97-01 5, Digital Equipment Cor po ration. In Pr o c e e dings of the Sixth International World Wide Web Confer enc e 391–4 04. [4] Broder, A. Z. (1998). On the r esemblance and containmen t of do cuments. In 1997 International Confer enc e on Comp r ession and Comp lexity of S e quenc es (SEQUENCES ’97) , June 11–1 3 1997 , Positano, Italy , 21– 29. IEEE Computer So ciety , Los Alamitos, California. [5] Cutting, D. R. , Karger, D. R., Pedersen, J. O. and Tukey, J. W. (1992). Scatter/g a ther: a cluster-based a pproach to browsing larg e do c ument collections. In Pr o c. Fifte ent h Annual International ACM SIGIR Confer en c e on R ese ar ch and Development in Information Retriev al , Cop enhage n, Den- mark, J une 21– 24 1992 (N. J. Belkin, P . Ingwersen and A. M. Pejtersen, eds.) 318–3 29. Asso ciation for Co mputing Machinery , New Y or k. [6] Djeraba, C. (2002). Multime dia Mining – A H ighway to In tel ligent Multime- dia Do cument s . K luw er, Boston. [7] Feuer ver ger, A., H all, P., Tilahun, G. and Ger vers, M. (200 5). Dis- tance mea sures and smo othing metho do logy for imputing features o f do cu- men ts. J. Statist. Gr aph. St atist. 14 255 –262. MR21608 12 [8] Fiallos, R. (2 000a). An ov erview of the pro cess of dating undated mediev al charters: latest results a nd future developmen ts. In Dating Undate d Me dieval Charters (M. Gervers, ed.) 37– 48. Boydell P ress, W o o dbridge, UK. [9] Fiallos, R. (2000b). P ro cedure for dating undated do cuments using a rational database. Manuscript. [10] Ger vers, M. (198 9). The textile industry in Esse x in the late 12 th a nd 13th cent uries: A study ba sed on o ccupa tional names in charter s ources. Essex Ar- chaelo gy and History 20 3 4–73. [11] Ger vers, M. (1982 , 1 996). The Cartulary of the Knights of St. John of Jerusalem in England , Parts 1, 2. Oxford Univ. Press , London. [12] Ger vers, M. (20 0 0a). The DEEDS pro ject and the dev elopment of a comput- erised metho dology for dating undated English priv ate charters of the tw elfth Dating me dieval manuscripts 331 and thirteen th centuries. In Dating Undate d Me dieva l Charters (M. Gerv ers, ed.) 13–3 5. Boydell Pr ess, W o odbr idge, UK. [13] Ger vers, M. (2000b). The dating of mediev al English pr iv ate charters of the t welf th and thirteenth centuries. Ma n uscript. [14] H ¨ ardle, W. and Gasser, T. (1984). Robust no npa rametric function fitting. J. R oy. Statist. So c. Ser. B 46 , 42–51 . MR07452 14 [15] Rees, U. (197 5). The Cartulary of Shr ewsbury Abb ey 1 . Ab e r ystwyth. [16] Rabin, M. O. (1981). Fingerprinting by r andom poly no mials. Rep ort TR-15- 81, Center for Resea rch in Computing T echnology , Ha r v ard Univ. [17] Stenton, F. M. (192 2). T r anscripts of Charters r elating to the Gilb ertine Houses of Sixle, Ormsby, Catley, Bul lington, and Al vingham. Public ations of the Linc oln R e c or d So ciety for 1920 18 . Hor ncastle, UK.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment