중세 사료 연대 추정을 위한 다변량 커널 스무딩 기법
본 논문은 11세기부터 15세기까지의 영국 에식스 카운티 사료 3,300건을 학습 데이터로 삼아, 5,000건의 미연대 사료에 대해 다변량 커널 스무딩을 이용해 연도를 추정한다. 문서 간 유사도를 셰링(연속 단어열) 기반 거리로 정의하고, 거리 벡터에 커널 가중치를 부여해 가중 평균 또는 가중 중앙값으로 연도를 예측한다. 실험 결과 셰링 크기 2와 최적 밴드폭을 사용했을 때 평균 절대 오류가 약 11년 수준임을 확인했다.
저자: Andrey Feuerverger, Peter Hall, Gelila Tilahun
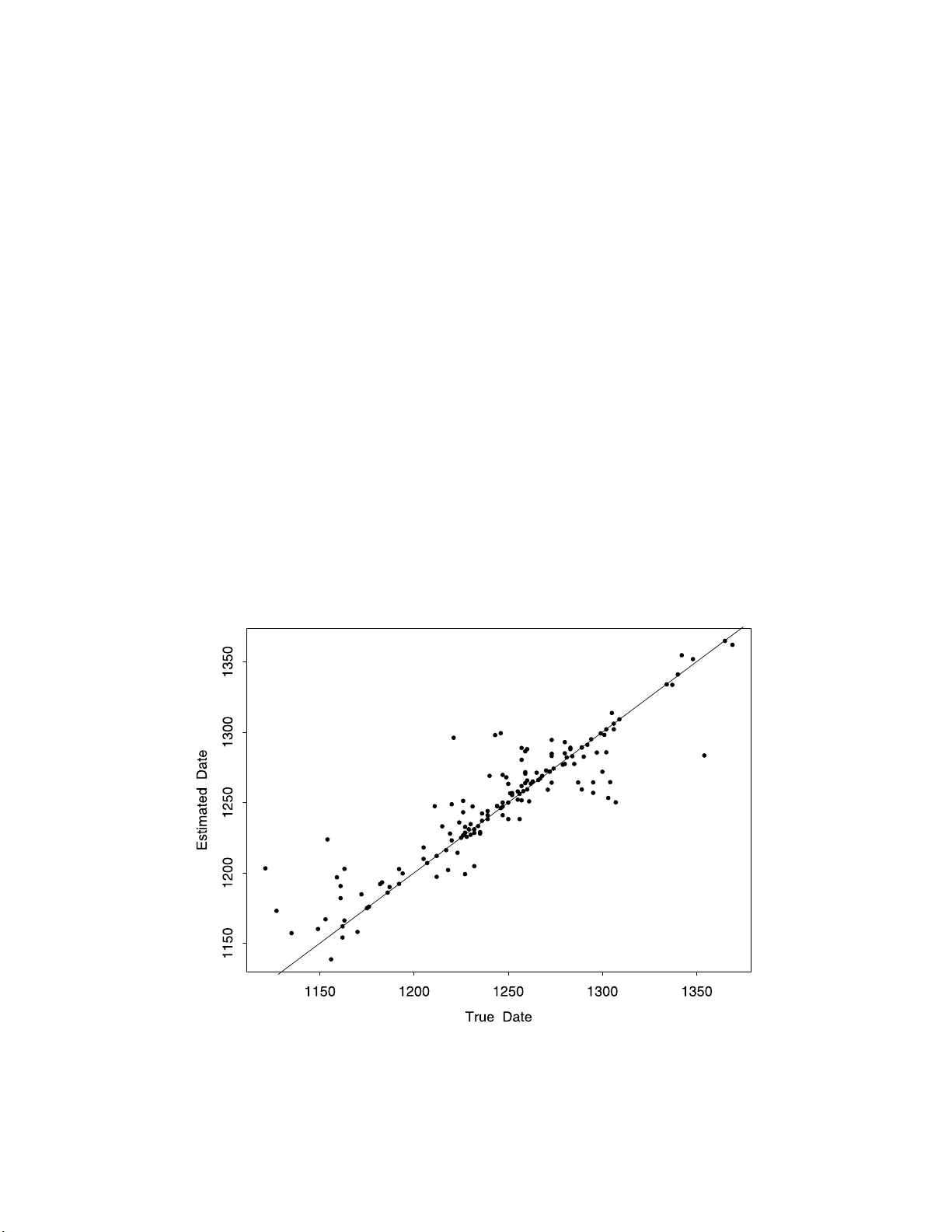
이 논문은 11세기부터 15세기까지 영국 에식스 카운티에서 작성된 중세 사료(주로 토지 증서)의 연대를 통계적으로 추정하는 새로운 방법을 제시한다. 연구팀은 총 3,353건의 연대가 알려진 사료와 5,000건의 연대가 알려지지 않은 사료를 확보했으며, 앞의 데이터를 학습용으로 활용해 후자의 연대를 추정한다. 핵심 가정은 “문서 간 거리가 가깝다면 연대도 가깝다”는 것으로, 이를 구현하기 위해 문서 간 유사도를 셰링(연속 단어열) 기반 거리로 정의한다.
먼저, 각 사료에서 구두점을 제거하고 단어 시퀀스를 만든 뒤, 연속 k개의 단어를 하나의 셰링으로 본다(k=1,2,3을 실험). 두 사료 i와 j 사이의 k‑order 셰링 집합 S_k(i), S_k(j)의 교집합과 합집합을 이용해 Jaccard 거리 d_k(i,j)=1‑|S_k(i)∩S_k(j)|/|S_k(i)∪S_k(j)| 를 계산한다. 이렇게 얻은 거리값들을 벡터 (d_1,…,d_r) 로 묶어 다변량 거리 공간을 만든다. 여기서 r은 사용한 셰링 크기의 수이며, 필요에 따라 문서 길이·키워드 빈도 등 추가 변수를 포함할 수 있다.
다변량 거리 벡터에 커널 스무딩을 적용한다. 각 성분에 대해 밴드폭 h_k 를 두고, 비증가 함수 K(x)=e^{‑x} 로 가중치 a(i,j)=∏_{k=1}^r K(d_k(i,j)/h_k) 를 정의한다. 이 가중치는 거리와 반비례해 감소하므로, 가까운 사료일수록 큰 가중치를 갖는다. 연대 추정은 가중 평균 ˆt_i=Σ_j t_j a(i,j)/Σ_j a(i,j) 로 수행한다. 로버스트 추정을 위해 가중 절대 손실을 최소화하는 가중 중앙값(ψ(u)=|u|)도 제안했으며, 이는 기존 비선형 비모수 회귀와 유사한 형태이다.
밴드폭 선택은 교차 검증 기반 최적화 절차를 사용한다. 검증 집합의 각 사료 j′에 대해 다른 사료 j들의 가중 평균을 이용해 ˆt_{j′}(h) 를 계산하고, 전체 검증 집합에 대해 Σ (t_{j′}‑ˆt_{j′})^2 를 최소화하는 (h_1,…,h_r) 를 찾는다. 이는 “예측 교차 검증”이라고 부를 수 있다. 또한, 가중 평균에 포함할 가장 가까운 문서 수 m을 조정해 모델 복잡도를 제어한다.
실험은 전체 데이터를 학습(3,034건), 검증(167건), 테스트(152건)로 무작위 분할했다. 셰링 크기 1,2,3을 각각 단독 및 조합으로 실험했으며, m과 h를 그리드 탐색했다. 결과는 셰링 크기 2가 가장 좋은 성능을 보였으며, 최적 파라미터는 m=5, h≈6.7×10⁻³ 로 평균 절대 오류(MAE) 11.1년을 기록했다. 셰링 크기 1은 구분력이 낮아 MAE가 13년 수준, 셰링 크기 3은 희소성 때문에 비슷한 수준을 보였다. 다중 셰링을 결합하면 최적 밴드폭이 다른 차원에 대해 무한대에 가까워지는 현상이 나타났으며, 실제 성능은 셰링 2 단독과 거의 동일했다. 검증 집합과 테스트 집합 모두에서 MAE는 11~12년 사이였으며, 이는 기존 내부 증거 기반 연대 추정(수십 년 오차)보다 현저히 개선된 결과다.
시각화(그레이스케일 이미지)에서는 검증 사료와 학습 사료 간 유사도가 대각선 방향으로 높게 나타나, 연대가 비슷한 사료끼리 유사도가 높다는 가정을 시각적으로 확인할 수 있었다. 또한, 연대가 가장 이른·가장 늦은 사료에서는 가장 가까운 매칭이 제한되어 약간의 편향이 관찰되었다.
논문의 한계로는 (1) 학습 데이터 자체가 내부 증거에 의존해 연대가 부정확할 수 있다는 점, (2) 라틴어 사료에만 적용했으며 다른 언어·문서 유형에 대한 일반화 검증이 필요함, (3) 거리 벡터에 추가 변수를 포함하면 차원 저주와 밴드폭 최적화 복잡도가 증가함을 들 수 있다. 향후 연구에서는 가우시안·트라이앵귤러 등 다양한 커널 형태와 적응형 밴드폭, 그리고 문서 길이·키워드 빈도 등 추가 특성을 통합해 성능을 더욱 향상시키는 방안을 모색한다.
결론적으로, 이 연구는 다변량 커널 스무딩을 이용해 중세 사료의 연대를 자동화·정량화하는 새로운 통계적 프레임워크를 제시했으며, 실험을 통해 평균 11년 수준의 오류로 실용적인 연대 추정이 가능함을 입증했다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기