A Principal Component Analysis for Trees
The active field of Functional Data Analysis (about understanding the variation in a set of curves) has been recently extended to Object Oriented Data Analysis, which considers populations of more general objects. A particularly challenging extension…
Authors: Burcu Aydin, Gabor Pataki, Haonan Wang
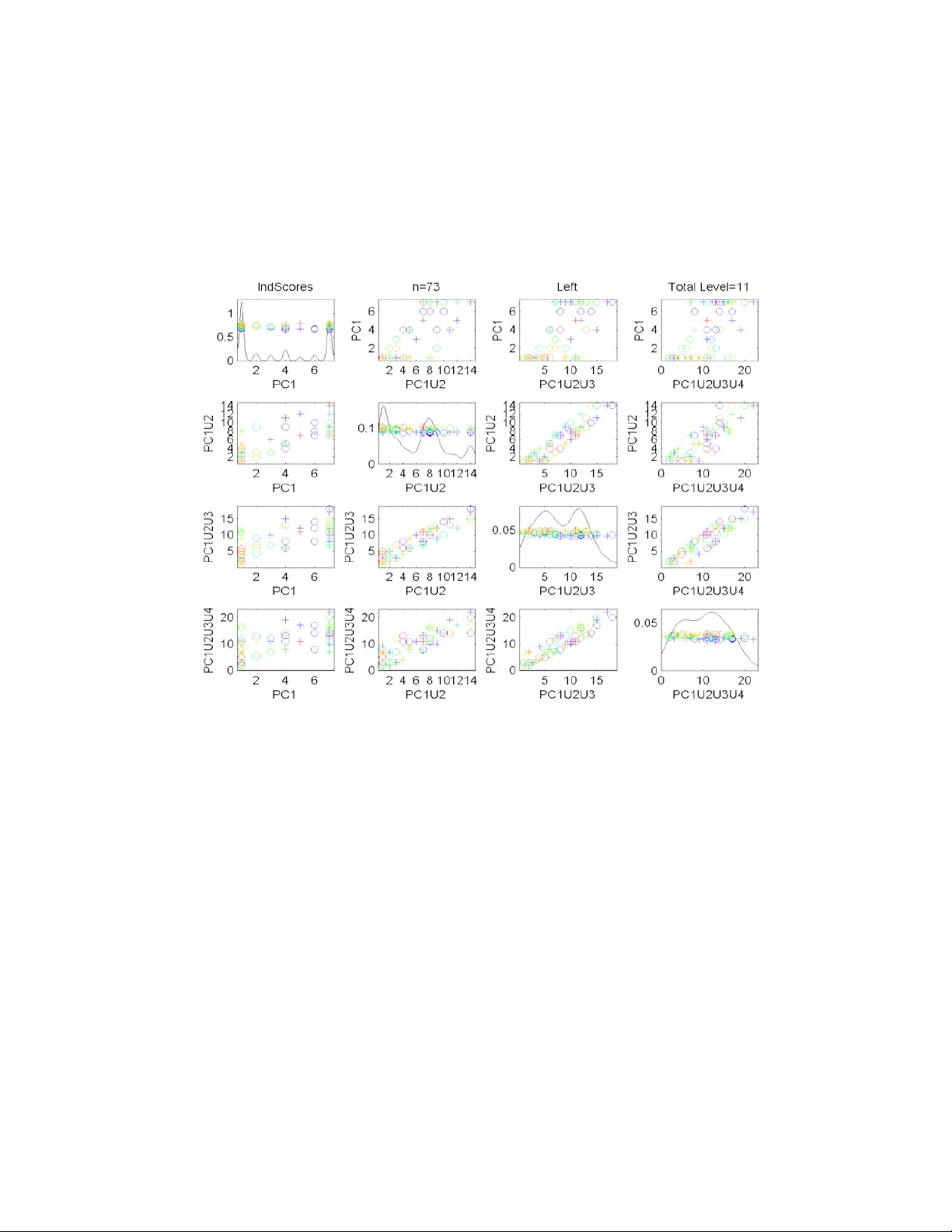
A PRINCIP AL COMPONENT ANAL YSIS F OR TREES By Burcu A ydın ∗ , G ´ abor P a t aki , Haonan W ang † , Elizabeth Bullitt ‡ and J.S. Marro n § University of North Car olina and Color ado State University The activ e field of F unctional Data Analysis (about understand- ing the v ariation in a set of curves) has been recently extended to Ob ject Orien ted Data Analysis, which considers populations of more general ob jects. A particularly challenging extension of this set of ideas is to populations of tree-structured ob jects. W e develop an ana- log of Principal Component Analysis for trees, based on the notion of tree-lines, and propose numerically fast (linear time) algorithms to solv e the resulting optimization problems. The solutions we obtain are used in the analysis of a data set of 73 individuals, where eac h data ob ject is a tree of blo od v essels in one p erson’s brain. 1. In tro duction. F unctional data analysis has b een a recen t active re- searc h area. See Ramsa y and Silv erman (2002, 2005) for a go od introduction and o v erview, and F erraty and Vieu (2006) for a more recent viewp oin t. A ma jor difference b et ween this approach, and more classical statistical meth- o ds is that curves are viewed as the atoms of the analysis, i.e. the goal is the statistical analysis of a p opulation of curves . W ang and Marron (2007) recently extended functional data analysis to Ob ject Orien ted Data Analysis (OOD A), where the atoms of the analysis are allo w ed to be more general data ob jects. Examples studied there include im- ages, shap es and tree structures as the atoms, i.e. the basic data elements of the p opulation of in terest. Other recent examples are p opulations of mo vies, suc h as are b eing sub jects of functional magnetic resonance imaging. A ma- jor contribution of W ang and Marron (2007) was the developmen t of a set of tree-p opulation analogs of standard functional data analysis techniques, suc h as Principal Com ponent Analysis (PCA). The foundations were laid via the form ulation of particular optimization problems, whose solution re- ∗ P artially supp orted by NSF grant DMS-0606577, and NIH Grant RF A-ES-04-008. † P artially supp orted by NSF grant DMS-0706761. ‡ P artially supported by NIH grants R01EB000219-NIH-NIBIB and R01 CA124608- NIH-NCI. § P artially supp orted by NSF grant DMS-0606577, and NIH Grant RF A-ES-04-008. AMS 2000 subje ct classifications: Primary 62H35, 62H35; secondary 90C99 Keywor ds and phr ases: Ob ject Orien ted Data Analysis, Population Structure, Principal Comp onen t Analysis, T ree-Lines, T ree Structured Ob jects 1 2 sulted in that analysis metho d (in the same spirit in whic h ordinary PCA can b e formulated in terms of optimization problems). Here the fo cus is on the challenging OOD A case of tree structured data ob jects. A limitation of the w ork of W ang and Marron (2007) was that no general solutions app eared to be av ailable for the optimization problems that were dev elop ed. Hence, only limited toy examples (three and four no de trees, which th us allow ed manual solutions) were used to illustrate the main ideas (although one interesting real data lesson was discov ered ev en with that strong limitation on tree size). One of our main contributions is that, through a detailed analysis of the underlying optimization problem, and a complete solution of it, a linear time computational metho d is no w av ailable. This allows the first actual OODA of a pro duction scale data set of a population of tree structured ob jects. Ideas are illustrated in Section 2 using a set of blo o d vessel trees in the h uman brain, collected as describ ed in Aylward and Bullitt (2002). In the presen t pap er, we choose to consider only v ariation in the top olo gy of the trees, i.e. we consider only the branching structure and ignore other asp ects of the data, suc h as lo cation, thickness and curv ature of each branch. Ev en with this top ology only restriction, there is still an imp ortant c or- r esp ondenc e decision that needs to b e made: which branc h should b e put on the left, and whic h one on the right, see Section 2.1 . Later analysis will also include location, orien tation and thic kness information, by adding attributes to the tree no des b eing studied. A useful set of ideas for pursuing that type of analysis was developed b y W ang and Marron (2007). In Subsection 2.2 we define our main data analytic concept, the tr e e- line , and the notion of principal comp onents based on tree-lines. Here we also state, and illustrate our main result, Theorem 2.1 , whic h will allow us to quic kly compute the principal comp onents. Subsection 2.3 is dev oted to our data analysis using the blo od vessel data: we carefully compare the corresp ondence approac hes, and p resent our findings based on the computed principal comp onen ts. In Section 3 we prov e Theorem 2.1 along with a host of necessary claims. 2. Data and Analysis. The data analyzed here are from a study of Magnetic Resonance Angiograph y brain images of a set of 73 h uman sub jects of b oth sexes, ranging in age from 18 to 72, which can b e found at Handle (2008). One slice of one such image is sho wn in Figure 1 . This mode of imaging indicates strong blo o d flow as white. These white regions are trac k ed in 3 dimensions, then com bined, to give trees of brain arteries. The set of trees dev elop ed from the image of which Figure 1 is one slice is TREE-LINE ANAL YSIS 3 Fig 1 . Single Slice fr om a Magnetic R esonanc e Angio gr aphy image for one p atient. Bright r e gions indic ate bloo d flow. sho wn in Figure 2 . T rees are colored according to region of the brain. Each region is studied separately , where eac h tree is one data point in the data set of its region. The goal of the present OOD A is to understand the p opulation structure of 73 sub jects through 3 data sets extracted from them: Back data set (gold trees), left data set (cy an) and right data set (blue). One p oin t to note is that the fron t trees (red) are not studied here. This is b ecause the source of flo w for the fron t trees is v ariable, therefore this subp opulation has less biological meaning. F or simplicity w e c hose to omit this sub-p opulation. The stored information for each of these trees is quite rich (enabling the detailed view shown in Figure 2 ). Eac h colored tree consists of a set of branc h segments. Each branch segment consists of a sequence of spheres fit to the white regions in the MRA image (of which Figure 1 w as one slice), as describ ed in Aylw ard and Bullitt (2002). Each sphere has a center (with x , y , z co ordinates, indicating lo cation of a p oin t on the center line of the artery), and a radius (indicating arterial thickness). 2.1. T r e e Corr esp ondenc e. Given a single tree, for example the gold col- ored (bac k) tree in Figure 2 , w e reduce it to only its top ological (connec- tivit y) aspects by representing it as a simple binary tree. Figure 3 is an 4 Fig 2 . Re c onstructe d set of tr ees of br ain arteries for the same p atient as shown in Figur e 1 . The colors indic ate r e gions of the br ain: Gold (b ack), Right (blue), F r ont (r e d), L eft (cyan). example of such a representation. Each no de in Figure 3 is b est thought of as a branch of the tree, and the green line segmen ts simply show whic h child branc h connects to which parent. The ro ot no de at the top represen ts the initial fat gold tree trunk shown near the b ottom of Figure 2 . The thin blue lines show the supp ort tree, whic h is just the union of all of the back trees, o v er the whole data set of 73 patien ts. There is one set of am biguities in the construction of the binary tree sho wn in Figure 3 . That is the choice, m ade for each adult branc h, of which c hild branc h is put on the left, and whic h is put on the right. The following t w o wa ys of resolving this am biguit y are considered here. Using standard terminology from image analysis, we use the w ord c orr esp ondenc e to refer to this choice. • Thic kness Corresp ondence: Put the no de that corresp onds to the c hild with larger median radius (of the sequence of spheres fit to the MRA image) on the left. Since it is exp ected that the fatter child v essel will transp ort the most blo o d, this should b e a reasonable notion of dominant br anch . • Descendan t Corresp ondence: Put the node that corresponds to the child with the most descendants on the left. These corresp ondences are compared in Subsection 2.3 . Other types of corresp ondence, that hav e not yet b een studied, are also p ossible. An attractive p ossibilit y , suggested in p ersonal discussion by Marc TREE-LINE ANAL YSIS 5 Fig 3 . Gr e en line se gments show the top olo gy only r epr esentation of the gold (b ack tr e e) fr om Figur e 2 . Only br anching information is r etaine d for the OODA. Br anch lo cation and thickness information is delib er ately ignor e d. Thin blue curve shows the union over al l tr ees in the sample. Niethammer, is to use lo cation information of the c hildren in this c hoice. E.g. in the back tree, one could choose the c hild whic h is physically m ore on the left side (or p erhaps the c hild whose descendants are more on av erage to the left) as the left no de in this represen tation. This would giv e a representation that is physically closer to the actual data, whic h ma y b e more natural for addressing certain types of anatomical issues. 2.2. T r e e-Lines. In this section w e develop the to ols of our main analysis, based on the notion of tr e e-lines . W e follow the ideas of W ang and Marron (2007), who laid the foundations for this t yp e of analysis, with a set of ideas for extending the Euclidean workhorse metho d of PCA to data sets of tree structured ob jects. The key idea (originally suggested in p ersonal con v ersation b y J. O. Ramsa y) w as to define an appropriate one dimensional r epr esentation , and then find the one that b est fits the data. The tree-line is a first simple approac h to this problem. First we define a binary tree: Definition 2.1 . A binary tr e e is a set of no des that ar e c onne cte d by e dges in a dir e cte d fashion, which starts with one no de designate d as r o ot , 6 Fig 4 . T oy example of a data set of tr e es, T , with n = 3 . This wil l b e use d to il lustr ate sever al issues b elow. wher e e ach no de has at most two childr en. Using the notation t i for a single tree, w e let (2.1) T = { t 1 , ..., t n } denote a data set of n such trees. A toy example of a set of 3 trees is given in Figure 4 . T o identify the no des within each tree more easily , we use the level-order indexing metho d from W ang and Marron (2007). The ro ot no de has index 1. F or the remaining no des, if a no de has index ω , then the index of its left c hild is 2 ω and of its righ t child is 2 ω + 1. These indices enable us to identify a binary tree b y only listing the indices of its nodes. The basis of our analysis is an appropriate metric, i.e. distance, on tree space. W e use the common notion of Hamming distance for this purp ose: Definition 2.2 . Given two tr e es t 1 and t 2 , their distanc e is d ( t 1 , t 2 ) = | t 1 \ t 2 | + | t 2 \ t 1 | , wher e \ denotes set differ enc e. Tw o more basic concepts are defined b elow; the notion of supp ort tree has already b een shown in Figure 3 (as the thin blue lines). Definition 2.3 . F or a data set T , given as in ( 2.1 ), the supp ort tr e e, and the interse ction tr e e ar e define d as Supp( T ) = ∪ n i =1 t i In t( T ) = ∩ n i =1 t i . Figure 7 sho ws the supp ort trees of the data sets used in this study . Figure 8 includes the corresponding in tersection trees. TREE-LINE ANAL YSIS 7 Fig 5 . T oy example of a tr e e-line. Each memb er c ome fr om adding a no de to the pr evious. Each new no de is a child of the pr eviously adde d no de. Starting p oint ( ` 0 ) is the intersection tr e e of the toy data set of Figur e 4 . The main idea of a tree-line (our notion of one dimensional representation) is that it is constructed by adding a sequence of single no des, where each new no de is a child of the most recen t child: Definition 2.4 . A tr e e-line , L = { ` 0 , · · · , ` m } , is a se quenc e of tr e es wher e ` 0 is c al le d the starting tr e e, and ` i c omes fr om ` i − 1 by the addition of a single no de, lab ele d v i . In addition e ach v i +1 is a child of v i . An example of a tree-line is given in Figure 5 . Insigh t as to how well a giv en tree-line fits a data set is based up on the concept of pro jection: Definition 2.5 . Given a data tr e e t , its pr oje ction onto the tr e e-line L is P L ( t ) = arg min ` ∈ L { d ( t, ` ) } . W ang and Marron (2007) sho w that this pro jection is alw a ys unique. This will also follow from Claim 3.1 in Section 3 , whose c haracterization of the pro jection will b e the key in computing the principal comp onent tree-lines, defined shortly . The ab o v e toy examples pro vide an illustration. Let t 3 b e the third tree sho wn in Figure 4 . Name the trees in the tree-line, L , shown in Figure 5 , as ` 0 , ` 1 , ` 2 , ` 3 . The set of distances from t 3 to each eac h tree in L is tabulated as j 0 1 2 3 d ( t 3 , ` j ) 6 5 4 5 The minim um distance is 4, ac hiev ed at j = 2, so the pro jection of t 3 on to the tree-line L is ` 2 . Next we develop an analog of the first principal comp onent ( P C 1), by finding the tree-line that b est fits the data. 8 Definition 2.6 . F or a data set T , the first princip al c omp onent tr e e-line , i.e. P C 1 , is L ∗ 1 = arg min L X t i ∈ T d ( t i , P L ( t i )) In con v en tional Euclidean PCA, additional comp onen ts are restricted to lie in the subspace orthogonal to existing comp onen ts, and sub ject to that restriction, to fit the data as well as p ossible. F or an analogous notion in tree space, we first need to define the concept of the union of tree-lines, and of a pro jection onto it. Definition 2.7 . Given tr e e-lines L 1 = { ` 1 , 0 , ` 1 , 1 , . . . , ` 1 ,p 1 } , . . . , L q = { ` q , 0 , ` q , 1 , . . . , ` q ,p q } , their union is the set of al l p ossible unions of memb ers of L 1 thr ough L q : L 1 ∪ · · · ∪ L q = { ` 1 ,i 1 ∪ · · · ∪ ` q ,i q | i 1 ∈ { 0 , . . . , p 1 } , . . . , i q ∈ { 0 , . . . , p q } . } Given a data tr e e t , the pr oje ction of t onto L 1 ∪ · · · ∪ L q is (2.2) P L 1 ∪···∪ L q ( t ) = arg min ` ∈ L 1 ∪···∪ L q { d ( t, ` ) } . In our non-Euclidean tree space, there is no notion of orthogonality a v ail- able, so we instead just ask that the 2nd tree-line fit as muc h of data as p ossible, when used in combination with the first, and so on. Definition 2.8 . F or k ≥ 1 the k th princip al c omp onent tr e e-line is define d r e cursively as (2.3) L ∗ k = arg min ` ∈ L X t i ∈ T d ( t i , P L ∗ 1 ∪···∪ L ∗ k − 1 ∪ L ( t i )) , and it is abbr eviate d as P C k . F or the concept of PC tree-lines to b e useful, it is of crucial imp ortance to b e able to compute them efficiently . W e need another notion. Definition 2.9 . Given a tr e e-line L = { ` 0 , ` 1 , · · · , ` m } we define the path of L as V L = ` m \ ` 0 . TREE-LINE ANAL YSIS 9 Fig 6 . Weighte d supp ort tr e e il lustr ating Theor em 2.1 In tuitiv ely , a tree-line that well fits the data “should gro w in the direction that captures the most information”. F urthermore, the k th PC tree-line should only aim to capture information that has not b een explained by the first k − 1 PC tree-lines. This intuition is made precise in the following theorem, which is the main theoretical result of the pap er: Theorem 2.1 . L et k ≥ 1 , and L ∗ 1 , . . . , L ∗ k − 1 b e the first k − 1 PC tr e e- lines. F or v ∈ Supp( T ) define (2.4) w k ( v ) = ( 0 , if v ∈ V L ∗ 1 ∪ · · · ∪ V L ∗ k − 1 , P v ∈ t i 1 , otherwise Then the k th PC tr e e-line L ∗ k is the tr e e-line whose p ath maximizes the sum of w k weights in the supp ort tr e e, i.e. P v ∈ V ∗ L k w k ( v ) . The pro of of Theorem 2.1 is given in Section 3 . Figure 6 is an illustration: the w eight of a no de is the num b er of times the no de app ears in the trees of Figure 4 . The black edge is the intersection tree of the same data set. The maxim um weigh t path attached to Int( T ) is the red path, which gives rise to the tree-line of Figure 5 , whic h is th us the first principal comp onen t of the data set of Figure 4 . After setting the weigh ts of the no des on the red path to zero, the max- im um w eight path attac hed to Int(T) b ecomes the green path, whic h b y Theorem 2.1 gives rise to P C 2. The usefulness of these to ols is demonstrated with actual data analysis of the full tree data set. 10 2.3. R e al Data R esults. This section describ es an exploratory data anal- ysis of the set of n = 73 brain trees discussed ab o v e using these tree-line ideas. The principal comp onen t tree-lines are computed as defined in The- orem 2.1 . Both corresp ondence types, defined in Section 2.1 are considered and compared. The differen t brain location types (sho wn as differen t colors in Figure 2 ) are analyzed as separate p opulations (i.e. the n = 73 blue trees are first considered to b e the p opulation, then the n = 73 gold trees, etc.), called br ain lo c ation sub-p opulations . This reveals some in teresting contrasts b et ween the brain lo cation types in terms of symmetry . Fig 7 . Supp ort tr e es, for b oth types of c orresp ondenc e (shown in the r ows), and for thr e e br ain lo c ation tr e e typ es (shown in c olumns, c orr esp onding to the c olors in Figure 2 ). Shows that the desc endant c orr esp ondenc e gives a p opulation with mor e c omp act variation than the thickness c orr esp ondence. W e first compare the tw o types of corresp ondence defined in Section 2.1 using the concept of the supp ort tree. This is done b y displa ying the supp ort TREE-LINE ANAL YSIS 11 trees each type of corresp ondence, and for each of the three tree lo cation t yp es (shown with differen t colors in Figure 2 ), in Figure 7 . Note that all of the supp ort trees for the descendan t corresp ondence (bottom) are m uc h smaller than for the thickness corresp ondence (top), indicating that the de- scendan t corresp ondence results in a m uc h more compact p opulation. This seems likely to mak e it easier for our PCA metho d to find an effective rep- resen tation of the descendan t based p opulation. Figure 7 already reveals an asp ect of the p opulation that w as previously unkno wn: there is not a very strong correlation b etw een median tree thick- ness of a branc h, and the num b er of c hildren. Figure 8 sho ws the first 3 PC tree-lines, for the three sub-populations (sho wn as rows), with the in tersection tree as the starting tree, for the descendan t corresp ondence. In the h uman brain, the bac k circulation (gold) arises from a single vessel (the basilar artery) and immediately splits into tw o main trunks, supplying the back sides of the left and right hemispheres. These t wo parts of the back circulation are exp ected to be appro ximately mirror-image symme trical with b oth sides containing one main vessel and other branches stemming from that. Consequen tly , for each tree on the bac k data set if we imagine a vertical axis that goes through the ro ot no de, we exp ect the subtrees on b oth sides of the axis to b e symmetrical with each other. The results of our mo del for the back subp opulation are consistent with this exp ectation. The main vessel of one of the hemispheres can b e seen in the starting p oin t (in tersection tree) as the leftmost set of no des, while the other main vessel b ecomes the first principal comp onen t. As for the left and right circulations (cy an and blue trees) of the brain, they are exp ected to b e close to mirror images of each other. Unlik e the case of the back subp opulation, in each of these circulations there is a single trunk from which smaller branches stem. F or this reason the bilateral symmetry observ ed within the bac k trees is not exp ected to b e found here. The fact that P C 1’s for left and right subp opulations are at later splits suggest that the earlier splits tend to ha ve relatively few descendants. The remaining P C 2 and P C 3 tree-lines do not contain muc h additional infor- mation by themselves. Ho w ever, when we consider PC’s 1,2 and 3 together and compare left and righ t subp opulations,i.e. compare the second and third ro ws of Figure 8 , the structural likeliness is quite visible. It should also b e noted that for b oth of the subp opulations all PC’s are on the left side of the ro ot-axis, indicating a strong bilateral asymmetry , as exp ected. The tree-lines, and insigh ts obtained from them, were essentially similar for the thickness corresp ondence, so those graphics are not sho wn here. 12 Fig 8 . Best fitting tr e e-lines, for differ ent sub-p opulations (r ows), and PC numb er (c olumns). Interse ction tr ees ar e shown in black. Next we study the tree-line analog of the familiar sc or es plot from con- v en tional PCA (a commonly used high dimensional visualization device, sometimes called a dr aftsman ’s plot or a sc atterplot matrix ). In that case, the scores are the pro jection co efficients, whic h indicate the size of the com- p onen t of eac h data p oin t in the given eigen-direction. Pairwise scatterplots of these often giv e a set of useful t wo dimensional views of the data. In the presen t case, given a data p oin t and a tree-line, the corresp onding sc or e is just the length (i.e. the num b er of no des) of the pro jection. Unlike con ven- tional PC scores, these are all integer v alued. Figure 9 shows the scores scatterplot for the set of left trees, based on the descendan t corresp ondence. The data p oints hav e b een colored in Figure 9 , to indicate age, whic h is an imp ortan t cov ariate, as discussed in Bullitt et al (2008). The color scheme starts with purple for the youngest p erson (age 20) and extends through a rain b o w t yp e sp ectrum (blue-cyan-green-y ellow- orange) to red for the oldest (age 72). An additional co v ariate, of p ossible TREE-LINE ANAL YSIS 13 Fig 9 . Sc or es Scatterplot for the Desc endant Corr esp ondenc e, Left Side sub-p opulation. Colors show age, symb ols gender. No cle ar visual p atterns ar e app ar ent. in terest, is sex, with females shown as circles, males as plus signs, and tw o transgender cases indicated using asterisks. It was hop ed that this visualization w ould rev eal some interesting struc- ture with respect to age (color), but it is not easy to see an y such connection in Figure 9 . One reason for this is that the tree-lines only allo w the v ery lim- ited range of scores as in tegers in the range 1-10. A simple wa y to generate a wider range of scores is to pro ject not just on to simple tree-lines, but instead on to their union, as defined in ( 2.2 ). Figure 10 shows a scatterplot matrix, of several union PC scores, in particular P C 1 vs. P C 1 ∪ 2 (shorthand for P C 1 ∪ P C 2) vs. P C 1 ∪ 2 ∪ 3 vs. P C 1 ∪ 2 ∪ 3 ∪ 4. This com bined plot, called the cumulative sc or es sc atterplot , shows a b etter separation of the data than is a v ailable in Figure 9 . The PC unions show a banded structure, which again is an artifact that follows from each PC score individually having a v ery limited range of p ossible v alues. This seems to b e a serious limitation of the tree-line approac h to analyzing p opulation structure. 14 As with Figure 9 , there is unfortunately no readily apparent visual con- nection b etw een age and the visible p opulation structure. How ever, visual impression of this type can b e tricky , and in particular it can b e hard to see some subtle effects. Fig 10 . Cumulative Sc or es Sc atterplot for the Desc endant Corresp ondenc e, Left Side sub- p opulation. Figure 11 shows a view that more deeply scrutinizes the dep endence of the P C 1 score on age, using a scatterplot, ov erlaid with the least squares regression fit line. Note that most of the lines slop e down wards, suggesting that older p eople tend to hav e a smaller P C 1 pro jection than younger p eo- ple. Statistical significance of this down ward slop e is tested by calculating the standard linear regression p -v alue for the null h yp othesis of 0 slop e. F or the left tree, using the descendan t correspondence, the p -v alue is 0 . 0025. This result is strongly significant, indicating that this component is con- nected with age. This is consistent with the results of Bullitt et al (2008), who noted a decreasing trend with age in the total n umber of no des. Our result is the first lo cation sp ecific v ersion of this. TREE-LINE ANAL YSIS 15 Similar score v ersus age plots hav e b een made, and hypothesis tests hav e b een run, for other PC comp onents, and the resulting p -v alues, for the left tree using the descenden t corresp ondence are summarized in this table: P C 1 0 . 003 P C 2 0 . 169 P C 3 0 . 980 P C 4 0 . 2984 P C 1 ∪ 2 0 . 003 P C 1 ∪ 2 ∪ 3 0 . 004 P C 1 ∪ 2 ∪ 3 ∪ 4 0 . 007 Fig 11 . Scatterplot of P C 1 sc or e versus age. L e ast squar es fit r e gr ession line suggests a downwar d tr end in age. T r end is c onfirme d by the p -value of 0 . 003 (for signific anc e of slop e of the line). Note that for the individual PCs, only P C 1 gives a statistically signifi- can t result. F or the cumulativ e PCs, all are significan t, but the significance diminishes as more comp onen ts are added. This suggests that it is really 16 P C 1 whic h is the driv er of all of these results. T o in terpret these results, recall from Figure 8 , that for the left trees, P C 1 c ho oses the left c hild for the first 3 splits, and the righ t child at the 4th split. This suggests that there is not a significant difference b et ween the ages in the tree levels closer to the ro ot, how ever, the difference do es show up when one lo oks at the deep er tree structure, in particular after the 4th split. This is consistent with the ab o v e remark, that for the left brain sub-p opulation, the first few splits did not seem to contain relev an t p opulation information. Instead the effects of age only app ear on splits after level 4. W e did a similar analysis of the back and righ t brain lo cation sub-p opulations, but none of these found significan t results, so they are not shown here. Ho w- ev er, these can b e found at the web site ( 8 ). W e also considered parallel results for the thickness corresp ondence, which again did not yield significant results (but these are on the web site ( 8 )). The fact that descendan t correspondence ga ve some significan t results, while thic kness never did, is one more indication that descendant corresp ondence is preferred. One more approach to the issue of corresp ondence choice is sho wn in Figure 12 . This sho ws the amount of v ariation explained, as a function of the order of the Cumulativ e Union PC, for b oth the thickness and the descendan t corresp ondences, for the left brain lo cation sub-p opulation. The amount of variation explaine d is defined to b e the sum, ov er all trees in the sub- p opulation of the lengths of the pro jections. There are 5023 nodes in total for b oth corresp ondences. (The corresp ondence difference affects the lo cations of no des, total count remains the same.) It is not surprising that these curves are concav e, since the first PC is designed to explain the most v ariation, whic h each succeeding comp onen t explaining a little bit less. But the imp ortant lesson from Figure 12 is that the descendant corresp ondence allows PCA to explain muc h more p opulation structure, at each step, than the thickness corresp ondence. In summary , there are several imp ortant consequences of this work: • In real data sets with branching structure, tree PCA can rev eal in ter- esting insights, such as symmetry . • The descendan t corresp ondence is clearly sup erior to the thickness corresp ondence, and is recommended as the default c hoice in future studies. • As expected, the bac k sub-p opulation is seen to ha ve a more symmetric structure. • F or the left sub-p opulation there is a statistically significan t structural age effect. TREE-LINE ANAL YSIS 17 Fig 12 . T otal numb er of no des explaine d, as a function of Cumulative PC Numb er. Shows that the descendant c orr espondenc e al lows PCA to explain a much higher pr op ortion of the variation in the p opulation than the thickness c orr esp ondence. • There seems to be ro om for impro vemen t of the tree-line idea for doing PCA on p opulations of trees. A p ossible improv ement is to allow a ric her branching structure, such as adding the next no de as a child of one of the last 2 or 3 no des. W e are exploring this metho dology in our curren t research. 3. Optimization pro ofs. This section is dev oted to the pro of of The- orem 2.1 with some accompan ying claims. Claim 3.1 . L et L = { ` 0 , . . . , ` m } b e a tr e e-line, and t a data tr e e. Then P L ( t ) = ` 0 ∪ ( t ∩ V L ) . (3.1) Pro of: Since ` i = ` i − 1 ∪ v i , we hav e (3.2) d ( t, ` i ) = ( d ( t, ` i − 1 ) − 1 if v i ∈ t ; d ( t, ` i − 1 ) + 1 otherwise . 18 In other w ords, the distance of the tree to the line decreases as w e k eep adding no des of V L that are in t , and when we step out of t , the distance b egins to increase, so Claim ( 3.1 ) follows. Claim 3.2 . L et L 1 , . . . , L q b e tr e e-lines with a c ommon starting p oint, and t a data tr e e. Then P L 1 ∪···∪ L q ( t ) = P L 1 ( t ) ∪ · · · ∪ P L q ( t ) . Pro of: F or simplicity , we only prov e the statemen t for q = 2. Assume that L 1 = { ` 1 , 0 , ` 1 , 1 , . . . , ` 1 ,p 1 } L 2 = { ` 2 , 0 , ` 2 , 1 , . . . , ` 2 ,p 2 } with ` 0 = ` 1 , 0 = ` 2 , 0 , and (3.3) V L 1 = { v 1 , 1 , . . . , v 1 ,p 1 } , V L 2 = { v 2 , 1 , . . . , v 2 ,p 2 } . Also assume P L 1 ( t ) = ` 1 ,r 1 , (3.4) P L 2 ( t ) = ` 2 ,r 2 . (3.5) F or brevity , let us define f ( i, j ) = d ( t, ` 1 ,i ∪ ` 2 ,j ) for 1 ≤ i ≤ p 1 , 1 ≤ j ≤ p 2 . (3.6) Using Claim 3.1 , ( 3.4 ) means v 1 ,i ∈ t, if i ≤ r 1 , and v 1 ,i 6∈ t, if i > r 1 , (3.7) hence (3.8) f ( i, j ) ≤ f ( i − 1 , j ) if i ≤ r 1 ; f ( i, j ) ≥ f ( i − 1 , j ) if i > r 1 . By symmetry , w e hav e (3.9) f ( i, j ) ≤ f ( i, j − 1) if j ≤ r 2 ; f ( i, j ) ≥ f ( i, j − 1) if j > r 2 . Ov erall, ( 3.8 ) and ( 3.9 ) imply that the function f attains its minim um at i = r 1 , j = r 2 , which is what w e had to pro v e. TREE-LINE ANAL YSIS 19 Claim 3.3 . L et S b e a subset of Supp( T ) which c ontains ` 0 . F or v ∈ Supp( T ) define (3.10) w S ( v ) = ( 0 , if v ∈ S, P v ∈ t i 1 , otherwise Then among the tr e elines with starting tr e e ` 0 the one which maximizes X t i ∈ T | ( V L ∪ S ) ∩ t i | is the one whose p ath V L maximizes the sum of the w S weights: P v ∈ V L w S ( v ) . Pro of: F or v ∈ Supp( T ) , and a subtree t of Supp( T ) , let us define (3.11) δ ( v , t ) = ( 1 , if v ∈ t, 0 , otherwise Then arg max ` ∈ L P t i ∈ T | ( V L ∪ S ) ∩ t i | = arg max ` ∈ L P t i ∈ T P v ∈ V L ∪ S δ ( v , t i ) = arg max ` ∈ L P v ∈ V L ∪ S P t i ∈ T δ ( v , t i ) = arg max ` ∈ L P v ∈ V L ∪ S w ∅ ( v ) = arg max ` ∈ L P v ∈ V L w S ( v ) . Finally , we pro v e our main result: Pro of of Theorem 2.1 : F or b etter intuition, w e first giv e a pro of when k = 1 . Using Claim 3.1 in Definition 2.6 , w e get L ∗ 1 = arg min L X t i ∈ T d ( t i , ` 0 ∪ ( t i ∩ V L )) . Since V L is disjoint from ` 0 , L ∗ 1 = arg max L X t i ∈ T | V L ∩ t i | , the statement follows from Claim 3.3 with S = ∅ . 20 W e no w prov e the statement for general k . F or an arbitrary data tree t , and tree-line L , w e hav e (3.12) P L ∗ 1 ∪···∪ L ∗ k − 1 ∪ L ( t ) = P L ∗ 1 ( t ) ∪ · · · ∪ P L ∗ k − 1 ( t ) ∪ P L ( t ) = ` 0 ∪ ( V L ∗ 1 ∩ t ) ∪ · · · ∪ ( V L ∗ k − 1 ∩ t ) ∪ ( V L ∩ t ) = ` 0 ∪ [( V L ∗ 1 ∪ · · · ∪ V L ∗ k − 1 ∪ V L ) ∩ t ] , with the first equation from Claim 3.2 , the second from Claim 3.1 , and the third straightforw ard. Com bining ( 3.12 ) with ( 2.3 ) we get (3.13) L ∗ k = arg min L X t i ∈ T d ( t i , ` 0 ∪ [(( V L ∗ 1 ∪ · · · ∪ V L ∗ k − 1 ∪ V L ) ∩ t i ]) . Again, the paths of L ∗ 1 , . . . , L ∗ k − 1 and L are disjoint from ` 0 , so ( 3.13 ) b e- comes (3.14) L ∗ k = arg max L X t i ∈ T | ( V L ∗ 1 ∪ · · · ∪ V L ∗ k − 1 ∪ V L ) ∩ t i | , so the statement follows from Claim 3.3 with S = V L ∗ 1 ∪ · · · ∪ V L ∗ k − 1 . References. [1] Aylward, S. and Bullitt, E. (2002) Initialization, noise, singularities and scale in height ridge trav ersal for tubular ob ject centerline extraction, IEEE T r ansactions on Me dic al Imaging , 21, 61-75 [2] Bullitt, E., Zeng, D., Ghosh, A., Aylward, S. R., Lin, W., Marks, B. L., Smith, K. (2008) The effects of health y aging on in tracerebral blo o d vessels visualized by mag- netic resonance angiography , submitted to Neurobiology of Aging. [3] F errat y , F. and Vieu, P . (2006) Nonpar ametric functional data analysis: the ory and pr actic e , Berlin, Springer. [4] Handle (2008) h ttp://hdl.handle.net/1926/594 [5] Ramsay , J. O. and Silverman, B. W. (2002) Applie d F unctional Data A nalysis , New Y ork: Springer-V erlag. [6] Ramsay , J. O. and Silv erman, B. W. (2005) F unctional Data Analysis , New Y ork: Springer-V erlag (2nd edition). [7] W ang, H. and Marron, J. S. (2007) Ob ject oriented data analysis: Sets of trees, The Annals of Statistics , 35, 1849-1873. [8] W ang, H. (2008) http://www.stat.colostate.edu/ ∼ w anghn/tree.htm Dep ar tment of St a tistics and O pera tions Research University of Nor th Carolina Chapel Hill, NC 27599-3260 E-mail: aydin@email.unc.edu pataki@email.unc.edu marron@email.unc.edu Dep ar tment of St a tistics Colorado St a te University For t Collins, CO 80523-1877 E-mail: wanghn@stat.colostate.edu Dep ar tment of Surger y University of Nor th Carolina Chapel Hill, NC 27599-3260 E-mail: bullitt@med.unc.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment