트리 구조 데이터의 주성분 분석: 트리‑라인 기반 선형 알고리즘
본 논문은 트리 형태의 객체 집합에 대해 전통적인 주성분 분석(PCA)의 개념을 확장한다. 트리‑라인이라는 일차원 표현을 정의하고, 지원 트리와 교차 트리를 이용해 거리와 투영을 정량화한다. 핵심 정리(Theorem 2.1)를 통해 k번째 주성분 트리‑라인은 이전 k‑1개의 주성분이 차지한 노드를 제외한 지원 트리에서 가중치 합이 최대인 경로로 구해진다. 이 알고리즘은 트리 크기에 선형적인 시간 복잡도를 가지며, 73명의 뇌 혈관 트리를 대상으…
저자: Burcu Aydin, Gabor Pataki, Haonan Wang
본 연구는 객체 지향 데이터 분석(OODA)의 확장으로, 트리 구조를 가진 객체 집합에 대한 주성분 분석(PCA) 방법을 제시한다. 기존의 기능적 데이터 분석(FDA)은 곡선 형태의 데이터를 대상으로 변동성을 분석했지만, 트리와 같은 복합 구조를 다루기 위해서는 새로운 수학적 도구가 필요하다. 저자들은 이러한 필요성을 충족시키기 위해 “트리‑라인(tree‑line)”이라는 개념을 도입하고, 이를 기반으로 트리 공간에서의 거리, 투영, 그리고 주성분을 정의한다.
먼저, 모든 트리를 이진 트리로 변환한다. 각 노드는 레벨‑오더 인덱싱(루트 = 1, 왼쪽 자식 = 2·ω, 오른쪽 자식 = 2·ω+1)으로 고유하게 식별된다. 두 트리 사이의 거리는 해밍 거리 d(t₁,t₂)=|t₁\t₂|+|t₂\t₁| 로 정의되며, 이는 한 트리에는 존재하지만 다른 트리에는 없는 노드 수의 합이다.
트리‑라인은 시작 트리(보통 교차 트리 Int(T))에서 시작해, 매 단계마다 현재 트리에서 가장 최근에 추가된 노드의 자식 하나를 추가하는 일련의 트리 집합 L={ℓ₀,…,ℓ_m}이다. 여기서 ℓ₀는 시작 트리이며, ℓ_i는 ℓ_{i‑1}에 새로운 노드 v_i를 추가한 결과이다. 트리‑라인에 대한 데이터 트리 t의 투영 P_L(t)는 L 내에서 d(t,ℓ)값이 최소가 되는 ℓ이며, 이는 유일함을 보인다(Claim 3.1).
주성분 트리‑라인은 전통적인 PCA와 유사하게 정의된다. 첫 번째 주성분 PC₁은 모든 데이터 트리 t_i∈T에 대해 Σ_i d(t_i, P_{L}(t_i))를 최소화하는 트리‑라인 L*₁이다. 이후 k번째 주성분 PC_k는 이미 구한 k‑1개의 주성분이 만든 트리‑라인들의 합집합에 대해 동일한 최소화 문제를 푼 결과물이다. 트리 공간에서는 직교 개념이 없으므로, “합집합”은 가능한 모든 트리‑라인 조합을 의미한다.
Theorem 2.1은 위 정의를 실용적인 알고리즘으로 전환한다. 지원 트리 Supp(T)=∪_{i=1}^n t_i와 교차 트리 Int(T)=∩_{i=1}^n t_i를 먼저 구한다. 각 노드 v∈Supp(T)에 대해 가중치 w_k(v)를 부여한다. w_k(v)=0이면 v가 이전 k‑1개의 주성분 트리‑라인이 차지한 경로 V_{L*₁}∪…∪V_{L*_{k‑1}}에 속한다는 뜻이며, 그렇지 않으면 v가 포함된 데이터 트리들의 수 P(v)∈t_i를 가중치로 둔다. 그런 다음 Int(T)에서 시작해 지원 트리 내에서 w_k 합이 최대인 경로 V*를 찾는다. 이 경로가 바로 k번째 주성분 트리‑라인 L*ₖ의 “경로”이며, ℓ₀=Int(T)에서 시작해 순차적으로 노드를 추가하면 L*ₖ가 완성된다. 이 과정은 각 노드의 가중치를 한 번 계산하고, 최대 가중치 경로를 찾는 DFS/BFS를 수행하면 되므로 시간 복잡도는 O(|Supp(T)|), 즉 트리 크기에 선형이다.
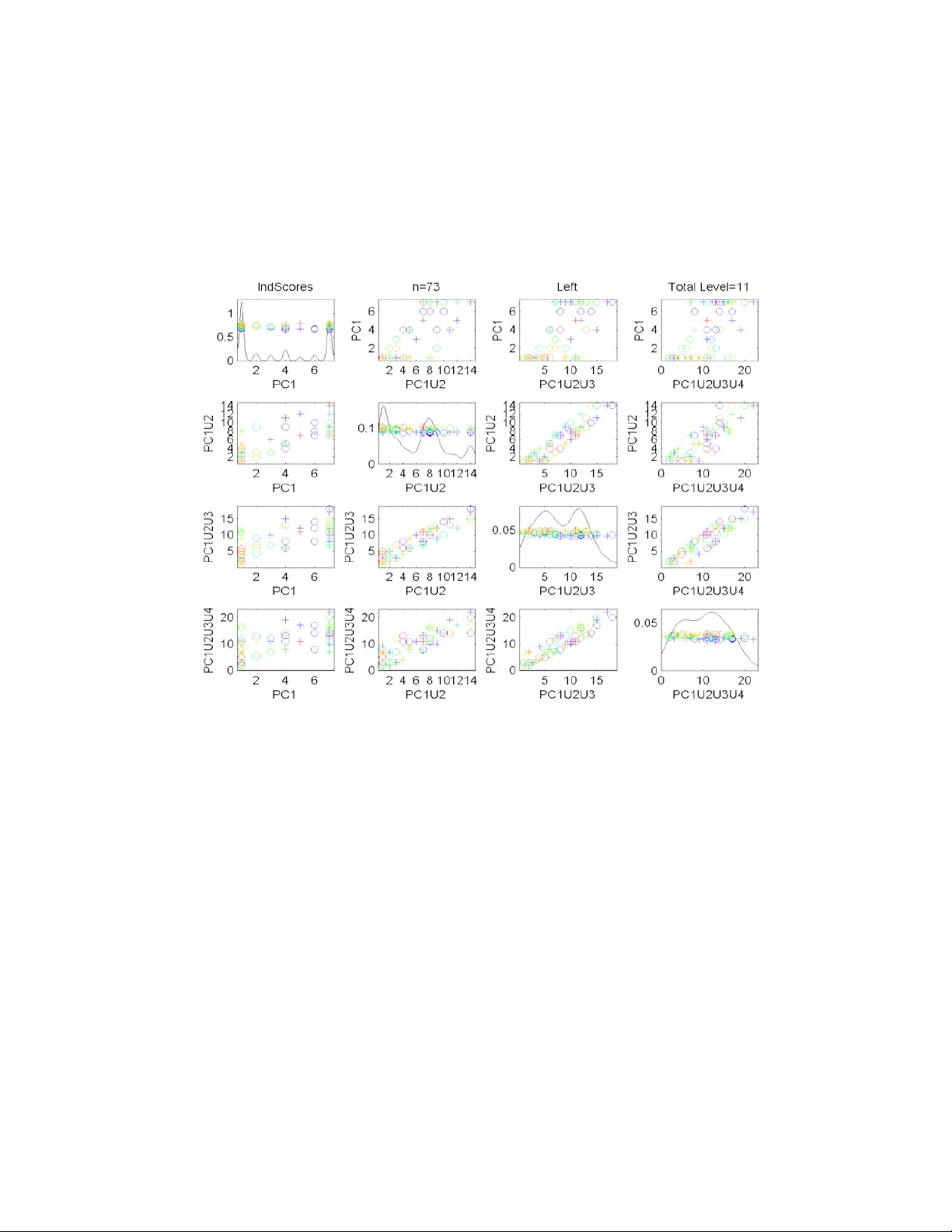
실제 데이터 적용에서는 73명의 피험자에 대해 뇌 혈관을 3차원 MRA 영상으로부터 추출한 트리를 사용한다. 각 피험자는 백(back), 좌(left), 우(right) 세 영역별로 트리를 구성하며, 전처리 단계에서 트리의 위상(연결 구조)만을 남기고 위치·두께·곡률 등은 무시한다. 트리의 좌·우 자식 순서를 정하기 위해 두 가지 “correspondence” 방식을 제안한다. 첫 번째는 “Thickness correspondence”로, 자식 중 평균 반경이 큰 쪽을 왼쪽으로 배정한다. 두 번째는 “Descendant correspondence”로, 하위 노드 수가 많은 쪽을 왼쪽으로 배정한다.
분석 결과, Descendant correspondence가 지원 트리를 더 작게 만들며, 이는 가중치 경로 탐색을 용이하게 한다는 점에서 우수함을 보였다. 또한, 각 영역별로 구한 첫 번째 PC 트리‑라인은 해당 영역의 주요 혈관 분지를 포착한다. 예를 들어, 백 영역에서는 기저동맥이 두 개의 주요 가지로 분리되는 구조가 첫 번째와 두 번째 PC에 각각 나타나며, 이는 인간 뇌의 좌·우 대칭성을 정량적으로 확인시킨다. 좌·우 영역에서는 단일 주 혈관에서 여러 작은 가지가 뻗어 나가는 형태가 두 번째·세 번째 PC에 반영된다.
결론적으로, 본 논문은 트리‑라인이라는 새로운 일차원 표현을 도입하고, 가중치 기반 최대 경로 탐색을 통해 비유클리드 트리 공간에서도 PCA와 동등한 최적화 목표를 달성한다. 제안된 알고리즘은 트리 크기에 선형적인 시간 복잡도를 가지며, 실제 뇌 혈관 데이터에 적용해 의미 있는 해부학적 패턴을 성공적으로 추출한다. 이는 트리 구조 데이터를 다루는 OODA 분야에서 실용적인 분석 도구로서의 가능성을 크게 확장한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기