Sign Language Tutoring Tool
In this project, we have developed a sign language tutor that lets users learn isolated signs by watching recorded videos and by trying the same signs. The system records the user's video and analyses it. If the sign is recognized, both verbal and an…
Authors: ** - Oya Aran¹ - Ismail Ari¹ - Alex, re Benoit² - Ana Huerta Carrillo³ - François‑Xavier Fanard⁴ - Pavel Campr⁵ - Lale Akarun¹ - Alice Caplier² - Michele Rombaut² - Bulent Sankur¹ ¹ Bogazici University, Türkiye ² LIS_INPG
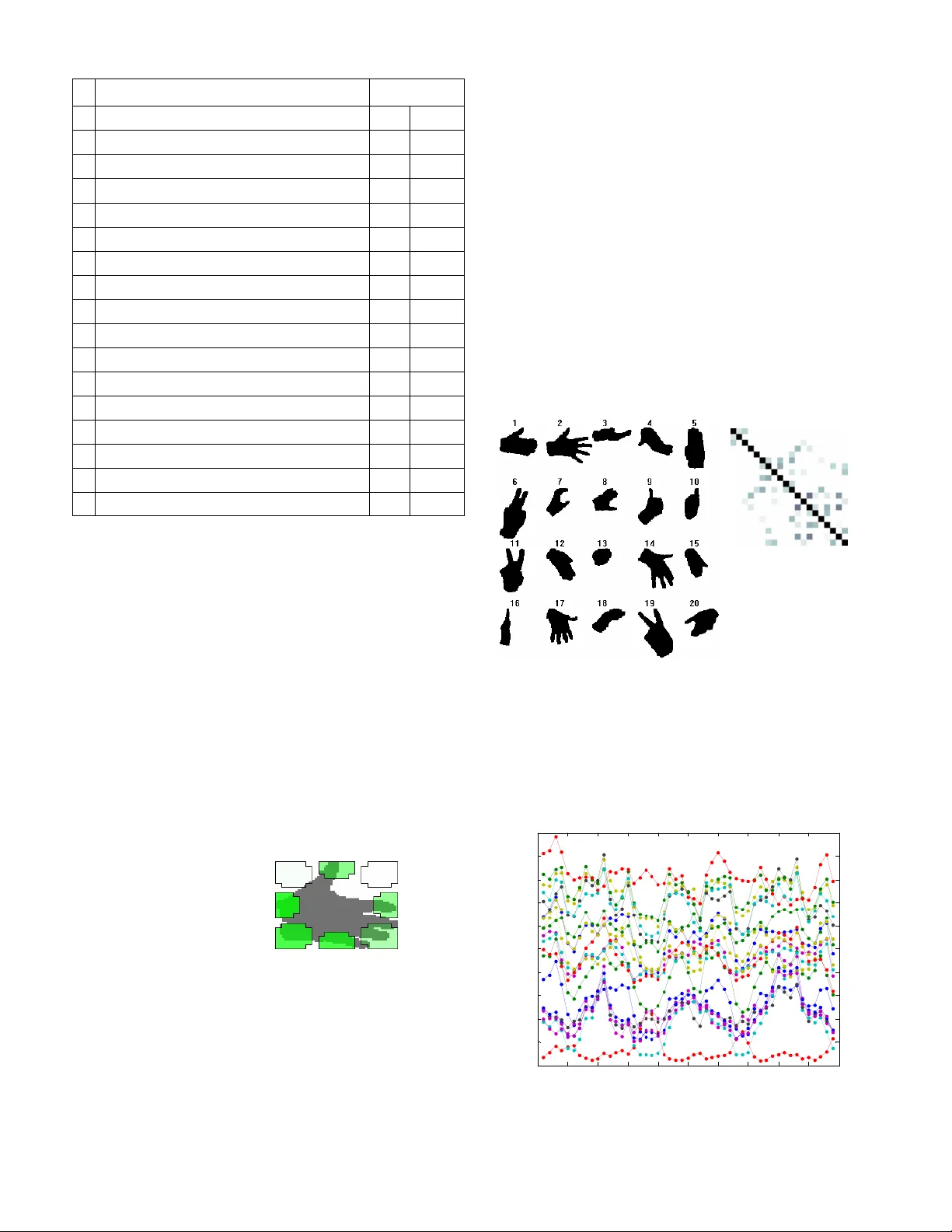
eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report Sign Language T utoring T ool Oya Aran¹, Ismail Ari¹, Alexandre Benoit², Ana Huerta Carrillo³, François-Xavier Fanard 4 , Pavel Campr 5 , Lale Akarun¹, Alice Caplier², Michele Rombaut² and Bulent Sankur¹ ¹ Bogazici University, ²LIS_INPG, ³Technical University of Madrid, 4 Universite Catholique de Louvain, 5 University of West Bohemia in Pilsen Abstract — In this project, we have developed a sign language tutor that lets users learn isolated signs by watching recorded videos and by try ing the same signs. The system records the user’s video and analyses it. If the sign is rec ognized, both verbal and animated feedback is given to the user. The system is able to recognize complex signs that involve both ha nd gestures and head movements and expressions. Our performance te sts yield a 99% recognition rate on signs involving only manual gestur es and 85% recognition rate on signs that involve both manual a nd non manual components, such as head movement and facial expressions. Index Terms —Gesture recognition, s ign language recognition, head movement analysis, human body animation I. I NTRODUCTION HE purpose of this project is to develop a Sign Language Tut oring Demonstrator t hat lets users pract ice demonstrated signs and get feedback about thei r performance. In a learning step, a video of a specific si gn is demonstrated to t he user and in the practice step, the user is asked to repeat the sign. An evaluation of produced gesture is given to the learner; together wi th a synthesized version of t he sign that lets the user get visu al feedback in a caricatured form. The specificity of Sign Language is t hat the whole message i s contained not only i n hand gestures and shapes (m anual signs) but also in facial expressi ons and head/shoulder m otion (non-manual signs). As a consequence, the language is intrinsically multimodal. In order to solve the hand trajectory recognition problem , Hidden Markov Models have been used extensively for the last decade. Lee and Kim [1] propose a m ethod for online gesture spotting using HMMs. Starner et al. [2] used HMMs for continuous Ameri can Sign Language recogni tion. The vocabulary contains 40 signs and the sentence structure to be recognized was constrained to personal pronoun, verb, noun, and adjective. In 1997, Vogler and Metaxas [3] proposed a system for both isolated and continuous ASL recognition sentences with a 53-sign vocabulary. In a later st udy [4] the same authors attacked the scalability problem and proposed a method for the parallel modeling of t he phonemes within an HMM fram ework. Most systems of Sign Language r ecognition concentrate on hand gest ure analysis only. In , a survey on autom atic sign language analysis i s given and integrating non-m anual signs with hand gestures is exam ined. A preliminary version of t he tutor we propose to develop, demonstrated at EUSIPC O, uses only hand trajectory based gesture recognition [6] . The signs selected were signs that coul d be recognized based on solely the t rajectory of one hand. In this project, we aim at developi ng a tutoring system able to cope with two sources of informat ion: hand gestures and head motion. The data base contains complex si gns that are performed with two hands and head gest ures. Therefore, our Sign Language Recognition sy stem fuses the data com ing from two sources of inform ation to recognize a performed sign: The shape and trajectory of the t wo hands and the head movem ents. T Fig. 1. Sign language recogn ition system block diagram Fig. 1 illustrates the steps in sign recognition. The first step i n hand gesture recognition is to detect and track both hands. This is a complex task becau se the hands may occlude each other and also overlap other skin colored regions, such as the arms and the face. To make the detection problem easier, markers on the hand and fingers are wi dely used in the literature. In this project, we have used differently colored gloves worn on the two hands. Once the hands are detected, a complete hand gest ure recognition system must be able to extract the hand shape, and the hand motion. We have extracted simple hand shape feat ures and com bined them with hand motion and positi on information t o obtain a combined feature vector. A left-t o-right continuous HMM model with no This report, as well as the source code for the software developed dur ing the project, is available online from the eNTERFACE ’06 web site: www.enterface.net . eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report state skips is trained for each sign. These HMM models could be directly used for recognit ion if we were to recognize only the manual si gns. However, some signs involve non-m anual components. Thus further anal ysis of head m ovements and facial expressions m ust be done to recognize non-ma nual signs. Head movement analysis works concurrently wi th hand gesture analysis. Following the face detection step, a method based on the human visual system is used to calculate the motion energy and the velocit y of the head, eye, eyebrows and mouth. These features are co mbined into a single feature vector and HMM m odels for the non-manual si gns are trained. For the final decision, m anual and non-manual HMM m odels are fused in a sequential m anner. Decisions of the manual HMMs are used as the base for decision and non- manual HMMs take part to differentiate between the variants of the base sign. Another new feature of the Sign Language Tutoring tool is t hat it uses synthesized head and arm m otions based on the analysis of arm and head movem ents. This let s the user get accentuated feedback. Feedback, either TRUE or FALSE, is given for the manual com ponent as well as for the non-m anual one, separately. In this project, we have first defi ned a lim ited num ber of signs that can be used for sign l anguage tutoring. 19 signs have been selected so that head motions are crucial for their recognition: Some signs have identical hand mot ions but different head moti ons. After defining the dataset , we have collected data from eight subject s. Each subject perform ed all the signs five tim es. The sign language tutor application was designed t o show sel ected signs to the user and to let the user record his/her own sign using the webcam connected to the system. The application then runs the analy sis, recognition, and sy nthesis subsystem s. The recognized sign is identi fied by a text message and the synt hesized animati on is shown as feedback to the user. If the sign is not pe rform ed correctly, the user m ay repeat the test. This report is organized as foll ows: In section II, we give details of the sign language t utor application, together wi th database details. Section III details the analysis: hand segmentati on, hand motion feature extraction, hand shape feature extraction, and head mo tion feature extraction. Section IV describes the recognition by fusi on of information from all sources. Section V describes the synthesis of head m otion, facial expressions, hands and arms m otion. Section VI gives results of the recognition t ests and Section VII concludes the report and outlines fu ture directions. II. S IGN L ANGUAGE T UTOR A. Si gn Language The linguistic characteristi cs of sign language is different t han that of spoken languages due to the existe nce of several components affecting the cont ext such as the use of facial expressions and the head movements i n addition to the hand movem ents. The structure of spoken language makes use of words linearly i.e., one afte r another, whereas sign language makes use of several body movem ents in parallel in a completel y different spatial and t emporal sequence. Language modeling enables t o improve the perform ance of speech recognition systems. A language m odel for sign language is also required for the same purpose. Besi des, the significance of co-articulati on effects necessitates the continuous recognition of si gn language instead of the recognition of isolated signs. These are com plex problem s to be tackled. For the present, we have focused on recognition of isolated words, or phrases, that involve m anual and non- manual com ponents. There are many sign languages in the worl d. We have chosen si gns from Am erican Sign Language (ASL), since ASL is widely studied. However, our system is quite general and can be adapted to others. B. Dat abase For our database, 19 signs from Ameri can Sign Language were used. The sel ected signs include non-m anual signs and inflections in the signi ng of the same manual sign [5] . For each sign, we recorded five repetitions from eight subjects. The preferred video resolution was 640*480 pixels and the frame rate was 25 fps. Short descript ions about the signs we used in the database can be seen in TABLE I . TABLE I. ASL SIGNS IN THE DATABASE Sign Head / Facial Expr ession Hand [smbdy] is here Nod Is [smbdy] here? Brows up, Head forward [smbdy] is not here Head shake Circular motion parallel to the ground with right hand. Clean - Very clean Lips closed, head turns from right to frontt, sharp m otion Right palm facing down, left palm facing up. Sweep left hand with right. Afraid - Hands start from the sides and meet in front of body , in the middle Very afraid Facial expression (lips open, ey es wide) The same as “afraid”, but s hake the hands at the middle Fast - Very fast Facial expression (lips open, ey es wide), and sharp motion Hands start in front of body and motion towards the body. Fingers partially closed, thumb open To drink Head motion (up and down) Drinking motion, hand as holding a cup Drink (noun) - Repetitive drinking motion, hand as holding a cup. eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report To open door - Palms facing to the front. One hand moves as if the door is opened; only once. Open door (noun) - Palms facing to the front. One hand moves as if the door is opened. Repeat, with sm all hand motion Study - Left hand palm facing upwards, right hand all fingers open, mainly finger motion (finger tilt) Study continuously Circular head motion accom panies hand motion Left palm facing up, right hand all fingers open, finger tilt together with large and downward circular motion Study regularly Downward head motion accom panies hand motion Left palm facing upwards, right hand all fingers open, downward/ upward sharp motion, no finger motion Look at - Starting from the eyes, forward motion, two hands together. Look at continuously Circular head motion accom panies hand motion Starting from the eyes, forward motion, two hands together. Larger and circular motion Look at regularly Downward head motion accom panies hand motion Starting from the eyes, forward motion, two hands together. Sharp forward/ backward motion C. Tu tor Application The sign language tutor applicat ion was designed to show sel ected signs to the user and to let the user record his/her own sign using the webcam connect ed to the system. The graphical user interface for the tutor can be observed in Fig. 2. The graphical user interface consists of four panels: Trai ning, Information, Practi ce and Synthesis. Training panel involves the teacher videos, thus the user can watch the videos to learn the sign by pressing the Play butt on. The program captures the user’s sign video after the Try button is pressed. Afterwards, informati on panel is used for informing the user about the results of his/her trial. There are three ty pes of results: “ok” (the sign was confi rmed), “false” (the sign was wrong) and “head is ok but hands are fal se”. Possible errors are also shown in this field. Users can watch the original capt ured video or the segm ented video in this panel as shown in Fig. 3. Afterwards, if the user wants to see the synthesized video, he/s he can use the synthesis panel. III. S IGN L ANGUAGE A NALYSIS A. Hand segment ation The user wears gloves with different colors when perform ing the signs. The two colored regions are detect ed and marked as separate com ponents. Ideally, we expect an image with three com ponents: the background, the right hand and the left hand. Fig. 3: A screenshot of original and segmented videos For the classification, hi stogr am approach is used as proposed in [7] . Double thresholding i s used to ensure co nnectivity, and to av oid spikes in the binary image. We prefer HSV color space as Jayaram et al. [7] and Albiol et al . [8] propose. HSV is preferred because of its robustness to changing illum ination conditions. The scheme is com posed of training the hi stogram and threshold values for future use. We took 135 random snapshot images from our training video database. For each snapshot, ground truth binary images were const ructed for the true position of the hands. Using the ground truth images, we have constructed the histogram for the left and right hands, resulting in two different histograms. Fi nally, norm alization is needed for each histogram such that the values lie in the interval [0,1]. The low and high threshold values for double t hresholding are found in training period. When singl e thresholding is used, a threshold value is chosen according to the miss and false alarm rates. Si nce we use double thresholding, we use an iterative scheme to minimize total error. We iteratively search for the minim um tota l error. This search is done in the range [ μ - δ , μ + δ ] to decrease the running time, where μ is the mean and δ is the standard deviation of t he histogram. Fig. 2: Sign Language Tutoring Tool GUI After classificati on by using the scheme described above, eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report we observed that some confusing colors on the subject’s clothing were classified as hand pi xels. To avoid this, we selected the largest connected com ponent of the cl assified regions into consideration. T hus we had onl y one component classified as hand for each color. This classification approach can also be used for different col ored gloves or skin after changing t he ground truth i mages in the training period. B. Hand mot ion analysis The analysis of hand mot ion is done by tracking the cent er of m ass (CoM) and calculating th e velocity of each segm ented hand. However, these hand trajectories are noisy due to noise introduced at the segmentation step. Thus, we use Kalm an filters to smooth the obtained trajectories. The motion of each hand is approximated by a constant velocity motion m odel, in which the acceleration is neglected. Two independent Kalman filters are used for each hand. The initialization of the Kalm an Filter is done when the hand is first detected in the video. At each sequential frame, Kalman filter time update equations are calculated to predict the new hand position. The hand posit ion found by the hand segmentation is used as measur ements to correct the Kalman Filter parameters. Posterior states of each Kalman filter is defined as feature vectors for x, y coordinates of CoM and velocity. The hand can be lost due to occlusion or bad lighting in some frames. In that case, Kalman Filter prediction is directly used without correcti ng the Kalman Filter parameters. The hand is assumed to be out of the camera view if no hand can be detected for some num ber of (i.e. six) consecutive frames. Fig. 4 shows the extr acted trajectories for each hand for the “fast” sign. Fig. 4. Hand trajectories for sign “fast ” C. Hand shape anal ysis Hand shape analysis is perform ed during sign recogniti on in order to increase the accuracy of recognition system and to differentiate between si gns that differ only i n hand shape. Each sign has a specific movement of the head, hands and hand postures. The extreme sit uation is when two signs have the same m ovement s of head and hands and they differ only in hand postures. In this case, hand shape analysis is necessary to distinguish between them . Another application can be in si gn synthesis. If we anal yze an unknown gest ure and want to synthesize it with the sam e moveme nts to caricature the movements of the actor, then finger and palm movem ents may be synthesized by foll owing these steps: 1) unknown hand shape is classified into one of predefined clusters, 2) hand posture synthesis of classified cluster is performed (synthesis is prepared for each cluster). This can be useful whenever it is difficult to analyze finger and palm positions direct ly from im age, for example when only low resolution images are av ailable. This was the case in this project – each hand shape image was smaller than 80x80 pixels. 1) Input – binary image After the segment ation of the source im age is done, two bi nary images (onl y two colours representing background and hand) of left and right hand are analy zed.The mirror reflecti on of the right hand is taken so we anal yze both hands in the same geom etry; with thum b to the right. There are several difficulties using these images: 1. Low resol ution (max. 80 pixel s wide in our case) 2. Segm entation errors due to blurri ng caused by fast movem ent (see Fig. 5b) 3. Two di fferent hand postures can have the same binary im age (see Fig. 5a; which can be left hand observed from top or right hand from bottom ) Fig.5. Two different hand segm entations: a. Hand shape 1; b. hand shape 2 2) Hand shape anal ysis – feature extracti on The binary image is converted into a set of numbers which descri be hand shape, yielding t h e feature set. The aim is to have simil ar values of features for simi lar hand shapes and distant values for different shapes. It is also requi red to have scale invariant features so th at images with the same hand shape but different size would have the sam e feature values. This is done by choosing features whi ch are scale invariant . Our system uses only a singl e camera and our features do not have depth informati on; except for the foreshorteni ng due to perspective. In order to keep this informat ion about the z- coordinate (depth), five of the 19 features wer not normalized. All 19 features are listed in TABLE II . TABLE II. HAND SHAPE FEATURES invariant # feature scale rotation 1 Best fitting ellipse width 2 Best fitting ellipse height eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report invariant 3 Compactness (perimeter 2 /area) 4 Ratio of hand pixels outside / inside of ellipse 5 Ratio of hand / background pi xels inside of ellipse 6 sin (2* α ) α = angle of ellipse major axis 7 cos (2* α ) α = angle of ellipse major axis 8 Elongation (ratio of ellipse major/m inor axis length) 9 Percentage of NW (north -west) area filled by hand 10 Percentage of N area filled by hand 11 Percentage of NE area filled by hand 12 Percentage of E area filled by hand 13 Percentage of SE area filled by hand 14 Percentage of S area filled by hand 15 Percentage of SW area filled by hand 16 Percentage of W area filled by hand 17 Total area (pixels) 18 Bounding box width 19 Bounding box height An initial idea was to use “high level” knowledge about the shape such as finger count, but the problems li sted previously caused us to use more low level features, which are robust to segmentation errors and work well with low resolution images. Seven of the features (#1,2,4,5,6,7,8) are based on using the b est fitting ellipse (in least-squares sense) to a binary image, as seen in Fig. 6a.. The angle α is a value from 0° to 360°. However, only only values from 0 to 180 are m eaningful, because the ellipse has mirror sym metry. Hence only 0° to 180° interval is used. Another problem is the following: Consider 5° and 15° ellipses, wh ich have similar angles and similar orientation. 5° a nd 175° ellipses have similar orientations as before, but t he angles are com pletely different. In order to represent this difference, we use sin(2* α ) and cos(2* α ) as features. Fig. 6 a. Best fitting ellipse; b . Area filters Features #9 to 16 are based on u sing “area filters”, as seen in Fi g. 6a. The bounding box of the hand is divi ded into eight areas, in which percentage of hand pixels are cal culated. Other features in TABLE II, are perimeter, area and boundi ng box width and height. 3) Cla ssification Hand shape classification can be used for sign synt hesis or t o improve the recognition: The cl assified cluster can be used as new feature: We can use hand features for recognition only when the unknown hand shape is classified into a cluster (this means that the unknown hand shape i s simila r to a known one and not to a blurred shape which can have misl eading features). We have tried classification of hand shapes i nto 20 clusters (see Fig. 7 “clusters”). Each cluster is represented by approximate ly 15 templ ates. We use K-means algorit hm (K=4) to classify unknown hand shape (represented by set of features described above). If the distance of unknown shape and each cluster is greater than 0. 6 then this shape is declared as unclassified. Fig. 7. a.The hand clusters; b.Sim ilarity of clusters As seen in Fig. 7b, some of the clusters are m ore similar t han the others. For example, clusters 12, 14 and 19 are similar; so it is more difficult to correctly classify the unknown shape into one of these clusters. 0 5 10 15 20 25 30 35 40 45 50 0 0. 5 1 1. 5 2 2. 5 3 3. 5 4 4. 5 5 Clas s i fic at ion ex am ple: Dis t anc es bet ween unknown hand s hape and 20 c l us t ers fram e di st anc e bet ween unk nown hand s hape and c lus t er Fig. 8 Classificati on example: dist ances between an unknown hand shape and cent er of 20 clusters. a .[best fitting ellipse] b. [area filters] white: areas wi thout hand green: areas with hand each row and column (1 to 20) represents 1 cluster. darker point = more similar c lusters a. Clusters b. Sim ilarity of Clusters eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report Classification of hand shapes is made in each fram e of video sequence. It is reasonable to use inform ation from previous frames, because hand shape cannot change so fast in each frame (1 frame = 40ms). Usually the classification is the same as in the previous frame, as seen i n Fig. 8, where an unknown shape is classified into a clus ter with the smallest distance. To avoid fast variations of classi fications we proposed a filter which smoothes these distances by weighted averagin g Fig. 9 shows a classificatio n example with filtering. 0 5 10 15 20 25 30 35 40 45 50 0 0. 5 1 1. 5 2 2. 5 3 3. 5 4 4. 5 5 fram e dis t anc e bet ween unk nown hand s hape and c lus t er [ f il t ered] Clas s i fic at ion ex am ple: Dis t anc es bet ween unknown hand s hape and 2 0 cl us t ers [fi lt ered ] Fig. 9 Classificati on example: dist ances between an unknown h and shape and center of 20 clusters (filtered). The new distance is calculat ed by the following equation: D new (t) = 0.34 · D old (t) + 0.25 · D old (t-1) + 0.18 · D old (t-2) + 0.12 · D old (t-3) + 0.07 · D old (t-4) + 0.04 · D old (t-5) By comparing Fig. 8 and 9 , one can see that this filter p revents fast changes in frames 5 and 6. This filter is designed to work in real-time applications. If used in offline application, it can easil y be changed to use informati on from the future to in crease the accuracy. D. Head mot ion analysis 1) General Overview of the system Once a bounding box around the sign language student’s face has been detected, rigid head m otions such as head rotations and head nods are detected by using an algorithm working in a way close to the hum an visual system. In a first step, a filter inspired by the modeling of the human retina is applied. This filter enhances moving contour s and cancels static ones. In a second step, the fast fouri er transform (FFT) of the filtered image is computed in the log polar domain as a model of the prim ary visual co rtex (V1). This step allows extracting two types o f features: the quantity of motion and motion event alerts. In parallel, an optic flow algorithm extracts both vertical and vel ocity inform ation only on the motion events alerts provided by the visual cortex stage. Fig. 10 gives a general overview of the algorithm . This module provides th ree features per frame: the quantity of motion, horizontal velocity and vertical velocity . Fig. 10: Algorit hm for rigid head m otion data ext raction 2) Description of the components The first step consists in an efficient prefiltering [9] : the retina OPL (Outer Plexiform Laye r) that enhances all contours by attenuating spatio-tem poral noise, correcting lum inance and whitening the spectrum (see Fig. 2). The IPL filter (Inner Plexiform Layer) [9] removes the static cont ours and extracts m oving ones. This pr efiltering is essential for data enhancement and all ows minim izing the comm on problems of video acquisition such as lum inance variations and noi se. The second step consists in a frequency analysis of the IPL filter output around the face whose response is presented on Fig.11. By com puting the total energy of the am plitude spectrum of this output, as described in [10] , we have i nformation that depends linearly on the m otion. The tem poral evolution of this signal is the first data that is used in the sign language analyzer. Fig. 11: Retina preprocessi ng outputs: extraction of enhanced cont ours (OPL) and moving contours (IPL) In order to estimate the rigid head rot ations [10] , the proposed method analyses the spectrum of the IPL filter output in the log polar dom ain. It first detects head motion events [11] and is also able to extract its orien tation. Then, in order t o complete t he description of the velocity , we propose to use features based o n neuromorphic optical flow filters [12] wh ich are orien ted filters able to compute the velocity of th e global head. Finally , optical flow is com puted only when motion alert s are provided and its ori entation is compared to the result given by the spectrum analysis. If the information is eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report redundant, then we extract the velocity value at each fram e, either horizontal o r vertical in order to simplify the system. • Al l the frames at the begi nning of the sequence are eliminated until the hand is d etected. • If the hand can not be detected at the middle of the sequence for less than N frames, the shape information is copied from the last frame where there is detection. 3) Extracte d data sample In the end, the head analyzer is abl e to provide three signals per frame, information related to th e quantity of motion and the vertical and horizontal velocity values. Fig. 12 shows two examples of the evolut ion of th ese signals, first in the case of a sequence in which the person expresses an affirmative « Here », second in the case of the expression of the sign «Very clean ». For the first sign, the head motion i s a sequence of vertical head nods . Then, the quantity of motion indicator shows a periodic variation of its values wi th high amplitude for maximum velocity. The vertical velocity presents non zero values only during m otion and also exhibits a periodic variation. On the contrary, the horizontal velocity indicator remains at zero. The « Very clean » sign consists of two opposite horizontal head mo tions. The quantity of motion indicator exhibits them . This tim e, the horizontal m otion reports the velocity si gn and amplitude variations while the vertical velocity in dicator remains at zero. On this last sequence, we can see that some false alarm s can be generated at the velocity ou tput level: For example, at fram e 68, a false horizontal moti on is detected, but since the val ue of the quantity of motion is low, this velocity should not be taken into account. This is the advantage of using two det ection signals: the cortex analysis mode l helps the velocity analyzer. • If the hand can not be detected for m ore than N consequent frames, the si gn is assumed to be finished. Rests of the fram es including the last N frames are eliminated. • Aft er indicating the start and end of the sequence and eliminating the unnecessary frames the transition frames can be eliminated by deleting T frames from the start and end of the sequence. B. Si gn features and normaliz ation issues 1) Hand mot ion features The trajectories must be further norm alized to obtain translation and scale invariance. We use a similar normalizat ion strategy as i n [13] . The normalized trajectory co ordinates are calculated with the following formulas: Fig. 12: Data extracted by the head analyzer IV. S IGN LANGUAGE RECOGNITION A. Preprocessi ng of sign sequences The sequences obtained from t he videos contain parts where t he signer is not performing the sign (start and end parts) and some parts that can be considered as transition frame s. These frames of the sequence are elim inated by looking at the resul t of the segmentation step: Let (;...;;...;) be the hand trajectory where N is the sequence length. For translation normalizat ion, define x m and y m : x m = (x + x ) / 2 max min y m = (y + y ) / 2 max min where x m and y m are the mid-point s of the range in x and y coordinates respectively. For scal e normalizat ion, define d x and d y : d x = (x / x ) / 2 max min d y = (y / y ) / 2 max min where d x and d y are the amount of spread in x and y coordinates respectively. The sca ling factor is selected to be the maxim um of the spread in x and y coordinates, since scaling with different fact ors disturbs the shape. d = max(d x ; d y ) ;y ′ >;...;; ...;) such that 0 <= x ′ N N t , y ′ t <= 1, are then calculated as follows: x’ t = 0.5 + 0.5 (x t - x m ) / d y’ t = 0.5 + 0.5 (y t - y m ) / d Since the signs can be also two handed, both hand t rajectories must be norm alized. However, normaliz ing the trajectory of the two hands independently m ay result in a possible loss of data. To solve this problem , the mi dpoints and the scaling factor of left and right hand t rajectories are calculated jointly. Fo llowing this normalization step, the left and right hand trajectori es are translated such that their starting posit ion is (0,0). eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report 2) Hand position features In sign language, the position of the hand with respect to the body location is also im porta nt. We integrated position information by calculating the distance of the CoM of each hand to the face CoM. The distance at x and y coordinates are normalized by the face width and height respectively. 3) Hand shape f eatures All 19 hand shape features are nor m alized into values between 0 and 1. Features calculated as percenta ge (0 to 100%) are just divided by 100. The rest of features i s normalized by using this equation: F normalized = (F - min) / ( m ax – mi n) where min i s minim al value of feature (in t raining dataset) and max is maxim um value. In case smaller or greater value occurs, F normalized is truncated to stay in <0,1>. 4) Head mot ion features Head motion analy sis provides three features that can be used in the recognition: mot ion energy of the head, horizontal and vertical velocity of the h ead. However these features are not invariant to differences t h at can exist between different performances of the same sign. Moreover, the head m otion is not directly sy nchronized with the hand m otion. To handle inter and intra personal differences, adaptive sm oothing is applied to head motion features where α is used as 0.5: F i = α F i + (1 - α ) F i-1 This smoothing has an effect of cancell ing the noise between di fferent performances of a sign and creating a smoot her pattern. C. HMM model ing After sequence pre-processing and normali zation, HMM m odels are trained for each sign, using Baum-Welch algorithm. We have t rained 3 different HM Ms for com parison purposes: • HM M manual uses only hand inform ation. Since hands form the basis of the signs, these models are expected to be very powerful in classificat ion. However, absence of the head motion i nformation prohibi ts a correct classification when the only difference of two signs is related to the head motion (i.e. here, ishere and not here) • HM M manual&nonmanual uses hand and head information. Since there is not a direct synchroni zation between hand and head motions, these m odels are not expected to have much better performance than HMM manual . However using head information results in a slight increase in the performance. • HM M nonmanual uses only head information. The head motion is com plementary of the sign thus it can not be used alone to classify the signs. A data fusion methodology is needed to utilize these models together with m odels of manual com ponents. D. Fusion of different m odalities of sign language We have used a sequential score fusion strategy for com bining manual and non-manual parts of the sign. We want our system to be as general as possi ble and capable of extending the sign set without changing the recognition system. Thus, we do not use any prior knowl edge about the sign classes. For exampl e, we know that here, ishere and nothere have exactly the same hand inform ation but the head informati on differs. Using this pr ior inform ation as a part of the recognition system increases the perform ance however the system looses its extendibility for upcom ing signs since each sign will require a similar prior information. Instead we choose to extract the cluster inform ation as a part of the recognition system . Base decision is given by an HMM whi ch uses both hand and head features in the sam e feature vector. However, the decision of these models is not totally correct since the head information is not utilized well. We used the likelihoods of HMM nonmanual to give the final decision. Fig. 13. Sequential fusion st rategy 1) Training • During training, models for each sign class are trained for HMM manual&nonmanual and HMM nonmanual. • The cluster information for each sign is extracted from the confusion m atrix of HM M manual&nonmanual . In the confus ion matrix of the validation set the misclassifications are investigated. If all exam ples of a sign class are classified co rrectly, the cluster of th at sign class only contains itself. For each misclassification, we add that sign class to the cluster. 2) Testing The fusion strategy (Fig. 13) for an unseen test exam ple is as follows: • Li kelihoods of HMM manual&nonmanual for each sign class are calculated and the sign class with the maximum likelihood is selected as the base decisi on. • Selected sign and its cluste r information are sent to HMM nonmanual . • HM M nonmanual likelihood of the selected si gn is calculated as well as t he likelihoods of the signs in its cluster. • Am ong these likelihoods, the sign cl ass with the max imum HM M nonmanual likelihood id selected as the final decision. eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report V. S YNTHESIS AND A NIMATION A. Head motion and facial expression synt hesis The head synthesis perform ed in the present project is based on the MPEG-4 Facial Anim ation Standard [14] , [15] . In order to ease the synthesis of a virtual face, the MPEG-4 Faci al Animation (FA) defines t wo sets of parameters i n a standardized way. The first set of parameters, the Facial Definition Param eter (FDP) set, is used to define 84 Feature Points (FP), located on morphol ogical places of the neutral head, as depicted in Fig. 14 (black poi nts). The feature points serve as anchors for 3D face deformable m eshes, represented by a set of 3D vertices. The second set defined by the MPEG-4 Standard i s the Facial Animation Parame ter (FAP ) set. The Facial Animation Parameters (FAPs) represent a complete set of basic facial actions closely rela ted to muscle m ovement s and therefore allow the representation of faci al expressions by m odifying the positions of the previously defined feature poi nts (FP). They consist of a set of 2 hi gh-level (visem es and 6 archet ypal emotions) and 66 low-level parameters (depicted as white filled points on Fig. 14). In this project, we only u se the low- level parame ters which are basic deform ations applied to specific morphological places of the face, like the top middle outer-lip, the bottom right eyelid, etc... Fig. 15 : Head synthesis system archit ecture Fig. 14. The 3D feature points of the FDP set The head synthesis system arch i tecture is depicted on Fig. 15. As input, we receive the de tected gesture (one data per sequence), the IPL energy, and the vertical and horizontal velocity of the head motion (as much data as frames in the sequence). W e then filter and normalize these data in ord er to compute the head m otion during the considered sequence. The result of the processing is expressed in terms of FAPs so that we can output a FAP file. The FAP file for the considered sequence is fed into the anim ation player. The animation player we used is an MPEG-4 compliant 3D talking head animati on player developed by Fig. 16. Rendered head with different input values B. Hands and arms synt hesis For the hands and arms synthesis, we use a library of predefined positions for each gest ure. Each animation has key positions (the positions t hat define the gesture) and interpolated positi ons. To creat e an animation we only need to set the key positions i n the correct frames depending on the speed we want to get, and then interpolate the rest of the frames. [16] , part of an open source tools set available at [17] . Once rendered, we finally out put an avi file containing t he head synthesis sequence. Fig. 16 shows an example rendering wi th respect to the input data. For our system, we need to do two different adapt ations: speed adapt ation, and position adaptation. The gesture detected is supposed to be closer to i ts predefined one, so we eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report can define a set of steps th at will be the same for each synthesis. To create an animation from th e features com municated by the analysis m odule, we have to follow the following st eps: 1. Physical features extracti on: from the input file, we extract the information about th e head position, the length of the arms, and the m aximal and minim al values of the hands coordinates (x,y). Th ese will be used to normalize the information in order to ad apt the system to our avatar features. Fig. 17 : Arms sy stem and m ain features. 2. Speed features extraction: For each gesture, we need to find the fram es where the speed changes the most (border frames), because these fram es will define our key positions. We find these features by diffe rencing the coordinates of each frame and the next one. If t he variation is smal ler than a threshold we have set, it is supposed to be the same position than the last fram e. It is necessary to know how much time we have to hold a position. With th is extracti on we have defined the frames where we will set the key positions. 3. Physical adaptati on and position definition: W e can adapt the the parameters of our avatar according to the analysis result s. Depending on the mi nimal and maxi mal values, we have extracted for x and y , we choose two predefined positions for each border frame, and then we interpolate these posit ions to get a new one. All positions we get here will be our k ey positions. Fig. 18 : System structure for hands and arms sy nthesis. 4. Set positions depending on the speed f eatures: To set the positions we have created, we take t he border frames defined in step 2. We set the key posit ions for the border frames, holding them i f necessary. After this, we only need to interpolate the rest of th e frames, to get the final animation. From the final animation we will generate the video output that will be represented with the head result to show the complete avat ar playing the gesture that t he person in front of the camera did. VI. R ECOGNITION RESULTS We have used 70% of the signs in the database for traini ng and t he rest for testing. The distri butions of sign classes are equal both in training and test sets. Confusion ma trices and performance results are reported on the test set. The confusion matri x of HMMs that are trained by using only hand information is shown in TABLE III. The total recognition rate is 67%. However, i t can be seen that m ost of the misclassificati ons are between the sign groups where the hand information is the same or similar and the main difference is in the head in formation, which is not utilized in this scheme. When sign clusters are taken into account, there are only five misclassifications out of 228; resulting in a 97.8% recognition rate. TABLE III. CONFUSION MATRIX. (ONLY HAND INFORMATION) The confusion matrix of HMMs that are trained by the combined feature vector of hand and head inform ation is shown in TABLE IV . The total performance is 77%. All misclassi fications, except one, are between the sign groups. Although there is a slight increase in the perform ance, this fusion method does not utilize the head inform ation effectively. Therefore, we have adopted the sequential fusion fusion strategy described i n Section IVD. The confusion matri x of the sequential fusi on methodol ogy is sh own in TABLE IV. The total performance is 85.5%. The misclassi fications between the sign groups are very few except for the study and look at sign groups. The reason of these misclassifications can be related to the deficiency of vision hardware or to the m isleading feature values: • The st udy sign: The confusion between st udy regularly and study continuously can stem from a deficiency of the 2D capture system. These two signs d iffer m ainly in the third dime nsion, which we cannot capture. The confusi on between study and study regularly can be a result of over- smoothing t he trajectory. • For the look at sign, the hands can be in front of t he head for many of the fram es. For those frames, the face detector may fail to detect the face and may provide wrong feature values which can m islead the recognizer. eNTERFACE’06, July 17 th – August 11 th , Dubrovnik, Croatia ⎯ Final Project Report Manual sign classification perform ance is 99.5%, which means only one si gn is miscla ssified out of 228. TABLE IV. CONFUSION MATRIX. FEATURE LEVEL FUSION TABLE 3. CONFUSION MATRIX. SEQUENTIAL FUSION VII. C ONCLUSIONS AND FUTURE WORK In this project, we have developed a si gn tutor applicat ion t hat lets users learn and pr actice signs from a predefined library. The tuto r application records the p racticed signs; analyses the hand shapes and moveme nts as well as the head movem ents, classifies the sign, and gi ves feedback to the user. The feedback consists of both t ext inform ation and synthesized video, which shows t he user a caricaturi zed version of his movem ents when the sign is correctly classified. Our performance tests yield a 99% recognit ion rate on signs involving manual gestures and 85% recognition rate on signs that involve both manual and non manual com ponents, such as head movem ent and facial expressions. A CKNOWLEDGMENT We thank Jakov Pavlek and Vjekoslav Levacic, who have vol unteered to be in the sign database. R EFERENCES [1] H-K. Lee, J-H Kim , “Gesture spotting from continuous hand motion” in Pattern Recognition Letters , 19( 5-6), pp. 513-520, 1998. [2] T. Starner and A. Pentland. “Realtime american sign language recognition from video using hidden mar kov models”. Technical repor t, MIT Media Labor atory, 1996 . [3] C. Vogler and D. Metaxas.”Adap ting hidden m arkov m odels for asl recognition by using three-dim ensional computer vision m ethods”. In Conference on Systems, Man and Cybernetics (SMC’97) , Orlando, FL, pages 156–161, 1997. [4] C. Vogler and D. Metaxas. “A SL r ecognition based on a coupling between HMMs and 3D motion analysis”. In International Conference on Computer Vision (ICCV’98), Mumbai, India, 1998. [5] Ong, S. Ranganath. “Automatic Si gn Language Analysis: A survey and the Future beyond Lexical Meaning”, IEEE Transactions on PAMI, vol.27, no.6, pp.873-891, June 2005. [6] O. Aran, C. Keskin, L. Akarun, “Sign language tutoring tool”, in Proceedings EUSIPCO’05, September 2005. [7] Jay aram S. , S. Schmugge, M . C. Shin, and L. V. Tsap, " Effect of Colorspace Transformation, the I llum inance Component, and Color Modeling on Skin Detection," c vpr, pp. 813-818, 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'04) - Volum e 2, 2004. [8] Albiol, A., L. Torres, and E. J. De lp, "Optim um colo r spaces for skin detection", Proceedings of IEEE International Conference on Image Processing, Vol. 1, 122--124. , 2001. [9] Beaudot W ., "The neural inform ation processing in the vertebra te retina: A melting pot of ideas for artifficial vision" , PhD Thesis in Computer Science, INPG (France) december 1994. [10] Benoit A. , Caplier A. "Head Nods Analysis: Interpretation of Non Verbal Com munication Gestures" IEEE, ICIP 2005, Genova, Italy [11] Benoit A. , Caplier A. "Hypovigilence Analysis: Open or Closed E ye or Mouth ? Blinking or Yawning Fre quency ?" IEEE, AVSS 2005, Como, Italy [12] T orralba A. B., Herault J. ( 1999). "An efficient neurom orphic analog network for motion estimation." IEEE Transactions on Circuits an d Systems-I: Special Issue on Bio-In spired Processors and CNNs for Vision. Vol 46, No. 2, February 1999. [13] Oy a Aran, Lale Akarun "Recognizing two handed gestures with generative, discrim inative and ensemble m ethods via Fisher kernels" , International Workshop on Multimedia Content Representation, Classification and Security, (M RCS’06) , Istanbul, September 2006. [14] M. Tekalp, Face and 2D m esh animati on in MPEG-4, Tutorial Issue On The MPEG-4 Standard, Im age Comm unication Journal, Elsevier, 1999. [15] I.S. Pan dzic & R. Forchheimer, MPEG-4 Facial Animation: The standard, implem entation and applications, Wiley, 2002. [16] K. Balci, XfaceEd: authoring tool for em bodied conversational agents, 7th International Conference on Multimodal Interfaces (ICMI ’05), 2005. [17] http://xface.itc.it/index.html [18] M achine Perception Toolbox (MPT) http://mplab.ucsd.edu/grants/project 1/free-software/MPTWebSite/API/]. [19] Kevin M urphy , “Bayes Net Toolbox for M ATLAB., http://bnt.sourceforge.net/ [20] I ntel Open Source Computer Vision Libr ary, http://opencvlibrary.sourceforge. net/ AP PENDIX : S OFTWARE NOTES Since the individual part s in this project were coded in C , C ++ and MATLAB, we preferre d MATLAB to combine them for the tutor. MATLAB GUI was used to prepare the user interface. We used the “Machine Perception Toolbox” [18] for head an alysis. For HMM training, HMM routin es in [19] are used. W e also used “Intel Open S ource Computer Vi sion Library” [20] routines in our project.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment