시각 기반 손·머리 움직임 통합 인식으로 구현한 수화 튜터링 시스템
본 논문은 컬러 장갑과 얼굴 마스크를 이용해 손과 머리·얼굴 움직임을 동시에 추출하고, 각각을 HMM으로 모델링한 뒤 순차적 융합을 통해 19개의 미국 수화(ASL) 동작을 인식한다. 손 동작만을 대상으로는 99 %의 정확도, 손·비수동(머리·표정) 복합 동작에서는 85 %의 정확도를 달성하였다. 인식 결과를 텍스트와 카툰 형태의 합성 영상으로 피드백해 주는 튜터링 애플리케이션을 구현하였다.
저자: ** - Oya Aran¹ - Ismail Ari¹ - Alex, re Benoit² - Ana Huerta Carrillo³ - François‑Xavier Fanard⁴ - Pavel Campr⁵ - Lale Akarun¹ - Alice Caplier² - Michele Rombaut² - Bulent Sankur¹ ¹ Bogazici University, Türkiye ² LIS_INPG
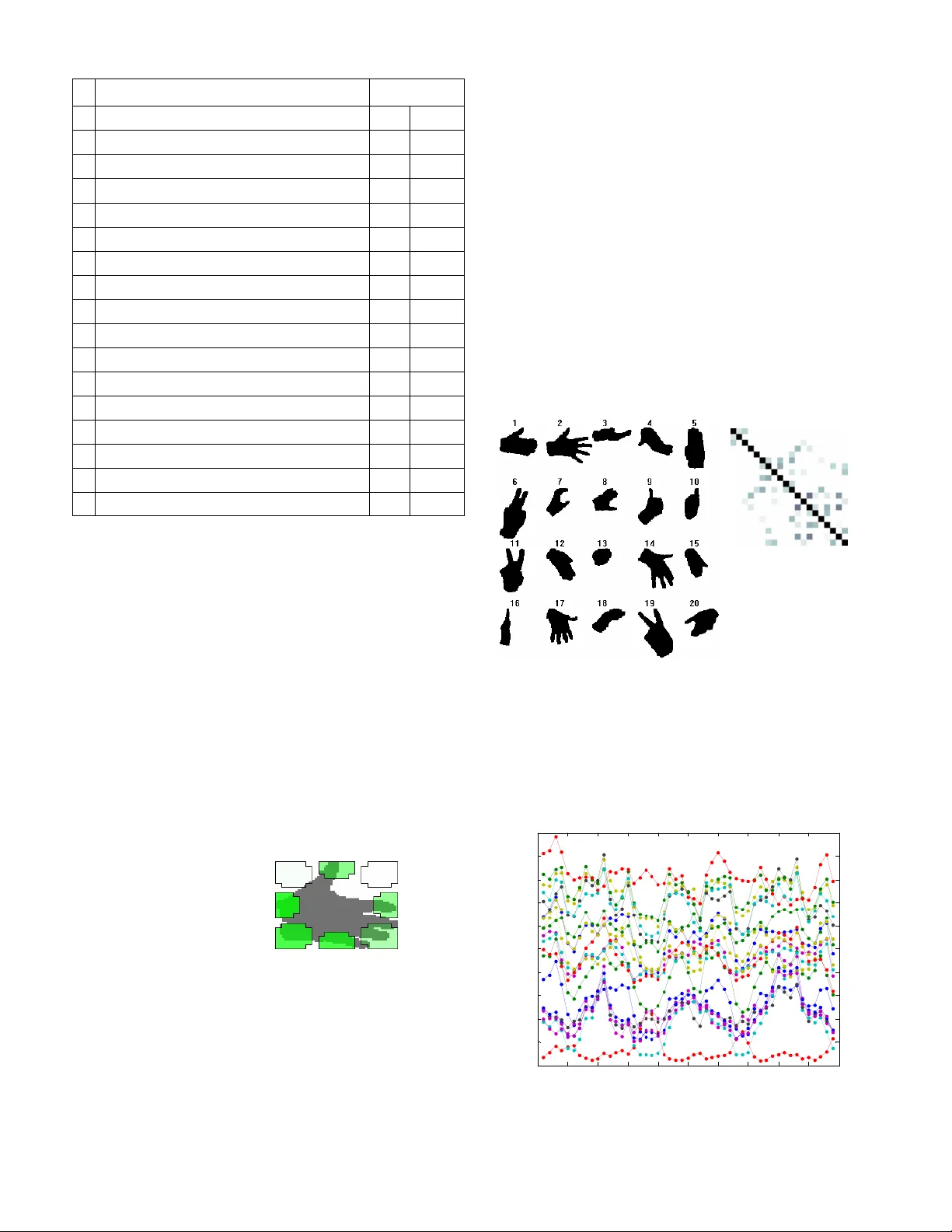
본 논문은 수화 학습자를 위한 튜터링 도구를 개발하고, 그 구현 과정과 성능을 상세히 보고한다. 시스템은 크게 네 단계로 구성된다. 첫 번째 단계는 입력 영상에서 손과 얼굴을 검출·분할하는 전처리이다. 사용자는 양손에 서로 다른 색상의 장갑을 착용하고, 얼굴은 마스크 없이 촬영한다. 손 검출은 HSV 색공간에서 각각의 장갑 색에 대한 히스토그램을 사전 학습하고, 이 히스토그램을 기반으로 이중 임계값(thresholding) 방식을 적용해 배경과 손을 구분한다. 이 과정에서 색상 혼동을 최소화하기 위해 가장 큰 연결 요소만을 손 영역으로 선택한다.
두 번째 단계는 손 움직임 분석이다. 손 영역의 중심 질량(CoM)을 매 프레임마다 계산하고, 이를 Kalman 필터에 입력해 속도와 위치를 스무딩한다. 필터는 손이 일시적으로 가려지거나 조명 변화가 있을 때도 예측값을 사용해 연속성을 유지한다. 손의 궤적은 이후 HMM 학습에 사용되는 연속적인 좌표 시퀀스로 변환된다.
세 번째 단계는 손 형태 특징 추출이다. 손 영역을 80 × 80 픽셀 이하의 이진 이미지로 축소한 뒤, 19개의 저차원 특징을 계산한다. 여기에는 타원 적합을 통한 폭·높이·주축·부축 비율, 컴팩트니스, 타원 축 각도의 사인·코사인, 영역 비율(북·동·남·서 등 8방향 채워짐 비율) 등이 포함된다. 일부 특징은 스케일·회전 불변성을 유지하도록 설계했으며, 깊이 정보를 보완하기 위해 5개의 특징은 정규화하지 않았다. 이러한 특징은 저해상도에서도 손 모양을 구분하는 데 충분히 강인하였다.
네 번째 단계는 비수동 요소인 머리·얼굴 움직임 분석이다. 얼굴 검출 후 인간 시각 시스템(HVS) 기반 모션 에너지와 속도를 계산해 머리, 눈, 눈썹, 입술의 움직임을 정량화한다. 이 특징들은 별도의 HMM에 입력되어 비수동 사인을 모델링한다.
인식 모델은 두 종류의 HMM을 사용한다. 첫 번째는 손 동작(위치·속도·형태) 전용 HMM이며, 각 수화에 대해 좌-우 연속 HMM을 학습한다. 두 번째는 비수동 HMM으로, 머리·표정 변화를 모델링한다. 최종 판단은 순차적 융합 방식으로 이루어진다. 먼저 손 HMM이 가장 높은 확률을 보인 사인을 후보로 선택하고, 비수동 HMM이 해당 후보의 변형(예: 같은 손동작에 다른 머리 움직임) 중 어느 것이 맞는지 추가 판단한다. 이를 통해 손동작만으로는 구분이 어려운 복합 수화를 정확히 인식한다.
데이터베이스는 미국 수화(ASL)에서 19개의 동작을 선정하였다. 이 동작들은 모두 머리·표정이 의미를 바꾸는 경우가 포함돼 있어 비수동 인식의 필요성을 강조한다. 각 동작은 8명의 피험자가 5회씩 수행해 총 760개의 영상 샘플을 확보했으며, 영상 해상도는 640 × 480 픽셀, 프레임 레이트는 25 fps이다.
시스템 구현은 C++와 OpenCV 기반이며, GUI는 네 개의 패널(Training, Information, Practice, Synthesis)로 구성된다. 사용자는 Training 패널에서 교사 영상을 시청하고, Practice 패널에서 자신의 영상을 촬영한다. 인식 결과는 Information 패널에 텍스트와 색상으로 표시되며, “ok”, “false”, “head ok but hands false” 등 세부 오류 정보를 제공한다. 또한 원본 영상과 분할 영상을 비교해 볼 수 있다. Synthesis 패널에서는 인식된 수화를 텍스트와 함께 카툰 형태의 합성 영상을 재생해 사용자가 올바른 동작을 시각적으로 확인하도록 돕는다.
성능 평가 결과, 손동작만을 포함한 경우 99 %의 인식률을 기록했으며, 손·비수동을 모두 포함한 복합 동작에서는 85 %의 인식률을 달성했다. 이는 비수동 요소 추출·모델링이 아직 개선 여지가 있음을 보여준다. 또한 실험은 실내 고정 조명과 단순 배경에서 수행되었으며, 피험자 수가 8명에 불과해 일반화 가능성에 제한이 있다.
논문의 주요 기여는 다음과 같다. (1) 손·머리·표정을 동시에 추출하고 HMM으로 모델링한 통합 인식 프레임워크 제시, (2) 저해상도 영상에서도 강인한 손 형태 특징 설계, (3) 순차적 HMM 융합을 통한 복합 수화 구분 방법, (4) 인식 결과를 텍스트와 카툰 합성 영상으로 피드백하는 인터랙티브 튜터링 애플리케이션 구현. 한계점으로는 장갑 착용에 의존하는 전처리, 제한된 어휘·피험자 규모, 비수동 인식 정확도 향상이 필요함을 들 수 있다. 향후 연구에서는 장갑 없이 피부색 기반 손 검출, 딥러닝 기반 멀티모달 특징 학습, 실시간 스트리밍 환경에서의 평가 등을 통해 시스템의 실용성을 높일 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기