Rollout Sampling Approximate Policy Iteration
Several researchers have recently investigated the connection between reinforcement learning and classification. We are motivated by proposals of approximate policy iteration schemes without value functions which focus on policy representation using …
Authors: Christos Dimitrakakis, Michail G. Lagoudakis
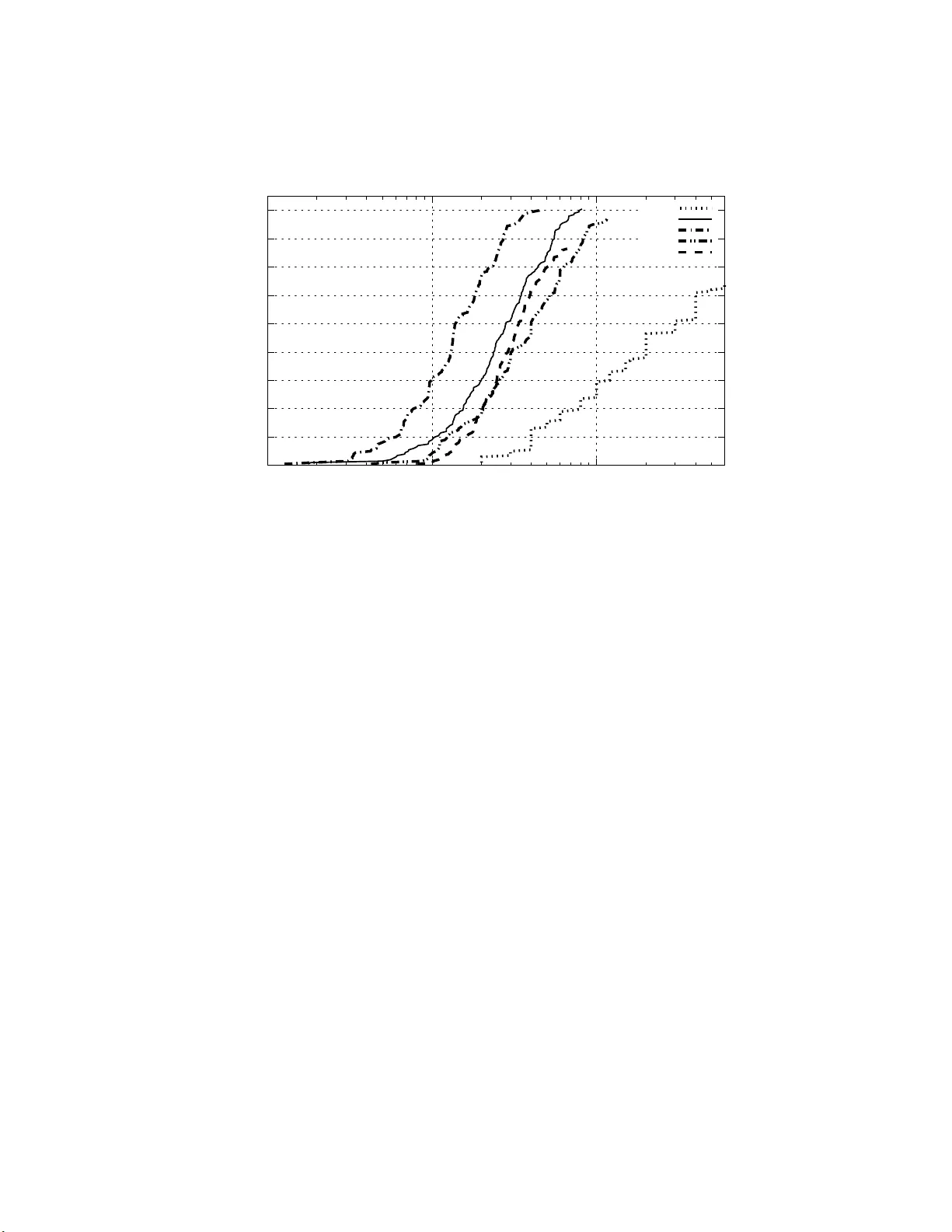
Rollout Sampling Appro ximate P olicy Iterati on Christos Dimitrak akis Mic hail G. Lagoudakis No v ember 10, 202 1 Abstract Several researc hers hav e recently inv estigated the connection betw een reinforcemen t learning and classificati on. W e are motiv ated by prop osals of approximate policy iteration schemes without v alue functions, which focus on policy representa tion u sing classifiers and address policy learn- ing as a su p ervised learning p roblem. This paper p rop oses vari ants of an imp ro ved p olicy iteration scheme which addresses the core sampling problem in ev aluating a p olicy through simulation as a multi-armed ban- dit machine. The resulting algorithm offers comparable p erformance to the previous algorithm achiev ed, ho w ever, w ith significan tly less com- putational effort. An order of magnitud e improv ement is demonstrated exp erimentall y in tw o standard reinforcement learning domains: in verted p endulum and mountain-car. 1 In tro du ction Super vised and reinforcement learning are t wo w ell- known learning paradigms, which hav e b een resea rched mostly indep endently . Recen t studies have inv esti- gated the use of super vised learning methods for reinforcement lea rning, either for v alue function Lagoudakis and Parr (2003a); Riedmiller (2005) or po licy rep- resentation Lagoudak is and Parr (20 03b); F ern et al. (2004); Langfor d and Zadrozny (2005). Initial results hav e shown that p olicies can b e appr oximately rep- resented using either m ulti-cla ss classifier s o r combinations o f binary classi- fiers Rexakis and La goudakis (2008) and, ther efore, it is pos s ible to incorp or ate classification algorithms within the inner lo ops of several reinforcement learning algorithms Lago udakis and Parr (2003b); F ern et al. (2004). This viewp oint al- lows the quantification of the p erfor mance of reinforcement learning a lgorithms in terms of the p er fo rmance of classification alg orithms Langford a nd Zadrozny (2005). While a v ar ie ty of promising combinations be come po ssible through this s ynergy , her etofore ther e hav e b een limited practical and widely-applica ble algorithms. Our work builds on the work o f Lagoudak is and Parr La goudakis and Parr (2003b) who sug gested an appr oximate p o licy itera tion alg orithm for lear ning a go o d po licy r e presented as a classifier, av o iding repr esentations of a ny kind of v alue function. A t each iteration, a new p olicy/ c lassifier is pr o duced using 1 training data o btained through e xtensive sim ula tion (rollouts) of the pr evious po licy on a generative model of the pro cess. These rollouts a im at identifying better action choices ov er a subset of states in o rder to form a set of data for training the classifier representing the improved p olicy . A similar algorithm was prop osed by F ern et al. F ern et al. (2 0 04) a t aro und the s a me time. The key differences b etw een the t wo algo rithms are related to the t yp es of learning problems they are suitable for, the c ho ice of the underlying cla ssifier type, and the ex act for m of classifier training. Nevertheless, the main ideas o f pr o ducing training data using ro llouts and iter ating ov er p olicies rema in the sa me. Even though both of these studies look carefully in to the distribution of tr aining states ov er the state s pace, their ma jo r limitation r emains t he large amoun t of sa mpling employ ed a t ea ch training sta te. It is hinted Lagouda k is (2003), how ever, that great improv ement could b e a chiev ed with so phisticated management of rollo ut sampling. Our pap er sugg ests manag ing the rollout sa mpling pro cedure within the ab ov e algorithm with the g oal of obta ining co mpa rable training sets (and there- fore p o licies of similar quality), but with significantly less effort in terms of nu mber of r ollouts and computation effor t. This is do ne by viewing the set- ting as akin to a ba ndit pr oblem ov er the rollo ut states (states s a mpled using rollouts). W ell-kno wn algorithms for bandit problems, suc h as Upp er Confi- dence Bo unds Auer e t al. (20 02) and Successive Elimination Even-Dar et al. (2006), allow optimal a llo cation of r esources (r o llouts) to trials (states). Our contribution is t wo-fold: (a) w e suitably adapt bandit tec hniques for rollout management, and (b) we sug g est an impro ved statistical test for iden tifying early with high confidence states with dominating actions. In return, we obtain up to an order of magnitude impro vement ov er the origina l algorithm in ter ms of the effort needed to collect the training data for each cla s sifier. This makes the r esulting a lgorithm attractive to pr actitioners who need to a ddr ess lar ge real-world pro blems. The rema inder of the pap er is or ganized as follows. Section 2 provides the necessary bac kg round and Section 3 r eviews the or iginal alg orithm w e are based on. Subsequently , our approa ch is presented in detail in Section 4. Finally , Sec- tion 5 includes exp erimental res ults obtained from w ell-known learning domains. 2 Preliminaries A Markov De cision Pr o c ess (MDP) is a 6-tuple ( S , A , P, R, γ , D ), where S is the state spa ce of the pro ces s, A is a finite set of actio ns, P is a Marko vian transition mo del ( P ( s, a, s ′ ) denotes the pr obability of a tra nsition to state s ′ when taking action a in state s ), R is a r e ward function ( R ( s, a ) is the exp ected reward for taking action a in sta te s ), γ ∈ (0 , 1] is the discount factor for future rewards, a nd D is the initial state distr ibutio n. A deterministic p olicy π for an MDP is a mapping π : S 7→ A from states to actions; π ( s ) deno tes the action choice at state s . T he v alue V π ( s ) o f a state s under a po licy π is the expe c ted, total, discounted reward when the pro cess b egins in state s and all decisions at 2 all steps a re made a c c ording to p olicy π : V π ( s ) = E " ∞ X t =0 γ t R s t , π ( s t ) s 0 = s, s t ∼ P # . The goal of the decision mak er is to find an optimal p olicy π ∗ that maximizes the exp ected, total, discounted reward from the initial state distributio n D : π ∗ = a rg ma x π E s ∼ D [ V π ( s )] . It is w ell-known that for ev er y MDP , ther e exists at least one optimal determin- istic p olicy . Policy iter ation (PI) How ar d (1 960) is an e fficie nt metho d for deriving an optimal p olicy . It gener ates a sequence π 1 , π 2 , ..., π k of gra dually improving po licies and terminates when there is no change in the p o licy ( π k = π k − 1 ); π k is an optimal p o lic y . Impro vemen t is a chiev ed by co mputing V π i analytically (solving the linear Bellman equations ) and the actio n v alues : Q π i ( s, a ) = R ( s, a ) + γ X s ′ ∈S P ( s, a, s ′ ) V π i ( s ′ ) , and then determining the improv ed p olicy a s: π i +1 ( s ) = ar g max a ∈A Q π i ( s, a ) , Policy iteration typically terminates in a small num b er of steps. Ho wev er , it relies on knowledge o f the full MDP model, exact computation a nd r epresen- tation of the v alue function of eac h policy , and exact representation of each po licy . Appr oximate p olicy iter ation (API) is a family of metho ds, which have bee n suggested t o addr ess the “curse of dimensionality”, that is, the h uge growth in complexity as the problem grows. In API, v alue functions and p olicies a re represented approximately in some compact f o r m, but the iter ative improv ement pro cess remains the same. Apparently , the guarantees for monotonic improv e- men t, optimality , and con vergence are co mpromised. API may never conv erge, how ever in pra ctice it re a ches go o d p o licies in o nly a few iterations . In reinforcement learning, the learner in teracts with the pro ces s and t ypically observes the state and the immediate reward at every step, how ever P and R are not a ccessible. T he goal is to gradually learn a n optimal p olic y through int er action with the pro cess. At each step of int er action, the learner observes the curre n t state s , c ho o ses an actio n a , and o bs erves the r e sulting next sta te s ′ and the reward received r . In man y c a ses, it is further a ssumed that the learner has the abilit y to reset the pr o cess in any arbitra ry s tate s . This amo unt s to having a ccess to a generative mo del of the pro cess (a sim ulator ) fr om wher e the lea rner ca n dr aw a rbitrarily man y times a next state s ′ and a reward r for per forming any giv en action a in any giv en state s . Several algorithms hav e been prop osed for lear ning go o d o r even optimal po licies Sutton a nd Bar to (19 98). 3 3 Rollout Classificati on Po licy Iteration The Ro l lout Classific ation Policy Iter ation ( RCPI) a lgorithm La g oudakis and Parr (2003b); La goudakis (200 3) belo ngs to the API family a nd fo c uses o n direct pol- icy learning and representation b ypassing the need for a n explicit v alue function. The k ey idea in RCPI is to cast the pr oblem o f policy learning as a class ification problem. Thinking of states a s examples a nd of actions as clas s labels , an y de- terministic policy can be thought of as a classifier that maps s tates to actions. Therefore, po licies in RCPI a re repres ent ed (appr oximately) as gener ic multi- class clas sifiers that assign sta tes (exa mples ) to actions (class es). The pr oblem of finding a go o d p o licy is eq uiv alent to the problem o f finding a classifier that maps states to “go o d” actions, where the g o o dness of an action is measured in terms of its co nt r ibution to the long term goa l of the a gent. The s ta te-action v alue function Q π in the co nt ex t o f a fixed p olicy π provides s uch a meas ure; the a ction that max imizes Q π in s tate s is a “go o d” action, whereas a ny action with s ma ller v alue o f Q π is a “bad” one. A training set could be easily for med if the Q π v alues for all ac tio ns were av aila ble for a subset of states. The Mo nte-Carlo e s timation tec hnique of r ol louts pro vides a way of accu- rately estimating Q π at an y given sta te-action pair ( s, a ) without requiring an explicit repr esentation of the v alue fun ctio n. A rollout for ( s, a ) a mounts to simulating a tra jectory o f the pr o cess b eginning fro m s ta te s , cho osing action a for the fir s t step, and choosing actions ac c ording to the p olicy π ther eafter up to a cer tain hor izon T . The obser ved total discounted r eward is av erage d ov er a nu mber of rollouts to yield an estimate. Thus, using a sufficient amount of rollouts it is p o s sible to form a v alid training set for the improved p olicy ov er any base p olicy . Mor e sp ecifica lly , if we deno te the s equence o f co llected rewards dur ing the i -th simulated tra jectory a s r ( i ) t , t = 0 , 1 , 2 , . . . , T − 1, then the rollo ut estimate ˆ Q π ,T K ( s, a ) of the true sta te-action v alue function Q π ( s, a ) is the obse r ved total discount ed r eward, averaged ov er all K tra jectories: ˆ Q π ,T K ( s, a ) , 1 K K X i =1 ˜ Q π ,T ( i ) ( s, a ) , ˜ Q π ,T ( i ) ( s, a ) , T X t =0 γ t r ( i ) t . With a sufficient amoun t of r ollouts a nd a la rge T , w e can create an improv ed po licy π ′ from π at any state s , without requiring a mo del o f the MDP . Algorithm 1 describ es RCPI step-by-step. Beginning with any initial p olicy π 0 , a training set ov er a subset of sta tes S R is formed by q uerying the r ollout pro cedure for the state-action v alues of all actio ns in each state s ∈ S R with the purp ose of identifying the “b est” a ction and the “ba d” a c tions in s . An action is said to b e dominating if its empirical v alue is significantly greater than those o f all other actions. In RCPI this is measured in a statistical sense using a pair wise t -test, to factor out estimation erro rs. Notice that the training set contains b oth p o s itive and nega tive examples for e a ch state wher e a clear domination is found. A new classifier is tra ined using these ex amples to yield an approximate repres ent a tion of the impr oved p olicy o ver the previous one. This cycle is then rep eated un til a termination condition is met. Given the 4 Algorithm 1 Rollout Classificatio n P o lic y Iteration Input: ro llout states S R , initial p o licy π 0 , tra jectorie s K , horizon T , discount factor γ π ′ = π 0 (default: uniformly random) rep eat π = π ′ T ra iningSet = ∅ for (each s ∈ S R ) do for (each a ∈ A ) do estimate Q π ( s, a ) using K rollo uts of length T end for if (a dominating action a ∗ exists in s ) then T ra iningSet = T rainingSet ∪ { ( s, a ∗ ) + } T ra iningSet = T rainingSet ∪ { ( s, a ) − } , ∀ a 6 = a ∗ end if end for π ′ = TrainClassifier (T ra iningSet) un til ( π ≈ π ′ ) return π approximate na ture of this po licy itera tion, the termination condition cannot rely o n con vergence to a single optimal p olicy . Rather, it terminates when the per formance o f the new p olic y (measured via simulation) do es not exc eed that of the previo us p olicy . The RCPI a lgorithm has yielded promising res ults in several le arning do- mains, how ever, as s tated also by Lagoudak is Lagouda kis (20 03), it is sensitive to the distribution of states in S R ov er the state s pace. F or this reaso n it is suggested to draw s ta tes fro m the γ -dis c ounted future state distribution of the improv ed po licy . This tricky-to-sample dis tribution, also sugges ted by F ern et al. F er n et al. (2 004), yields b etter results and resolves a ny p otential mismatch betw ee n the training and testing distributio ns of the classifier. Ho wev er, the main drawbac k is still the exces s ive computational cos t due to the need for lengthy and r ep eated rollouts to reach a go o d level of accuracy . In o ur exp er- imen ts with RCPI, it has been o bserved that most of the effort is w as ted o n states wher e ac tio n v alue differ e nc e s are either non-existent or so fine that they require one to use a prohibitive num b e r of r ollouts to iden tify them. Significa nt effort is als o wasted on sampling states wher e a dominating action could b e easily identified without exhausting all rollouts allo cated to it. In this pap er, we pro po se rollout sampling metho ds to remov e this perfor mance b ottle-neck. 5 Algorithm 2 SampleSt a te Input: state s , p olicy π , horizon T , discount fa ctor γ for (each a ∈ A ) do ( s ′ , r ) = Simula te ( s, a ) ˜ Q π ( s, a ) = r x = s ′ for t = 1 to T − 1 do ( x ′ , r ) = Simula te ( x, π ( x )) ˜ Q π ( s, a ) = ˜ Q π ( s, a ) + γ t r x = x ′ end for end for return ˜ Q π ( s, · ) 4 Rollout Sampling P olicy Iteration The excess ive sa mpling cost mentioned ab ove can b e r e duce d by careful ma n- agement o f reso urces. The scheme suggested by RCPI, also use d b y F ern et al. F er n et al. (20 04), is somewha t na ¨ ıve; the same num b er o f K |A| rollouts is allo cated to each sta te in the subset S R and all K ro llouts dedicated to a single action are e xhausted b efor e moving on to the next action. Intuitiv ely , if the de- sired o utcome (domination of a single a ction) in some state can b e confidently determined ear ly , there is no need to exhaust a ll K |A| rollouts av ailable in that state; the tra ining data co uld b e sto red a nd the state co uld b e remov ed from the po ol without further examination. Simila rly , if we can confident ly determine that a ll a ctions are indifferen t in some state, we can simply reject it without wasting a ny mor e rollouts; such rejected s tates could be replaced by fre s h ones which might yield meaningful results. These ideas lead to the following ques- tion: can we examine all states in the subset S R collectively in some interlea ved manner b y choosing each time a single state to fo cus on, allo ca ting r ollouts only as needed? A similar resource allo cation setting in the co ntext of reinforcement learning are bandit pro blems. Therein, the le arner is faced with a ch o ice betw een n ban- dits, each one having an unknown reward function. The task is to allo c a te plays such as to discov er the bandit with the highest exp ected r eward without wasting to o many r esources in either cumulativ e reward, or in n umber of plays required 1 . T ak ing inspira tion from such pro blems, we view the set of rollo ut states a s a m ulti-a rmed bandit, where each state corresp o nds to a single lever/arm. Pulling a lever cor resp onds to sampling the corresp onding state once. By sampling a state we mean that we p e rform a single rollout for ea ch a ction in that state as shown in Algorithm 2. This is the minim um a mo unt of information we can 1 The precise definition of the task depends on the sp ecific problem f ormulation and is beyond the s cope of this article. 6 request from a single state 2 . Thus, the problem is transformed to a variant of the classic multi-armed bandit pr oblem. Several metho ds hav e b een prop os e d for v arious versions o f this problem, which could p otentially be used in this context. In this pape r , we fo cus on three of them: simple counting, upper con- fidence b ounds Auer et al. (2002), and successive elimination Ev en-Dar et al. (2006). Our goa l at this p oint is to co llect go o d tr aining data for the classifier with as little computational effort as p o ssible. W e can quantify the notion o f go o d- ness for the training data in ter ms of three guar a ntees: (a) that s tates will b e sampled o nly as needed to pro duce training data without w asting rollouts, (b) that with high pro ba bility , the discov er ed action lab els in the tr a ining da ta in- dicate domina ting actions, and (c) that the tra ining data cover the state spac e sufficiently to pro duce a go o d repr e sentation of the entire p olicy . W e lo o k at each o ne of these o b jectives in turn. 4.1 Rollout Man agemen t As mentioned previously , our alg orithm maintains a po ol of states S R from which sampling is p erfor med. In this pap er , s tates s ∈ S R are dr awn from a uniformly r a ndom distributio n to cov er the state spa ce evenly , how ever other, more sophisticated, distributions may also b e used. In order to a llo cate rollouts wisely , we need to decide which s tate to sa mple fr o m at every step. W e also need to determine c r iteria to decide when to stop sampling fro m a state, when to add new s tates to the po o l, and fina lly when to sto p sampling completely . The gener al form of the state selection rule for all algo rithms is: s = a rg max s ′ ∈ S R U ( s ′ ) , where U ( s ) represents the utility ass o ciated with sampling state s . The pr e- sented alg orithms use one o f the fo llowing v ariants: 1. Count , Su ccE : U ( s ) , − c ( s ) 2. SUCB1 : U ( s ) , ˆ ∆ π ( s ) + p 1 / (1 + c ( s )) 3. SUCB2 : U ( s ) , ˆ ∆ π ( s ) + p ln m/ (1 + c ( s )) where c ( s ) is a counter reco r ding the n umber of times state s ha s been s a mpled, m is the total num b er of sta te samples, and ˆ ∆ π ( s ) is the empirical counterpart of the marg inal difference ∆ π ( s ) in Q π v alues in state s defined as ∆ π ( s ) , Q π ( s, a ∗ s,π ) − max a 6 = a ∗ s,π Q π ( s, a ) , 2 It is p ossible to also manage sampling of the actions within a state, but our preliminary experiments show ed that managing action sampling alone s a ved little effort compared to managing state sampling. W e are curren tly working on managing sampl ing at both leve l s. 7 where a ∗ s,π is the action 3 that maximizes Q π in state s : a ∗ s,π = a rg ma x a ∈A Q π ( s, a ) . Similarly , the empirica l difference ˆ ∆ π ( s ) is defined in ter ms of the empirical Q v alues : ˆ ∆ π ( s ) , ˆ Q π ,T K ( s, ˆ a ∗ s,π ) − max a 6 =ˆ a ∗ s,π ˆ Q π ,T K ( s, a ) , where ˆ a ∗ s,π is the action that maximizes ˆ Q π ,T K in state s : ˆ a ∗ s,π = a rg ma x a ∈A ˆ Q π ,T K ( s, a ) , with K = c ( s ) and some fix ed T indep endent of s . The Count v aria nt is a simple counting criterio n, where the s ta te that has bee n s ampled least has higher prio rity for b eing sampled next. Since we stop sampling a state as so on as w e hav e a sufficiently go o d estimate, this cr iterion should r esult in less sampling compared to R CPI , whic h c o ntin ue s sampling even after an estimate is deemed sufficien tly go o d. The SuccE v ar ia nt uses the same criterion as Cou nt to sample states, but features an additional mechanism for r emoving a ppa rently hop eless states from S R . This is based on the Successive Elimination algor ithm (Algo rithm 3 in E ven-Dar et al. (200 6)). W e exp ect this criter ion to be us eful in problems with many sta tes where all actions are indifferent. Howev er, it might als o result in the contin ual r e jectio n of small-difference s ta tes until a high-difference s tate is sampled, effectively limiting the a mount of state spa ce covered b y the final gathered examples. The SUCB1 v ariant is based on the UCB algorithm Auer et al. (2 0 02) and gives higher pr iority to states with a high empirical difference and high un- certaint y as to what the differ ence is. Thus, states can take priority for tw o reasons . Firstly , becaus e they hav e b een sa mpled less, and secondly b ecause they ar e more likely to result in a cceptance quickly . The SUCB2 v a riant is base d on the or iginal UCB1 algorithm by Auer Auer et al. (2002), in that it uses a shrinking erro r b ound for calcula ting the uppe r confi- dence in terv al. Since in our setting we stop sampling states where the difference in actions is sufficien tly lar g e, this will b e similar to simple counting as the pro cess co ntin ues . How ever, intuitiv ely it will focus on those states that are most lik ely to res ult in a positive identification of a dominating action quickly tow ards the end. In all cases, new states are a dded to the po ol as s o on as a state has b een remov ed, so S R has a constant size. The criterion for selecting examples is describ ed in the following section. 3 The case of multiple equiv alent maximizing actions can be easily handled by generalising to sets of actions in the manner of F ern et al. F ern et al. (2006). Here we discuss only the single best action case to simplify the exposition. 8 4.2 Statistical Significance Sampling o f states pro ceeds a ccording to one o f these rules a t eac h s tep. Once a state is identified as “go o d”, it is remov ed fro m the state po ol a nd is added to the training data to preven t fur ther “wasted” sampling on that state 4 . In order to terminate sampling and accept a state as g o o d, we rely on the following well-kno wn lemma. Lemma 4. 1 (Ho effding i nequalit y) L et X b e a r andom variable i n [ b 1 , b 2 ] with ¯ X , E [ X ] , observe d values x 1 , x 2 , . . . , x n of X , and ˆ X n , 1 n P n i =1 x i . Then P ( ˆ X n ≥ ¯ X + ǫ ) = P ( ˆ X n ≤ ¯ X − ǫ ) ≤ exp − 2 nǫ 2 / ( b 1 − b 2 ) 2 . Consider t wo rando m v ar iables X , Y , their true means ¯ X , ¯ Y , and their em- pirical means ˆ X n , ˆ Y n , as well as a ra ndom v ariable ∆ , X − Y repr esenting t heir difference, its true mean ¯ ∆ , ¯ X − ¯ Y , and its empirical mea n ˆ ∆ n , ˆ X n − ˆ Y n . If ∆ ∈ [ b 1 , b 2 ], it fo llows from Lemma 4 .1 that P ( ˆ ∆ n ≥ ¯ ∆ + ǫ ) ≤ exp − 2 nǫ 2 ( b 2 − b 1 ) 2 . (1) W e no w co nsider a pplying this for determining the be s t action at any state s where we have taken c ( s ) sa mples from every action. As previously , let ˆ a ∗ s,π be the empirica lly o ptimal actio n in that state. If ∆ π ( s ) ∈ [ b 1 , b 2 ], then for any a ′ 6 = ˆ a ∗ s,π , we can set ¯ X = Q π ( s, ˆ a ∗ s,π ), ¯ Y = Q π ( s, a ′ ), a nd corresp ondingly ˆ X n , ˆ Y n to obtain: P ˆ Q π ( s, ˆ a ∗ s,π ) − ˆ Q π ( s, a ′ ) ≥ Q π ( s, ˆ a ∗ s,π ) − Q π ( s, a ′ ) + ǫ ≤ exp − 2 c ( s ) ǫ 2 ( b 2 − b 1 ) 2 . (2) Corollary 4. 1 F or any state s wher e the fol lowing c ondition hold s ˆ ∆ π ( s ) ≥ v u u t ( b 2 − b 1 ) 2 2 c ( s ) ln |A| − 1 δ ! , (3) the pr ob ability of inc orr e ct ly identifying a ∗ s,π is b ounde d by δ . Pro of W e can set ǫ equal to the right hand side of (3), to obtain: P ˆ Q π ( s, ˆ a ∗ s,π ) − ˆ Q π ( s, a ′ ) ≥ Q π ( s, ˆ a ∗ s,π ) − Q π ( s, a ′ ) + v u u t ( b 2 − b 1 ) 2 2 c ( s ) ln |A| − 1 δ ! ≤ δ / ( |A| − 1) , (4) 4 Of course, i f we wan ted to cont inuously shrink the probabili t y of error we could contin ue sampling from those states. 9 Incorrectly iden tifying a ∗ s,π implies that there e x ists s ome a ′ such that Q π ( s, ˆ a ∗ s,π ) − Q π ( s, a ′ ) ≤ 0, while ˆ Q π ( s, ˆ a ∗ s,π ) − ˆ Q π ( s, a ′ ) > 0. Howev er, due to our stopping condition, ˆ Q π ( s, ˆ a ∗ s,π ) − ˆ Q π ( s, a ′ ) ≥ ˆ ∆ π ( s ) ≥ s ( b 2 − b 1 ) 2 2 c ( s ) ln[( |A| − 1) /δ ] , so in order to make a mistake concer ning the ordering of the tw o actions, the estimation e rror must b e large r than the righ t side of (3). Thus, this probability is also b ounded by δ / ( |A| − 1). Giv en that the num b er o f actions a ′ 6 = ˆ a ∗ s,π is |A| − 1, an a pplication of the union bound implies that the to tal probability o f making a mistake in state s must b e b o unded by δ . In summary , ev ery time s is sampled, b oth c ( s ) and ˆ ∆ π ( s ) change. Whenever the stopping condition in (3) is satisfied, s tate s can be safely removed from S R ; with high pr obability (1 − δ ) the current empirical difference v a lue will not change sign with further sampling and confidently the resulting action lab el is indeed a dominating action 5 . Fina lly note that in practice, w e mig ht not be able to obtain full tra jectories – in this cas e, the estimates and true v alue functions should b e r e placed with their T -hor izon versions. 4.3 State Spa ce C ov erage F or each po licy improv ement s tep, the a lgorithm terminates when we hav e suc- ceeded in collecting n max examples, o r when we hav e p erformed m max rollouts. Initially , | S R | = n max . In or der to make sure that tr aining data are not restricted to a static subset S R , ev er y time a state is c har a cterized go o d a nd removed fr om S R , we add a new state to S R drawn fro m some fixed distribution D R that serves as a s ource of ro llout states. The simplest ch o ice for D R would b e a unifor m distribution over the state spa ce, howev er other choices ar e p ossible, esp ecially if domain knowledge a b o ut the str ucture of go o d p olicies is known. A sophis- ticated choice of D R is a difficult problem itself a nd we do not inv estig a te it here; it has b een conjectur e d tha t a go o d c hoic e is the γ -discounted future state distribution of the impr ov ed policy b eing lear ned Lag oudakis and Parr (20 03b); F ern e t al. (2004). W e ha ve also toy ed with the idea o f r ejecting sta tes which seem hop eless to pro duce training data, replacing them with fresh states sampled from some distribution D R . The SuccE rule incorp ora tes such a rejection criterion b y default E ven-Dar et al. (200 6). F or the other v ar ia nts, if r ejection is adopted, we re ject all states s ∈ S R with U ( s ) < √ ln m , which suits SUCB2 pa rticularly well. The complete alg orithm, called R ol lout Sampling Policy It er ation ( RSPI ), is descr ib e d in de ta il in Algorithm 3. The call to SelectSt a te refers to one of 5 The original RCP I algorithm employ ed a pairwise t -test. This c hoice is fla wed, since it assumes a normal distribution of errors, whereas the Ho effding b ound si m ply assumes that the v ariables are b ounded. 10 the four selection rule s describ ed ab ove. Note that a call to SuccE might a lso eliminate some states from S R replacing them with fresh ones dr awn from D R . Algorithm 3 Rollout Sampling Policy Iteration Input: distribution D R , initial p olicy π 0 , horizon T , discount factor γ , max data n max , max samples m max , probability δ , number of rollout states N , Boolean Rejec- tion, range [ a, b ] π ′ = π 0 (default: random), n = 0, m = 0 S R ∼ D N R (default: N = n max ) for all s ∈ S R , a ∈ A : ˆ Q π ( s, a ) = 0, ˆ ∆ π ( s ) = 0, U ( s ) = 0, c ( s ) = 0 repe at π = π ′ T rainingSet = ∅ while ( n ≤ n max and m ≤ m max ) do s = SelectSt a te ( S R , ˆ ∆ π , c, m ) ˜ Q π = Sam pleSt a te ( s, π , T , γ ) up date ˆ Q π ( s, a ), ˆ ∆ π ( s ), and U ( s ) using ˜ Q π ( s, a ) c ( s ) = c ( s ) + 1 m = m + 1 if 2 c ( s ) “ ˆ ∆ π ( s ) ” 2 ≥ ( b 2 − b 1 ) 2 ln |A| − 1 δ !! then n = n + 1 T rainingSet = T rainingSet ∪ { ( s, ˆ a ∗ s,π ) + } T rainingSet = T rainingSet ∪ { ( s, a ) − } , ∀ a 6 = ˆ a ∗ s,π S R = S R − { s } S R = S R ∪ { s ′ ∼ D R } end if if (R ejection) then for (each s ∈ S R ) do if ( U ( s ) < √ ln m ) then S R = S R − { s } S R = S R ∪ { s ′ ∼ D R } end if end for end if end whil e π ′ = TrainClassifier (T rainingSet) un til ( π ≈ π ′ ) return π 5 Exp erimen ts T o demo nstrate the p er formance of the pro p o sed algor ithm in practice a nd to set the basis for comparison with R CP I , we present exp erimental results on t wo standa r d reinforcement lea rning do mains, na mely the inv erted p endulum and the mountain car. In bo th do mains, we tried several settings of the v ario us 11 parameters related to state sampling. How ever, w e kept the learning par ameters of the classifier constant and us ed the new statistical test even for RCPI to filter out their influence. In all cases, we measured the p erforma nc e of the resulting po licies aga inst the effort needed to derive them in ter ms of num b er o f samples. Section 5.1 and 5.2 descr ib e the lea rning domains, while the exact ev alua tio n metho d used and results are des crib ed in Sectio n 5 .3. 5.1 In ve r t ed P endulum The inverte d p endulum problem is to bala nce a p endulum of unknown length and mass at the upr ight p osition by a pplying forces to the cart it is attached to. Three a ctions are allow ed: left force (LF), r ight force (RF), or no fo r ce (NF), applying − 50 N , +50 N , 0 N r esp ectively , with uniform no ise in [ − 1 0 , 10 ] added to the chosen action. Due to the noise in the pro blem, the r eturn from any single state-action pair is sto chastic even though w e a re only employing deterministic po licies. Ha d this not b een the case, w e w o uld have needed but a single sample from each state. The state spa ce is contin uous and consists of the vertical angle θ and the a ngular velocity ˙ θ of the p endulum. The transitions a re governed by the nonlinear dynamics of the system W ang et al. (19 96) and depend on the current state and the curre nt control u : ¨ θ = g sin( θ ) − αml ( ˙ θ ) 2 sin(2 θ ) / 2 − α cos( θ ) u 4 l / 3 − αml co s 2 ( θ ) , where g is the gr avit y consta nt ( g = 9 . 8 m/s 2 ), m is the mass of the pe ndulum ( m = 2 . 0 kg), M is the mass of the cart ( M = 8 . 0 kg), l is the length of the pendulum ( l = 0 . 5 m), a nd α = 1 / ( m + M ). The sim ulation step is 0 . 1 seconds, while the control input is changed only at the beg inning of each time step, and is kept constant for its duration. A r eward of 0 is given as long as the angle of the pendulum do es not exceed π / 2 in absolute v alue (the p endulum is a bove the ho rizontal line). An angle greater than π / 2 sig nals the end of the episo de and a reward (penalty) of − 1. The discount f a ctor of the pr o cess is set to 0 . 9 5. This forces the Q v alue function to lie in [ − 1 , 0], so we can set b 1 = − 1 , b 2 = 0 for this proble m. 5.2 Moun tain-Car The mountain-c ar problem is to drive an underp owered car fro m the b ottom of a v a lley b etw een tw o moun tains to the top of the mountain o n the right. The car is not powerful enough to climb a ny of the hills directly from the b ottom of the v alley even at full thro ttle; it must build some momentum b y climbing first to the left (moving aw ay from the go al) and then to the right. Thr ee actions are allow ed: forward throttle FT (+1), reverse throttle R T ( − 1), or no thro ttle NT (0). The original specification a ssumes a deterministic tra nsition mo del. T o make the pr oblem a little mo r e c ha lle nging we ha ve added nois e to all three actions; uniform noise in [ − 0 . 2 , 0 . 2] is added to the c hos en action’s effect. Aga in, 12 due to the noise in this problem, the returns are sto chastic, th us necess itating the use of m ultiple sa mples at ea ch state. The state s pace of the pr oblem is contin uous a nd co nsists of the p o sition x and the velocity ˙ x of the ca r a lo ng the horizontal a x is. The transitions ar e gov erned b y the s implified nonlinear dynamics o f the system Sutton and Barto (1 998) and dep end on the c urrent state ( x ( t ) , ˙ x ( t )) and the current (noisy ) control u ( t ): x ( t + 1) = Bound x [ x ( t ) + ˙ x ( t + 1)] ˙ x ( t + 1) = Bound ˙ x [ ˙ x ( t ) + 0 . 00 1 u ( t ) − 0 . 0025 cos(3 x ( t ))] , where Bound x is a function that keeps x within [ − 1 . 2 , 0 . 5], while Bound ˙ x keeps ˙ x within [ − 0 . 07 , 0 . 07]. If the ca r hits the left bound of the p osition x , the velocity ˙ x is set to zero . F or this problem, a p enalty of − 1 is given at ea ch step as long as the p osition of the car is b elow the right b ound (0 . 5). As so on as the car p os itio n hits the right b o und, the episo de ends success fully and a reward o f 0 is given. The discount facto r of the pr o cess is set to 0 . 99. Cho osing [ b 1 , b 2 ] for this problem is trickier, since without a ny further conditions, the v alue function lies in ( − 100 , 0 ]. How ever, the difference b etw een Q v alues fo r an y state do es not v ary muc h in practice. That is, for mos t state and p o lic y combinations the initial a ction do es not alter the final r eward by more than 1. F or this reason, we used | b 1 − b 2 | = 1. 5.3 Ev aluation After a preliminary investigation we selected a multi-la yer per ceptron with 10 hidden units as the class ifier for representing p olicies and s to chastic gra dient descent with a learning rate of 0 . 5 for 2 5 iterations of training. Note that this is only one of n umer ous choices. The main problem w as to devise an exp er iment to determine the computa- tional effort that would be required by each metho d to find an o ptimal po licy in practice. This meant that for each metho d w e w o uld have to s imulate the pro cess of manual tuning that a practitioner would p er form in or der to discov er optimal so lutions. A usual pra ctice is to p erfor m a grid sea rch in the s pace of hyper-pa r ameters, with multiple runs p er g r id po int. Assuming that the exp erimenter can p erform a num b er of such runs in par allel, we can then use the n umber of solutions found after a c e rtain num b er of samples taken b y eac h metho d as a practical metric of the sample complexity of the alg orithms. More specifically , we tested all the pro p o sed state selection meth o ds ( Count , SUCB1 , SUCB2 , SuccE ) with RSPI and R CPI for each pro blem. F or all metho ds, w e used the follo wing sets of h yp er-pa r ameters: m max , n max ∈ { 10 , 2 0 , 50 , 100 , 200 } , and δ ∈ { 10 − 1 , 10 − 2 , 10 − 3 } for the p endulum and δ ∈ { 0 . 5 , 1 0 − 1 , 10 − 2 } for the car 6 . W e perfor med 5 runs with different random seeds for e a ch h yp er -parameter combination, for a total o f 3 75 runs p er metho d. After each run, the resulting po licy was tested for quality; a p olicy that could balance the p endulum for a t 6 In exploratory runs, it appeared particularly hard to obtain an y samples at all for the car problem with δ = 10 − 3 so we used 0 . 5 instead. 13 0 20 40 60 80 100 120 140 160 180 100 1000 10000 cumulative number of successful runs number of samples RCPI CNT SUCB1 SUCB2 SUCCE Figure 1: The cumulativ e distribution of successful runs (at least 1 000 steps of balancing) in the pendulum domain. least 1 000 s teps or a p o licy that c ould dr ive the car to the go al in under 75 steps from the sta r ting p osition were considered success ful (practically optimal). W e repor t the cumulativ e distribution of succ essful p olicies found ag ainst the n umber o f samples (rollo uts) us e d b y e a ch metho d, summed ov er all runs. F or mally , if x is the num b er o f s amples a lo ng the hor izontal axis, we plot the measure f ( x ) = µ { π i : π i is successful , m i ≤ x } , i.e. the hor izontal axis shows the least num b er of samples required to o btain the num b er o f s uc c essful runs shown in the vertical a xis. Effectively , the figures show the num b er of s amples x required to obtain f ( x ) near -optimal policies, if the ex pe rimenter was fortuitous enough to select the appropr iate hyper -para meter s. In more de ta il, Figure 1 shows the results for the p endulum pr oblem. While the Count , S UCB1 , SU CB2 , SuccE metho ds have approximately the same total num b er of success ful runs, SUCB1 clearly dominates, as after 4 0 00 s a mples per r un, it had already obtained 180 succes sful policies ; at that point it has six times more chances of pro ducing a succes s ful p olic y compa red to RCPI . In the contrary , RCPI o nly managed to pro duce less than half the tota l num b er of po licies as the first metho d. More impor tantly , none of its runs had pro duced any suc c e ssful p olicies at a ll with fewer than 2000 samples – a po int at which all the other methods w er e alrea dy making significant progr ess. Perhaps it is w or thwhile noting a t this p o int that the step-wise form of the R CPI plot is due to the fact that it was alwa ys terminating sampling when all its rollouts ha d been exhausted. The o ther metho ds may also terminate whenever n max go o d samples hav e been obtained. Due to this reas on, the plots might terminate at an earlier stage. 14 Similarly , Figure 2 shows the results for the moun tain-ca r pr oblem. This time, we consider runs where les s than 7 5 steps have been taken to reach the goal as succes sful. Again, it is clear that the prop osed metho ds p erfor m b etter than R CPI as they hav e hig her c ha nces of pr o ducing go o d p olic ie s with few er samples. Once ag ain, SUCB1 exhibits an a dv antage over the o ther metho ds. How ever, the differences be tween metho ds are slightly finer in this do main. It is interesting to note tha t the r esults were not very sensitive to the actual v alue of δ . In fact we were usua lly able to obtain g o o d po lic ies with quite lar ge v alues (i.e. 0 .5 in the mountain c a r domain). On the other hand, if one is working with a limited budget of rollouts, a very small v alue o f δ , might make conv erge nce imp ossible, s ince there a re no t e no ugh rollouts a v ailable to obtain the b est actions with the necessary confidence. A similar thing o ccurs when | b 2 − b 1 | is very large, as we noticed with initial exp eriments with the mountain car where we had set them to [ − 100 , 0]. Perhaps predictably , the most important par ameter appeared to be n max . Below a certain thresho ld, no go o d p o licies could b e found by a ny algor ithm. This in gener al o ccurr ed when the total num b er of go o d states at the end o f a n iteration were to o few for the classifier to be a ble to create an improv ed p olicy . Of course, when δ and n max are v er y la rge, there is no g uarantee for the per formance of p olicy improv ement, i.e. we cannot bound the probability that all o f the s tates will use the correct action lab els. Howev er, this do es not app ear to b e a problem in pra c tice . W e p o sit t wo factors that may expla in this. Fir stly , the relatively lo w stochasticity of the problems: if the environmen ts and p olicies were deter ministic, then a sing le sa mple would ha ve b een enoug h to determine the optimal action at each state. Secondly , the smo othing influence of the classifier may b e sufficient for p olicy improv ement ev en if some p ortion of the states sampled have incor rect lab els. Computational time do es no t give mea ningful measur ement s in this setting as the time taken for each tra jectory dep ends on how many steps pa ss until the episo de ter minates. F or some problems (i.e. infinite-horizo n pr oblems with a finite horiz o n cutoff fo r the rollout estimate), this may b e consta nt , but for others the length of time v a ries with the quality of the po licy: in the pendulum domain, p olicies run for lo nger as they improv e, while the opp osite o ccurs in the mountain car problem. F or this reason we decide d to only rep or t results of computational complex ity . W e would finally lik e to note tha t our experiments with additional rejections and replacements of states failed to pro duce a further improv ement. Howev er, such methods might be of use in environmen ts wher e the actions are indistin- guishable in most states. 6 Discussion The propos e d appro aches deliver equally go o d policies as those pro duced by R CPI , but with significantly less e ffort; in both problems, there is up to an order of magnitude reduction in the n umber of rollouts per formed and thus 15 0 20 40 60 80 100 120 160 100 1000 10000 100000 1e+06 cumulative number of successful runs number of samples RCPI CNT SUCB1 SUCB2 SUCCE 140 Figure 2: The cumulative distribution of successful runs (less than 75 steps to reach the goal) in the mountain-car domain. in computatio nal effort. W e thus conclude that tha t the selective sampling approach can make rollout a lgorithms muc h more practical, esp e cially since similar approa ches hav e already demonstr ated their effectiveness in the pla n- ning domain Ko csis and Szepes v´ ari (2006). How ever, some practical o bstacles remain - in par ticula r, the choice of δ, n max , | b 1 − b 2 | is not ea s y to determine a priori, esp ecially when the choice o f classifier needs to b e taken into account as well. F or example, a nea rest-neighbour cla ssifier may not tolera te as large a δ as a soft-margin supp or t vector mac hine. Unfortunately , at this p oint, the choice of hyper- parameters can only be done via lab or io us exp er iment a tion. Even so, since the original algor ithm suffered from the same problem, the exp erimenter is at lea st assured that no t as muc h time will b e sp ent until an optimal solutio n is found, as our results show. Currently the bandit algor ithm v a riants employ ed for s tate rollout selection are used in a heuristic manner . How ever, in a companion pap er Dimitrak akis a nd L a goudakis (2008), we hav e analyzed the whole p olicy iter a tion pro cess a nd pr ov ed P AC- style b ounds on the progress tha t the Count metho d is guaranteed to make under certain as sumptions o n the underlying MDP mo del. W e hop e to extend this w or k in the f uture in order to produce bandit-like algorithms that are specif- ically tuned for th is task . F urthermo r e, w e plan to address rollout sampling both at the state a nd the action levels a nd fo c us our attention on sophistica ted state sampling dis tributions a nd on exploiting sa mpled states for which no c lear neg- ative o r p ositive action exa mples ar e drawn, poss ibly by developing a v a riant of the upper b ound on trees a lgorithm Ko csis a nd Szep esv´ ari (2006). An comple- men ta ry r esearch route would b e to in tegr ate sa mpling pro cedures with fitting 16 algorithms that c a n use a single tra jector y , such as An to s et al. (200 8). In s ummary , we have pres ent ed an approximate policy iteration sc heme for reinforcement learning, whic h relies on classification technology for p olicy repre- sentation and lear ning a nd cle ver ma nagement of resources for obtaining data. It is our belief that the s ynergy b etw een these t wo learning para digms has still a lot to reveal to machine learning res earchers. Ac kno wledgemen ts W e would like to thank the reviewers for providing v aluable feedback and Kate- rina Mitr okotsa for a dditio nal pro ofreading. This work was partially suppor ted by the ICIS-IAS pro ject and the Eur op ean Marie- Cur ie International Reinte- gration Grant MCIR G-CT- 2006- 04498 0 a warded to Mic ha il G. Lag oudakis. References Andr´ as Antos, Csaba Szep esv ´ ar i, and R ´ emi Munos. Learning near-o ptimal po licies with Bellman-residual minimization based fitted p olicy iteration and a single sample pa th. Machine L e arning , 71(1):89 –129 , Apr 2008 . doi: 10. 1007/ s1099 4- 007- 5038- 2. P . Auer, N. Ce s a-Bianchi, and P . Fischer. Finite-time analysis of the m ultiarmed bandit proble m. Mach ine L e arning Journal , 47 (2-3):235 –256 , 2002. Christos Dimitrak akis and Michail Lag oudakis. Algorithms and b ounds for sampling-base d appro xima te p o licy iteration. (T o be presented at the 8th Europ ean W o rkshop on Reinforcement Lear ning ), 2008. Eyal Even-Dar, Shie Mannor, and Yishay Ma nsour. Action elimination and stopping conditions for the m ulti-armed bandit and reinforcement learning problems. Journal of Machine L e arning R ese ar ch , 7:10 79–11 05, 20 06. ISSN 1533- 7928. A. F ern, S. Y o on, a nd R. Giv an. Approximate p olic y iteration with a p o licy language bias. Ad vanc es in Neu r al Information Pr o c essing Systems , 16(3), 2004. A. F ern, S. Y o on, and R. Giv an. Approximate policy iteration with a po lic y lan- guage bias: Solving r elational Markov decision pro cesses. Journal of Artificial Intel ligenc e R ese ar ch , 25 :75–1 18, 200 6. Ronald A. How ar d. Dynamic Pr o gr amming and Markov Pr o c esses . The MIT Press, Cambridge, Massach usetts, 1960 . Leven te Ko csis and Csaba Szep esv´ ari. Bandit bas ed Monte-Carlo planning. In Pr o c e e dings of the Eur op e an Confer enc e on Machine L e arning , 2006. 17 M.G. La goudakis and R. Parr. Least-Squar es Policy Iteration. Journal of Ma- chine L e arning R ese ar ch , 4(6):11 07–1 149, 2003 a. Michail G. Lago udakis. Effici ent Appr oximate Policy Iter ation Metho ds for Se quential De cision Making in R einfor c ement L e arning . PhD thesis, Depart- men t of Computer Science, Duk e University , May 20 0 3. Michail G. Lagouda kis a nd Ronald Parr. Reinfo r cement lear ning as clas sifica- tion: Leveraging mo dern classifiers. In Pr o c e e dings of the 20th International Confer enc e on Machine L e arning (ICML) , pages 424–4 31, W ashington, DC, USA, August 2 003b. John La ngford and Bianca Za drozny . Relating reinforcement learning p erfo r- mance to classification p erforma nce. I n Pr o c e e dings of the 22nd Interna- tional Confer enc e on Machine le arning (ICML) , pag e s 473– 480, Bonn, Ger - many , 200 5. ISBN 1-59593 -180- 5. doi: http://doi.acm.org/1 0.114 5 /1102351. 11024 11. Ioannis Rexakis and Mic hail Lagouda kis. Cla ssifier-ba s ed p olicy repr esentation. (T o b e presented at the 8 th Euro p ean W o rkshop on Reinforcement Learning), 2008. M. Riedmiller. Neural fitted Q iteratio n-first exp eriences with a data efficient neural reinforcement learning metho d. 16th Eur op e an Confer enc e on Machine L e arning , pages 317–3 28, 20 05. Richard Sutton a nd Andrew Barto. R einfor c ement L e arning: An In t r o duct ion . The MIT Pr ess, Cambridge, Massach usetts, 1998. Hua O. W ang, K azuo T anak a, and Mic hae l F. Griffin. An a pproach to fuzzy control of nonlinear systems: Stabilit y and design issues. IEEE T r ans actions on F uzzy Systems , 4(1):14– 2 3, 1 996. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment